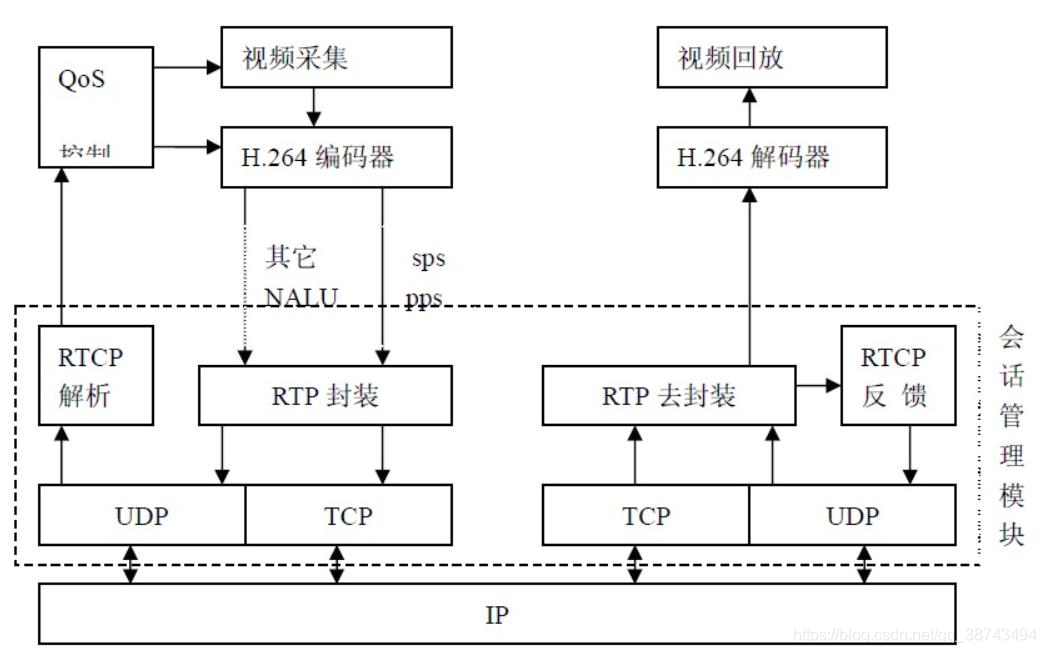
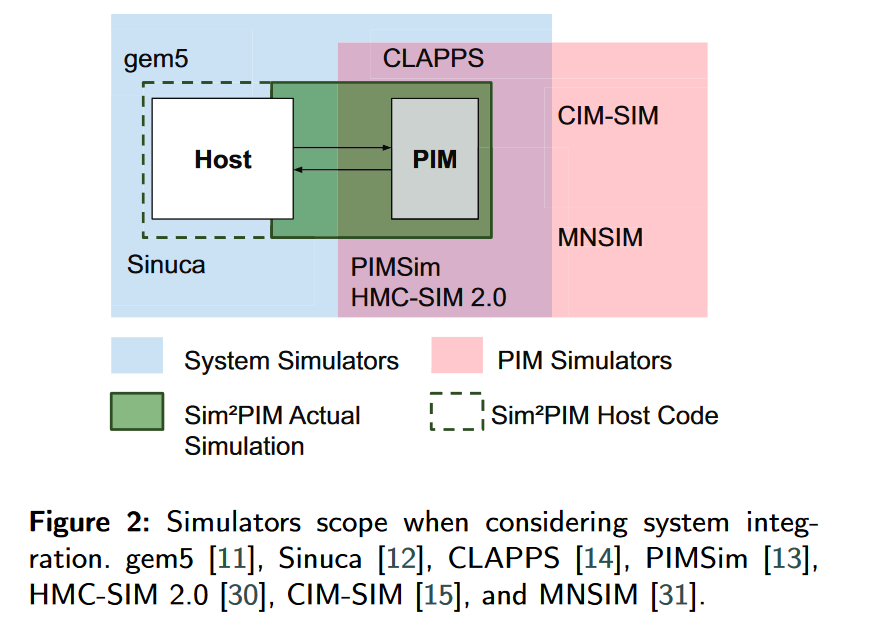
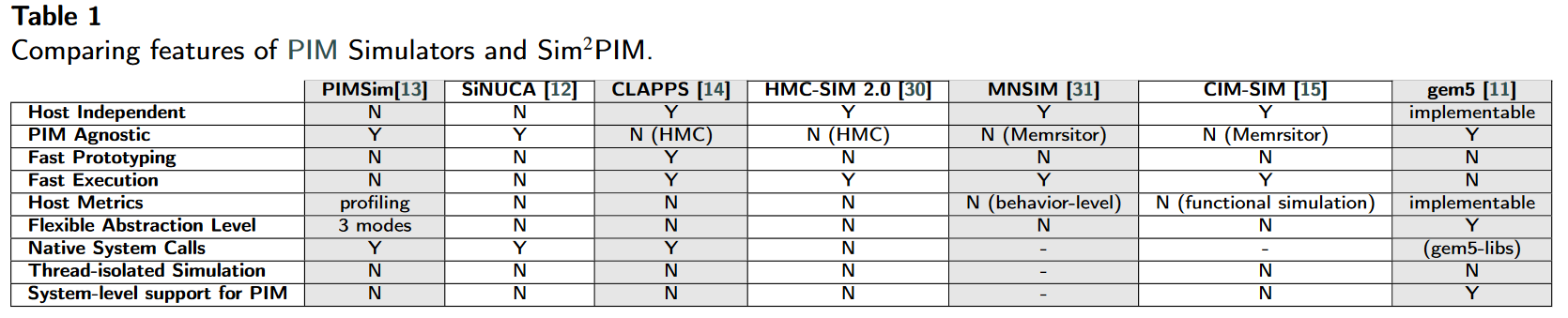
同样是1080P 25帧,码率不同,大小差异很大。
或者(有时候会失效,eg 720P)
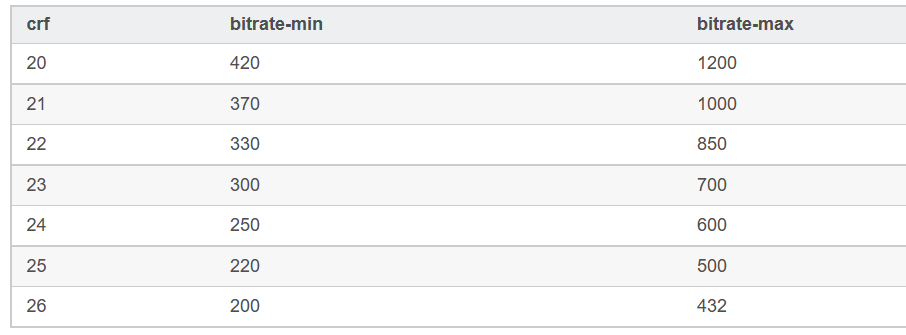
CRF(英文:constant ratefactor 意思:压缩质量)是动态码率,要看你拍摄的视频画面抖动切换的程度,如果比较安静就20,动的厉害就25。
crf18就接近无损,字幕组惯用20-22,crf23是默认值。 CRF的值越小,视频将会越清晰 当然视频质量就会更大。
2-pass通过两次编码,第一次编码是先对整个文件进行扫描,记录一些统计信息,第二次编码时根据前面记录的统计信息再进行编码。这么做虽然转换时间会漫长,但压出的片子会有更好的画质,画面细节更好,而且体积会更小。
常用于非实时转码的情景。
疫情线上参会邮件投递Presentation视频,邮件大小限制100MB。PPT生成的过大
直接自定义导入导出,默认设置就行(确定分辨率不变的情况下,大小无法限制)。视频部分就只有原来五分之一(中间),而且完全看不出损失。
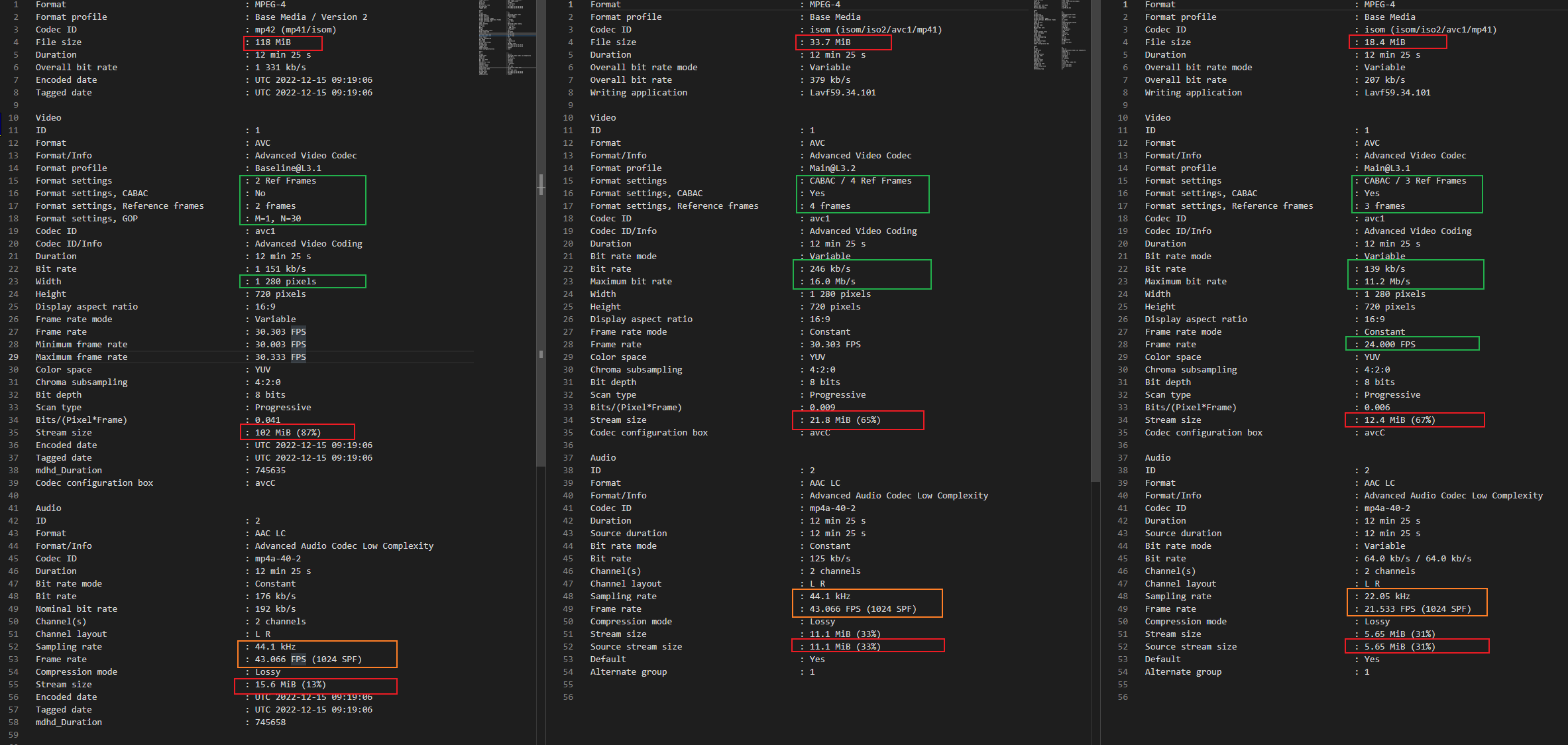
如果要最小大小,选择“转mp4”,然后“输出设置”选择“低质量和大小”,最后在分辨率选回原来的分辨率。
如果不熟悉H.265的参数设置,压缩后不一定比H.264小。
PS: H.264中熵编码有两种方法:
