Vue
vue-chart
https://stackblitz.com/edit/vue-echarts-vue-3?file=src%2FApp.vue
需要进一步的研究学习
暂无
遇到的问题
暂无
开题缘由、总结、反思、吐槽~~
参考文献
无
https://stackblitz.com/edit/vue-echarts-vue-3?file=src%2FApp.vue
暂无
暂无
无
横向条形图排序赛跑叫Bar chart race
参考项目
但是好像是静态的,而且只有一个排序的柱状图
参考文档, 使用template项目
git clone https://github.com/Kirrito-k423/leetcode-ranking-visualization-anichart.git
# Install Dependencies
npm install -g pnpm
pnpm i
pnpm build # error
由于项目还在开发,暂时不进一步尝试
暂无
暂无
无
CUDA编程水平高低的不同,会导致几十上百倍的性能差距。但是这篇将聚焦于CUDA的编程语法,编译与运行。
我一向的观点是现实生活已经投入了很多时间体验了,影视剧(动漫作品)肯定要是看现实中没有的。这导致的第一个问题就是既然不存在,你怎么让观众相信呢?
喜欢一个角色往往是没有什么理由的,虽然要追求格物致知。但是将最感性的情感拿来分析是不是有点无情呢?
初印象的美好(40)
暂无
暂无
看了星野爱之后,我又emo了
无
摘要
g++ -fsyntax-only your_file.cppMinGW-w64项目,是从原本MinGW产生的分支。如今已经独立发展MinGW Installation Manager 中 勾选gcc/g++和bash 等项。注意,base包括了关键的make程序。
git bash,就没有上述程序。Pacman的包管理系统, 来提供包的轻松安装和保持更新的方式,Arch Linux用户应该很熟悉这个系统。MSYS2 MSYS安装软件
MSYS2 MinGW UCRT 64-bit终端的路径下。 CTRL+O CTRL+X 保存退出bash
cd ~
nano .bashrc
export PATH=$PATH:/e/commonSoftware/Microsoft\ VS\ Code/bincode .就能打开E:\commonSoftware\msys32\ucrt64\bin VSCODE 就能正常访问g++官网直接下载,但是由于证书的原因,公司内部使用要内网下载。
遵循内部云笔记下载:
存在红色波浪线, 插件clangd导致的
C/C++插件includePathCtrl+Shift+P输入C/C++ 编辑配置E:\\commonSoftware\\msys32\\ucrt64\\includehttps://solarianprogrammer.com/2021/06/11/install-clang-windows-msys2-mingw-w64/
