Victima: feature extension
Victima当前的缺陷¶
至少支持两级缓存, 不支持只设置L1缓存,但是支持设置L1缓存Passthrough。
兼容性trick导致的问题
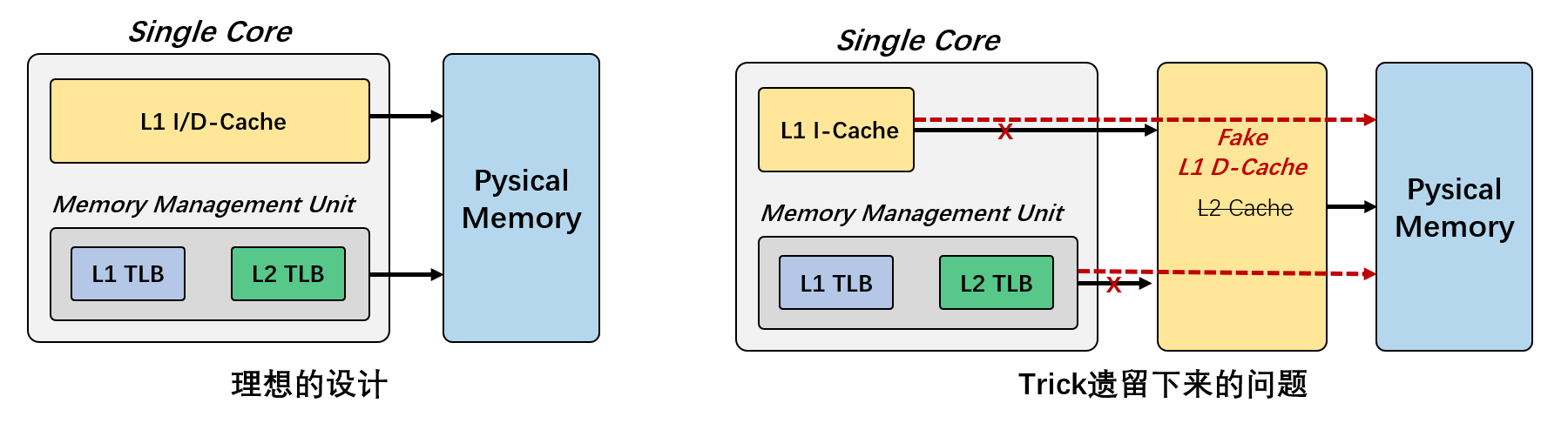
除开图中的不应该存在的数据通路
- MMU -> Fake L1
- L1 I-cache -> Fake L1 D-cache
涂布新师弟还发现了一些其他的问题:
- NUCA Cache 大小设置为1之后,还是有命中率
- metadata_passthrough 应该设置为2而不是3 ???
目标¶
支持原生的L1缓存
测试环境¶
- 可运行机器 icarus0-4、hades0-1
- 代码 https://github.com/ACSA-PIM/Victima/tree/NDP_dev
- 运行测试脚本 https://github.com/ACSA-PIM/UniNDP-virtuoso/tree/master/test-test
运行¶
Victima容器环境依赖的配置与启动¶
选择 icarus3 机器, 使用Podman测试, 直接使用docker的Dockerfile
FROM docker.io/kanell21/artifact_evaluation:victima
WORKDIR /root
RUN apt update \
&& apt install -y \
vim \
ack-grep \
htop \
tmux \
zip \
cloc \
wget \
lsb \
net-tools \
inetutils-ping \
zsh \
&& apt clean \
依次执行build和run即可
podman build -t victima .
podman run --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --rm --name=victima -it -v /staff/shaojiemike/test/Victima/src:/root victima
podman命令涉及的参数解释
这些文件展示了如何使用 podman 来构建和运行名为 "Victima" 的项目的容器。下面是具体的步骤和命令的解释:
- 构建容器镜像
脚本 build_victima_docker.sh 包含了一个用来构建容器镜像的命令:
podman build:这个命令告诉 Podman 去构建一个新的镜像。-t victima:这个参数为新创建的镜像设置一个标签,名为victima。.:表示构建上下文是当前目录,当前目录中应该包含 Dockerfile 文件。
Dockerfile 文件提供了镜像的详细配置:
- FROM kanell21/artifact_evaluation:victima:这行设定了容器的基础镜像,即 kanell21/artifact_evaluation 的 victima 标签。
- WORKDIR /root:设置容器内部的工作目录为 /root。
- RUN apt update && apt install -y ...:安装了多个软件包,如 vim、ack-grep、htop 等,并在安装后清理。
- 运行容器
脚本 run_victima_docker.sh 包含了运行容器的命令:
podman run --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --rm --name=victima -it -v /staff/tubuxin:/root victima
podman run:运行容器的命令。--cap-add=SYS_PTRACE:添加SYS_PTRACE能力,通常用于在容器内调试或追踪进程。--security-opt seccomp=unconfined:禁用 seccomp 过滤以允许所有系统调用,这对于某些调试或安全分析任务是必要的。--rm:在容器退出时自动删除容器,这有助于不留下执行后的容器实例。--name=victima:将容器实例命名为victima。-it:以交互模式运行容器,并且提供一个终端,允许你与容器的 shell 互动。-v /staff/tubuxin:/root:将主机上的/staff/tubuxin目录挂载到容器的/root目录。这意味着主机上的/staff/tubuxin目录的内容可以在容器的/root目录中访问,从而实现了主机和容器之间的数据共享。-
victima:指定使用的镜像,即之前用victima标签构建的镜像。 -
总结
要使用 podman 运行 "Victima" 项目,你需要:
1. 使用 build_victima_docker.sh 脚本构建镜像,该脚本利用 Dockerfile 中的配置。
2. 使用 run_victima_docker.sh 脚本运行容器,该脚本设置了必要的权限、名称和挂载,并启动了一个交互式的 shell 会话,在容器内可以按照 Dockerfile 和脚本设置配置的环境中工作。
Error setting up pivot dir: mkdir permission denied
奇怪的现象:即使设置了文件夹777也不行。
# shaojiemike @ icarus3 in ~/test/Victima [10:32:53]
$ ./build_victima_docker.sh
STEP 1/3: FROM docker.io/kanell21/artifact_evaluation:victima
Trying to pull docker.io/kanell21/artifact_evaluation:victima...
