VeRL Speculative Decoding
导言
RL rollout 中的 speculative decoding 不是普通推理加速的简单移植。普通 serving 只关心 latency、throughput 和用户体验;RL rollout 还必须保证 response、old logprob、reward、advantage 和 policy loss 都对应同一个 verifier policy。
换句话说,draft model 可以帮助系统更快地产生候选 token,但训练语义必须仍然属于 target / verifier policy。
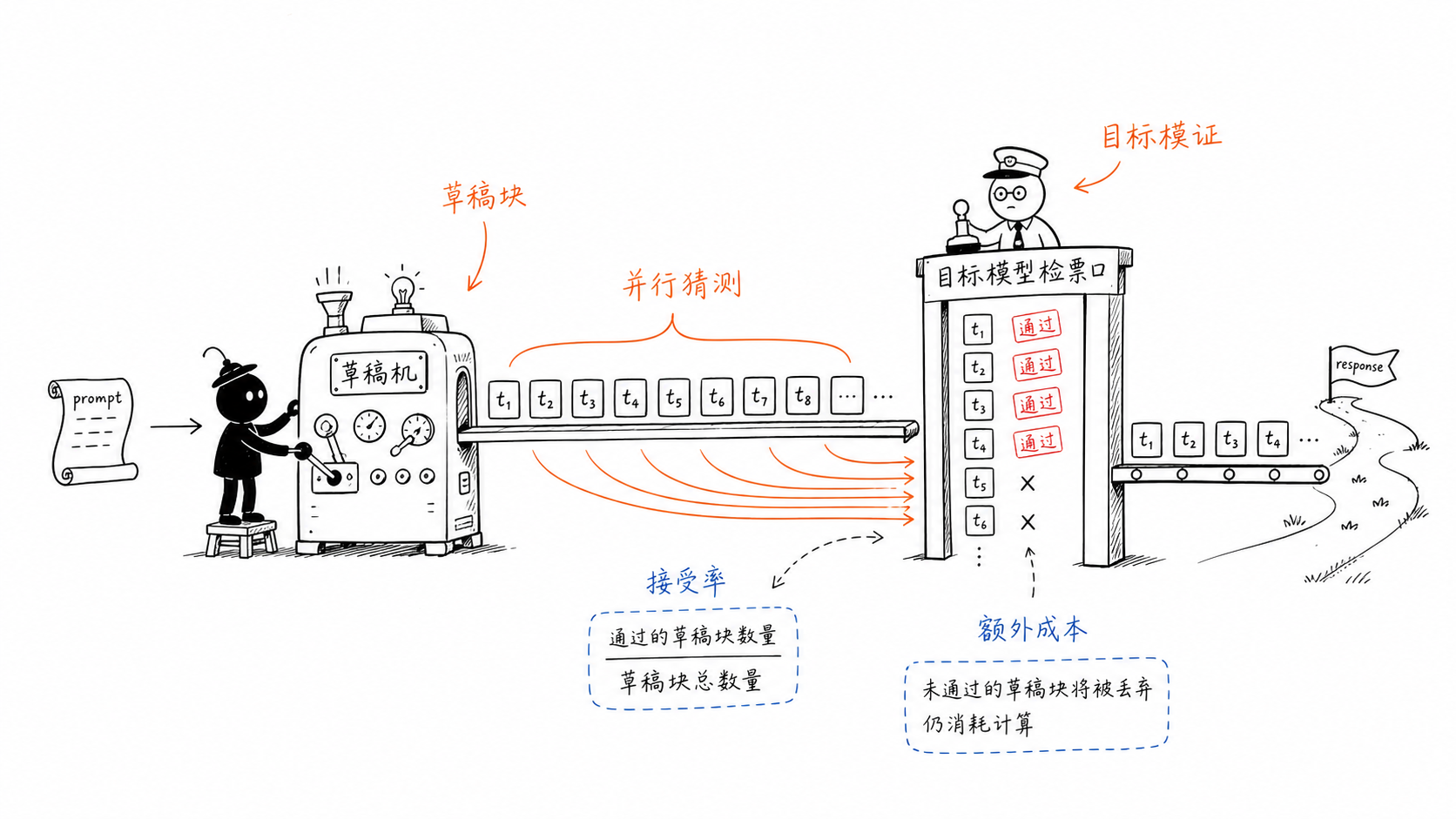
核心判断¶
Speculative decoding 在 RL 中最重要的约束是 verifier-exact:最终进入训练样本的 token 分布必须等价于当前 actor / verifier policy 的采样分布。MTP、EAGLE 和 DFlash 的区别主要体现在 draft token 的生成方式和 acceptance length 上,但它们接入 RL 后都必须服从同一条规则:logprob、KL 和 policy loss 只能基于 target policy 计算,不能基于 draft policy 计算。
这也是为什么 rollout 加速不能只看 tokens/s。一个 speculative 方法即使在在线 serving 中很快,接入 RL 时仍要回答四个问题:
- old logprob 口径:样本里的 old logprob 是否来自真正采样的 target policy。
- policy version:response、logprob、reward 和 advantage 是否能追溯到同一个 actor version。
- draft 同步:actor 更新后,draft head 或 draft model 是否同步,stale draft 是否只影响接受率而不影响训练目标。
- metadata 完整性:accepted length、finish reason、response mask、sample id、group id、routing metadata 是否完整回传。
不要把 draft 当策略
