Algorithm: leetcode
导言
计算机笔试,以及华为可信科目一相关的常见算法。
导言
计算机笔试,以及华为可信科目一相关的常见算法。
导言
在进程/线程并发执行的过程中,进程/线程之间存在协作的关系,例如有互斥、同步的关系。
为了实现进程/线程间正确的协作,操作系统必须提供实现进程协作的措施和方法,主要的方法:
这两个都可以方便地实现进程/线程互斥,而信号量比锁的功能更强一些,它还可以方便地实现进程/线程同步。
共享内存加锁之后释放锁,别的进程是如何知道锁释放的
如何保证操作的原子性
如何避免死锁
Test-and-Set 和 Compare-and-Swap (CAS) 都是并发编程中的重要原子操作指令,通常用于同步和处理多线程或多进程环境中的竞争条件。它们的作用是确保某些操作在执行时不会被中断,以保持数据一致性和避免并发冲突。我们来详细了解这两个命令。
它的操作过程如下:
操作是原子的,即不会被中断或干扰,保证在并发环境下,多个线程或进程不能同时修改同一位置。
用途:
假设有一个共享的锁标志 lock,初始化为 false:
它的操作步骤如下:
CAS 也具有原子性,这意味着它在操作期间不会被中断。CAS 是实现无锁编程和避免线程同步问题的常用工具,尤其在需要高性能的并发程序中。
用途:
假设有一个变量 x,初始值为 10:
Test-and-Set 指令,XCHG 被用作实现类似功能的原子操作。; x86 示例,使用 XCHG 实现 Test-and-Set
; 假设锁变量位于 memory_location
; eax 是存储旧值的寄存器
mov eax, 0 ; eax 设为 0,表示“未锁定”
xchg eax, [lock] ; 将 eax 与锁变量交换,如果锁变量是 0,就设置为 1
; 如果返回的 eax 仍为 0,说明锁成功设置
这个操作会交换 eax 和 [lock] 位置的值,并将原值存储在 eax 中。如果 [lock] 最初是 0,eax 将变为 1,并且 lock 会被设置为 1,表示锁已经被占用。
虽然 Test-and-Set 并不一定直接映射到汇编中的特定指令,但它可以通过交换指令来模拟。
CMPXCHG 指令,ARM 等其他架构也有类似的原子操作指令(如 LDREX 和 STREX)。x86 提供了 CMPXCHG(比较和交换)指令,它就是 CAS 操作的硬件实现。其语法如下:
destination:是要比较的内存位置。source:是用于替换的值。destination 中的值与 source 中的值相等,destination 将被更新为 source 的值,且 AX 寄存器的值将保存 destination 原先的值。destination 的值保持不变,并且 AX 寄存器将保存 destination 的原值。; x86 示例,使用 CMPXCHG 实现 Compare-and-Swap
; 假设目标内存位置是 lock,期望值是 eax,新的值是 ebx
mov eax, expected_value ; 将期望的值加载到 eax
mov ebx, new_value ; 将新的值加载到 ebx
cmpxchg [lock], ebx ; 比较 [lock] 的值与 eax(期望值),如果相等则将 [lock] 更新为 ebx(新值)
; 如果不相等,eax 会保存 [lock] 的原值
这个 CMPXCHG 指令会首先将内存中的值与 eax 比较,如果两者相等,它会将 ebx 的值存储到内存中,并且 eax 会保存原来的值;如果两者不相等,内存中的值不会改变,而 eax 会保存当前内存值,指示操作失败。
ARM 也提供了类似的原子操作指令,称为 LDREX 和 STREX。LDREX 加载一个值并锁定它,STREX 则用于条件性地写回值。
std::atomic 是对 Test-and-Set 和 Compare-and-Swap 等底层原子操作的高级封装,使得 C++ 开发者可以在多线程环境中更方便、更安全地使用这些原子操作。
原子操作(std::atomic)有如下特点:
std::atomic 只能用于一些简单的类型(如整数、指针和布尔类型),对于复杂的数据结构,仍然需要其他同步机制(如锁)。示例:使用 std::atomic<bool> 控制初始化
在控制初始化只执行一次的场景中,你可以使用 std::atomic<bool> 来替代普通的 bool 类型,这样就能确保线程安全地检查和设置初始化标志。
#include <atomic>
std::atomic<bool> isInited(false);
void initFunction() {
// 原子操作,检查并更新 isInited
if (!isInited.exchange(true)) { // mutex std::call_once 和std::once_flag 也可以实现类似功能。
// 执行初始化逻辑
// ...
