GCC Compiler Option 1 : Optimization Options
手册¶
全体选项其中一部分是Optimize-Options
编译时最好按照其分类有效组织, 例子如下:
g++
# Warning Options
-Wall -Werror -Wno-unknown-pragmas -Wno-dangling-pointer
# Program Instrumentation Options
-fno-stack-protector
# Code-Gen-Options
-fno-exceptions -funwind-tables -fasynchronous-unwind-tables
# C++ Dialect
-fabi-version=2 -faligned-new -fno-rtti
# define
-DPIN_CRT=1 -DTARGET_IA32E -DHOST_IA32E -fPIC -DTARGET_LINUX
# include
-I../../../source/include/pin
-I../../../source/include/pin/gen
-isystem /staff/shaojiemike/Download/pin-3.28-98749-g6643ecee5-gcc-linux/extras/cxx/include
-isystem /staff/shaojiemike/Download/pin-3.28-98749-g6643ecee5-gcc-linux/extras/crt/include
-isystem /staff/shaojiemike/Download/pin-3.28-98749-g6643ecee5-gcc-linux/extras/crt/include/arch-x86_64
-isystem /staff/shaojiemike/Download/pin-3.28-98749-g6643ecee5-gcc-linux/extras/crt/include/kernel/uapi
-isystem /staff/shaojiemike/Download/pin-3.28-98749-g6643ecee5-gcc-linux/extras/crt/include/kernel/uapi/asm-x86
-I../../../extras/components/include
-I../../../extras/xed-intel64/include/xed
-I../../../source/tools/Utils
-I../../../source/tools/InstLib
# Optimization Options
-O3 -fomit-frame-pointer -fno-strict-aliasing
-c -o obj-intel64/inscount0.o inscount0.cpp
常见选项¶
-Wxxx对 xxx 启动warning,-fxxx启动xxx的编译器功能。-fno-xxx关闭对应选项???-gxxxdebug 相关-mxxx特定机器架构的选项
| 名称 | 含义 |
|---|---|
| -Wall | 打开常见的所有warning选项 |
| -Werror | 把warning当成error |
| -std= | C or C++ language standard. eg 'c++11' == 'c++0x' 'c++17' == 'c++1z', which 'c++0x','c++17' is develop codename |
| -Wunknown-pragmas | 未知的pragma会报错(-Wno-unknown-pragmas 应该是相反的) |
| -fomit-frame-pointer | 不生成栈帧指针,属于-O1优化 |
| -Wstack-protector | 没有防止堆栈崩溃的函数时warning (-fno-stack-protector) |
| -MMD | only user header files, not system header files. |
| -fexceptions | Enable exception handling. |
| -funwind-tables | Unwind tables contain debug frame information which is also necessary for the handling of such exceptions |
| -fasynchronous-unwind-tables | Generate unwind table in DWARF format. so it can be used for stack unwinding from asynchronous events |
| -fabi-version=n | Use version n of the C++ ABI. The default is version 0.(Version 2 is the version of the C++ ABI that first appeared in G++ 3.4, and was the default through G++ 4.9.) ABI: an application binary interface (ABI) is an interface between two binary program modules. Often, one of these modules is a library or operating system facility, and the other is a program that is being run by a user. |
| -fno-rtti | Disable generation of information about every class with virtual functions for use by the C++ run-time type identification features (dynamic_cast and typeid). If you don’t use those parts of the language, you can save some space by using this flag |
| -faligned-new | Enable support for C++17 new of types that require more alignment than void* ::operator new(std::size_t) provides. A numeric argument such as -faligned-new=32 can be used to specify how much alignment (in bytes) is provided by that function, but few users will need to override the default of alignof(std::max_align_t). This flag is enabled by default for -std=c++17. |
| -Wl, xxx | pass xxx option to linker, e.g., -Wl,-R/staff/shaojiemike/github/MultiPIM_icarus0/common/libconfig/lib specify a runtime library search path for dynamic libraries (shared libraries) during the linking process. |
General Optimization Options¶
-O, -O2, -O3¶
-O3 turns on all optimizations specified by -O2
and also turns on the -finline-functions, -funswitch-loops, -fpredictive-commoning, -fgcse-after-reload, -ftree-loop-vectorize, -ftree-loop-distribute-patterns, -ftree-slp-vectorize, -fvect-cost-model, -ftree-partial-pre and -fipa-cp-clone options
-ffastmath¶
允许使用浮点计算获得更高的性能,但可能会略微降低精度。
-Ofast¶
更快但是有保证正确
-flto¶
(仅限 GNU)链接时优化,当程序链接时检查文件之间的函数调用的步骤。该标志必须用于编译和链接时。使用此标志的编译时间很长,但是根据应用程序,当与 -O* 标志结合使用时,可能会有明显的性能改进。这个标志和任何优化标志都必须传递给链接器,并且应该调用 gcc/g++/gfortran 进行链接而不是直接调用 ld。
-mtune=processor¶
此标志对特定处理器类型进行额外调整,但它不会生成额外的 SIMD 指令,因此不存在体系结构兼容性问题。调整将涉及对处理器缓存大小、首选指令顺序等的优化。
在 AMD Bulldozer 节点上使用的值为 bdver1,在 AMD Epyc 节点上使用的值为 znver2。是zen ver2的简称。
Optimization Options: 数据预取相关¶
-fprefetch-loop-arrays- 如果目标机器支持,生成预取内存的指令,以提高访问大数组的循环的性能。这个选项可能产生更好或更差的代码;结果在很大程度上取决于源代码中的循环结构。
-Os禁用
Optimization Options: 访存优化相关¶
https://zhuanlan.zhihu.com/p/496435946
下面没有特别指明都是O3,默认开启
调整数据的访问顺序¶
-ftree-loop-distribution- 允许将一个复杂的大循环,拆开成多个循环,各自可以继续并行和向量化
-ftree-loop-distribute-patterns- 类似上面一种?
