VeRL Async Policy
导言
VeRL async 的核心问题不是“开异步就一定更快”,而是把 rollout 长尾、训练更新、参数同步和旧样本容忍度放到同一个队列系统里调参。这篇笔记梳理 VeRL 老版 one_step_off_policy / fully_async_policy 与新版 trainer v1 的关系,解释 staleness 的真实语义,并给出 64P、128P NPU 场景下选择训推资源比例的第一轮计算方法。
结论速记¶
- 新版入口应优先看 trainer v1:当前 VeRL
main_ppo.py已经通过trainer.use_v1=True进入TaskRunnerV1,并用trainer.v1.trainer_mode选择sync、colocate_async、separate_async。ppo_trainer.yaml里默认use_v1: true、trainer_mode: sync。 - 旧版 async 仍有参考价值:
one_step_off_policy解释了一步错位 overlap;fully_async_policy更完整地暴露staleness_threshold、trigger_parameter_sync_step、partial_rollout和独立 Trainer/Rollouter 资源配置。 - staleness 不是简单“推理完多推百分比”:旧版 fully async 里它表示允许使用旧参数样本的最大比例;V1 replay buffer 里还会记录 trajectory 跨越的模型版本数和相对当前训练步的滞后。
- 64P/128P 资源配比应先看同步耗时结构:如果同步 profile 显示 rollout:train 约为
3:1,第一轮可以从train:rollout ≈ 1:3开始,即 64P 试16:48,128P 试32:96,再用trainer/idle_ratio、rollouter/idle_ratio和实际 step time 回调。 - 异步不保证单步时间或单卡吞吐一定变好:当训推比例错、参数同步开销高、rollout 队列过旧、NPU 后端通信或显存切换成本过大时,单步时间可能下降有限,单卡吞吐也可能低于 32P 基线。
新旧实现¶
VeRL async 现在至少有三层容易混在一起的实现。
one-step overlap¶
老的 one_step_off_policy 入口是:
python3 -m verl.experimental.one_step_off_policy.async_main_ppo \
--config-path=config \
--config-name='one_step_off_ppo_trainer.yaml' \
actor_rollout_ref.hybrid_engine=False \
trainer.nnodes=1 \
trainer.n_gpus_per_node=6 \
rollout.nnodes=1 \
rollout.n_gpus_per_node=2
它的机制是训练当前 batch 时异步生成下一个 batch。官方文档给出的近似拆解是:
- colocate sync:
step ≈ gen + old_log_prob + update_actor - one-step-overlap async:
step ≈ wait_prev_gen + old_log_prob + update_actor
所以它主要吃掉的是 rollout 与训练之间的串行等待,但仍然比较像“一步错位”的固定策略,灵活度有限。官方说明 里 32 张 H20、Qwen2.5-Math-7B 的例子显示 FSDP2 从 19h18m 降到 15h34m,Megatron 从 18h21m 降到 13h06m。
fully async policy¶
fully_async_policy 入口仍在 experimental 下:
python -m verl.experimental.fully_async_policy.fully_async_main \
actor_rollout_ref.hybrid_engine=False \
actor_rollout_ref.rollout.mode=async \
trainer.nnodes="${NNODES_TRAIN}" \
trainer.n_gpus_per_node="${NGPUS_PER_NODE}" \
rollout.nnodes="${NNODES_ROLLOUT}" \
rollout.n_gpus_per_node="${NGPUS_PER_NODE}" \
async_training.staleness_threshold="${staleness_threshold}" \
async_training.trigger_parameter_sync_step="${trigger_parameter_sync_step}" \
async_training.partial_rollout="${partial_rollout}"
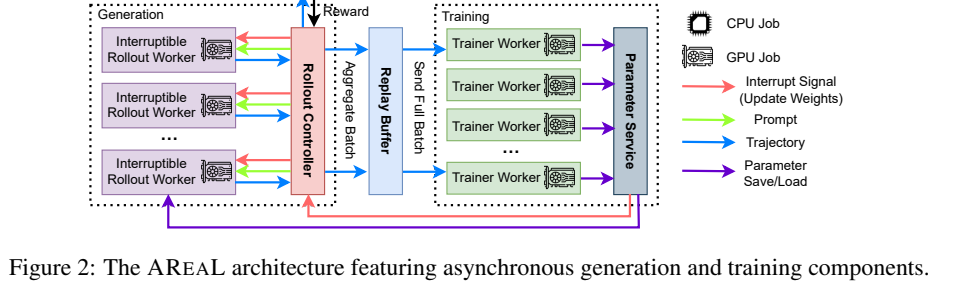
它把系统拆成 Rollouter、MessageQueue、Trainer 和 ParameterSynchronizer 四部分:Rollouter 单样本流式生成,Trainer 从队列取够 require_batches * ppo_mini_batch_size 后训练,训练若干步后触发参数同步。设计文档 也明确指出,收益来自训推隔离后把 rollout 和 train 的时间重叠起来。
trainer v1¶
新版 V1 的入口回到主训练命令:
python3 -m verl.trainer.main_ppo \
trainer.use_v1=True \
trainer.v1.trainer_mode=colocate_async \
actor_rollout_ref.rollout.mode=async \
