NPU Training Operators - GDN
导言
这篇笔记记录一次很窄的接入设计:在 verl release/v0.8.0 的 Qwen3.5 GRPO + FSDP 路径里,NPU 已经有 RMSNorm、RoPE、MoE GMM 等 patch,但 Gated Delta Net / GDN 仍然落在原始 eager 路径。目标不是改 GRPO 算法,而是给模型 forward 里的 chunk_gated_delta_rule 加一个可配置的 Triton 优先路径。
参考对象是 MindSpeed-MM 提交 5aaf0791d00abcbf5dd16af10091f4391030ad00:它把 Qwen3.5 的 GDN 计算模式显式化为 gdn_compute_mode,并区分 triton、ascendc、eager。本文给出的 verl 方案先接入 Triton,保留 eager 回退;AscendC 自定义算子作为后续扩展。
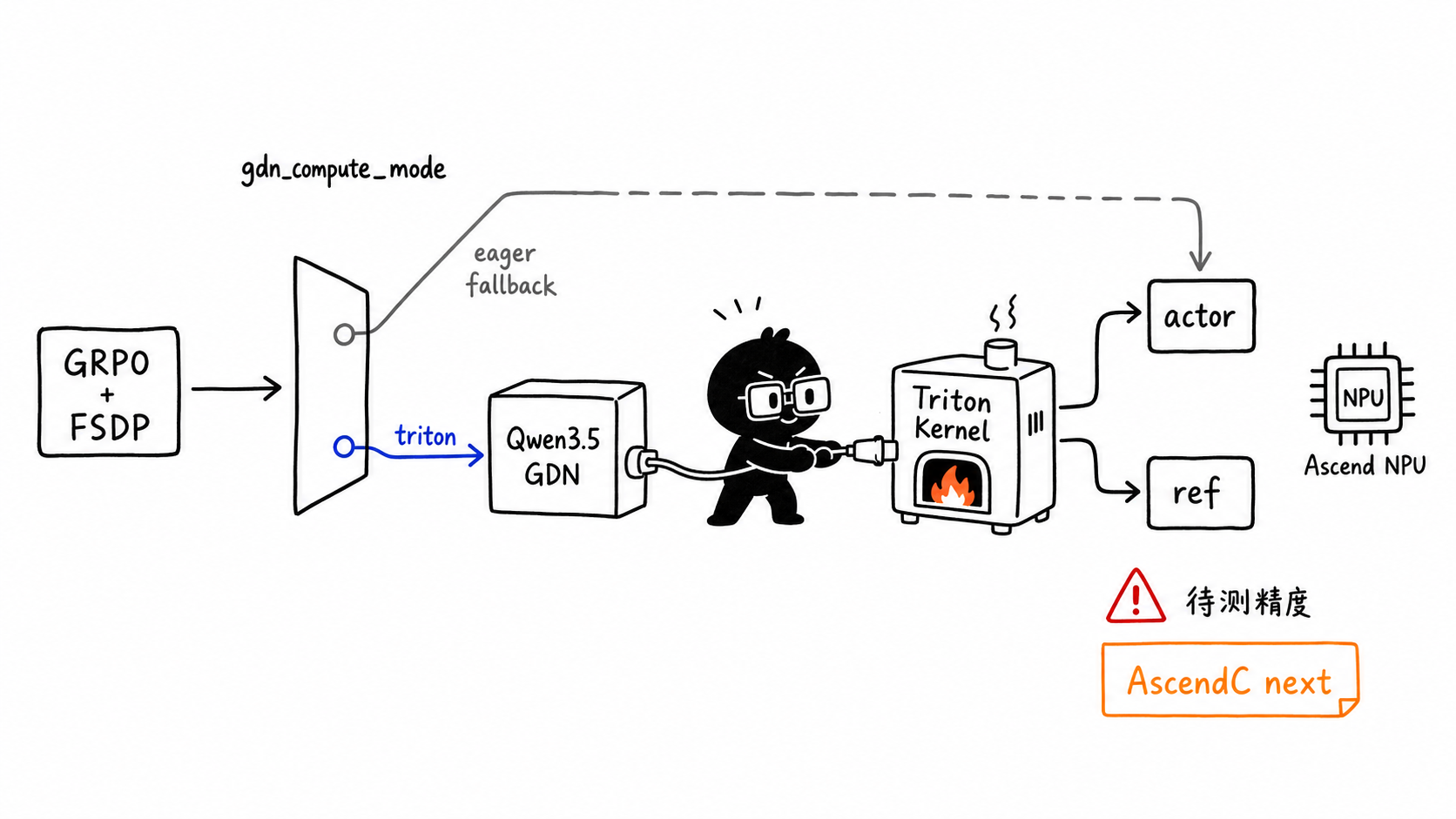
结论¶
- 问题边界:GDN 是 Qwen3.5 模型 forward 内的 linear attention block,不是 GRPO advantage,也不是 MoE routed expert 的 GMM。
- 现状判断:
verlrelease/v0.8.0 的 Qwen3.5 FSDP GRPO 示例已经存在,但 NPU patch 层只覆盖 RMSNorm/RoPE/MoE GMM 等模块,没有把Qwen3_5GatedDeltaNet的chunk_gated_delta_rule替换为 fused Triton 或 AscendC 实现。12 - 接入点:FSDP engine 初始化时调用
apply_npu_fsdp_patches,所以最小改动应落在verl.models.transformers.npu_patch的 monkey patch 层,而不是 GRPO trainer。3 - 配置方案:新增
actor_rollout_ref.model.gdn_compute_mode,取值先限制为eager或triton;GPU 默认eager,NPU 默认triton。 - 代码状态:draft PR
verl-project/verl#6908已移植 MindSpeed-MM Triton GDN wrapper/kernels,并通过py_compile、ruff check、ruff format --check与 CRLF-awaregit diff --check。由于本机没有torch_npu/Triton Ascend 环境,数值一致性与性能仍需在 NPU 机器补测。9
现状路径¶
verl 的 Qwen3.5 FSDP GRPO 示例主要在两个脚本里:
run_qwen3_5_27b_fsdp.sh对应 Dense 27B。run_qwen3_5_35b_fsdp.sh对应 35B-A3B MoE。
这两条脚本在算法层还是标准 GRPO trainer:rollout 采样、计算 log probability、构造 GRPO loss、再由 actor/ref 模型参与训练或参考分布计算。GRPO 本身来自 DeepSeekMath,它用 Group Relative Policy Optimization 避免额外训练 critic model,通过同一 prompt 的多条 sampled output 构造相对优势。4
但 GDN 的位置更靠下。Qwen3.5 的 linear attention 模块在每层 forward 里执行 chunk_gated_delta_rule,输入通常是:
