DRAM types: Size, Latency, Bandwidth, Energy Consumption
这篇文章主要聚焦于各种计算设备的DRAM的参数,以及发展趋势。
这篇文章主要聚焦于各种计算设备的DRAM的参数,以及发展趋势。
网站解析 当您想在Internet上通过域名访问您的网站时,可以通过华为云的云解析服务为域名添加解析记录。
例如,搭建一个网站服务器,采用IPv4格式的弹性IP地址。如果想要实现通过域名“example.com”及其子域名“www.example.com”访问该网站,需要配置如下解析记录:
A:添加域名“example.com”到弹性IP地址的解析记录。
A:添加子域名“www.example.com”到弹性IP地址的解析记录。
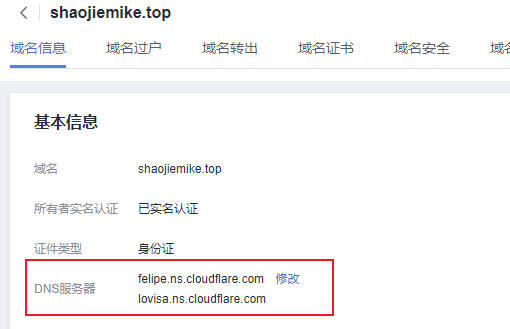 不要修改成域名解析的
不要修改成域名解析的
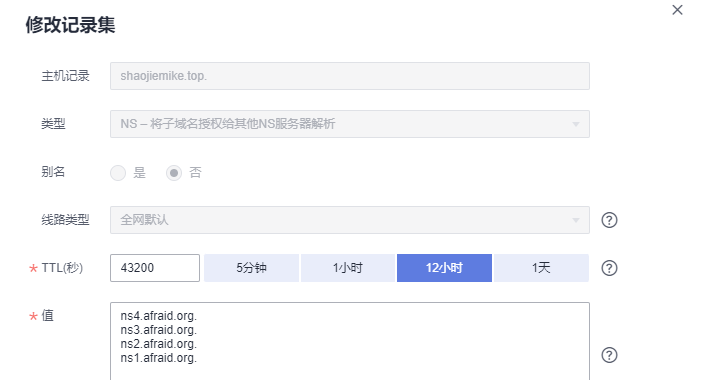
# shaojiemike @ node6 in ~ [21:24:21]
$ dig +trace shaojiemike.us.to
; <<>> DiG 9.16.1-Ubuntu <<>> +trace shaojiemike.us.to
;; global options: +cmd
. 184 IN NS f.root-servers.net.
. 184 IN NS h.root-servers.net.
. 184 IN NS c.root-servers.net.
. 184 IN NS m.root-servers.net.
. 184 IN NS g.root-servers.net.
. 184 IN NS j.root-servers.net.
. 184 IN NS a.root-servers.net.
. 184 IN NS i.root-servers.net.
. 184 IN NS l.root-servers.net.
. 184 IN NS k.root-servers.net.
. 184 IN NS d.root-servers.net.
. 184 IN NS e.root-servers.net.
. 184 IN NS b.root-servers.net.
;; Received 262 bytes from 127.0.0.53#53(127.0.0.53) in 0 ms
to. 172800 IN NS frankfurt.tonic.to.
to. 172800 IN NS singapore.tonic.to.
to. 172800 IN NS tonic.to.
to. 172800 IN NS newyork.tonic.to.
to. 172800 IN NS colo.tonic.to.
to. 172800 IN NS sydney.tonic.to.
to. 172800 IN NS helsinki.tonic.to.
to. 86400 IN NSEC today. NS RRSIG NSEC
to. 86400 IN RRSIG NSEC 8 1 86400 20221118050000 20221105040000 18733 . zYyPgXiUoIoPzZsXi8WD0aT0Ps7ajmQYA/blzyfNG6Pl1NdONShc/3T1 3p2rAfr2a7NI6SI+yeEyiRYeeI86RuNv1u4aAJD2QXZapKlogP+hveb/ SYztzsr70Ha6/7RQAqQqY+ctHOZXIzUMhpNxFneTXcJ2CVhQmGIYG0sa 0BmaDKH0kxFHtbJZvENMpo4WrE0KTNzFsYlHZQGZV0OQeU/MpcSkPt5I DefxNVBMqMS8lF0Wzg8ESwEDddE7WvMlCNlnBLE7LHk0ZdQGU5Qg/8Ot CpNKEjCoROXA7sA/CkrGEdhW3CZnJYOdQ6UcH2pDwYYVIOsE7L8QJV/r RC9/tA==
;; Received 653 bytes from 199.7.83.42#53(l.root-servers.net) in 60 ms
us.to. 86400 IN NS NS4.AFRAID.ORG.
us.to. 86400 IN NS NS3.AFRAID.ORG.
us.to. 86400 IN NS NS1.AFRAID.ORG.
us.to. 86400 IN NS NS2.AFRAID.ORG.
;; Received 156 bytes from 95.216.159.42#53(helsinki.tonic.to) in 272 ms
us.to. 3600 IN SOA ns1.afraid.org. dnsadmin.afraid.org. 2211050595 86400 7200 2419200 3600
;; Received 133 bytes from 2001:1850:1:5:800::6b#53(NS2.AFRAID.ORG) in 260 ms
可以看到13个根DNS服务器到to子服务器再到us.to的解析过程。
在“公网域名”页面的域名列表的“域名”列,单击域名的名称“example.com”。 进入“解析记录”页面。
在页面右上角,单击“添加记录集”。 在“添加记录集”页面,根据界面提示为域名“example.com”设置A记录集参数。

主机记录:设置为“www”,表示解析的域名为子域名“www.example.com”。
测试域名解析是否生效
D:\OneDrive - mail.ustc.edu.cn\homepage> nslookup shaojiemike.top ns1.huaweicloud-dns.org
Server: ecs-159-138-77-159.compute.hwclouds-dns.com
Address: 159.138.77.159
Name: shaojiemike.top
Address: 202.38.73.26

云服务器Elastic Compute Service(ECS)是阿里云提供的一种基础云计算服务。它能帮助您快速的构建更稳定、安全的应用,提高运维效率,降低IT成本
有这么一种情况:拉的联通的带宽,分配的IP只能在联通内部访问,移动网络不能访问。这个IP最多只能算是“联通内的公网IP”,不是真的公网IP。
上面几部分IP都可称为内网IP
貌似node5 与 node6 挂了网络通,是动态公网IP(chivier说的)
node5 ip: 202.38.73.26
IPv4封了许多端口(至少ssh的22端口是不行的)
IPv6是直接可以ssh访问的
ipv4是32位地址,分成4段,每段之间都有"."分开,而每段之间有8位,从0-255 最普遍看到的就是ipv4
ipv6是128位地址,每个数目等于4位(0-f)16位进制,4个一组,每段之间由“:”隔开,共有8段,其中如果有连续性的"0" 如fe80:0000:0000:0000:0000:0000:0000:de4f
IPv4DNS服务器能根据IP修改,但是我不知道华为DNS服务器的IP。
ns1.huaweicloud-dns.com:中国大陆各区域DNS地址 ns1.huaweicloud-dns.cn:中国大陆各区域DNS地址 ns1.huaweicloud-dns.net:除中国大陆之外国家或地区DNS地址 ns1.huaweicloud-dns.org:除中国大陆之外国家或地区DNS地址
动态公网IP,可以使用nat123动态域名解析解决公网IP不固定的问题
node6配置没用80端口,不能直接IP访问
还是不能直接访问shaojiemike.top(TTL为300,需要时间?) 第二天可以了。
https://ngx.hk/2019/01/27/%E4%BD%BF%E7%94%A8acme-sh%E4%B8%8E%E9%98%BF%E9%87%8C%E4%BA%91dns%E7%AD%BE%E5%8F%91lets-encrypt%E7%9A%84%E5%85%8D%E8%B4%B9%E6%95%B0%E5%AD%97%E8%AF%81%E4%B9%A6.html
我用阿里的域名,用这个教程,把我的IP挂到阿里DNS上面去了
https://support.huaweicloud.com/qs-dns/dns_qs_0002.html
https://blog.csdn.net/meitesiluyuan/article/details/58588216
https://blog.csdn.net/bennny/article/details/86319768?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.baidujs&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.baidujs
https://blog.csdn.net/bennny/article/details/82988260
导言
服务器没网,姜师兄说可以ssh转发网络请求到本地windows
SSH 端口转发自然需要 SSH 连接,而SSH 连接是有方向的,从 SSH Client 到 SSH Server 。
而我们所要访问的应用也是有方向的,应用连接的方向也是从应用的 Client 端连接到应用的 Server 端。比如需要我们要访问Internet上的Web站点时,Http应用的方向就是从我们自己这台主机(Client)到远处的Web Server。
如果SSH连接和应用的连接这两个连接的方向一致,那我们就说它是本地转发。
ssh -L [bind_address:]port:host:hostport <SSH hostname>
ssh -L 3333:127.0.0.1:2333 -vN -f -l shaojiemike 222.195.72.218
debug1: Local connections to LOCALHOST:3333 forwarded to remote address(222.195.72.218) 127.0.0.1:2333
 本地转发在本地这台机器上监听一个端口,然后所有访问这个端口的数据都会通过ssh 隧道传输到远端的对应端口上。命令中的 host 和
本地转发在本地这台机器上监听一个端口,然后所有访问这个端口的数据都会通过ssh 隧道传输到远端的对应端口上。命令中的 host 和 <SSH hostname> 可以是不同的主机。
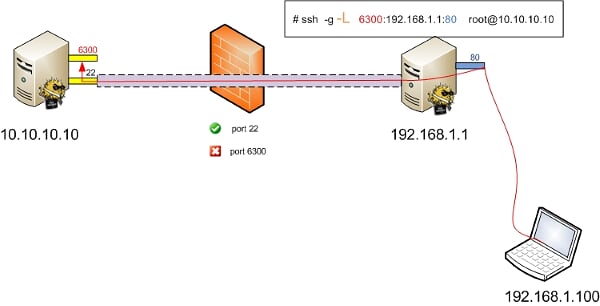
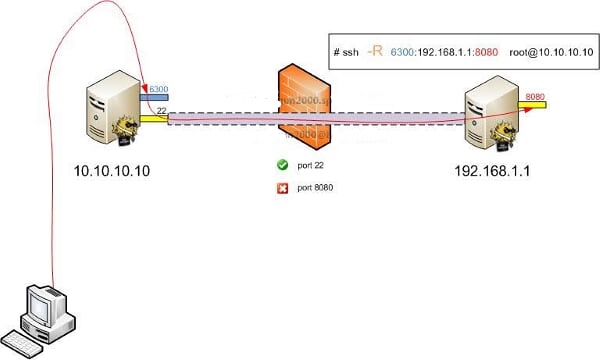
如果SSH连接和应用的连接这两个连接的方向不同,那我们就说它是远程转发。
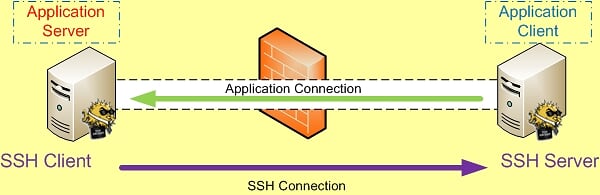
远程转发与本地转发正好相反,打开ssh隧道以后,在远端服务器监听一个端口,所有访问远端服务器指定端口都会通过隧道传输到本地的对应端口上,下面是例子。
-C:压缩数据传输。
-f :后台认证用户/密码,通常和-N连用,不用登录到远程主机。
-N :不执行脚本或命令,通常与-f连用。
-g :在-L/-R/-D参数中,允许远程主机连接到建立的转发的端口,如果不加这个参数,只允许本地主机建立连接。
-f Requests ssh to go to background just before command execution. This is useful if ssh is going to ask for passwords or
passphrases, but the user wants it in the background. This implies -n. The recommended way to start X11 programs at a remote
site is with something like ssh -f host xterm.
If the ExitOnForwardFailure configuration option is set to "yes", then a client started with -f will wait for all remote port
forwards to be successfully established before placing itself in the background.
