OpenMP
线程绑定¶
OpenMP 4.0 提供 OMP_PLACES 和 OMP_PROC_BIND 环境变量来指定程序中的 OpenMP 线程如何绑定到处理器。这两个环境变量通常结合使用。OMP_PLACES 用于指定线程将绑定到的计算机位置(硬件线程、核心或插槽)。OMP_PROC_BIND 用于指定绑定策略(线程关联性策略),这项策略指定如何将线程分配到位置。
除了 OMP_PLACES 和 OMP_PROC_BIND 这两个环境变量外,OpenMP 4.0 还提供可在 parallel 指令中使用的 proc_bind 子句。proc_bind 子句用于指定如何将执行并行区域的线程组绑定到处理器。
OMP_NUM_THREADS=28 OMP_PROC_BIND=true OMP_PLACES=cores:每个线程绑定到一个 core,使用默认的分布(线程 n 绑定到 core n);
OMP_NUM_THREADS=2 OMP_PROC_BIND=true OMP_PLACES=sockets:每个线程绑定到一个 socket;
OMP_NUM_THREADS=4 OMP_PROC_BIND=close OMP_PLACES=cores:每个线程绑定到一个 core,线程在 socket 上连续分布(分别绑定到 core 0,1,2,3;
OMP_NUM_THREADS=4 OMP_PROC_BIND=spread OMP_PLACES=cores:每个线程绑定到一个 core,线程在 socket 上尽量散开分布(分别绑定到 core 0,7,14,21;
编译制导格式¶
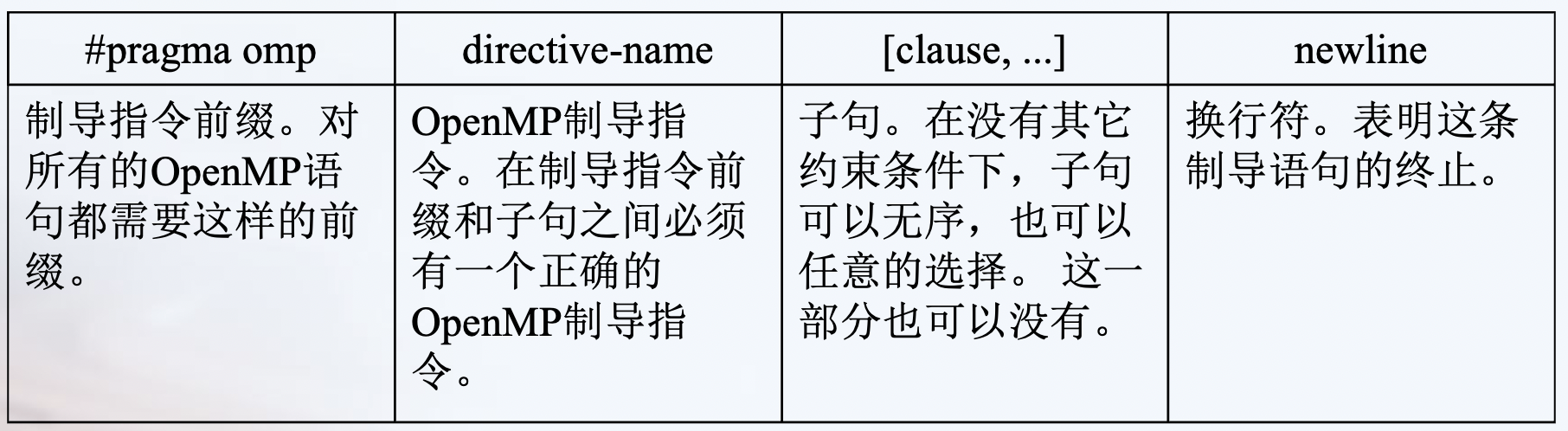
静态扩展 * 文本代码在一个编译制导语句之后,被封装到一个结构块中
孤立语句 * 一个OpenMP的编译制导语句不依赖于其它的语句
parallel¶
并行域中的代码被所有的线程执行

for¶
for语句指定紧随它的循环语句必须由线程组并行执行;

sections¶
sections编译制导语句指定内部的代码被划分给线程组中的各线程
不同的section由不同的线程执行


single¶
single编译制导语句指定内部代码只有线程组中的一个线程执行。
线程组中没有执行single语句的线程会一直等待代码块的结束,使用nowait子句除外

