The CUDA Execution Model
导言
The CUDA Execution Model: how the CUDA architecture handles the execution of code in parallel.
这篇将聚焦于CUDA的基础知识,基本概念,
cuda 语法逻辑¶
运行配置逻辑¶
Kernel Functions & Device Functions:详见 编程语法部分 __global__ 和 __device__ 的区别。1
依赖与同步逻辑¶
__global__函数启动后,是异步与CPU执行的。- 默认连续执行的cuda kernel function之间是有依赖关系的:前一个kernel(copy operation)完成了,下一个kernel才能开始。
- kernel function之间默认是有implicit synchronization. 但是kernel内就没有了,需要类似的
cudaDeviceSynchronize()函数实现同步。但是对性能会有极大影响,慎用。
Architecture-Agnostic Code¶
cuda 代码是设计成架构无关的,一种编程语言。
Execution Hierarchy¶
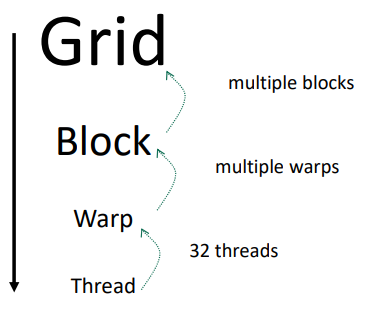
CUDA distinguishes four granularities:
- Grid (launch configuration)
- Block (cooperative threads)
- warps (implicat hardware-governed layer)
- Blocks will implicitly be split into warps.
- Groups of 32 threads, enable SIMD execution
- Thread (isolated execution state): Threads within a block can synchronize and share
Shared Memory

Logical Hierarchy Aspects: grid, block, thread¶
- Allows developers to structure their solutions for particular problem sizes
- Leaves threads with the independence to make individual decisions

Physical Hierarchy Aspects: the warp¶
- If you want to use Hardware
SIMD-width, implies that atleast 32 threadswill run.
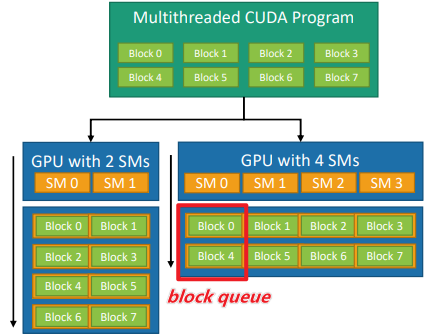
Block Execution Model : block queue¶
- Grid 里的 Blocks, 会自适应不同的GPU,调度到SM单元的block queue里 按顺序执行。
cuda Block相当于C++线程,数目可以设置比较大,调度依靠GPU,方式类似于CPU在多核系统下调度多threads. - 一个block里的warps,分配到一个SM里
- 一个block里的threads,共享一个SM里的资源(e.g.,
Shared Memory)
Warp Execution Model : warp scheduler¶
Design¶
- Warp = Threads grouped into a SIMD instruction
- From Oxford Dictionary: Warp: 在纺织工业中,“Warp 经纱”一词指的是“织机上纵向拉伸的纱线,然后由纬纱交叉”。
Detail¶
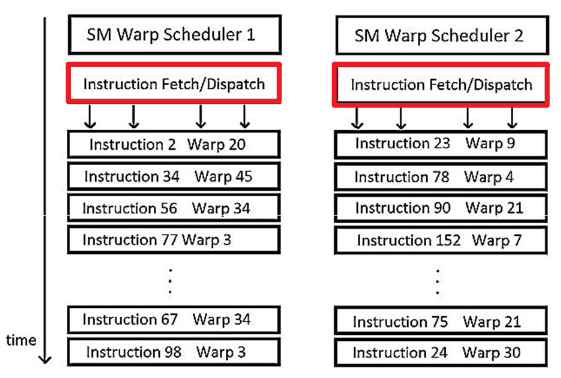
- 一旦block分配给SM,block内的warps就resident(驻留在)SM里。
- 如果warp is ready(前置依赖数据ready),warp schduler就会执行,如下图
- The SM warp schedulers will try to find ready warps, fetch instructions and dispatch them for execution.