Getting image source signatures
Copying blob c8ebb4a49be8 done
Copying blob 64abb1f147e8 done
Copying blob b51569e7c507 done
Copying blob 58690f9b18fc done
Copying blob da8ef40b9eca done
Copying blob fb15d46c38dc done
Copying blob b5c29a874298 done
Copying blob 708575ea07ef done
Copying blob 9c6c184481fa done
Error: error creating build container: writing blob: adding layer with blob "sha256:58690f9b18fca6469a14da4e212c96849469f9b1be6661d2342a4bf01774aa50": Error processing tar file(exit status 1): Error setting up pivot dir: mkdir /staff/shaojiemike/.local/share/containers/storage/overlay/be96a3f634de79f523f07c7e4e0216c28af45eb5776e7a6238a2392f71e01069/diff/.pivot_root4140717486: permission denied
# shaojiemike @ icarus3 in ~/test/Victima [10:33:27] C:125
$ ls -ld /staff/shaojiemike/.local/share/containers
drwxrwxrwx 4 shaojiemike acsastaff 4 Apr 18 10:23 /staff/shaojiemike/.local/share/containers
解决方案:NFS和rootless-podman不兼容2,需要自己稍微修改一下~/.config/containers/storage.conf配置,因为默认会安装到~/.local/share/containers/storage的ZFS目录4。
程序的编译¶
我们使用外部挂载目录来实现文件的共享(主要是便于vscode修改)
# 下载需要的分支
git clone --branch NDP_dev --single-branch https://github.com/ACSA-PIM/Victima.git
git clone https://github.com/ACSA-PIM/UniNDP-virtuoso.git
# 编译sniper in Podman
cd Victima/sniper && make clean && make -j4
测试与运行¶
- 待测试脚本位于
UniNDP-virtuoso/tree/master/test-test,~/UniNDP-virtuoso/test-test/run_ndp.sh只需运行25s - 最短的8min的例子的trace为
/staff/tubuxin/codes/Victima/traces_small/GraphBIG_BFS_amazon0302_30M.sift
sniper=/root/Victima/sniper/run-sniper
trace=/root/Victima/traces_small/bigJump.sift
config_ndp=/root/Victima/sniper/config/UniNDP/NDP/baseline_NDP_1core_test.cfg
cd /root/UniNDP-virtuoso/test-test/NDP
$sniper -c $config_ndp --genstats --traces=$trace & pid_cpu=$!
调试与分析¶
podman容器包装,加上sniper的多进程协同。使得GDB比较麻烦。还是采用从配置参数和关键输出两方面入手来理解代码逻辑
配置分析¶
实际运行指令参数
/root/Victima/sniper/lib/sniper
-c /root/Victima/sniper/config/base.cfg
--general/total_cores=1
--general/output_dir=/root/UniNDP-virtuoso/test-test/NDP
--config=/root/Victima/sniper/config/nehalem.cfg
--config=/root/Victima/sniper/config/utopia_motivation_baseline.cfg
--config=/root/Victima/sniper/config/virtual_memory_configs/common_translation.cfg
--config=/root/Victima/sniper/config/UniNDP/configs/UniNDP_baseline_NDP_cuckoo.cfg
--config=/root/Victima/sniper/config/UniNDP/NDP/baseline_NDP_1core_test.cfg
-g --traceinput/mirror_output=true
-g --traceinput/stop_with_first_app=true
-g --traceinput/restart_apps=false
-g --traceinput/enabled=true
-g --traceinput/emulate_syscalls=false
-g --traceinput/num_apps=1
-g --traceinput/thread_0=/root/Victima/traces_small/bigJump.sift
实际运行指令输入了6个config文件。从sim.cfg寻找cache相关参数
在/staff/shaojiemike/test/Victima/src/Victima/sniper/config/UniNDP/configs/UniNDP_baseline_NDP_cuckoo.cfg中被找到。
设置 levels = 1 无法运行
0 [14326] [ ] [cache_cntlr.cc : 182] *ERROR* Cache pass-through not supported on last-level cache
代码位于Victima/sniper/common/core/memory_subsystem/parametric_dram_directory_msi/cache_cntlr.cc文件的CacheCntlr::CacheCntlr函数。(cache_cntlr 通常是 cache controller缩写)
问题一: 设置 levels = 1 & passthrough = "false" 无法运行
Creating L1-I cache with 64 sets, 8-way associative, 64B blocksize
Initializing cache L 3
Creating L1-D cache with 64 sets, 8-way associative, 64B blocksize
[SNIPER] Internal exception: Segmentation fault. Access Address = 0x18
14355 139
inside nested try
inside try
0
[SNIPER] End
[SNIPER] Elapsed time: 2.07 seconds
------------------------------------------------------------
Segmentation fault. Access Address = 0x18
Backtrace:
cache_cntlr.cc:ParametricDramDirectoryMSI::CacheCntlr::setPrevCacheCntlrs:348
memory_manager.cc:ParametricDramDirectoryMSI::MemoryManager::MemoryManager:715 (discriminator 1)
memory_manager_base.cc:MemoryManagerBase::createMMU:18
core.cc:Core::Core:100
vector.tcc:void std::vector<Core*, std::allocator<Core*> >::emplace_back<Core*>:94 (discriminator 3)
simulator.cc:Simulator::start:158 (discriminator 15)
simulator.h:Simulator::getSingleton:46
??:??:0
??:_start:?
