Assembly Arm
关于X86 与 arm的寄存器的区别写在了arm那篇下
arm
https://developer.arm.com/documentation/dui0068/b/CIHEDHIF
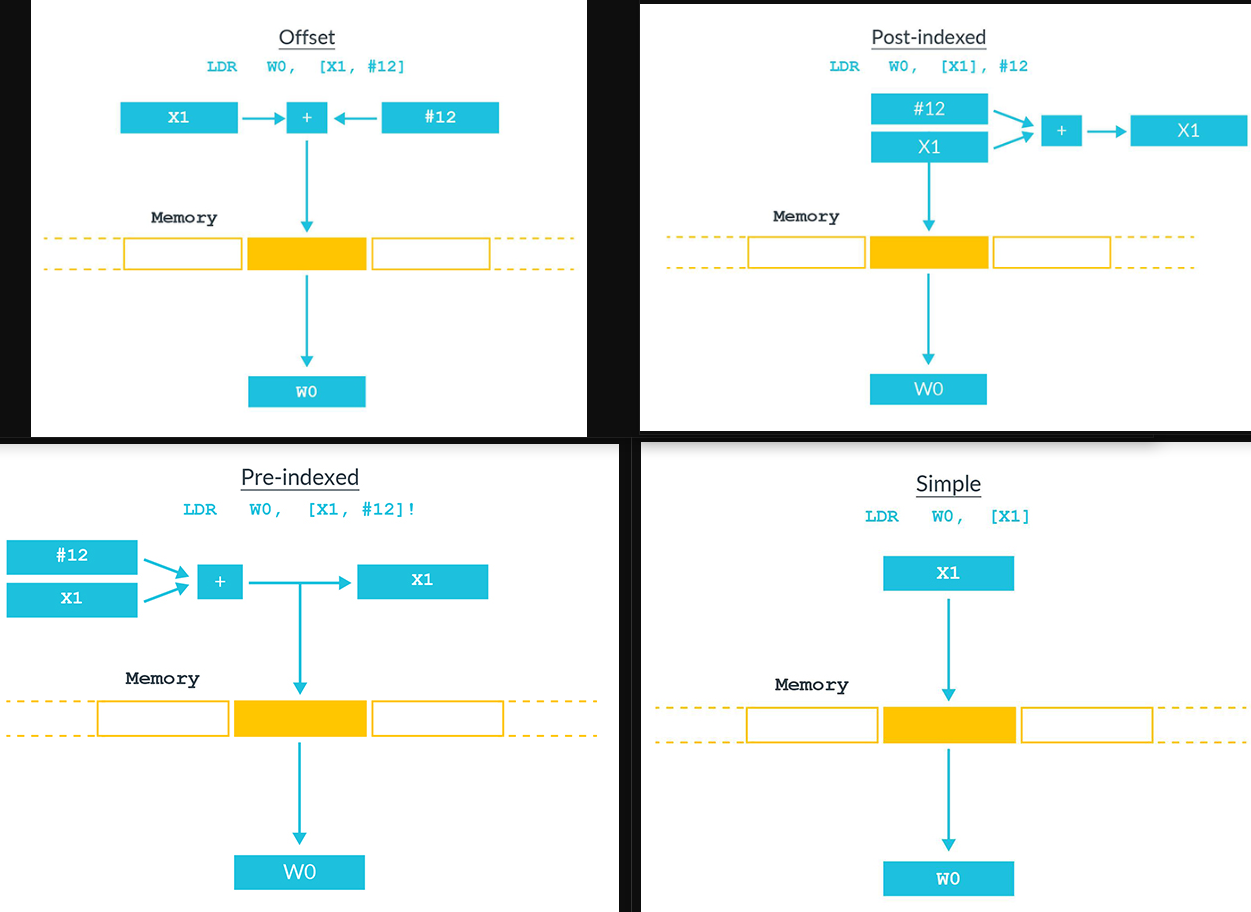
Arm 的四种寻址方式

Aarch64
Arm A64 Instruction Set Architecture https://modexp.wordpress.com/2018/10/30/arm64-assembly/
直接阅读文档 Arm® A64 Instruction Set Architecture Armv8, for Armv8-A architecture profile最有效
指令后缀说明
read from ARMv8 Instruction Set Overview 4.2 Instruction Mnemonics
The container is one of:
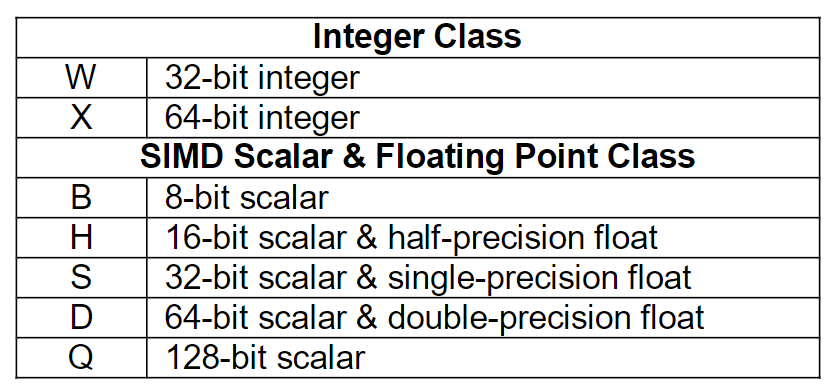
The subtype is one of:
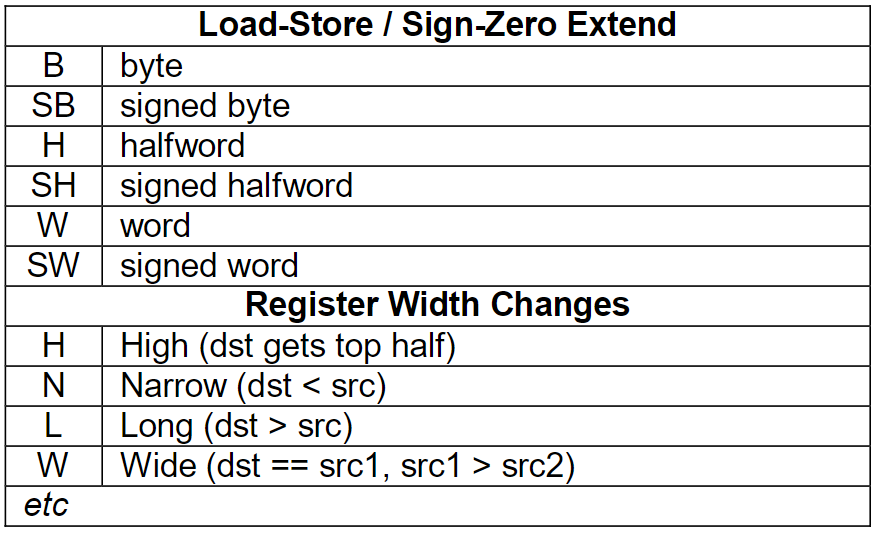
combine
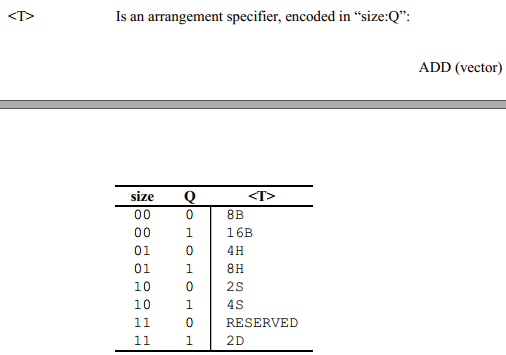
注意后缀的作用主体


指令速查
官网查找指令: https://developer.arm.com/architectures/instruction-sets/intrinsics
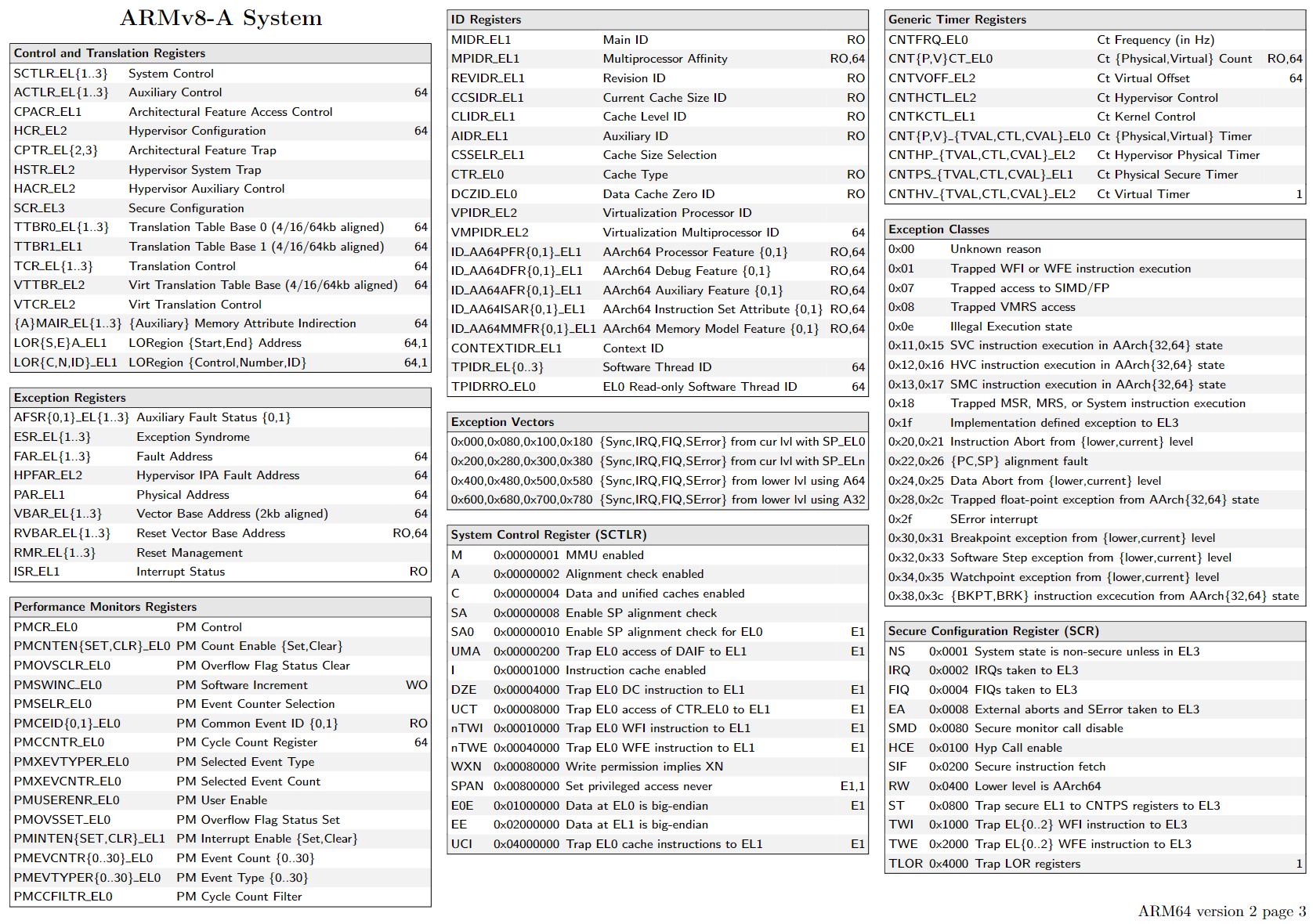
https://armconverter.com/?disasm&code=0786b04e
SIMD/vector
几乎每个指令都可以同时作用在不同寄存器和vector或者scalar上。比如add指令,并没有像X86一样设计vadd或者addps等单独 的指令,如果一定要区分,只能从寄存器是不是vector下手。
根据这个图,确实是有做向量操作的add,FADD是float-add的意思,ADDP是将相邻的寄存器相加放入目的寄存器的意思。不影响是标量scalar还是向量vector的操作。addv是将一个向量寄存器里的每个分量归约求和的意思,确实只能用在向量指令。

由于需要满足64或者128位只有下面几种情况

需要额外注意的是另外一种写法,位操作指令,不在乎寄存器形状shape
是同一个意思,但是不支持and v3.8h, v3.8h, v7.8h
DUP //Duplicate general-purpose register to vector.or Duplicate vector element to vector or scalar.
addp //Add Pair of elements (scalar). This instruction adds two vector elements in the source SIMD&FP register and writes
//the scalar result into the destination SIMD&FP register.
calculate
add
addp //Add Pair of elements (scalar). This instruction adds two vector elements in the source SIMD&FP register and writes the scalar result into the destination SIMD&FP register.
adds // Add , setting flags.
eor // Bitwise Exclusive OR
orr // Move (register) copies the value in a source register to the destination register. Alias of ORR.