- 最佳并行线程数:\(144 SM * 4 warpScheduler/SM * 32 Threads/warps = 18432\)
warp switch cost¶
warp switch cost in the same warp scheduler is zero. 原因主要是所需上下文是保存在寄存器里的,而不像CPU进程/线程的上下文切换可能需要访存来读取上下文信息。
- 快速上下文切换:当一个warp等待(例如,等待内存访问完成)时,SM可以快速切换到另一个warp进行计算。这种上下文切换的开销极小(0/1 cycle),因为warp的状态(寄存器等)是独立存储的。
- 隐藏延迟:通过warp切换,GPU能够隐藏延迟,特别是内存访问延迟。当一个warp因为内存访问而阻塞时,SM可以执行其他warp中的线程,这样就可以有效利用计算资源,减少闲置时间。
- 硬件调度:Warp的调度是由硬件进行的,不需要操作系统级别的上下文切换。这使得切换过程非常快速和高效。
warp scheduler = sub-core. *32?¶
subcore内的并行资源(计算和访存bank)不一定是32的倍数,来支持线程并行。resource contention会导致必然的等待。
SIMT (warp divergence)¶
SIMD 与 SIMT的关系:SIMT的线程使用warp并行处理包含了SIMD的思想
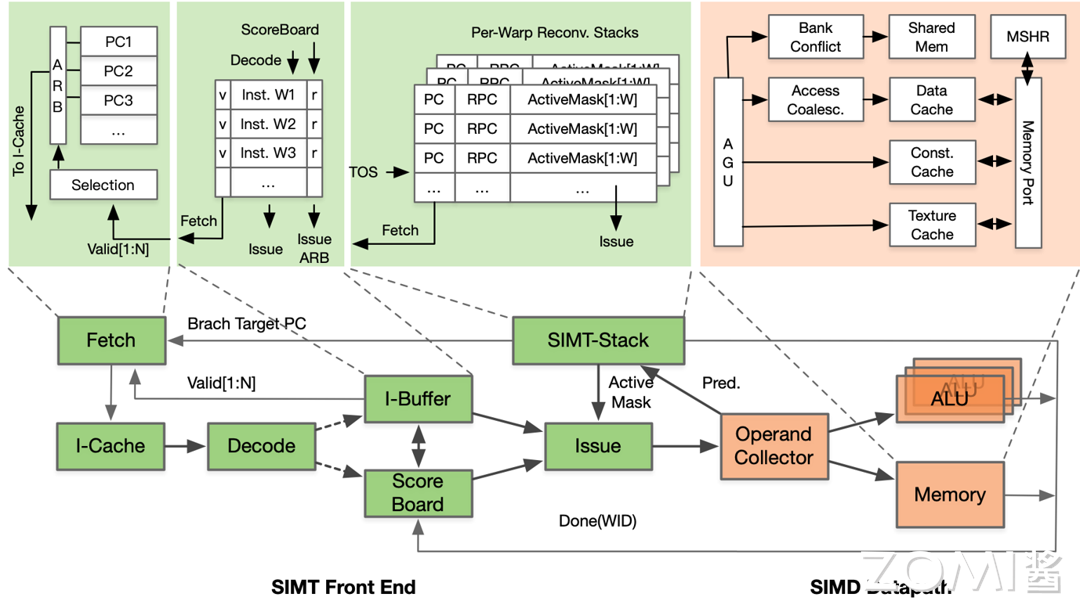
SMID虽然执行的是同一份代码,但是threadid不同,执行的代码路径是可以不同的
warp里每条指令的32个线程是SIMT而不是SIMD,有几点理由:
- 线程独立计算值:不同CPU的SIMD,warp内的线程更像cpu里并行执行的多进程但是限制了不同进程每条指令要同时执行,