------------------------------------------------------------
可见运行时直接越界了。
分析报错函数调用栈
// simulator.cc:Simulator::start:158 (discriminator 15)
m_core_manager = new CoreManager();
// core.cc:Core::Core:100
m_memory_manager = MemoryManagerBase::createMMU(
Sim()->getCfg()->getString("caching_protocol/type"),
this, m_network, m_shmem_perf_model);
// memory_manager_base.cc:MemoryManagerBase::createMMU:18
MemoryManagerBase*
MemoryManagerBase::createMMU(String protocol_type,
Core* core, Network* network, ShmemPerfModel* shmem_perf_model)
{
CachingProtocol_t caching_protocol = parseProtocolType(protocol_type);
switch (caching_protocol)
{
case PARAMETRIC_DRAM_DIRECTORY_MSI:
return new ParametricDramDirectoryMSI::MemoryManager(core, network, shmem_perf_model);
case FAST_NEHALEM:
return new FastNehalem::MemoryManager(core, network, shmem_perf_model);
default:
LOG_PRINT_ERROR("Unsupported Caching Protocol (%u)", caching_protocol);
return NULL;
}
}
// memory_manager.cc:ParametricDramDirectoryMSI::MemoryManager::MemoryManager:715 (discriminator 1)
m_cache_cntlrs[MemComponent::L2_CACHE]->setPrevCacheCntlrs(prev_cache_cntlrs);
// cache_cntlr.cc:ParametricDramDirectoryMSI::CacheCntlr::setPrevCacheCntlrs:348
void
CacheCntlr::setPrevCacheCntlrs(CacheCntlrList& prev_cache_cntlrs)
{
/* Append our prev_caches list to the master one (only master nodes) */
for(CacheCntlrList::iterator it = prev_cache_cntlrs.begin(); it != prev_cache_cntlrs.end(); it++)
if ((*it)->isMasterCache())
m_master->m_prev_cache_cntlrs.push_back(*it);
#ifdef ENABLE_TRACK_SHARING_PREVCACHES
LOG_ASSERT_ERROR(m_master->m_prev_cache_cntlrs.size() <= MAX_NUM_PREVCACHES, "shared locations vector too small, increase MAX_NUM_PREVCACHES to at least %u", m_master->m_prev_cache_cntlrs.size());
#endif
}
跟踪了解相关变量的类型和定义。
// 变量创建其一 cache_cntlr.cc: CacheCntlr::CacheCntlr():118
m_master = new CacheMasterCntlr(name, core_id, cache_params.outstanding_misses);
// 函数定义
CacheMasterCntlr(String name, core_id_t core_id, UInt32 outstanding_misses)
: m_cache(NULL)
, m_prefetcher(NULL)
, m_dram_cntlr(NULL)
, m_dram_outstanding_writebacks(NULL)
, m_l1_mshr(name + ".mshr", core_id, outstanding_misses)
, m_next_level_read_bandwidth(name + ".next_read", core_id)
, m_evicting_address(0)
, m_evicting_buf(NULL)
, m_atds()
, m_prefetch_list()
, m_prefetch_next(SubsecondTime::Zero())
{}
// m_prev_cache_cntlrs的位置,
class CacheMasterCntlr
{
private:
CacheCntlrList m_prev_cache_cntlrs;
...
}
问题: m_prev_cache_cntlrs不需要初始化吗?
class CacheCntlrList : public std::vector<CacheCntlr*>
{
public:
#ifdef ENABLE_TRACK_SHARING_PREVCACHES
PrevCacheIndex find(core_id_t core_id, MemComponent::component_t mem_component);
#endif
};
就是std::vector<CacheCntlr*>,应该是不需要初始化的。
发现与修改一: m_master 未被正确的初始化,跳过未初始化的L2的相关变量的使用
经过debug测试输出,确定是m_master。为此继续探究m_master的相关逻辑。
说明是m_cache_cntlrs[MemComponent::L2_CACHE]没有初始化子元素m_master
跟踪了解相关变量的类型和定义。
// /staff/shaojiemike/test/Victima/src/Victima/sniper/common/core/memory_subsystem/parametric_dram_directory_msi/memory_manager.h
class MemoryManager : public MemoryManagerBase
{
private:
CacheCntlr* m_cache_cntlrs[MemComponent::LAST_LEVEL_CACHE + 1];
}
// 枚举类型
class MemComponent
{
public:
enum component_t
{
INVALID_MEM_COMPONENT = 0,
MIN_MEM_COMPONENT,
CORE = MIN_MEM_COMPONENT,
FIRST_LEVEL_CACHE,
L1_ICACHE = FIRST_LEVEL_CACHE,
L1_DCACHE,
L2_CACHE,
L3_CACHE,
L4_CACHE,
/* more, unnamed stuff follows.
make sure that MAX_MEM_COMPONENT < 32 as pr_l2_cache_block_info.h contains a 32-bit bitfield of these things
*/
LAST_LEVEL_CACHE = 20,
TAG_DIR,
NUCA_CACHE,
DRAM_CACHE,
DRAM,
MAX_MEM_COMPONENT = DRAM,
NUM_MEM_COMPONENTS = MAX_MEM_COMPONENT - MIN_MEM_COMPONENT + 1
};
};
可见m_cache_cntlrs是固定大小的指针数组,没有初始化之前,里面的指针指向随机的地址。那么问题变成了为什么m_cache_cntlrs[MemComponent::L2_CACHE]没有初始化就使用了。
初始化代码如下:
for(UInt32 i = MemComponent::FIRST_LEVEL_CACHE; i <= (UInt32)m_last_level_cache; ++i) {
std::cout << "Initializing cache L " << (MemComponent::component_t)i << std::endl;
CacheCntlr* cache_cntlr = new CacheCntlr(...);
m_cache_cntlrs[(MemComponent::component_t)i] = cache_cntlr;
setCacheCntlrAt(getCore()->getId(), (MemComponent::component_t)i, cache_cntlr);
}
其中变量定义m_last_level_cache = (MemComponent::component_t)(Sim()->getCfg()->getInt("perf_model/cache/levels") - 2 + MemComponent::L2_CACHE); 又MemComponent::L2_CACHE: 4、perf_model/cache/levels=1,故m_last_level_cache=3
修改一: 跳过未定义变量的使用即可。
// Link the L1 cache to the L2 cache if the L2 cache exists.
