IPCC Preliminary SLIC Optimization 1
第一部分优化¶
从数据重用(不重复计算,降低计算量)、计算融合(减少访存次数)、循环重组、改变数据结构入手
数据重用¶
主体变量数据依赖梳理¶
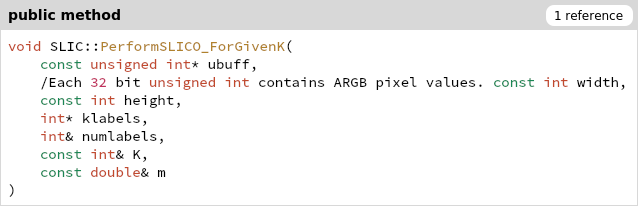 一开始所有的RGB颜色在ubuff里,klabel存分类结果
一开始所有的RGB颜色在ubuff里,klabel存分类结果
首先经过转换,将ubuff的RGB转换为lvec avec bvec三个double[sz]数组 存在私有变量m_lvec m_avec m_bvec,供class内访问
优化建议:lab三种颜色存在一起,访问缓存连续
DoRGBtoLABConversion(ubuff, m_lvec, m_avec, m_bvec);
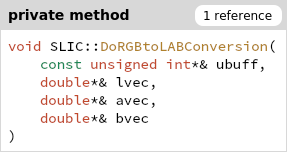
计算冗余一:
 计算出的全体edges,只有一部分在后面一个地方用了196个中心以及周围8个节点。