- 出现的情况:通常是在cuda代码里有
if时导致执行流程分叉了:对于同一条执行,有些线程执行,但是另一些跳过了。 - 系统支持:每条指令对每个线程,有
active flag来判断是否执行。 - 受限的并行度:sub-core 里可能只有8个FP64单元,即使线程全部执行,同一时刻SIMD的并行度也只有8。而且要在这些单元上执行四遍才能处理完32个线程。
- \(One^4\) rule: One functional unit can handle one instruction, for one thread, per clock. 但是CPU unit的延迟就不是one cycle,需要流水线隐藏。
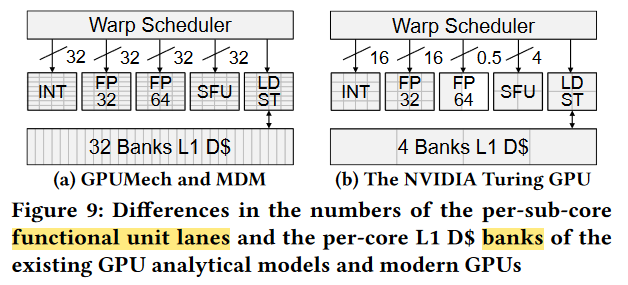
fewer than 32 of a particular type of unit
Other types of instructions will still require 32 units (eventually) but there may not be 32 of a given type of unit in the SM. When there are fewer than 32 of a particular type of unit, the warp scheduler will schedule a single instruction across multiple clock cycles.3
Suppose, for example, that a particular GPU SM design was such that there are only 4 DP units. Then the warp scheduler, when