Draft model 只提出候选 token。只要未被 verifier 接受,它就不能进入 tool call、reward、trace、response mask 或 logprob 计算。否则加速路径会改变训练数据分布。
MTP 的工程现实¶
verl 的 MTP 文档把配置统一放在 actor_rollout_ref.model.mtp 下。当前 RL / SFT 训练侧只支持 mbridge / Megatron-Bridge + megatron 组合;推理侧取决于模型是否在 vLLM / SGLang 等后端的兼容列表中。1
MTP 至少有三种含义,写实验时要分清:
| 用法 | 典型配置 | 含义 |
|---|---|---|
| 加载 MTP 参数 | enable=True |
权重包含 MTP 模块,显存会上升 |
| 训练 MTP loss | enable=True, enable_train=True |
训练 MTP 预测能力,可配 detach_encoder=True |
| rollout speculative | enable_rollout=True |
在 rollout 阶段用 MTP 提供 draft token |
vLLM 侧的 rollout 配置通常是:
actor_rollout_ref.model.mtp.enable=True
actor_rollout_ref.model.mtp.enable_rollout=True
actor_rollout_ref.model.mtp.method=mtp
actor_rollout_ref.model.mtp.num_speculative_tokens=1
SGLang 侧更接近 EAGLE 配置:
actor_rollout_ref.model.mtp.enable=True
actor_rollout_ref.model.mtp.enable_rollout=True
actor_rollout_ref.model.mtp.speculative_algorithm=EAGLE
actor_rollout_ref.model.mtp.speculative_num_steps=2
actor_rollout_ref.model.mtp.speculative_eagle_topk=2
actor_rollout_ref.model.mtp.speculative_num_draft_tokens=4