| Tensor | Shape | 含义 |
|---|---|---|
q |
[B, T, H, K] |
query。 |
k |
[B, T, H, K] |
key。 |
v |
[B, T, H, V] |
value。 |
g |
[B, T, H] |
log-space forget gate。 |
beta |
[B, T, H] |
delta update 的门控系数。 |
initial_state |
[N, H, K, V] |
chunk recurrent state,可选。 |
所以它的性能问题不会通过改 GRPO 公式解决。正确抓手是:在模型被 FSDP 包装前,把 Qwen3.5 GDN module 的实现函数替换掉。
MindSpeed 参考¶
MindSpeed-MM 提交 5aaf0791d00abcbf5dd16af10091f4391030ad00 的标题是 [feature] Supports GDN with Ascendc,核心变化有三点:5
- 目录收敛:把原先散在 Qwen3.5 model 目录下的 Triton GDN kernel 整理到
mindspeed_mm/fsdp/ops/gdn/。 - 模式显式化:把配置从
use_triton_gdn: true改为gdn_compute_mode: triton。 - 后端分流:
triton:NPU 上导入 Triton 版chunk_gated_delta_rule。ascendc:NPU 上导入flash_chunk_gated_delta_rule,内部调用 AscendC 自定义 NPU op。eager:保留 torch eager 版torch_chunk_gated_delta_rule。
这给 verl 的启发是:不要把开关命名成“是否 Triton”,而应命名成“GDN 计算模式”。这样当前 PR 可以先接 triton,以后扩展 AscendC 时不需要再次更改配置语义。
为什么不直接接 AscendC
MindSpeed-MM 的 AscendC 版本依赖 torch.ops.npu.npu_recompute_w_u_fwd、npu_chunk_gated_delta_rule_fwd_h、npu_chunk_fwd_o、npu_chunk_bwd_* 等自定义 op。verl 侧如果直接接入,需要同步 wheel/build、op 注册、版本探测和 fallback 逻辑。作为第一步,Triton 移植的边界更小,也更容易 review。
算子语义¶
GDN 的直觉是:每个 token 不再把全部历史 KV cache 展开成二次 attention,而是维护一个随时间递推的状态矩阵。g 控制遗忘,beta 控制 delta update 强度,q/k/v 控制读写内容。Gated Delta Networks 论文把这类结构放在线性复杂度序列建模问题中讨论,目标是让模型具备更好的长上下文效率和状态更新能力。6
Triton 版 chunk_gated_delta_rule 可以拆成下面几段:
- 局部门控前缀和:
chunk_local_cumsum(g)把 log-space gate 转换为 chunk 内可用的累积门控。 - 块内 KKT:
chunk_scaled_dot_kkt_fwd(k, g, beta)计算 chunk 内 key-key 相关项。 - 三角求解:
solve_tril(A)求解 WY 表示需要的下三角系统。 - WY 表示重算:
recompute_w_u_fwd(k, v, beta, A, g)得到用于状态更新的w/u。 - 状态递推:
