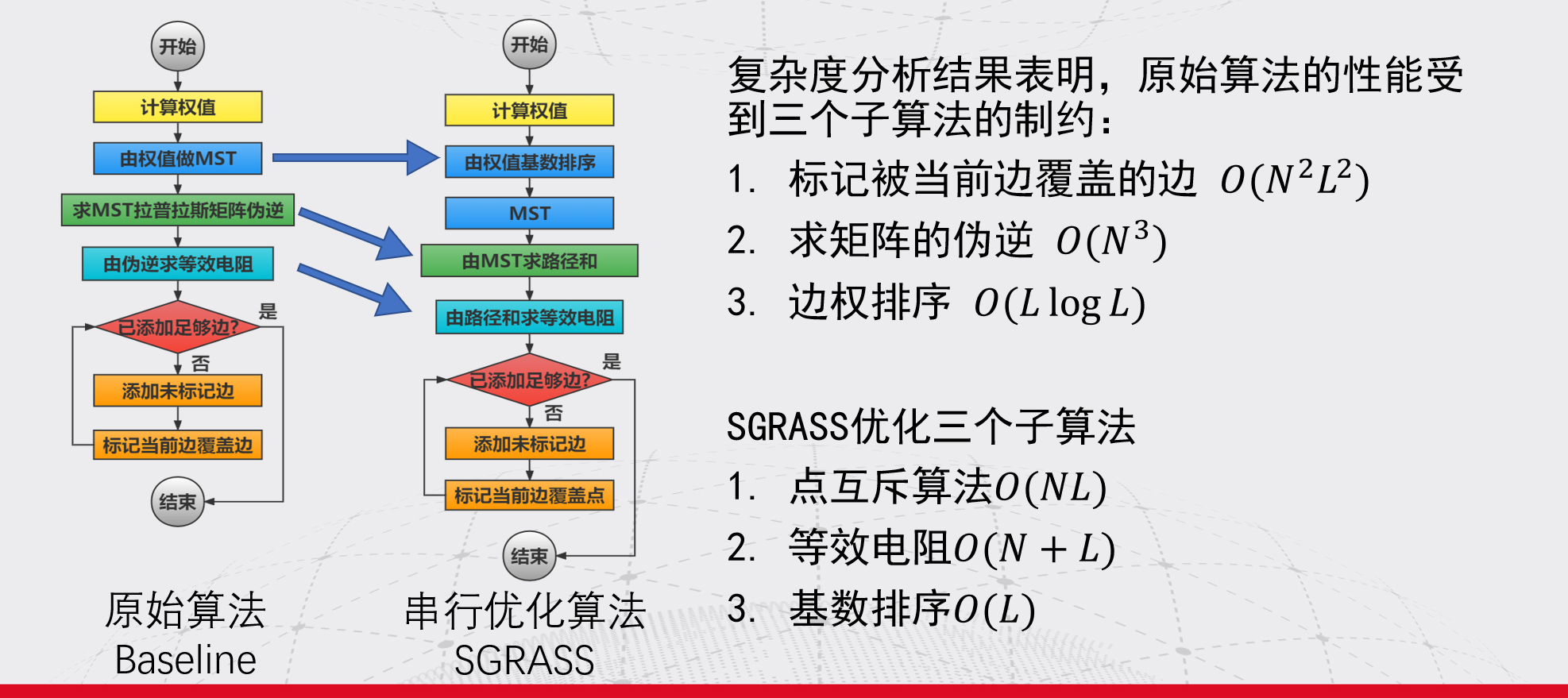
MAJ:MIN 主:次 设备号
TYPE:块设备类型,比如disk磁盘,part分区,lvm逻辑卷,rom只读存储
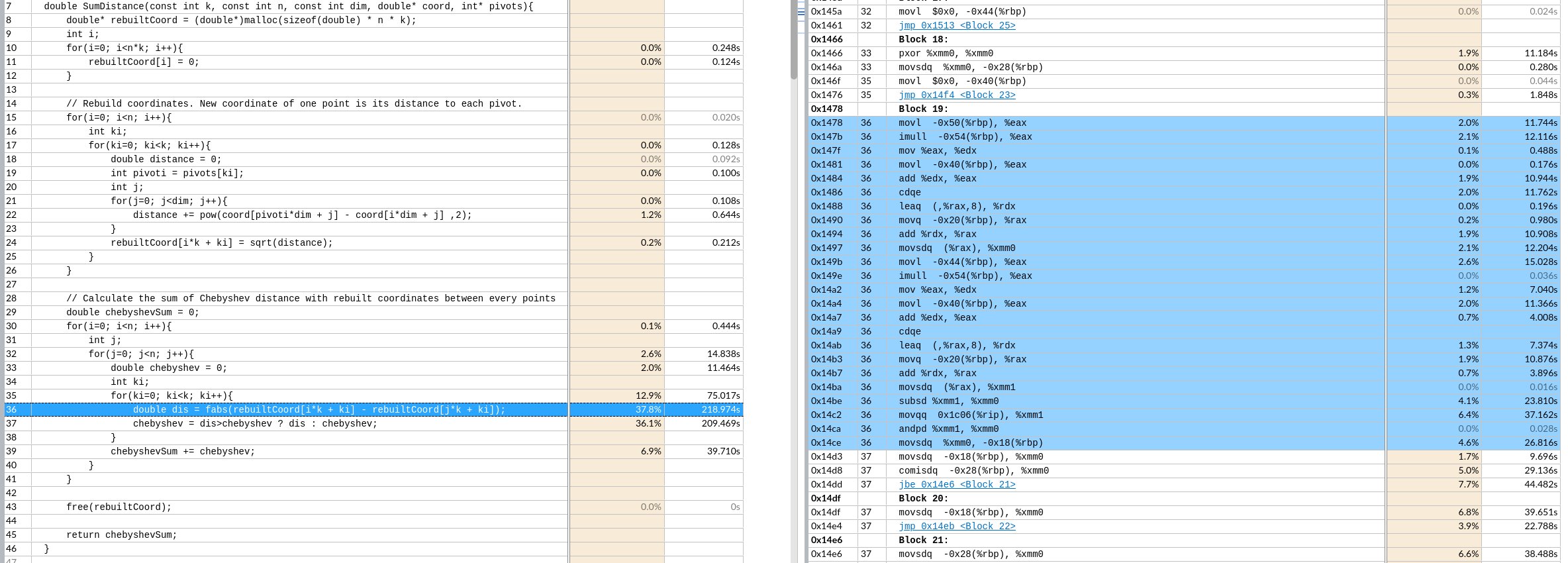
$ lsblk -f # 查看磁盘分区格式,有格式才能挂载成功。
NAME FSTYPE LABEL UUID FSAVAIL FSUSE% MOUNTPOINT
sda
├─sda1
└─sda2 ext4 9449ee1e-7cdb-4852-9c60-73959ce812c0 18.1G 93% /
sdb
lsblk显示 nvme2n1 什么意思
In the output of the lsblk command, nvme2n1 refers to a Non-Volatile Memory Express (NVMe) device. Here's a breakdown of the naming convention:
nvme: This prefix indicates that the device is an NVMe storage device, which is a type of high-performance, solid-state drive (SSD) that connects directly to the motherboard via the PCIe bus.
