Optimization Outline
Sun's 常见超线性加速的情况¶
http://www.cs.iit.edu/%7Esun/cs546.html#materials
https://annals-csis.org/Volume_8/pliks/498.pdf
Superlinear Speedup in HPC Systems: why and when?
- Cache size increased 多核的cache总size增加
- 在大多数的并行计算系统中,每个处理器都有少量的高速缓存,当某一问题执行在大量的处理器上,而所需要的数据都放在高速缓存中时,由于数据的复用,总的计算时间趋于减少,如果由于这种高速缓存效应补偿了由于通信造成的额外开销,就有可能造成超线性加速比。
- Overhead reduced 锁减少,粒度变小
- Latency hidden 数据预取更多了
- Randomized algorithms
- 在某些并行搜索算法中,允许不同的处理器在不同的分支方向上同时搜索,当某一处理器一旦迅速的找到了解,它就向其余的处理器发出中止搜索的信号,这就会提前取消那些在串行算法中所做的无谓的搜索分枝,从而出现超线性加速比现象
- Mathematical inefficiency of the serial algorithm 改并行算法
- Higher memory consumption access cost for in sequantial processing
应用优化前提¶
- 迭代进行 :分析程序最大热点(perf,vtune工具)->优化该热点—>分析程序最大热点->……
-
自顶向下分析优化程序热点的思路
- 全局算法的调研、理解、总体设计改进
- 程序任务划分,并行各部分模块
- 仔细分析热点的kernel循环
-
基本了解物理数学背景公式
- 阅读代码,明白实现
- 从main函数开始看的都是大撒比,没错,说的就是我
- 带着问题看,才能快速抓住重点
- 建议串行直接用vtune判断算法热点和时间
- 粗略判断热点
- 加入各部分热点的时间输出 (必需的:积极的正向反馈,会提高积极性和理清思路)
- 寻找合适的大例子
- 运行n次求得平均值; 或者对不同大小的例子在不同参数下的效果拉图对比
- 单机不同数量多核,同机器的不同编译器,不同核心kernel/CPU
- warmup=10 loop=50 先热身10次,然后循环10次
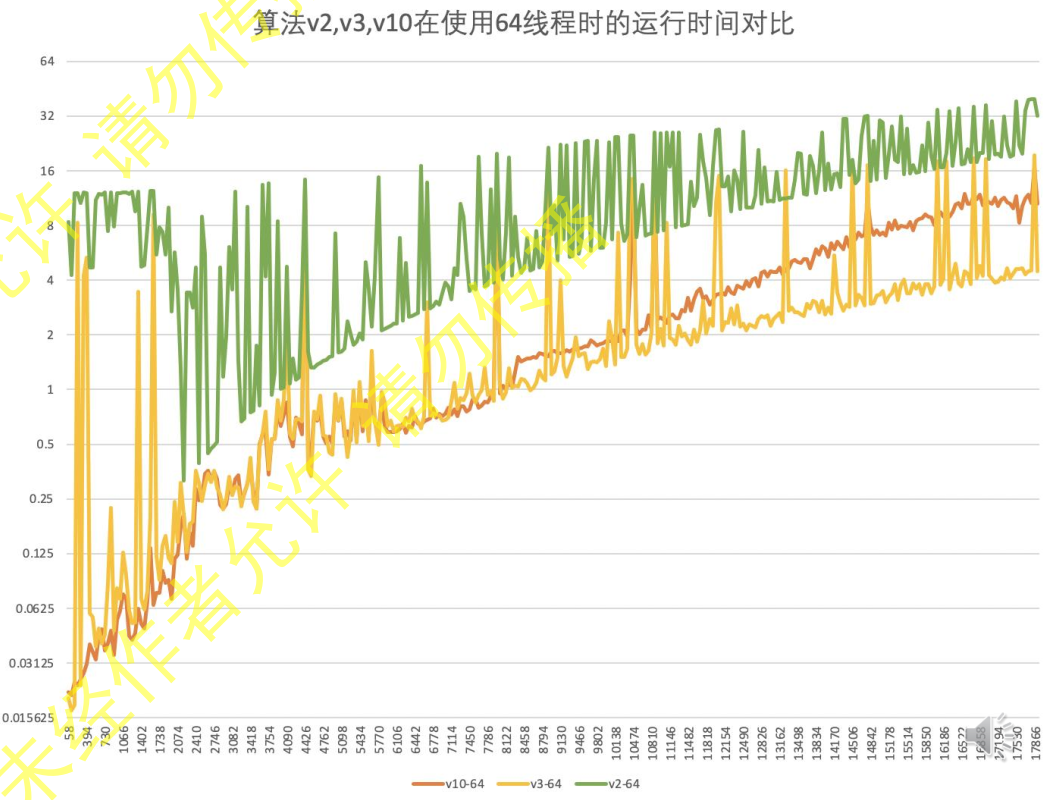 7. 每次优化基给予正确性的评价,并对负优化进行解释。
7. 每次优化基给予正确性的评价,并对负优化进行解释。
- 查看汇编
- 基本并行加速实现后,vtune检查访存,或者用Intel advisor的Roofline Model来分析。
- 新函数用
utils.cpp和utils.h写
应用类型及其常见优化¶
- 计算密集
- 采用适合并行平台的算法
- CPU核数利用率
- 多进程
- 进程池动态调度
- 多线程(对于特别小的例子,一个cpu的核就够用了)
- 线程亲和性
- 线程动态调度
- 多进程
- 向量化率(提高单次计算量)SIMD
- 自动向量化提升有限吗?怎么写出好让编译器自动向量化的代码
- https://blog.csdn.net/zyl910/?type=blog SIMD测试比较
- pragma omp parallel for simd
- 循环展开,凑够无依赖计算,填满流水线avx512的宽度(8个float)
- intrins接口手动向量化
- 注意边界,不足8个单独计算
- 手动向量化avx2一般会快一些

