隐藏文件夹 .github , 里面放两个文件:
ISSUE_TEMPLATE.md
PULL_REQUEST_TEMPLATE.md
仓库有两个基础分支:
通过pull request来合并新的代码:
协作者的代码通过pr合并到dev
dev通过pr合并到master
注意点:
merge 到 dev,使用squash merge
merge 到 master,使用普通的merge
永远不向master直接commit代码
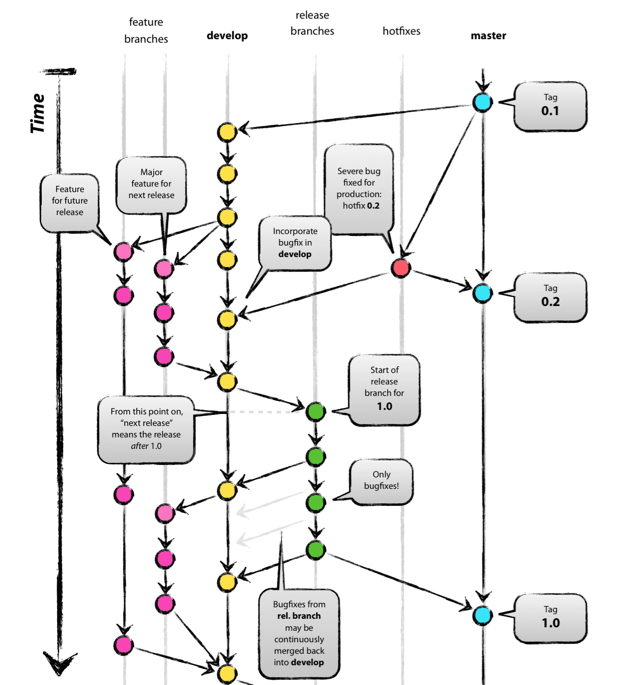
只有一个长期分支 master ,而且 master 分支上的代码,永远是可发布状态,
to do
github自带的,貌似比Travis CI好用
ctest 怎么写
自动化生成TOC 目录
可以使用 toc-generator
- 在README里配置插入TOC的位置
<!-- START doctoc -->
<!-- END doctoc -->
- 配置GitHub Action, 需要在仓库的
Settings > Actions > General里的Workflow permissions开启Read and write permissions
name: Generate TOC
on:
push:
branches:
- main
jobs:
toc:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- uses: technote-space/toc-generator@v4
with:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
Travis CI 提供的是持续集成服务(Continuous Integration,简称 CI)。它绑定 Github 上面的项目,只要有新的代码,就会自动抓取。然后,提供一个运行环境,执行测试,完成构建,还能部署到服务器。
持续集成的好处在于,每次代码的小幅变更,就能看到运行结果,从而不断累积小的变更,而不是在开发周期结束时,一下子合并一大块代码。
- 使用准备
- 登录 https://app.travis-ci.com/ ,绑定github,选择监听仓库.
- 项目里面有可运行的代码,项目还包含构建或测试脚本
.travis.yml- 在项目根目录下新建 .travis.yml 文件。参考官方文档编写 https://docs.travis-ci.com/user/languages/cpp/
- 运行流程
- install 阶段:安装依赖
- script 阶段:运行脚本
- 可选部分
before_install:install 阶段之前执行
before_script:script 阶段之前执行
after_failure:script 阶段失败时执行
after_success:script 阶段成功时执行
before_deploy:deploy 步骤之前执行
after_deploy:deploy 步骤之后执行
after_script:script 阶段之后执行
- 运行状态
passed:运行成功,所有步骤的退出码都是0
canceled:用户取消执行
errored:before_install、install、before_script有非零退出码,运行会立即停止
failed :script有非零状态码 ,会继续运行
- 可选加密环境变量
Angular规范
<type>(<scope>): <subject>
| name |
description |
实例 |
| feat: |
新功能(feature)。 |
打印函数 feat: Add print function for enhanced runtime information |
| fix/to: |
修复bug,可以是QA发现的BUG,也可以是研发自己发现的BUG。 |
|
| fix: |
产生diff并自动修复此问题。适合于一次提交直接修复问题 |
|
| to: |
只产生diff不自动修复此问题。适合于多次提交。最终修复问题提交时使用fix |
|
| docs: |
文档(documentation)。 |
|
| style: |
格式(不影响代码运行的变动)。 |
|
| refactor: |
重构(即不是新增功能,也不是修改bug的代码变动)。 |
|
| perf: |
优化相关,比如提升性能、体验。 |
|
| test: |
增加测试。 |
|
| chore: |
构建过程或辅助工具的变动。 |
|
| revert: |
回滚到上一个版本。 |
|
| merge: |
代码合并。 |
|
| sync: |
同步主线或分支的Bug。 |
|
格式为:
<type>(<scope>): <subject>
<BLANK LINE>
<body>
<BLANK LINE>
<footer>
- 对于Revert:
If the commit reverts a previous commit, it should begin with
revert:, followed by the header of the reverted commit. In the body it should say: This reverts commit <hash>., where the hash is the SHA of the commit being reverted.
