AI Documentation Workflow
导言
这篇文章记录我当前的 Work with AI 文档工作流:不是把一段 prompt 扔给模型、得到一篇孤立文章,而是把调研、来源管理、论文图表、正文插图、图片上传、Hugo 写作规范、可复用 skill 和 git 发布串成一个可验证的流水线。
这条流水线的关键变化来自 Karpathy 的 LLM Wiki 思路:把知识库视作一个由 LLM 维护的 Markdown 代码库。原始资料进入 raw 层,结构化理解进入 wiki 层,Hugo 文章只是最终发布层。这样每次写作都会沉淀可复用记忆,而不是从聊天记录里重新发明一次。
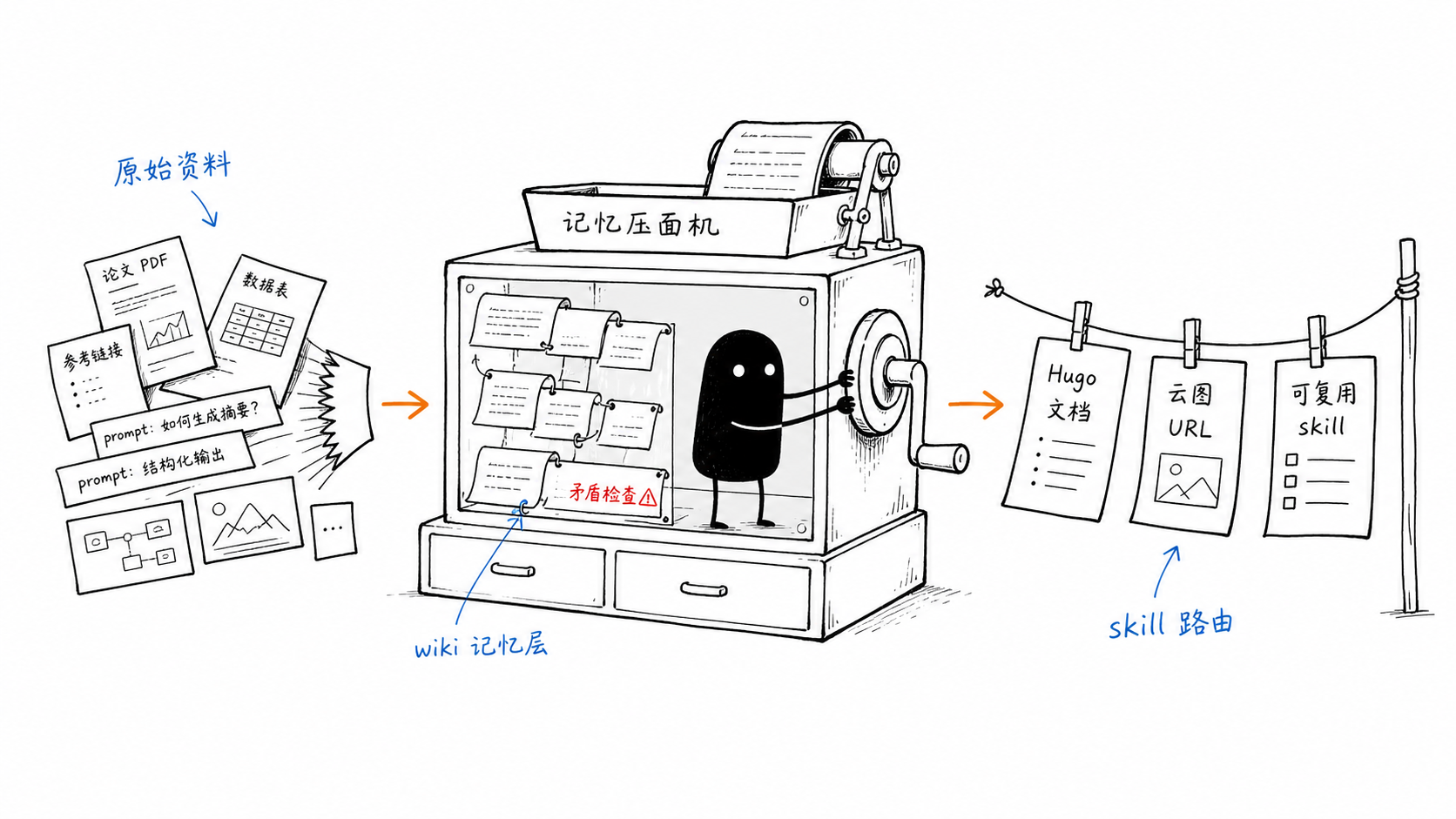
工作流实质¶
用户侧看到的是一串很长的 prompt:
首先使用 skills/hugo-tech-blog-writer/SKILL.md 调研后续问题和相关;
使用 ian-xiaohei-illustrations 配图;
使用 image-cloud-uploader 上传图;
调研涉及到的论文;
使用 paper-figure-supplement 添加逻辑图和数据图;
最后 push 文档。
它真正表达的是一个 文档生产状态机,每个 skill 负责一个稳定边界:
- Hugo 写作入口:
hugo-tech-blog-writer负责文章放在哪里、front matter 怎么写、导言和<!-- more -->如何维护、中文技术文风怎么保持。 - 来源与论文调研:先找一手来源、论文 PDF、官方项目页,再写判断;没有来源的结论要显式标注不确定。
- LLM Wiki 记忆层:重要来源保存到
obsidian-vault/.raw/,结构化理解写入obsidian-vault/wiki/,让后续任务能继承本次调研。 - 正文认知锚点图:
ian-xiaohei-illustrations生成一张能解释核心流程的手绘图,而不是做装饰图。 - 论文图表补充:
paper-figure-supplement只选两张图:一张解释逻辑,一张提供实验或数据证据。 - 图片云端化:
image-cloud-uploader上传最终仓库图,Markdown 引用云端 URL,避免本地路径在站点发布后失效。 - 安装与发布:重复 prompt 固化成 skill;文章、图片、wiki 资料和 skill 通过 git commit/push 留下历史。
核心判断
这条流程不是“AI 帮我写文章”,而是 AI 帮我维护一个可复利的文档系统。文章只是输出物,真正重要的是来源、规则、图像资产、wiki 记忆和 skill 都会留下来。
LLM Wiki¶
Karpathy 的 LLM Wiki gist 提出一个很直接的区分:多数 RAG 系统是在问题发生时检索相关片段,再临时综合答案;LLM Wiki 则让 LLM 增量维护一个持久 Markdown wiki,把每次来源、问题和回答都编译进知识库。1
这套模式有三层:
- Raw sources:原始论文、网页、截图、数据文件,只读保存,是事实来源。
- Wiki layer:LLM 维护的概念页、来源页、实体页、对比页、问题页、索引和日志。
- Schema layer:
AGENTS.md、CLAUDE.md、WIKI.md或 skill,规定目录、front matter、更新规则和维护边界。
对 hugoMinos 来说,这个模式已经有了合适落点:
obsidian-vault/.raw/articles/karpathy-llm-wiki.md保存 Karpathy gist 原文。obsidian-vault/wiki/sources/Karpathy LLM Wiki.md保存结构化来源页。obsidian-vault/wiki/concepts/LLM Wiki.md和AI Documentation Workflow.md保存可复用概念。content/仍然是 Hugo 发布层,不承担草稿知识库职责。