it has e.g. a DP multiply operation/instruction to issue, will use those 4 units for a total of 8 clock cycles (4x8=32) so as to provide a functional/execution unit for each instruction when considered per-thread, warp-wide.
Observation:类比CPU¶
- warp类似自带SIMT的指令
- sub-core也和CPU类似在追求提高部件利用率,但是两者还是有区别: - sub-core主要是多线程间的切换(好像也没有乱序,而是上下文切换) - CPU的乱序执行,通过计分板等实现识别出有序指令流中无依赖的指令,根据情况(乱序)打乱他们的顺序,来提高硬件利用率。
GPU vs CPU 超线程 Hyper-threading
- CPU一般最多是核数的2倍,切换时上下文开销过大。一般只在IO时。多线程有额外优势。
- GPU借助硬件的设计,线程数几乎没有上限。上下文切换开销为0,反而线程越多能能隐藏延迟

Thread Execution Model (TEM)¶
- 顺序执行(In-order program execution), 当然这不包括编译时重排打乱指令顺序。
- GPU上是没有ILP, 指令级并行的。
Volta后架构,有两种GPU线程执行模型(有编译选项来选择):
TEM1: Legacy Thread Scheduling¶
- 每个warp的线程只有一个唯一Program Counter
- 所有线程会同步执行一条指令
- 面对分支,也只能按顺序,分别执行两个branch