}
}
std::atomic<bool> isInited(false);:声明一个原子类型的 bool 变量,初始值为 false。isInited.exchange(true):调用 exchange 方法,该方法会将 isInited 的当前值返回,并将其更新为 true。如果当前值为 false,说明还没有初始化,此时会执行初始化逻辑。isInited 已经是 true,则 exchange 会返回 true,跳过初始化部分。避免直接读取 std::atomic 对象, 使用load store
原子操作是不会失败的
std::memory_order对于一个线程里的同一个代码块内的无依赖关系的指令,处理器在运行时会重排序乱序执行。这对原子指令也是一样的。但实际生产中,多个原子操作之间,可能会有依赖关系,比如一个线程读取另一个线程写入的数据。为了确保这些依赖关系的正确性,需要使用内存顺序来控制处理器对指令的重排序。
std::atomic 的操作支持指定内存顺序,这控制了编译器和硬件对操作的优化和重排序。常见的内存顺序选项有:
std::memory_order_relaxed:没有限制,运行时会乱序。std::memory_order_acquire 和 std::memory_order_release:分别用于“获取”和“释放”同步,确保操作顺序。std::memory_order_seq_cst:默认的内存顺序,保证在多线程程序中,所有原子操作按顺序执行,不允许重排序。但性能可能会略受影响。这两者提供了获取和释放同步的保证:
std::memory_order_acquire:保证在此操作之前的所有操作不会被重排序到它之后。std::memory_order_release:保证在此操作之后的所有操作不会被重排序到它之前。#include <atomic>
#include <iostream>
#include <thread>
std::atomic<int> counter(0);
std::atomic<bool> ready(false);
void producer() {
counter.store(42, std::memory_order_release); // 确保 counter 写入在 ready 之前
ready.store(true, std::memory_order_release); // 标记准备好
}
void consumer() {
while (!ready.load(std::memory_order_acquire)) {} // 等待 ready 为 true
std::cout << "Counter: " << counter.load(std::memory_order_acquire) << std::endl;
}
int main() {
std::thread t1(producer);
std::thread t2(consumer);
t1.join();
t2.join();
return 0;
}
解释:
consumer 线程在 ready.load(std::memory_order_acquire) 后才能读取 counter,确保 ready 被设置为 true 后,counter 的写入才是可见的。memory_order_release 确保 producer 线程的 counter 写操作不会被重排序到 ready.store 之前。memory_order_acquire 确保 consumer 在读取 ready 后,才能正确地读取到 counter 的值。store在原子操作中,store 用来将一个值存储到原子变量中。与普通赋值不同,store 会确保在多线程环境下,赋值操作是原子性的(即不会被打断)。
store 会保证在指定的内存顺序下将值存储到原子变量中,因此它是线程安全的。
loadload 用于从原子变量中读取值。它会确保在多线程环境中,读取操作是线程安全的,并且可以指定内存顺序。
load 会确保读取的是正确同步后的值,避免在多线程场景下出现读取错误。compare_exchange_strongcompare_exchange_strong(以及 compare_exchange_weak)广泛应用于实现锁和无锁算法。它会尝试将原子变量的值与一个预期值进行比较,如果相同,则将其更新为新值。如果比较失败,原子变量的值不会更改,并且返回 false。std::atomic<int> value(0);
int expected = 0;
int desired = 42;
if (value.compare_exchange_strong(expected, desired)) {
std::cout << "CAS succeeded! Value updated to " << value.load() << "\n";
} else {
std::cout << "CAS failed! Expected: " << expected << ", Actual: " << value.load() << "\n";
}
// 尝试比较并交换
while (!value.compare_exchange_weak(expected, desired)) {
std::cout << "CAS failed, retrying...\n";
// 可以执行一些其他的操作或稍微延迟再重试
}
std::cout << "CAS succeeded! Value updated to " << value.load() << "\n";
exchangeexchange 是一种常见的原子操作,类似于 store,但它会返回原子变量的先前值。
exchange 在多线程环境下是安全的,并且可以返回修改前的值,适用于某些需要获取旧值的场景。多线程同步的一种忙等待锁,线程反复检查锁变量是否可用。
std::atomic_flag lock = ATOMIC_FLAG_INIT;
void spinlock() {
while (lock.test_and_set(std::memory_order_acquire)) {
// 自旋等待,直到锁被释放
}
// 临界区代码
lock.clear(std::memory_order_release); // 解锁
}
把自己阻塞起来(内核态和用户态之间的切换进入阻塞状态,可能上下文切换),等待重新调度请求。
