IPCC2022final
学到的一些亮点¶

总结反思¶
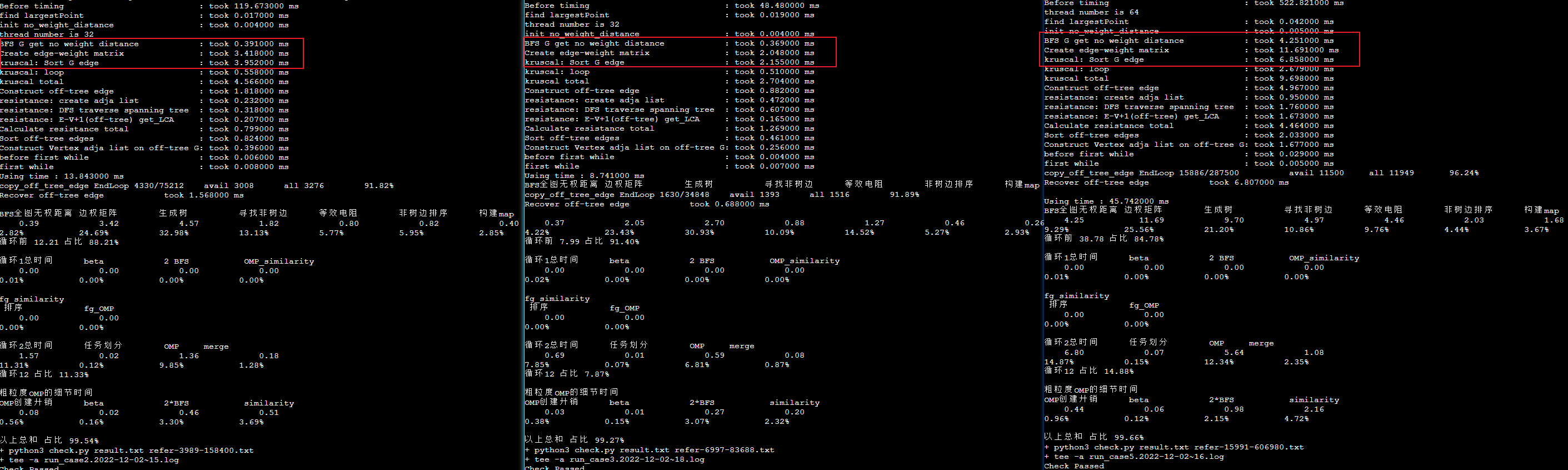
由于决赛是黑盒制度,没有排行榜,也不知道最终算分的例子是多大。我们优化着眼于自己找的清华的大例子,并行的占比在这部分很小。忽略了小例子里,占比比较高的部分的优化。结果最终赛题例子很小。
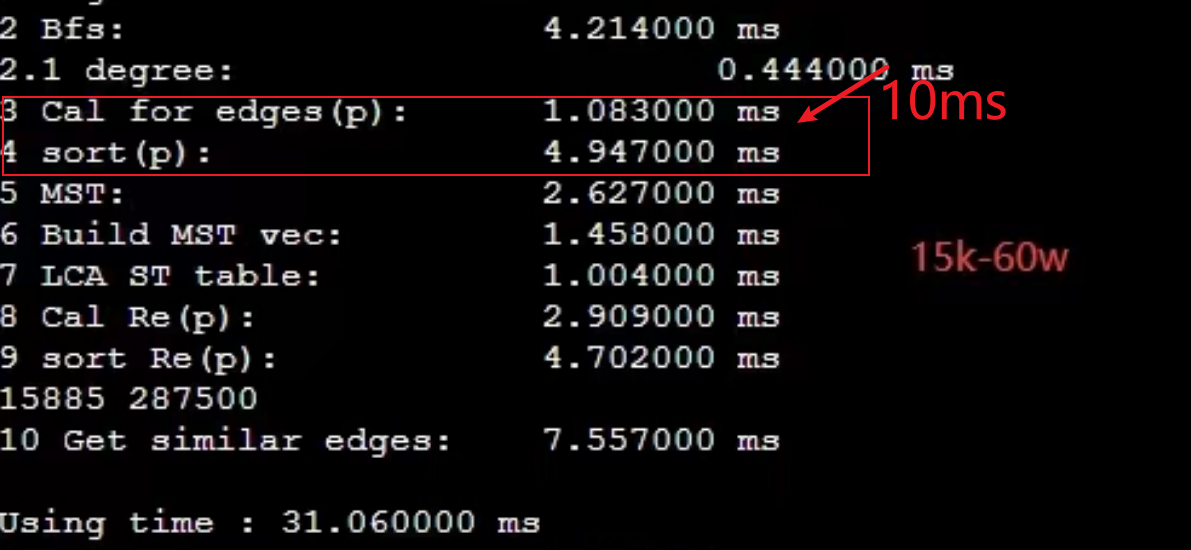
如果提前知道元素个数,并行对同一个数组的末尾添加元素可以并行,添加到指定位置之后再统一排序就行。比如山东大学,就是这里快了大约10ms,加上第一次排序快5ms。
