LLVM-MCA: docs
Introduction¶
LLVM Machine Code Analyzer 是一种性能分析工具,它使用llvm中可用的信息(如调度模型)静态测量特定CPU中机器代码的性能。
性能是根据吞吐量和处理器资源消耗来衡量的。该工具目前适用于在后端中使用LLVM调度模型的处理器。
该工具的主要目标不仅是预测代码在目标上运行时的性能,还帮助诊断潜在的性能问题。
给定汇编代码,llvm-mca可以估计每个周期的指令数(IPC)以及硬件资源压力。分析和报告风格的灵感来自英特尔的IACA工具。
github¶
https://github.com/llvm/llvm-project/tree/main/llvm/tools/llvm-mca
docs¶
https://llvm.org/docs/CommandGuide/llvm-mca.html
options¶
architecture¶
-mtriple=<target triple>
eg. -mtriple=x86_64-unknown-unknown
-march=<arch>
Specify the architecture for which to analyze the code. It defaults to the host default target.
-march=<arch>
Specify the architecture for which to analyze the code. It defaults to the host default target.
output-report¶
-output-asm-variant=<variant id>
为工具生成的报告指定输出程序集变量。???
-print-imm-hex
优先16进制输出。
-json
除了瓶颈分析,基本都支持json格式输出视图
-timeline
打印指令流水线情况
runtime options¶
-dispatch=<width>
为处理器指定不同的调度宽度。调度宽度默认为处理器调度模型中的“IssueWidth”字段。
-register-file-size=<size>
指定寄存器文件的大小。指定时,该项会限制可用于寄存器重命名的物理寄存器的数量。此标志的值为零意味着“无限数量的物理寄存器”。
-iterations=<number of iterations>
指定要运行的迭代次数。如果此标志设置为 0,则该工具会将迭代次数设置为默认值(即 100)。
-noalias=<bool>
loads and stores don’t alias
-lqueue=<load queue size>
-squeue=<store queue size>
在工具模拟的加载/存储单元中指定加载队列的大小。默认情况下,该工具假定加载队列中的条目数量不受限制。此标志的零值将被忽略,而是使用默认加载队列大小。
-disable-cb
强制使用通用的 CustomBehaviour 和 InstrPostProcess 类,而不是使用目标特定的实现。通用类从不检测任何自定义危险或对指令进行任何后处理修改。
more values/Info¶
-resource-pressure
Enable the resource pressure view. This is enabled by default.
-register-file-stats
启用注册文件使用统计。
-dispatch-stats
-scheduler-stats
-retire-stats
-instruction-info
启用额外的调度/发出/retire control unit统计。该视图收集和分析指令分派事件,以及静态/动态分派停顿事件。默认情况下禁用此视图。
-show-encoding
打印指令16进制
-all-stats
-all-views
-instruction-tables
这与资源压力视图不同,因为它不需要模拟代码。相反,它按顺序打印每个指令的资源压力的理论均匀分布。
-bottleneck-analysis
打印有关影响吞吐量的瓶颈的信息。这种分析可能很昂贵,并且默认情况下是禁用的。瓶颈在摘要视图中突出显示。具有有序后端的处理器目前不支持瓶颈分析。???