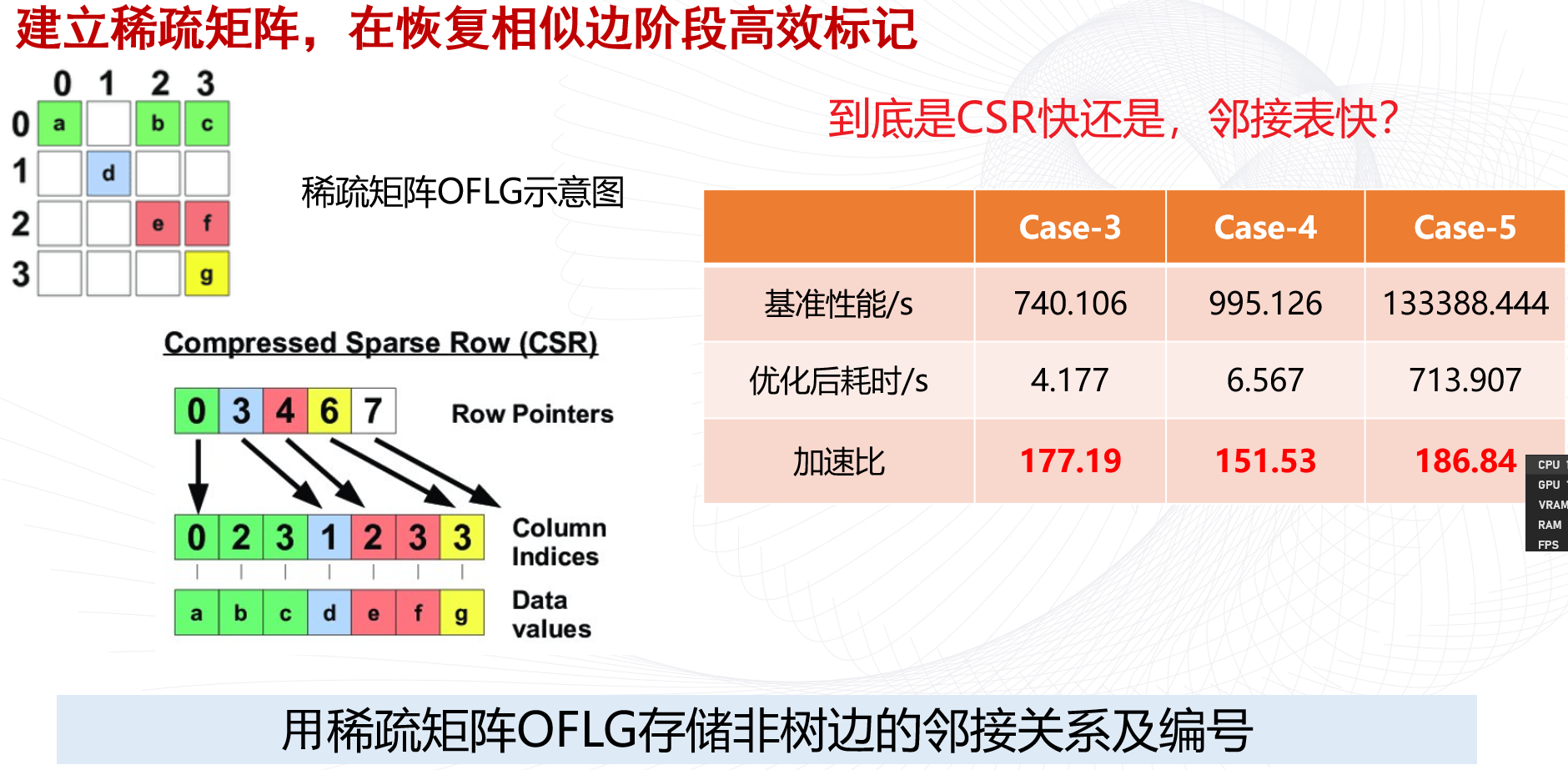
使用blkid命令对查询设备上所采用文件系统类型进行查询。blkid主要用来对系统的块设备(包括交换分区)所使用的文件系统类型、LABEL、UUID等信息进行查询。要使用这个命令必须安装e2fsprogs软件包。
直接使用blkid可列出当前系统中所以已挂载文件系统的类型。(或者 check /etc/fstab)
> blkid
/dev/sdb: UUID="2d900913-d0a4-4a15-7bd8-46dda015c95e" UUID_SUB="dc35a623-6a3e-f4fe-f9f7-05e102a9c7ec" LABEL="ubuntu-server:0" TYPE="linux_raid_member"
/dev/sdc: UUID="2d900913-d0a4-4a15-7bd8-46dda015c95e" UUID_SUB="7772d530-24d2-2064-29a3-9d61c0b6289e" LABEL="ubuntu-server:0" TYPE="linux_raid_member"
/dev/sda: UUID="2d900913-d0a4-4a15-7bd8-46dda015c95e" UUID_SUB="683c1101-69b1-f2c6-586b-155fbda91846" LABEL="ubuntu-server:0" TYPE="linux_raid_member"
/dev/sdd1: UUID="F51A-FBBA" TYPE="vfat" PARTUUID="f377e755-9c1e-41dd-b50b-cb50a095be4c"
/dev/sdd2: UUID="3df43f90-d64c-4061-bbca-2614ecc57f34" TYPE="ext4" PARTUUID="c599a2f0-9888-4f86-88fb-a49b9cde4666"
/dev/sdd3: UUID="f12ca879-4545-46b7-bb2e-bdcdf771cb96" TYPE="swap" PARTUUID="bb5ab1b6-f67b-46fc-aead-14b8b86972ad"
/dev/sdd4: UUID="07fbfa2a-6b48-4423-9260-dc36080b42c4" TYPE="ext4" PARTUUID="6b4f7a39-1c0f-4fcf-a407-b31e469a3cdc"
/dev/sdf: UUID="2d900913-d0a4-4a15-7bd8-46dda015c95e" UUID_SUB="86ffe123-2c7f-f7f1-40a0-57a12982fe17" LABEL="ubuntu-server:0" TYPE="linux_raid_member"
/dev/sdg: UUID="2d900913-d0a4-4a15-7bd8-46dda015c95e" UUID_SUB="36a06a4f-c84e-0684-8997-2997a68de012" LABEL="ubuntu-server:0" TYPE="linux_raid_member"
/dev/sdh: UUID="2d900913-d0a4-4a15-7bd8-46dda015c95e" UUID_SUB="369a926d-1f63-f397-ba4e-3118ef2ecf1d" LABEL="ubuntu-server:0" TYPE="linux_raid_member"
/dev/sde: UUID="2d900913-d0a4-4a15-7bd8-46dda015c95e" UUID_SUB="4dd3f6ca-1e73-2606-ec65-c98badcd77ad" LABEL="ubuntu-server:0" TYPE="linux_raid_member"
/dev/md0p1: UUID="c960e42b-f321-482d-aed4-c90f29e77291" TYPE="ext4" PARTUUID="d0949a94-c6e4-4621-890b-8d3f2d70fe57"
/dev/md0p2: UUID="addb8c13-8e34-4d8a-995b-101638f2dcbb" TYPE="ext4" PARTUUID="c6594348-58c5-49c2-9f40-82ce49653b7c"
/dev/md0p3: UUID="3354846e-7bec-45fb-8b59-4c6d60340d0d" TYPE="ext4" PARTUUID="8012f7e0-7dfa-46c5-b748-ef04d68a31ed"
/dev/md0p4: UUID="def8fb56-701e-4d6c-81d9-ecb765cc4d06" TYPE="ext4" PARTUUID="f6bb7944-fb1c-42de-af77-545c26303ad2"
/dev/md0p5: UUID="2f0590a9-6490-4758-999f-bdb5ef5954db" TYPE="ext4" PARTUUID="bbfe02f4-6b6a-4eeb-bb58-92b8b14b0997"
> blkid -o list
device fs_type label mount point UUID
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
/dev/sdb linux_raid_member ubuntu-server:0 (not mounted) 2d900913-d0a4-4a15-7bd8-46dda015c95e
/dev/sdc linux_raid_member ubuntu-server:0 (not mounted) 2d900913-d0a4-4a15-7bd8-46dda015c95e
/dev/sda linux_raid_member ubuntu-server:0 (not mounted) 2d900913-d0a4-4a15-7bd8-46dda015c95e