if(m_last_level_cache >= MemComponent::L2_CACHE){
CacheCntlrList prev_cache_cntlrs;
prev_cache_cntlrs.push_back(m_cache_cntlrs[MemComponent::L1_ICACHE]);
prev_cache_cntlrs.push_back(m_cache_cntlrs[MemComponent::L1_DCACHE]);
m_cache_cntlrs[MemComponent::L2_CACHE]->setPrevCacheCntlrs(prev_cache_cntlrs);
}
问题二: segfault m_next_cache_cntlr 空指针
------------------------------------------------------------
Segmentation fault. Access Address = 0x18
Backtrace:
cache_cntlr.cc:ParametricDramDirectoryMSI::CacheCntlr::getCacheBlockInfo:1592
cache_cntlr.cc:ParametricDramDirectoryMSI::CacheCntlr::operationPermissibleinCache:1524
cache_cntlr.cc:ParametricDramDirectoryMSI::CacheCntlr::processShmemReqFromPrevCache:1009
cache_cntlr.cc:ParametricDramDirectoryMSI::CacheCntlr::processMemOpFromCore:644
pagetable_walker_cuckoo.cc:ParametricDramDirectoryMSI::PageTableWalkerCuckoo::accessTable:146
subsecond_time.h:SubsecondTime::operator+=:91
subsecond_time.h:SubsecondTime::SubsecondTime:70 (discriminator 4)
memory_manager.cc:ParametricDramDirectoryMSI::MemoryManager::performAddressTranslation:968
memory_manager.cc:ParametricDramDirectoryMSI::MemoryManager::coreInitiateMemoryAccess:880
core.cc:Core::initiateMemoryAccess:391
core.cc:Core::readInstructionMemory:267
subsecond_time.h:SubsecondTime::divideRounded:197
performance_model.cc:PerformanceModel::iterate:309
trace_thread.cc:TraceThread::run:919
------------------------------------------------------------
猜测二:m_next_cache_cntlr填充nullptr导致的错误
查看对应代码
SharedCacheBlockInfo* cache_block_info = getCacheBlockInfo(address);
// step 1
SharedCacheBlockInfo*
CacheCntlr::getCacheBlockInfo(IntPtr address)
{
return (SharedCacheBlockInfo*) m_master->m_cache->peekSingleLine(address);
}
// step 2,3,4
hit_where = m_next_cache_cntlr->processShmemReqFromPrevCache(eip, this, mem_op_type, ca_address, modeled, count,block_type, Prefetch::NONE, t_start, false, mem_origin);
报错相关的定义
class CacheCntlr : ::CacheCntlr
{
private:
CacheMasterCntlr* m_master;
}
class CacheMasterCntlr
{
private:
Cache* m_cache;
}
// Single line cache access at addr
CacheBlockInfo*
Cache::peekSingleLine(IntPtr addr)
{
IntPtr tag;
UInt32 set_index;
splitAddress(addr, tag, set_index);
// std::cout << "Peeking single line with address: " << addr << "and tag" << tag << std::endl;
if(m_sets[set_index]->find(tag) == NULL){
if(m_name == "L2" && metadata_passthrough_loc >2)
return m_fake_sets[0]->find(tag);
return NULL;
}
return m_sets[set_index]->find(tag);
}
class Cache : public CacheBase
{
private:
CacheSet** m_sets;
}
CacheBlockInfo*
CacheSet::find(IntPtr tag, UInt32* line_index)
{
for (SInt32 index = m_associativity-1; index >= 0; index--)
{
if (m_cache_block_info_array[index]->getTag() == tag)
{
if (line_index != NULL)
*line_index = index;
return (m_cache_block_info_array[index]);
}
}
return NULL;
}
class CacheSet
{
protected:
CacheBlockInfo** m_cache_block_info_array;
}
猜测是m_next_cache_cntlr填充nullptr导致的错误。继而思考那为什么一定要调用,或者说不设置为nullptr那应该是什么。
首先测试了正常情况的样例,发现这里是L1 I/DCACHE触发m_next_cache_cntlr。并不是有用的发现。
只能继续看调用关系
// step 5 pagetable_walker_cuckoo.cc:ParametricDramDirectoryMSI::PageTableWalkerCuckoo::accessTable:146
cache->processMemOpFromCore(...);
其中cache是class PageTableWalker的protected变量。感觉是page walk要经过访存,但是应该先应该弄清楚访存的逻辑。
与其弄清楚全部的逻辑关系。不如目标更专注局部程序的修改:野指针为什么会被使用,对应函数的作用,为什么不能注释或者跳过。
修改二: 跳过出错的函数
理清访存逻辑: 当前cache miss, 如何触发next level的数据读取
对应代码位置cache_cntlr.cc:ParametricDramDirectoryMSI::CacheCntlr::processMemOpFromCore:644~689
CacheCntlr*
CacheCntlr::lastLevelCache()
{
if (! m_last_level) {
/* Find last-level cache */
CacheCntlr* last_level = this;
while(last_level->m_next_cache_cntlr)
last_level = last_level->m_next_cache_cntlr;
m_last_level = last_level;
}
return m_last_level;
}
修改二(后续证明是错误的尝试): 使用lastLevelCache()来判断是否有next level cache。从而跳过出错的函数。
if(lastLevelCache()==this){
hit_where = HitWhere::MISS;
}else{
hit_where = m_next_cache_cntlr->processShmemReqFromPrevCache(eip, this, mem_op_type, ca_address, modeled, count,block_type, Prefetch::NONE, t_start, false, mem_origin);
}