不要把 LLM Wiki 写成普通 RAG
RAG 的重点是 query-time retrieval,LLM Wiki 的重点是 persistent synthesis。前者解决“这次回答能不能找到资料”,后者解决“这次理解能不能沉淀到未来”。
论文背景¶
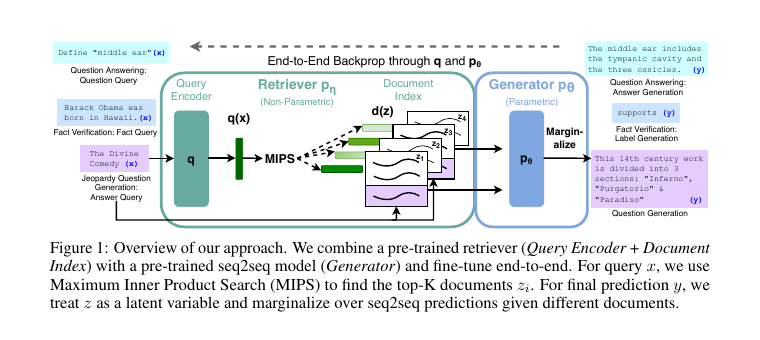
RAG 论文提供了这条讨论的技术基线:它把 query encoder、document index 和 generator 组合起来,让生成模型在回答时接入非参数化外部知识。2
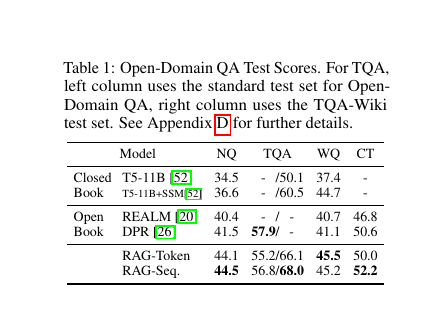
论文主结果也说明:在开放域 QA 上,RAG-Token/RAG-Sequence 相比 DPR 等基线有明显提升。这个结果证明 检索增强生成是有效的,但它没有自动解决跨 session 的整理、链接、矛盾维护和写回问题。
后续论文可以从两个方向理解 LLM Wiki 的价值:
- 长期记忆机制:Generative Agents 使用 memory stream、retrieval、reflection 来支持角色行为的连续性,说明“记忆检索 + 反思更新”是 agent 持续性的核心部件。3
- 显式内存管理:MemGPT 把 LLM 看成带内存层级的操作系统过程,通过 context、external memory 和控制策略缓解上下文窗口限制。4
- 个人知识库传统:Karpathy 也把 LLM Wiki 追溯到 Vannevar Bush 的 Memex:真正有价值的不是单个文档,而是文档之间可维护的关联路径。5
这篇文章的证据边界
RAG 论文图表证明的是 retrieval-augmented generation 的有效性,不证明 LLM Wiki 本身有实验指标优势。LLM Wiki 目前更像一种工程工作流和知识组织模式,其价值需要从长期维护成本、可追溯性、复用率和后续写作速度中评估。
融入 Prompt¶
把原来的长 prompt 改成可复用版本后,应该尽量让任务入口短、边界清楚、可验证:
使用 $work-with-ai-doc-workflow 完成下面的文档任务。
目标:新建或更新一篇 Hugo Markdown 文章,要求先调研、再写作、再配图、再上传图片、最后验证并 push。
流程要求:
1. 读取 AGENTS.md、archetypes/default.md、skills/hugo-tech-blog-writer/SKILL.md。
2. 若主题涉及长期知识积累,使用 Karpathy LLM Wiki 思路:原始资料进入 obsidian-vault/.raw/,结构化理解进入 obsidian-vault/wiki/,并更新 index/log/hot。
3. 调研一手来源和相关论文,只写可追溯结论。
4. 使用 skills/ian-xiaohei-illustrations/SKILL.md 生成正文认知锚点图。
5. 使用 skills/paper-figure-supplement/SKILL.md 为相关论文或概念加入一张逻辑图和一张证据图/表。
6. 使用 skills/image-cloud-uploader/SKILL.md 上传最终仓库图片,并把 Markdown 图片链接替换成云端 URL。
7. 将重复 prompt 沉淀为仓库 skill 或 wiki 规则,而不是只留在聊天记录。
8. git diff --check,通过后只 stage 本次相关文件,commit 并 push。
具体主题:
[在这里写文章主题、要介绍的工作流、必须引用的来源、希望安装的 prompt 或 skill]
这段 prompt 的重点不是“列更多要求”,而是把工作拆成可以被检查的中间物:
- raw source 是否存在:例如