1. 一种是对所有的待编码的符号采用统一的VLC(UVLC :Universal VLC),
2. 另一种是采用内容自适应的二进制算术编码(CABAC:Context-Adaptive Binary Arithmetic Coding)。CABAC是可选项。
CABAC动态的根据内容的码率能在效能与压缩效率上取得相当大的改善空间,但是顺序处理造成资料依存性(Data Dependency)偏高。
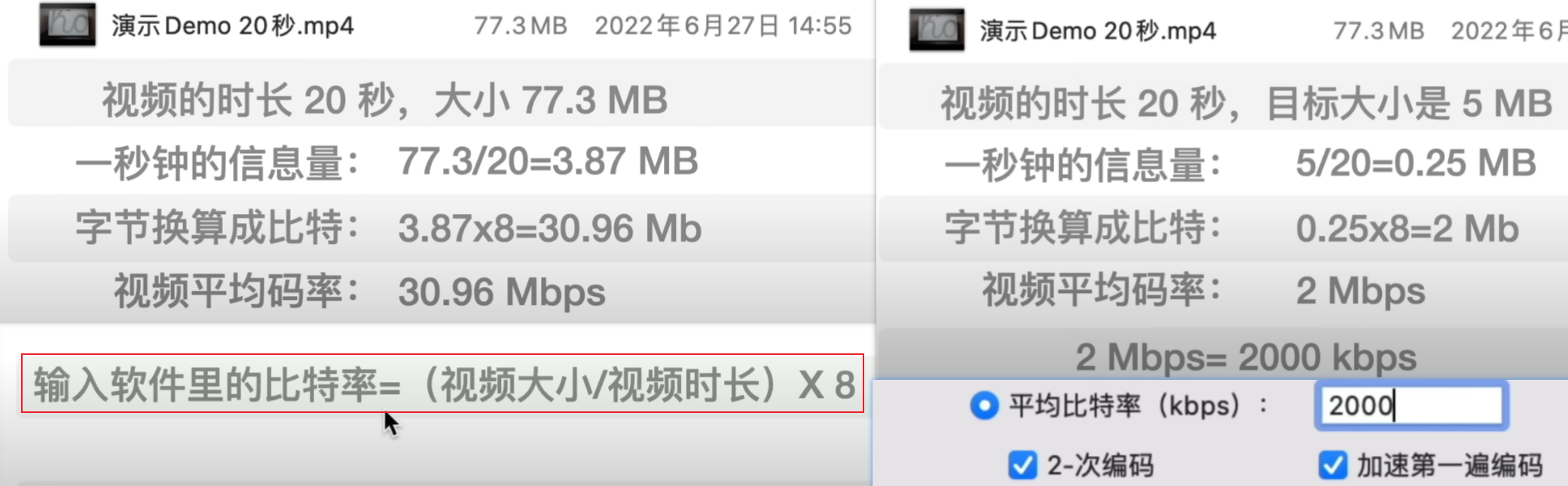
已知大小需求来计算需要压缩的码率。直接设置压缩后的平均码率就行,常见软件有:小丸工具箱,HandBrake, 剪映
首先需要知道如何计算码率

ffmpeg是一个自由软件,可以运行音频、视频多种格式的录影、转换、流功能,包含
* libavcodec--这是一个用于多个项目中的音频、视频的解码器库,
* libavformat--一个音频和视频格式转换库。
# 视频流码率 500k, 音频流码率 50k
ffmpeg -i huawei_report_English_video.mp4 -c:v libx264 -b:v 500k -b:a 50k out_500k.mp4
# 或者设置最大最小
ffmpeg -i huawei_report_English_video.mp4 -minrate 100K -maxrate 500K -bufsize 2000K out.mp4
结果如下
$ ls
-rw-r--r-- 1 shaojiemike staff 119M Jan 2 16:59 huawei_report_English_video.mp4