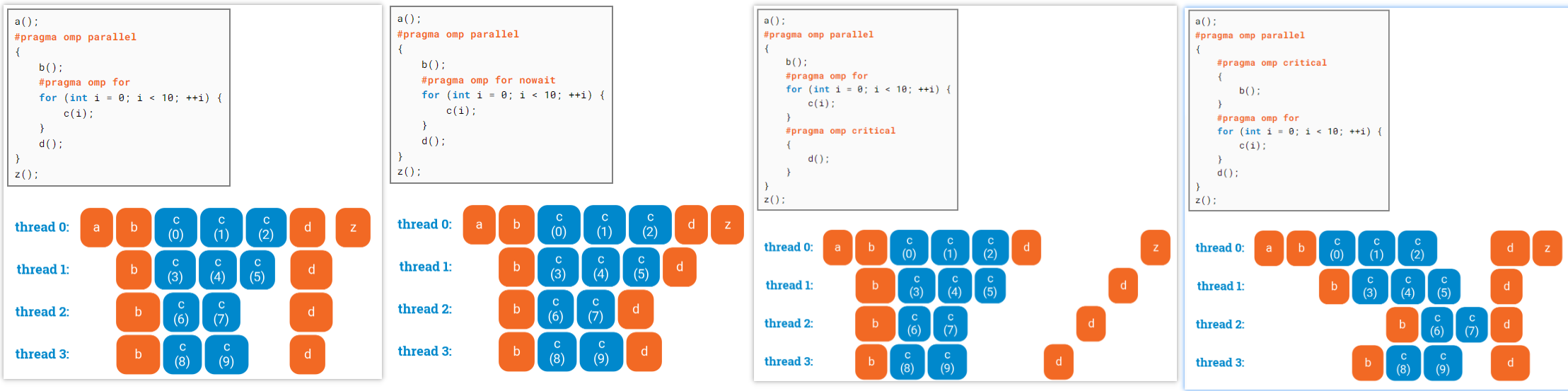
来自 https://ppc.cs.aalto.fi/ch3/nowait/
组合parallel for / parallel sections 编译制导语句¶
- Parallel for编译制导语句表明一个并行域包含一个独立的for语句
- parallel sections编译制导语句表明一个并行域包含单独的一个sections语句
同步结构¶
- master 制导语句
- 指定代码段只有主线程执行
- critical制导语句
- critical制导语句表明域中的代码一次只能执行一个线程,其他线程被阻塞在临界区
- 语句格式:
#pragma omp critical [name] newline - barrier制导语句
- 同步一个线程组中所有的线程,先到达的线程在此阻塞,等待其他线程
- atomic制导语句
- 指定特定的存储单元将被原子更新
#pragma omp atomic x++;- flush制导语句
- 标识一个同步点,用以确保所有的线程看到一致的存储器视图

- ordered制导语句
- 相对于critical,多了一个顺序
- 只能出现在for或者parallel for语句的动态范围中
- threadprivate语句使一个全局文件作用域的变量在并行域内变成每个线程私有
- 每个线程对该变量复制一份私有拷贝
critical vs atomic¶
The fastest way is neither critical nor atomic. Approximately, addition with critical section is 200 times more expensive than simple addition, atomic addition is 25 times more expensive then simple addition.(maybe no so much expensive, the atomic operation will have a few cycle overhead (synchronizing a cache line) on the cost of roughly a cycle. A critical section incurs the cost of a lock.)
