Cuda Optimize : Stencil
课程报告PPT¶
有对应的PPT,代码。
最终将1000ms程序优化到1~2ms
乔良师兄有根据知乎介绍如何利用寄存器文件缓存
SMEM难点: 跨线程访存¶
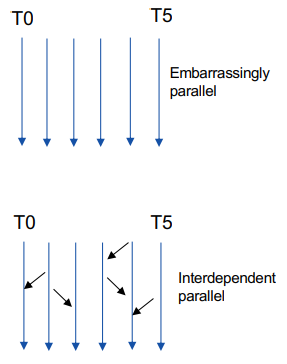
- 不仅每个线程需要访问自己划分对应区域之外的元素
- 而且访问的总个数也不是线程数对应的倍数
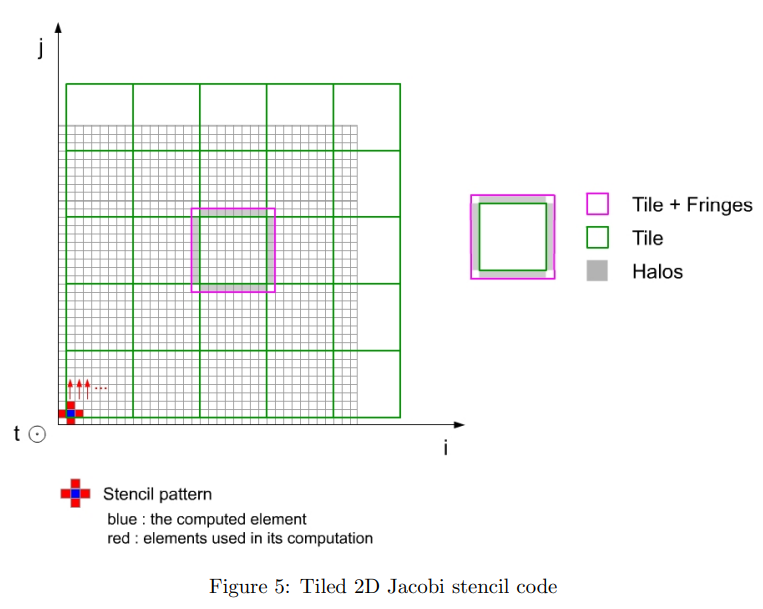
导致Embarrassingly Parallel Problems
1D 梯度计算 Stencil实例¶
计算某点的梯度,需要前后的function值。

Halo/Ghost Cells 光晕¶
问题: 对于边界上的cells,需要访问相邻区域的元素。
解决办法: 将他们也加入进当前block的SMEM
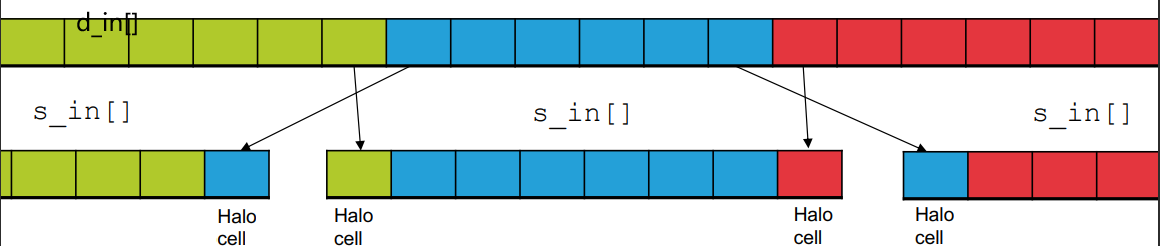
Indexing with Halo Cells¶
- Stencil问题的半径 radius (RAD) 是边缘元素需要的某方向的额外元素
- 在梯度的例子里是1
- SMEM声明的大小,需要在每个维度上都增加 2*RAD的个数
- 这导致SMEM的index的每个维度需要增加RAD.
s_idx = threadIdx.x + RAD;
code¶
int main() {
const float PI = 3.1415927;
const int N = 150;
const float h = 2 * PI / N;
float x[N] = { 0.0 };
float u[N] = { 0.0 };
float result_parallel[N] = { 0.0 };
for (int i = 0; i < N; ++i) {
x[i] = 2 * PI*i / N;
u[i] = sinf(x[i]);
}
ddParallel(result_parallel, u, N, h);
}
Kernel Launching
#define TPB 64
#define RAD 1 // radius of the stencil
…
void ddParallel(float *out, const float *in, int n, float h) {
float *d_in = 0, *d_out = 0;
cudaMalloc(&d_in, n * sizeof(float));
cudaMalloc(&d_out, n * sizeof(float));
cudaMemcpy(d_in, in, n * sizeof(float), cudaMemcpyHostToDevice);
// Set shared memory size in bytes
const size_t smemSize = (TPB + 2 * RAD) * sizeof(float);
ddKernel<<<(n + TPB - 1)/TPB, TPB, smemSize>>>(d_out, d_in, n, h);
cudaMemcpy(out, d_out, n * sizeof(float), cudaMemcpyDeviceToHost);
cudaFree(d_in);
cudaFree(d_out);
}
Kernel Definition
__global__ void ddKernel(float *d_out, const float *d_in, int size, float h) {
const int i = threadIdx.x + blockDim.x * blockIdx.x;
if (i >= size) return;
const int s_idx = threadIdx.x + RAD;
extern __shared__ float s_in[];
// Regular cells
s_in[s_idx] = d_in[i];
// Halo cells
if (threadIdx.x < RAD) {
s_in[s_idx - RAD] = d_in[i - RAD];
s_in[s_idx + blockDim.x] = d_in[i + blockDim.x];
}
__syncthreads();
d_out[i] = (s_in[s_idx-1] - 2.f*s_in[s_idx] + s_in[s_idx+1])/(h*h);
}
需要进一步的研究学习¶
暂无
遇到的问题¶
暂无
开题缘由、总结、反思、吐槽~~¶
研一下USTC并行计算自己的选题
参考文献¶
https://dumas.ccsd.cnrs.fr/dumas-00636254/document
https://indico.fysik.su.se/event/6743/contributions/10338/attachments/4175/4801/4.CUDA-StencilsSharedMemory-Markidis.pdf