-
type的类型有:
-
feat: A new feature
- fix: A bug fix
- docs: Documentation only changes
- style: Changes that do not affect the meaning of the code (white-space, formatting, missing semi-colons, etc)空白、格式、缺少分号等
- refactor:(重构) A code change that neither fixes a bug nor adds a feature
- perf: A code change that improves performance
- test: Adding missing or correcting existing tests
-
chore: (琐事)Changes to the build process or auxiliary tools(辅助工具) and libraries such as documentation generation
-
scope:
commit 改变的位置,如果是多处写*
- subject:
简明的描述:
- 使用祈使句,现在时态
- 不要
.结尾
- 第一个字母不要大写
- body:
包括改变的动机,并将其与以前的行为进行对比。
- footer:
Breaking Changes或者reference GitHub issues that this commit closes.
Breaking Changes should start with the word
BREAKING CHANGE: with a space or two newlines. The rest of the commit message is then used for this.
插件 vscode插件git-commit-plugin
命令行 husky + commitlint
- Standard Version
- 实现自动化版本控制,自动创建changelog, 创建 git tags
- 安装
npm cache clean --force #npm指令清除npm缓存
# 删除node_module包
npm install -g npm # npm 更新到最新
npm install -g n
n latest # node 更新
Note: the node command changed location and the old location may be remembered in your current shell.
old : /usr/bin/node
new : /usr/local/bin/node
To reset the command location hash either start a new shell, or execute PATH=$PATH"
PATH=/usr/local/bin/:$PATH
npm install -D standard-version
- 编写package.json
"scripts": {
"release": "standard-version"
}
-
CHANGELOG.md 记录内容的配置
- 创建.versionrc
{
"types": [
{"type": "chore", "section":"Others", "hidden": false},
{"type": "revert", "section":"Reverts", "hidden": false},
{"type": "feat", "section": "Features", "hidden": false},
{"type": "fix", "section": "Bug Fixes", "hidden": false},
{"type": "improvement", "section": "Feature Improvements", "hidden": false},
{"type": "docs", "section":"Docs", "hidden": false},
{"type": "style", "section":"Styling", "hidden": false},
{"type": "refactor", "section":"Code Refactoring", "hidden": false},
{"type": "perf", "section":"Performance Improvements", "hidden": false},
{"type": "test", "section":"Tests", "hidden": false},
{"type": "build", "section":"Build System", "hidden": false},
{"type": "ci", "section":"CI", "hidden":false}
]
}
-
使用Standard Version
// 初次发布版本
npm run release --first-release
npm run release #(自动更新版本号,自动更新 CHANGELOG.md, 自动创建 git tag)
git push --follow-tags origin master

- Commitizen for contributors
- Linux下commit规范辅助,用来选择(没vscode的时候用)
- 用 git-cz 来提交文件
- https://www.jianshu.com/p/acfdd4ca0104
- Visual Studio Code Commitizen Support
vscode的插件
- conventional-changelog/commitlint
阻止不规范的提交
github-release-notes,以下简称 gren ,是用来一键向 github 发布 release notes 的工具。
https://zhuanlan.zhihu.com/p/99499246
https://blog.csdn.net/weixin_39586683/article/details/110643111
版本格式:主版本号.次版本号.修订号,版本号递增规则如下:
主版本号:当你做了不兼容的 API 修改,
次版本号:当你做了向下兼容的功能性新增,
修订号:当你做了向下兼容的问题修正。
先行版本号及版本编译信息可以加到“主版本号.次版本号.修订号”的后面,作为延伸。
- github Actions / travis-ci
- 自动化测试
- Commitizen / Visual Studio Code Commitizen Support
- 规范commit message
- standard-version
- 更新 package 版本并打 tag
- github-release-notes
- 生成 release-log
写个github模板
- 明确文件结构
- src/include/build/Doc/Debug/test/example
- 清晰的README
- Intro/Install&Run/Features/Bugs/Acknowledge
- 图片和标签
- https://shields.io/category/build
- Release的自动发布
- 规范commit
- 其他自动化的轮子持续整合 (Continuous Integration, CI)
- travis ci
- github action
- ctest 怎么写?