trainer.v1.colocate_async.num_warmup_batches=1
关键代码路径很短:
trainer_cls = get_trainer_cls(config.trainer.v1.trainer_mode)
config.transfer_queue.enable = True
tq.init(config.transfer_queue)
self.trainer = trainer_cls(config=config)
self.trainer.init()
self.init_agent_loop_manager()
self.trainer.fit(self.agent_loop_manager)
这里值得注意两点:
trainer.v1.trainer_mode决定具体 trainer 类,注册类包括PPOTrainerSync、PPOTrainerColocateAsync、PPOTrainerSeparateAsync。- V1 默认启用
TransferQueue,AgentLoop 把生成结果写入队列,Trainer 侧通过 replay buffer 取样训练。
三种模式¶
flowchart LR
subgraph S["sync"]
S1["同一资源池"] --> S2["采样完成"]
S2 --> S3["训练更新"]
S3 --> S4["update_weights"]
end
subgraph C["colocate_async"]
C1["同一资源池"] --> C2["warmup batch"]
C2 --> C3["异步生成入队"]
C3 --> C4["Trainer 取样训练"]
C4 --> C5["abort / sleep / resume"]
end
subgraph A["separate_async"]
A1["Trainer 资源池"] --> A3["训练"]
A2["Standalone rollout 资源池"] --> A4["异步生成"]
A4 --> A5["TransferQueue"]
A5 --> A3
A3 --> A6["按 parameter_sync_step 同步权重"]
A6 --> A2
endsync¶
sync 是 V1 默认模式:
代码注释写得很直接:Trainer 和 rollout colocated,partial rollout disabled;每步结束 update_weights,sample 结束后 sleep_replicas。trainer_sync.py 适合作为 correctness baseline 或对 staleness 极敏感的任务。
colocate_async¶
colocate_async 仍然是同一组卡共享训练与推理,但生成请求是 fully async client,训练开始前先塞入 warmup batch:
python3 -m verl.trainer.main_ppo \
trainer.use_v1=True \
trainer.v1.trainer_mode=colocate_async \
trainer.v1.colocate_async.num_warmup_batches=1 \
actor_rollout_ref.rollout.mode=async
代码路径是:get_llm_client() 返回 FullyAsyncLLMServerClient;on_train_begin() 先 _add_batch_to_generate();on_step_end() 更新权重并 resume_generation_replicas();on_sample_end() abort 未完成请求并 sleep replicas。E2E smoke test 给了最小可运行配置。
separate_async¶
separate_async 才是真正把 Trainer 与 rollout 拆资源池的 V1 模式:
python3 -m verl.trainer.main_ppo \
trainer.use_v1=True \
trainer.v1.trainer_mode=separate_async \
trainer.v1.separate_async.num_warmup_batches=4 \
trainer.v1.separate_async.parameter_sync_step=4 \
actor_rollout_ref.rollout.mode=async \
actor_rollout_ref.rollout.nnodes="${ROLLOUT_NNODES}" \
actor_rollout_ref.rollout.n_gpus_per_node="${ROLLOUT_GPUS_PER_NODE}" \
actor_rollout_ref.rollout.checkpoint_engine.backend=nccl
这一路径有几条硬约束:
data.train_batch_size == actor_rollout_ref.actor.ppo_mini_batch_sizeactor_rollout_ref.rollout.nnodes > 0actor_rollout_ref.rollout.n_gpus_per_node > 0- rollout checkpoint engine 不能是
naive - 如果启用 reward model,
separate_async不支持 colocated RM,要求reward.reward_model.enable_resource_pool=True
trainer_separate_async.py 还会把 hybrid engine 在 rollout/trainer 状态之间切换;standalone rollout 通过独立 LLMServerManager 提供生成服务,按 parameter_sync_step 同步权重。
Staleness 定义¶
是不是多推理这些百分比给下一次训练?