std::lock_guard<std::mutex> 是 C++ 标准库中的一个 RAII(Resource Acquisition Is Initialization)类,它用于在作用域内自动锁住一个 std::mutex,并在作用域结束时自动解锁。它可以帮助你避免手动管理锁,减少死锁和忘记解锁的风险。
用法
std::lock_guard 通过构造时自动锁住互斥量,并且在作用域结束时自动释放互斥量的锁。因此,你不需要手动调用 mutex.unlock()。只需要确保 lock_guard 的生命周期结束时,互斥量会被自动解锁。
示例代码
#include <iostream>
#include <mutex>
#include <thread>
std::mutex init_mutex_; // 互斥量,防止多个线程同时初始化
void some_function() {
// 创建一个 lock_guard 对象,自动锁住 init_mutex_
std::lock_guard<std::mutex> lock(init_mutex_);
// 在此作用域内,init_mutex_ 被锁定
std::cout << "Doing some work inside the critical section...\n";
// lock_guard 在作用域结束时会自动解锁 mutex
}
int main() {
std::thread t1(some_function);
std::thread t2(some_function);
t1.join();
t2.join();
return 0;
}
解释
std::lock_guard<std::mutex> lock(init_mutex_);:lock_guard 对象被创建,并立即锁住 init_mutex_。std::lock_guard 的构造函数会调用 mutex.lock() 来锁定互斥量。lock 变量在作用域结束时自动销毁,这会触发析构函数 lock_guard::~lock_guard(),并自动解锁互斥量(即调用 mutex.unlock())。
在 some_function 中,互斥量在整个函数内都是被锁定的,因此其他线程无法进入这段代码,避免了并发冲突。
为什么使用 std::lock_guard?
std::lock_guard 会自动解锁互斥量,减少了忘记解锁的风险。std::lock_guard 可以确保每次只有一个线程能够访问临界区,防止数据竞争。适用场景
通常用于在函数、代码块中保护共享资源。它适合需要访问互斥量的代码块,但不想手动管理锁和解锁时。
如果你希望在销毁环境的 Final 函数中等待某些子线程完成,可以使用 std::mutex 和 std::condition_variable 来同步子线程的完成状态。
示例代码: 假设你有一个主线程(执行 Final 函数)和一个子线程,主线程需要等待子线程完成后才能销毁环境。
#include <iostream>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <atomic>
std::mutex mtx;
std::condition_variable cv;
std::atomic<bool> thread_done{false};
void worker_thread() {
std::this_thread::sleep_for(std::chrono::seconds(2)); // 模拟工作
std::cout << "Worker thread finished." << std::endl;
thread_done = true; // 设置线程完成标志
cv.notify_one(); // 通知主线程
}
void Final() {
std::cout << "Final: Waiting for worker thread to finish..." << std::endl;
// 等待子线程完成
std::unique_lock<std::mutex> lock(mtx);
cv.wait(lock, [] { return thread_done.load(); });
// cv.wait(lock, [this] { return thread_done.load(); }); // in class
std::cout << "Final: Worker thread finished. Proceeding with cleanup." << std::endl;
}
int main() {
// 启动子线程
std::thread t(worker_thread);
// 在主线程中调用 Final
Final();
t.join(); // 等待子线程结束
return 0;
}
关键点:
std::mutex mtx: 用于锁住条件变量,确保线程间的同步。std::condition_variable cv: 用于实现主线程等待子线程的完成。std::atomic<bool> thread_done: 用于标记子线程是否完成。cv.wait(lock, condition): 主线程会等待子线程设置 thread_done 为 true,然后才会继续执行。适用于大段的修改和同步。
eventfd 事件通知eventfd 是 Linux 提供的一种用于线程安全的事件通知机制,类似于文件描述符,可以通过读写操作来实现跨线程或跨进程的同步。通过 eventfd,线程或进程可以通过某些事件(例如计数器增减、通知等)来触发其他线程或进程的动作。
eventfd 可以通过两种方式工作:
eventfd_write 增加计数器,其他线程或进程可以通过 eventfd_read 来读取这些计数器的值。eventfd 进行事件通知,线程或进程通过 eventfd_read 来等待并响应这些事件。eventfd_read 的功能 : eventfd_read 是一个用于从 eventfd 文件描述符读取事件的系统调用。它会从 eventfd 中读取一个 64 位无符号整数,并返回这个值。这个值通常表示某个事件的状态或计数器的值。
线程间同步
如果两个线程同时对同一个 eventfd 文件描述符进行读写操作:
函数原型
#include <sys/eventfd.h>
ssize_t eventfd_read(int efd, uint64_t *value);
ssize_t eventfd_write(int efd, uint64_t value);