- cmake.yml
- .github/workflow
- https://github.com/iBug/AWS-Lambda-webhook-py/tree/master/.github/workflows
- https://github.com/Kirrito-k423/github-stats
- 文档生成
- doxygen
- Doxygen主要解决说明书问题,可以在我们写代码的时候讲注释转化为说明书,Graphviz主要是用于图形展示
- 有项目,文件,函数三部分的书写要求 https://www.cnblogs.com/silencehuan/p/11169084.html
- Codecov
- 代码覆盖率,执行部分占比。因为未执行部分可能是错的
- projects/ bug fixs
- 设置为 template repository
- 查看 https://app.travis-ci.com/github/Kirrito-k423/githubTemplate
set(Boost_USE_STATIC_LIBS ON)
set(Boost_DEBUG ON)
Boost_INCLUDE_DIR: 含有boost头文件的目录
Boost_LIBRARYDIR: 偏好的含有boost库的库目录
https://stackoverflow.com/questions/3897839/how-to-link-c-program-with-boost-using-cmake
http://c.biancheng.net/view/7772.html cache?
cmake boost install path
https://cloud.tencent.com/developer/ask/107360
设置boost-root 查看安装位置
Travis-CI 依赖软件包每次都要重新安装吗
https://stackoverflow.com/questions/57982945/how-to-apt-get-install-in-a-github-actions-workflow
Actions may have no Boost, where
Ctest add build/bin to test