实现逻辑¶
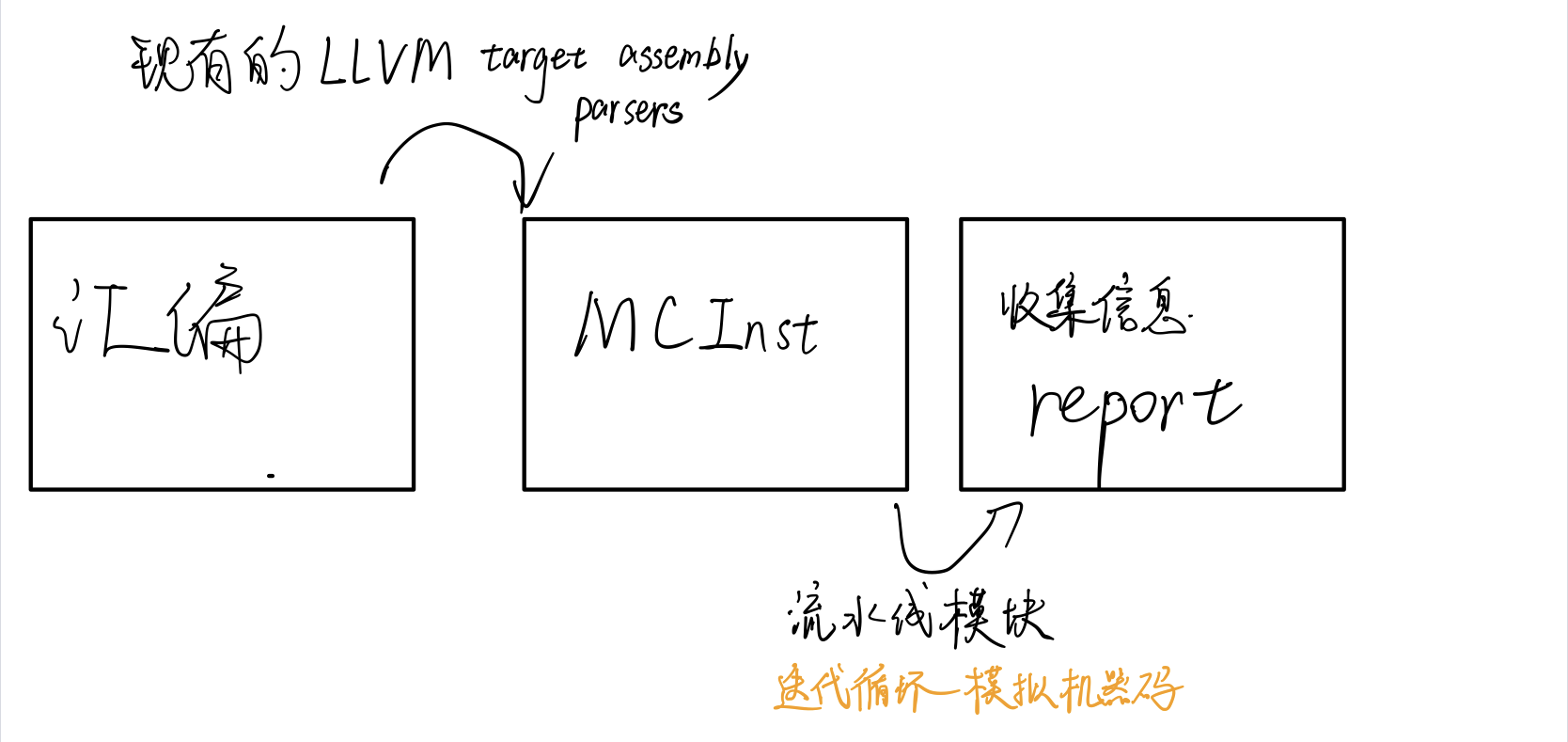
样例分析¶
quick overview of the performance throughput¶
Iterations: 300
Instructions: 900
Total Cycles: 610
Total uOps: 900
Dispatch Width: 2
uOps Per Cycle: 1.48
IPC: 1.48
Block RThroughput: 2.0
- IPC
- 理论最大值是$\(\frac{OneLoopInstructions}{Block\_RThroughput}=(OneLoopInstructions)*(Block\_Throughput)\)$
- uOps Per Cycle
- simulated micro opcodes (uOps)
- 每个周期的simulated micro opcodes数
- 在不考虑循环依赖的情况下,理论上最大值是$\(\frac{OneLoopUOps}{Block\_RThroughput}=(OneLoopUOps)*(Block\_Throughput)\)$
- A delta between Dispatch Width and this field is an indicator of a performance issue.
- The delta between the Dispatch Width (2.00), and the theoretical maximum uOp throughput (1.50) is an indicator of a performance bottleneck caused by the lack of hardware resources, and the Resource pressure view can help to identify the problematic resource usage.
- Dispatch Width
- 发射到乱序后端的最大微指令操作数(the maximum number of micro opcodes/uOps)?
