Linux下的任务调度分为两类:系统任务调度和用户任务调度。
Linux系统任务是由 cron (crond) 这个系统服务来控制的,这个系统服务是默认启动的。用户自己设置的计划任务则使用crontab 命令。
crontab [-u user] file
crontab [ -u user ] [ -i ] { -e | -l | -r }
-u user:用于设定某个用户的crontab服务;file: file为命令文件名,表示将file作为crontab的任务列表文件并载入crontab;-e:编辑某个用户的crontab文件内容,如不指定用户则表示当前用户;-l:显示某个用户的crontab文件内容,如不指定用户则表示当前用户;-r:从/var/spool/cron目录中删除某个用户的crontab文件。-i:在删除用户的crontab文件时给确认提示。
- crontab有2种编辑方式:
- 直接编辑
/etc/crontab文件,其中/etc/crontab里的计划任务是系统中的计划任务,
- 通过
crontab –e来编辑用户的计划任务;
- 每次编辑完某个用户的cron设置后,cron自动在/var/spool/cron下生成一个与此用户同名的文件,此用户的cron信息都记录在这个文件中,这个文件是不可以直接编辑的,只可以用crontab -e 来编辑。
- 所有用户定义的crontab 文件都被保存在
/var/spool/cron目录中。其文件名与用户名一致。
- crontab中的command尽量使用绝对路径,否则会经常因为路径错误导致任务无法执行。
- 新创建的cron job不会马上执行,至少要等2分钟才能执行,可从起cron来立即执行。
%在crontab文件中表示“换行”,因此假如脚本或命令含有%,需要使用\%来进行转义。
配置文件实例:
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
HOME=/
MAILTO=root # MAILTO变量指定了crond的任务执行信息将通过电子邮件发送给root用户,如果MAILTO变量的值为空,则表示不发送任务执行信息给用户
# * * * * * user-name command to be executed
@reboot /home/user/test.sh #可以实现开机自动运行
@reboot sleep 300 && /home/start.sh # 延时启动
@reboot 表示重启开机的时候运行一次。还有很多类似参数如下:
string meaning
------ -----------
@reboot Run once, at startup.
@yearly Run once a year, "0 0 1 1 *".
@annually (same as @yearly)
@monthly Run once a month, "0 0 1 * *".
@weekly Run once a week, "0 0 * * 0".
@daily Run once a day, "0 0 * * *".
@midnight (same as @daily)
@hourly Run once an hour, "0 * * * *".
# For details see man 4 crontabs
# Example of job definition:
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
* */1 * * * /etc/init.d/smb restart # 每一小时重启smb
在以上各个字段中,还可以使用以下特殊字符:
*代表所有的取值范围内的数字,如月份字段为*,则表示1到12个月;/代表每一定时间间隔的意思,如分钟字段为*/10,表示每10分钟执行1次。-代表从某个区间范围,是闭区间。如2-5表示2,3,4,5,
- 组合:小时字段中
0-23/2表示在0~23点范围内每2个小时执行一次。
,分散的数字(不一定连续),如1,2,3,4,7,9。
tail -f /var/log/cron观察查看cron运行日志(/var/log/cron.log),但是并未找到相关文件,原因是ubuntu默认没有开cron日志,执行命令:
sudo vim /etc/rsyslog.d/50-default.conf
找到cron.log相关行,将前面注释符#去掉,保存退出,重启rsyslog:
sudo service rsyslog restart
执行
less -10 /var/log/cron.log再次查看cron运行日志,log出来了,提示如下信息:
No MTA installed, discarding output
原因是cron把屏幕输出都发送到email了,而当前环境并未安装email server,于是系统报错,解决方面就是不要直接向屏幕输出内容,而是重定向到一个文件。
cd /var/spool/mail/
less shaojiemike
service cron status # ubuntu
夜间利用机器进行批量实验
如果Linux系统有时差,需要加8小时在0、3、6点。
0 0,3,6 * * * cd /home/t00906153/OpenSora/OpenSora_performance_test && git stash save "Stash before script run at $(date +"%Y-%m-%d %H:%M:%S")" && bash test/train_full_opensorav1_1.sh >> /home/t00906153/crontab.log 2>&1 && git stash pop && echo "Executed at $(date)" >> /home/t00906153/crontab.log
crontab on OpenWRT
# 1.编辑好脚本加入cron
crontab -e
* * * * * sh /root/tst.sh
# 2.创建cron初始化脚本 vi /etc/init.d/S60cron,添加下面内容
#!/bin/sh
#start crond
/usr/sbin/crond -c /etc/crontabs
# 修改权限
chmod 755 /etc/init.d/S60cron
# 3.手动启动crond
/etc/init.d/S60cron
# 4.查看crond任务
logread -e cron
# 5.重启crond
killall crond; /etc/init.d/S60cron
# 6.禁用crond日志 修改/etc/init.d/S60cron
/usr/sbin/crond -c /etc/crontabs -L /dev/null
https://zhuanlan.zhihu.com/p/35402730
https://blog.csdn.net/qq_35440678/article/details/80489102
https://neucrack.com/p/91
https://www.linuxprobe.com/how-to-crontab.html
https://martybugs.net/wireless/openwrt/cron.cgi

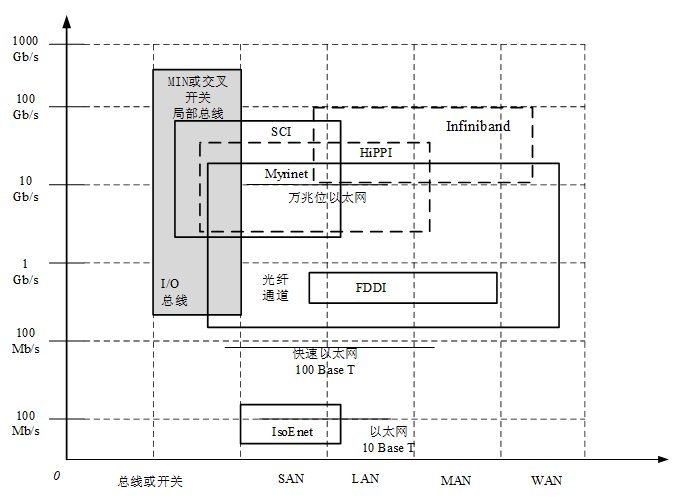 System Area Network(系统域网):主机及外设
Local Area Network(局域网):以太网
Metropolitan Area Network(城域网):WiMax
Wide Area Network(广域网):因特网,X.25
System Area Network(系统域网):主机及外设
Local Area Network(局域网):以太网
Metropolitan Area Network(城域网):WiMax
Wide Area Network(广域网):因特网,X.25