Address
Branch
b.cond // branch condition eg. b.ne
bl //Branch with Link branches to a PC-relative offset, setting the register X30 to PC+4
//带链接的跳转。 首先将当前指令的下一条指令地址保存在LR寄存器,然后跳转的lable。通常用于调用子程序,可通过在子程序的尾部添加mov pc, lr 返回。
blr //Branch with Link to Register calls a subroutine at an address in a register, setting register X30 to PC+4.
cbnz //Compare and Branch on Nonzero compares the value in a register with zero, and conditionally branches to a label at a PC-relative offset if the comparison is not equal. It provides a hint that this is not a subroutine call or return. This instruction does not affect the condition flags.
tbnz // test and branch not zero
ret //Return from subroutine, branches unconditionally to an address in a register, with a hint that this is a subroutine return.
Load/Store
ldrb // b是byte的意思
ldar // LDAR Load-Acquire(申请锁) Register
STLR //Store-Release(释放锁) Register
ldp // load pair(two) register
stp // store pair(two) register
ldr(b/h/sb/sh/sw) // load register , sb/sh/sw is signed byte/half/word
str // store register
ldur // load register (unscaled) unscaled means that in the machine-code, the offset will not be encoded with a scaled offset like ldr uses. or offset is minus.
prfm // prefetch memory
Control/conditional
ccmp // comdition compare
CMEQ // Compare bitwise Equal (vector). This instruction compares each vector element from the frst source SIMD&FP register with the corresponding vector element from the second source SIMD&FP register