/dev/sdd1 vfat /boot/efi F51A-FBBA
/dev/sdd2 ext4 / 3df43f90-d64c-4061-bbca-2614ecc57f34
/dev/sdd3 swap [SWAP] f12ca879-4545-46b7-bb2e-bdcdf771cb96
/dev/sdd4 ext4 /tmp 07fbfa2a-6b48-4423-9260-dc36080b42c4
/dev/sdf linux_raid_member ubuntu-server:0 (not mounted) 2d900913-d0a4-4a15-7bd8-46dda015c95e
/dev/sdg linux_raid_member ubuntu-server:0 (not mounted) 2d900913-d0a4-4a15-7bd8-46dda015c95e
/dev/sdh linux_raid_member ubuntu-server:0 (not mounted) 2d900913-d0a4-4a15-7bd8-46dda015c95e
/dev/sde linux_raid_member ubuntu-server:0 (not mounted) 2d900913-d0a4-4a15-7bd8-46dda015c95e
/dev/md0p1 ext4 /home c960e42b-f321-482d-aed4-c90f29e77291
/dev/md0p2 ext4 /usr addb8c13-8e34-4d8a-995b-101638f2dcbb
/dev/md0p3 ext4 /boot 3354846e-7bec-45fb-8b59-4c6d60340d0d
/dev/md0p4 ext4 /var def8fb56-701e-4d6c-81d9-ecb765cc4d06
/dev/md0p5 ext4 /srv 2f0590a9-6490-4758-999f-bdb5ef5954db
帮助使用者唯一的确定系统中的所有存储设备,不管它们是什么类型的。它可以标识DVD驱动器,USB存储设备以及你系统中的硬盘设备等。
使用原因包括:设备名并非总是不变的
shaojiemike@brainiac1 ~/blockFrequency [08:02:54]
> df -lh
文件系统 容量 已用 可用 已用% 挂载点
udev 94G 0 94G 0% /dev
tmpfs 19G 4.3M 19G 1% /run
/dev/sdd2 984G 12G 923G 2% /
tmpfs 95G 88K 95G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 95G 0 95G 0% /sys/fs/cgroup
/dev/md0p3 20G 347M 19G 2% /boot
/dev/sdd4 53G 319M 50G 1% /tmp
/dev/md0p5 47G 53M 45G 1% /srv
/dev/sdd1 511M 3.6M 508M 1% /boot/efi
/dev/md0p4 590G 5.7G 554G 2% /var
/dev/md0p1 6.5T 5.1T 1.2T 82% /home
/dev/loop0 49M 49M 0 100% /snap/core18/2289
/dev/loop1 58M 58M 0 100% /snap/core20/1360
/dev/loop3 38M 38M 0 100% /snap/snapd/14982
/dev/loop4 38M 38M 0 100% /snap/snapd/15183
/dev/loop2 58M 58M 0 100% /snap/core20/1380
/dev/loop5 61M 61M 0 100% /snap/lxd/21843
/dev/loop7 49M 49M 0 100% /snap/core18/2349
/dev/loop6 62M 62M 0 100% /snap/lxd/22530
tmpfs 19G 0 19G 0% /run/user/1006
tmpfs 19G 0 19G 0% /run/user/1008
tmpfs 19G 0 19G 0% /run/user/1005
一种新的安装包管理方式。使用snapcraft将软件打包成snap格式的打包工具集。
+-----------+ +------------+ +------------+
| Developer +------>| Snapcraft +----->| Snap Store |
+-----------+ +------------+ +-----+------+
| update
v
+-----------+ +------------+ +------------+
| End User +------>| Snap +----->| Snapd |
+-----------+ +-----+------+ +-----+------+
| containerize |
v |
+------------+ |
| Snaps |<-----------+ manage
+------------+
snap的每个版本软件会,占用一个/dev/loop
/snap/core18 代表ubuntu 18版本的软件所运行的环境
/snap/core20 代表ubuntu 20版本的软件所运行的环境
Snap应用运行在以Ubuntu
为核心的容器里,与各个发行版做到了解耦。因此Snap应用的开发者很开心了,
只需保证自己应用在[Ubuntu Core]欢快运行即可,不需要考虑其他发行版的适配。
Snap应用由snapd守护进程管理。snapd每天会去Snap Store查本地Snap应
用有没有可用更新,如果有,就把更新拿下来,应用到当前Snap应用上。自动更新不可关闭,但是可以设置延迟60天。
