Research logic
导言
There's a perennial curiosity surrounding the inception of ideas in research. How do researchers stumble upon those brilliant concepts that pave the way for groundbreaking work? The answer lies in a certain logic—a methodology that can be learned and applied to discover remarkable ideas in the realm of research.
Paper writing logic¶
- experiments 1. What and Why design the experiment 2. explain the detail in diagram. (e.g., x/y asix) 3. Summary 1. We make two key observations. First, xxx 2. This relatively high reuse is due to two reasons/factors. First,
- prove that each design/(number config) is very useful : In architecture design, you can not just post a overview speedup diagram(1), but need more design components comparison to show it's effectiveness. 1
- check the special design for some target workloads cause low overhead/negligible performance impact to other normal workloads.
- maybe accidental event of magic design combination, like most AI model.
Insights on Computer Architecture Research¶
Fundamental Approaches in Computer Architecture Research:¶
- Modeling and Object abstraction
- Quantifying Costs in Various Scenarios and Methods: Measuring the overhead in different situations and under various methods.
- Tradeoffs and Combinations: Exploring tradeoffs or combinations of these methods.
- Computational Theoretical Limits: Understanding the theoretical boundaries of computation.
- Gap Analysis and Potential Assessment: Reviewing the disparities and potential improvements.
Confirm the motivation and research scope is the Key to obtain clear task boundary
During the system design, It's difficult but necessary to find the orthogonal work boundary to reduce the workload and focus on the limit design.
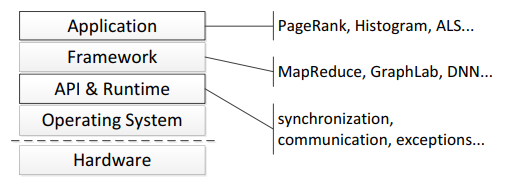
As shown in Figure 3, a lightweight runtime interfaces between the OS and userlevel software. It hides the low-level NDP hardware details and provides system services through a simple API. We ported three popular frameworks for in-memory analytics to the NDP runtime: MapReduce, graph processing, and deep neural networks. The application developer for these frameworks is unaware that NDP hardware is used and would write exactly the same program as if all execution happened in a conventional system.4
tradeoff 1: flexibility and high-performance¶
The abstraction layer in a system inherently remains potential for performance optimization, e.g, Virtual Memory1 and API in project programming.
This is because abstraction
- provide easy-to-use api,
- but lack of the detail api implementation in the API-based different lower system.
So we need collaborative-design approach known as "软硬协同设计" to boost performance.
tradeoff 2: best performance/complexity (benefit/cost) trade-off¶
The marginal effect is evident:
doubling the size of the cache does not result in a proportional decrease in cache miss rates.
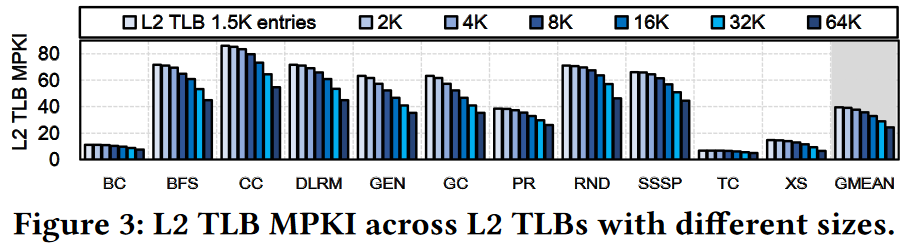
We need to consider the tradeoff between the average latency reduction due to the decrease in cache misses and the hardware area and power overhead.
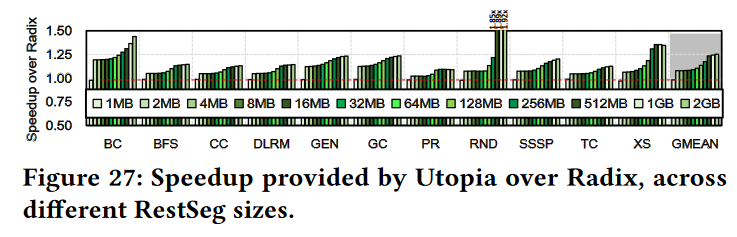
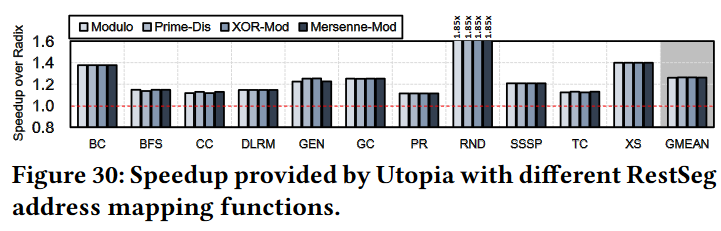
tradeoff 3 : programmer/(micro)architect tradeoff¶
Abstraction: Virtual vs. Physical Memory. Design complex virtual memory archi for programer convenience.5
tradeoff 4: big but slow¶
like cache hierarchy design
Common Approach 0: Special Design(metadata cache/ new way) to prune the critical path of performance¶
Utopia combine fast way to old baseline way to speedup.