将发往本机的80端口访问转发到174.139.9.66的8080端口
ssh -C -f -N -g -L 80:174.139.9.66:8080 [email protected]
将发往174.139.9.66的8080访问转发到本机的80端口
ssh -C -f -N -g -R 80:174.139.9.66:8080 [email protected]
使用远程管理服务器上的MySQL
ssh -C -f -N -g -L 80:174.139.9.66:8080 [email protected]
一次同时映射多个端口
反向隧道技术:节假日需要回公司加班。但是公司是内网,使用NAT,所以没办法连回去。
端口转发:本机不允许访问www.xxx.com这个网站,但是远程主机(remote_ip)可以。
现在我们就可以在本地打开 http://localhost:31609 访问www.xxx.com了。
SOCKS代理:本机不允许访问某些网站,但是远程主机(remote_ip)可以,并且公司没有组织你连接remote_ip。
现在在浏览器socks 5 proxy设置为localhost:8888,所有之前无法访问的网站现在都可以访问了。
假设本地主机A提供了HTTP服务,主机B无网络
通过访问 http://host-B 来访问主机A上的HTTP服务了。
如果没有主机B的root账号,则只能远程转发到1024以后的端口号
通过访问http://host-B:8080 来访问主机A上的HTTP服务
.ssh/config修改
Host *
ControlPersist yes
ControlMaster auto
ControlPath /tmp/sshcontrol-%C
ControlPersist 1d
# 以上四条配合使用,实现多条ssh连接共享,而且保持1天内ssh存在。再次执行ssh命令几乎秒连
TCPKeepAlive=yes
# 发送空TCP包来保持连接,但是可能被防火墙过滤
ServerAliveInterval 30
# 表示每隔多少秒(30秒),从客户端向服务器发送一次心跳(alive检测)
# 心跳具体格式: debug1: client_input_global_request: rtype [email protected] want_reply 1
ServerAliveCountMax 240
# 表示服务端多少次(240次)心跳无响应后, 客户端才会认为与服务器到SSH链接已经断开,然后断开连接。
Port 443
Host *
ForwardAgent yes
# 可以讓本地的 SSH Key 在遠端 Server 上進行轉送,也就是经过跳板机Server1,使用本地key访问Server2,不用把key传到Server1上导致泄露
# 虽然Server1不会获得key,但是可以使用key。所以该选项不宜用于Host *,应该只添加您信任的服务器以及打算用于代理转发的服务器。
# 注意跳板机需要设置允许代理转发, /etc/ssh/sshd_config 将AllowAgentForwarding的值设置为yes, 并重启服务
AddKeysToAgent yes
ForwardX11 yes
ForwardX11Trusted yes
Compression yes
# 压缩,加快数据传输速度
更改ssh服务器的配置文件/etc/ssh/sshd_config
原理同上 重启ssh服务以使配置生效
我们可以把这个映射的端口绑定在0.0.0.0的接口上,方法是加上参数-b 0.0.0.0。
同时修改SSH服务器端 /etc/sshd_config中 GatewayPorts no为 GatewayPorts yes来打开它。
本地网络代理到服务器
ssh -fNgR 7333:127.0.0.1:7890 [email protected]
ssh -fNgR 7333:127.0.0.1:80 [email protected]
7333数字不要太小,以免冲突。7890是本地clash端口,80也可以。#YJH proxy
export proxy_addr=localhost
export proxy_http_port=7890
