vllm-omni & DiT Inference Accelerate
导言
vllm专门为了多模态单独推出了推理框架vllm-omni,调研一下
导言
vllm专门为了多模态单独推出了推理框架vllm-omni,调研一下
导言
VeRL 作为RL领域趋势最火的开源仓,值得学习。
导言
VeRL 基于ray的多进程管理,并结合 推理、训练等多个阶段。其E2E时间组成和如何加速都是待研究的课题。
导言
导言
learning rate、clip_norm、梯度累计、micro bs 这些通用超参,应该如何调整。
导言
模型训练,为什么需要这么多阶段,每个阶段的独特职责和意义是什么。
导言
导言
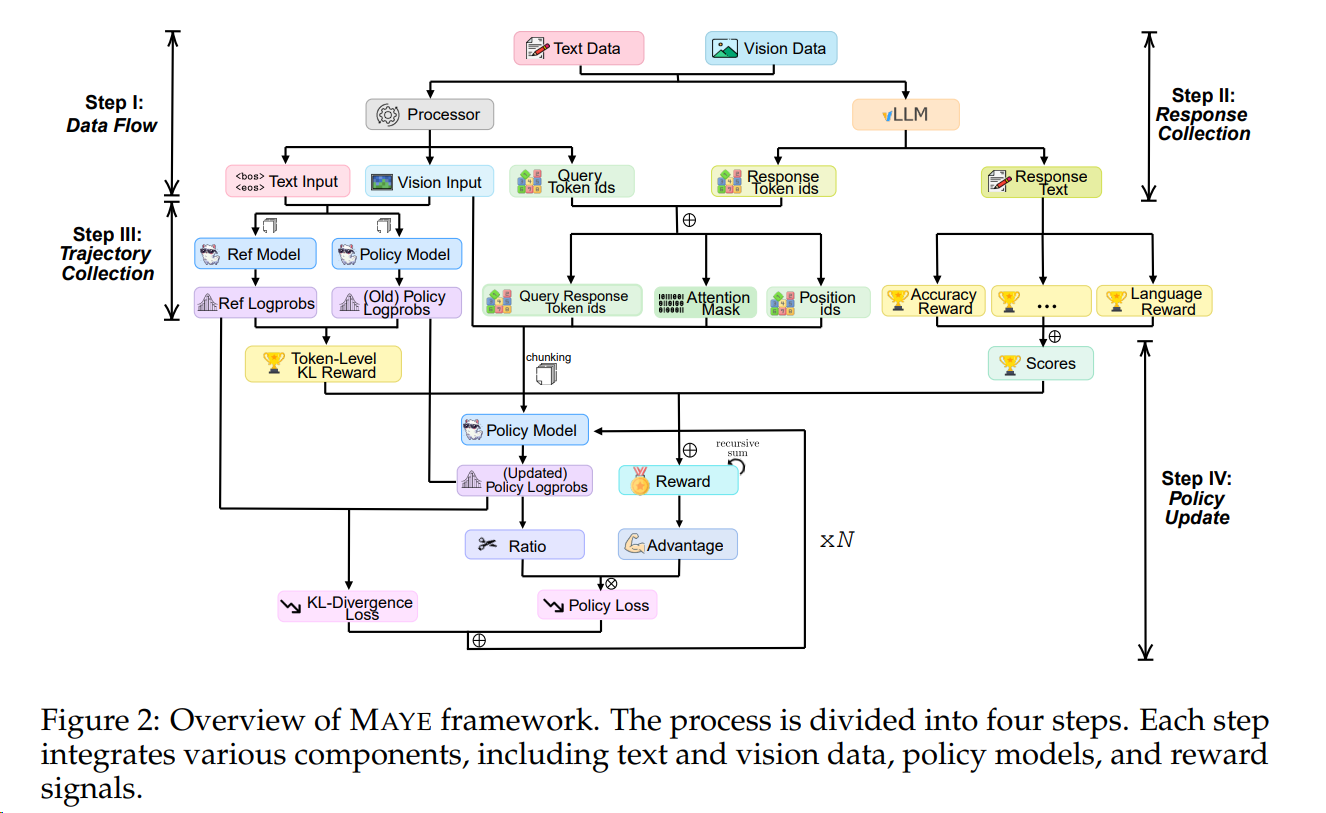
快速调研多模态强化学习及其ai infra(verl类似)的下一步方向、技术点和与LLM RL的差异点:
导言