-rw-r--r-- 1 shaojiemike staff 50M Jan 2 17:23 out_500k.mp4
-rw-r--r-- 1 shaojiemike staff 24M Jan 2 17:14 out.mp4
$ ffmpeg -i out_500k.mp4 -hide_banner
Duration: 00:12:25.68, start: 0.000000, bitrate: 553 kb/s
Stream #0:0(und): Video: h264 (High) (avc1 / 0x31637661), yuv420p, 1280x720 [SAR 1:1 DAR 16:9], 493 kb/s, 30.30 fps, 30.30 tbr, 30303 tbn, 60.61 tbc (default)
Stream #0:1(und): Audio: aac (LC) (mp4a / 0x6134706D), 44100 Hz, stereo, fltp, 50 kb/s (default)
# shaojiemike @ snode6 in ~/test/ffmpeg [17:14:42] C:1
$ ffmpeg -i out.mp4 -hide_banner
Duration: 00:12:25.68, start: 0.000000, bitrate: 269 kb/s
Stream #0:0(und): Video: h264 (High) (avc1 / 0x31637661), yuv420p, 1280x720 [SAR 1:1 DAR 16:9], 125 kb/s, 30.30 fps, 30.30 tbr, 30303 tbn, 60.61 tbc (default)
Stream #0:1(und): Audio: aac (LC) (mp4a / 0x6134706D), 44100 Hz, stereo, fltp, 134 kb/s (default)
# shaojiemike @ snode6 in ~/test/ffmpeg [17:15:29] C:1
$ ffmpeg -i huawei_report_English_video.mp4 -hide_banner
Duration: 00:12:25.66, start: 0.000000, bitrate: 1330 kb/s
Stream #0:0(und): Video: h264 (Constrained Baseline) (avc1 / 0x31637661), yuv420p, 1280x720 [SAR 1:1 DAR 16:9], 1151 kb/s, 30.30 fps, 30.30 tbr, 30303 tbn, 60 tbc (default)
同样分辨率下,视频文件的码率越大,压缩比就越小,画面质量就越高。码率越高,精度就越高,处理出来的文件就越接近原始文件,图像质量越好,画质越清晰,要求播放设备的解码能力也越高。体积越大,说明压缩比小,越接近原文件。
帧率与码率的关系:帧率多,则每秒图片数目多;码率越高,每张图片质量越清晰。
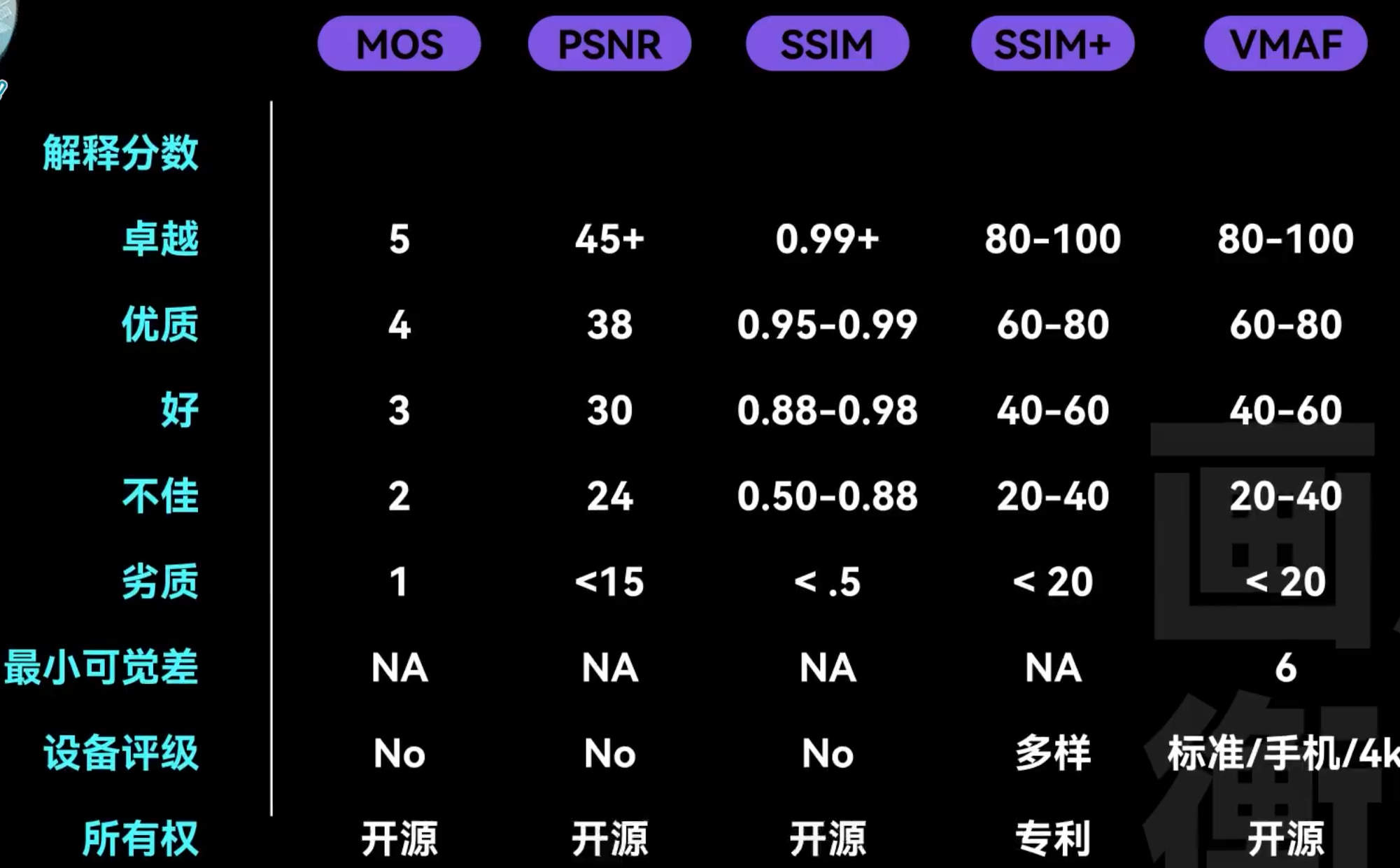
VMAF - Video Multi-Method Assessment Fusion 视频多方法评估
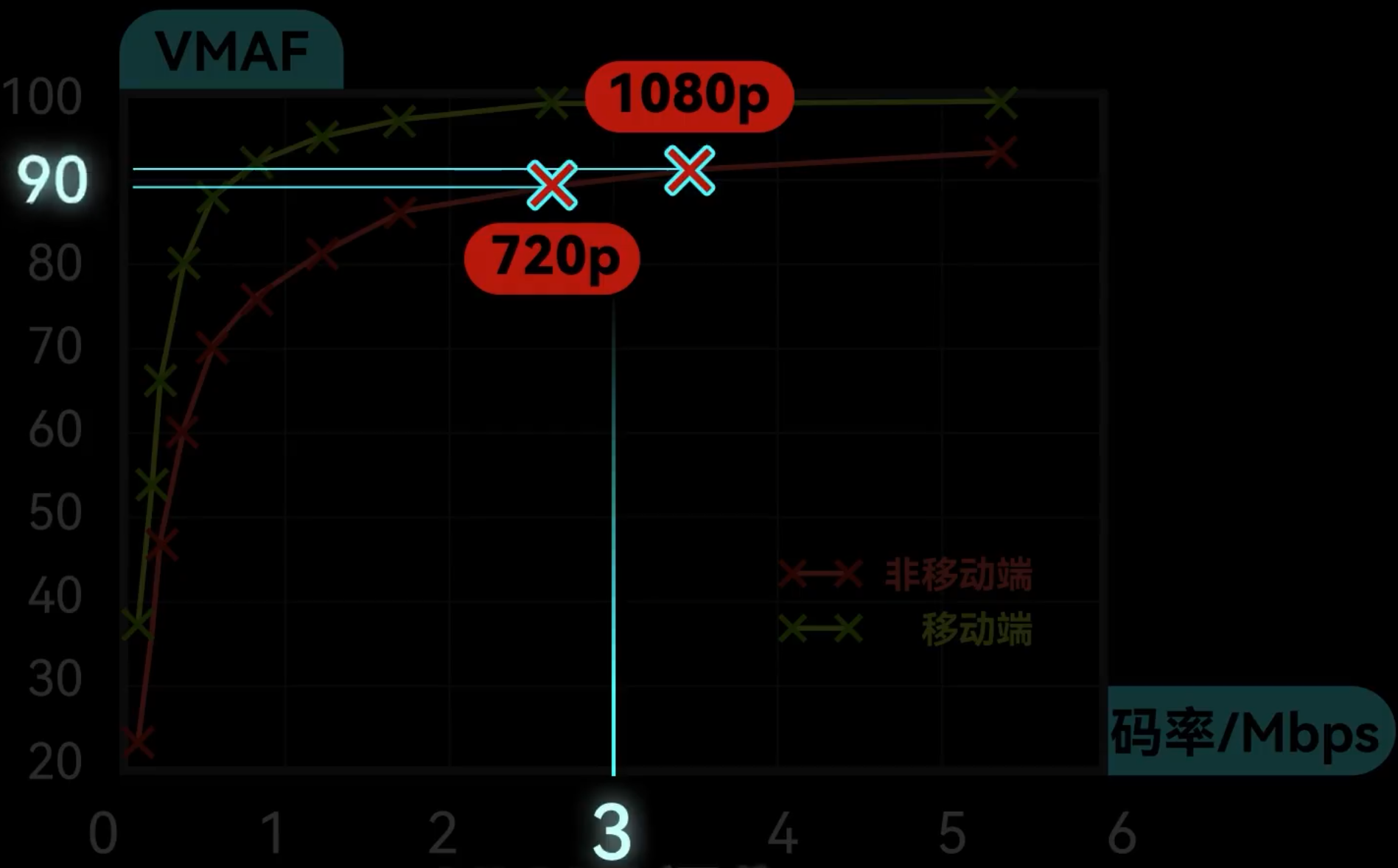
3Mbps是1080p的甜品点。