计算出的全体edges,只有一部分在后面一个地方用了196个中心以及周围8个节点。
优化建议:要用edges时再计算(保证了去除不必要计算和计算融合)

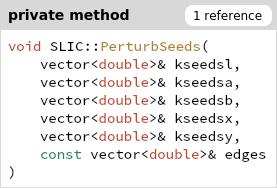
优化建议:kseedsl/a/b/x/y 分别用5个vector存是不好的,每个中心的5元组要存在一起,因为访问和修改都是一起的。
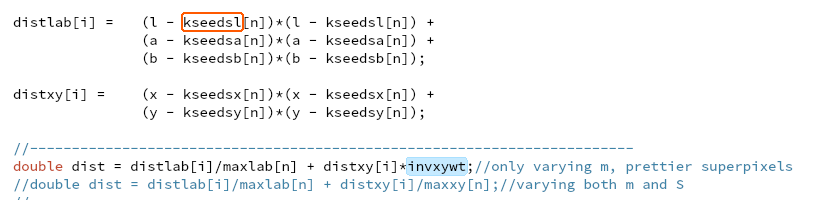
优化建议: 1. 核心计算,是不是要拆开? 2. 除以maxlab[n],改成乘1/maxlab[n] 3. maxxy没有用,可以除去定义与数组维护(line 429) 4. disxy[i]也就可以不用数组

优化建议:
1. if判断用掩码
2. 想将与每个像素i有关的属性放在一起,但是distvec要全部初始化。那我维护char*的passcheck数组判断是否已经遍历?未遍历直接赋值,已经遍历,比较后判断是否赋值。