https://blog.csdn.net/m0_51429482/article/details/125191731
导言
作为理工男 + 大直男,几乎没有注意个人形象管理。但是这马上要毕业了,也到了要开始找对象的年龄。
也不期望变帅哥,至少能实现给人的初印象是干净开朗男生的感觉。
为此需要从多个角度,指出现有问题、理性分析原因、量化改进指标、持续跟踪状态。
AtomicSimple是最简单规模的模型,一个cycle完成一条指令的执行,memory 模型比较理想化,访存操作为原子性操作。适用于快速功能模拟。TimingSimple模拟器也是无流水线的模拟,但是使用了存储器访问时序模型,用以统计存储器访问延迟。In-Order模型是GEM5模拟的新特性,强调指令时序与仿真精度,流水级为默认五级流水:取值、译码、执行、访存、写回。并且模拟了cache部件、执行部件、分支预测部件等。O3模拟器是流水级模拟,O3模拟器模拟了乱序执行和超标量执行的指令间依赖,以及运行在多CPU上的并发执行的多线程。time ./build/ARM/gem5.fast configs/example/se.py --cmd=/home/shaojiemike/test/llvmVSgem5/MV/MV_gem5 -n 32 --cpu-type=O3CPU --l1d_size=64kB --l1i_size=16kB --caches
scons build/<config>/<binary> 建立模拟器。<config> gem5的配置文件,如ARM,X86等<binary> 模拟器的类型,有如下gem5.debug 有关闭了优化,使gdb一类的工具更易于调试;gem5.opt有打开优化,但保留了调试输出和断言;gem5.fast去除了调试工具;gem5.prof用于与gprof共同使用可选选项在./build/ARM/gem5.fast configs/example/se.py -h或者 configs/common/Options.py 中查看
常规的配置:
--list-hwp-types查看。可以指定L1L2cache的HWP类型,如--l1d-hwp-type=TaggedPrefetcher。build/X86/gem5.opt configs/example/se.py
--caches --l1d_size=32kB --l1i_size=32kB
--l2cache --l2_size=256kB
--l3_size=8192kB # l3 在 se里是不生效的
-c tests/test-progs/hello/bin/x86/linux/hello
