Crawler
如何获取请求链接¶
这个api是怎么来的呢?
lesson_info_url = "https://www.eeo.cn/saasajax/webcast.ajax.php?action=getLessonLiveInfo"
感谢大佬回答
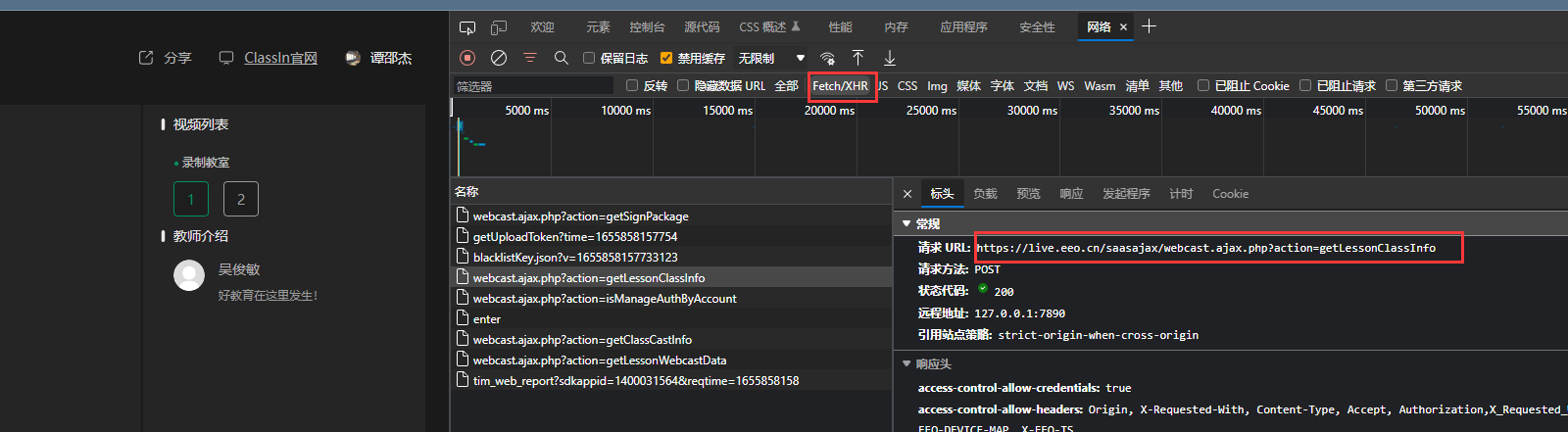
输入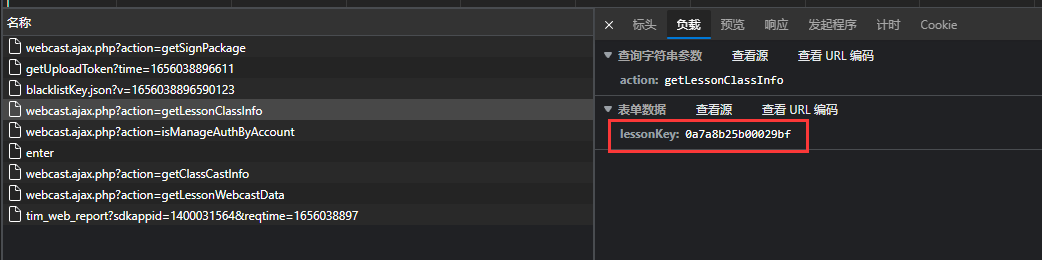
返回数据
PHP源文件¶
PHP是后端语言,前端是无法查看的,前端看到的是最终运算之后的结果,PHP源代码是无法查看的。
使用¶
将 header改一下就能用了,注意不要开代理
from requests import Session
session = Session()
lesson_info_url = "https://www.eeo.cn/saasajax/webcast.ajax.php?action=getLessonLiveInfo"
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.9,zh-TW;q=0.8,en;q=0.7',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36'
}
data = {
'lessonKey': lessonKey
}
resp = session.post(url=lesson_info_url, headers=headers, data=data)
text = resp.json()
CourseName = text['data']['courseName']
urllib.request下载视频¶
from urllib import request
base_url = 'https://f.us.sinaimg.cn/001KhC86lx07laEy0PtC01040200y8vC0k010.mp4?label=mp4_hd&template=640x360.28&Expires=1528689591&ssig=qhWun5Mago&KID=unistore,video'
#下载进度函数
def report(a,b,c):
'''
a:已经下载的数据块
b:数据块的大小
c:远程文件的大小
'''