export proxy_socks_port=7890
function set_proxy() {
export http_proxy=http://$proxy_addr:$proxy_http_port #如果使用git 不行,这两个http和https改成socks5就行
export https_proxy=http://$proxy_addr:$proxy_http_port
git config --global https.proxy http://$proxy_addr:$proxy_http_port
git config --global https.proxy https://$proxy_addr:$proxy_http_port
export all_proxy=socks5://$proxy_addr:$proxy_socks_port
export no_proxy=127.0.0.1,.huawei.com,localhost,local,.local
}
function unset_proxy() {
git config --global --unset http.proxy
git config --global --unset https.proxy
unset http_proxy
unset https_proxy
unset all_proxy
}
function test_proxy() {
curl -v -x http://$proxy_addr:$proxy_http_port https://www.google.com | egrep 'HTTP/(2|1.1) 200'
# socks5h://$proxy_addr:$proxy_socks_port
}
# set_proxy # 如果要登陆时默认启用代理则取消注释这句
export http_proxy=http://127.0.0.1:7333
# wget 正常使用
export all_proxy=socks5://127.0.0.1:7333
# git 正常使用
unset http_proxy
unset all_proxy
特定软件也需要设置代理
git config --global https.proxy http://127.0.0.1:1080
git config --global https.proxy https://127.0.0.1:1080
git config --global http.proxy 'socks5://127.0.0.1:1080'
git config --global https.proxy 'socks5://127.0.0.1:1080'
git config --global --unset http.proxy
git config --global --unset https.proxy
首先看看Windows上的输出
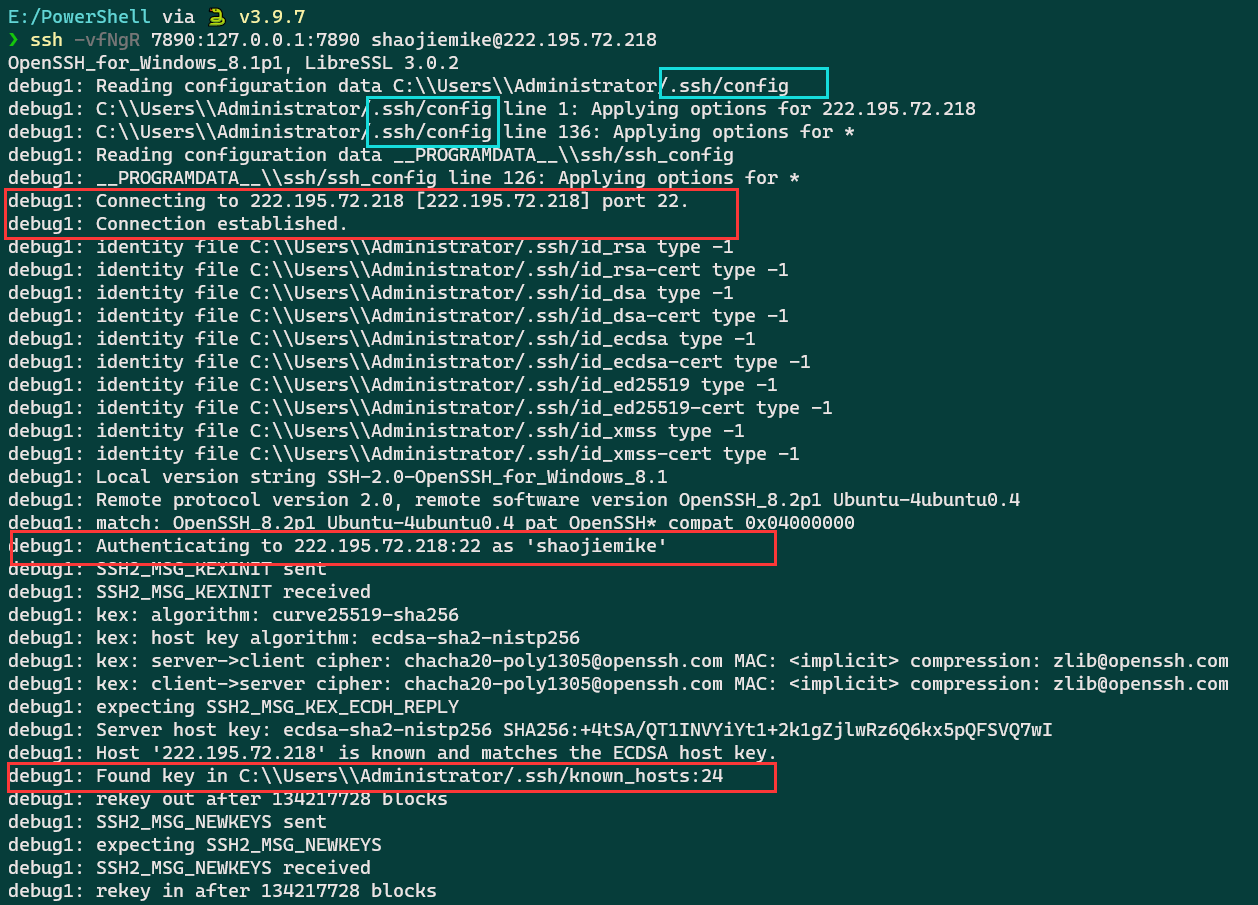
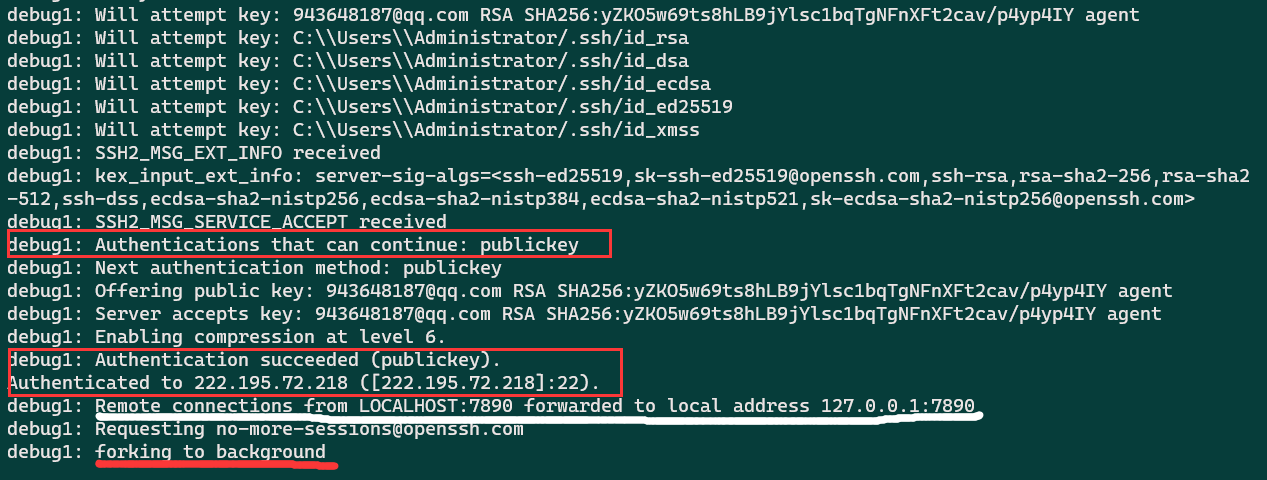
Mac的错误
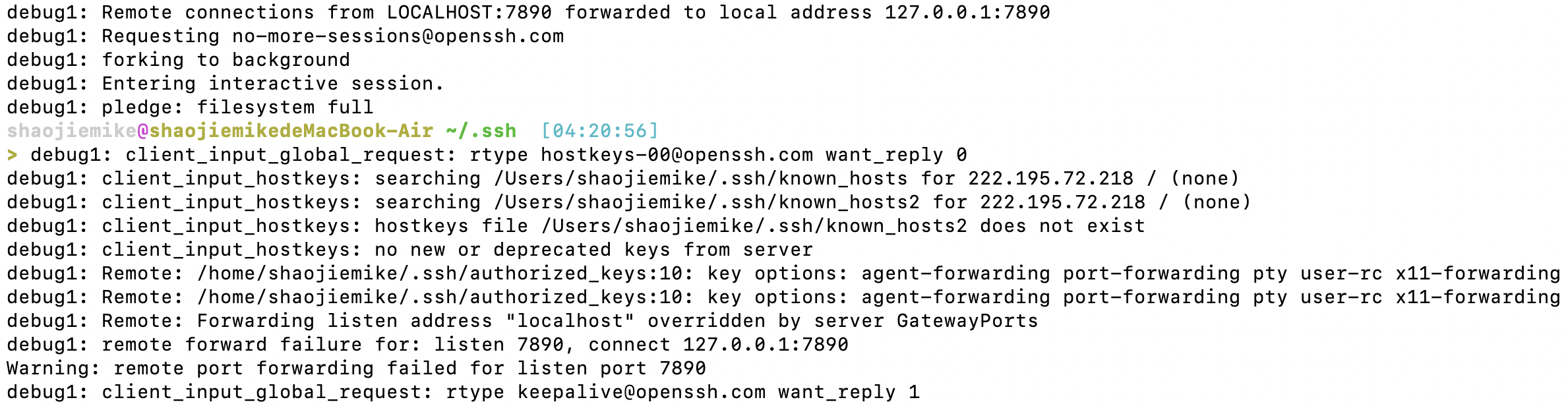
在完成windows所有输出后,
debug1: Remote: Forwarding listen address "localhost" overridden by server GatewayPorts
debug1: remote forward failure for: listen 7890, connect 127.0.0.1:7890
Warning: remote port forwarding failed for listen port 7890
猜测应该是已经端口占用了

首先,可以选择换端口,换成 7233
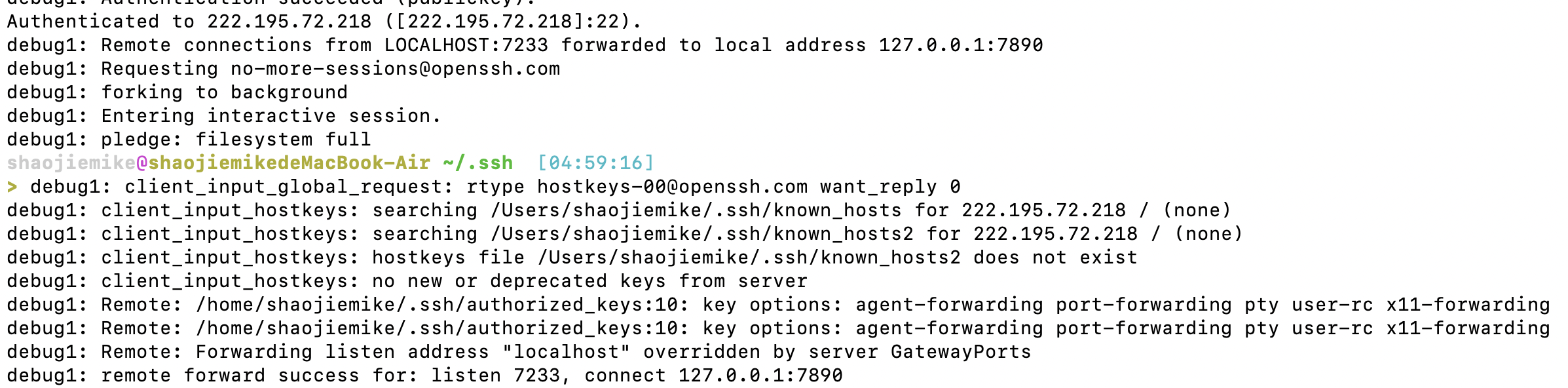
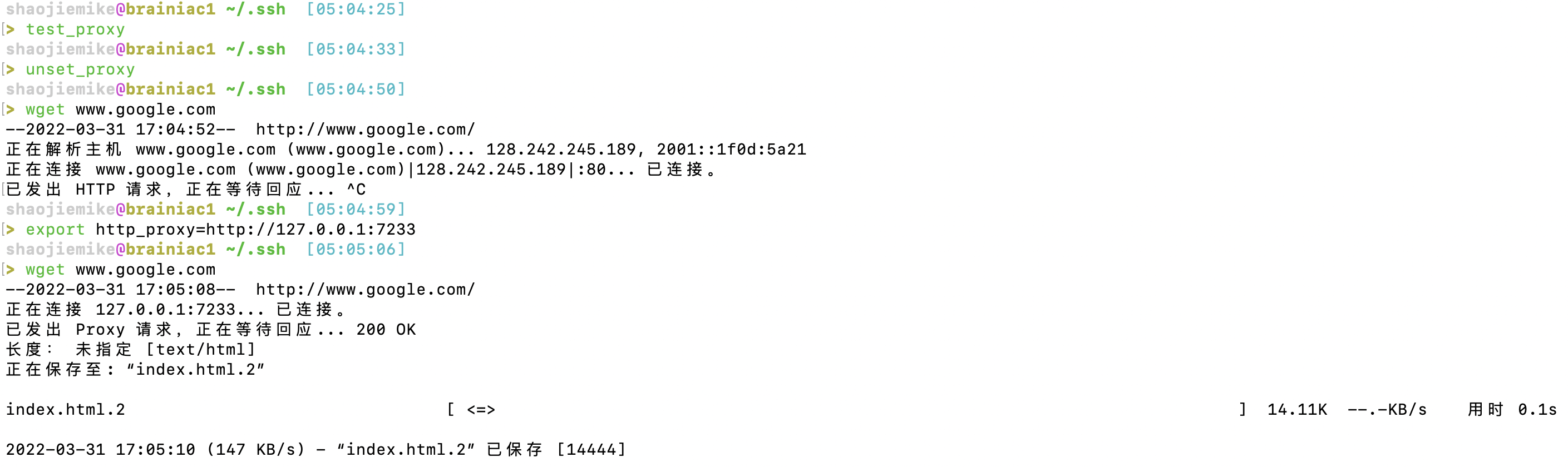
 2. wget验证
2. wget验证
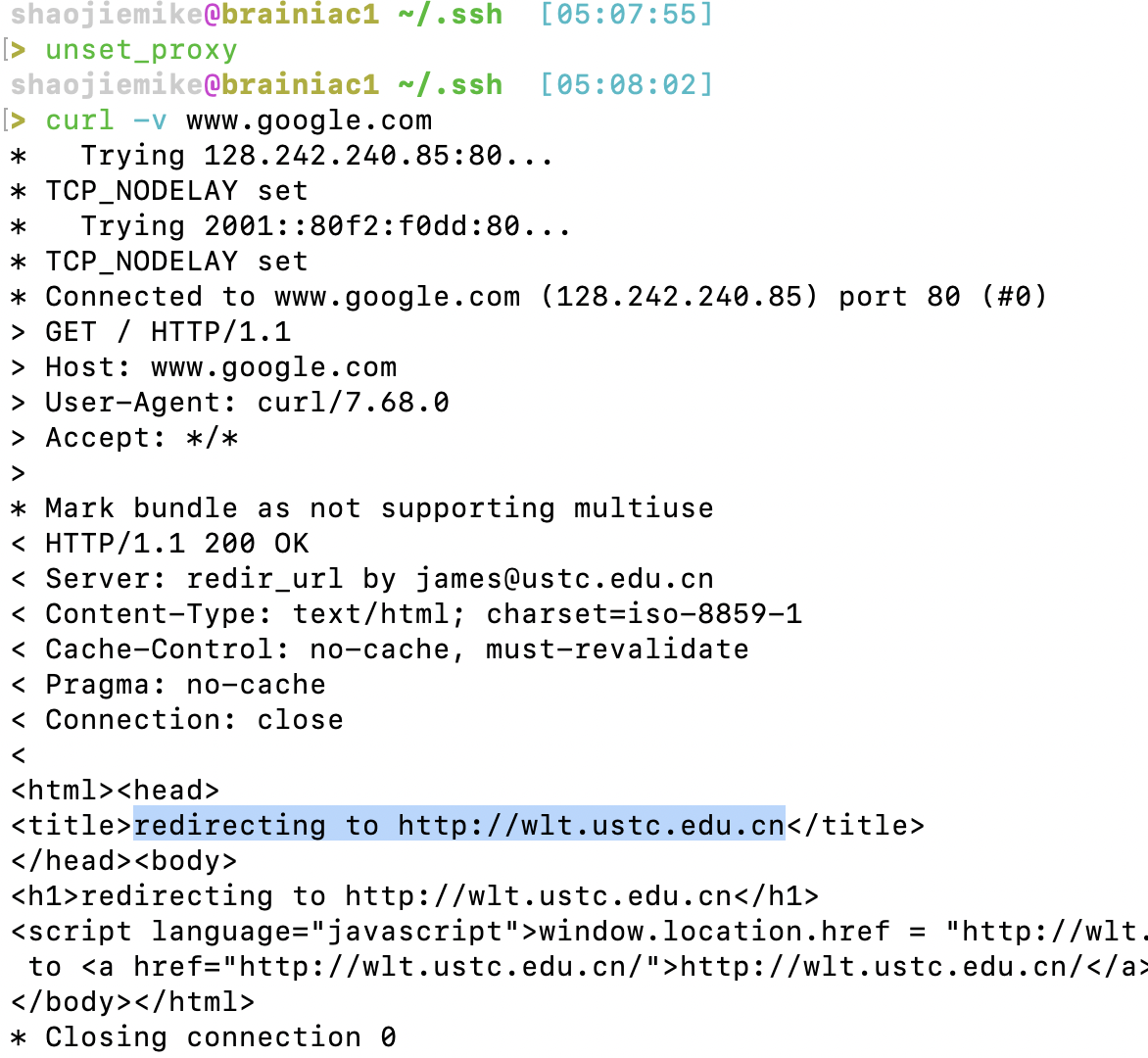