其他标准
视频压缩原理看差评君的就懂了,讲的真好。
柴知道也行
为什么有这么多标准:
H26x的视频的编解码“贵”:
* 视频编码由视频作者解决
* 使用H26x标准解码价格不菲
我们知道,其实视频就是一帧一帧的图片。计算一下,一部25帧每秒,90分钟,分辨率为1024*768,24位真彩色的视频,没有经过压缩,大小为
1Byte(字节) = 8bit(位)
一帧大小 = 1024 * 768 * 24 = 18874368(bit) = 2359296(Byte)
总帧数 = 90 * 60 * 25 = 135000
总大小 = 一帧大小 * 总帧数 = 2359296 * 135000 = 318504960000(Byte)= 303750(MB)≈ 296(GB)
从上面的计算可以看出,我们储存一部90分钟没压缩的电影需要296GB的,2部电影便可占满我们电脑整个硬盘。所以我们需要对视频进行压缩,这种视频压缩技术就是我们所说的编码。
视频编码方式:H.26X(H.261、H.262、…、H.264(目前最常用)、H.265)
音频编码方式:MP3、AAC等
通过视频压缩算法,减少了视频文件的大小。压缩比越大,解压缩还原后播放的视频越失真,这是因为压缩的同时不可避免的丢失了视频中原来图像的数据信息。
一般ITU(国际电信联盟)和ISO(国际标准化组织)来制定
1. ISO主导的MPEG系列: MPEG-1 用于 VCD, MPEG-2用于DVD 2. h.26x由ITU主导,比如 H.261到H.263
3. 两者联合制定了 H.264-H.265
1. 各自别称 MPEG-4/AVC(Advanced Video Coding)和 MPEG-4/HEVC(High Efficiency Video Coding)