比如信息中心(应该是第一名)的排序,用的是归并的基数排序
比如青海大学的优化: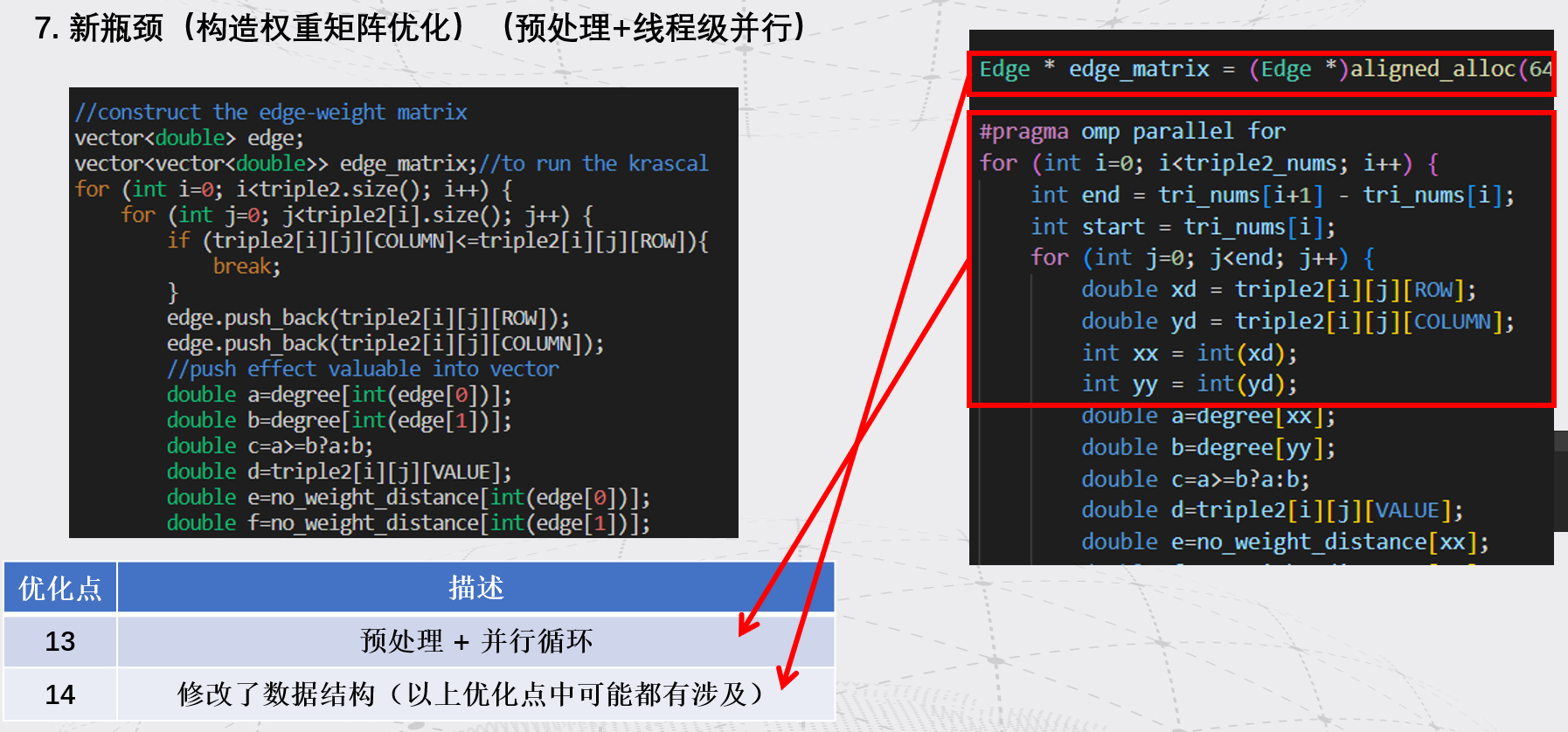
还有高效的排序,怎么实现。类似
需要进一步的研究学习¶
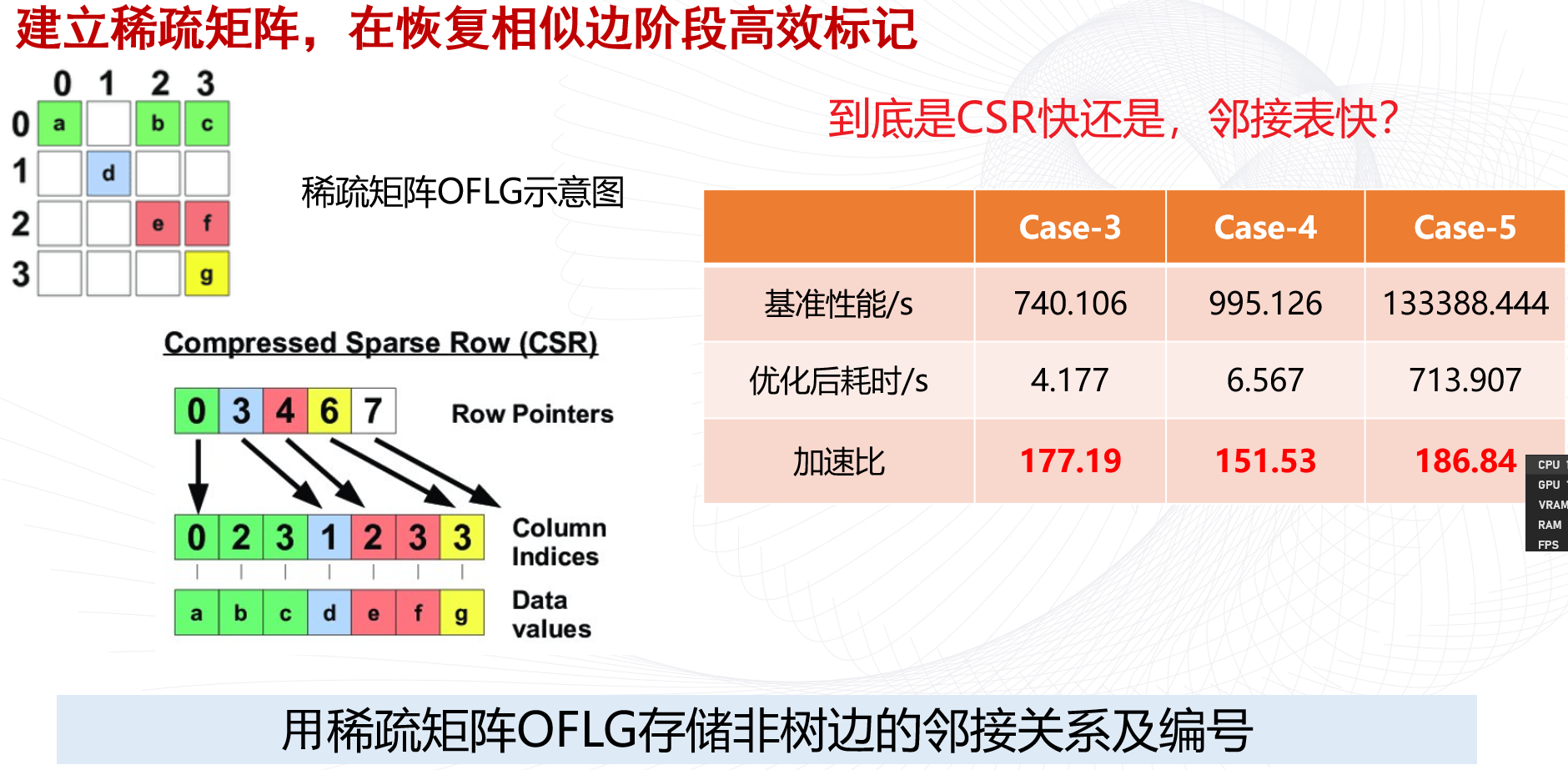
CSR (压缩稀疏行存储) 矩阵和邻接表在表示图数据结构时,计算和访问性能有些差异:
- CSR通过压缩行存储机制,可以大幅减少空间占用,节省内存。但索引算术运算负担重一些
- 邻接表使用链表指针连接相邻节点,追踪任意一条边的开销很低。但总体占用内存空间更大。
- CSR访问任意一个元素通过索引计算直接可以定位,兼具稠密和稀疏矩阵的特点。
- 邻接表的边访问性能更好,通过指针直接遍历一个节点的所有相邻节点。
- CSR的预处理时间较短,更易于向量化实现提高效率。
- 邻接表更灵活,可表示加权图或处理动态变化的图。
- CSR矩阵更易进行压缩和剪枝来优化存储,节省内存带宽。
所以简单来说,如果图更稠密,数据访问模式更随机,CSR可能会有些优势。如果需要频繁遍历边,图结构变化大,邻接表访问效率可能会更高一些。需要根据具体情况选择合适的表示。
遇到的问题¶
暂无
开题缘由、总结、反思、吐槽~~¶
哎呀,你干嘛! 今年又~西巴了~,惜败了,应该是第三名左右。
参考文献¶
无