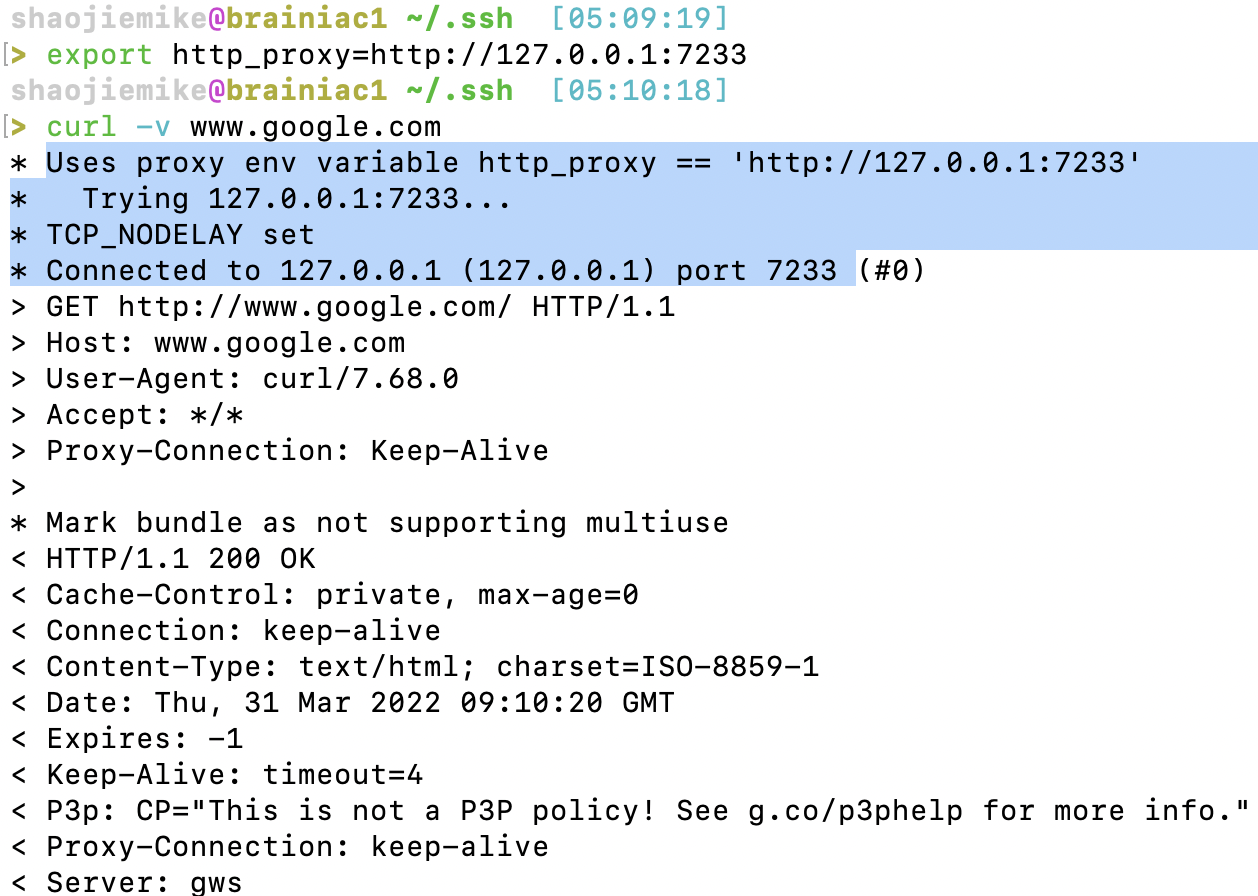
 3. curl验证(原本会走WLT)
3. curl验证(原本会走WLT)
sudo lsof -i TCP:7890
sudo kill -9 process_id_1 process_id_2 process_id_3
sudo ps -ef | grep 'nc -X' | grep -v grep | awk '{print $2}' | sudo xargs -r kill -9
sudo lsof -i TCP:7233 |grep shaojiemike| awk '{print $2}'|sudo xargs -r kill -9

http://blog.sina.com.cn/s/blog_704836f40100lwxh.html
https://blog.csdn.net/xyyangkun/article/details/7025854?utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1.no_search_link&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1.no_search_link
RAM (random access memory), 中文名叫随机存储器, 随机是什么意思呢? 意思是, 给定一个地址, 可以立即访问到数据(访问时间和位置无关)
而不像咱们熟悉的磁带, 知道最后一首歌在最后的位置, 却没法直接一下子跳到磁带的最后部门, 所以磁带不是随机存储器, 而是顺序存储器。
SRAM (Static Random Access Memory) and DRAM (Dynamic Random Access Memory)
| BASIS FOR COMPARISON | SRAM | DRAM |
|---|---|---|
| Speed | Faster | Slower |
| Size | Small | Large |
| Cost | Expensive | Cheap |
| Used in | Cache memory | Main memory |
| Density | Less dense | Highly dense |
| Construction | Complex and uses transistors and latches. | Simple and uses capacitors and very few transistors. |
| Single block of memory requires | 6 transistors | Only one transistor. |
| Charge leakage property | Not present | Present hence require power refresh circuitry |
| Power consumption | Low | High |
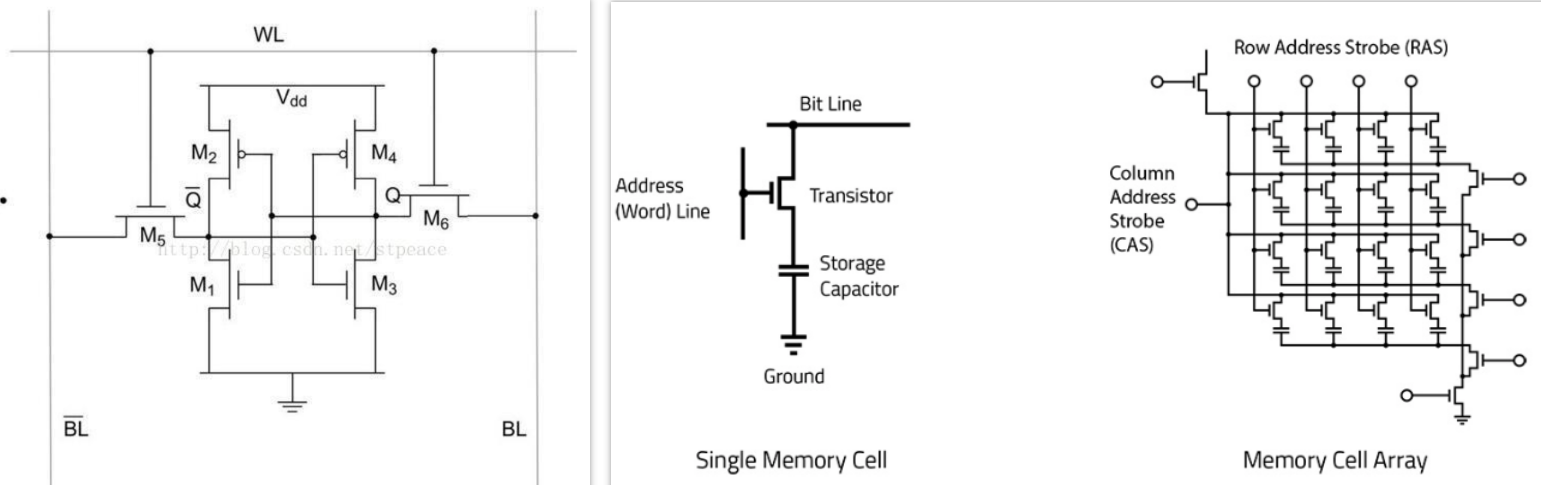
左边的是静态的,右边的是dynamic的。
SRAM,保存一个bit需要6个晶体管。
DRAM 存储一个bit的DRAM只需要一个电容和一个晶体管。 DRAM的数据实际上是存在于电容里面的, 电容会有电的泄露, 损失状态, 故需要对电容状态进行保持和刷新处理, 以维持持久状态, 而这是需要时间的, 所以就慢了。而且很耗电。
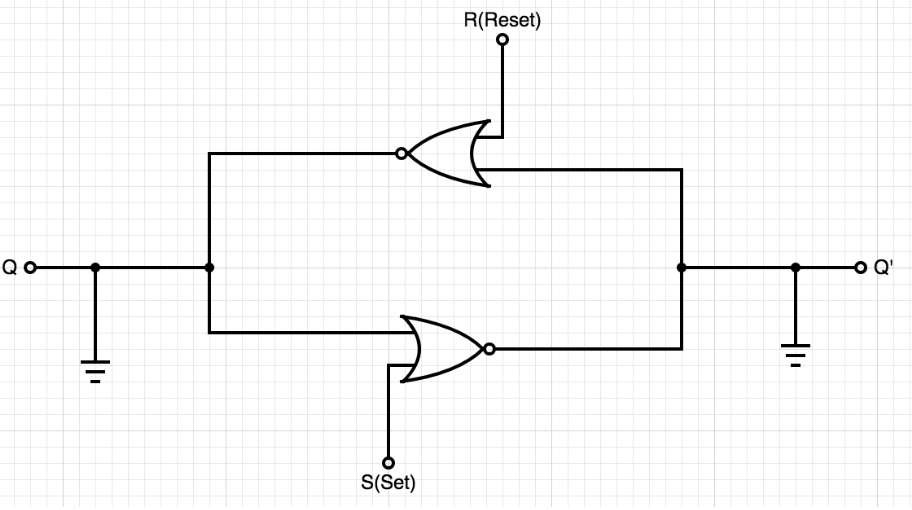
DRAM内存实现的存储是通过晶体管实现的一个电路 门控D锁存器,其更简化的形式是 SR锁存器,电路结构如下图:
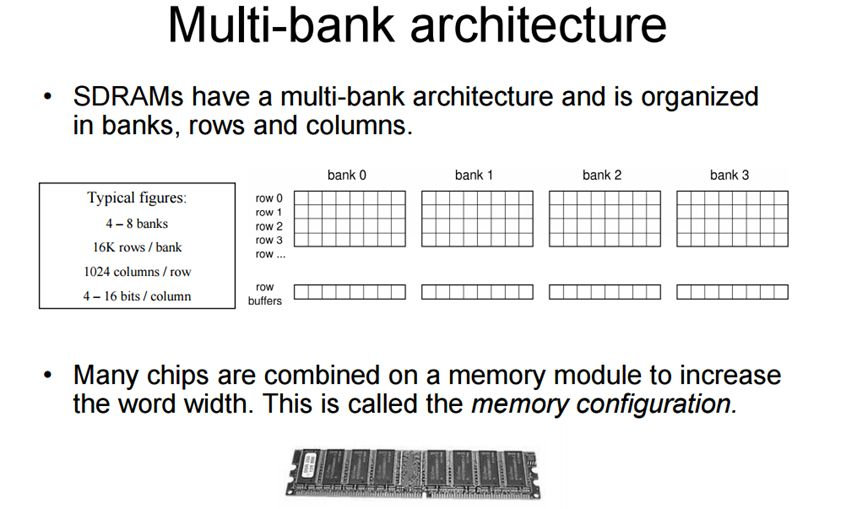
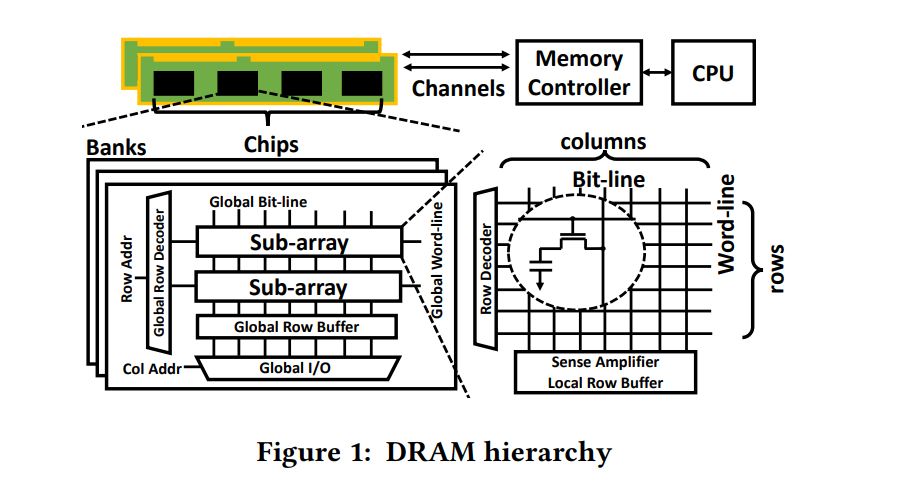
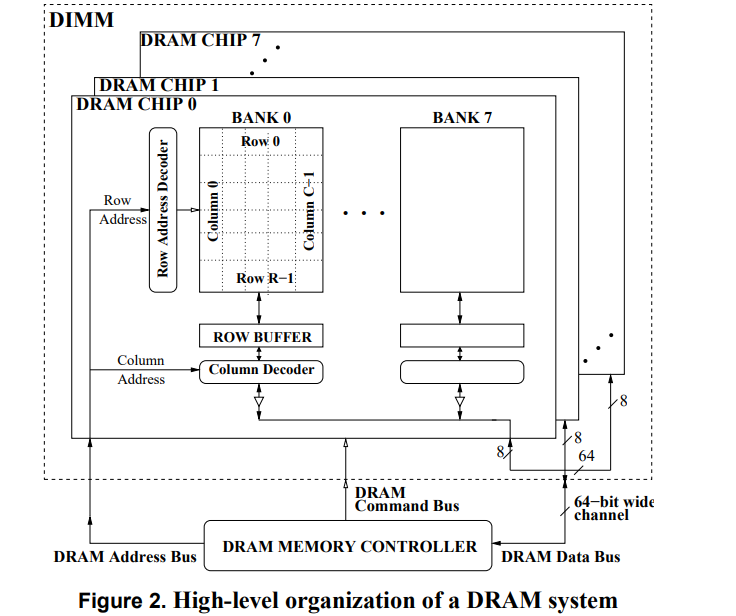
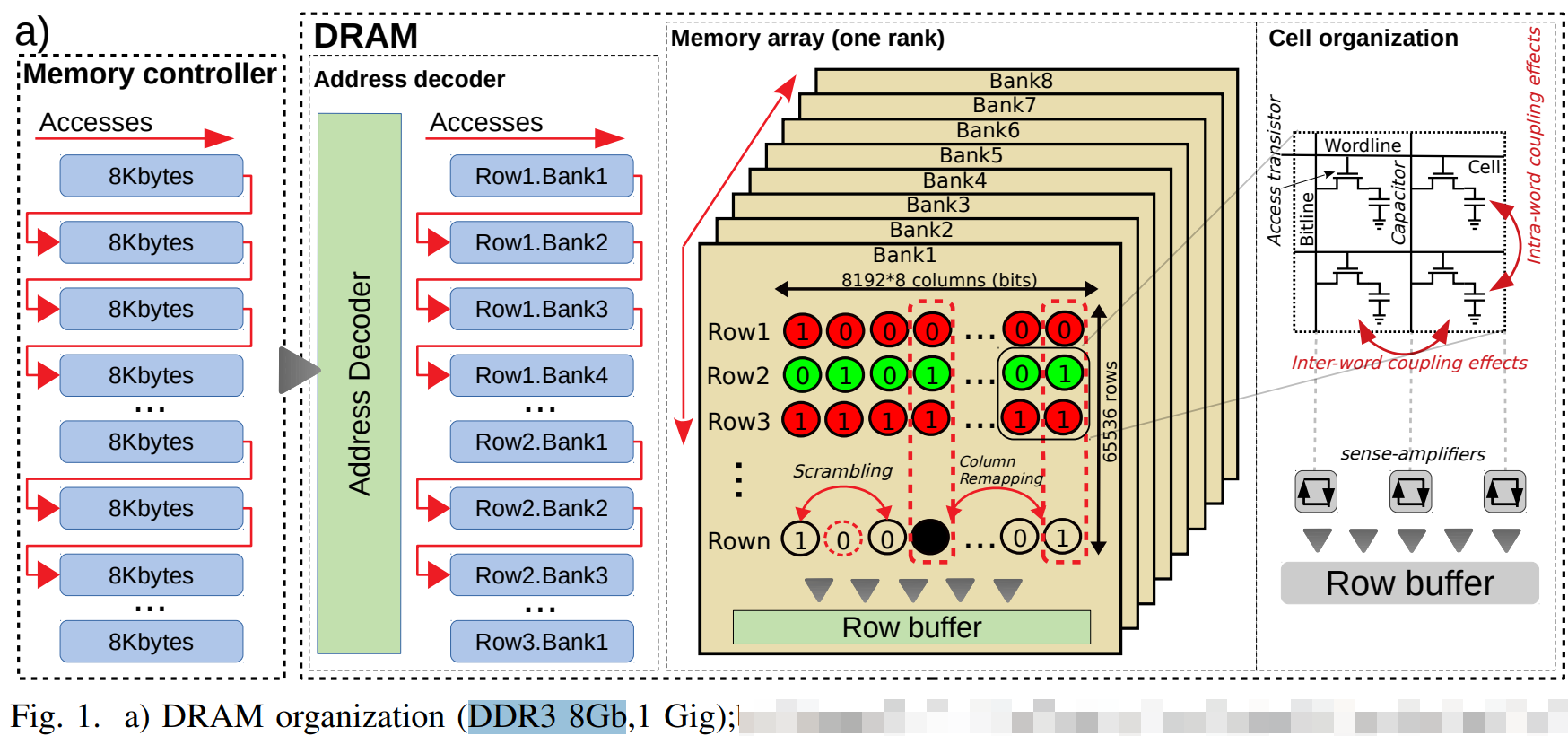
但是bank矩阵的一个点(基本存储单元, 寻址能力, 内存颗粒(Chip)的位宽)一般是8bit.