per = 100.0 * a * b / c
if per > 100:
per = 100
if per % 1 == 1:
print ('%.2f%%' % per)
#使用下载函数下载视频并调用进度函数输出下载进度
request.urlretrieve(url=base_url,filename='weibo/1.mp4',reporthook=report,data=None)
例子一¶
小白尝试 扒学校的资源网址(http://wlkt.ustc.edu.cn/)
爬取List读取¶
正则匹配video/detail出视频网址后缀

网页视频位置¶
正则匹配mp4.php得到视频位置http://wlkt.ustc.edu.cn/mp4.php?file=HXMEV11IQNB2ZXPM6BVWY77AJ2HZTM4U
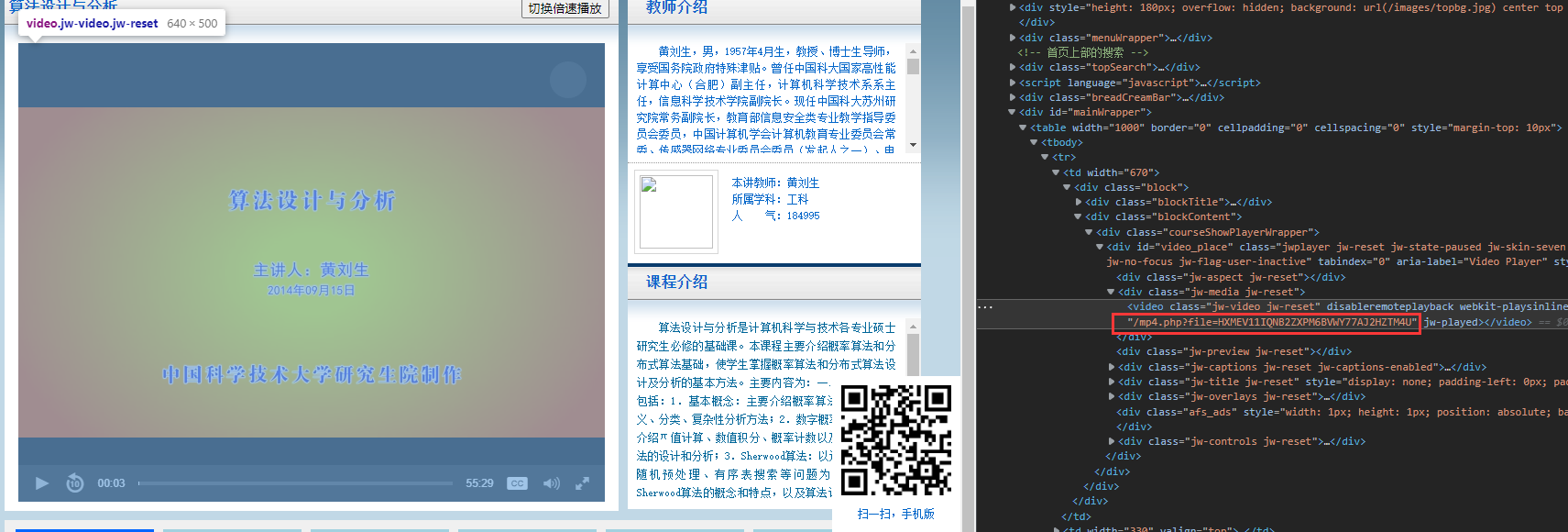 但是不打开网站没有php返回,网页只能得到。
但是不打开网站没有php返回,网页只能得到。
 可通过下面API返回需要的, 可以见github代码
可通过下面API返回需要的, 可以见github代码
opener = urllib.request.FancyURLopener({})
f = opener.open(taskUrl)
content = f.read()
#1.得到beautifulsoup对象
soup = BeautifulSoup(content,'html.parser')
#通过指定的 属性获取对象
ic(soup.find(id=glv._get(taskType)["data1id"]).attrs['value'])#单个对象
 data输入
data输入
 返回数据
返回数据

需要进一步的研究学习¶
暂无
遇到的问题¶
暂无
开题缘由、总结、反思、吐槽~~¶
科大BB clashIn 想爬录像。但是网上的两个都用不了了,想自学,改一下
https://github.com/aoxy/ClassIn-Video-Download
https://github.com/JiangGua/classin-downloader
参考文献¶
https://blog.csdn.net/qq_37275405/article/details/80780925