The fastest option (not always applicable) is to give each thread its own counter and make reduce operation when you need total sum.
critical vs ordered¶
omp critical is for mutual exclusion(互斥), omp ordered refers to a specific loop and ensures that the region executes sequentually in the order of loop iterations. Therefore omp ordered is stronger than omp critical, but also only makes sense within a loop.
omp ordered has some other clauses, such as simd to enforce the use of a single SIMD lane only. You can also specify dependencies manually with the depend clause.
Note: Both omp critical and omp ordered regions have an implicit memory flush at the entry and the exit.
ordered example¶
vector<int> v;
#pragma omp parallel for ordered schedule(dynamic, anyChunkSizeGreaterThan1)
for (int i = 0; i < n; ++i){
...
...
...
#pragma omp ordered
v.push_back(i);
}
tid List of Timeline
iterations
0 0,1,2 ==o==o==o
1 3,4,5 ==.......o==o==o
2 6,7,8 ==..............o==o==o
= shows that the thread is executing code in parallel. o is when the thread is executing the ordered region. . is the thread being idle, waiting for its turn to execute the ordered region.
With schedule(static,1) the following would happen:
语句绑定与语句嵌套规则¶


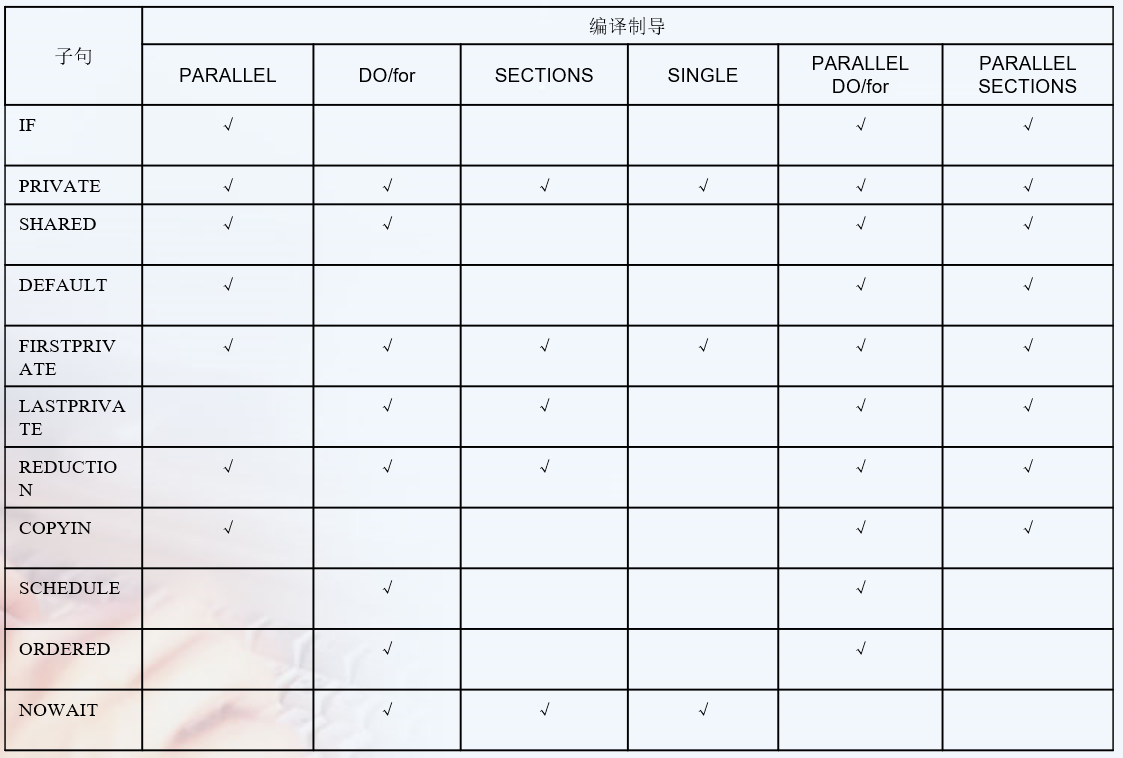
Clauses 子句¶
见 https://docs.microsoft.com/en-us/cpp/parallel/openmp/reference/openmp-clauses?view=msvc-160
#pragma omp parallel for collapse(2)
for( int y = y1; y < y2; y++ )
{
for( int x = x1; x < x2; x++ )
{
schedule¶
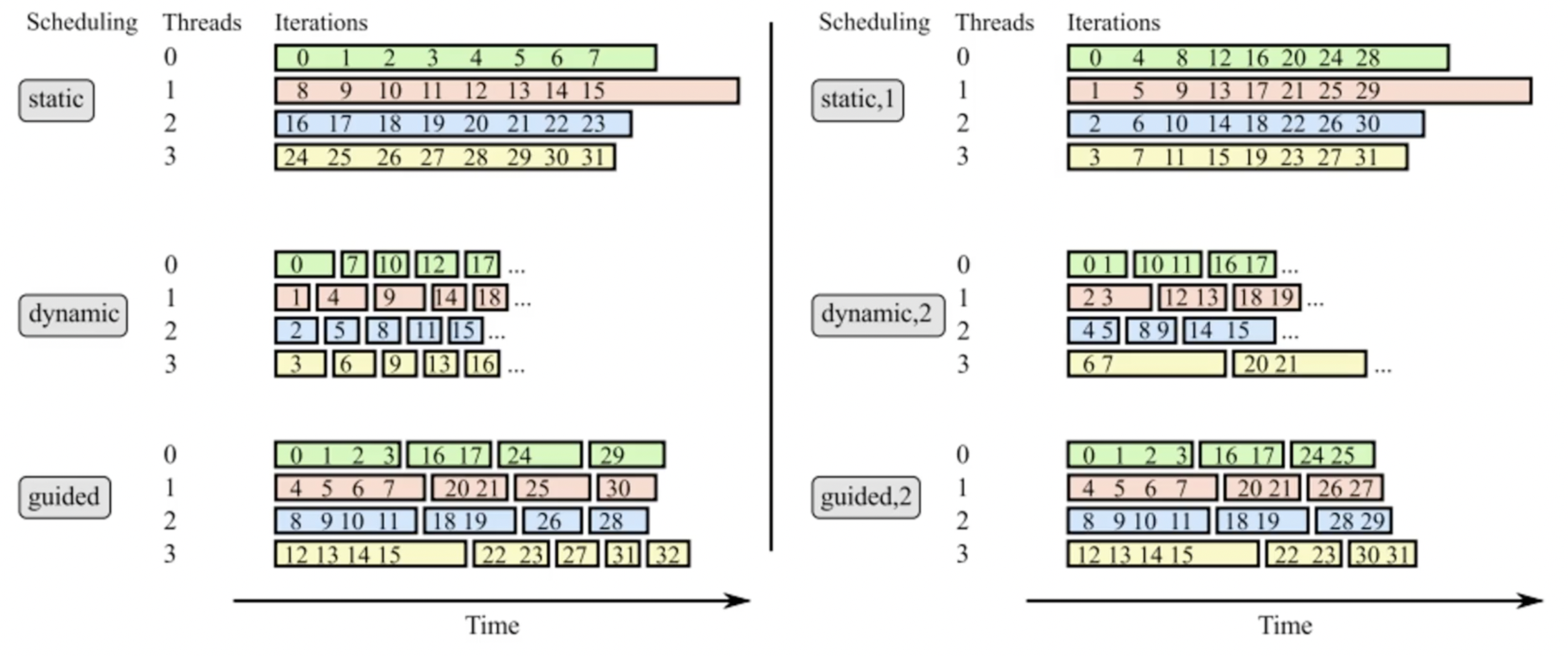
------------------------------------------------
| static | static | dynamic | dynamic | guided |
| 1 | 5 | 1 | 5 | |
------------------------------------------------
| 0 | 0 | 0 | 2 | 1 |
| 1 | 0 | 3 | 2 | 1 |
| 2 | 0 | 3 | 2 | 1 |
| 3 | 0 | 3 | 2 | 1 |
| 0 | 0 | 2 | 2 | 1 |
| 1 | 1 | 2 | 3 | 3 |
| 2 | 1 | 2 | 3 | 3 |
| 3 | 1 | 0 | 3 | 3 |
| 0 | 1 | 0 | 3 | 3 |
| 1 | 1 | 0 | 3 | 2 |
| 2 | 2 | 1 | 0 | 2 |
| 3 | 2 | 1 | 0 | 2 |
| 0 | 2 | 1 | 0 | 3 |
| 1 | 2 | 2 | 0 | 3 |
| 2 | 2 | 2 | 0 | 0 |
| 3 | 3 | 2 | 1 | 0 |
| 0 | 3 | 3 | 1 | 1 |
| 1 | 3 | 3 | 1 | 1 |
| 2 | 3 | 3 | 1 | 1 |
| 3 | 3 | 0 | 1 | 3 |
------------------------------------------------
private vs firstprivate vs lastprivate¶
private variables are not initialised, i.e. they start with random values like any other local automatic variable
firstprivate initial the value as the before value.