-floop-interchange- 允许交换多层循环次序来连续访存
-floop-unroll-and-jam- 允许多层循环,将外循环按某种系数展开,并将产生的多个内循环融合。
代码段对齐¶
(不是计算访问的数据)
-falign-functions=n:m:n2:m2- Enabled at levels -O2, -O3. 类似有一堆
调整代码块的布局¶
-freorder-blocks- 函数基本块重排来,减少分支
Optimization Options: Unroll Flags¶
-funroll-loops¶
Unroll loops whose number of iterations can be determined at compile time or upon entry to the loop. -funroll-loops implies -frerun-cse-after-loop. This option makes code larger, and may or may not make it run faster.
-funroll-all-loops¶
Unroll all loops, even if their number of iterations is uncertain when the loop is entered. This usually makes programs run more slowly. -funroll-all-loops implies the same options as -funroll-loops,
max-unrolled-insns¶
The maximum number of instructions that a loop should have if that loop is unrolled, and if the loop is unrolled, it determines how many times the loop code is unrolled. 如果循环被展开,则循环应具有的最大指令数,如果循环被展开,则它确定循环代码被展开的次数。
max-average-unrolled-insns¶
The maximum number of instructions biased by probabilities of their execution that a loop should have if that loop is unrolled, and if the loop is unrolled, it determines how many times the loop code is unrolled. 如果一个循环被展开,则根据其执行概率偏置的最大指令数,如果该循环被展开,则确定循环代码被展开的次数。
max-unroll-times¶
The maximum number of unrollings of a single loop. 单个循环的最大展开次数。
Optimization Options: SIMD Instructions¶
-march=native¶
会自动检测,但有可能检测不对。
-march="arch"¶
这将为特定架构生成 SIMD 指令并应用 -mtune 优化。 arch 的有用值与上面的 -mtune 标志相同。
g++ -march=native -m32 ... -Q --help=target
-mtune= skylake-avx512
Known valid arguments for -march= option:
i386 i486 i586 pentium lakemont pentium-mmx winchip-c6 winchip2 c3 samuel-2 c3-2 nehemiah c7 esther i686 pentiumpro pentium2 pentium3 pentium3m pentium-m pentium4 pentium4m prescott nocona core2 nehalem corei7 westmere sandybridge corei7-avx ivybridge core-avx-i haswell core-avx2 broadwell skylake skylake-avx512 cannonlake icelake-client icelake-server cascadelake tigerlake bonnell atom silvermont slm goldmont goldmont-plus tremont knl knm intel geode k6 k6-2 k6-3 athlon athlon-tbird athlon-4 athlon-xp athlon-mp x86-64 eden-x2 nano nano-1000 nano-2000 nano-3000 nano-x2 eden-x4 nano-x4 k8 k8-sse3 opteron opteron-sse3 athlon64 athlon64-sse3 athlon-fx amdfam10 barcelona bdver1 bdver2 bdver3 bdver4 znver1 znver2 btver1 btver2 generic native
-msse4.2 -mavx -mavx2 -march=core-avx2¶
dynamic flags¶
-fPIC¶
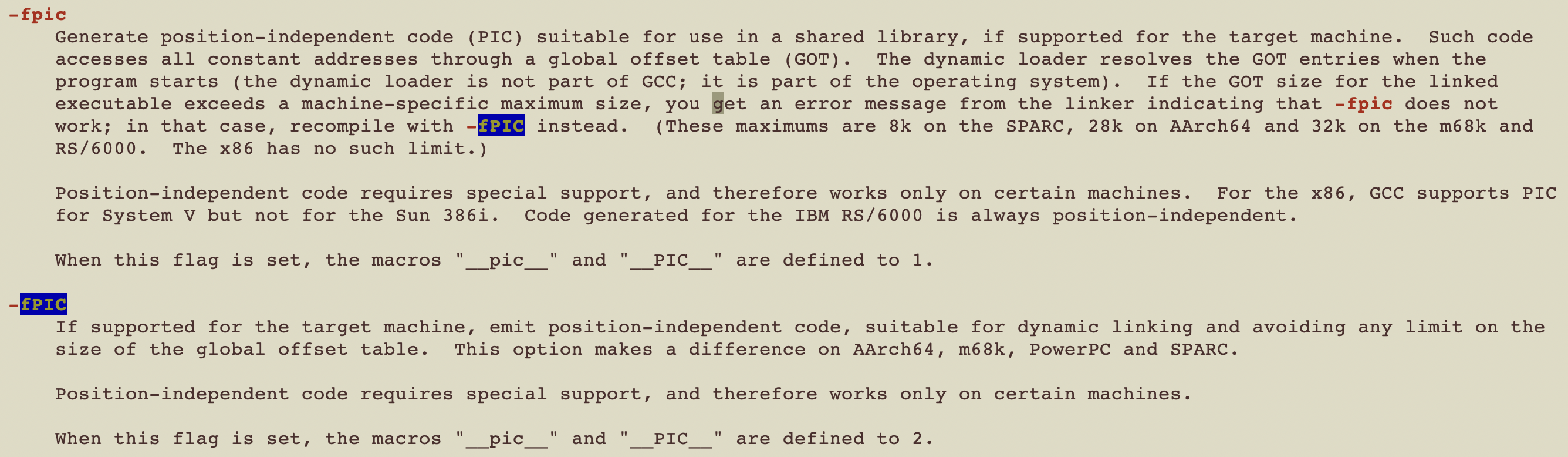
position-independent code(PIC)
需要进一步的研究学习¶
暂无
遇到的问题¶
暂无