3. 对于2和并行化这个部分的问题:1.按照中心划分,存储每个点的距不同中心的距离,最后归约取最小。2. 并行还是按照坐标划分,判断在哪几个区域内,然后计算距离最小的)
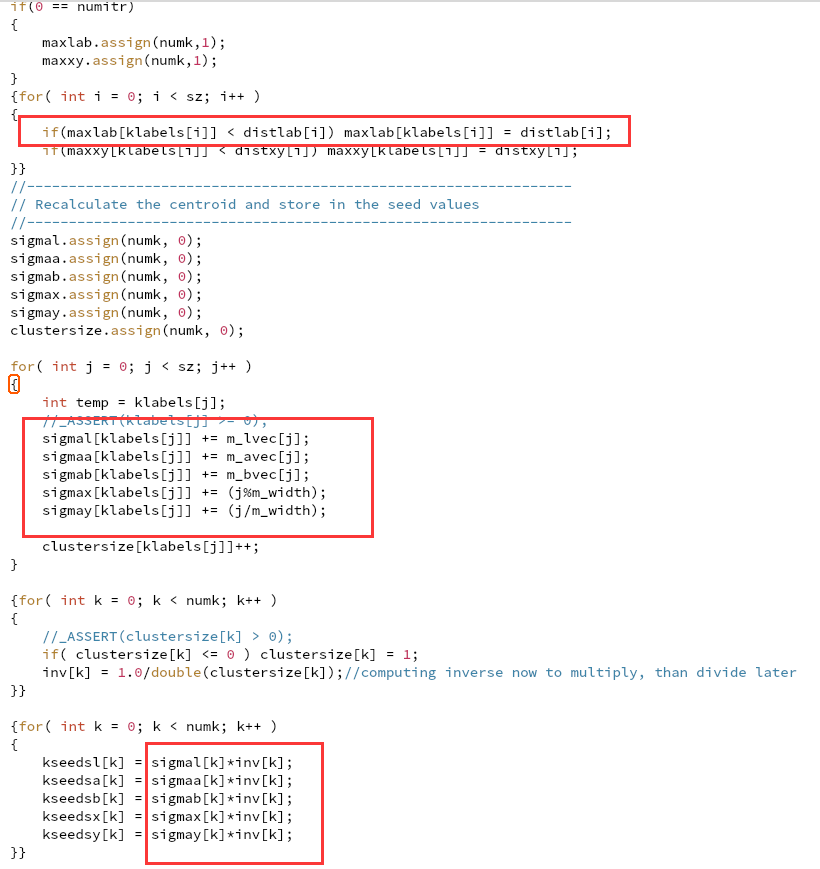
优化建议: 1. 对于求和部分labxy与1/clustersize??存在一起 2. 这部分按坐标并行时,归约的是196个元素的最小值或者求和
vector 连续性¶
vector中的元素在内存中是连续存储的.
vector的实现是由一个动态数组构成. 当空间不够的时候, 采用类似于C语言的realloc函数重新分配空间. 正是因为vector中的元素是连续存储的, 所以vector支持常数时间内完成元素的随机访问. vector中的iterator属于Random Access Iterator.
cache缓存原理疑问¶
每级cache难道只存读取数据周围的所有地址数据吗?还是一块一块读的。