CSEL // If the condition is true, Conditional Select writes the value of the frst source register to the destination register. If the condition is false, it writes the value of the second source register to the destination register.
CSINC //Conditional Select Increment returns
CSINV //Conditional Select Invert returns
CSNEG //Conditional Select Negation returns
Logic&Move
ASRV //Arithmetic Shift Right Variable
lsl //logic shift left
orr //bitwise(逐位) or
eor //Bitwise Exclusive OR
TST/ANDS //Test bits (immediate), setting the condition flags and discarding the result. Alias of ANDS.
MOVZ //Move wide with zero moves an optionally-shifted 16-bit immediate value to a register
UBFM // Unigned Bitfield Move. This instruction is used by the aliases LSL (immediate), LSR (immediate), UBFIZ, UBFX, UXTB, and UXTH
BFM //Bitfield Move
BIC (shifted register) //Bitwise Bit Clear
CLZ // Count Leading Zeros counts the number of binary zero bits before the frst binary one bit in the value of the source register, and writes the result to the destination register.
REV, REV16, REVSH, and RBIT // below
REV //Reverse byte order in a word.
REV16 //Reverse byte order in each halfword independently.
REVSH //Reverse byte order in the bottom halfword, and sign extend to 32 bits.
RBIT //Reverse the bit order in a 32-bit word.
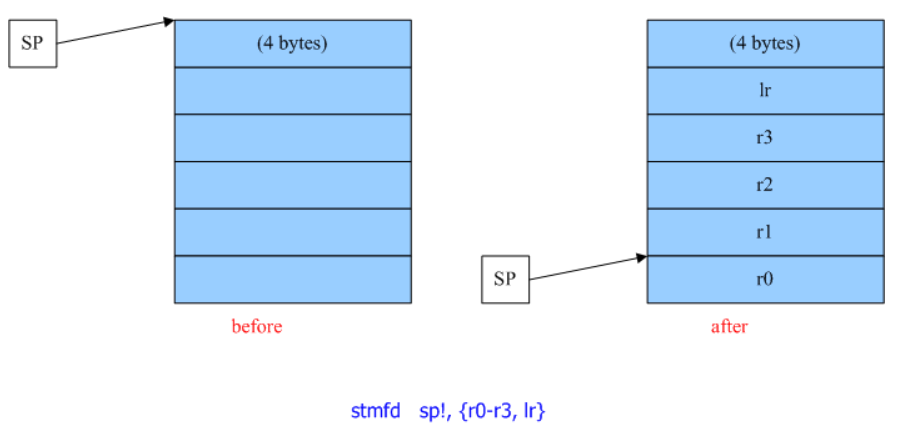