- Block RThroughput (Block Reciprocal Throughput)
- 在不考虑循环依赖的情况下,理论上的每次循环的最大block或者iterations数
- 受限于dispatch rate和the availability of hardware resources.
Instruction info view¶
Instruction Info:
[1]: #uOps
[2]: Latency
[3]: RThroughput
[4]: MayLoad
[5]: MayStore
[6]: HasSideEffects (U)
[1] [2] [3] [4] [5] [6] Instructions:
1 2 1.00 vmulps %xmm0, %xmm1, %xmm2
1 3 1.00 vhaddps %xmm2, %xmm2, %xmm3
1 3 1.00 vhaddps %xmm3, %xmm3, %xmm4
```
显示了指令里队列每条指令的**延迟**和**吞吐量的倒数**。
RThroughput是指令吞吐量的倒数。在不考虑循环依赖的情况下,吞吐量是**单周期能执行的同类型指令的最大数量**。
### Resource pressure view
Resource pressure per iteration: [0] [1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] - - - 2.00 1.00 2.00 1.00 - - - - - - -
Resource pressure by instruction: [0] [1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] Instructions: - - - - 1.00 - 1.00 - - - - - - - vmulps %xmm0, %xmm1, %xmm2 - - - 1.00 - 1.00 - - - - - - - - vhaddps %xmm2, %xmm2, %xmm3 - - - 1.00 - 1.00 - - - - - - - - vhaddps %xmm3, %xmm3, %xmm4 ```
每次循环或者每条指令执行,消耗的资源周期数。从而找到高资源占用的部分。
Timeline View¶
可打印流水线情况
Timeline view:
012345
Index 0123456789
[0,0] DeeER. . . vmulps %xmm0, %xmm1, %xmm2
[0,1] D==eeeER . . vhaddps %xmm2, %xmm2, %xmm3
[0,2] .D====eeeER . vhaddps %xmm3, %xmm3, %xmm4
[1,0] .DeeE-----R . vmulps %xmm0, %xmm1, %xmm2
[1,1] . D=eeeE---R . vhaddps %xmm2, %xmm2, %xmm3
[1,2] . D====eeeER . vhaddps %xmm3, %xmm3, %xmm4
[2,0] . DeeE-----R . vmulps %xmm0, %xmm1, %xmm2
[2,1] . D====eeeER . vhaddps %xmm2, %xmm2, %xmm3
[2,2] . D======eeeER vhaddps %xmm3, %xmm3, %xmm4
Average Wait times (based on the timeline view):
[0]: Executions
[1]: Average time spent waiting in a scheduler's queue
[2]: Average time spent waiting in a scheduler's queue while ready
[3]: Average time elapsed from WB until retire stage
[0] [1] [2] [3]
0. 3 1.0 1.0 3.3 vmulps %xmm0, %xmm1, %xmm2
1. 3 3.3 0.7 1.0 vhaddps %xmm2, %xmm2, %xmm3
2. 3 5.7 0.0 0.0 vhaddps %xmm3, %xmm3, %xmm4
3 3.3 0.5 1.4 <total>
影响因素包括:
- 数据冲突/依赖:读后写,写后读依赖 。无法指令级并行,也可以通过寄存器重命名解决
- 结构冲突:占用发射位 或者 同一硬件
- 控制冲突:分支?