obsidian-vault/.raw/articles/karpathy-llm-wiki.md。 - wiki 是否更新:概念页、来源页、index/log/hot cache 是否同步。
- 图片是否可追溯:生成图和仓库图 hash 一致,论文裁图注明 Figure/Table 来源。
- Markdown 是否可发布:front matter、导言、图床链接、引用、
git diff --check都通过。 - skill 是否安装:仓库 skill 和本机
~/.codex/skills/是否同步。
安装结果¶
本次已经把工作流安装到仓库和本机:
repo:
skills/work-with-ai-doc-workflow/SKILL.md
skills/work-with-ai-doc-workflow/agents/openai.yaml
local:
/Users/Zhuanz/.codex/skills/work-with-ai-doc-workflow
-> /Users/Zhuanz/work/github/hugoMinos/skills/work-with-ai-doc-workflow
wiki:
obsidian-vault/.raw/articles/karpathy-llm-wiki.md
obsidian-vault/wiki/sources/Karpathy LLM Wiki.md
obsidian-vault/wiki/concepts/LLM Wiki.md
obsidian-vault/wiki/concepts/AI Documentation Workflow.md
本机安装选择 symlink,而不是复制一份 skill。原因是 仓库版本是源头:后续修改 skills/work-with-ai-doc-workflow/SKILL.md,本机 Codex 自动看到同一份规则,避免 repo 和电脑出现两个分叉版本。
后续问题¶
这条链路还需要继续演化,尤其是四个方向:
- wiki lint 怎么做:当
obsidian-vault/wiki/页面变多后,需要定期检查孤立页、过期结论、缺失来源和重复概念。 - 什么时候写回 wiki:不是每个回答都值得入库。适合写回的是可复用判断、来源摘要、概念框架、对比结论和调研路径。
- 图表选择标准:论文证据图应该优先选择主 benchmark、核心 ablation 或最能支撑文章论点的数据表;不要用生成图冒充实验结果。
- 是否接入本地搜索:Karpathy 提到
qmd这类 Markdown 搜索工具适合 wiki 规模变大后使用;当前index.md + rg足够,后续再安装更稳。
总结¶
这次改造后,我的文档工作流从“长 prompt 驱动”变成了“skill + wiki + Hugo + 图床 + git 驱动”。它的好处是每一步都有可检查产物:
- 资料被保存,而不是只在模型上下文里出现;
- 判断被写入 wiki,而不是散落在聊天记录里;
- 图片有仓库源文件和云端 URL;
- 论文图表有 Figure/Table 来源;
- 重复 prompt 被安装成 skill;
- 文章通过 git 历史进入长期维护。
最终目标不是让 AI 一次写完文章,而是让每次写作都给下一次写作留下更好的地基。
参考文献¶
-
Patrick Lewis et al., Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, NeurIPS 2020. ↩
-
Joon Sung Park et al., Generative Agents: Interactive Simulacra of Human Behavior, UIST 2023. ↩
-
Charles Packer et al., MemGPT: Towards LLMs as Operating Systems, arXiv 2023. ↩
-
Vannevar Bush, As We May Think, The Atlantic, 1945. ↩