Modifier
system
dmb //data memory barrier
SVC //The SVC instruction causes an exception. This means that the processor mode changes to Supervisor,
ARM no push/pop
are aliases for
需要进一步的研究学习
暂无
遇到的问题
暂无
开题缘由、总结、反思、吐槽~~
参考文献
https://www.cs.virginia.edu/~evans/cs216/guides/x86.html
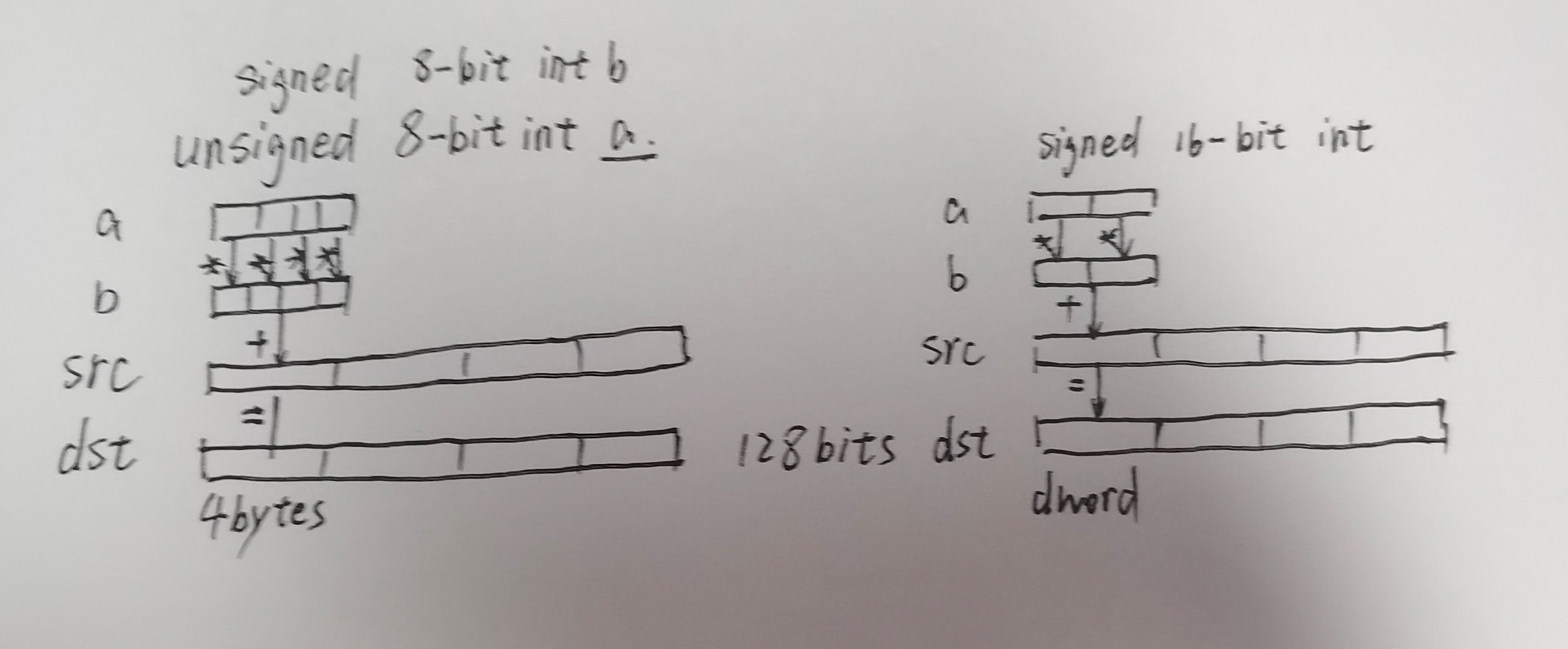
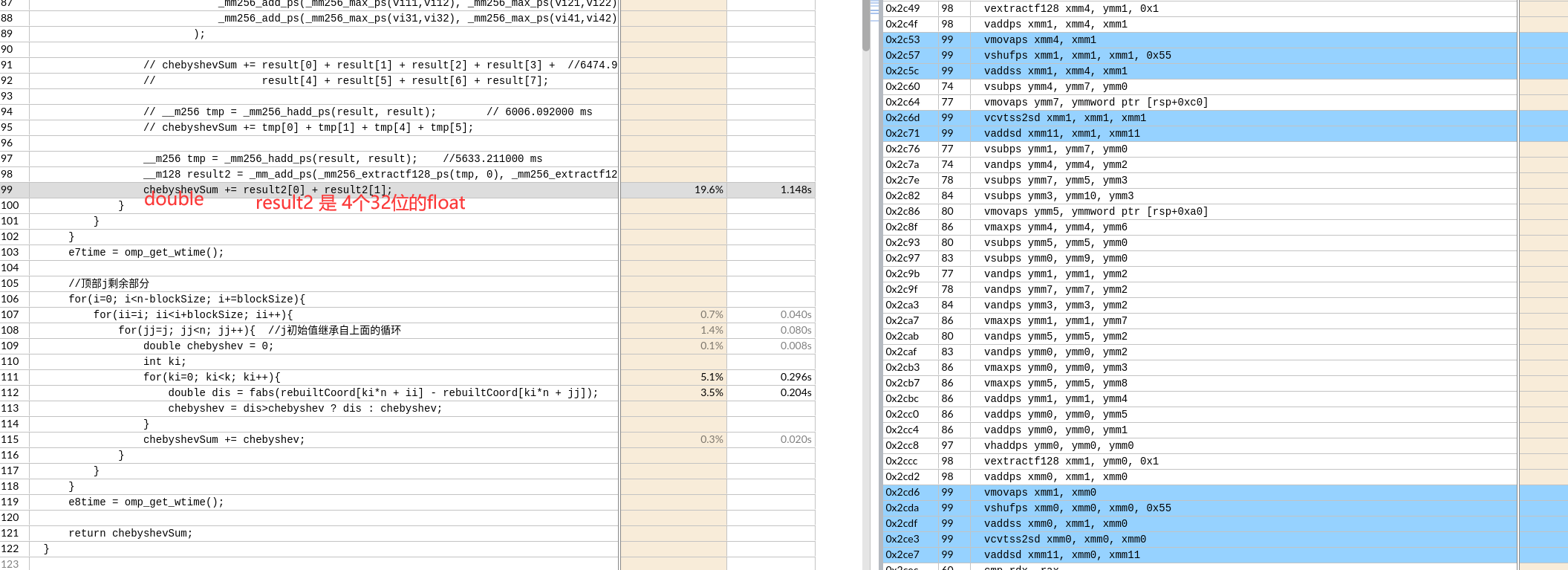
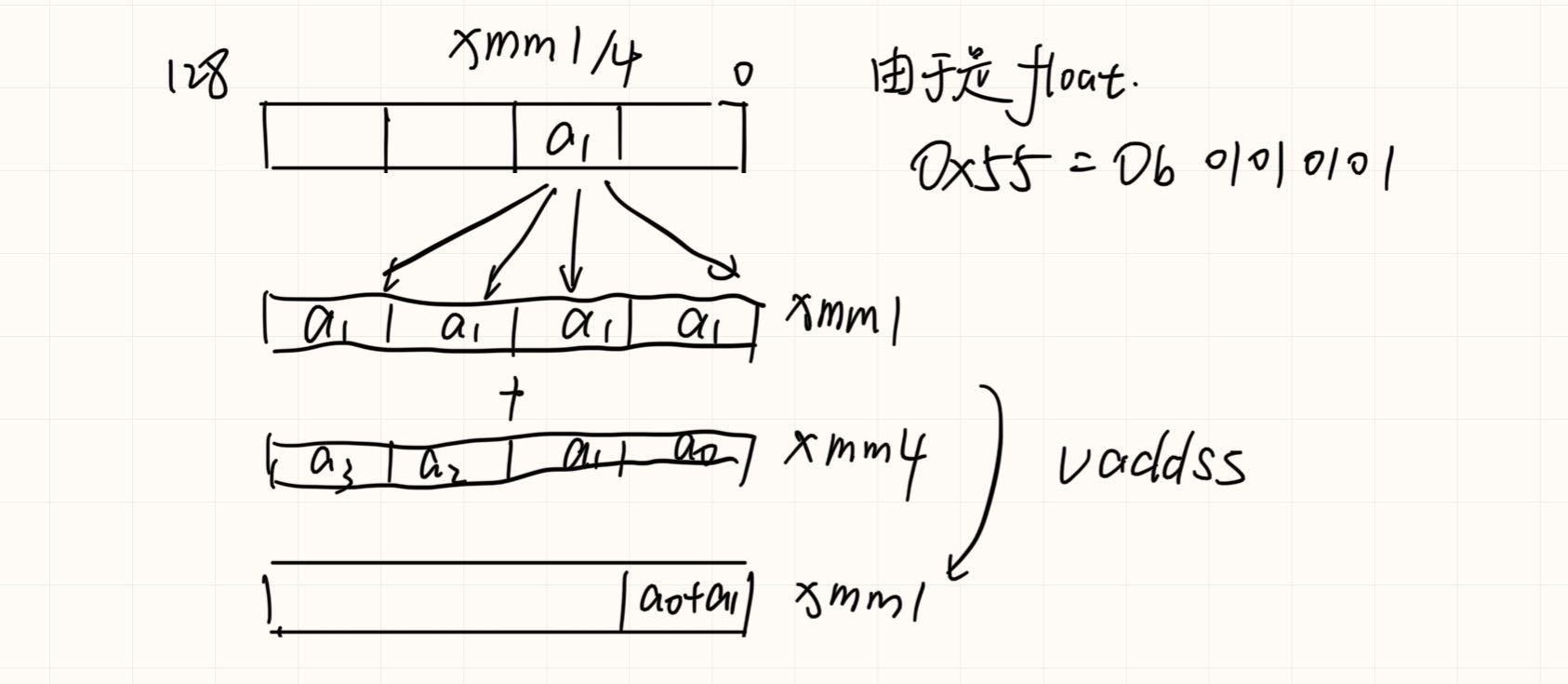 之后float类型转换为double,再求和。
之后float类型转换为double,再求和。



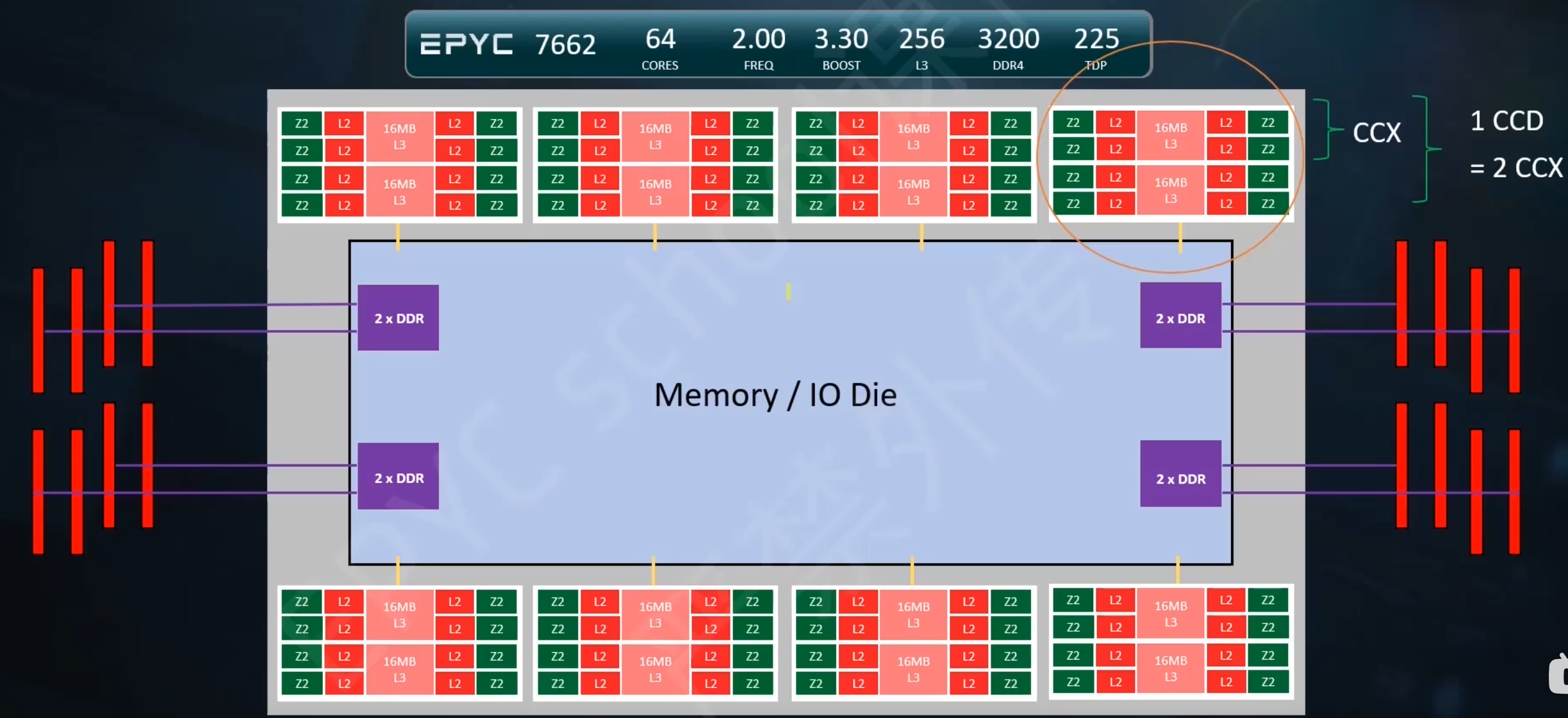
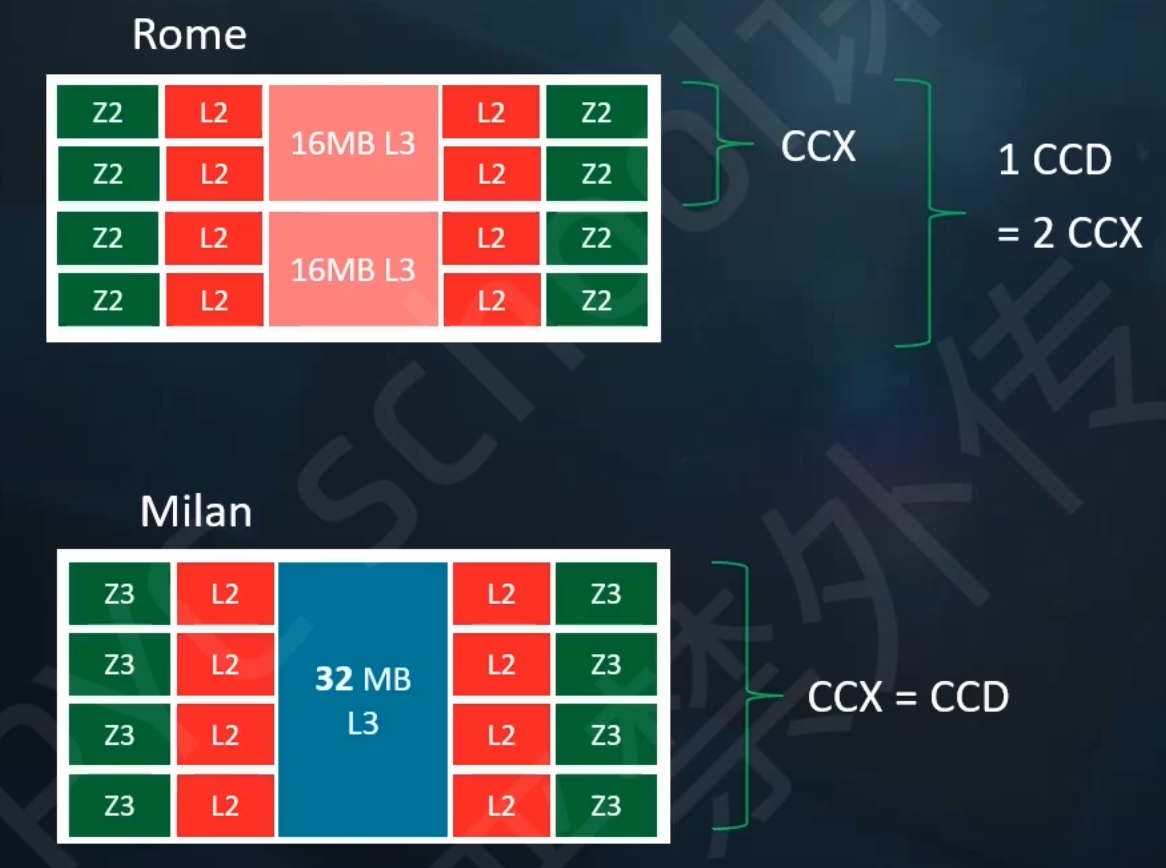
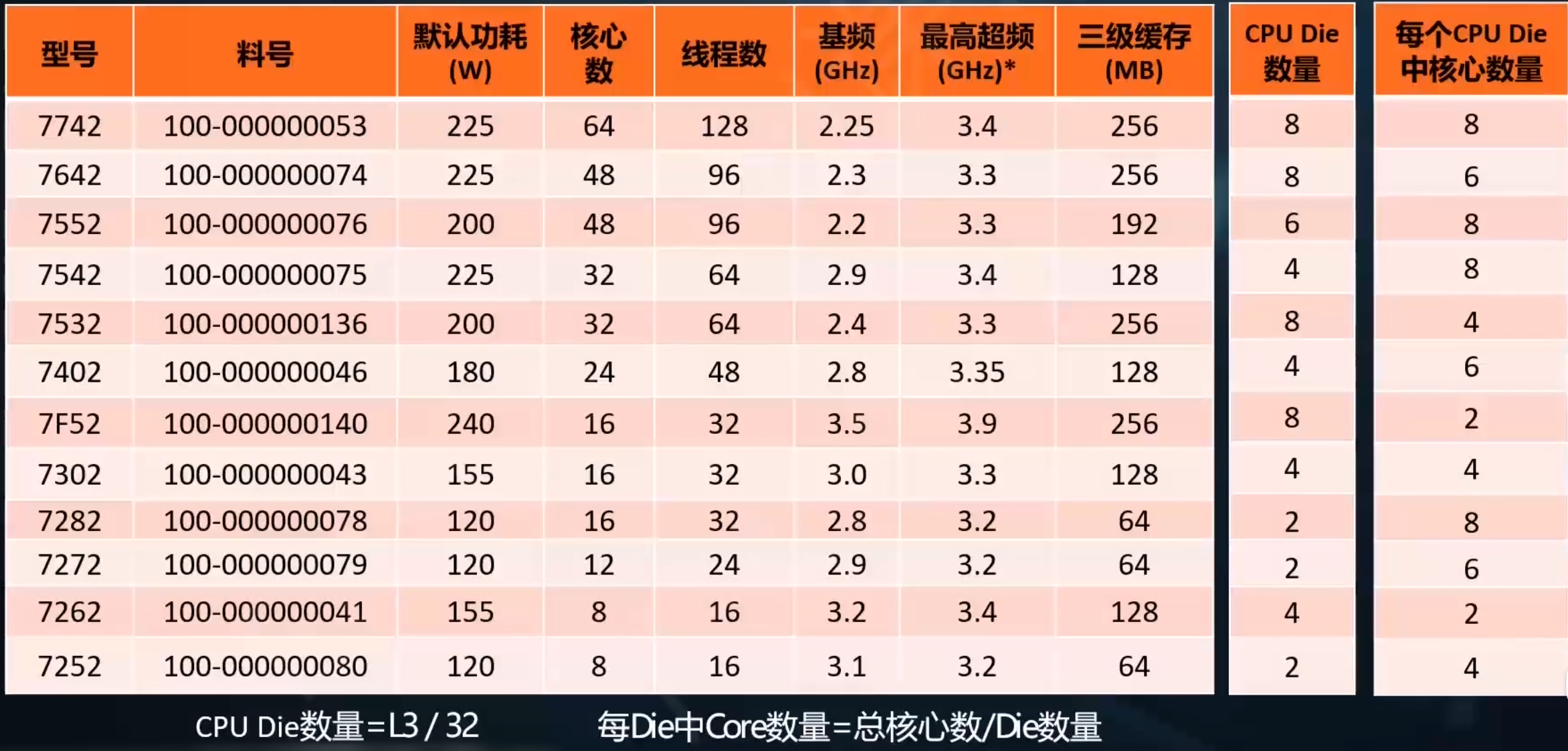
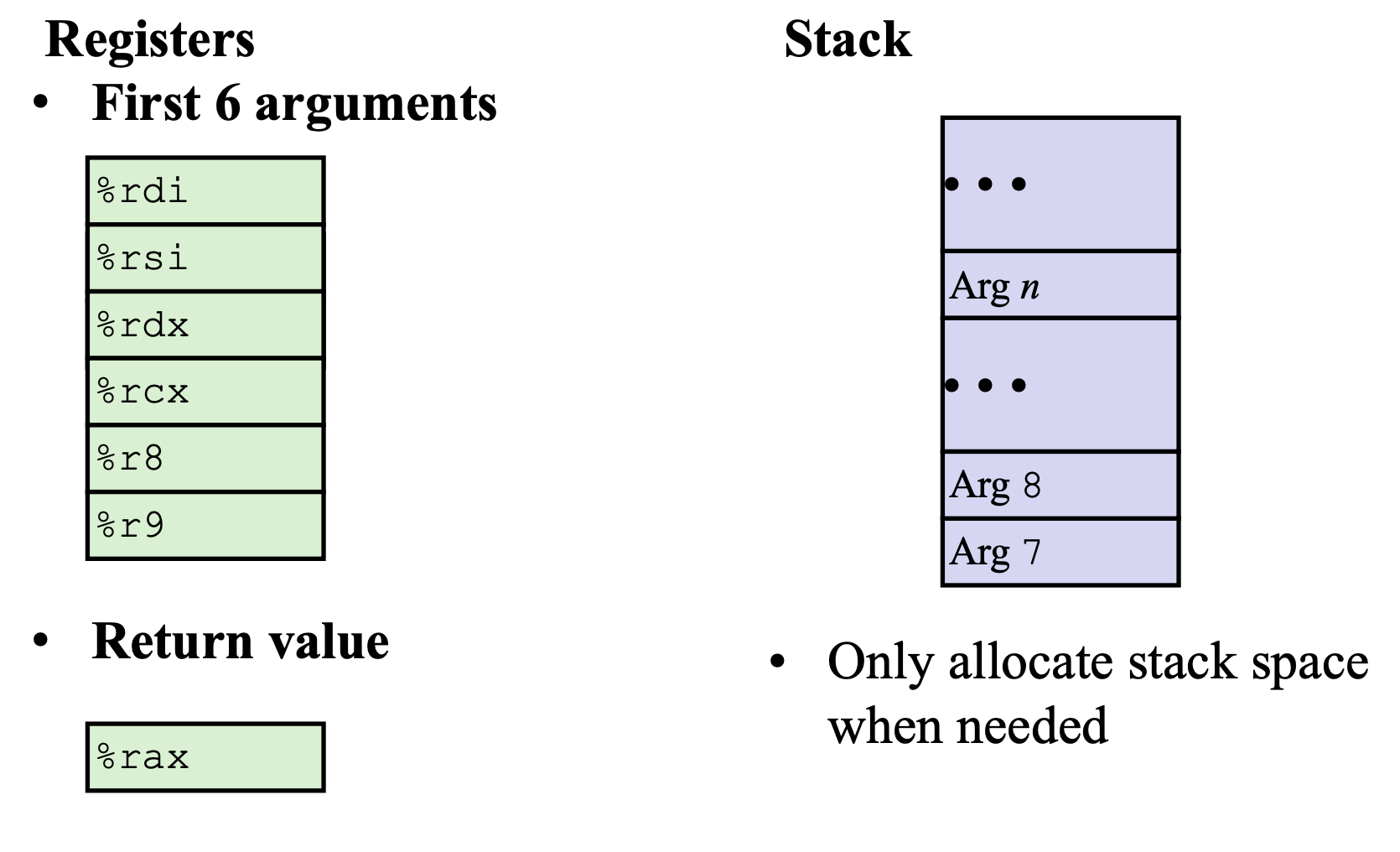
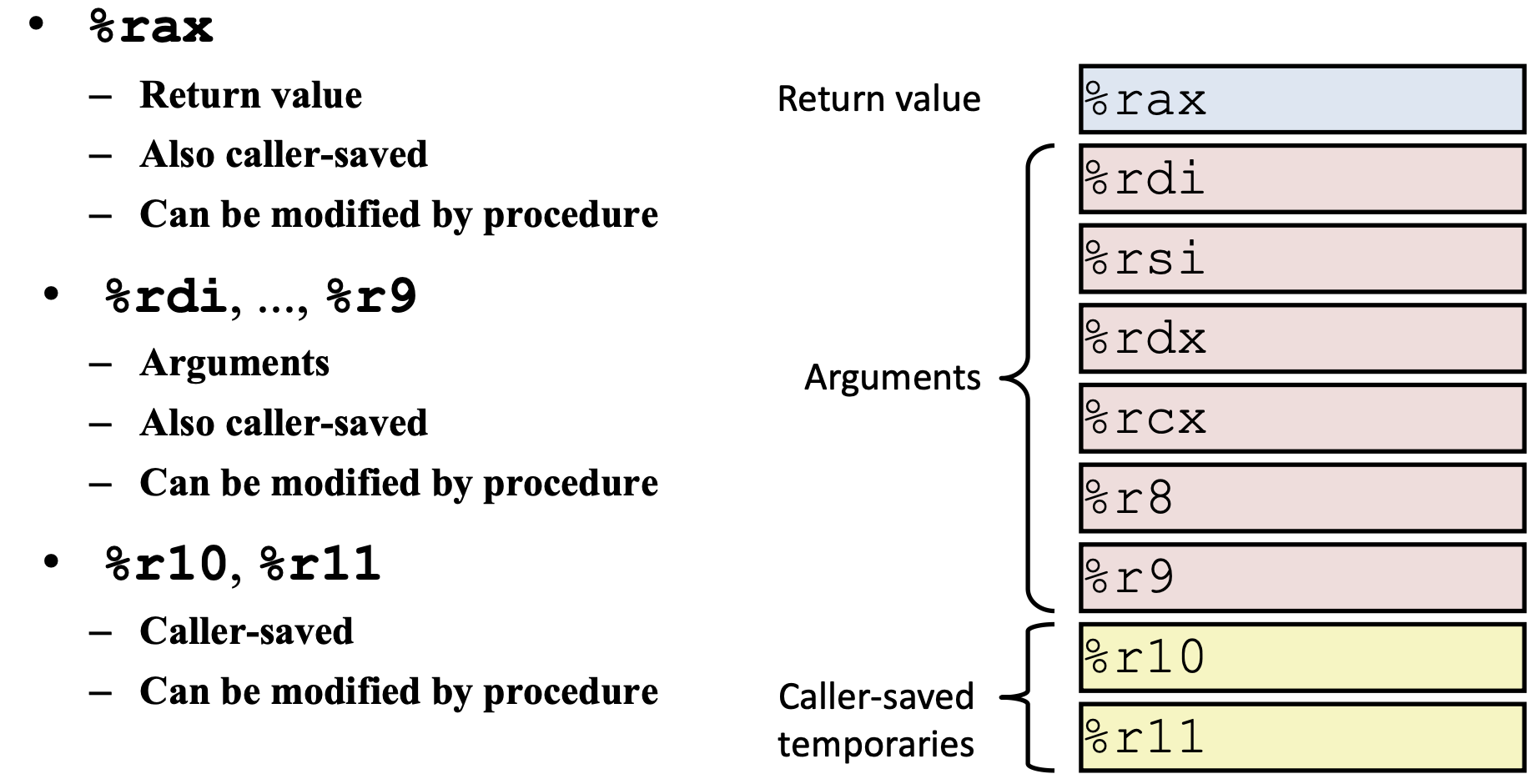
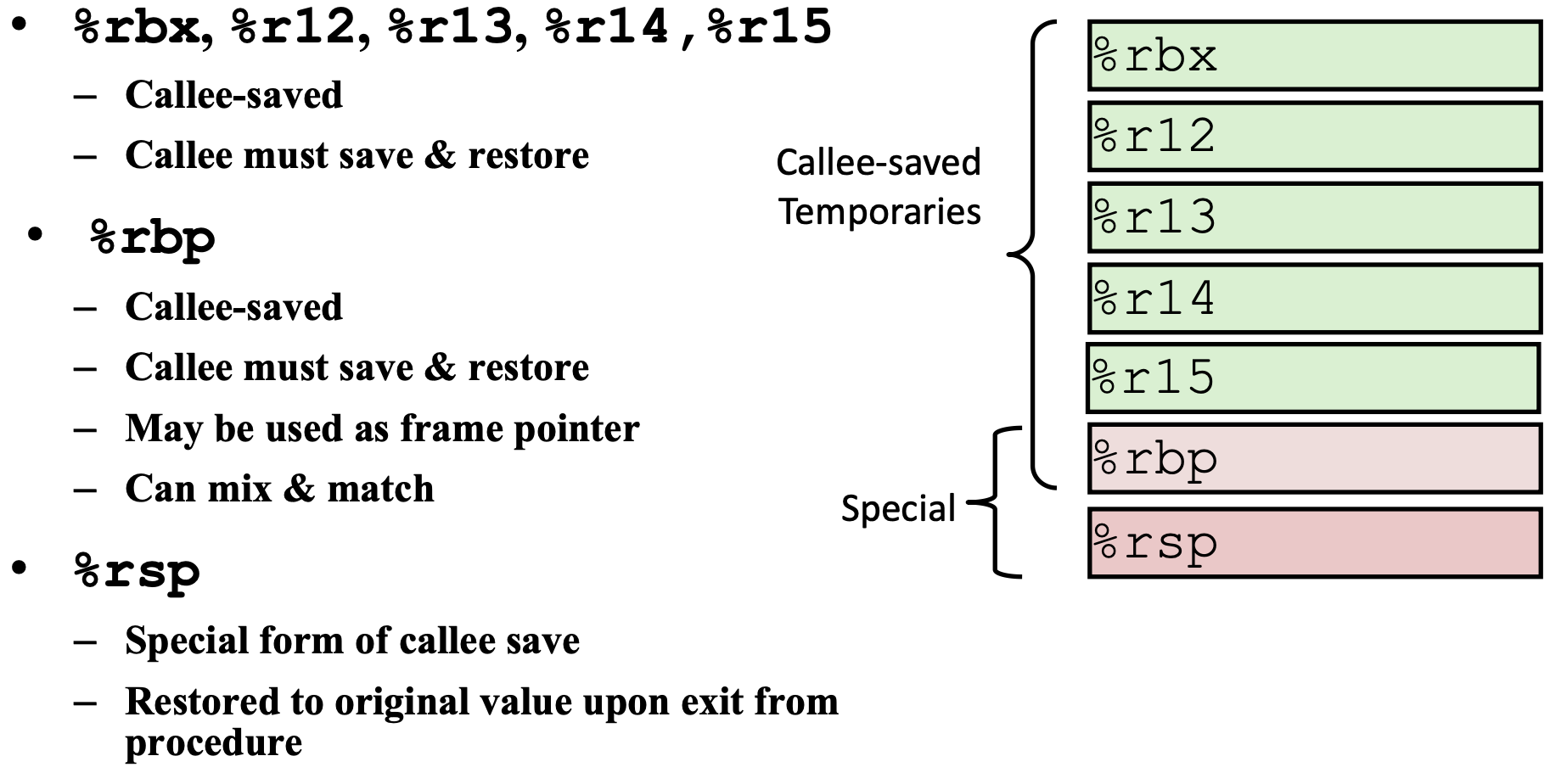