- instructions must retire in program order, so [1,0] has to wait for [0,2] to be retired first
Bottleneck Analysis¶
- 可以分析出数据冲突/依赖和结构冲突的影响大小
- 准确性取决于模拟和是否有对应CPU模型。
- 暂时不支持有序后端。
Cycles with backend pressure increase [ 91.52% ]
Throughput Bottlenecks:
Resource Pressure [ 0.01% ]
- SBPort0 [ 0.01% ]
- SBPort1 [ 0.01% ]
- SBPort5 [ 0.01% ]
Data Dependencies: [ 91.51% ]
- Register Dependencies [ 91.51% ]
- Memory Dependencies [ 10.76% ]
- 端口信息来自TableGen
llvm/lib/Target/X86/X86SchedSandyBridge.td - 鲲鹏920的来自
llvm/lib/Target/AArch64/AArch64SchedTSV110.td
额外信息¶
- Dynamic Dispatch Stall Cycles
- Dispatch Logic
- 可以看出流水线发射满带宽或几条指令的时间占比
- Schedulers
- 每个周期微指令发射数占比
- Scheduler's queue usage
- 执行时使用的平均或最大buffer entries (i.e., scheduler queue entries)
-
AMD Jaguar
-
JALU01 - A scheduler for ALU instructions. JFPU01 - A scheduler floating point operations. JLSAGU - A scheduler for address generation. -
Retire Control Unit
- 在一个周期里有多少指令retired的占比(好吧,感觉有语病)
- A re-order buffer (ROB) 的使用情况
- Register File statistics
- physical register file (PRF)
- floating-point registers (JFpuPRF)
- integer registers (JIntegerPRF)
Instruction Flow¶
llvm-mca 假设指令在模拟开始之前已经全部解码并放入队列中。因此,指令提取和解码阶段没有被计算。未考虑前端的性能瓶颈。此外,llvm-mca 不模拟分支预测。
Instruction Dispatch¶
处理器的默认 dispatch width值等于LLVM’s scheduling model里的IssueWidth值。
An instruction can be dispatched if:
- The size of the dispatch group is smaller than processor’s dispatch width.
- There are enough entries in the reorder buffer.
- There are enough physical registers to do register renaming.
- The schedulers are not full.
reorder buffer负责跟踪命令,使之按照程序顺序retired结束。其默认值为 MicroOpBufferSize 。
各种Buffered resources 被视作scheduler resources.
Instruction Issue¶
每个处理器调度器实现一个指令缓冲区。指令必须在调度程序的缓冲区中等待,直到输入寄存器操作数可用。只有在那个时候,指令才符合执行的条件,并且可能会被发出(可能是乱序的)以供执行。 llvm-mca 在调度模型的帮助下计算指令延迟。
llvm-mca 的调度器旨在模拟多处理器调度器。调度器负责跟踪数据依赖关系,并动态选择指令消耗哪些处理器资源。它将处理器资源单元和资源组的管理委托给资源管理器。资源管理器负责选择指令消耗的资源单元。例如,如果一条指令消耗了一个资源组的1cy,则资源管理器从该组中选择一个可用单元;默认情况下,资源管理器使用循环选择器来保证资源使用在组的所有单元之间均匀分配。
llvm-mca’s scheduler internally groups instructions into three sets:
- WaitSet: a set of instructions whose operands are not ready.
- ReadySet: a set of instructions ready to execute.
- IssuedSet: a set of instructions executing.
Write-Back and Retire Stage¶
retire control unit
- When instructions are executed,the flags the instruction as “ready to retire.”
- Instructions are retired in program order
- free the physical registers
Load/Store Unit and Memory Consistency Model¶
load/store unit (LSUnit)用来模拟乱序memory操作
The rules are:
- A younger load is allowed to pass an older load only if there are no intervening stores or barriers between the two loads.
- A younger load is allowed to pass an older store provided that the load does not alias with the store.
- A younger store is not allowed to pass an older store.不能交换顺序的意思
- A younger store is not allowed to pass an older load.
假设 loads do not alias (-noalias=true) store operations.Under this assumption, younger loads are always allowed to pass older stores. ???
LSUnit不打算跑alias analysis来预测何时load与store不相互alias???
in the case of write-combining memory, rule 3 could be relaxed to allow reordering of non-aliasing store operations.???
LSUnit不管的其余三点:
- The LSUnit does not know when store-to-load forwarding may occur.
- The LSUnit does not know anything about cache hierarchy and memory types.
- The LSUnit does not know how to identify serializing operations and memory fences.