假如调度是一块一块读取的而且cache足够大存下时,对于m_lvec m_avec m_bvec,假如各读取同一块,会导致和将其存储在一起是一样的效果。对于m_lvec[i]的下一个元素m_lvec[i+1],m_avec[i+1],m_bvec[i+1]也在cache中。
chivier 建议¶
#pragma omp parallel for collapse(2)
icpc -xCOMMON-AVX512 -O3 -std=c++11 -qopenmp SLIC.cpp -o SLIC
g++ -fopenmp
先openMP优化,然后MPI一分为二
数据结构没有必要改,不会访存连续
pip install gdbgui to localhost
gdb tui enable
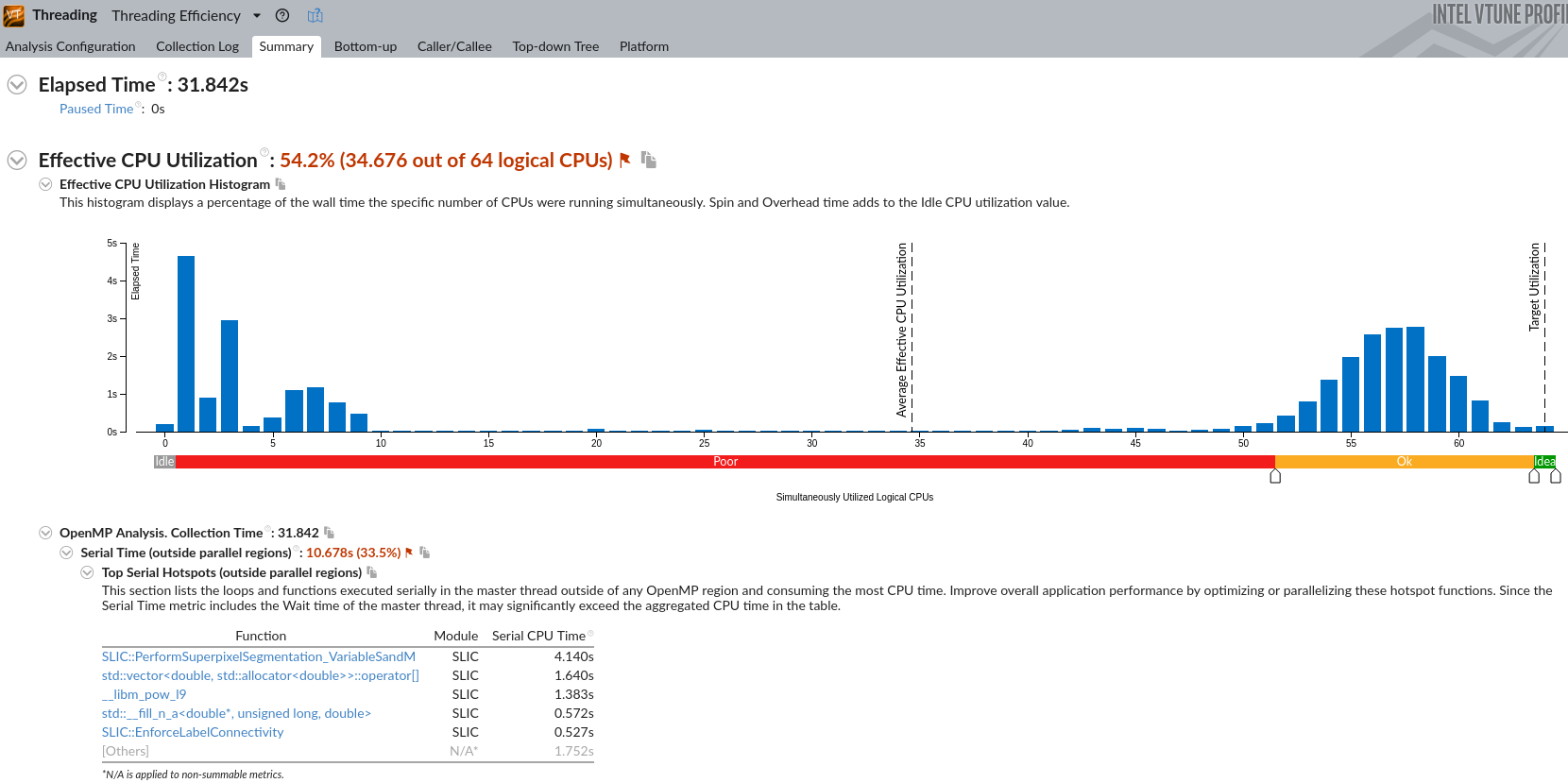
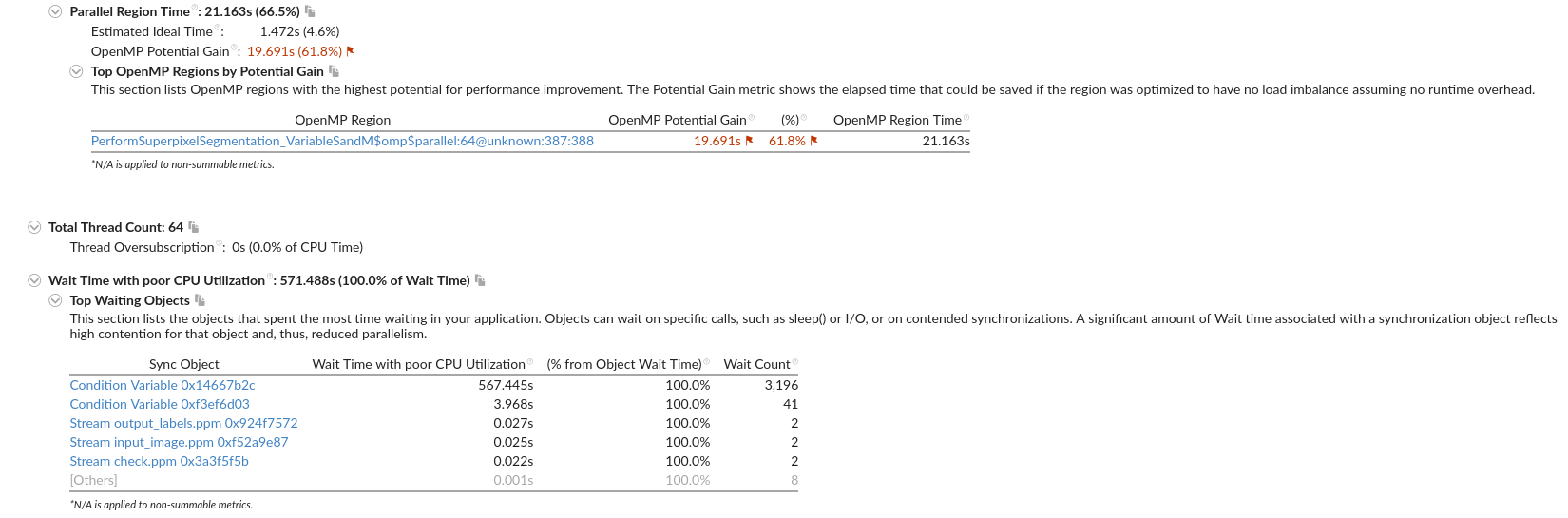
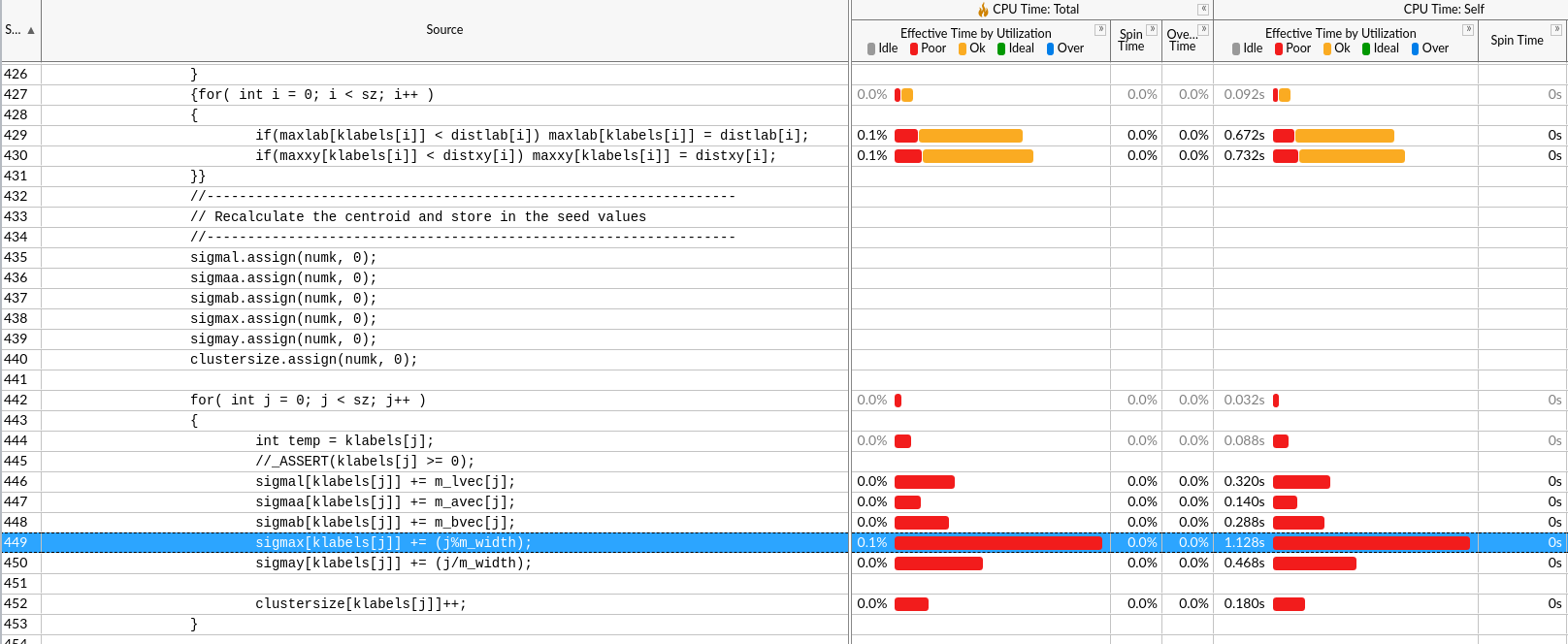
需要进一步的研究学习¶
暂无
遇到的问题¶
暂无
参考文献¶
无