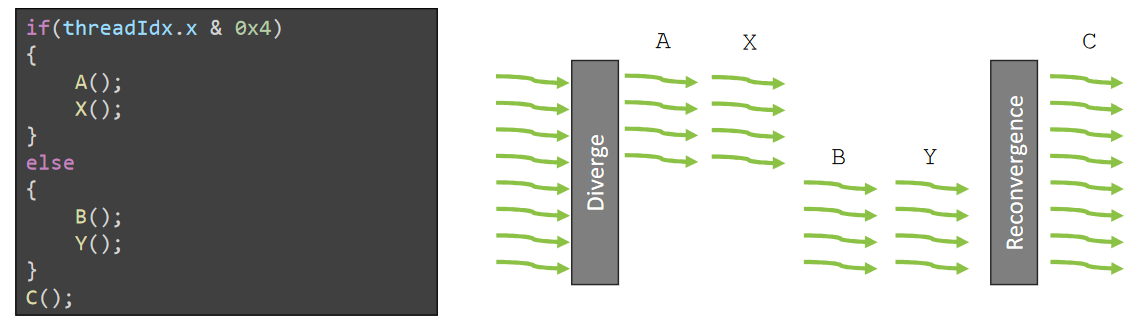
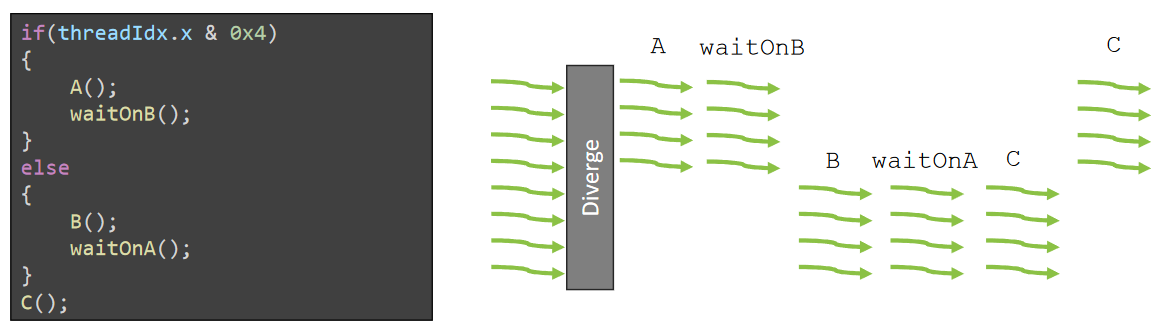
Control flow: Branch divergence
Branch divergence occurs when threads inside warps branches to different execution paths.
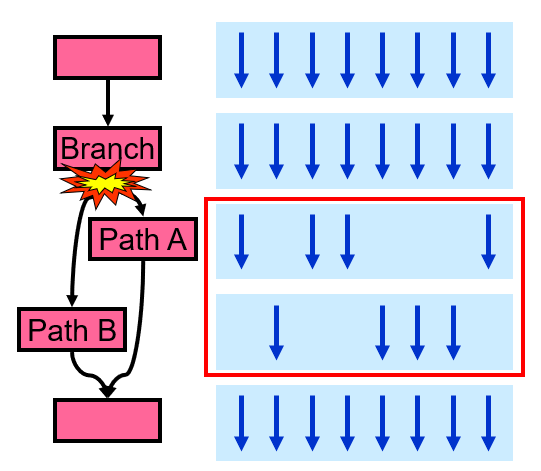
Deadlock branch
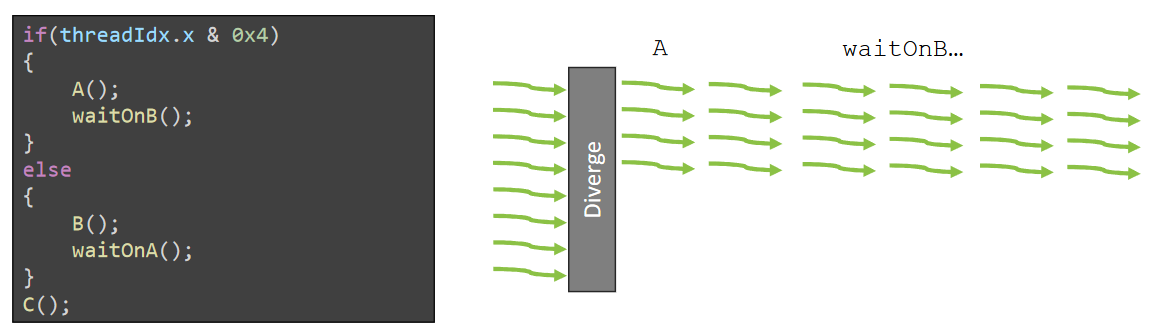
TEM2: Independent Thread Scheduling (ITS)¶
- 改变点:每个Thread都有了自己的PC, 一个warp内的线程执行的位置(下一条想执行的指令)不必再相同。
- 不变点:但是warp内线程每个cycle执行的还是同一条指令。但是warp执行的指令可以在所属线程的32个PC间跳转,这解决了前面的Deadlock。
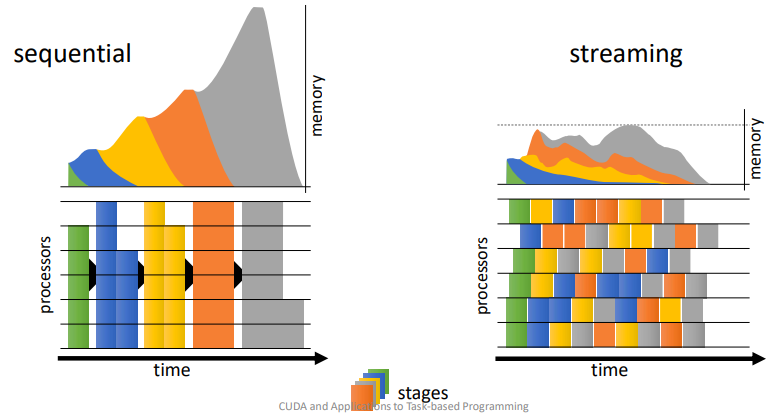
Streaming and Task-based programming¶
[^5]
Time-Sliced Kernels (Kernel by Kernel, KBK)¶
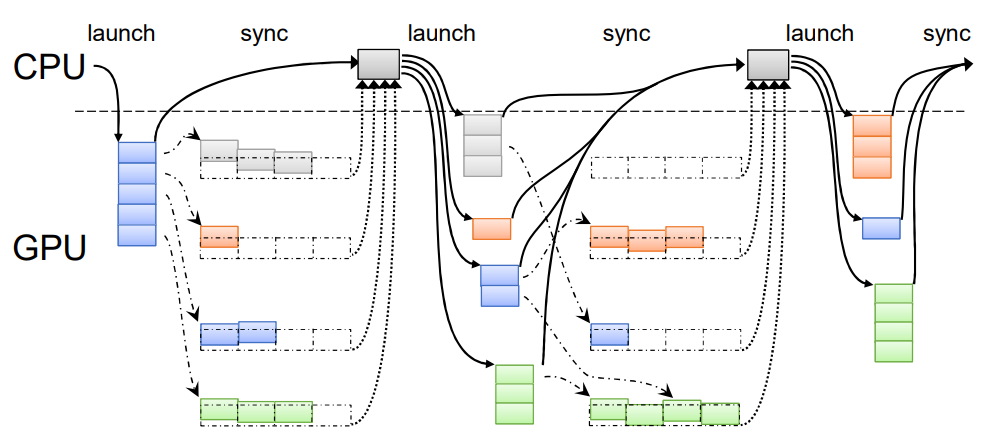
The benefits of this approach are
- There is no (added) divergence within a kernel
- This also means that we should observe optimal occupancy for each kernel