- The LSUnit does not attempt to predict if a load or store hits or misses the L1 cache(不考虑cache命中,默认是命中L1,产生the load-to-use latency的最乐观开销)
llvm-mca 不知道序列化操作或内存屏障之类的指令。 LSUnit 保守地假设同时具有“MayLoad”和未建模副作用的指令的行为类似于“软”load-barrier。这意味着,它在不强制刷新load队列的情况下序列化加载。类似地,“MayStore”和具有未建模副作用的指令被视为store障碍。完整的memory-barrier是具有未建模副作用的“MayLoad”和“MayStore”指令。LLVM的实现是不准确的,但这是我们目前使用 LLVM 中可用的当前信息所能做的最好的事情。
load/store barrier会占用在load/store 队列里占用一项。 当load/store barrier是其队列里oldest项时,其会被执行

In-order Issue and Execute¶
有序处理器被建模为单个 InOrderIssueStage 阶段。它绕过 Dispatch、Scheduler 和 Load/Store 单元。一旦它们的操作数寄存器可用并且满足资源要求,就会发出指令。根据LLVM的调度模型中IssueWidth参数的值,可以在一个周期内发出多条指令。一旦发出,指令就会被移到 IssuedInst 集,直到它准备好retire。 llvm-mca 确保按顺序提交写入。但是,如果 RetireOOO 属性for at least one of its writes为真,则允许指令提交写入并无序retire???
Custom Behaviour 自定义行为¶
某些指令在该模型中并不能被准确的模拟。为了几条指令而修改模型不是个好的选择,一般通过CustomBehaviour类对某些指令进行特殊建模:自定义数据依赖,以及规避、单独处理特殊情况。
为此,llvm-mca设置了一个通用的以及多个特殊的CustomBehaviour类。下面两种情况下会使用通用类:
- 开启了
-disable-cb选项 - 不存在针对某目标的特殊类(通用类也做不了什么,我什么也做不到😥)
但是注意目前只有in-order流水线实现了CustomBehaviour类,out-order流水线将来也会支持。
该类主要通过checkCustomHazard()函数来实现,通过当前指令和真正流水线中执行的指令,来判断当前指令需要等待几个周期才能发射。
如果想对没有实现的目标添加CustomBehaviour类,可以参考已有的实现,比如在/llvm/lib/Target/AMDGPU/MCA/目录下。
Custom Views 自定义视图¶
关于自定义的视图的添加路径,如果没有输出从未在MC layer classes (MCSubtargetInfo, MCInstrInfo, etc.)里出现过的新后端值,请把实现加入/tools/llvm-mca/View/。相反,请加入/lib/Target/<TargetName>/MCA/目录。
关于Custom Views所需内容,需要写特殊的CustomBehaviour类来覆写CustomBehaviour::getViews()函数,根据位置的不同还有三种实现getStartViews(), getPostInstrInfoViews(),getEndViews()。
影响准确性的因素¶
调度模型不仅用于计算指令延迟和吞吐量,还用于了解可用的处理器资源以及如何模拟它们。
llvm mca进行分析的质量不可避免地受到llvm中调度模型质量的影响。
功能(能估计的值¶
- IPC
- 硬件资源压力resource-pressure
-
一些额外Info? 1.
-
吞吐量瓶颈?
支持对特定代码块的分析¶
-
汇编代码,支持命名和嵌套
-
高级语言,通过内联汇编实现
int foo(int a, int b) {
__asm volatile("# LLVM-MCA-BEGIN foo");
a += 42;
__asm volatile("# LLVM-MCA-END");
a *= b;
return a;
}
但是,这会干扰循环矢量化等优化,并可能对生成的代码产生影响。具体影响请对比汇编代码。
相关论文¶
Google学术搜llvm-mca,一堆论文。但是不急着看,因为没有预备知识,没有问题的去看论文。效率和收获很低的,而且会看不懂。
相关项目¶
mc-ruler¶
mc-ruler是整合了llvm-mca的cmake,可以打印指定部分的代码分析信息。如果之后要测试可能用得上。
需要进一步的研究学习¶
- 具体功能
- llvm如何实现的,要看代码。
遇到的问题¶
- (llvm-mca detects Intel syntax by the presence of an .intel_syntax directive at the beginning of the input. By default its output syntax matches that of its input.)
- ???的地方
- 大概看了一下功能,但是性能怎么对比呢。准确值是多少呢?
- arm kunpeng pmu-tools 实现
- 每次的估计值会波动吗?
如何和大神交流呢+提问的艺术
开题缘由、总结、反思、吐槽~~¶
参考文献¶
无