__global__ void device_copy_scalar_kernel(int* d_in, int* d_out, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
for (int i = idx; i < N; i += blockDim.x * gridDim.x) {
d_out[i] = d_in[i];
}
}
void device_copy_scalar(int* d_in, int* d_out, int N)
{
int threads = 128;
int blocks = min((N + threads-1) / threads, MAX_BLOCKS);
device_copy_scalar_kernel<<<blocks, threads>>>(d_in, d_out, N);
}
简单的分块拷贝。
通过cuobjdump -sass executable.得到对应的标量copy对应的SASS代码
/*0058*/ IMAD R6.CC, R0, R9, c[0x0][0x140]
/*0060*/ IMAD.HI.X R7, R0, R9, c[0x0][0x144]
/*0068*/ IMAD R4.CC, R0, R9, c[0x0][0x148]
/*0070*/ LD.E R2, [R6]
/*0078*/ IMAD.HI.X R5, R0, R9, c[0x0][0x14c]
/*0090*/ ST.E [R4], R2
(SASS不熟悉,请看SASS一文)
其中4条IMAD指令计算出读取和存储的指令地址R6:R7和R4:R5。第4和6条指令执行32位的访存命令。
通过使用int2, int4, or float2
比如将int的指针d_in类型转换然后赋值。
reinterpret_cast<int2*>(d_in)
// simple in C99
(int2*(d_in))
但是需要注意对齐问题,比如
reinterpret_cast<int2*>(d_in+1)
这样是非法的。
通过使用对齐的结构体来实现同样的目的。
struct Foo {int a, int b, double c}; // 16 bytes in size
Foo *x, *y;
…
x[i]=y[i];
执行for循环次数减半,注意边界处理。
__global__ void device_copy_vector2_kernel(int* d_in, int* d_out, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
for (int i = idx; i < N/2; i += blockDim.x * gridDim.x) {
reinterpret_cast<int2*>(d_out)[i] = reinterpret_cast<int2*>(d_in)[i];
}
// in only one thread, process final element (if there is one)
if (idx==N/2 && N%2==1)
d_out[N-1] = d_in[N-1];
}
void device_copy_vector2(int* d_in, int* d_out, int n) {
threads = 128;
blocks = min((N/2 + threads-1) / threads, MAX_BLOCKS);
device_copy_vector2_kernel<<<blocks, threads>>>(d_in, d_out, N);
}
对应汇编可以看出
/*0088*/ IMAD R10.CC, R3, R5, c[0x0][0x140]
/*0090*/ IMAD.HI.X R11, R3, R5, c[0x0][0x144]
/*0098*/ IMAD R8.CC, R3, R5, c[0x0][0x148]
/*00a0*/ LD.E.64 R6, [R10]
/*00a8*/ IMAD.HI.X R9, R3, R5, c[0x0][0x14c]
/*00c8*/ ST.E.64 [R8], R6
变成了LD.E.64
执行for循环次数减半,注意边界处理。
__global__ void device_copy_vector4_kernel(int* d_in, int* d_out, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
for(int i = idx; i < N/4; i += blockDim.x * gridDim.x) {
reinterpret_cast<int4*>(d_out)[i] = reinterpret_cast<int4*>(d_in)[i];
}
// in only one thread, process final elements (if there are any)
int remainder = N%4;
if (idx==N/4 && remainder!=0) {
while(remainder) {
int idx = N - remainder--;
d_out[idx] = d_in[idx];
}
}
}
void device_copy_vector4(int* d_in, int* d_out, int N) {
int threads = 128;
int blocks = min((N/4 + threads-1) / threads, MAX_BLOCKS);
device_copy_vector4_kernel<<<blocks, threads>>>(d_in, d_out, N);
}
对应汇编可以看出
/*0090*/ IMAD R10.CC, R3, R13, c[0x0][0x140]
/*0098*/ IMAD.HI.X R11, R3, R13, c[0x0][0x144]
/*00a0*/ IMAD R8.CC, R3, R13, c[0x0][0x148]
/*00a8*/ LD.E.128 R4, [R10]
/*00b0*/ IMAD.HI.X R9, R3, R13, c[0x0][0x14c]
/*00d0*/ ST.E.128 [R8], R4
变成了LD.E.128
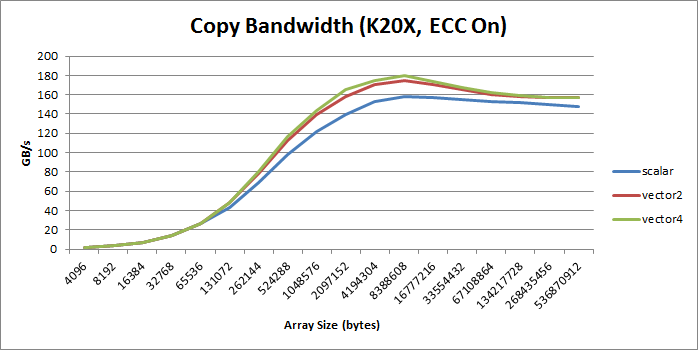
(个人感觉,提升也不大吗?也没有两倍和四倍的效果)
绝大部分情况,向量比标量好, increase bandwidth, reduce instruction count, and reduce latency. 。
但是会增加额外的寄存器(SASS里也没有看到??)和降低并行性(什么意思???)