 1. SSE2则进一步支持双精度浮点数,由于寄存器长度没有变长,所以只能支持2个双精度浮点计算或是4个单精度浮点计算.另外,它在这组寄存器上实现了整型计算,从而代替了MMX.
2. SSE3支持一些更加复杂的算术计算.
3. SSE4增加了更多指令,并且在数据搬移上下了一番工夫,支持不对齐的数据搬移,增加了super shuffle引擎.
4. 由于2007年8月,AMD抢先宣布了SSE5指令集。之后Intel将新出的叫做AVX指令集。由于SSE5和AVX指令集功能类似,并且AVX包含更多的优秀特性,因此AMD决定支持AVX指令集
1. SSE2则进一步支持双精度浮点数,由于寄存器长度没有变长,所以只能支持2个双精度浮点计算或是4个单精度浮点计算.另外,它在这组寄存器上实现了整型计算,从而代替了MMX.
2. SSE3支持一些更加复杂的算术计算.
3. SSE4增加了更多指令,并且在数据搬移上下了一番工夫,支持不对齐的数据搬移,增加了super shuffle引擎.
4. 由于2007年8月,AMD抢先宣布了SSE5指令集。之后Intel将新出的叫做AVX指令集。由于SSE5和AVX指令集功能类似,并且AVX包含更多的优秀特性,因此AMD决定支持AVX指令集

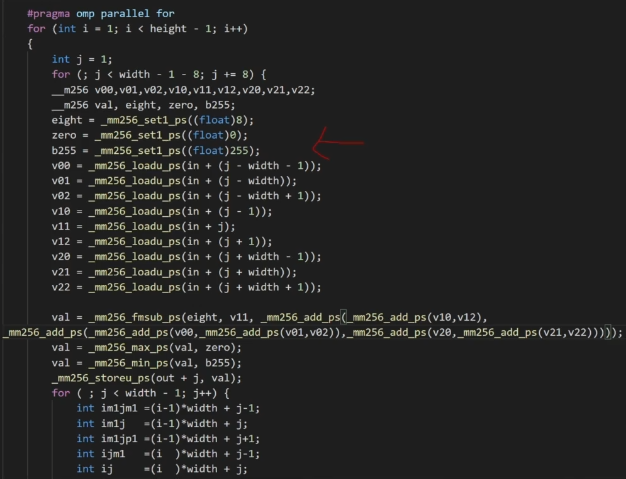
 开启-O3选项,一般不用将代码改成多次计算和内存对齐。
开启-O3选项,一般不用将代码改成多次计算和内存对齐。
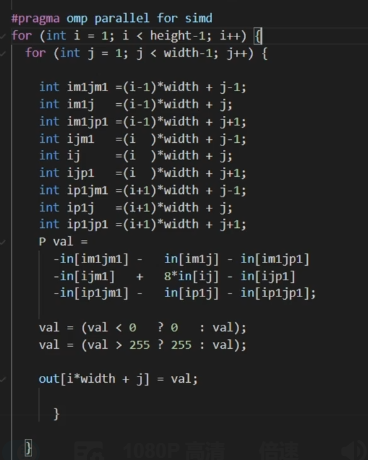 循环展开8次
循环展开8次