lastprivate save the value to the after region. 这个last的意思不是实际最后运行的一个线程,而是调度发射队列的最后一个线程。从另一个角度上说,如果你保存的值来自随机一个线程,这也是没有意义的。
firstprivate and lastprivate are just special cases of private
#pragma omp parallel
{
#pragma omp for lastprivate(i)
for (i=0; i<n-1; i++)
a[i] = b[i] + b[i+1];
}
a[i]=b[i];
private vs threadprivate¶
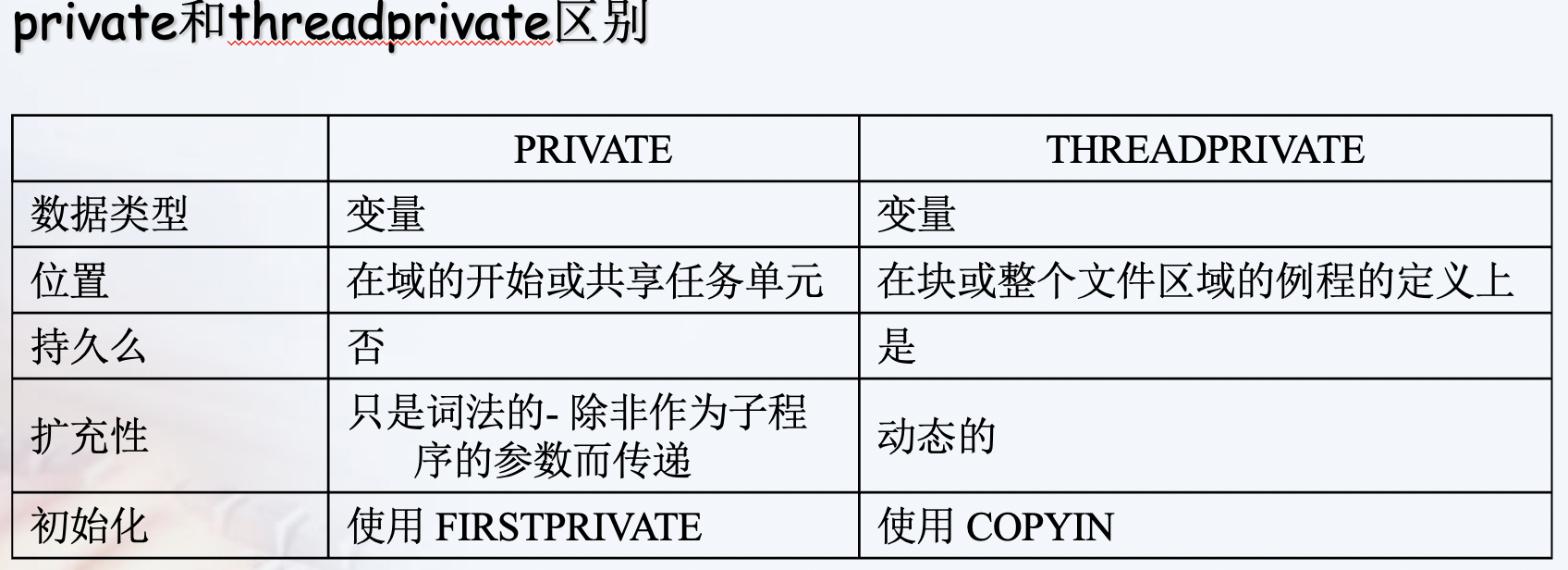
A private variable is local to a region and will most of the time be placed on the stack. The lifetime of the variable's privacy is the duration defined of the data scoping clause. Every thread (including the master thread) makes a private copy of the original variable (the new variable is no longer storage-associated with the original variable).