思路是没错的,但是跳过processShmemReqFromPrevCache一整个函数是不对的,应该该函数不只是返回true/false的判断函数,在内部进行了读写的处理。应该从这个函数中拆分出子函数processMissLLC()。
问题三: 释放锁后。程序在waitForNetworkThread();结束
void
CacheCntlr::waitForNetworkThread()
{
m_user_thread_sem->wait();
}
// 定义
class CacheCntlr : ::CacheCntlr
{
private:
Semaphore* m_user_thread_sem;
}
// Semaphore
class Semaphore
{
private:
int _count;
int _numWaiting;
int _futx;
Lock _lock;
public:
Semaphore(int count);
Semaphore();
~Semaphore();
void wait();
void signal();
void broadcast();
};
// wait
void Semaphore::wait()
{
_lock.acquire();
while (_count <= 0)
{
_numWaiting ++;
_futx = 0;
_lock.release();
syscall(SYS_futex, (void*) &_futx, FUTEX_WAIT | FUTEX_PRIVATE_FLAG, 0, NULL, NULL, 0);
_lock.acquire();
_numWaiting --;
}
_count --;
_lock.release();
}
通过测试,定位到syscall(SYS_futex, (void*) &_futx, FUTEX_WAIT | FUTEX_PRIVATE_FLAG, 0, NULL, NULL, 0);执行后程序就退出了。
SYS_futex 是用于线程间通信的一种系统调用,主要在实现锁和其他同步机制时使用。这里的调用使用了 FUTEX_WAIT 和 FUTEX_PRIVATE_FLAG 选项,这表明程序在等待某个条件变成真。具体参数如下:
- _futx 是需要等待的 futex 变量的地址。
- FUTEX_WAIT | FUTEX_PRIVATE_FLAG 指定 futex 的操作方式。FUTEX_WAIT 表示等待 futex 变量变为某个值,而 FUTEX_PRIVATE_FLAG 表示这个 futex 是进程内私有的,不应跨进程共享。
- 第三个参数 0 指定了等待条件,即 _futx 变量的值必须为 0 才进行等待。
- 后面的参数分别是 NULL 表示没有超时限制,以及两个额外的 NULL 和 0 分别对应于更复杂的同步机制的设置。
调用 futex 系统调用进行等待。这里指示程序等待 _futx 变为非0。如果 _futx 是0,线程将挂起直到其他线程修改 _futx 的值。
需要检查是否有其他线程会修改 _futx 的值,特别是是否有线程会将其设置为 0,允许等待的线程继续执行。
这看上去影响到了更深层的逻辑,提醒我们审视之前修改的兼容正确性。
重新测试level=2,发现了子线程的存在,说明修改二跳过的函数不只是判断next level是否命中,至少还有启子线程的功能, 所以不能简单跳过
为此,我们需要回滚修改二,并且理解hit_where = m_next_cache_cntlr->processShmemReqFromPrevCache(eip, this, mem_op_type, ca_address, modeled, count,block_type, Prefetch::NONE, t_start, false, mem_origin);具体的作用。尤其是何处启动了子线程,以及为什么要怎么设计。
访存逻辑: processShmemReqFromPrevCache:992~1313
关于锁和多线程:ScopedLock sl(getLock()); 有局部锁的样子。暂时没找到多线程的地方。
逻辑简单来说:
- 根据访存的位置和类型更新各种计数器, total_load++, store++, hit++, miss++, 更新MSHR信息
- 如果hit,
- 如果miss,或者hit了但是cache block是独占的,
- 不是last level,就迭代这个函数到下一级cache,
- last_level有三种情况 ??? 访问访存结构里后一级。
- 处理Prefetcher
具体来说的三种情况
if (cache_block_info && cache_block_info->getCState() == CacheState::EXCLUSIVE)
// 独占的缓存更新,维护一致性的invaild其它,计算访问数据时间
else if (m_master->m_dram_cntlr)
// 存在 dram controller, 计算延迟并累加延迟
latency = accessDRAM();
getMemoryManager()->incrElapsedTime(latency,...);
else
// 初始化并且发送请求到目录,
initiateDirectoryAccess();
process-XXX-ReqToDirectory::getMemoryManager()->sendMsg(xxx);
修改三:既然m_next_cache_cntlr是nullptr,那访存逻辑为什么不从自己开始迭代
修改三:访存逻辑从自己开始迭代, 这涉及到几个问题:
- 需要修正函数内部涉及到的
m_prev_cache_cntlrs里没有自己的问题 - 函数前面对于L1的情况单独拿出来特殊处理了。所以改方法不可行。
修改四:拆分出子函数processMemAccess()来进行跳过默认存在L2的操作
至此,问题的起因和解决思路大致清楚了
- 问题: 作者为了正确处理L1 I/DCache,单独在
m_next_cache_cntlr->processShmemReqFromPrevCache()函数前处理了,然后该函数能够多次迭代自身,来处理访存层级后续的L2+Cache、和访问主存的逻辑。也就是将后续的逻辑都写在一个函数里了。问题出在这个函数至少执行一次,也就是默认有一次m_next_cache_cntlr, 也就是默认有L2 cache。 - 解决思路: 不能像前面的错误方案将该函数全部跳过,不然内存的访问逻辑也跳过了。要打散这个函数,将内存的访问逻辑单独拿出来供我们实验。
- 额外限制:要复用
accessDRAM函数,所以只能在外层修改。 - 问题:内存访问有点奇怪:
- 貌似要分初始化两种情况: 除开
CacheCntlr::accessDRAM()函数,还涉及到initiateDirectoryAccess()。 - 观察代码发现涉及到多线程交互,设计的初衷和作用还不能get到。
- 貌似要分初始化两种情况: 除开
- 问题: 按道理来说,L1数据命中就会跳过后续的L2以及内存的判断,即使L2也命中了。但是
processShmemReqFromPrevCache()会判断L2是否命中,然后还进行处理,完全不参考L1命中的情况。一部分是需要修改对应block状态setCState(CacheState::MODIFIED);,但是看代码还是进行处理(hit increase access time)。感觉是个错误。 - 问题:
m_master->m_dram_cntlr为什么是空的。即使是有L2时,也是空的,怪中怪。
// define in header
// fix the case where only L1 cache is present and acts as the LLC (Last Level Cache)
HitWhere::where_t processMemAccess(IntPtr eip, CacheCntlr* requester, Core::mem_op_t mem_op_type, IntPtr address, bool modeled, bool count,CacheBlockInfo::block_type_t block_type, Prefetch::prefetch_type_t isPrefetch, SubsecondTime t_issue, bool have_write_lock, Core::mem_origin_t mem_origin);
// add branch return logic in old function
if(lastLevelCache()==this){
hit_where = processMemAccess(eip, this, mem_op_type, ca_address, modeled, count,block_type, Prefetch::NONE, t_start, false, mem_origin);
}else{
hit_where = m_next_cache_cntlr->processShmemReqFromPrevCache(eip, this, mem_op_type, ca_address, modeled, count,block_type, Prefetch::NONE, t_start, false, mem_origin);
}
// ...