8个 门控D锁存器 组成内存的基本(最小)存储单元,他们共用一个行/列 地址线。在一次寻址中每个内存颗粒返回 8 bit的数据 8个内存可以同时寻址 最终得到的是 8 * 8(8个chip) = 64 bit 的连续数据 也就是说 内存一次寻址可以读取 8 Byte 的数据,这里也能说明在C语言中的内存不齐的原因(减少寻址次数)。
现在的DRAM一般都是SDRAM,即Synchronous Dynamic Random Access Memory,同步且能自由指定地址进行数据读写。其结构一般由许多个bank组成并利用以达到自由寻址。
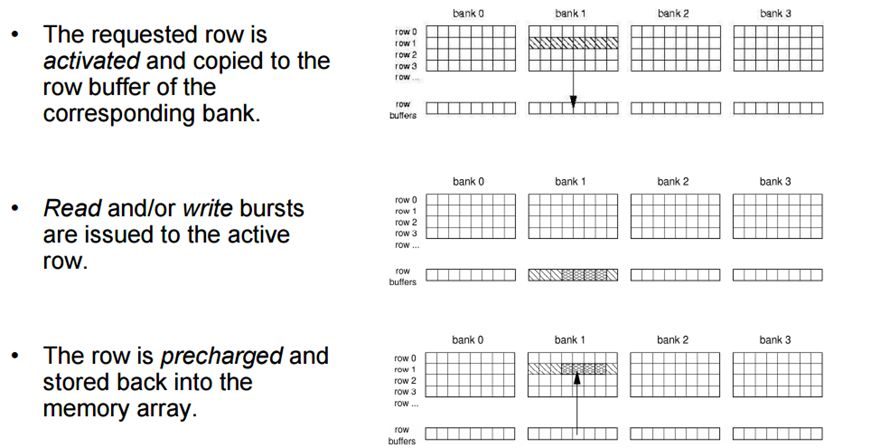
chip的多 Bank 的设计允许向每个Bank 发出不同的命令。同一时刻,不同的bank可以处理不同的行地址。当然,不可能同时读取或者写入多个 Bank,因为读写通道只有 1 个,当时可以在 1 个 Bank 读写时,向另一个 Bank 发出 Precharge 或者 Active 命令。
| 名词 | 解释 |
|---|---|
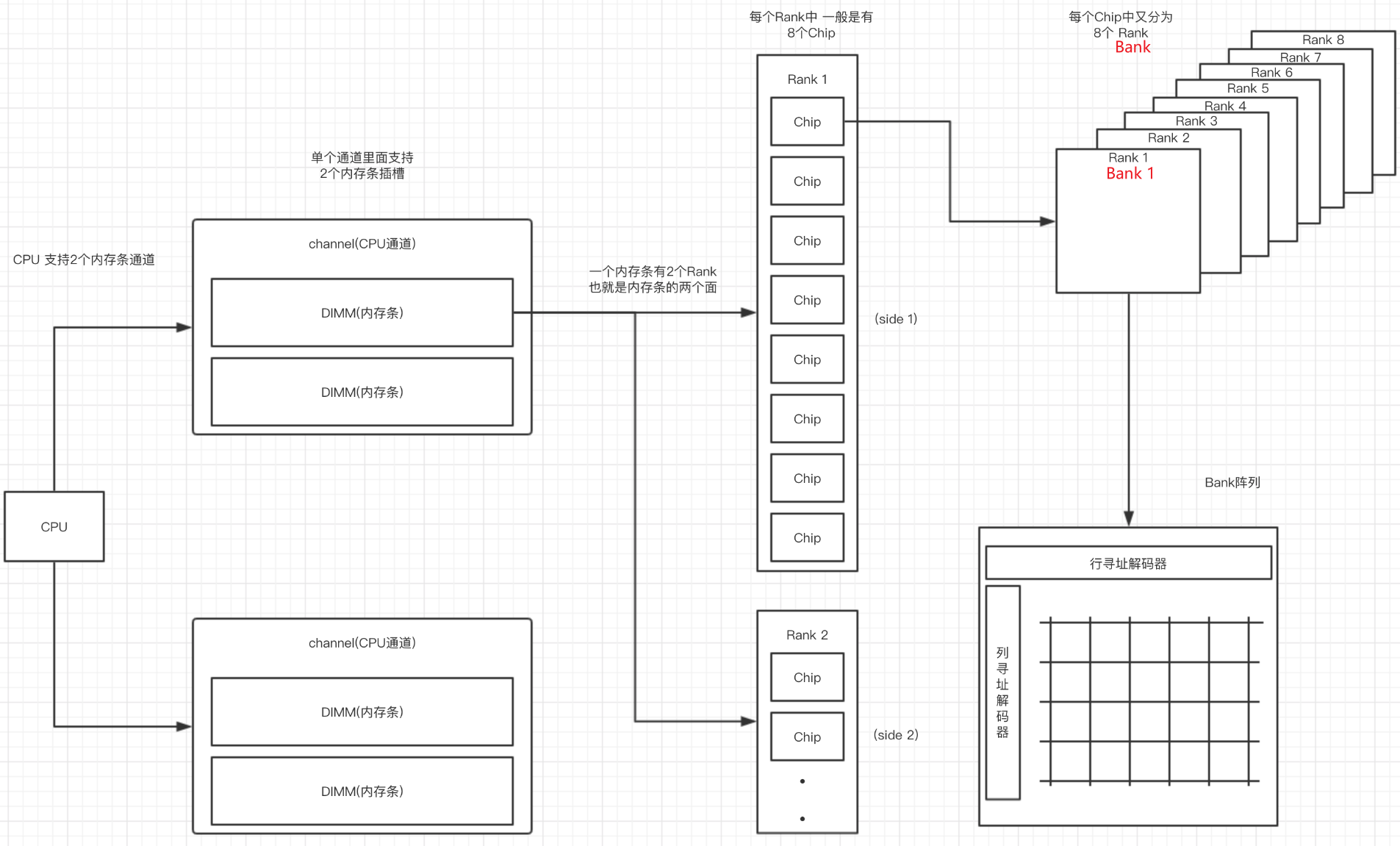
| dual inline memory modules (DIMMs). | 每个channel可以连接多个DIMM,每个DIMM与多个DRAM chip相联 |
| Cell: | 颗粒中的一个数据存储单元叫做一个Cell,由一个电容和一个N沟道MOSFET组成。 |
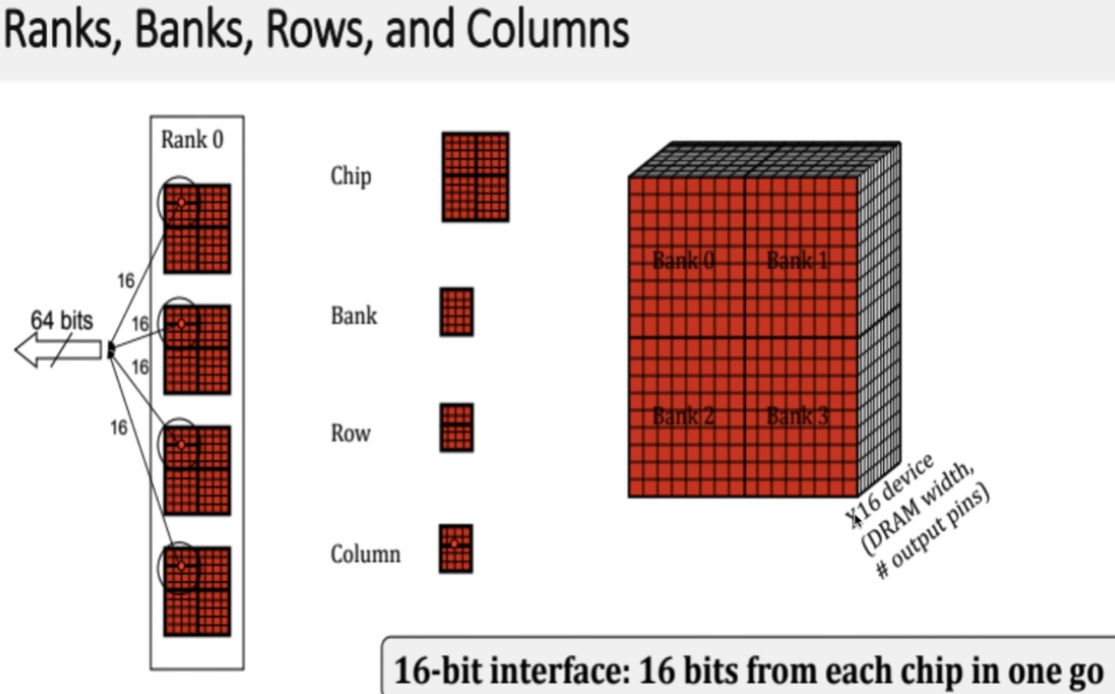
| chip: | 一个颗粒叫做一个chip。一根内存的内存带宽是64bit,如果是单面就是8个8bit颗粒,如果是双面,那就是16个4bit的颗粒分别在两面,不算ECC颗粒(Error Checking and Correcting错误校验芯片)。 |
| Bank | 每个chip有4~8个bank,每个bank可以看作一个行列矩阵,每个点存储4~16bit的信息。 |
| Rank: | 内存PCB的一面所有颗粒叫做一个rank,目前在Unbuffered台式机内存上,通常一面是8个颗粒,所以单面内存就是1个rank,8个chip |
| 寻址空间 | 是指内存总共可以存储多少个地址,比如一个2G DDR3内存 ,每个Rank是2/1=1G ,每个内存颗粒是1/8=128M 每个Bank是 128/8=16M 16M = 2^4 * 2^10 = 2^14 也就是地址线需要14根 正对应地址线的 A0-A13 |
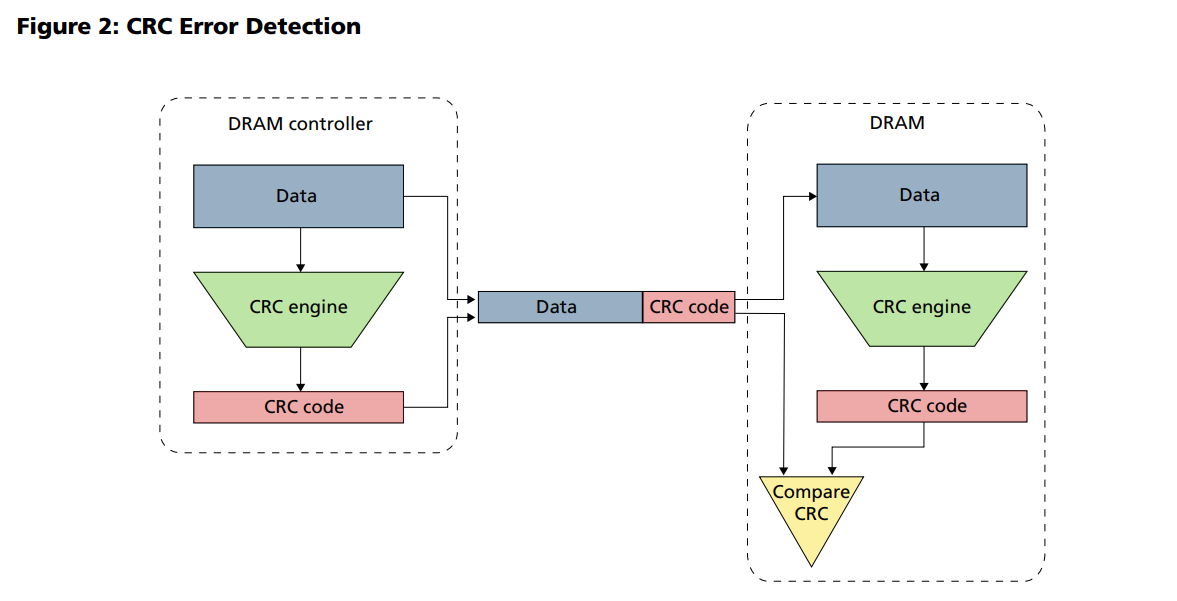
每個DRAM裏有4個bank選取位元可用來選取多達16個bank單元:兩個bank位址位元(BA0、BA1),和兩個bank群組位元(BG0、BG1)。當在同一個bank群組中存取不同的bank單元時會有另外的時間限制;在不同的bank群組中,存取一個bank比以往的更快。
另外,3個晶片層選取信號(C0、C1、C2),允許最多8個堆疊式晶片層封裝於一塊DRAM封裝上。這可以更有效地充當3個以上的bank單元選取位元,使選取總數達到7(可以定位128個bank單元)。

我们知道cache的存在导致访存是按照cache line(32或者64字节)来进行的,但是内存一般只会处理连续64bits数据,导致需要控制器和总线分多周期(memory burst概念)来实现cache的更新。
SNB CPU的内存控制器可以实现和处理:
reduction in DRAM row buffer conflicts
 [^1]
[^1]
AMD公司提高CPU与内存性能的一项技术,将北桥的内存控制器集成到CPU,使得原来CPU-北桥-内存三方传输数据的过程简化成CPU与内存之间的单向传输技术,降低了延迟。

以2GB DDR3为例子,编码如上,
DDR中的Burst(突发长度)指的是,当收到了一个读请求和地址后,会连续取出这个地址周围几个连续地址上的数据,具体取几个就叫BL(Burst Length),是可以随地址信号配置的。(原因是:次次等待Address和Enable信号再读写有些浪费时间)
Burst的实现是通过Prefetch完成的,Prefetch就是一次从Array上取出多bit的过程,而Burst则是根据规则发送这些预取的数据的过程。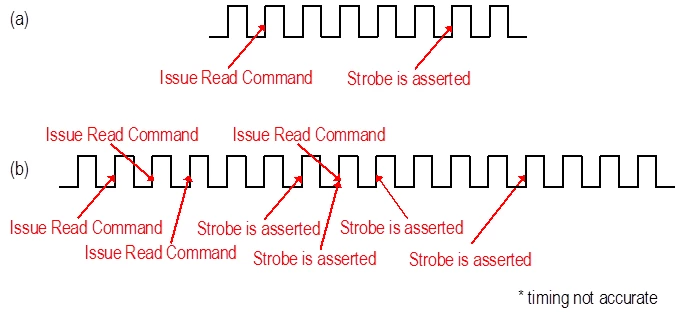
Burst Length(BL)是可以配置的,比如8Bit预取可以支持BL8的Burst或者BC4(Burst Length Chopped)的Burst。
Prefetch数量也是前几代DDR的主要区别。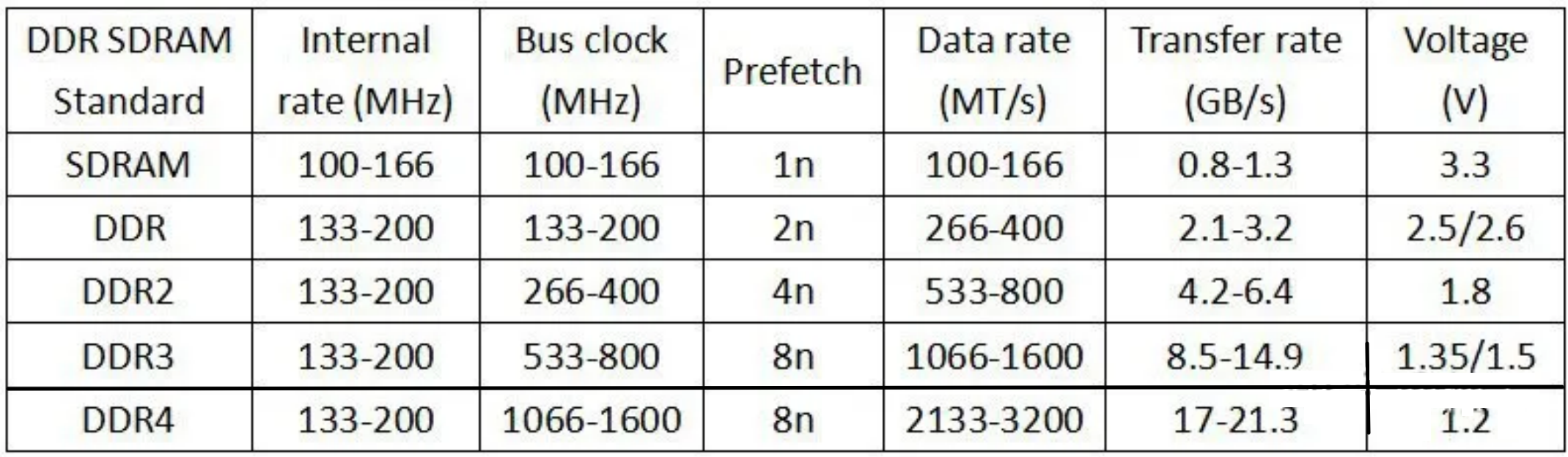
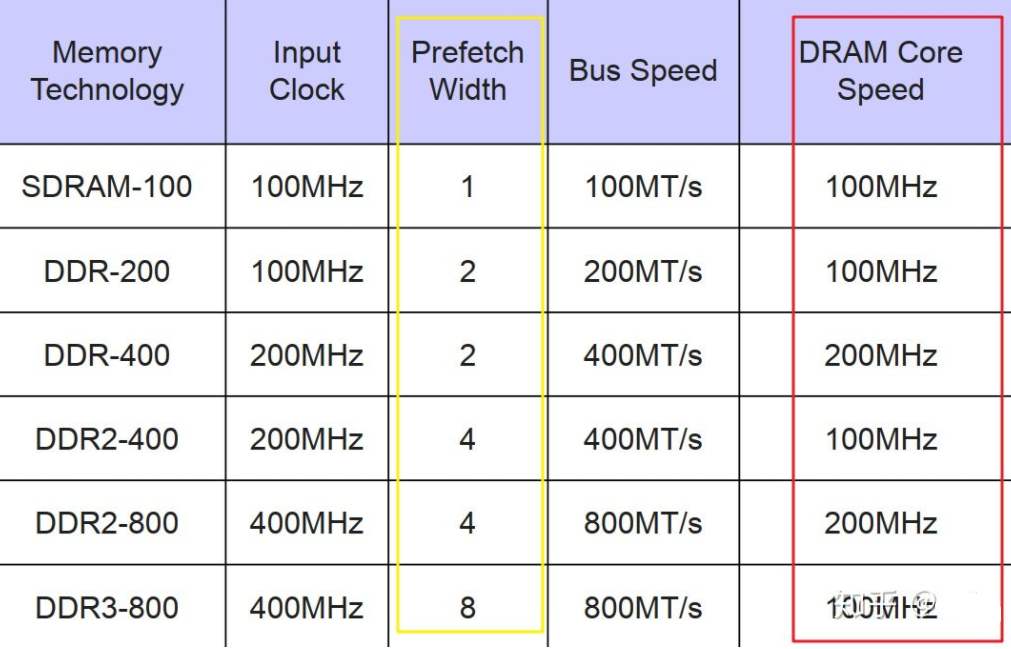