不完全是。可以把它直观理解为旧参数样本缓冲区的容忍上限,而不是固定要求 Rollouter 每次都多生成某个百分比。Rollouter 是否真的多生成,取决于 rollout 速度、队列大小、正在运行的请求、参数同步时机和 partial rollout。
在旧版 fully_async_policy 文档里,async_training.staleness_threshold 表示最大允许使用的 stale samples 比例:
rollout_num =
(1 + staleness_threshold)
* (trigger_parameter_sync_step * require_batches * ppo_mini_batch_size)
- num_staleness_sample
源码里的控制也对应这个含义:max_required_samples = required_samples * (staleness_threshold + 1) * trigger_parameter_sync_step,而每次参数变化后会把 active_tasks + queue_size 重新计入 staleness_samples。rollouter 代码 和 reset 逻辑 都说明它是“队列/正在生成样本有多旧”的约束。
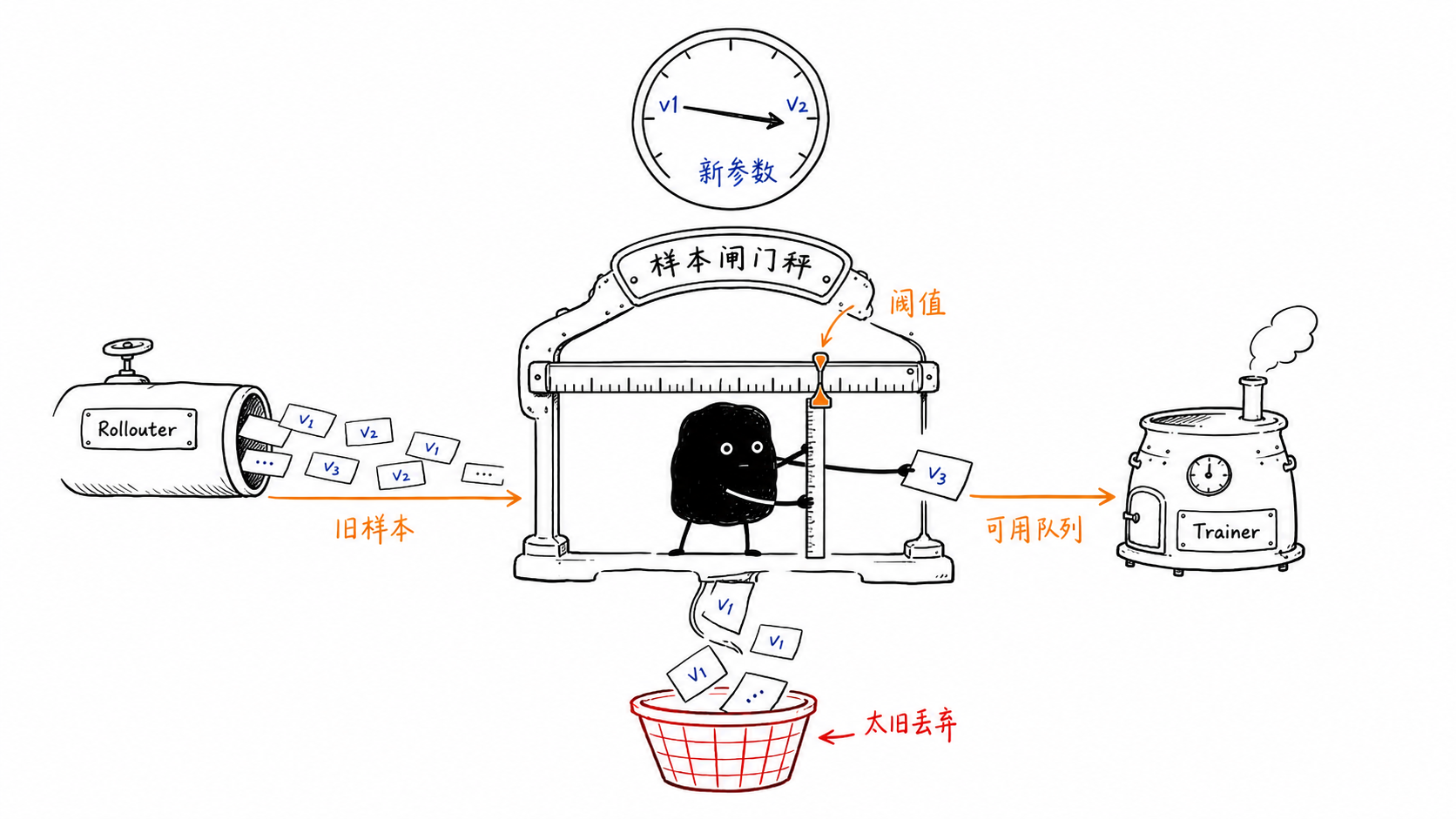
V1 的 staleness 还要多看 replay buffer 指标。ReplayBuffer 会按 prompt 的 global_steps 排序,优先取更老但已完成的 prompt,以降低堆积;如果超过 max_off_policy_threshold,按策略 drop 或 wait 处理。V1 replay buffer 的判断式是:
V1 训练指标还会记录 trajectory 在生成过程中跨越多少版本,以及相对当前策略滞后多少版本:
trajectory_spans = (max_global_steps - min_global_steps + 1) / parameter_sync_step
trajectory_staleness = ((global_steps - 1) - max_global_steps) / parameter_sync_step
trajectory_staleness_worst = ((global_steps - 1) - min_global_steps) / parameter_sync_step
