IPCC Preliminary SLIC Analysis part3 : Hot spot analysis
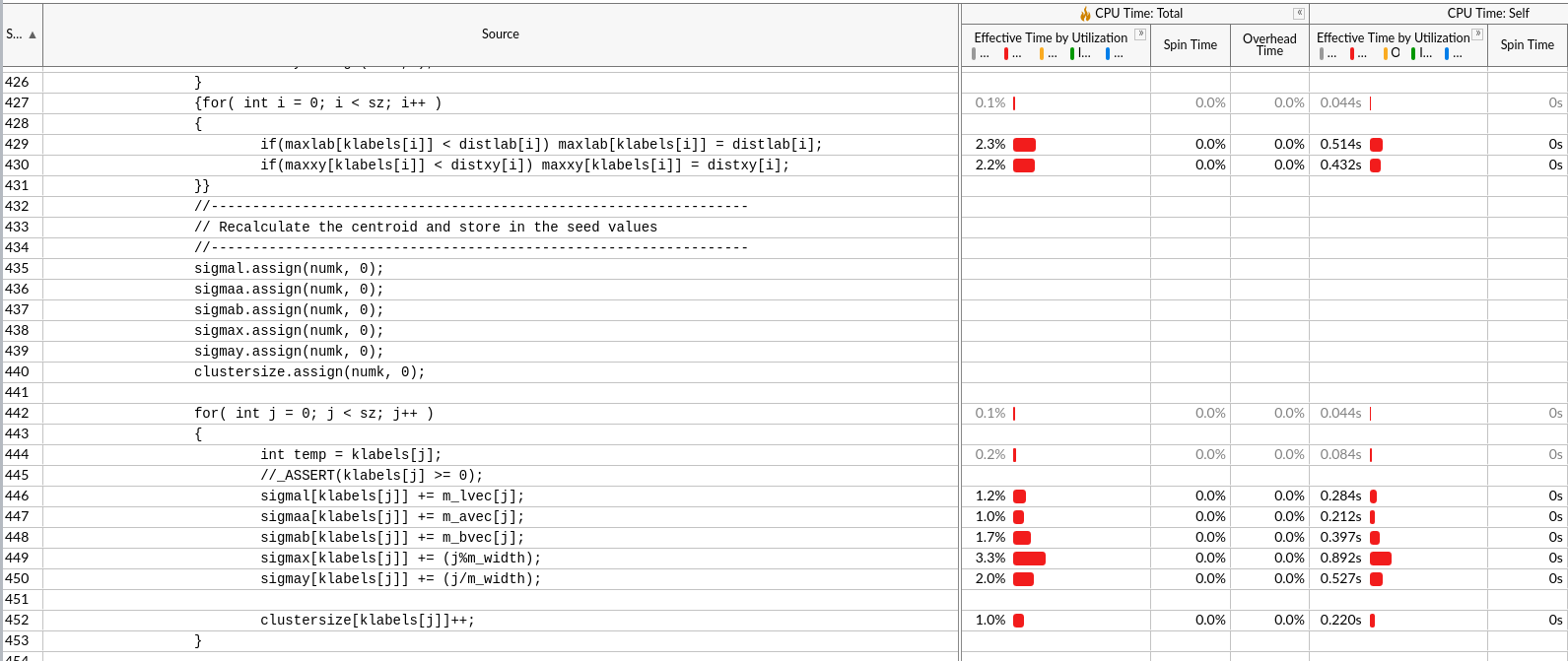
vtune hotspots¶