# 建议将L3大小并入L2来模拟cycle的下限
build/X86/gem5.opt configs/example/se.py
--caches --l1d_size=32kB --l1i_size=32kB
--l2cache --l2_size=256kB+8192kB
-c tests/test-progs/hello/bin/x86/linux/hello
进阶配置:
运行完SE模式,默认会在指令路径下生成m5out文件夹,其中各文件大致含义如下:
config.ini或者config.json 运行指令的系统参数json格式的文件能比较好的理清config的重要设置[system.cpu] 有CPU的具体设置[system.mem_ctrls.dram] 有DRAM读取数据的具体设置[system.membus] BUS的相关设置stats.txt 模拟结果数据(具体的周期数等)system.clk_domain.clock 1000 # Clock period in ticks (Tick)system.cpu_clk_domain.clock 500 # Clock period in ticks (Tick)fs/proc/lscpu 模拟系统配置(类似lscpu)config.dot.* 模拟的系统结构config.dot 是以文字展示config.dot.pdf 和 config.dot.svg 都是以图片表示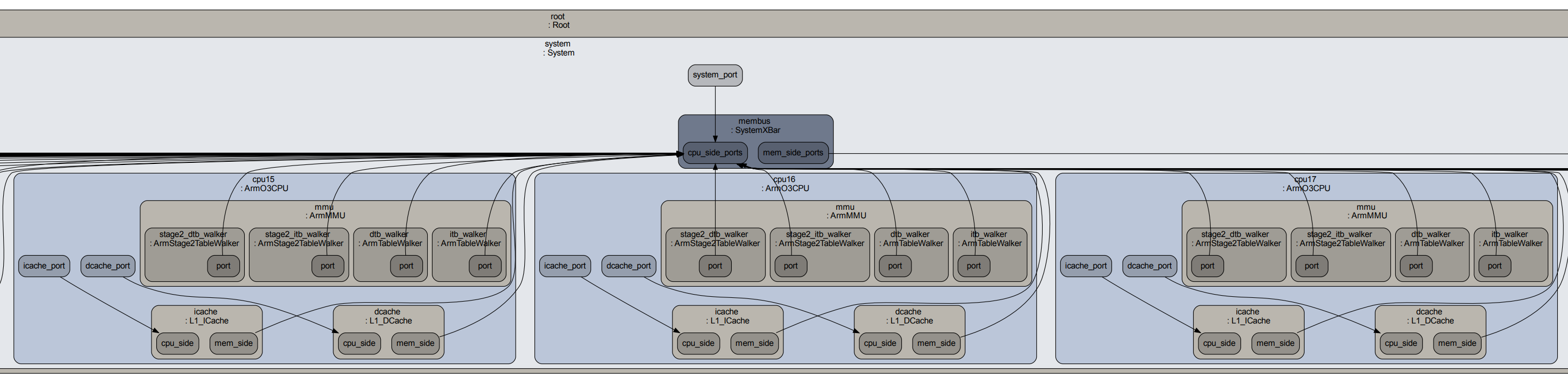
config.dot.svg 能展示每个部件的细节参数 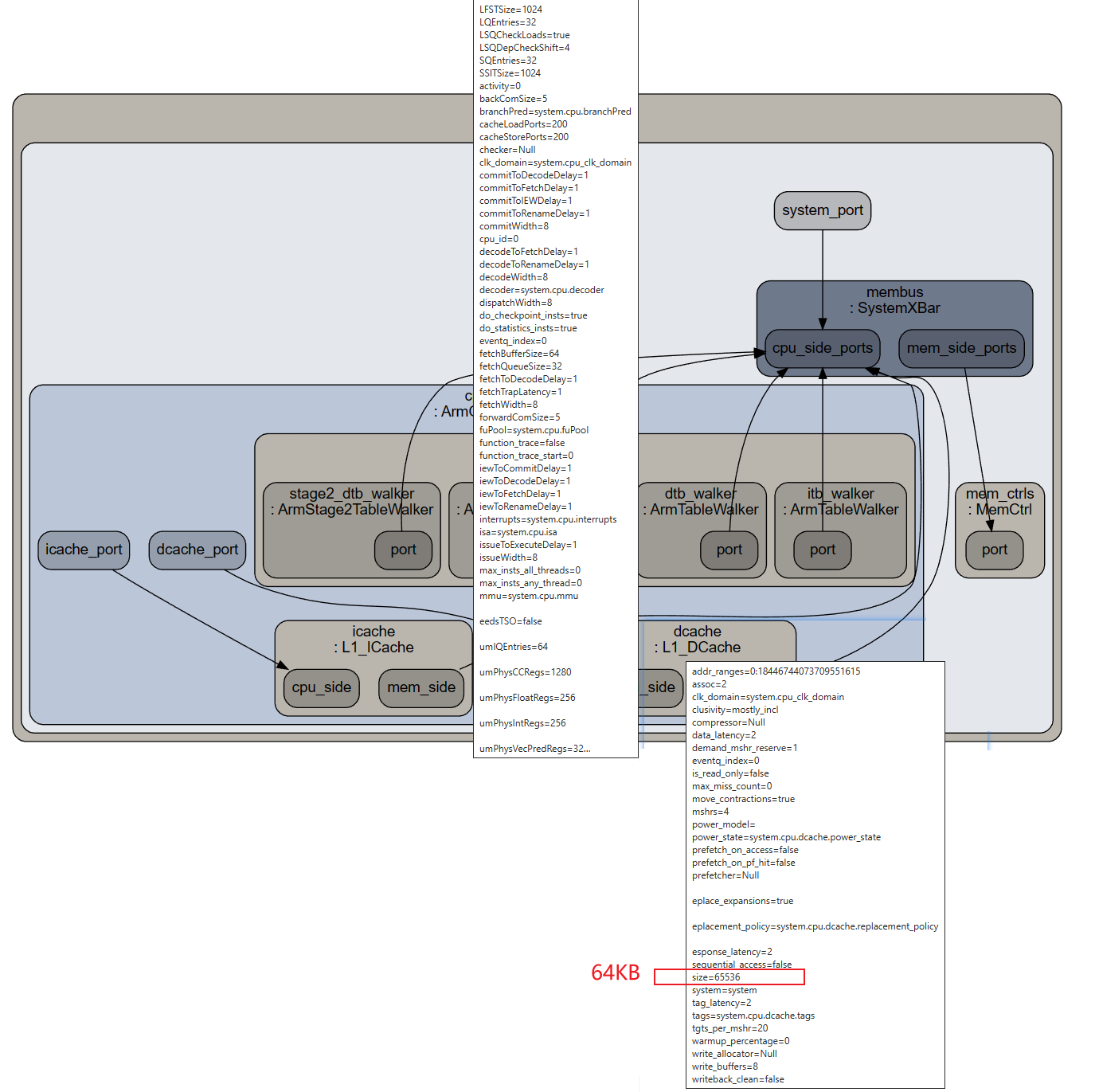
commitWidth, decodeWidth, dispatchWidth, fetchWidth, issueWidth, renameWidth, squashWidth, wbWidth
下面是行数占比最大的几个部分
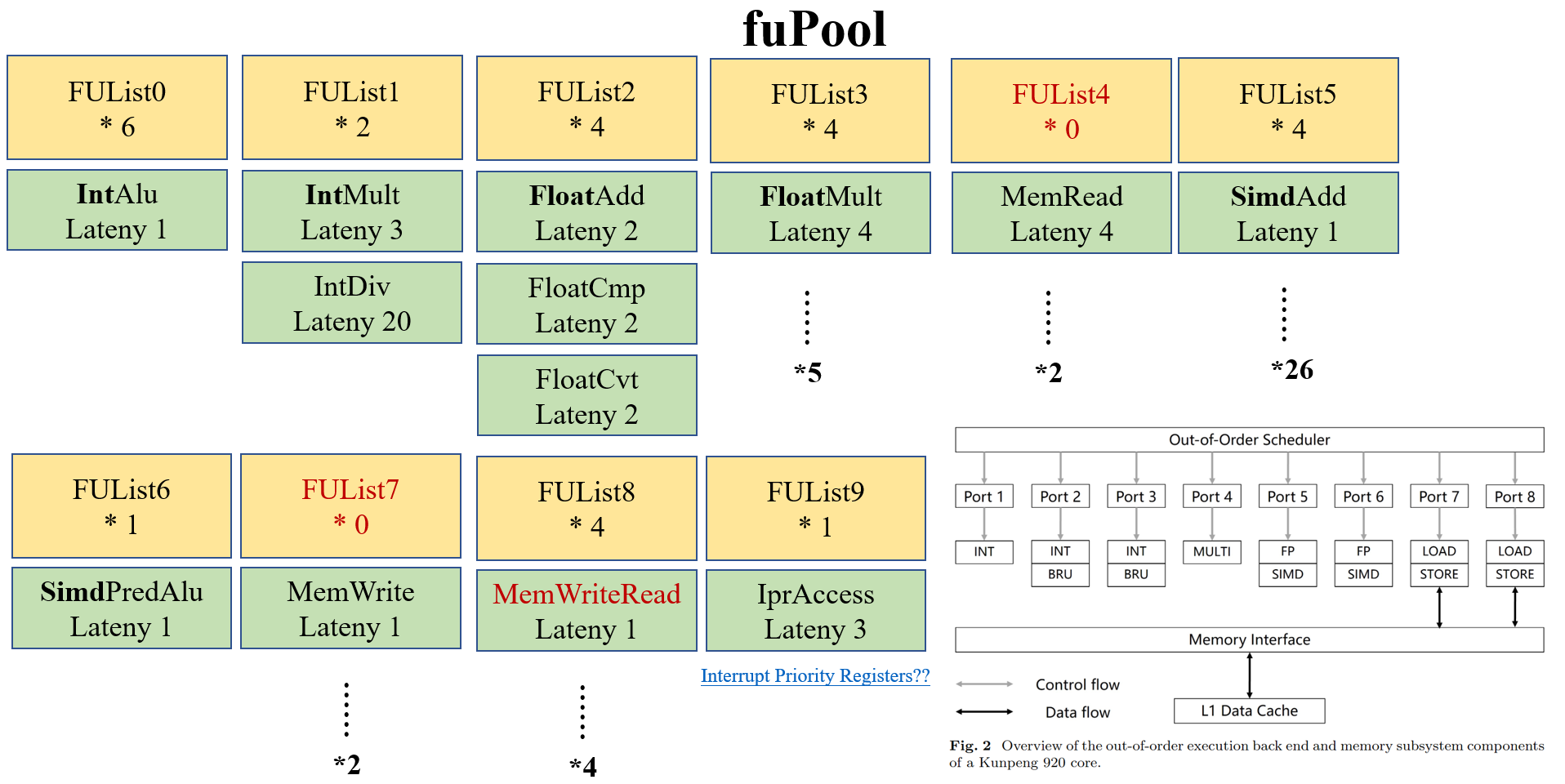
perf stat test.exe, 可参考本博客perf文章暂无
暂无
编写脚本/var/services/homes/shaojiemike/wgReboot.sh
#!/bin/bash
ip ro add default via 222.195.90.254 dev eth0 table eth0-table
ip ro a 114.214.233.0/24 via 222.195.90.254 dev eth0 src 222.195.90.2 table main
wg-quick up wg1
ip ro d default via 222.195.90.254 dev eth0 src 222.195.90.2 table main
chmod +xbash /var/services/homes/shaojiemike/wgReboot.sh暂无