所以不要把所有 staleness 都理解成同一个标量:
- 旧 fully async 的
staleness_threshold:允许 stale samples 的比例上限。 - V1 sampler 的
max_off_policy_threshold:trajectory 可跨越的模型版本阈值。 - 训练日志里的 trajectory staleness:实际样本相对当前训练步的版本滞后。
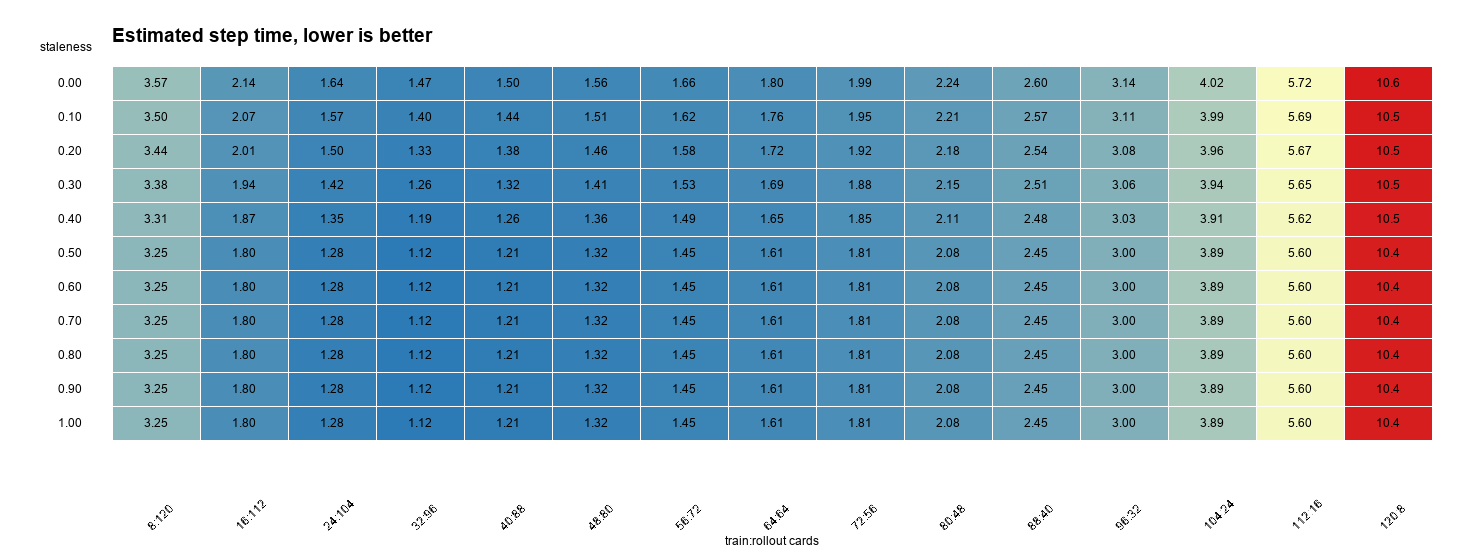
资源配比¶
资源配比的第一原则是:让 rollout 时间和 train 时间在异步流水线里尽量接近。VeRL fully async 文档也给了同样建议:理想资源分配应让 rollout time 与 train time 接近,减少 pipeline bubble;如果 rollouter/idle_ratio 高而 trainer/idle_ratio 低,就增加 Trainer 资源、减少 Rollouter 资源,反之亦然。调参建议
如果同步 profile 里 rollout:train 约为 3:1,且暂时假设训推随卡数近似同指数扩展,那么第一轮可以按:
对应建议是:
| 总卡数 | 第一轮配比 | 备选配比 | 适用判断 |
|---|---|---|---|
| 64P | 16 train : 48 rollout |
24:40、32:32 |
如果训练显存或 DP/TP 切分要求更高,从 24:40 起步更稳。 |
| 128P | 32 train : 96 rollout |
40:88、48:80、64:64 |
如果 rollout 长尾极重,优先试 32:96;如果 update_actor 已接近瓶颈,试 48:80 或 64:64。 |
不要只看同步阶段比例
同步 profile 的 gen:update_actor 比例是起点,不是最终答案。异步后 old log prob、reward、参数同步、队列等待、sleep/resume、NPU 通信后端都会改变瓶颈。资源比例必须通过 timing_s/step、timing_s/gen、trainer/idle_ratio、rollouter/idle_ratio 和 off-policy 指标回调。
异步收益边界¶
上异步后,单步耗时不一定降低,单卡吞吐也不一定上升。
它有效的条件是:
- rollout 长尾明显,Trainer 经常等生成。