官方经验很克制:MTP rollout acceptance rate 约提升 14%,但 H20 上整体吞吐没有提升,在一个 mimo-7B + SGLang 场景甚至下降约 50%。1 因此 MTP 更适合作为“可训练 speculative head 能力”先保留,而不应默认视为 rollout 吞吐优化开关。
DFlash 的意义¶
DFlash 的关键贡献不是又训练了一个更强的小 draft model,而是改变了 draft 的计算形态。EAGLE-3 这类方法仍然逐 token 自回归生成 draft,draft cost 会随 speculative depth 增长;DFlash 则用 block diffusion drafter 在一次 forward 中预测一整块 token,并用 target model hidden states 作为条件信息提高接受率。2
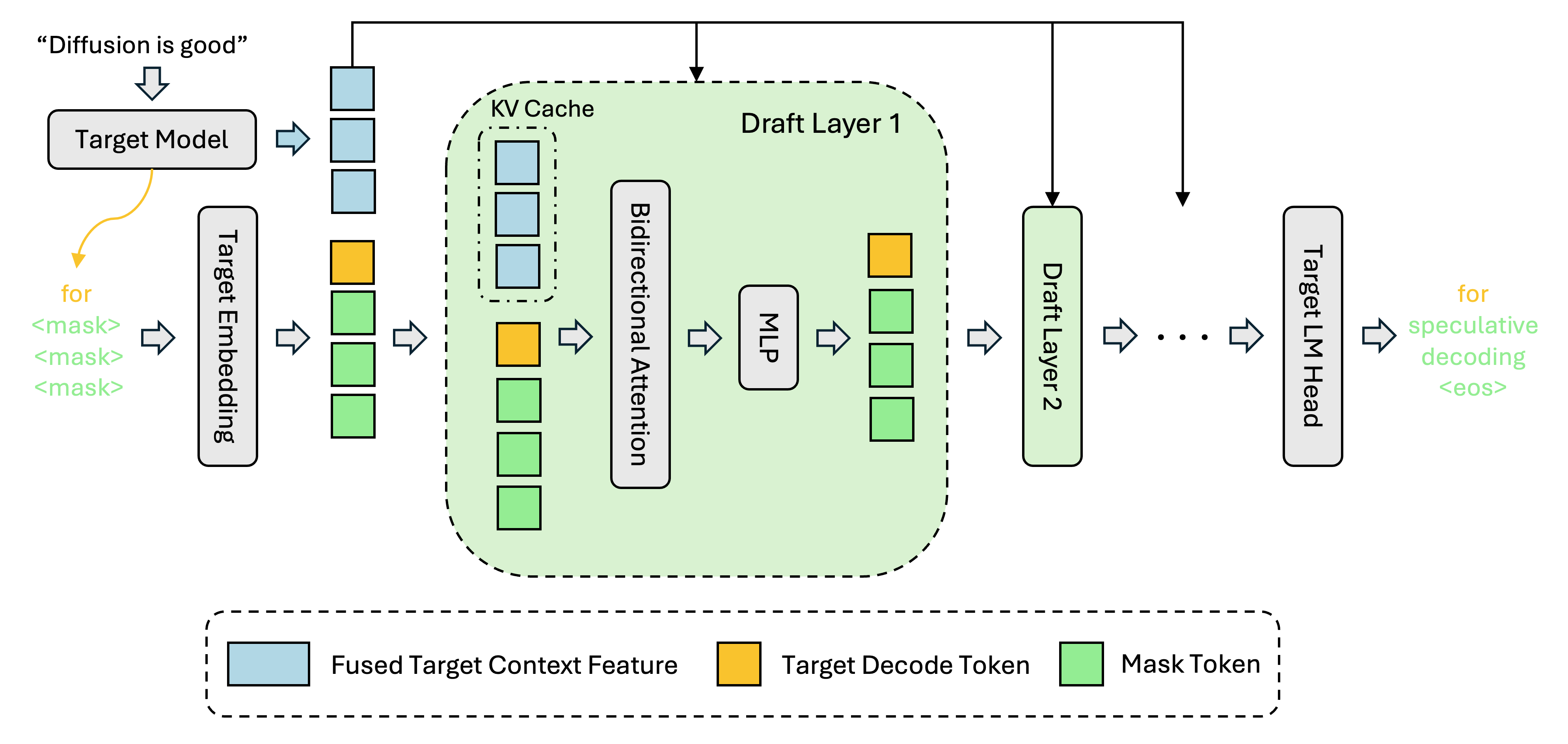
它对 RL rollout 的启发在于:
- draft 并行化:一次 forward 产生 token block,减少 draft 串行深度。
- target feature conditioning:draft 不是凭空猜,而是利用 target hidden states。
- lossless verification:最终输出仍由 target model 验证,理论上保持 speculative decoding 的无损性质。
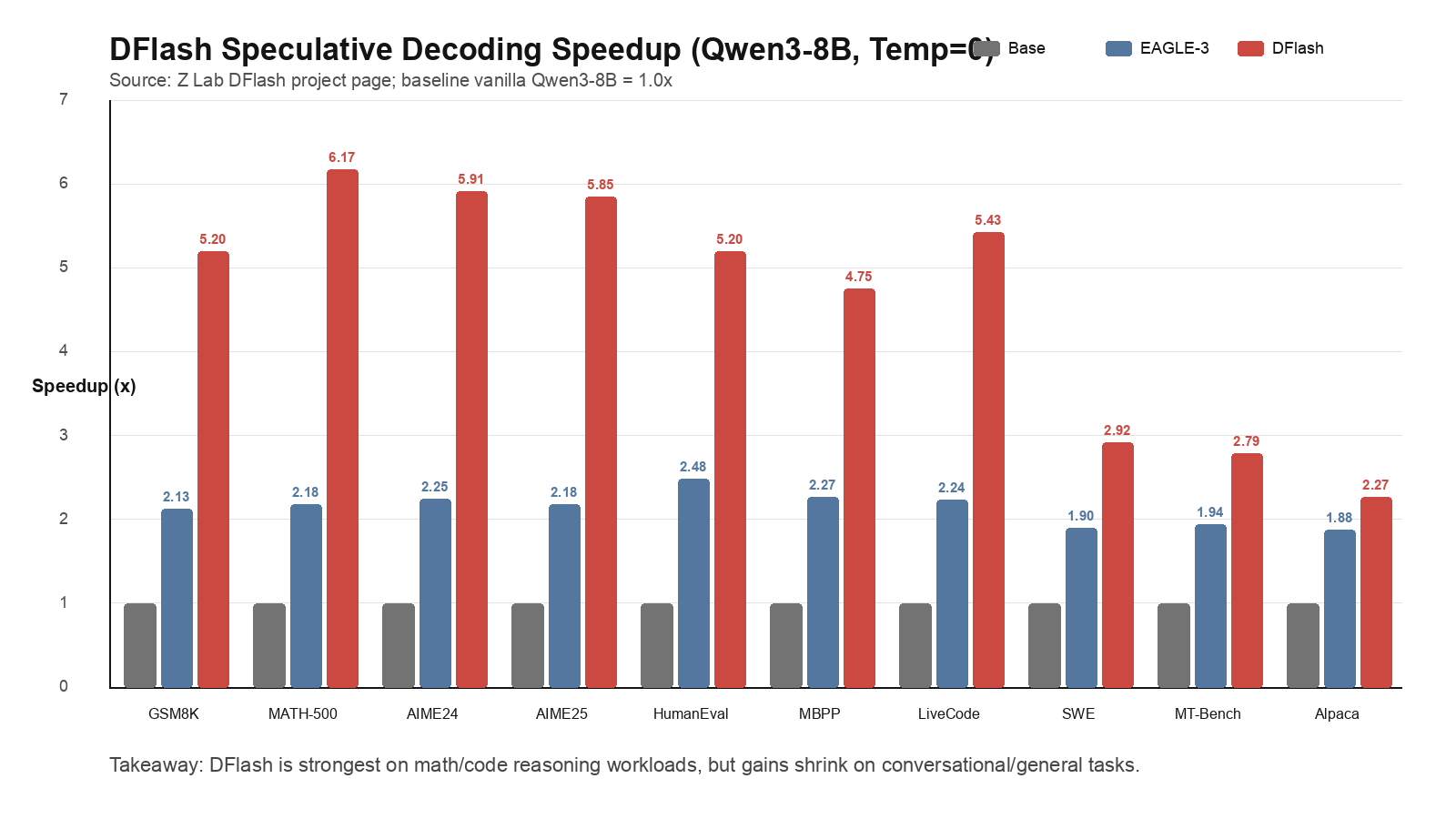
DFlash 论文摘要报告了 over 6x lossless acceleration,并称最高可达到 EAGLE-3 的 2.5x speedup;项目 README 写明 vLLM v0.20.1+ 已包含核心 DFlash 支持。3 但对 RL 来说,这仍然只是“可以考虑接入”的推理能力,而不是 verl 训练闭环中已经无条件稳定的开关。
接入风险¶
logprob 口径¶
PPO / GRPO 的 old logprob、ref logprob、KL 和 policy loss 必须基于 verifier / target policy。Draft model 的概率只能用于内部加速分析,不能进入训练目标。
policy version¶