https://developer.nvidia.com/blog/cuda-pro-tip-increase-performance-with-vectorized-memory-access/#entry-content-comments
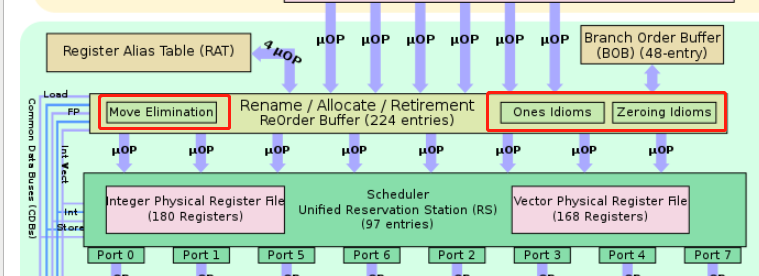 1. 由于是在寄存器重命名阶段(Rename)时实现的
1. 所以不需要发射到port执行单元执行,占用硬件资源。也没有延迟
2. 但是需要划分前面部分的decode的带宽,和ROB(reorder buffer)的资源
1. 由于是在寄存器重命名阶段(Rename)时实现的
1. 所以不需要发射到port执行单元执行,占用硬件资源。也没有延迟
2. 但是需要划分前面部分的decode的带宽,和ROB(reorder buffer)的资源
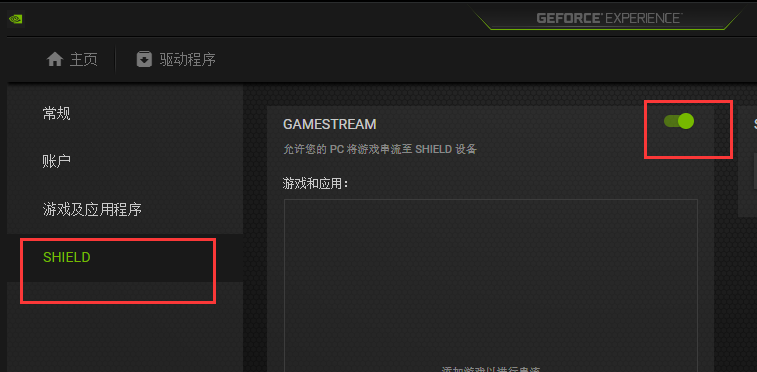
 还是不行,猜测是
还是不行,猜测是
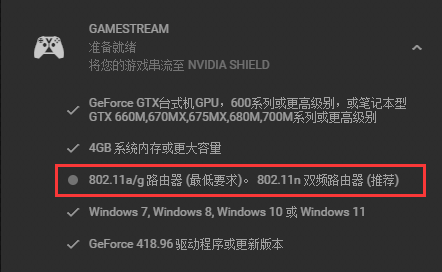
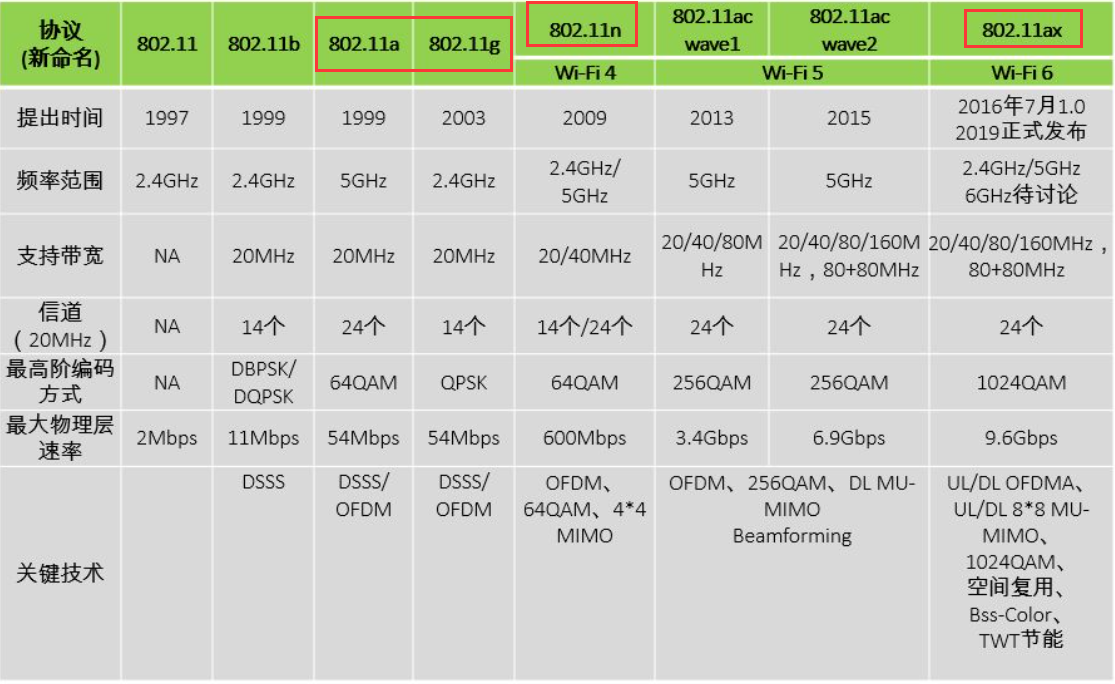