efd:eventfd 文件描述符。* value:指向一个 uint64_t 类型的变量,用于存储从 eventfd 读取的值。value:要写入 eventfd 的值,通常是一个 64 位无符号整数 (uint64_t),表示事件计数器的增加量或特定事件的通知值。返回值
eventfd_read 返回读取到的字节数,通常为 8(因为它读取一个 64 位的值)。-1,并将 errno 设置为合适的错误码。错误码
EAGAIN:eventfd 中没有事件可读(即没有数据)。EBADF:无效的文件描述符。代码示例
假设你使用 eventfd 来同步不同的线程:
#include <sys/eventfd.h>
#include <unistd.h>
#include <iostream>
#include <cstring>
int main() {
// 创建 eventfd 文件描述符
int efd = eventfd(0, EFD_NONBLOCK);
if (efd == -1) {
std::cerr << "Failed to create eventfd: " << strerror(errno) << std::endl;
return -1;
}
// 写入事件
uint64_t u = 1; // 写入一个事件值
ssize_t s = write(efd, &u, sizeof(u));
if (s == -1) {
std::cerr << "Failed to write to eventfd: " << strerror(errno) << std::endl;
close(efd);
return -1;
}
// 读取事件
uint64_t read_value;
s = eventfd_read(efd, &read_value);
if (s == -1) {
std::cerr << "Failed to read from eventfd: " << strerror(errno) << std::endl;
} else {
std::cout << "Read value: " << read_value << std::endl;
}
close(efd);
return 0;
}
如CSDN,有一条依赖线,需要一个信号量
在使用信号量(Semaphore)进行线程同步时,P(proberen)和V(verhogen)操作是非常重要的概念。
P操作(也称为Wait操作或Down操作):
表示获取或等待信号量。
伪代码表示为:
V操作(也称为Signal操作或Up操作):
表示释放或增加信号量。
伪代码表示为:
P和V操作保证了对共享资源的互斥访问。
一个线程使用P操作等待获取信号量,V操作在使用完共享资源后释放信号量。
信号量的值通常用于控制共享资源的数量,它可以是非负整数。当信号量被初始化为1时,称为二进制信号量(Binary Semaphore),因为它只能取0或1的值,通常用于实现互斥访问临界区。如果信号量的值大于1,称为计数信号量,可用于限制对资源的并发访问数。
在实际编程中,P操作和V操作通常是原子操作,确保在多线程或多进程环境下的正确同步和竞争条件的安全处理。
https://www.cswiki.top/pages/f398f1/#blocking-i-o
原文链接:https://blog.csdn.net/qq_15437629/article/details/79116590
LLVM Machine Code Analyzer 是一种性能分析工具,它使用llvm中可用的信息(如调度模型)静态测量特定CPU中机器代码的性能。
性能是根据吞吐量和处理器资源消耗来衡量的。该工具目前适用于在后端中使用LLVM调度模型的处理器。
该工具的主要目标不仅是预测代码在目标上运行时的性能,还帮助诊断潜在的性能问题。
给定汇编代码,llvm-mca可以估计每个周期的指令数(IPC)以及硬件资源压力。分析和报告风格的灵感来自英特尔的IACA工具。
https://github.com/llvm/llvm-project/tree/main/llvm/tools/llvm-mca
https://llvm.org/docs/CommandGuide/llvm-mca.html
-mtriple=<target triple>
eg. -mtriple=x86_64-unknown-unknown
-march=<arch>
Specify the architecture for which to analyze the code. It defaults to the host default target.
-march=<arch>
Specify the architecture for which to analyze the code. It defaults to the host default target.
-output-asm-variant=<variant id>
为工具生成的报告指定输出程序集变量。???
-print-imm-hex
优先16进制输出。
-json
除了瓶颈分析,基本都支持json格式输出视图
-timeline
打印指令流水线情况
-dispatch=<width>
为处理器指定不同的调度宽度。调度宽度默认为处理器调度模型中的“IssueWidth”字段。
-register-file-size=<size>
指定寄存器文件的大小。指定时,该项会限制可用于寄存器重命名的物理寄存器的数量。此标志的值为零意味着“无限数量的物理寄存器”。
-iterations=<number of iterations>
指定要运行的迭代次数。如果此标志设置为 0,则该工具会将迭代次数设置为默认值(即 100)。
-noalias=<bool>
loads and stores don’t alias
-lqueue=<load queue size>
-squeue=<store queue size>
在工具模拟的加载/存储单元中指定加载队列的大小。默认情况下,该工具假定加载队列中的条目数量不受限制。此标志的零值将被忽略,而是使用默认加载队列大小。
-disable-cb
强制使用通用的 CustomBehaviour 和 InstrPostProcess 类,而不是使用目标特定的实现。通用类从不检测任何自定义危险或对指令进行任何后处理修改。
-resource-pressure
Enable the resource pressure view. This is enabled by default.