2. h.26x由ITU主导,比如 H.261到H.263
3. 两者联合制定了 H.264-H.265
1. 各自别称 MPEG-4/AVC(Advanced Video Coding)和 MPEG-4/HEVC(High Efficiency Video Coding)
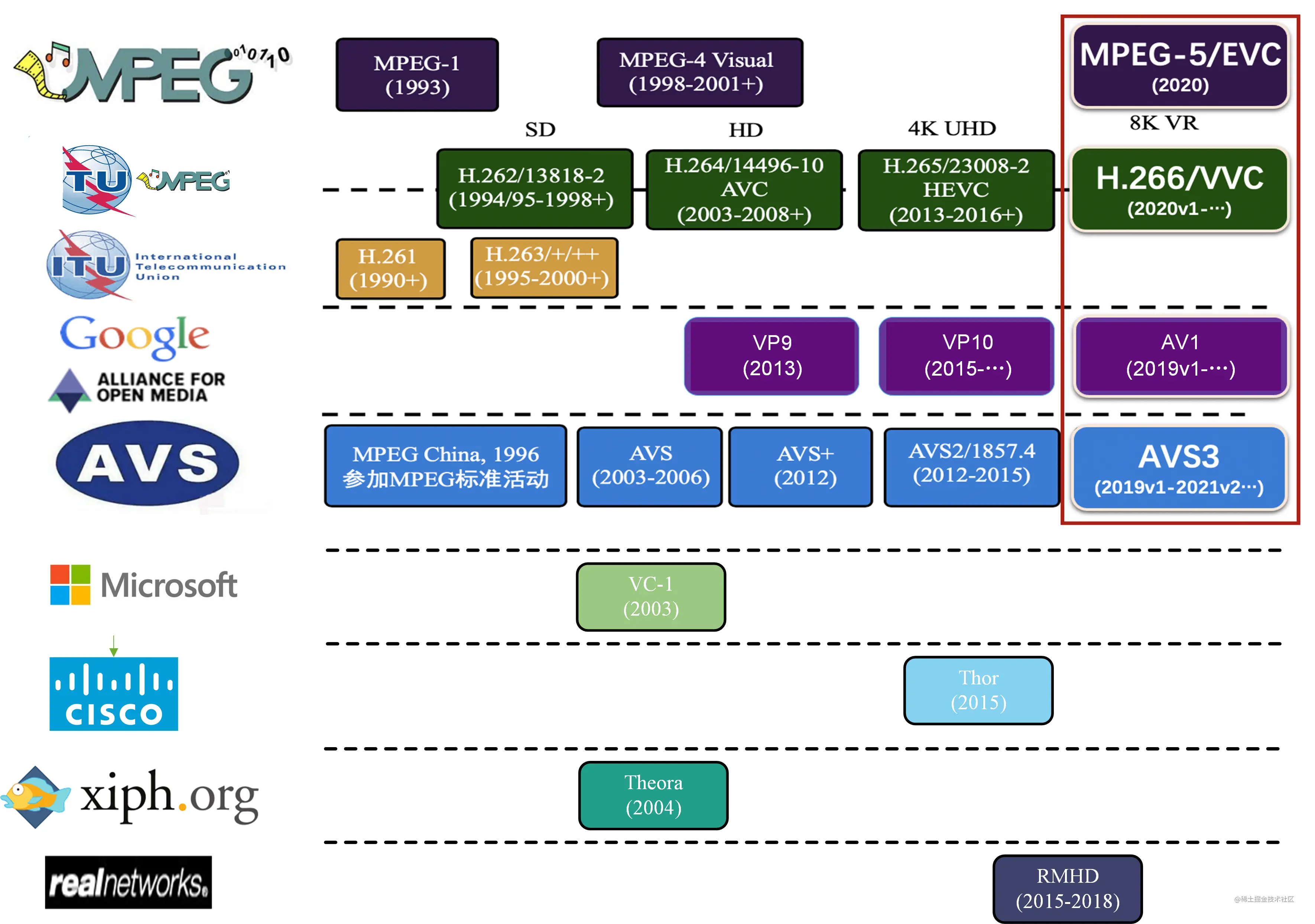
B站新支持的AOM联盟的AV1标准,免费而且没有潜在的版权问题。
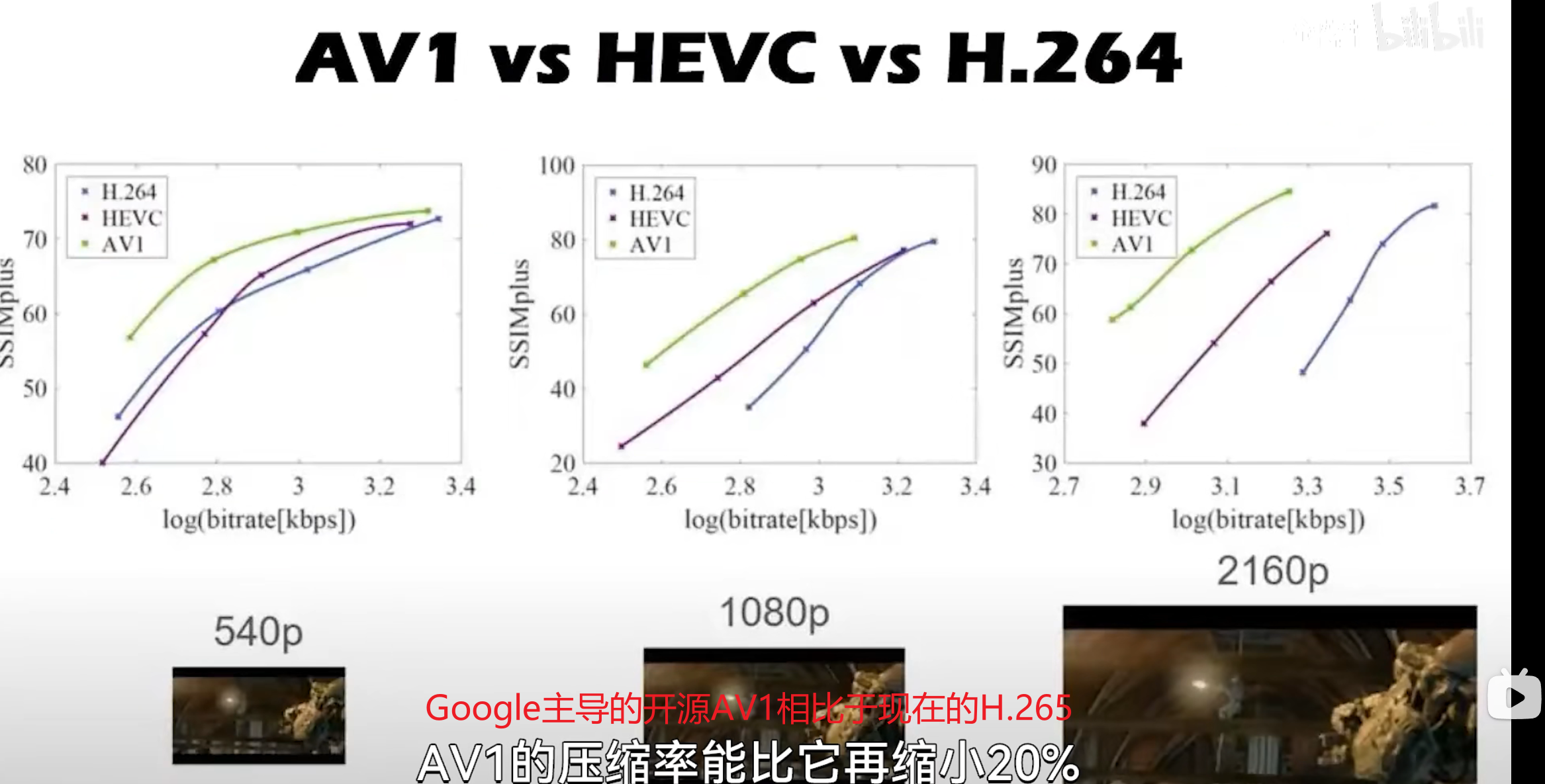
画质不变时,编码标准越先进,码率越低.

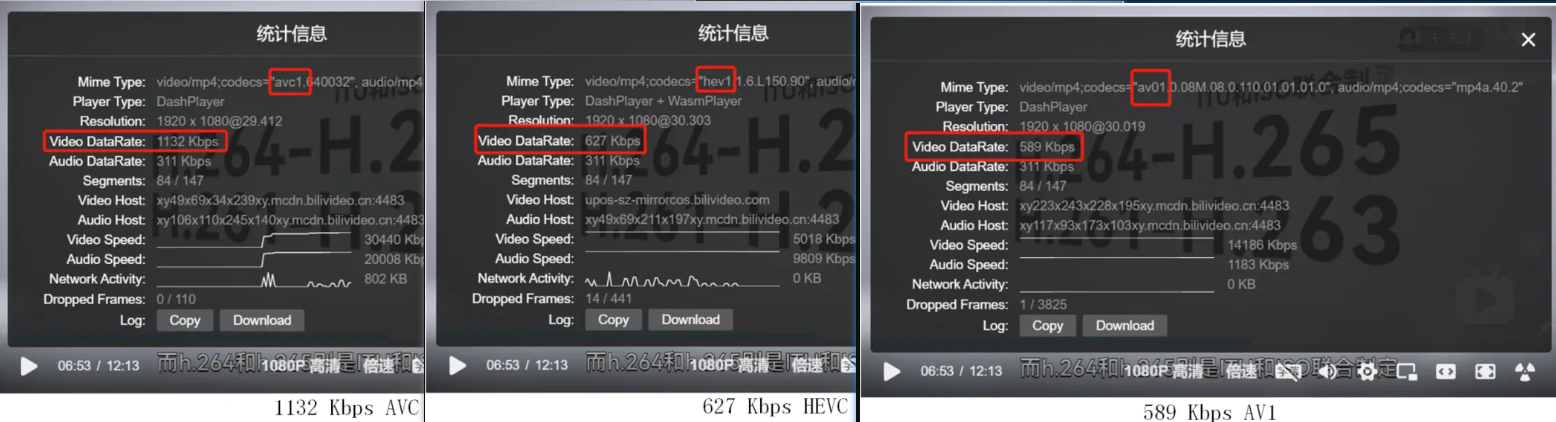
相对于优酷等最高大约4000的码率,虽然B站码率低,但是以普通的动画素材为主的视频而言,因为动画以简单的单色大色块居多,一般来说1500左右的码率就足够了。
目前 AVC 依然是使用最广泛的编码标准,无论新老设备都可以播放 AVC 视频,因此保留 AVC 编码可以保证广泛的兼容性。
但是 AVC 在编码超高清视频时,输出码率较高,无法保证良好的观看体验;同时很多 AVC 解码器也不支持 HDR 和 8K 视频的解码。而 HEVC 和 AV1 对于超高清视频的压缩能力明显提升,对于 HDR 和 8K 视频的支持显著改善,因此 B 站使用更先进的编码标准为用户提供服务。
低频率部分是最重要的信息。

先将视频分块,
1. 重用不变的色块
2. 对于平移的色块只记录移动矢量

帧间预测 & 帧内预测

 关键帧I帧 与 预测帧P帧
关键帧I帧 与 预测帧P帧