chunk_gated_delta_rule_fwd_h沿 chunk 递推 hidden state,并可输出 final state。 - 输出读出:
chunk_fwd_o(q, k, v_new, h, g, scale)得到[B, T, H, V]输出。
反向路径也不是一个简单 matmul 的反向,而是需要同时回传:
dq/dk/dv:query、key、value 梯度。db/dg:beta和 gate 梯度,其中dg需要 reverse cumsum。dh0:初始 recurrent state 梯度。
这就是 GDN 比普通 fused RMSNorm/GMM 更难接的地方:它跨 chunk、跨状态,还要同时处理 forward cache 与 backward recompute。
接入方案¶
verl 的最小方案分四层:
-
vendored kernel 包
新增
verl.models.transformers.gdn,移植 MindSpeed-MM Triton wrapper 和 kernel 文件:verl/models/transformers/gdn/ chunk_gated_delta_rule.py triton/chunk_delta_h.py triton/chunk_o.py triton/chunk_scaled_dot_kkt.py triton/convolution.py triton/cumsum.py triton/solve_tril.py triton/utils.py triton/wy_fast.py这些文件保持上游 kernel 布局,不做格式化重排,只在文件头部加
ruff: noqa和fmt: off,减少后续和 MindSpeed-MM/FLA 代码对齐时的噪声。 -
模型配置
在
HFModelConfig增加:当用户传入
actor_rollout_ref.model.gdn_compute_mode=triton时,把字段写入hf_config;如果存在text_config,也同步写进去。当前只允许eager和triton,避免用户误以为 AscendC 已经可用。 -
NPU patch
在
npu_patch.py里包装两个类的__init__:_patch_qwen3_5_gated_delta_net_init(modeling_qwen3_5, "Qwen3_5GatedDeltaNet") _patch_qwen3_5_gated_delta_net_init(modeling_qwen3_5_moe, "Qwen3_5MoeGatedDeltaNet")wrapper 在原始 init 完成后读取
gdn_compute_mode:eager:不改任何行为。triton:把self.chunk_gated_delta_rule指向verl.models.transformers.gdn.chunk_gated_delta_rule。- 其他值:立即抛错。
-
示例脚本
在两个 Qwen3.5 FSDP GRPO 示例里增加:
然后按设备给默认值:
DEVICE 默认值 原因 gpueager不改变 CUDA/GPU 用户现有路径。 nputritonNPU 上优先启用移植的 GDN Triton kernel。
Tiling 与硬件约束¶
GDN 的 Triton kernel 默认 chunk_size=64。它不是把整段序列一次性展开,而是把序列切成 chunk,在 chunk 内做局部矩阵关系和三角求解,再在 chunk 间递推 state。
实现时要关注这些约束:
- dtype:wrapper 明确不支持 FP32 输入,推荐 BF16;部分归约或中间量会升到 FP32 再写回。
- layout:主路径使用