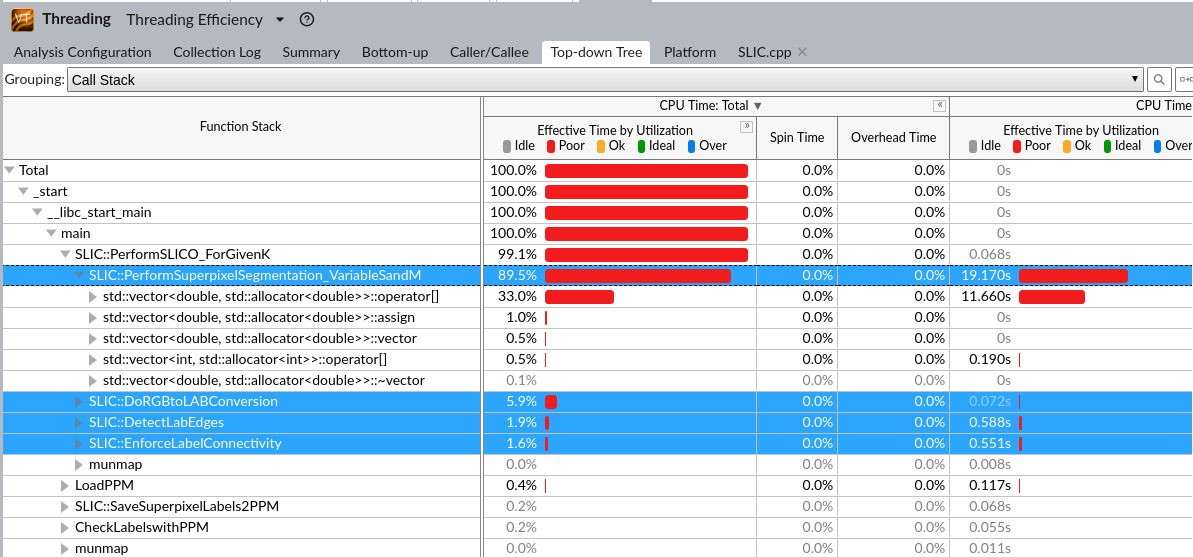
vtune threading¶


GUN profile gprof + gprof2dot graphviz¶
g++ -pg -g -std=c++11 SLIC.cpp -o SLIC
./SLIC # generate gmon.out
less gmon.out
"gmon.out" may be a binary file. See it anyway?
gprof ./SLIC
gprof ./SLIC| /home/shaojiemike/github/isc21-gpaw/LogOrResult/profile/gprof2dot.py -n0 -e0 | dot -Tpng -o output.png

 没什么用
没什么用
接下来¶
- 向量化
- 并行化
什么时候OpenMP并行,什么时候MPI并行¶
根据具体资源情况来,貌似是一个节点,那可以从OpenMP入手
自动并行化¶
Intel编译器的自动并行化功能可以自动的将串行程序的一部分转换为线程化代码。进行自动向量化主要包括的步骤有,找到有良好的工作共享(worksharing)的候选循环;对循环进行数据流(dataflow)分析,确认并行执行可以得到正确结果;使用OpenMP指令生成线程化代码。
/Qparallel:允许编译器进行自动并行化
/Qpar-reportn:n为0、1、2、3,输出自动并行化的报告
说明:/Qparallel必须在使用O2/3选项下有效
c++向量化怎么实现¶
什么是向量化¶
所谓的向量化,简单理解,就是使用高级的向量化SIMD指令(如SSE、SSE2等)优化程序,属于数据并行的范畴。
如何对代码向量化¶
向量化的目标是生成SIMD指令,那么很显然,要对代码进行向量化,
第一是依靠编译器来生成这些指令;
第二是使用汇编或Intrinsics函数。
自动向量分析器¶
Intel编译器中,利用其自动向量分析器(auto-vectorizer)对代码进行分析并生成SIMD指令。另外,也会提供一些pragmas等方式使得用户能更好的处理代码来帮助编译器进行向量化。
-
基本向量化 /Qvec:开启自动向量化功能,需要在O2以上使用。在O2以上,这是默认的向量化选项,默认开启的。此选项生成的代码能用于Intel处理器和非Intel处理器。向量化还可能受其他选项影响。由于此选项是默认开启的,所以不需要在命令行增加此选项。
-
针对指令集(处理器)的向量化 /QxHost:针对当前使用的主机处理器选择最优的指令集优化。
对于双重循环,外层循环被自动并行化了,而内层循环并没有被自动并行化,内层循环被会自动向量化。
影响向量化的因素¶
- 首先当然是指令集是否支持
- 内存对齐相关的问题,也是影响向量化的,很多的SSE指令都要求内存是16字节对齐,如果不对齐,向量化会得到错误结果。
如何判断向量化成功¶
看汇编代码 没成功需要手动内联向量化汇编代码???
Intel 编译器的向量化实现¶
AMD 编译器向量化实现¶
AMD 与 Intel 编译器的区别¶
需要进一步的研究学习¶
暂无
遇到的问题¶
暂无
参考文献¶
https://blog.csdn.net/gengshenghong/article/details/7027186
https://blog.csdn.net/gengshenghong/article/details/7034748
https://blog.csdn.net/gengshenghong/article/details/7022459