红框标出的DRAM的核心频率基本不变,传输速度的提高是通过增加prefetch的位数(黄框)来做到的。
DDR 有两项主要的技术 2n-prefetch (2 倍预取),和 DLL (延迟锁相环)。这在之后历代 DDR 协议中都是一脉相承的。所谓 2 倍预取,即在一个时钟的上升边沿读取当前地址单元的数据,并同时读取下一个地址单元的数据。
100MT/s(这里的T是传输的意思);DDRx的核心频率一直维持在100Mhz到266MHz的水平上,每代速度的提升都是靠倍增Prefetch的个数来达到的。
DDR4和DDR3一样,只有8n的prefetch,但为了提升前端Front End的总线速度,不得不在核心频率上动起了手脚:
核心频率不在徘徊在100~266HMz,直接200起跳,到400Mhz。因为核心频率提高,8bit的prefetch不变,总线速度才得以提升。
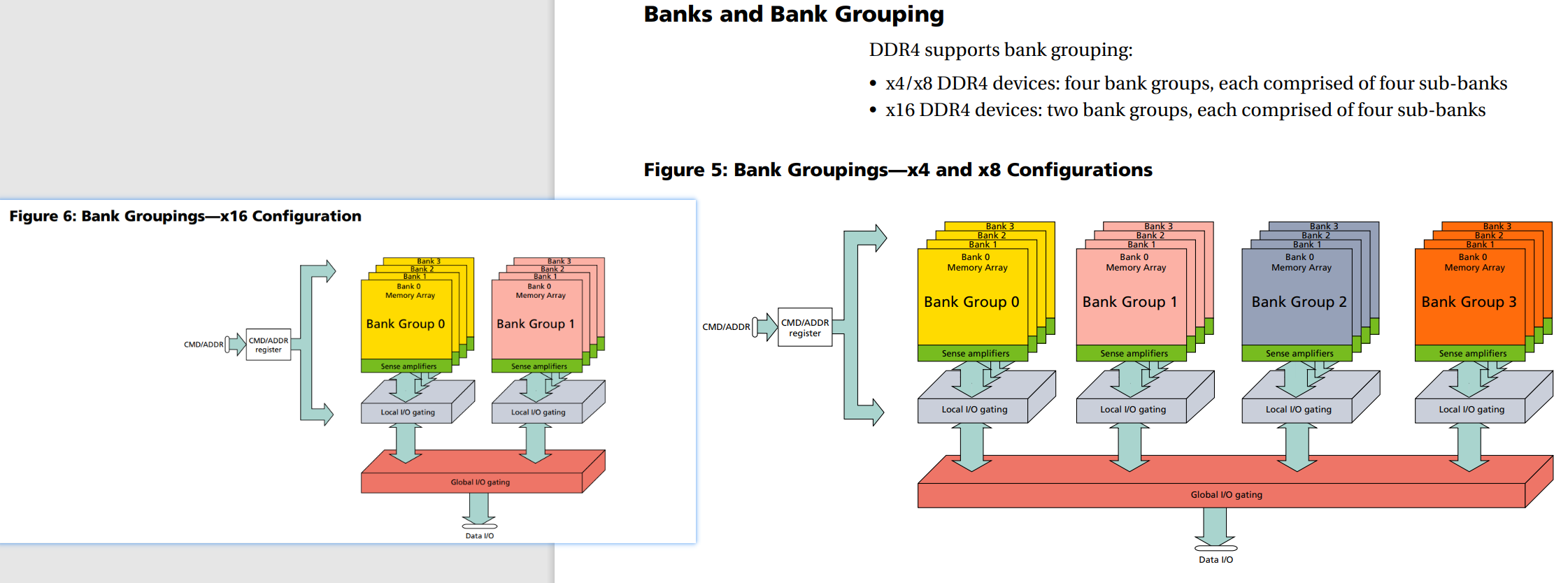
除此之外,引入了Bank Group。DDR4 新增了4 個Bank Group 資料組的設計,各個Bank Group具備獨立啟動操作讀、寫等動作特性,Bank Group 資料組可套用多工的觀念來想像,亦可解釋為DDR4 在同一時脈工作周期內,至多可以處理4 筆資料,效率明顯好過於DDR3。
我们都知道memory控制器实际上很大程度受cache操纵。X86 cache line 64B,而每次操作是64bit。所以一个cache line刷新是通过联系8个读操作实现的,这8个操作不是分别完成,而是一次burst操作,所以BL(burst line)是8。BL8的64B cache line只需要64个Bytes,如果prefetch是16,DIMM那边所有chip会准备
64 X 16 = 128 Byte
的数据。多出来的数据就变成了垃圾数据,空耗能而对速度帮助不大,所以DDR4到16 prefetch。
是不是CPU的cache line变长了呢?并不是,CPU的cache line还是64B,变化的是DIMM端增加了个新东西:Sub Channel。
Sub Channel,顾名思义,就是子通道,它是把DDR5 DIMM的72bit位宽(包括64bit数据+8bit ECC码)拆分成两个40bit的sub Channel。包括32bit的数据,+8bit的ECC:
这两个sub channel是相互独立的,既可以独立使用,也可以如前面合并使用。所以prefetch就可以提高到16n,当然也支持8n。
聪明的设计让DDR5在同样3200MT/s的传输率上,可以提高带宽1.36倍。再加上可以支持更高的频率,才能保证DDR5的传输速度。
DDR5的prefetch是16,那么怎么解决我们前面提到的cache line大小的问题呢?DDR5采取的方式是减少DIMM data lane的数量,从64个data lane降低到32个data lane,从而继续保持64 Byte的cache line大小。
CL-tRCD-tRP-tRAS-CR
| 名词 | 解释 |
|---|---|
| CL(CAS Latency) | 列信号延迟: 在读取命令发出后到数据读出到IO接口的间隔时间(时钟周期数) |
| tCAS(tCL?) | 实际延迟时间tCAS(ns)=(CAS*2000)/内存等效频率 |
| tRAS(Row Active Time) | 行地址激活的时间。从一个行地址预充电之后,从激活到寻址再到读取完成所经过的整个时间 tRCD+tCL |
| tRCD(Read-to-Column Delay) | 行地址激活(Active)命令发出之后,内存对行地址的操作所需要的时间。内存中某一行地址被激活时,我们称它为“open page” |
| tRCDR(Read-to-Column Command Delay) | 行地址激活(Active)命令发出之后,内存对行地址的读操作所需要的时间。 |
| tRCDW(Write-to-Column Command Delay) | 行地址激活(Active)命令发出之后,内存对行地址的写操作所需要的时间。 |
| nWR (Write Recovery Time) | time delay between successive write commands to the same row. |
| tRP(RAS Precharge Time) | 前一个行地址操作完成并在行地址关闭(page close)命令发出之后,准备对同一个bank中下一个行地址进行Active操作需要的时间(在对同一个bank的多个不同的行地址进行操作时影响才大) |
| CR(Command Rate) | 首命令延迟。是指从选定bank之后到可以发出行地址激活命令所经过的时间。(如果CPU所需要的数据都在内存的一个行地址上,就不需要进行重复多次的bank选择,CR的影响就很小) |