[B, T, H, K/V],head_first=False;head_first=True被标记为 deprecated。 - varlen:
cu_seqlens兼容 FlashAttention 风格的变长输入,但verl的 Qwen3.5 Megatron 示例已经提示 GDN 当前不支持 packed sequences / THD 格式;FSDP 路径也要谨慎验证 remove padding。7 - state:
initial_state与final_state的 shape 是[N, H, K, V],其中N对等长 batch 通常等于B,对 varlen 输入等于序列个数。 - NPU 内存:Ascend 上 kernel 需要考虑 UB 容量、对齐、mask 和 block 维度。Triton 路线先复用上游 tiling,AscendC 路线才需要进一步把
chunk_fwd_h、chunk_fwd_o、backward 等段映射到自定义算子。
论文证据¶
GDN 的系统动机不是“某一个算子天然快”,而是线性注意力/状态空间类结构在长序列场景里减少 KV cache 与二次 attention 压力。Qwen3.5-Omni 技术报告把 GDN 放在 Hybrid MoE 设计中讨论,并在 Table 2 给出并发下的首包延迟和 Thinker TPS。8
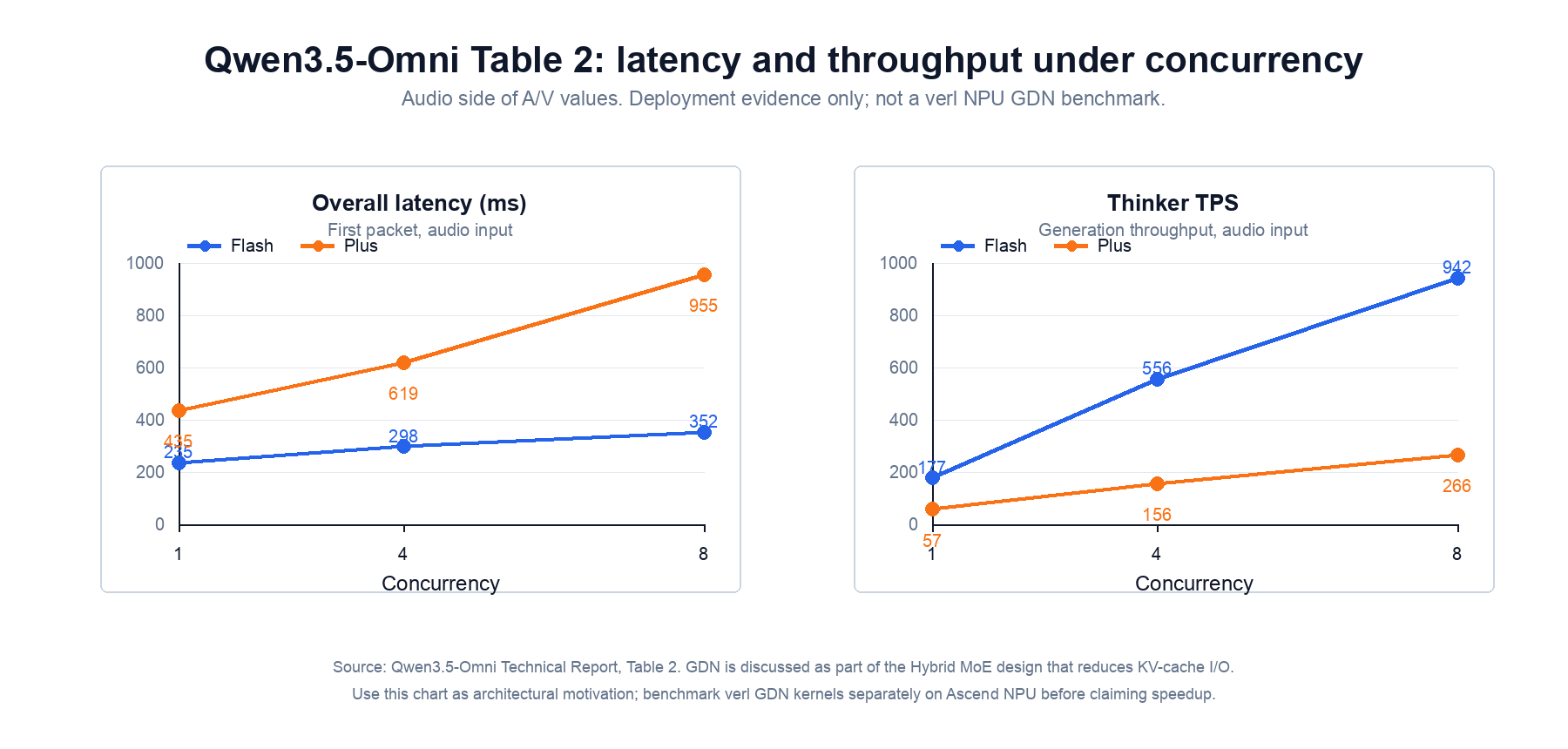
这张图的正确读法是:
- 能说明:Qwen3.5 系列设计确实把低延迟、高并发和状态化 attention 作为重要目标;GDN 相关路径值得在训练框架里给出 fused 实现。
- 不能说明:本次 Triton 移植已经在 Ascend NPU 上获得同等收益。训练侧还需要单算子 profiler、端到端 step time、loss/logprob 对齐和 backward 检查。
验证项¶
正式合入前建议至少补齐这些检查:
| 类型 | 检查项 | 失败信号 |
|---|---|---|
| 单算子 forward | 同一 q/k/v/g/beta/initial_state 下,Triton vs eager 输出对齐。 |
o 或 final_state diff 放大,尤其是长序列后段。 |
| 单算子 backward | 比较 dq/dk/dv/db/dg/dh0。 |
gate 梯度反向 cumsum 错误,或 beta 梯度异常。 |
| Shape 组合 | 覆盖 Dense/MoE、B/T/H/K/V 多组 shape、output_final_state 开关。 |
某个 head/value dim 下 kernel launch 或 mask 越界。 |
| FSDP actor/ref | actor 和 reference model 都能在 NPU 上完成 forward/logprob。 | 只有 actor patch 成功,ref 仍走 eager 或初始化失败。 |
| GRPO step | 跑一个最小 GRPO step,检查 loss、kl、entropy、logprob。 | 算子输出有限但训练指标突变。 |
| 变长输入 | 检查 cu_seqlens is None 与 varlen 输入;明确 packed/THD 是否禁用。 |
remove padding 后 shape 进入 GDN 路径不兼容。 |
| 性能 | NPU profiler 看 GDN kernel time、host launch、memory bandwidth。 | Triton kernel 可运行但 launch/host overhead 吃掉收益。 |