- rollout 与 train 可以真正重叠,而不是被参数同步、显存切换或队列阻塞重新串行化。
- stale 样本比例可控,没有大量 drop/wait。
- 训推资源比例接近瓶颈均衡。
- reward model、old log prob、ref log prob 等环节没有成为新瓶颈。
反过来,以下情况会让异步收益变差:
- rollout 卡太少,Trainer 仍然长期等队列。
- rollout 卡太多,Rollouter 高 idle,单卡吞吐变差。
parameter_sync_step太小,参数同步过于频繁。- staleness 太大,旧样本带来 off-policy 偏差,精度或 response length 不稳定。
separate_async下 checkpoint engine、NCCL/NIXL/Mooncake 后端不稳定。
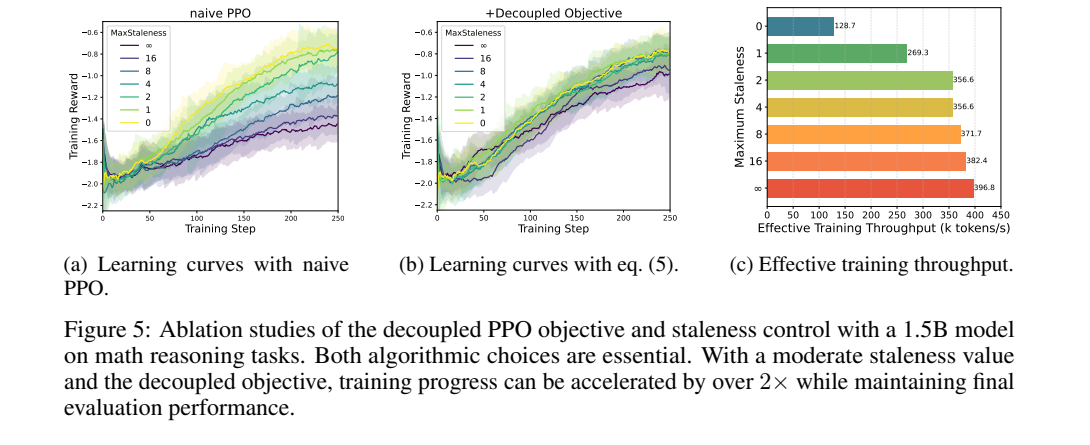
VeRL 文档里的 128 卡 Qwen2.5-Math-7B 实验可以作为参考,但不能机械外推:
| staleness_threshold | step | gen | update_actor | 400 step 总时长 | acc/mean@1 |
|---|---|---|---|---|---|
| 0 | 231.34 | 128.47 | 98.77 | 1d 1h 53m | max 0.2844 / last 0.2604 |
| 0.1 | 171.30 | 58.17 | 109.12 | 19h 59m | max 0.3542 / last 0.2979 |
| 0.3 | 146.11 | 38.88 | 103.22 | 17h 20m | max 0.3469 / last 0.2865 |
| 0.5 | 150.63 | 33.14 | 113.16 | 17h 22m | max 0.3521 / last 0.3094 |
这组数据说明三件事:
- 从
0到0.1/0.3/0.5,step time 明显下降。 0.3与0.5的时间很接近,收益不是线性增加。- 精度没有单调随 staleness 变化,文档也提示 response length 和训练稳定性会干扰结论。
估算脚本¶
我把一个轻量计算脚本放到独立仓库:Kirrito-k423/verl-perf。
默认假设:
- 32P 同步 baseline。