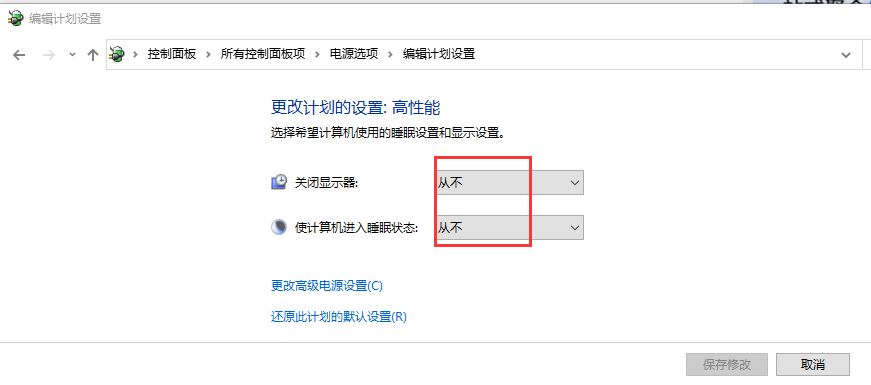
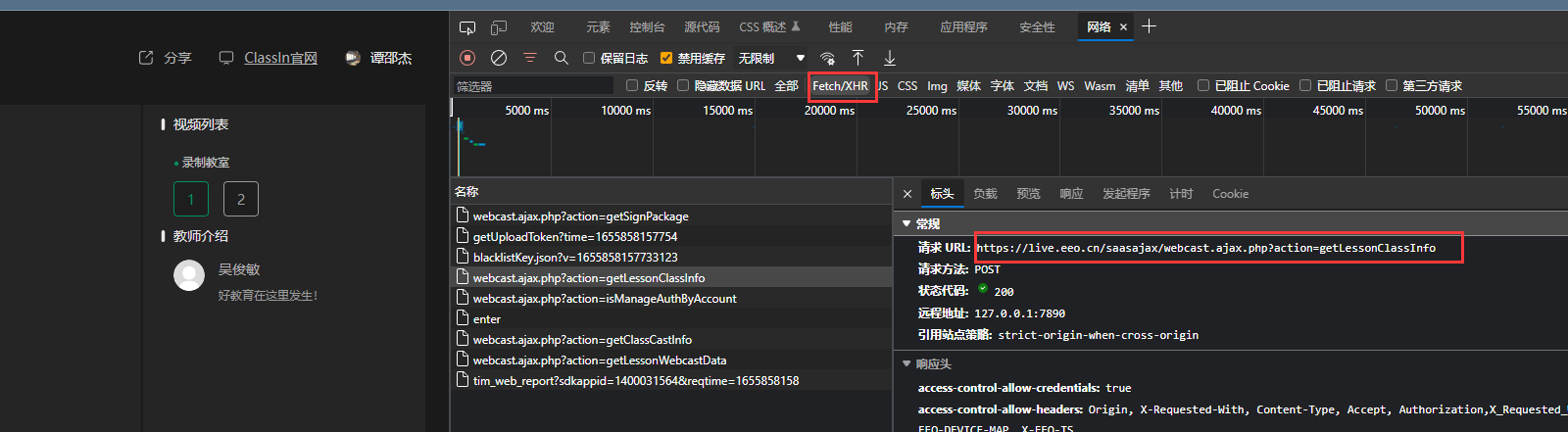


 但是不打开网站没有php返回,网页只能得到。
但是不打开网站没有php返回,网页只能得到。
 可通过下面API返回需要的, 可以见
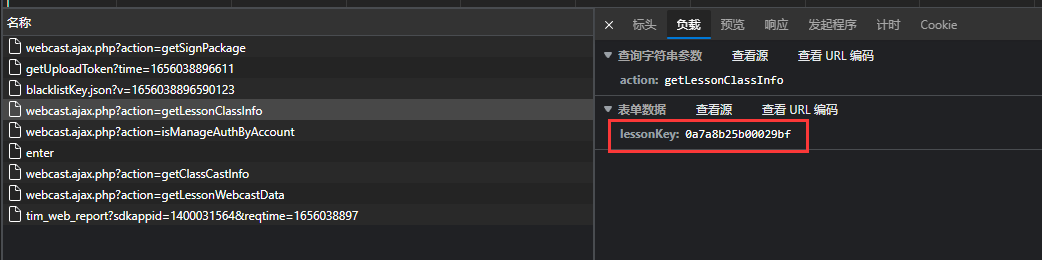
可通过下面API返回需要的, 可以见 data输入
data输入
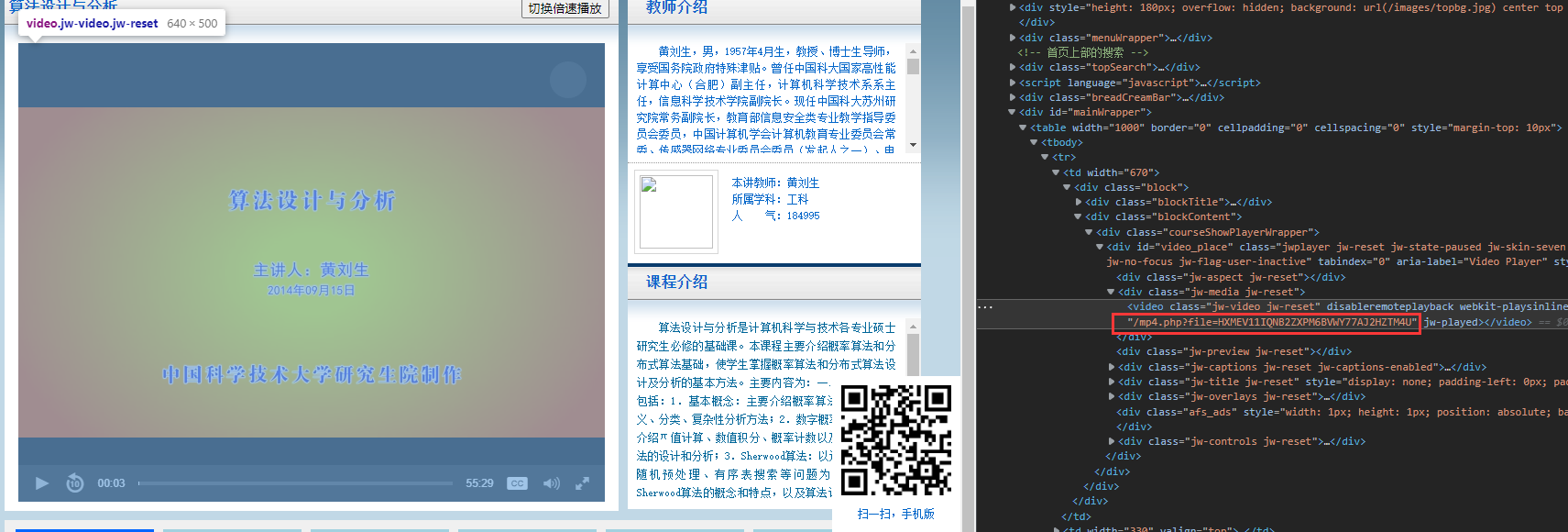
 返回数据
返回数据