| Tccd | is the minimum amount of time between column operations |
| tRPRE | The minimum pulse width of READ preamble |
| tRPST | The minimum pulse width of READ postamble |
XMP时序都没有介绍
不同的DRAM。随着频率提升,CL周期也同步提升,但是最后算出来的CL延迟时间却差不多(5~15ns)。其实当下memory的频率宽度过剩,integrated memory controller (IMC)才是瓶颈
在列信号之前还有行信号
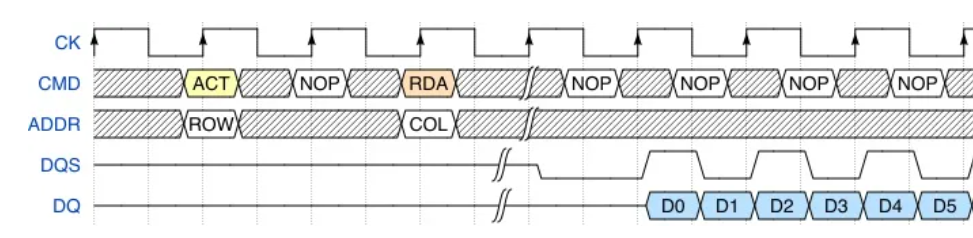
如何连续两次访问同一行的不同列,则之间不需要额外的切换行信号。
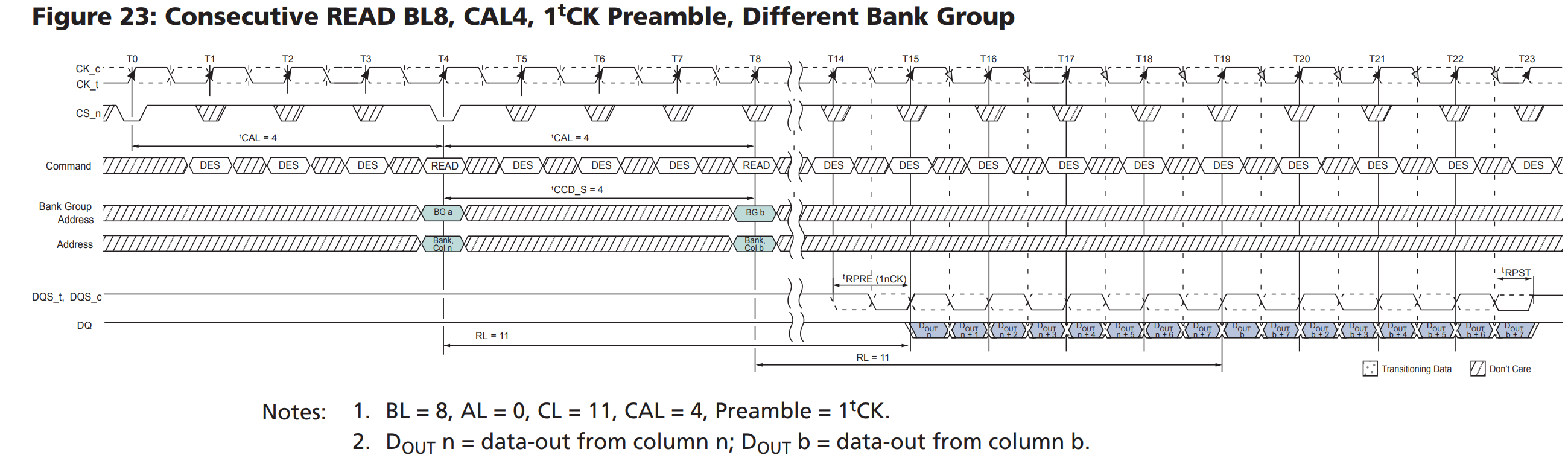
https://zhuanlan.zhihu.com/p/52272990
导言
IPCC比赛的时候,发现用hash map会比红黑树的map慢。感觉不对劲,我hash空间声明大,冲突不就低了吗?
导言
遇到的DNS相关的问题
sudo passwd root只要在安装系统时分出一个/home分区。你可以把Ubuntu的“/”分区看为Windows的C盘,重装Ubuntu时只格式化“/”分区,不格式化“/home”,这样就可以保留“/home”中的数据了。使用的时候就挂载就行
但是假如一开始没分区: 1. 可以插块新盘当作系统盘,系统安装好之后,把旧的文件系统挂载到新系统的某个目录下 2. 从旧的文件系统里划出一块区域,安装新系统。 1. 在你要安装的目标磁盘中,通过删除卷和删除分区操作腾出一块未分配的磁盘空间作为安装区
xfs类型不可以直接缩减,只扩不减。如果是ext2,ext3,ext4可以在线缩减,如果xfs盘要缩小就要删除后重新添加
https://www.ywbj.cc/?p=712
df -h查看的空间
不取消挂载,这步会报错,注:一定先减文件系统,再减逻辑卷
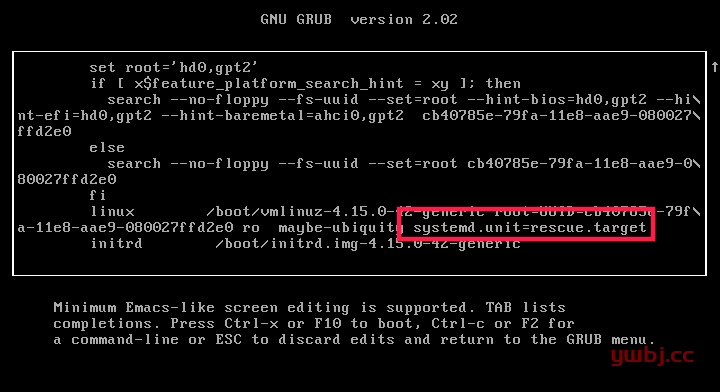
正常启动系统进入救援模式 :启动按shift键,出现选择系统界面,按e。找到以单词 linux 开头的行,并在该行的末尾添加以下内容(要到达末尾,只需按下 CTRL+e 或使用 END 键或左右箭头键):
添加完成后,只需按下CTRL+x 或 F10 即可继续启动救援模式。几秒钟后,你将以 root 用户身份进入救援模式(单用户模式)
暂无
https://blog.csdn.net/weixin_40018873/article/details/109537532
https://www.ywbj.cc/?p=712
# shaojiemike @ node5 in ~ [7:20:31]
$ mpicc -showme
gcc -I/usr/lib/x86_64-linux-gnu/openmpi/include/openmpi -I/usr/lib/x86_64-linux-gnu/openmpi/include -pthread -L/usr/lib/x86_64-linux-gnu/openmpi/lib -lmpi
source /opt/intel/oneapi/setvars.sh
# shaojiemike @ node5 in ~/github/IPCC/SLIC on git:main x [15:45:06] C:1
$ mpicc -compile_info
gcc -I'/opt/intel/oneapi/mpi/2021.1.1/include' -L'/opt/intel/oneapi/mpi/2021.1.1/lib/release' -L'/opt/intel/oneapi/mpi/2021.1.1/lib' -Xlinker --enable-new-dtags -Xlinker -rpath -Xlinker '/opt/intel/oneapi/mpi/2021.1.1/lib/release' -Xlinker -rpath -Xlinker '/opt/intel/oneapi/mpi/2021.1.1/lib' -lmpifort -lmpi -lrt -lpthread -Wl,-z,now -Wl,-z,relro -Wl,-z,noexecstack -Xlinker --enable-new-dtags -ldl
> mpicc -v
mpigcc for the Intel(R) MPI Library 2021.5 for Linux*
Copyright Intel Corporation.