- rollout:train 时间约为
3:1。 - 训推按卡数幂律缩放。
- staleness 通过减少 pipeline bubble 改善 step time,但不替代真实压测。
运行:
python3 verl_perf_heatmap.py \
--total-cards 128 \
--baseline-cards 32 \
--baseline-rollout-time 3 \
--baseline-train-time 1 \
--out-dir outputs/128p
输出:
verl_perf_grid.csvstep_time_heatmap.pngper_card_throughput_heatmap.png
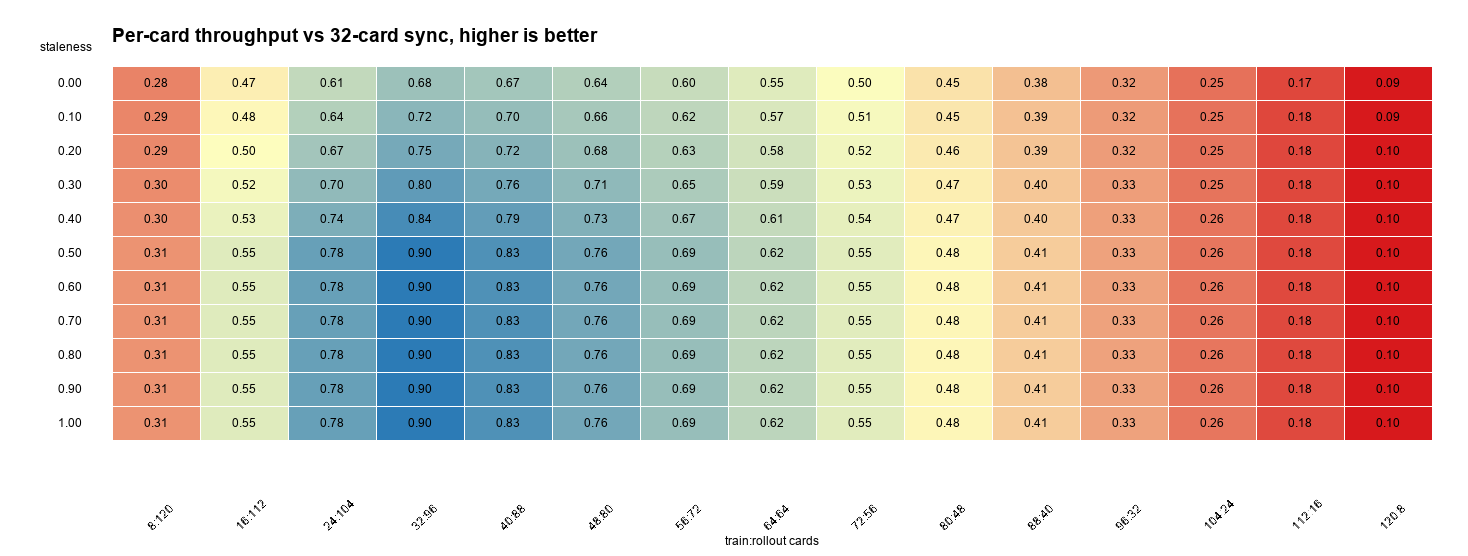
压测顺序
128P 场景建议先跑 32:96, staleness=0.3/0.5、48:80, staleness=0.3、64:64, staleness=0.3 三组;64P 场景先跑 16:48、24:40、32:32。每组至少记录 step 分解、idle ratio、stale/drop 样本数、response length 和验证集指标。
相关论文¶
这条技术线可以按“系统解耦”和“算法校正”两条线看:
- AReaL:把异步生成、Replay Buffer、Trainer、参数服务解耦,并提出 decoupled PPO objective 来缓解 stale data 的策略偏差。VeRL 文档和 V1 README 都明确引用了 AReaL 风格的 trainer。
- StreamRL:强调 disaggregated stream generation、异构与弹性资源管理,适合理解 rollout 服务化和流式生成。
- AsyncFlow:关注 asynchronous streaming RL post-training 的吞吐路径,与 fully async policy 的 streaming/partial rollout 思路相近。
- Magistral:作为大模型推理/训练异步化收益的相关案例,适合横向理解长链推理任务中的 rollout 长尾。
这些论文共同说明:staleness 的关键不是“能不能用旧样本”,而是旧样本带来的吞吐收益是否大于 off-policy 偏差和系统同步成本。
参考文献¶
- VeRL