lxc是Linux Container的简写,它是一种内核虚拟化技术,可以提供轻量级的虚拟化,以便隔离进程和资源;它不需要提供指令解释机制,没有全虚拟化的复杂性,相当于C++中的NameSpace。
lxc容器能有效地把操作系统管理的资源划分到不同的组中,并能在不同的组之间平衡有冲突的资源使用需求,因此它可以在单一的主机节点上同时执行多个相互隔离的容器。
lxd是基于lxc构筑的容器管理进程,提供镜像、网络、存储、以及容器等能力。
大家可能有个疑问,为什么不用docker容器呢?docker容器原先也是我的首选,但实际操作过程中发现snap包安装所需要的squashfs文件系统在docker中无法mount,会出现如下错误:
system does not fully support snapd: cannot mount squashfs imag
/dev/shm下的tmpfs是内存的一半,是一个临时文件系统,驻留在内存中,所以/dev/shm/这个目录不在硬盘上,而是在内存里。因为是在内存里,所以读写非常快,可以提供较高的访问速度。
/sys/fs/cgroup是systemd在代码里自动挂载的。cgroups(Control Groups) 是 linux 内核提供的一种机制,这种机制可以根据需求把一系列系统任务及其子任务整合(或分隔)到按资源划分等级的不同组内,从而为系统资源管理提供一个统一的框架。简单说,cgroups 可以限制、记录任务组所使用的物理资源。
/run/user是每个login的用户所需的一些数据
> ls /run/user -l
总用量 0
drwx------ 7 qcjiang qcjiang 360 Jul 11 14:54 1005
drwx------ 7 shaojiemike shaojiemike 780 Jul 11 01:10 1006
drwx------ 7 zwcao zwcao 360 Jul 9 15:48 1008
drwx------ 7 udfrt udfrt 200 Jul 11 16:03 1010
利用tmpfs这个特性可以用来提高服务器性能,把一些对读写性能要求较高,但是数据又可以丢失的这样的数据保存在/dev/shm中,来提高访问速度。
tmpfs用途还是较广的,Linux中可以把一些程序的临时文件放置在tmpfs中,利用tmpfs比硬盘速度快的特点来提升系统性能。比如可以用来放squid程序的缓存文件。
# 临时调整大小,重启后会恢复正常,恢复为内存一半大小。
mount -o remount,size=777M tmpfs /dev/shm
# 永久修改
vim /etc/fstab
# 把tmpfs这一行改为:
tmpfs /dev/shm tmpfs defaults,size=777M 0 0
/etc/fstab 是专门用配置挂载硬盘的文件
语法为:
[Device] [Mount Point] [File System Type] [Options] [Dump] [Pass]
[Device] 包含文件系统的device或者partition
[Mount Point] 挂载的目录,从该目录可以访问设备/分区的内容(注意:swap没有装入点)
[File System Type] 文件系统类型
[Options] mount的选项,默认的defaults
[Dump] 是否开启备份,0 来表示不备份这个区
[Pass] fsck是否会check该区域,0表示不检查。fsck (文件系统检查)是一种命令行程序,可让您在一个或多个Linux文件系统上执行一致性检查和交互式修复。 它用于检查指定类型文件系统。 在系统无法启动或无法安装分区的情况下,可以使用 fsck 命令修复损坏的文件系统。
device 有两种表示方式,可以用/dev/xdx 之类的location 或者 硬件的UUID 来表示,硬件的UUID 可以用blkid 来查询
对于uuid
# / was on /dev/sdd2 during curtin installation
/dev/disk/by-uuid/3df43f90-d64c-4061-bbca-2614ecc57f34 / ext4 defaults 0 0
> blkid |grep 3df
/dev/sdd2: UUID="3df43f90-d64c-4061-bbca-2614ecc57f34" TYPE="ext4" PARTUUID="c599a2f0-9888-4f86-88fb-a49b9cde4666"
对于id
# /home was on /dev/md0p1 during curtin installation
/dev/disk/by-id/md-uuid-2d900913:d0a44a15:7bd846dd:a015c95e-part1 /home ext4 defaults 0 0
# /usr was on /dev/md0p2 during curtin installation
/dev/disk/by-id/md-uuid-2d900913:d0a44a15:7bd846dd:a015c95e-part2 /usr ext4 defaults 0 0
# /boot was on /dev/md0p3 during curtin installation
/dev/disk/by-id/md-uuid-2d900913:d0a44a15:7bd846dd:a015c95e-part3 /boot ext4 defaults 0 0
# /var was on /dev/md0p4 during curtin installation
/dev/disk/by-id/md-uuid-2d900913:d0a44a15:7bd846dd:a015c95e-part4 /var ext4 defaults 0 0
# /srv was on /dev/md0p5 during curtin installation
/dev/disk/by-id/md-uuid-2d900913:d0a44a15:7bd846dd:a015c95e-part5 /srv ext4 defaults 0 0