- 自动向量化提升有限吗?怎么写出好让编译器自动向量化的代码
- 降低计算量技巧
- 其他各种小技巧
- 使用掩码代替分支判断
- 增A:
|A删A:&(~A)判断:&A!=0 - https://blog.csdn.net/zyl910/article/details/7345655
- 增A:
- 替换if
tmp[i][j] = (!(cnt^3))||((a[i][j]&1)&&(!(cnt^4))); - 使用乘法代替除法
- 位运算实现整数绝对值
- 位运算实现整数MaxMin
- 位运算求二进制内1的个数
- 位运算代替乘除2运算

- 重新划分去除乘除,小代价是归约一下sigma

- 混合精度(降低部分精度,降低计算量)
- 数据重用(不重复计算,降低计算量)
- 访存密集
- vtune memory access分析,提高cpu访存带宽,优化2CPU通信
- store与load比stream慢很多
- 原因store是将要写的数据load到缓存里,然后修改。而stream是直接写内存。
J5GBR.png)

- store与load比stream慢很多
- 计算分块
- 根据L1的大小设置块大小
- double 8 bytes
- 改变数据结构优化访存(提高cache命中率)
- 不合理的数据结构定义,导致数据存储不连续。通过改变数据结构,通过内存指针访问连续地址
- 强制使用静态链接库glibc
- 访存局部性原理(提高cache命中率)
- c语言先行后列
- 循环拆分、循环重组
- 根据cache空间,以及cache策略,进行cache数据预取,
- 计算融合(减少访存次数)
- 计算结果及时使用,去除中间结果的存储访问时间
- 将多个循环整合为一个
- 对于对同一个地址的连续读写依赖,采取pingpong-buffer来两个分治
- 申请空间
- 负载均衡(并行划分)
- 对不同的数据量进行不同的策略,比如数据特别少,单cpu反而最快。
- 二维的图,无脑按照y划分就行。
- 合并的时候,按照并查集(1.维护顺序 2.有代表性)
- 针对数据规模,是否要并行。
- IO密集
- 并行读取
- 内存硬盘化
- 通讯密集
- IB网通信
- 改变通信结构
- 打包发送
- 希尔伯特划分(一维二维)
- 编译选项
- O3优化,ipo过程优化,fp-model fast=2加速浮点计算
- 其他未分类

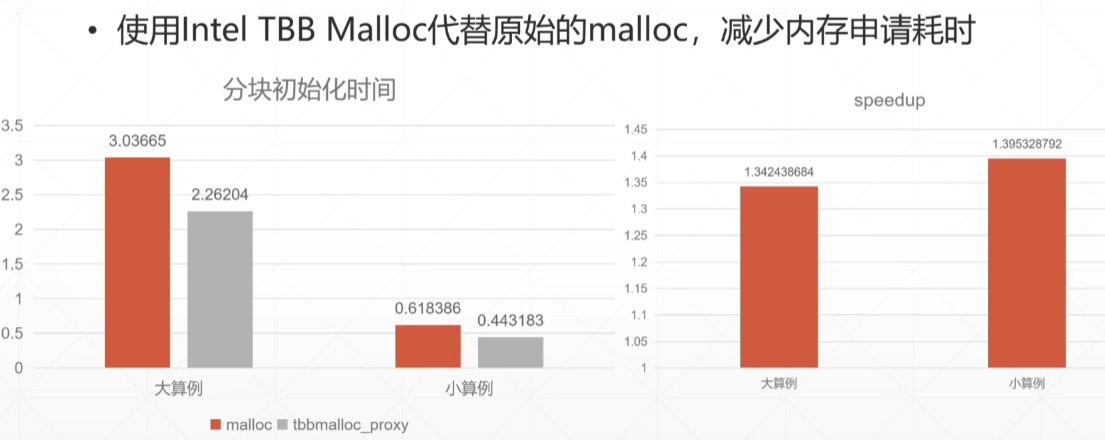
还没来得及看的优化¶
Software optimization resources :https://www.agner.org/optimize/
AMD 罗马米兰平台优化¶
https://www.bilibili.com/video/BV19q4y197uX?spm_id_from=333.999.0.0
https://www.bilibili.com/video/BV1vU4y1u7nL?spm_id_from=333.999.0.0




常见的参数¶
2 sockets cpu latency : 50/60
core memory bandwidth :20GB/s
样例图片¶
- 不合理数据结构,和合理的数据结构
GN)0F1X@WZW~J9U.png)

- 编译选项


性能 功耗 与容错¶
陈子忠 教授( 美国加州大学河滨分校 ) 230616报告
- 多核的出现,单核能耗与频率三次方成正比,难以压住散热
- 在已知调度时间复杂度估计的情况下,降低频率DVFS延长执行能大幅度节约功耗。同理提升频率也行。
- 纠错:检查点机制,中间验证算法复杂度比计算算法复杂度低。
需要进一步的研究学习¶
https://johnysswlab.com/
遇到的问题¶
太糊了

开题缘由、总结、反思、吐槽~~¶
因为参加2021 IPCC,观看B站视频,学到很多特地总结一下
参考文献¶
https://www.bilibili.com/video/BV1Dv411p7ay