main_ppo.pyV1 入口:https://github.com/verl-project/verl/blob/355bf40c734b9f743292dfc83f971b2ca1874cff/verl/trainer/main_ppo.py#L129-L179 - VeRL V1 trainer 配置:https://github.com/verl-project/verl/blob/355bf40c734b9f743292dfc83f971b2ca1874cff/verl/trainer/config/ppo_trainer.yaml#L200-L248
- VeRL
sync/colocate_async/separate_asynctrainer:https://github.com/verl-project/verl/tree/355bf40c734b9f743292dfc83f971b2ca1874cff/verl/trainer/ppo/v1 - VeRL fully async 文档:https://github.com/verl-project/verl/blob/355bf40c734b9f743292dfc83f971b2ca1874cff/docs/advance/fully_async.md
- VeRL one-step-off 文档:https://github.com/verl-project/verl/blob/355bf40c734b9f743292dfc83f971b2ca1874cff/docs/advance/one_step_off.md
- AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language Reasoning:https://arxiv.org/abs/2505.24298
- StreamRL: Scalable, Heterogeneous, and Elastic RL for LLMs with Disaggregated Stream Generation:https://arxiv.org/abs/2504.15930
- AsyncFlow: An Asynchronous Streaming RL Framework for Efficient LLM Post-Training:https://arxiv.org/abs/2507.01663
- Magistral:https://arxiv.org/abs/2506.10910