> blkid |grep a015c95e
/dev/sdb: UUID="2d900913-d0a4-4a15-7bd8-46dda015c95e" UUID_SUB="dc35a623-6a3e-f4fe-f9f7-05e102a9c7ec" LABEL="ubuntu-server:0" TYPE="linux_raid_member"
/dev/sdc: UUID="2d900913-d0a4-4a15-7bd8-46dda015c95e" UUID_SUB="7772d530-24d2-2064-29a3-9d61c0b6289e" LABEL="ubuntu-server:0" TYPE="linux_raid_member"
/dev/sda: UUID="2d900913-d0a4-4a15-7bd8-46dda015c95e" UUID_SUB="683c1101-69b1-f2c6-586b-155fbda91846" LABEL="ubuntu-server:0" TYPE="linux_raid_member"
/dev/sdf: UUID="2d900913-d0a4-4a15-7bd8-46dda015c95e" UUID_SUB="86ffe123-2c7f-f7f1-40a0-57a12982fe17" LABEL="ubuntu-server:0" TYPE="linux_raid_member"
/dev/sdg: UUID="2d900913-d0a4-4a15-7bd8-46dda015c95e" UUID_SUB="36a06a4f-c84e-0684-8997-2997a68de012" LABEL="ubuntu-server:0" TYPE="linux_raid_member"
/dev/sdh: UUID="2d900913-d0a4-4a15-7bd8-46dda015c95e" UUID_SUB="369a926d-1f63-f397-ba4e-3118ef2ecf1d" LABEL="ubuntu-server:0" TYPE="linux_raid_member"
/dev/sde: UUID="2d900913-d0a4-4a15-7bd8-46dda015c95e" UUID_SUB="4dd3f6ca-1e73-2606-ec65-c98badcd77ad" LABEL="ubuntu-server:0" TYPE="linux_raid_member"
这里可以看到这7个硬盘的UUID是一样的,说明属于同一个RAID文件系统卷,但是子卷UUID_SUB是不一样的
问题:
- 为什么8块盘里
/dev/sdd1第四块被拆成了4份
- blkid里的
- UUID_SUB 什么意思
- /dev/md0p1
- 好像和GPT分区有关
- 为什么device里 /dev/md0p1 没和blkid的对应上
auto, vfat( for FAT partition), ntfs or ntfs-3g( for NTFS partition), ext4 or ext3 or ext2 or jfs, udf or iso9660 ( for CD/DVD), swap
当服务器插入一块硬盘,如果我们想要使用该硬盘,需要先使用磁盘分区管理工具进行磁盘分区,然后格式化分区,把分区挂载到目录
上,才可以正式使用该硬盘存储文件。磁盘分区管理工具有很多,本文主要介绍fdisk,gdisk,parted,并进行比较。
fdisk -l和gdisk -l /dev/sda都可以,下面介绍另一种
sudo parted -l
型号:TOSHIBA AL15SEB120N (scsi) 磁盘 /dev/sdd: 1200GB
扇区大小 (逻辑/物理):512B/512B
分区表:gpt
磁盘标志:
编号 起始点 结束点 大小 文件系统 名称 标志
1 1049kB 538MB 537MB fat32 启动, EFI 启动
2 538MB 1074GB 1074GB ext4
3 1074GB 1143GB 68.7GB linux-swap(v1) 交换
4 1143GB 1200GB 57.2GB ext4
型号:Linux 软件 RAID 数组 (md)
磁盘 /dev/md0: 8401GB
扇区大小 (逻辑/物理):512B/512B
分区表:gpt
磁盘标志:
编号 起始点 结束点 大小 文件系统 名称 标志
1 1049kB 7147GB 7147GB ext4
2 7147GB 7684GB 537GB ext4
3 7684GB 7705GB 21.5GB ext4
4 7705GB 8349GB 644GB ext4
5 8349GB 8401GB 51.3GB ext4
可以看出上面的普通硬盘和RAID0都是GPT。#显示Partition Table: msdos,则是MBR分区
是传统的分区机制,应用于绝大多数使用BIOS引导的PC设备(苹果使用EFI的方式),很多Server服务器即支持BIOS也支持EFI的引导方式。MBR只支持不超过2TB的硬盘。
MBR分区分为:
- 主分区(一块硬盘最多只能创建4个主分区)、
- 扩展分区(一个扩展分区会占用一个主分区的位置)、
- 逻辑分区(逻辑分区是基于扩展分区创建出来的,
- 先有扩展分区,然后在扩展分区的基础上再创建逻辑分区;
- 也就是说我们要使用逻辑分区,必须先要创建扩展分区,扩展分区的空间是不能被直接使用的,
- 我们必须在扩展分区的基础上去建立逻辑分区,才能够被使用)。
- 在Linux上使用扩展分区和逻辑分区最多可以创建15个分区;
解决了MBR的很多缺点;
1. 支持超过2TB的磁盘;
2. 向后兼容MBR;
3. GPT分区只支持64位操作系统;
必须先取消挂载,取消挂载后分区。不然分区结果重启后会消失,文件全没了。
创建一个主分区,一个扩展分区,其中扩展分区包含两个逻辑分区。
lsblk
sdb 8:16 0 1G 0 disk
└─sdb1 8:17 0 200M 0 part
