Experiments For PIM Motivation
导言
Experiments is the key to explain the desing efficiency
Address Interleaving 地址交织¶
What is Address Interleaving
类似转置存储数据来并行访问利用多DIMM访存带宽。2
一个大SOC系统,内存都不是单一的,以DDR4-3200为例,一根DIMM条的带宽是25GB,那么全芯片的总带宽200GB是8个channel交织达成的。这是为了保证最大带宽效率,以及系统在多核下的共享。以INTEL为例,多个channel的地址是按照256B为粒度交织的,即4KB的数据会拆分成16份,每个DDR channel得2份,其中为了保证系统地址更加均匀,交织还会引入更高位地址打乱,即16份中的第0份并不会固定在channel-0。
所以,每个DIMM只能拿到连续数据的一部分,并且对于交织算法的不感知,DIMM甚至无法知道自己拿到了数据的什么部分。
绝大多数的应用,都会涉及到数据的连续性,例如SORT,是不能只对部分数据进行computing的。
PIM is a fake idea?
所以,市面上的PIM都有一个潜台词是去掉interleave,但是为了表现PIM的先进性,在性能比较时,PIM都是忽略interleave,直接和一个巨大的无需交织的单个memory比较,而这样的memory并不存在。2
如果系统去掉interleave,DDR CHANNEL就需要按照核分组或者业务分组来分配channel,按照操作系统理论,实际上需要引入额外的NUMA分层,这个损失在某些业务下是很悲惨的。所以,任何PIM的方案吹嘘,如果不敢直面interleave的问题,堂堂正正讲出来其性能收益大于去掉interleave的损伤,都是骗人的。
Observation on PIM/NDP¶
page walks¶
- First, the large number of memory chips and the arbitrary distribution of page table entries make page walks involve expensive cross-chip traffic. 1
- Second, the lack of deep cache hierarchies limits the caching of page table entries close to the MPUs.
- Third, the lean nature of the MPU cores (due to the tight power and area constraints) precludes integrating expensive hardware to overlap page walks with useful work.
local and remote access latency¶
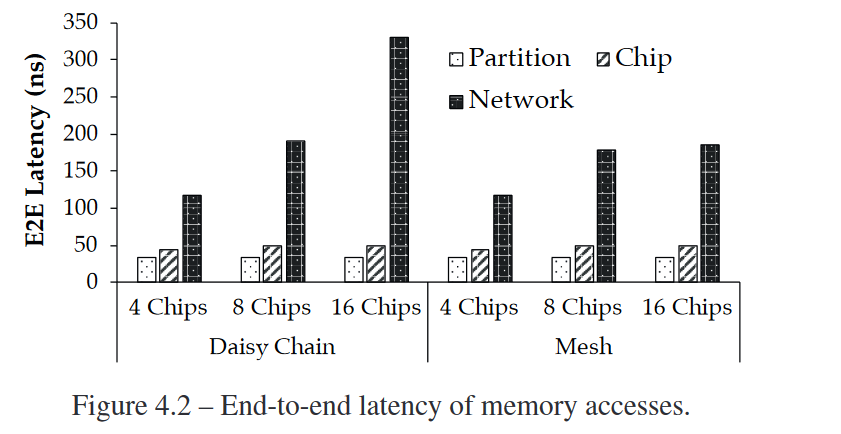
In these systems, a memory access from an MPU within its memory partition is much cheaper than accessing a remote one, as the latter involves traversing expensive NoC and cross-chip interconnects. 1
Fig. 4.2 compares the average end-to-end memory access latency depending on the target data’s location:
- same partition, (local access in same vault)
- different partition, same chip, (remote access but in same HMC chip)
- any chip in the network. (remote access but in diff HMC chip)
The three cases are labeled as Partition, Chip, and Network respectively.