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/public1/soft/gcc/8.1.0/libexec/gcc/x86_64-pc-linux-gnu/8.1.0/lto-wrapper
Target: x86_64-pc-linux-gnu
Configured with: ./configure --prefix=/public1/soft/gcc/8.1.0 --enable-languages=c,c++,fortran --disable-multilib
Thread model: posix
gcc version 8.1.0 (GCC)
# shaojiemike @ node5 in ~/github/IPCC/SLIC on git:main x [15:45:16]
$ mpiicc -compile_info
icc -I'/opt/intel/oneapi/mpi/2021.1.1/include' -L'/opt/intel/oneapi/mpi/2021.1.1/lib/release' -L'/opt/intel/oneapi/mpi/2021.1.1/lib' -Xlinker --enable-new-dtags -Xlinker -rpath -Xlinker '/opt/intel/oneapi/mpi/2021.1.1/lib/release' -Xlinker -rpath -Xlinker '/opt/intel/oneapi/mpi/2021.1.1/lib' -lmpifort -lmpi -ldl -lrt -lpthread
# shaojiemike @ node5 in ~/github/IPCC/SLIC on git:main x [15:50:09] C:255
$ mpiicc -show
icc -I'/opt/intel/oneapi/mpi/2021.1.1/include' -L'/opt/intel/oneapi/mpi/2021.1.1/lib/release' -L'/opt/intel/oneapi/mpi/2021.1.1/lib' -Xlinker --enable-new-dtags -Xlinker -rpath -Xlinker '/opt/intel/oneapi/mpi/2021.1.1/lib/release' -Xlinker -rpath -Xlinker '/opt/intel/oneapi/mpi/2021.1.1/lib' -lmpifort -lmpi -ldl -lrt -lpthread
ipcc22_0029@ln121 ~/github/IPCC2022-preliminary/run (float_trick*) [10:49:48]
> mpicc -show
gcc -I/public1/soft/mpich/3.1.4-gcc8.1.0/include -L/public1/soft/mpich/3.1.4-gcc8.1.0/lib -Wl,-rpath -Wl,/public1/soft/mpich/3.1.4-gcc8.1.0/lib -Wl,--enable-new-dtags -lmpi
-showme (Open MPI) or -show (Open MPI, MPICH and derivates) use -showme:compile and -showme:link to obtain the options automatically
> mpirun -info
HYDRA build details:
Version: 2021.5
Release Date: 20211102 (id: 9279b7d62)
Process Manager: pmi
Bootstrap servers available: ssh slurm rsh ll sge pbs pbsdsh pdsh srun lsf blaunch qrsh fork
Resource management kernels available: slurm ll lsf sge pbs cobalt
ipcc22_0029@ln121 ~ [11:55:08]
> mpiexec --version
HYDRA build details:
Version: 3.1.4
Release Date: Fri Feb 20 15:02:56 CST 2015
CC: gcc
CXX: g++
F77: gfortran
F90: gfortran
Configure options: '--disable-option-checking' '--prefix=/public1/soft/mpich/3.1.4-gcc8.1.0' 'CC=gcc' 'CXX=g++' 'FC=gfortran' '--cache-file=/dev/null' '--srcdir=.' 'CFLAGS= -O2' 'LDFLAGS= ' 'LIBS=-lpthread ' 'CPPFLAGS= -I/public1/home/deploy/amd-mpich/mpich-3.1.4/src/mpl/include -I/public1/home/deploy/amd-mpich/mpich-3.1.4/src/mpl/include -I/public1/home/deploy/amd-mpich/mpich-3.1.4/src/openpa/src -I/public1/home/deploy/amd-mpich/mpich-3.1.4/src/openpa/src -D_REENTRANT -I/public1/home/deploy/amd-mpich/mpich-3.1.4/src/mpi/romio/include'
Process Manager: pmi
Launchers available: ssh rsh fork slurm ll lsf sge manual persist
Topology libraries available: hwloc
Resource management kernels available: user slurm ll lsf sge pbs cobalt
Checkpointing libraries available:
Demux engines available: poll select
ipcc22_0029@ln121 ~ [11:55:31]
> mpichversion
MPICH Version: 3.1.4
MPICH Release date: Fri Feb 20 15:02:56 CST 2015
MPICH Device: ch3:nemesis
MPICH configure: --prefix=/public1/soft/mpich/3.1.4-gcc8.1.0/ CC=gcc CXX=g++ FC=gfortran
MPICH CC: gcc -O2
MPICH CXX: g++ -O2
MPICH F77: gfortran -O2
MPICH FC: gfortran -O2
## 安装了IB支持
> ompi_info | grep openib
MCA btl: openib (MCA v2.1.0, API v3.0.0, Component v3.1.6)
> mpiexec --version
mpiexec (OpenRTE) 4.1.1
Report bugs to http://www.open-mpi.org/community/help/
ipcc22_0029@ln121 ~/slurm/MPIInit [12:24:19]
> module load mpi/openmpi/4.1.1-gcc7.3.0
ipcc22_0029@ln121 ~/slurm/MPIInit [12:24:51]
> mpicc -v
Using built-in specs.
COLLECT_GCC=/public1/soft/gcc/7.3.0/bin/gcc
COLLECT_LTO_WRAPPER=/public1/soft/gcc/7.3.0/libexec/gcc/x86_64-pc-linux-gnu/7.3.0/lto-wrapper
Target: x86_64-pc-linux-gnu
Configured with: ./configure --prefix=/public1/soft/gcc/7.3.0 --disable-multilib
Thread model: posix
gcc version 7.3.0 (GCC)
暂无
暂无
https://stackoverflow.com/questions/11312719/how-to-compile-mpi-with-gcc
StackOverflow的回答是,Init在调用过程中初始化MPI库,并且在进程间建立通讯和编号。
知乎的回答: OpenMPI会在调用MPI_Init时按照你传递给mpirun的指令新建进程,而你传递给MPI_Init的参数,会被传递给新建的进程。
这似乎在暗示,两个进程不是同时产生和运行的。
有顺序的观点是不成立的

即使有顺序 malloc的时间也没这么长。
难道是malloc的数据需要MPI_Init复制一遍?
简单将MPI_Init提前到最开始,时间也基本没变,也不对。
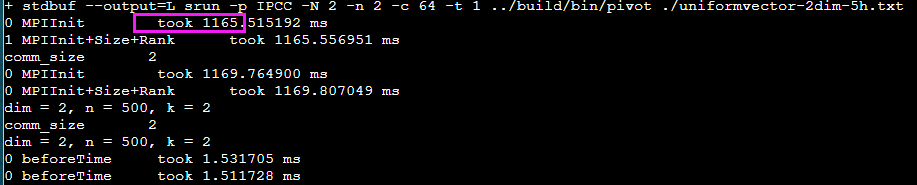
如果单独写一个只有MPI_Init的程序,IntelMPI还是要耗时800ms
ipcc22_0029@ln121 ~/slurm/MPIInit [11:42:32]
> srun -p IPCC -N 2 -n 2 -c 64 -t 1 MPI
MPIInit took 882.110047 ms
MPIInit took 892.112269 ms
以IPCC2022初赛的北京超算云 AMD机器举例
| mpirun的选择 | mpi版本 | GCC或者ICC的选择版本 | 超算运行 | MPI_Init时间(ms) |
|---|---|---|---|---|
| IntelMPI | mpi/intel/2022.1 | gcc/10.2.0 | 只能sbatch,不能srun | 1282.24 ~ 1678.59 |
| OpenMPI | mpi/openmpi/4.1.1-gcc7.3.0 | 2706ms~3235ms | ||
| MPICH | mpich/3.1.4-gcc8.1.0 | 17ms | ||
| mpich/3.4.2 | gcc/10.2.0 | 107ms |
需要export I_MPI_PMI_LIBRARY=libpmi2.so
https://www.intel.com/content/www/us/en/develop/documentation/vtune-help/top/analyze-performance/code-profiling-scenarios/mpi-code-analysis.html
https://www.intel.com/content/www/us/en/develop/documentation/vtune-cookbook/top/configuration-recipes/profiling-mpi-applications.html
设置这个Intel mpi 1200 -> 1100
实在是弄不懂,为什么不同的实现,时间差别这么大。可能慢是因为额外的通路设置,是为了之后的快速传输??
3.1.4的安装选项也看不到
> mpiexec --version
mpiexec: error while loading shared libraries: libslurm.so.35: cannot open shared object file: No such file or directory
暂无
无
必须先安装base,可以看到默认安装的内容
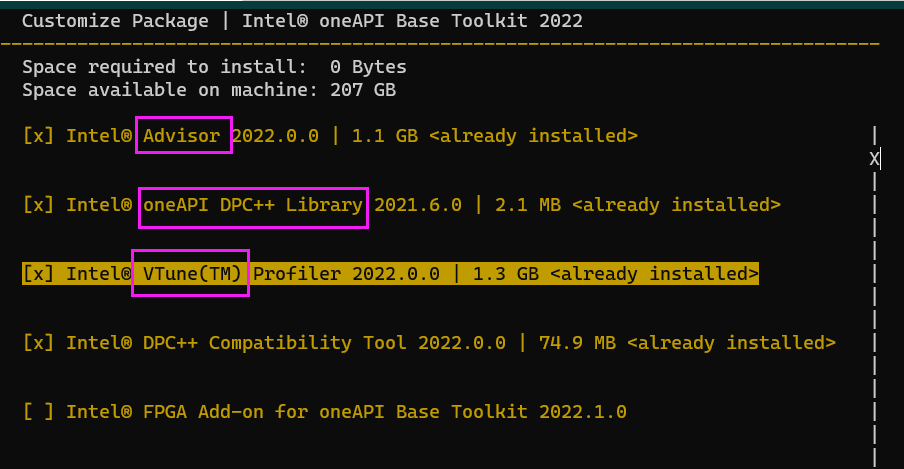
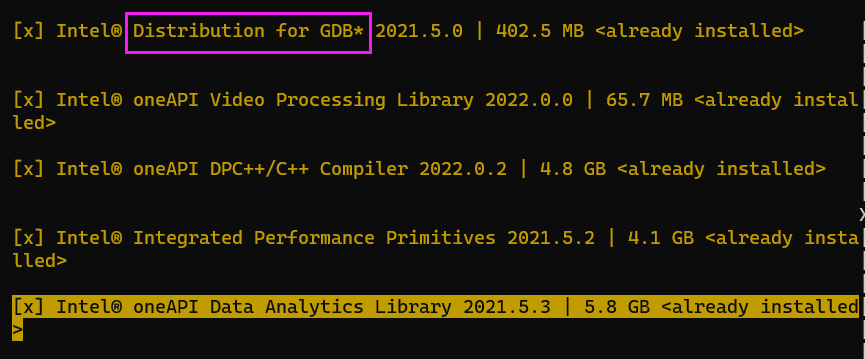
这个GDB好像可以分析多进程
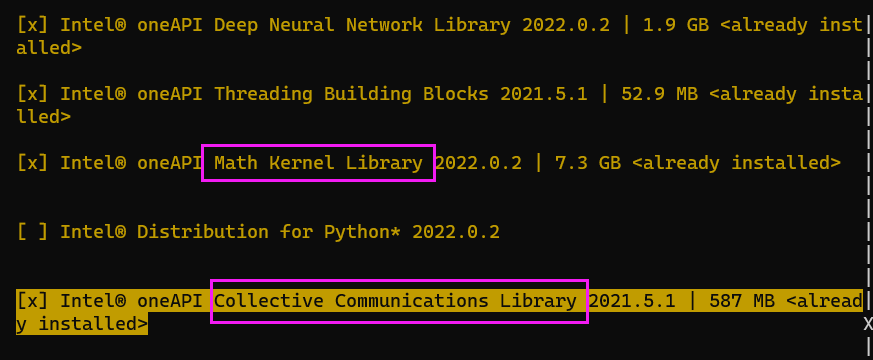
Intel OneAPI HPC toolkit包括了icc,icpc,ifort和OpenMP,IntelMPI还有MKL(Intel® oneAPI Math Kernel Library (oneMKL))
在Download界面选择版本, 选择online或者offline会有推荐指令,如下
wget https://registrationcenter-download.intel.com/akdlm/irc_nas/18679/l_HPCKit_p_2022.2.0.191.sh
sudo sh ./l_HPCKit_p_2022.2.0.191.sh
> icx -v
Intel(R) oneAPI DPC++/C++ Compiler 2022.0.0 (2022.0.0.20211123)
Target: x86_64-unknown-linux-gnu
Thread model: posix
InstalledDir: /opt/intel/oneapi/compiler/2022.0.2/linux/bin-llvm
Found candidate GCC installation: /usr/lib/gcc/x86_64-linux-gnu/8
Found candidate GCC installation: /usr/lib/gcc/x86_64-linux-gnu/9
Selected GCC installation: /usr/lib/gcc/x86_64-linux-gnu/9
Candidate multilib: .;@m64
Selected multilib: .;@m64
Found CUDA installation: /usr/local/cuda-11.5, version
> icpx --help
OVERVIEW: Intel(R) oneAPI DPC++/C++ Compiler
USAGE: clang++ [options] file...
暂无
暂无
https://www.intel.com/content/www/us/en/develop/documentation/installation-guide-for-intel-oneapi-toolkits-linux/top/prerequisites/install-intel-gpu-drivers.html