sdb这块磁盘大小为1G。而且已有分区sdb1
# fdisk /dev/sdb
p #打印分区表
d #因为此磁盘只有一个分区sdb1,所以按d删除时候默认不会让选择要删除的分区,如果有多个分区会提示要删除的分区。
p #打印分区表,再次查看分区表,发现/dev/sdb1已经被删除
Command (m for help): n #新建分区
Partition type:
p primary (0 primary, 0 extended, 4 free) #主分区
e extended #扩展分区
Select (default p): p #选择新建主分区
Partition number (1-4, default 1): #主分区号,会生成/dev/sdb1
First sector (2048-2097151, default 2048): #开始扇区,回车默认从2048开始
Using default value 2048
Last sector, +sectors or +size{K,M,G} (2048-2097151, default 2097151): +50M #分配主分区大小,在此为50M
Partition 1 of type Linux and of size 50 MiB is set
Command (m for help): n #新建分区
Partition type:
p primary (1 primary, 0 extended, 3 free)
e extended
Select (default p): e #选择创建扩展分区
Partition number (2-4, default 2): #扩展分区编号,在此我们直接回车,默认为/dev/sdb2
First sector (104448-2097151, default 104448): #默认回车,从当前扇区开始
Using default value 104448
Last sector, +sectors or +size{K,M,G} (104448-2097151, default 2097151): +500M #分配扩展分区大小,在此为500M
Partition 2 of type Extended and of size 500 MiB is set
Command (m for help): n
Partition type:
p primary (1 primary, 1 extended, 2 free)
l logical (numbered from 5)
Select (default p): l #新建逻辑分区
Adding logical partition 5 #默认逻辑分区编号为5
First sector (106496-1128447, default 106496): #逻辑分区起始位置
Using default value 106496
Last sector, +sectors or +size{K,M,G} (106496-1128447, default 1128447): +200M #分配逻辑分区大小,在此为200M
Partition 5 of type Linux and of size 200 MiB is set
Command (m for help): n
Partition type:
p primary (1 primary, 1 extended, 2 free)
l logical (numbered from 5)
Select (default p): l #新建第二个逻辑分区
Adding logical partition 6
First sector (518144-1128447, default 518144):
Using default value 518144
Last sector, +sectors or +size{K,M,G} (518144-1128447, default 1128447): #直接回车,默认分配剩余空间
Using default value 1128447
Partition 6 of type Linux and of size 298 MiB is set
Command (m for help): p
...
Disk label type: dos
Device Boot Start End Blocks Id System
/dev/sdb1 2048 104447 51200 83 Linux
/dev/sdb2 104448 1128447 512000 5 Extended
/dev/sdb5 106496 516095 204800 83 Linux
/dev/sdb6 518144 1128447 305152 83 Linux
#通过如上输出可知,/dev/sdb1为主分区,/dev/sdb2为扩展分区,扩展分区又包含两个逻辑分区/dev/sdb5和/dev/sdb6
Command (m for help): w #保存分区信息并退出
[root@node5 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sdb 8:16 0 1G 0 disk
├─sdb1 8:17 0 50M 0 part
├─sdb2 8:18 0 1K 0 part
├─sdb5 8:21 0 200M 0 part
└─sdb6 8:22 0 298M 0 part
把/dev/sdb5格式化成ext4文件系统
[root@node5 ~]# mkfs.ext4 /dev/sdb5
mkdir /sdb5
mount /dev/sdb5 /sdb5
磁盘分区使用mount手动挂载之后,还需要把挂载信息写入/etc/fstab文件中,不然重启之后,需要重新挂载。
mdadm是一个用于创建、管理、监控RAID设备的工具,它使用linux中的md驱动。mdadm程序是一个独立的程序,能完成所有软件RAID的管理功能。常见功能如下:
- mdadm --create device options...