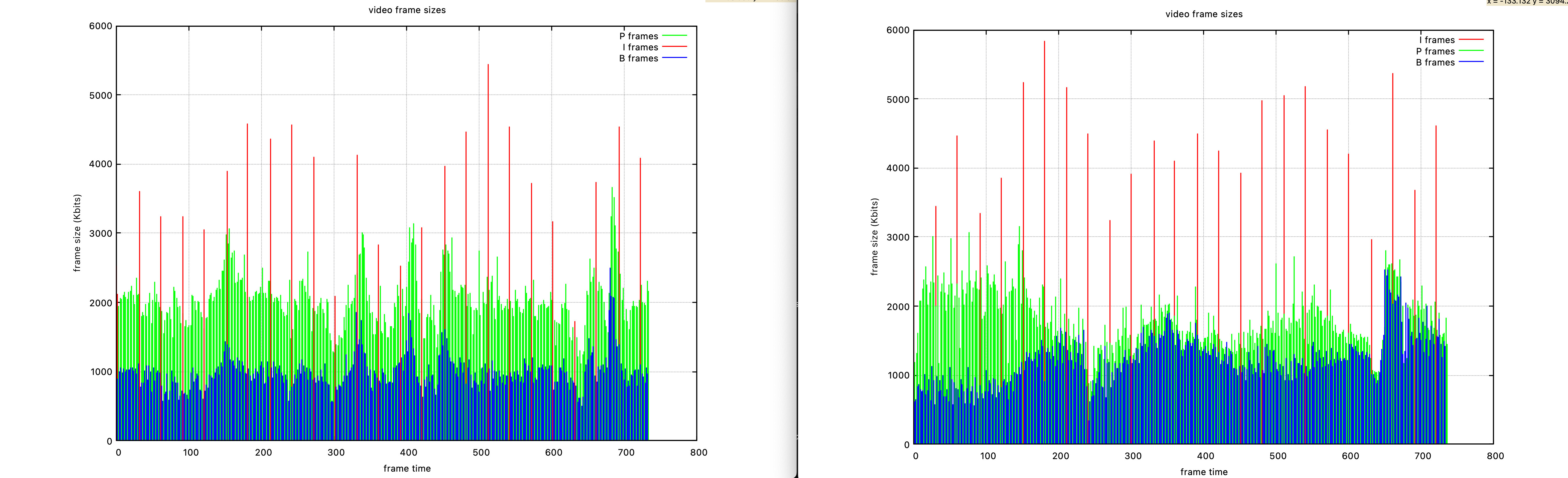
在 H.261 的基础上加入
1. 双向预测帧B帧
1. 更省空间,但是视频编码解码需要算力更大
2. 帧序列的概念
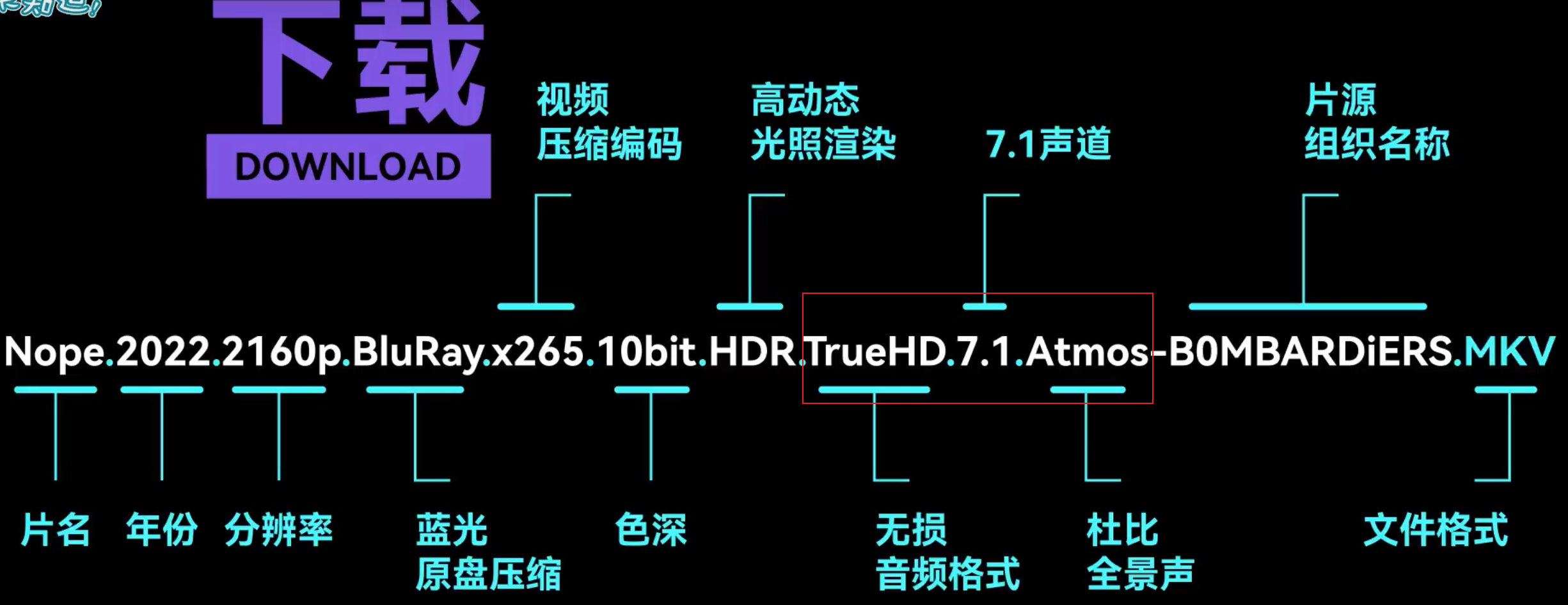
- 标 AVC / H264 / H.264 / x264 的可以一律看作H264
- 标 HEVC / HVC1 / H265 / H.265 / x265 的可以一律看作H265
- GB / CHS / SC / zh-Hans 指简中
- BIG5 / CHT / TC / zh-Hant 指繁中
- 远离闲杂播放器,拥抱 Potplayer / IINA / VLC / MPC-BE / MPV
- 容器
- mkv,mp4
- rmvb
- RealMedia可变比特率(RMVB)。在网速缓慢的时代,边下载边看是巨大优势
- 缺点:rm/rmvb格式编解码都是要收费。压缩比和速度都远逊于H264
- avi
- AVI是英语Audio Video Interleave(“音频视频交织”或译为“音频视频交错”)的首字母缩写,由微软在1992年11月推出的一种多媒体文件格式,用于对抗苹果Quicktime的技术。 现在所说的AVI多是指一种封装格式。
- 图像数据和声音数据是交互存放的。从尾部的索引可以索引跳到自己想放的位置。
- AVI與MP4本身只有聲音與影像沒有字幕

- ANSI 编码
- 美国国家标准学会(American National Standards Institute)的缩写
- ANSI并不是某一种特定的字符编码,而是在不同的系统中,ANSI表示不同的编码