A threadprivate variable on the other hand will be most likely placed in the heap or in the thread local storage (that can be seen as a global memory local to a thread). A threadprivate variable persist across regions (depending on some restrictions). The master thread uses the original variable, all other threads make a private copy of the original variable (the master variable is still storage-associated with the original variable).
task 指令¶
可以指定某一task任务在指定第几个thread运行吗?
section 命令 与 for 命令的区别¶
简单理解sections其实是for的展开形式,适合于少量的“任务”,并且适合于没有迭代关系的“任务”。每一个section被一个线程去执行。
常用函数¶
omp_get_thread_num() //获取线程的num,即ID。在并行区域外,获取的是master线程的ID,即为0。
omp_get_num_threads/omp_set_num_threads() //设置/获取线程数量,用于覆盖OMP_NUM_THREADS环境变量的设置。omp_set_num_threads在串行区域调用才会有效,omp_get_num_threads获取当前线程组的线程数量,一般在并行区域调用,在串行区域调用返回为1。
omp_get_max_threads() //返回OpenMP当前环境下能创建线程的最大数量。
环境变量¶
OMP_SCHEDULE:只能用到for,parallel for中。它的值就是处理器中循环的次数
OMP_NUM_THREADS:定义执行中最大的线程数
OMP_DYNAMIC:通过设定变量值TRUE或FALSE,来确定是否动态设定并行域执行的线程数
OMP_NESTED:确定是否可以并行嵌套
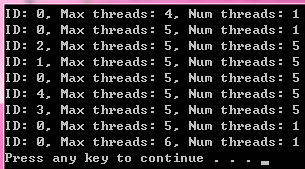
例子¶
#include <omp.h>
int main(int argc, _TCHAR* argv[])
{
printf("ID: %d, Max threads: %d, Num threads: %d \n",omp_get_thread_num(), omp_get_max_threads(), omp_get_num_threads());
omp_set_num_threads(5);
printf("ID: %d, Max threads: %d, Num threads: %d \n",omp_get_thread_num(), omp_get_max_threads(), omp_get_num_threads());
#pragma omp parallel num_threads(5)
{
// omp_set_num_threads(6); // Do not call it in parallel region
printf("ID: %d, Max threads: %d, Num threads: %d \n",omp_get_thread_num(), omp_get_max_threads(), omp_get_num_threads());
}
printf("ID: %d, Max threads: %d, Num threads: %d \n",omp_get_thread_num(), omp_get_max_threads(), omp_get_num_threads());
omp_set_num_threads(6);
printf("ID: %d, Max threads: %d, Num threads: %d \n",omp_get_thread_num(), omp_get_max_threads(), omp_get_num_threads());
return 0;
}
OpenMP和pthread是常见的模型¶
♦OpenMP为循环级并行提供了方便的功能。线程由编译器根据用户指令创建和管理。
♦pthread提供了更复杂、更动态的方法。线程由用户显式创建和管理。
需要进一步的研究学习¶
暂无
遇到的问题¶
暂无
开题缘由、总结、反思、吐槽~~¶
对子句和制导的关系不清楚
参考文献¶
https://blog.csdn.net/gengshenghong/article/details/7004594
https://docs.microsoft.com/en-us/cpp/parallel/openmp/reference/openmp-clauses?view=msvc-160