- Create a new array from unused devices.
- mdadm --manage device options...
- make changes to an existing array.
- mdadm --misc options... devices
- report on or modify various md related devices.
配置文件,默认是”/etc/mdadm.conf”或者是”/etc/mdadm/mdadm.conf”
> cat /etc/mdadm/mdadm.conf
ARRAY /dev/md0 metadata=1.2 name=ubuntu-server:0 UUID=2d900913:d0a44a15:7bd846dd:a015c95e
MAILADDR root
–metadata=定义组件设备上超级块的类型。对于–create,默认是0.90。
0,0.90 : 限制一个RAID中的设备数为28个,限制组件设备大小为2TB
1,1.0,1.1,1.2 :不同的子版本号标识在不同的地方存储超级块。1.0在设备的结尾,1.1在设备的开头,1.2在设备的4K处。
MAILADDR 使用monitor模式(同时也使–scan选项)时,警报事件发送到的Email地址。
sudo mdadm -Ds > /etc/mdadm/mdadm.conf
把查询出来的 RAID 信息写到 mdadm.conf 中
-s 或 --scan 扫描 RAID 设备;-D 或 --detail 查看 RAID 的详细信息
> cat /proc/mdstat
Personalities : [raid0] [linear] [multipath] [raid1] [raid6] [raid5] [raid4] [raid10]
md0 : active raid0 sdf[4] sde[3] sdh[6] sdg[5] sda[0] sdc[2] sdb[1]
8203865600 blocks super 1.2 512k chunks
unused devices: <none>
猜测命令
mdadm –create /dev/md0 –chunk=512 –metadata=1.2 –level=0 –raid-devices=7 /dev/sda /dev/sdb /dev/sdc /dev/sde /dev/sdf /dev/sdg /dev/sdh
说明:使用7块创建RAID0,条带大小是512KB。
创建完之后
> lsblk -l
md0 9:0 0 7.7T 0 raid0
md0p1 259:0 0 7.7T 0 md
fdisk /dev/md0 #分区
mount /dev/md0p1 /home/ #挂载
mount /dev/md0p2 /usr/ #挂载
mount /dev/md0p3 /boot/ #挂载
...
> lsblk -l
md0 9:0 0 7.7T 0 raid0
md0p1 259:0 0 6.5T 0 part /home
md0p2 259:1 0 500G 0 part /usr
md0p3 259:2 0 20G 0 part /boot
md0p4 259:3 0 600G 0 part /var
md0p5 259:4 0 47.8G 0 part /srv
vi /etc/fstab #设置开机自动挂载
增大RAID 的大小涉及按给定顺序执行下列任务:
- 增加所有组成 RAID 的所有分区的大小,
- 增加 RAID 本身的大小,
- 最后增加文件系统的大小。
第一步:
mdadm /dev/md0 --add /dev/sdc1
说明:给md0增加热备盘sdc1。运行cat /proc/mdstat等到 RAID 同步并一致,然后再继续下一个分区。
第二步:
RAID 阵列配置将继续使用原始阵列大小,直到您强制其了解新的可用空间。您可以为 RAID 指定大小或使用最大可用空间。
查看大小
sudo mdadm -D /dev/md0 | grep -e "Array Size" -e "Dev Size"
将RAID大小增加到最大可用大小
sudo mdadm --grow /dev/md0 -z max
第三步: 不确定
更改 Ext2、Ext3 或 Ext4 文件系统的大小(先查看md0分区大小)
先fdisk删除part1分区,新建同名(同分区标号)的分区,First cylinder起始点相同,通过改变终点为最大值来扩容。
将文件系统大小扩展为名为 /dev/md0 的设备的最大可用大小,请输入
> sudo resize2fs /dev/md0p1
resize2fs 1.45.5 (07-Jan-2020)
文件系统已经为 1744830464 个块(每块 4k)。无需进一步处理!
如果未指定大小参数,大小将默认为该分区的大小。
Loop设备是一种块设备,但是它并不指向硬盘或者光驱,而是指向一个文件块或者另一种块设备。
回环设备( 'loopback device')允许用户以一个普通磁盘文件虚拟一个块设备。设想一个磁盘设备,对它的所有读写操作都将被重定向到读写一个名为 disk-image 的普通文件而非操作实际磁盘或分区的轨道和扇区。(当然,disk-image 必须存在于一个实际的磁盘上,而这个磁盘必须比虚拟的磁盘容量更大。)回环设备允许你这样使用一个普通文件。
将一个Loop设备指向一个文件系统文件,比如iso文件,紧接着就可以通过mount挂载该loop设备到主文件系统的一个目录下了,我们就可以正常访问该镜像中的内容,就像访问一个文件系统一样。
losetup -a列出已使用的。
loop设备映射或者指向一个文件:
# 创建一个文件
dd if=/dev/zeroof=/var/loop.img bs=1M count=10240
# 使用losetup将文件转化为块设备,获得了一个磁盘
losetup /dev/loop0 /var/loop.img
# 在磁盘上构建文件系统
# 挂载
mkdir /myloopdev
mount /dev/loop0 /myloopdev
# 正常使用
# 卸载该磁盘
umount /myloopdev
# 接着删除该loop设备,
losetup –d /dev/loop0
注意,推进插入的时候把卡扣打开

fdisk -l # 看不见新盘
lsblk # 也看不见
sudo reboot # 重启
还是找不到? 还是8块。
猜测:盘坏了吗?