每条 rollout 必须记录生成它的 actor checkpoint 或 policy version。异步训练、off-policy rollout 或权重同步延迟下,如果 response 来自旧 policy,但 logprob 被新 policy 误当作 old policy 计算,importance ratio 就会被污染。
draft 同步¶
Target 更新后,MTP head、EAGLE draft 或 DFlash draft 如果不同步,通常首先影响 acceptance 和吞吐;但如果实现错误,把 draft logprob 混入 loss,就会改变优化目标。
routing metadata¶
MoE 模型还要关心 expert 路由。Speculative rollout 如果返回 token 但丢失 routed experts、accepted mask 或 sample id,就无法和 router replay、old logprob、actor update 正确对齐。
实践建议¶
- 先在纯 serving benchmark 验证:测 tokens/s、acceptance length、draft overhead、verify overhead、显存和长尾 latency。
- 再接入 rollout:确认 response mask、finish reason、accepted token mask、logprob 和 routing metadata 都完整。
- 最后进入训练闭环:同时观察 reward、KL、clip ratio、entropy、grad norm 和 policy version gap。
优先验证语义,再追吞吐
Speculative decoding 的吞吐收益很诱人,但 RL 系统里更危险的是悄悄改变训练语义。一个正确但收益小的 verifier-exact 实现,比一个看起来很快但 logprob 口径不清的实现更有价值。
参考文献¶
-
Jian Chen, Yesheng Liang, Zhijian Liu, DFlash: Block Diffusion for Flash Speculative Decoding, arXiv, 2026. ↩
-
DFlash GitHub repository, vLLM DFlash documentation and Z Lab DFlash project page. ↩