Common Approach 1: Integrating old way to new system¶
Amalgamate the best solutions for various situations into a single system 1
challenge¶
- identifying the candidates (potential situation)
- efficiently managing the co-existence of different system design(1)
-
extend system to support new method with minimal overhead on existing hardware solution
-
maybe capable of dynamically adapting based on the context at hand.
Common Approach 2:Rethink the default number design¶
“flattening” the page table: merging two levels of traditional 4 KB page table nodes into a single 2 MB node, thereby reducing the table’s depth and the number of indirections required to traverse it.2
Common Approach 3:Top2Down Modeling guding the detail design¶
modeling observation
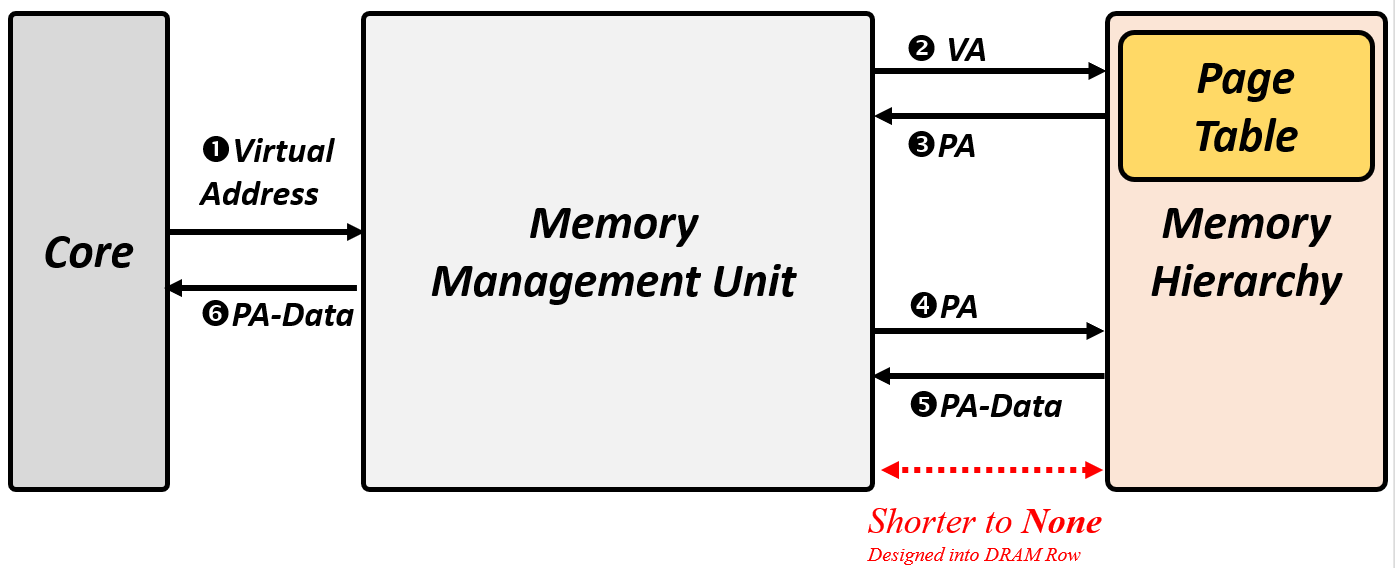