// new sub function
// fix the case where only L1 cache is present and acts as the LLC (Last Level Cache)
HitWhere::where_t
CacheCntlr::processMemAccess(IntPtr eip, CacheCntlr* requester, Core::mem_op_t mem_op_type, IntPtr address, bool modeled, bool count,CacheBlockInfo::block_type_t block_type, Prefetch::prefetch_type_t isPrefetch, SubsecondTime t_issue, bool have_write_lock, Core::mem_origin_t mem_origin)
{
// 根本没有这层cache,要直接跳过cache的部分,触发内存的访问
// skip cache count metrics
// skip cachehit condition
// Go2missHandler
// Increment shared mem perf model cycle counts
HitWhere::where_t hit_where = HitWhere::MISS;
if (modeled){
getMemoryManager()->incrElapsedTime(m_mem_component, CachePerfModel::ACCESS_CACHE_TAGS, ShmemPerfModel::_USER_THREAD);
}
if (m_master->m_dram_cntlr)
{
// weird, LLC why not have no next m_dram_cntlr
// Direct DRAM access
cache_hit = true;
if (cache_block_info)
{
// We already have the line: it must have been SHARED and this is a write (else there wouldn't have been a miss)
// Upgrade silently
cache_block_info->setCState(CacheState::MODIFIED);
hit_where = HitWhere::where_t(m_mem_component);
}
else
{
m_shmem_perf->reset(getShmemPerfModel()->getElapsedTime(ShmemPerfModel::_USER_THREAD), m_core_id);
Byte data_buf[getCacheBlockSize()];
SubsecondTime latency;
// Do the DRAM access and increment local time
boost::tie<HitWhere::where_t, SubsecondTime>(hit_where, latency) = accessDRAM(Core::READ, address, isPrefetch != Prefetch::NONE, data_buf,metadata_request);
getMemoryManager()->incrElapsedTime(latency, ShmemPerfModel::_USER_THREAD);
// Insert the line. Be sure to use SHARED/MODIFIED as appropriate (upgrades are free anyway), we don't want to have to write back clean lines
insertCacheBlock(address, mem_op_type == Core::READ ? CacheState::SHARED : CacheState::MODIFIED, data_buf, m_core_id, ShmemPerfModel::_USER_THREAD, block_type);
if (isPrefetch != Prefetch::NONE)
getCacheBlockInfo(address)->setOption(CacheBlockInfo::PREFETCH);
updateUncoreStatistics(hit_where, getShmemPerfModel()->getElapsedTime(ShmemPerfModel::_USER_THREAD));
}
}else
{
initiateDirectoryAccess(mem_op_type, address, block_type,isPrefetch != Prefetch::NONE, t_issue);
}
// TODO: tmp skip hit condition
MYLOG("returning %s", HitWhereString(hit_where));
return hit_where;
}
补全修改: 姜师兄指出要用L1代替L2, 提取出的新函数丢失了过多的代码逻辑,存在潜在的问题
为此需要在processMemAccess函数补充逻辑
- m_master->m_dram_cntlr 补全
- if (cache_block_info && cache_block_info->getCState() == CacheState::EXCLUSIVE) 把上一层的L1 cache_block_info传入,来继续执行。
完成后,完善了逻辑。但是并不能解决问题六。
问题四:segfault getCache() 涉及空指针
------------------------------------------------------------
Segmentation fault. Access Address = 0x18
Backtrace:
cache_cntlr.h:ParametricDramDirectoryMSI::CacheCntlr::getCache:390
subsecond_time.h:SubsecondTime::operator+=:91
subsecond_time.h:SubsecondTime::SubsecondTime:70 (discriminator 4)
memory_manager.cc:ParametricDramDirectoryMSI::MemoryManager::performAddressTranslation:968
memory_manager.cc:ParametricDramDirectoryMSI::MemoryManager::coreInitiateMemoryAccess:880
core.cc:Core::initiateMemoryAccess:391
core.cc:Core::readInstructionMemory:267
subsecond_time.h:SubsecondTime::divideRounded:197
performance_model.cc:PerformanceModel::iterate:309
trace_thread.cc:TraceThread::run:919
pthread_thread.cc:PthreadThread::spawnedThreadFunc:21
??:??:0
??:??:0
------------------------------------------------------------
函数堆栈的打印有错误,通过二分Print最终确定出错的函数栈如下:
TranslationResult MemoryManager::accessTLBSubsystem(){
SubsecondTime ptw_latency= ptw->init_walk(eip, address, (shadow_cache_enabled ? shadow_cache : NULL), m_cache_cntlrs[MemComponent::L1_DCACHE] , lock_signal, data_buf, data_length, modeled,count);
}
调研ptw相关的上下文
但是完全不知道代码是怎么调用的processMemOpFromCore()函数,PageTableWalker::init_walk()的内容很简单, debug后发现第一行都没有执行。
打印了函数栈之后发现找错class定义位置了,应该是子类的定义PageTableWalkerCuckoo::init_walk()。
修改五:跳过默认存在的L2相关设置
阅读函数栈,发现难以定位,因为有内联函数,借助backward理解后修改:
// skip if there is no L2 cache
if(!(cache->isFirstLevel() && cache->isLastLevel()))
mem_manager->getCache(MemComponent::component_t::L2_CACHE)->markMetadata(addr.value,CacheBlockInfo::block_type_t::PAGE_TABLE);
问题五: getSetLock() 访问m_setlocks对象越界
terminate called after throwing an instance of 'std::out_of_range'
what(): vector::_M_range_check: __n (which is 2732997632) >= this->size() (which is 0)
阅读函数栈,定位问题代码行
// Source "/root/Victima/sniper/common/core/memory_subsystem/parametric_dram_directory/cache_cntlr.cc", line 114, in at
SetLock* CacheMasterCntlr::getSetLock(IntPtr addr)
{
return &m_setlocks.at((addr >> m_log_blocksize) & (m_num_sets-1));
}
打印相关的变量的值,让人怀疑这个cache是哪一级的,是没初始化的吗?