The drawbacks are
- There is need for CPU synchronization, which adds some overhead to the execution
- We cannot easily use shared memory to keep data local from one stage to the other (only within onestage, consider a stage that could generate new input for itself)
- Load imbalance might be a problem
- If one kernel runs longer than the others due to longer processing, parts of the device might beunused until the next CPU sync as no new work can be launched until the synchronizationpoint with the CPU comes up
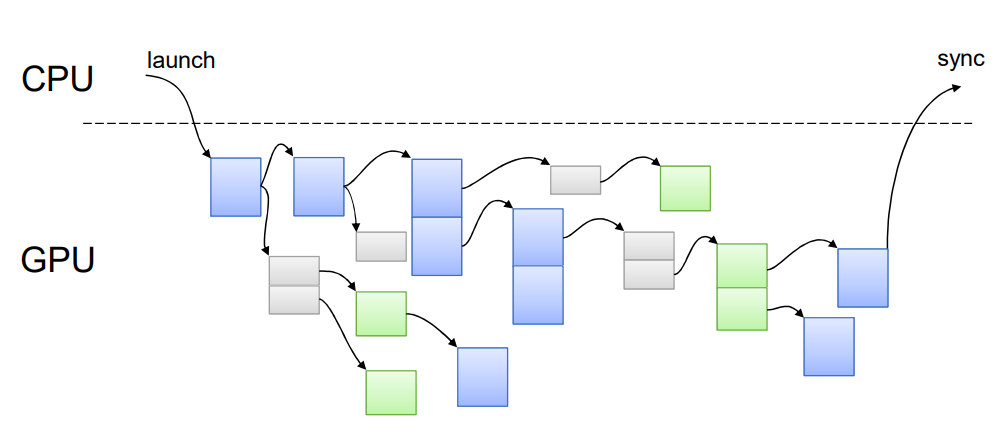
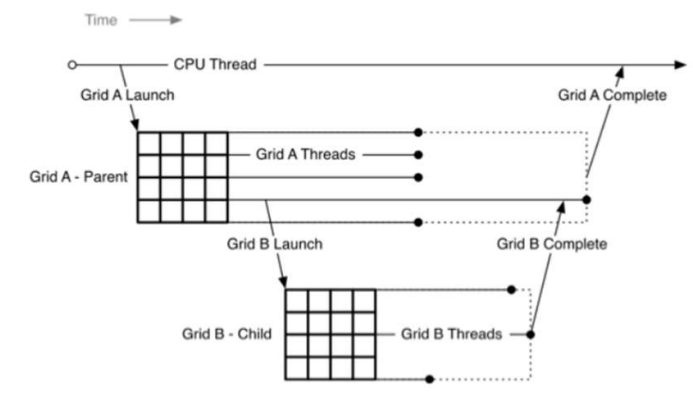
Dynamic Parallelism¶
[NVIDIA 2012]
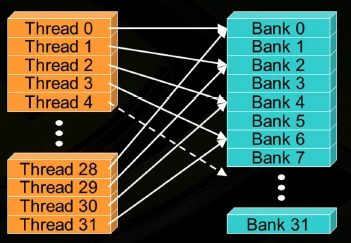
shared memory 原理¶
GPU 的共享内存,实际上是 32 块内存条通过并联组成的,每个时钟周期都可以读取一个 int。第 i 块内存,负责 addr % 32 == i 的数据。这样交错存储,可以保证随机访问时,访存能够尽量分摊到 32 个块。