额外找了其他类型的盘,还有160GB的固态插上。确实是四块坏盘。换了借口也无法识别。
sudo shutdown -h now # 热拔插还是有风险
总算整了5块
sdi 8:128 0 931.5G 0 disk
└─sdi1 8:129 0 931.5G 0 part
sdj 8:144 0 149.1G 0 disk
├─sdj1 8:145 0 512M 0 part
└─sdj2 8:146 0 148.6G 0 part
sdk 8:160 0 1.8T 0 disk
└─sdk1 8:161 0 1.8T 0 part
sdl 8:176 0 1.8T 0 disk
└─sdl1 8:177 0 1.8T 0 part
sdm 8:192 0 1.8T 0 disk
└─sdm1 8:193 0 1.8T 0 part
那sdk为例。
> sudo fdisk /dev/sdk #d 删除分区
> sudo mdadm /dev/md0 --add /dev/sdk
mdadm: add new device failed for /dev/sdk as 7: Invalid argument
# 没分区的结构
尝试分区后add分区
> sudo mdadm /dev/md0 --add /dev/sdk1
mdadm: add new device failed for /dev/sdk1 as 7: Invalid argument
第二种:
mdadm --grow /dev/md0 --level=0 --raid-devices=8 --add /dev/sdk
理论上这样的,但是要reshape,而且和dev.raid.speed_limit_max速度有关。我不确定会不会丢失资料,所以没尝试。
所以没有扩容
先格式化各个分区
> blkid -o list
/dev/sdi1 ext4 (not mounted)
/dev/sdl1 LVM2_member (not mounted)
/dev/sdm1 LVM2_member (not mounted)
/dev/sdk1 LVM2_member (not mounted)
sdi/l/m/k 全部格式化为ext4。blkid -o list不是实时的。挂载后通过df -Th查看
sudo mkfs.ext4 /dev/sdk1
sudo mount /dev/sdk1 /addDisk/DiskNo4
修改权限,大家都可以访问(直接777算了
sudo chmod -R ogu+r+w+X /addDisk
配置开机启动,blkid -o list 获得uuid
/dev/sdk1 ext4 (not mounted) ac862e68-9c6f-424a-b4ec-e44e62f7a330
/dev/sdj1 ext4 (not mounted) 8258b393-2e8e-41d1-9b84-0a7f88986443
/dev/sdl1 ext4 (not mounted) 5c2e1324-ecc5-40dd-a668-4ec682065d9f
/dev/sdi1 ext4 (not mounted) 0ae289c5-51f7-4ef2-a07c-6ec8d123e065
修改/etc/fstab
# /addDisk/DiskNo1 was on /dev/sdi1 during curtin installation
/dev/disk/by-uuid/0ae289c5-51f7-4ef2-a07c-6ec8d123e065 /addDisk/DiskNo1 ext4 defaults 0 0
# /addDisk/DiskNo2 was on /dev/sdl1 during curtin installation
/dev/disk/by-uuid/5c2e1324-ecc5-40dd-a668-4ec682065d9f /addDisk/DiskNo2 ext4 defaults 0 0
# /addDisk/DiskNo3 was on /dev/sdj1 during curtin installation
/dev/disk/by-uuid/8258b393-2e8e-41d1-9b84-0a7f88986443 /addDisk/DiskNo3 ext4 defaults 0 0
# /addDisk/DiskNo4 was on /dev/sdk1 during curtin installation
/dev/disk/by-uuid/ac862e68-9c6f-424a-b4ec-e44e62f7a330 /addDisk/DiskNo4 ext4 defaults 0 0
USB启动的系统,会挂载在COPY-ON-WRITE
ubuntu@ubuntu:/dev$ df -lh
Filesystem Size Used Avail Use% Mounted on
udev 126G 0 126G 0% /dev
tmpfs 26G 3.0M 26G 1% /run
/dev/sdc1 29G 2.1G 27G 8% /cdrom -- USB启动的设备
/dev/loop0 2.0G 2.0G 0 100% /rofs
/cow 126G 209M 126G 1% /
- 查找未挂载的盘 lsblk
- 判断硬盘好坏,是否坏道
- 检测坏块
sudo badblocks -v /dev/sda > badsectors.txt
- 综合评价
sudo smartctl -H /dev/sda10
- 格式化硬盘
- 挂载新分区
- 查看已有盘挂载的分区
- 如何挂载已有分区
暂无
https://forum.ubuntu.org.cn/viewtopic.php?t=487421
https://bbs.huaweicloud.com/blogs/197847
https://blog.csdn.net/dangelzjj/article/details/104200396
https://www.cnblogs.com/renshengdezheli/p/13941563.html
https://linux.cn/article-7961-1.html
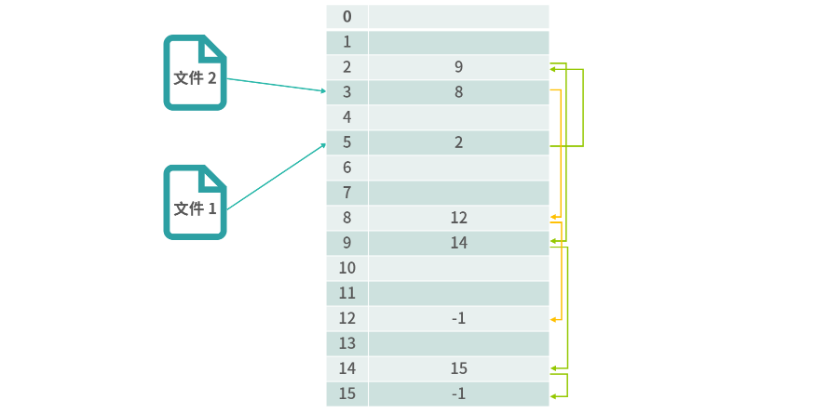 链表结构解决了文件和物理块映射的问题。
链表结构解决了文件和物理块映射的问题。