暂无
无
默认是不开启的,文件/etc/rc.local默认也不存在
/etc/systemd/system目录下启动即可ln -fs /lib/systemd/system/rc-local.service /etc/systemd/system/rc-local.servicetouch /etc/rc.local
chmod 755 /etc/rc.local
vim /etc/rc.local
eg. #!/bin/bash echo "test rc " > /var/test.log
/etc/init.d目录下建立文件testsudo chmod +x /etc/init.d/test方法一:使用update-rc.d 命令将脚本放到启动脚本中去(debian中可以使用更新的insserv):
注:其中数字95是脚本启动的顺序号,按照自己的需要相应修改即可。在你有多个启动脚本,而它们之间又有先后启动的依赖关系时你就知道这个数字的具体作用了。更多说明建议看man update-rc.d。
方法二:手动在rc*.d中建立软连接
rc*.d,*代表启动级别,在不同启动级别启动, K开头的脚本文件代表运行级别加载时需要关闭的, S开头的代表相应级别启动时需要执行, 数字代表顺序
使用sudo systemctl enable xxx
systemctl is-enabled servicename.service #查询服务是否开机启动
systemctl enable *.service #开机运行服务
systemctl disable *.service #取消开机运行
systemctl start *.service #启动服务
systemctl stop *.service #停止服务
systemctl restart *.service #重启服务
systemctl reload *.service #重新加载服务配置文件
systemctl status *.service #查询服务运行状态
systemctl --failed #显示启动失败的服务
/etc/systemd/system/读取配置文件。/usr/lib/systemd/system/,真正的配置文件存放在那个目录。systemctl enable命令用于在上面两个目录之间,建立符号链接关系。
> $ sudo systemctl enable [email protected]
# 等同于
$ sudo ln -s '/usr/lib/systemd/system/[email protected]' '/etc/systemd/system/multi-user.target.wants/[email protected]'
>
systemctl enable命令相当于激活开机启动。