如果在block内多个线程访问的地址落入到同一个bank内,那么就会访问同一个bank就会产生bank conflict,这些访问将是变成串行,在实际开发调式中非常主要bank conflict.
处理方法非常简单,我们不要把 shared memory 开辟的空间设置成 32 的倍数即可(线性同余方程,原理也很好理解)或者修改bank的size大小,默认是4字节
其中 cudaSharedMemConfi为一个枚举型:
cudaSharedMemBankSizeDefault = 0
cudaSharedMemBankSizeFourByte = 1
cudaSharedMemBankSizeEightByte = 2
只支持在host端进行调用,不支持在device端调用。 CUDA API中还支持获取bank size大小:
值得注意的是
- 多个线程同时访问同一个bank中相同的数组元素 不会产生bank conflict,将会出发广播
- 同一个 warp 的不同线程会访问到同一个 bank 的不同地址就会发生 bank conflict
容易发生bank conflit的情况¶
- 数据类型是4字节,但是不是单位步长
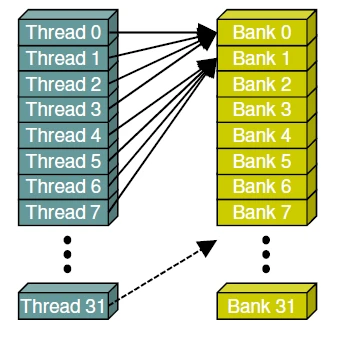
 2
2- 数据类型是1字节,步长是1。
Nvidia Design¶
NV 特殊汇编指令¶
限制的参数¶
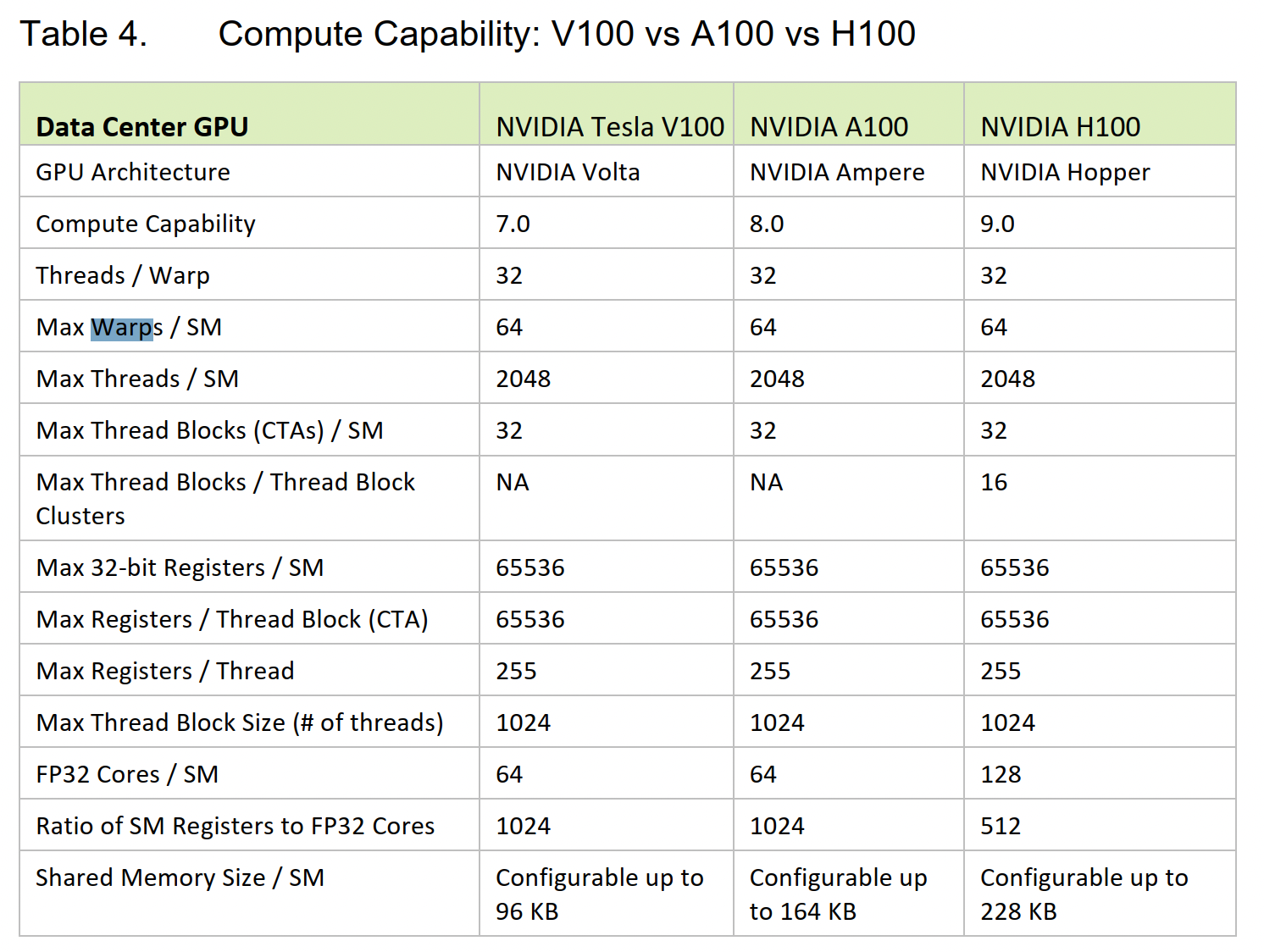
| 限制 | 具体值 |
|---|---|
| Maximum number of threads per block | 1024 |
| Maximum number of resident blocks per SM | 16/32 |