| 回退 | GDN_COMPUTE_MODE=eager 能一键关闭。 |
出问题时无法快速隔离 GDN patch。 |
风险¶
- 未做 NPU 实测:本地只能做静态检查,不能替代 Ascend NPU 上的精度和性能验证。
- Triton 版本绑定:Triton Ascend 的语义、mask、block size 和 dtype 支持可能随环境变化,需要在目标训练镜像里验证。
- transformers 类名变化:当前 patch 依赖
Qwen3_5GatedDeltaNet和Qwen3_5MoeGatedDeltaNet,若上游 transformers 改类名,需要同步更新。 - AscendC 未接入:配置层保留了
gdn_compute_mode语义,但当前实现只允许eager/triton;ascendc需要后续 op 注册与 wheel 依赖。 - diff 噪声:
npu_patch.py原文件是 CRLF,本地修改后会显示较多换行变化;review 时应重点看新增 helper 与底部两处调用。
参考文献¶
-
verlrelease/v0.8.0 Qwen3.5 27B FSDP GRPO 示例:https://github.com/verl-project/verl/blob/release/v0.8.0/examples/grpo_trainer/run_qwen3_5_27b_fsdp.sh ↩ -
verlrelease/v0.8.0 NPU patch 文件:https://github.com/verl-project/verl/blob/release/v0.8.0/verl/models/transformers/npu_patch.py ↩ -
verlFSDP engine 初始化路径:https://github.com/verl-project/verl/blob/release/v0.8.0/verl/workers/engine/fsdp/transformer_impl.py ↩ -
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models, arXiv:2402.03300. https://arxiv.org/abs/2402.03300 ↩
-
MindSpeed-MM commit
5aaf0791d00abcbf5dd16af10091f4391030ad00: https://gitcode.com/Ascend/MindSpeed-MM/commit/5aaf0791d00abcbf5dd16af10091f4391030ad00?ref=master ↩ -
Gated Delta Networks, arXiv:2412.06464. https://arxiv.org/abs/2412.06464 ↩
-
verlQwen3.5 Megatron GRPO 示例中对 GDN 与 packed sequences / THD 的说明:https://github.com/verl-project/verl/blob/release/v0.8.0/examples/grpo_trainer/run_qwen3_5_35b_megatron.sh ↩ -
Qwen3.5-Omni Technical Report, arXiv:2604.15804, Table 2. https://arxiv.org/abs/2604.15804 ↩
-
verldraft PR #6908,[Ascend] Add Qwen3.5 Triton GDN patch: https://github.com/verl-project/verl/pull/6908 ↩