addr: 22817599273984
m_log_blocksize: 0
m_num_sets: 0
(addr >> m_log_blocksize) & (m_num_sets-1): 2732997632
m_setlocks.size(): 0
使用getSetLock函数前,应该执行createSetLocks函数。发现在MemoryManager::MemoryManager()初始化时,唯一一处执行了
m_cache_cntlrs[(UInt32)m_last_level_cache]->createSetLocks(
getCacheBlockSize(),
num_sets,
m_core_id_master,
cache_parameters[m_last_level_cache].shared_cores
);
代码显示Victima默认存在多核共享的m_last_level_cache。在多核环境中,多个核心可能会同时访问缓存的同一集合。为了保持数据的一致性和避免竞争条件,使用锁机制是很常见的做法。createSetLocks 方法为每个缓存集创建锁。这些锁帮助同步对缓存集的访问,尤其是当多个核心尝试更新同一个缓存集中的数据时。参数包括缓存块大小、集合数、负责的核心ID和共享该级缓存的核心数。
我们之前的修改使得L1_DCache被Victima认为是m_last_level_cache, 使得其受到多核的共享锁限制,但是私有的L1应该不存在该限制。
除此之外还有疑问,为什么L1-Icache不是LLC在执行时也触发了共享的锁机制?
修改六: 解除默认的LLC的共享锁限制 以支持纯私有缓存的配置
为了实现这点,在给LLC上锁前应该判断isLLCShared()。 并且在访存逻辑执行的时候要判断是否触发多线程的锁机制,而不是遇到LLC就执行。
修改六:
// Victima/sniper/common/core/memory_subsystem/parametric_dram_directory_msi/memory_manager.cc:778
if((UInt32)m_last_level_cache > MemComponent::L1_DCACHE)
m_cache_cntlrs[(UInt32)m_last_level_cache]->createSetLocks(
getCacheBlockSize(),
num_sets,
m_core_id_master,
cache_parameters[m_last_level_cache].shared_cores
);
bool isLLCShared(void) { return ! (isFirstLevel() && isLastLevel());} // only L1 cache, so LLC must not shared
// 类似四个锁相关函数同样处理 releaseLock,acquireStackLock, releaseStackLock
void CacheCntlr::acquireLock(){
if(isLLCShared())
lastLevelCache()->m_master->getSetLock(address)->acquire_shared(m_core_id);
};
L2作为LLC不应该是shared,有待进一步分析
问题六: Could not find a request with address(0xa2e63c00)
template <class T_Req>
T_Req* ReqQueueListTemplate<T_Req>::front(IntPtr address)
{
LOG_ASSERT_ERROR(m_req_queue_list.count(address) != 0,
"Could not find a request with address(0x%x)", address);
return m_req_queue_list[address]->front();
}
CacheDirectoryWaiter* request = m_master->m_directory_waiters.front(address);
说明m_master->m_directory_waiters里竟然没有存要处理的地址,先要弄清楚初始化和存储的逻辑。为此阅读相关的定义:
CacheDirectoryWaiterMap m_directory_waiters;
typedef ReqQueueListTemplate<CacheDirectoryWaiter> CacheDirectoryWaiterMap;
template <class T_Req> class ReqQueueListTemplate
{
private:
std::map<IntPtr, std::queue<T_Req*>* > m_req_queue_list;
public:
ReqQueueListTemplate() {};
~ReqQueueListTemplate() {};
void enqueue(IntPtr address, T_Req* shmem_req);
T_Req* dequeue(IntPtr address);
T_Req* front(IntPtr address);
T_Req* back(IntPtr address);
UInt32 size(IntPtr address);
bool empty(IntPtr address);
};
template <class T_Req>
void
ReqQueueListTemplate<T_Req>::enqueue(IntPtr address, T_Req* shmem_req)
{
if (m_req_queue_list.count(address) == 0)
{
m_req_queue_list[address] = new std::queue<T_Req*>();
}
m_req_queue_list[address]->push(shmem_req);
}
为此需要寻找m_directory_waiters.enqueue(xxx,xxx),发现来自于我的修改四processMemAccess()的initiateDirectoryAccess()。因此,修改req对象的地方找到了,但是发出请求的地方在哪里呢?
打印线程ID,来区分多线程。证实了确定有多个线程同时运行。貌似一个主线程是访存的逻辑,另一个守护线程是处理模拟TCP网络的信包处理(包括访问内存的信包)
修改七: 取消或者无响应shared LLC对DRAM的消息处理
错误来自对shared LLC对来自DRAM的消息处理,有两种处理方式,一是不处理;另一种自然是一开始就不要发出处理的请求。
主线程何时发起请求,守护线程何时处理,为什么守护线程会处理不存在的请求?都需要进一步的研究。
// Victima/sniper/common/core/memory_subsystem/parametric_dram_directory_msi/memory_manager.cc:1382
m_cache_cntlrs[m_last_level_cache]->handleMsgFromDramDirectory(sender, shmem_msg);
void MemoryManagerNetworkCallback(void* obj, NetPacket packet)
{
MemoryManagerBase *mm = (MemoryManagerBase*) obj;
assert(mm != NULL);
switch (packet.type)
{
case SHARED_MEM_1:
// or add skip here
mm->handleMsgFromNetwork(packet);
break;
default:
LOG_PRINT_ERROR("Got unrecognized packet type(%u)", packet.type);
break;
}
}
为此,应该分别了解两个线程的函数栈, 以及如何了解程序从何处开始分叉出多线程,以及各个线程如何、何时实现调用enqueue修改和front的使用。
多线程的初衷与设计
为了模拟计算机对TCP信包的发送和接收,使用多线程来实现对信包的多个同时发送和接收处理的模拟。
问题: 设计的初衷是为了多线程并行来提高模拟速度吗?内存访问要通过TCP的机制吗?内存应该是有专门的数据通路的?使用信包来模拟与内存的数据交换的方式是错误的吧?