| Maximum number of resident warps per SM | 64/32 |
| Maximum number of resident threads per SM | 2048/1024 |
| Maximum number of 32-bit registers per thread | 255 |
| Maximum amount of shared memory per thread block | 48KB/96KB/64KB |
- Most recent GPUs (excepting Turing) allow a hardware limit of 64 warps per SM
一个SM最多有2048个线程
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
(30) Multiprocessors, (128) CUDA Cores/MP: 3840 CUDA Cores
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64) # 是x,y,z 各自最大值
Total amount of shared memory per block: 49152 bytes (48 Kbytes)
Total shared memory per multiprocessor(SM): 98304 bytes (96 Kbytes)
Total number of registers available per block: 65536
GP102
图中红框是一个SM, 绿点是core
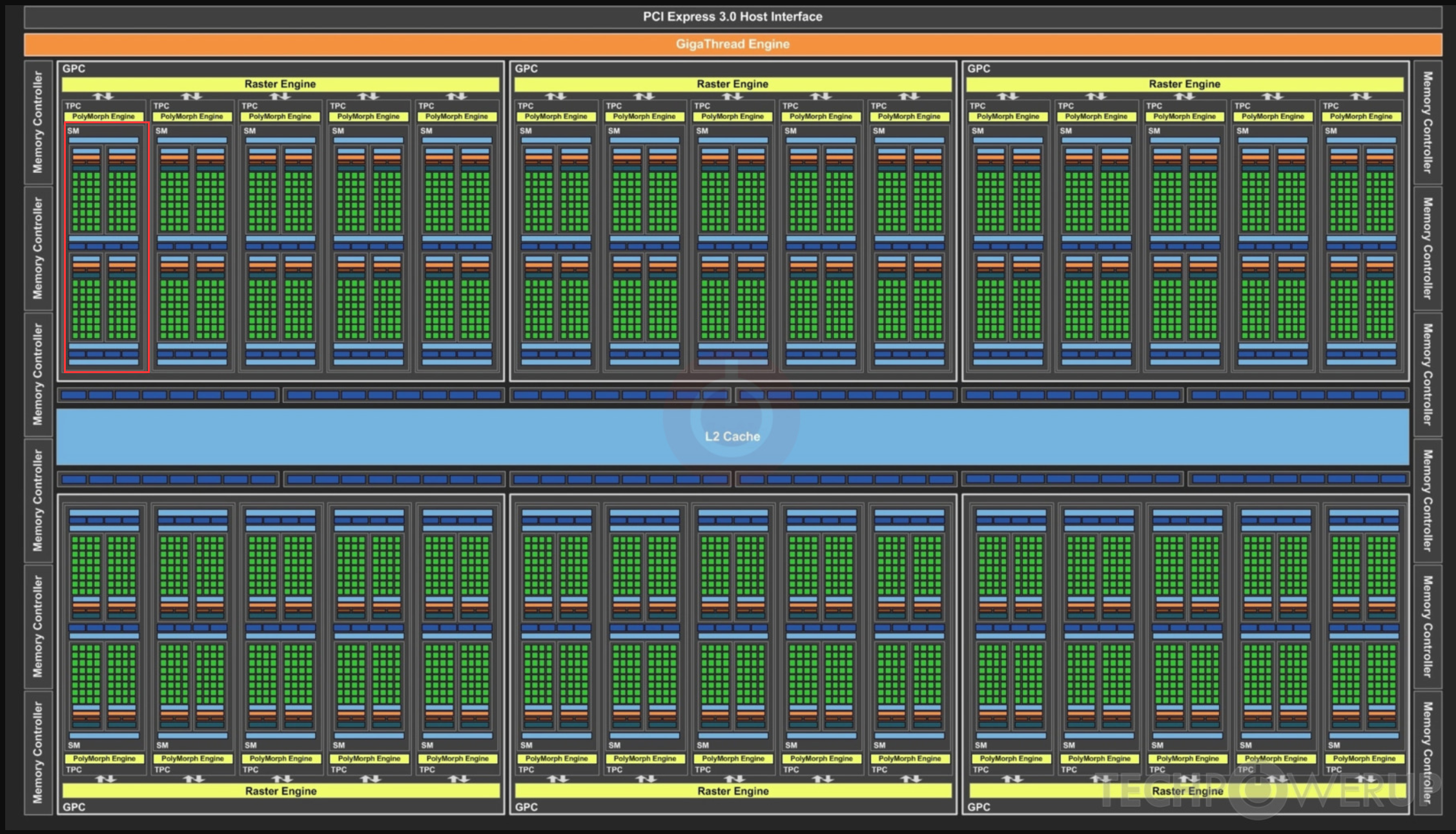
P40有30个SM,每个SM有4*32=128个核。