* 与之对应的,systemctl disable命令用于在两个目录之间,撤销符号链接关系,相当于撤销开机启动。
> $ sudo systemctl disable [email protected]
>
sshd.socket。
* 如果省略,Systemd 默认后缀名为.service,所以sshd会被理解成sshd.service。
进入目录/usr/lib/systemd/system,修改webhook.service
[Unit]
Description=Webhook receiver for GitHub
[Service]
Type=simple
ExecStart=/usr/local/bin/webhook
[Install]
WantedBy=multi-user.target
Loaded: loaded (/etc/systemd/system/webhook.service; enabled;这个enabled就是开机启动的意思
暂无
暂无
https://neucrack.com/p/91
Codeforces: Another good platform with nice contests where you will get to learn new things that will improve your understanding of concepts. It's ratings don't matter to recruiters but the things you'll learn will help you during interviews and company's coding tests.
TOPCODER: This caters to every aspect of software develpment. They have both designing and development contest. Major companies provide Topcoder community to experment with their nw products or APIs. But if you want to mention it in your CV, your ratings should be above 1400 to impress a recruiter.
for average is CODEFORCES, for expert TOPCODER
<1200或者unrated(即注册但还没参加过比赛的)参加Div II,>=1200的参加Div I。暂无
暂无
https://blog.csdn.net/qiuzhenguang/article/details/5552122
https://zhuanlan.zhihu.com/p/540098105