Ctest https://www.cnblogs.com/hustcpp/p/12922998.html
https://blog.csdn.net/zcteo/article/details/117527823?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EOPENSEARCH%7Edefault-15.no_search_link&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EOPENSEARCH%7Edefault-15.no_search_link
暂无
还是ipcc的github组织的太烂了,需要学习一下
https://zhuanlan.zhihu.com/p/67620599
http://www.ruanyifeng.com/blog/2017/12/travis_ci_tutorial.html
https://github.com/levy9527/blog/issues/1

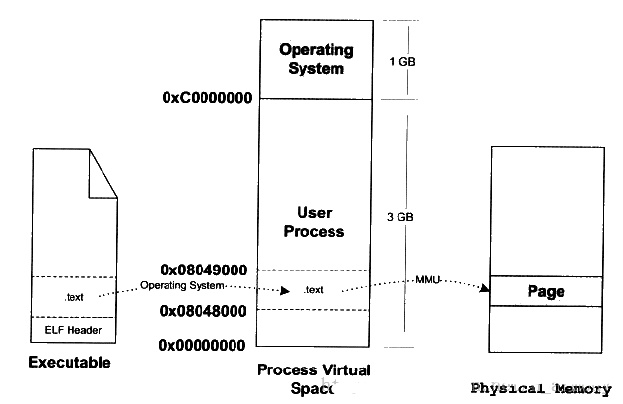
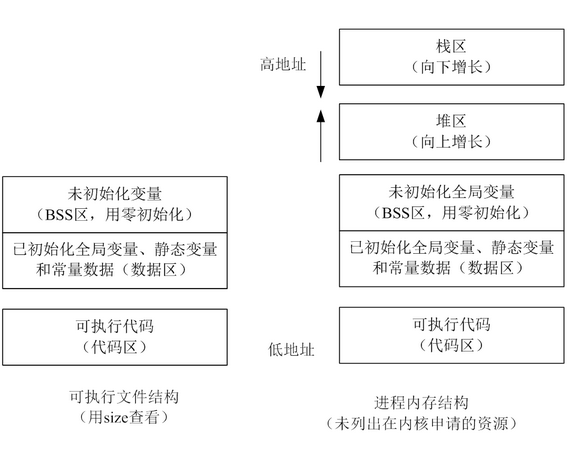
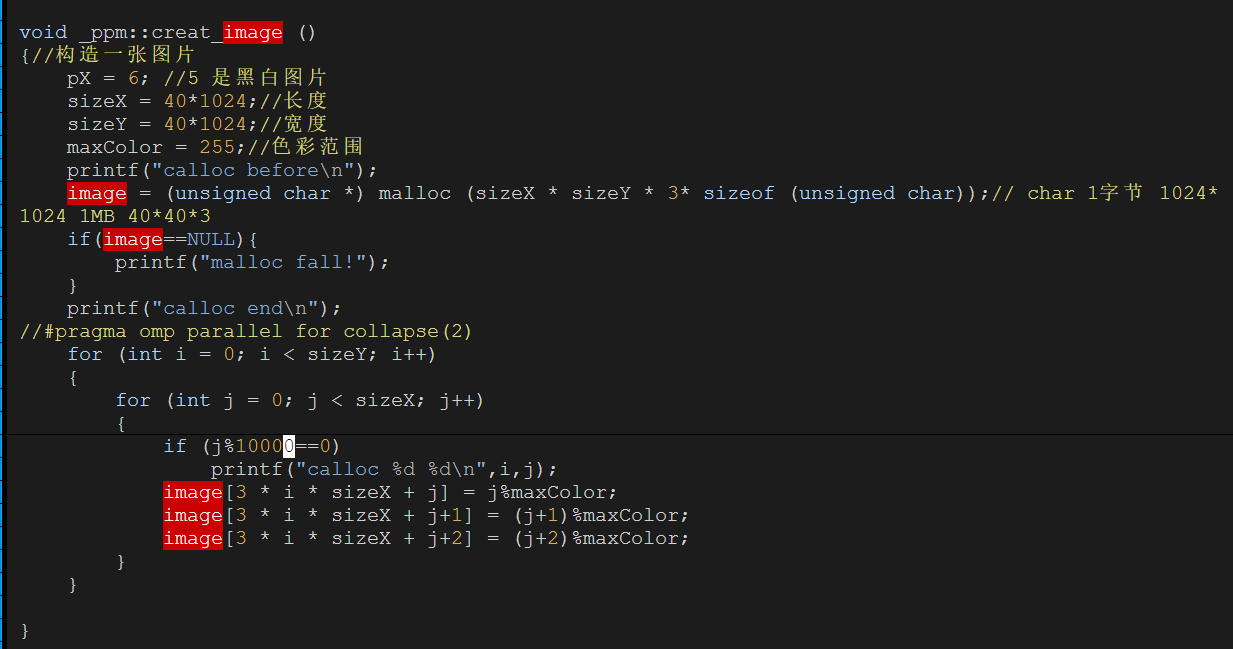
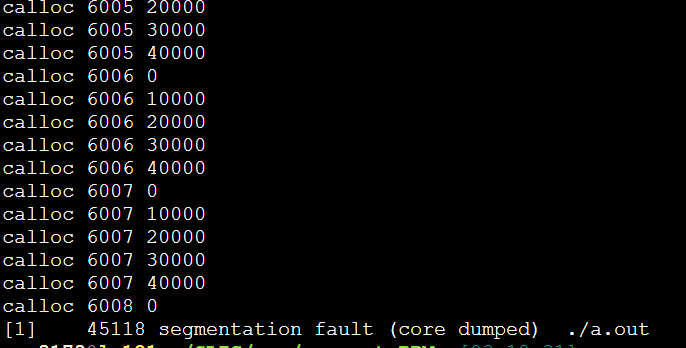 每次都是6008这里,40000*6008*3/1024/1024=687MB
每次都是6008这里,40000*6008*3/1024/1024=687MB
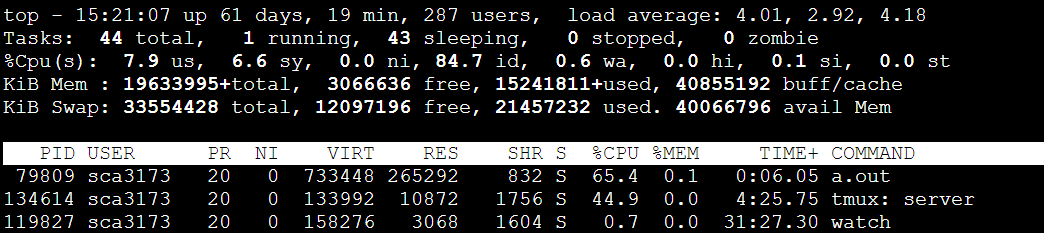 733448/1024=716MB
733448/1024=716MB
 问了大师兄,问题竟然是malloc的传入参数错误的类型是int,导致存不下3*40*1024*40*1024。应该用size_t类型。(size_t是跨平台的非负整数安全类型)
问了大师兄,问题竟然是malloc的传入参数错误的类型是int,导致存不下3*40*1024*40*1024。应该用size_t类型。(size_t是跨平台的非负整数安全类型)