主程序从何处开始分支出多线程
Sim()->getTraceManager()->run();
void TraceManager::run()
{
start();
wait();
}
void TraceManager::start()
{
// Begin of region-of-interest when running Sniper inside Sniper
SimRoiStart();
m_monitor->spawn();
for(std::vector<TraceThread *>::iterator it = m_threads.begin(); it != m_threads.end(); ++it)
(*it)->spawn();
}
void TraceManager::Monitor::spawn()
{
m_thread = _Thread::create(this);
m_thread->run();
}
void TraceThread::spawn()
{
m__thread = _Thread::create(this);
m__thread->run();
}
第一个问题:m_threads设计了多少个。其中每个App会独占一个线程,通过newThread()配置thread并 push_back到m_threads。
void TraceManager::init()
{
for (UInt32 i = 0 ; i < m_num_apps ; i++ )
{
// passBY(" new a thread for each app simulation");
newThread(i /*app_id*/, true /*first*/, false /*init_fifo*/, false /*spawn*/, SubsecondTime::Zero(), INVALID_THREAD_ID);
}
}
thread_id_t TraceManager::newThread(app_id_t app_id, bool first, bool init_fifo, bool spawn, SubsecondTime time, thread_id_t creator_thread_id)
{
// push_back到`m_threads`
}
第二个问题: 子线程的函数入口在哪里?
void PthreadThread::run()
{
LOG_PRINT("Creating thread at func: %p, arg: %p", m_data.func, m_data.arg);
pthread_attr_t attr;
pthread_attr_init(&attr);
pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_JOINABLE);
tIC(m_data.func, m_data.arg);
pthread_create(&m_thread, &attr, spawnedThreadFunc, &m_data);
}
线程的创建使用pthread_thread.h,可见最重要的是func的定义。 继续深入
class _Thread
{
public:
typedef void (*ThreadFunc)(void*);
static _Thread *create(ThreadFunc func, void *param);
static _Thread *create(Runnable *runnable)
{
return create(Runnable::threadFunc, runnable);
}
virtual ~_Thread() { };
virtual void run() = 0;
};
__attribute__((weak)) _Thread* _Thread::create(ThreadFunc func, void *param)
{
return new PthreadThread(func, param);
}
PthreadThread::PthreadThread(ThreadFunc func, void *arg)
: m_data(func, arg)
{
}
所以重点在传入的Runnable::threadFunc是什么。根据下面的包装,其实执行的是TraceThread::run()
class Runnable
{
public:
virtual ~Runnable() { }
virtual void run() = 0;
static void threadFunc(void *vpRunnable)
{
Runnable *runnable = (Runnable*)vpRunnable;
runnable->run();
}
};
阅读TraceThread::run()的代码,可以看出模拟的主框架,围绕PerformanceModel *prfmdl,对每条指令进行处理while(have_first && m_trace.Read(next_inst))
每个应用程序对应的线程也产生了子线程
从处理处打印堆栈并研究,
------------------------------
#4 Object "/root/Victima/sniper/lib/sniper", at 0x4b1aae, in MemoryManagerNetworkCallback(void*, NetPacket)
Source "/root/Victima/sniper/common/core/memory_subsystem/memory_manager_base.cc", line 50, in MemoryManagerNetworkCallback [0x4b1aae]
47: switch (packet.type)
48: {
49: case SHARED_MEM_1:
> 50: mm->handleMsgFromNetwork(packet);
51: break;
52:
53: default:
------------------------------
------------------------------
#3 Object "/root/Victima/sniper/lib/sniper", at 0x4b9635, in ParametricDramDirectoryMSI::MemoryManager::handleMsgFromNetwork(NetPacket&)
Source "/root/Victima/sniper/common/core/memory_subsystem/parametric_dram_directory_msi/memory_manager.cc", line 1396, in handleMsgFromNetwork [0x4b9635]
1393: switch(sender_mem_component)
1394: {
1395: case MemComponent::LAST_LEVEL_CACHE:
>1396: m_dram_directory_cntlr->handleMsgFromL2Cache(sender, shmem_msg);
1397: break;
1398:
1399: case MemComponent::DRAM:
------------------------------
可以确定子子线程是处理Network的网络请求的, 堆栈的mm->handleMsgFromNetwork(packet);到handleMsgFromL2Cache可以看出。
问题:
- 子子线程是何时产生的。子子线程是被触发/何时读取信包
- 信包是如何包装和拆解的,尤其注意其中的信息:访存地址、打印flag标志位。以及如何实现多线程间的数据交换的。
回答:子子线程作为守护线程一开始就创建了,并在Byte* SmTransport::SmNode::recv()用while(true)和void Network::netPullFromTransport()使用do-while一直监控着packet的共享空间。
回答:关于信包的结构, 访存地址直接村粗,并没有类似flag的结构。
NetPacket packet(_transport->recv());
PrL1PrL2DramDirectoryMSI::ShmemMsg* shmem_msg = PrL1PrL2DramDirectoryMSI::ShmemMsg::getShmemMsg((Byte*) packet.data, &m_dummy_shmem_perf);
IntPtr address = shmem_msg->getAddress();
class ShmemMsg{
IntPtr getAddress() { return m_address; }
}
回答:使用锁访问多线程shared mem的内容
Byte* SmTransport::SmNode::recv()
{
errorBY("attempting recv -- this: %p", this);
m_lock.acquire();
while (true)
{
if (!m_queue.empty())
{
Byte *data = m_queue.front();
m_queue.pop();
m_lock.release();
LOG_PRINT("msg recv'd -- data: %p, this: %p", data, this);
return data;
}
else
{
m_cond.wait(m_lock);
}
}
}
至此,弄清楚了子子线程监控处理的逻辑。接下来需要知道,何处发射了这么多的信包请求,为什么发射这么多?是每条指令对应的吗?以及最根本的为什么会发射访存越界的请求。
体会¶
感觉Victima设计初期就没考虑只有一层cache的情况。导致各处都不支持,野指针和越界到处都是。程序的完备性有待提升。