- 在简体中文系统下,ANSI 编码代表 GB2312 编码,在日文操作系统下,ANSI 编码代表 JIS 编码。
- GB2312
- 国家推出的常见6000汉字
- GBK
- 微软拓展了繁体汉字的普通技术规范,所以windows上基本都是默认GBK
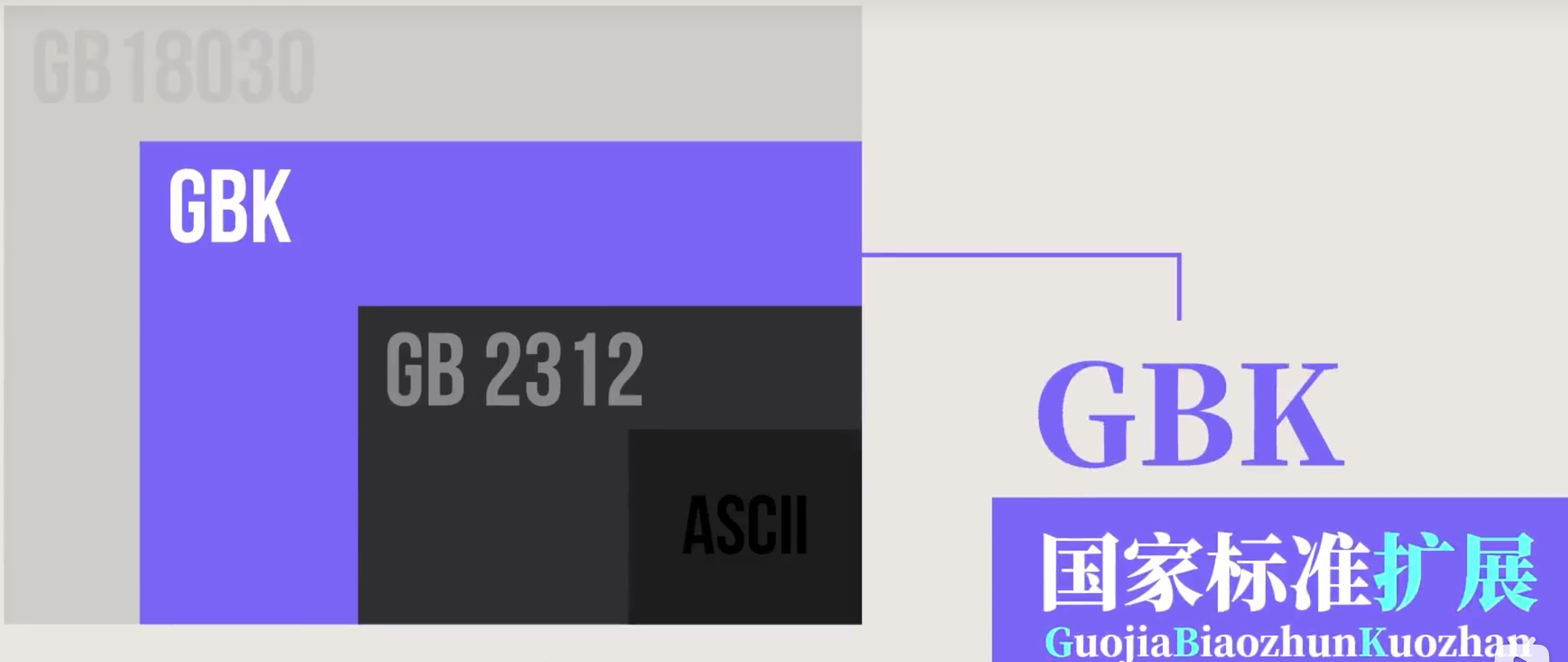
- UNICODE
- Universal Multiple-Octet Coded Character Set 统一码,初始就25种文字

- 采用了书写编码,导致会有长得像,但是完全不同的文字。导致很多钓鱼网站
- UTF-8编码
- UTF-8全称:8bit Unicode Transformation Format,8比特Unicode通用转换格式,是一种变长的编码方式。
- 其编码中的第一个字节仍然与ASCII兼容。
暂无
暂无
https://bravoing.github.io/2020/02/14/%E8%A7%86%E9%A2%91%E6%92%AD%E6%94%BE%E5%99%A8%E5%8E%9F%E7%90%86%E3%80%81%E5%88%86%E8%BE%A8%E7%8E%87%E3%80%81%E5%B8%A7%E7%8E%87%E3%80%81%E7%A0%81%E7%8E%87/
作者:哔哩哔哩技术 https://www.bilibili.com/read/cv16198183 出处:bilibili
https://www.youtube.com/watch?v=0LSHhatwTxM
柴知道也行
https://www.jianshu.com/p/c23f3ea5443d