Detail Design: with distributed mem-partition in PIM
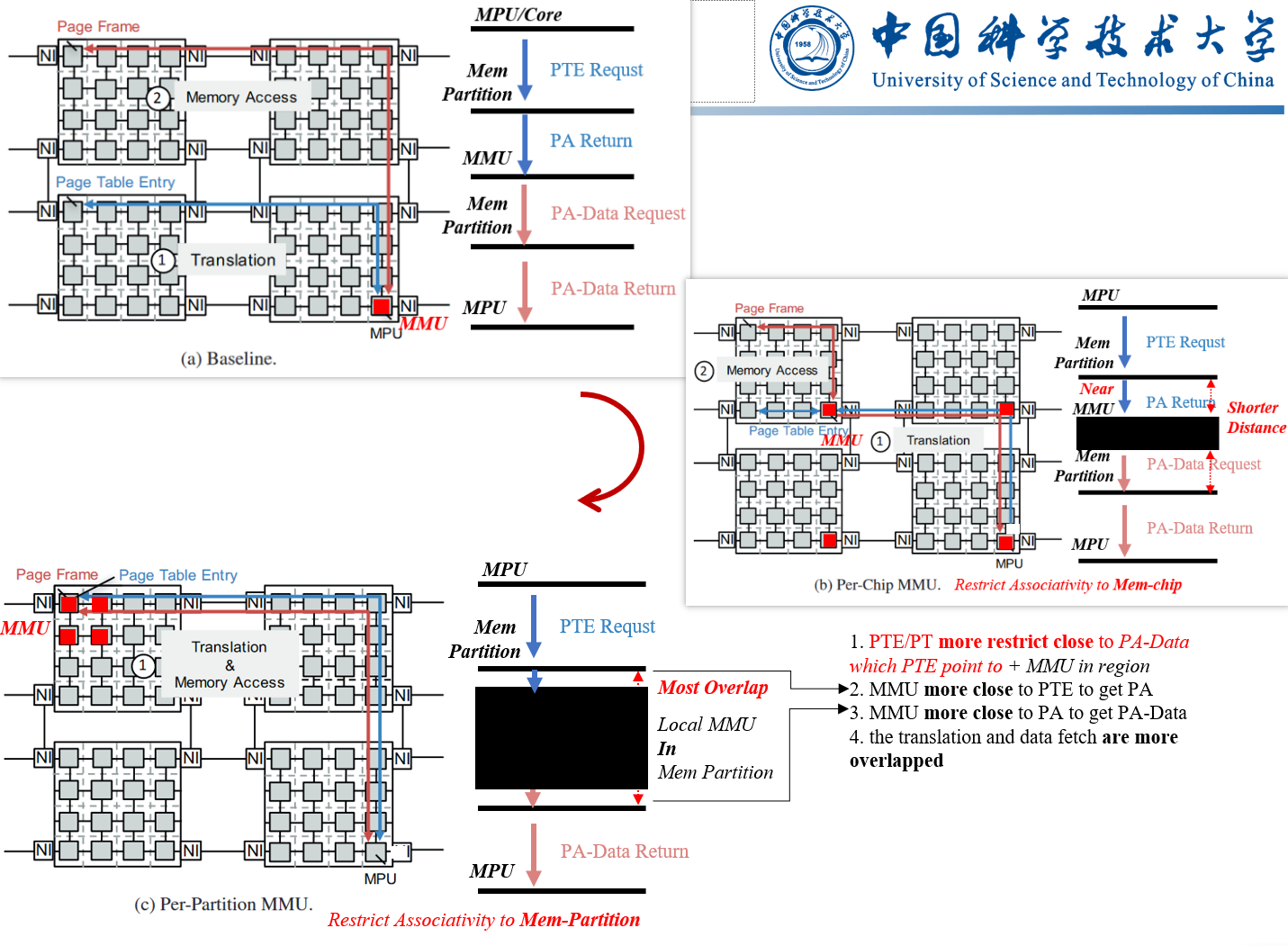
More Detail Design: considered design TLB in PIM-core or TLB in MMU
TLB in PIM-core:

TLB in MMU:

More * 2 Detail Design: considered conventional L1L2L3 cache in WHERE
TODO, but the lack of deep cache hierarchies limits the caching of page table entries close to the MPUs.
More * 3 Detail Design: considered PWCs
TODO, same reason mentioned before.
参考文献¶
-
Utopia: Fast and Efficient Address Translation via Hybrid Restrictive & Flexible Virtual-to-Physical Address Mappings ↩↩↩
-
ASPLOS22: Every Walk’s a Hit Making Page Walks Single-Access Cache Hits ↩
-
PACT'17 Near-Memory Address Translation ↩
-
PACT'15 Practical near-data processing for in-memory analytics frameworks ↩