-register-file-stats
启用注册文件使用统计。
-dispatch-stats
-scheduler-stats
-retire-stats
-instruction-info
启用额外的调度/发出/retire control unit统计。该视图收集和分析指令分派事件,以及静态/动态分派停顿事件。默认情况下禁用此视图。
-show-encoding
打印指令16进制
-all-stats
-all-views
-instruction-tables
这与资源压力视图不同,因为它不需要模拟代码。相反,它按顺序打印每个指令的资源压力的理论均匀分布。
-bottleneck-analysis
打印有关影响吞吐量的瓶颈的信息。这种分析可能很昂贵,并且默认情况下是禁用的。瓶颈在摘要视图中突出显示。具有有序后端的处理器目前不支持瓶颈分析。???
Iterations: 300
Instructions: 900
Total Cycles: 610
Total uOps: 900
Dispatch Width: 2
uOps Per Cycle: 1.48
IPC: 1.48
Block RThroughput: 2.0
Instruction Info:
[1]: #uOps
[2]: Latency
[3]: RThroughput
[4]: MayLoad
[5]: MayStore
[6]: HasSideEffects (U)
[1] [2] [3] [4] [5] [6] Instructions:
1 2 1.00 vmulps %xmm0, %xmm1, %xmm2
1 3 1.00 vhaddps %xmm2, %xmm2, %xmm3
1 3 1.00 vhaddps %xmm3, %xmm3, %xmm4
```
显示了指令里队列每条指令的**延迟**和**吞吐量的倒数**。
RThroughput是指令吞吐量的倒数。在不考虑循环依赖的情况下,吞吐量是**单周期能执行的同类型指令的最大数量**。
### Resource pressure view
Resource pressure per iteration: [0] [1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] - - - 2.00 1.00 2.00 1.00 - - - - - - -
Resource pressure by instruction: [0] [1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] Instructions: - - - - 1.00 - 1.00 - - - - - - - vmulps %xmm0, %xmm1, %xmm2 - - - 1.00 - 1.00 - - - - - - - - vhaddps %xmm2, %xmm2, %xmm3 - - - 1.00 - 1.00 - - - - - - - - vhaddps %xmm3, %xmm3, %xmm4 ```
每次循环或者每条指令执行,消耗的资源周期数。从而找到高资源占用的部分。
可打印流水线情况
Timeline view:
012345
Index 0123456789
[0,0] DeeER. . . vmulps %xmm0, %xmm1, %xmm2
[0,1] D==eeeER . . vhaddps %xmm2, %xmm2, %xmm3
[0,2] .D====eeeER . vhaddps %xmm3, %xmm3, %xmm4
[1,0] .DeeE-----R . vmulps %xmm0, %xmm1, %xmm2
[1,1] . D=eeeE---R . vhaddps %xmm2, %xmm2, %xmm3
[1,2] . D====eeeER . vhaddps %xmm3, %xmm3, %xmm4
[2,0] . DeeE-----R . vmulps %xmm0, %xmm1, %xmm2
[2,1] . D====eeeER . vhaddps %xmm2, %xmm2, %xmm3
[2,2] . D======eeeER vhaddps %xmm3, %xmm3, %xmm4
Average Wait times (based on the timeline view):
[0]: Executions
[1]: Average time spent waiting in a scheduler's queue
[2]: Average time spent waiting in a scheduler's queue while ready
[3]: Average time elapsed from WB until retire stage
[0] [1] [2] [3]
0. 3 1.0 1.0 3.3 vmulps %xmm0, %xmm1, %xmm2
1. 3 3.3 0.7 1.0 vhaddps %xmm2, %xmm2, %xmm3
2. 3 5.7 0.0 0.0 vhaddps %xmm3, %xmm3, %xmm4
3 3.3 0.5 1.4 <total>
影响因素包括:
Cycles with backend pressure increase [ 91.52% ]
Throughput Bottlenecks:
Resource Pressure [ 0.01% ]
- SBPort0 [ 0.01% ]
- SBPort1 [ 0.01% ]
- SBPort5 [ 0.01% ]
Data Dependencies: [ 91.51% ]
- Register Dependencies [ 91.51% ]
- Memory Dependencies [ 10.76% ]
llvm/lib/Target/X86/X86SchedSandyBridge.tdllvm/lib/Target/AArch64/AArch64SchedTSV110.tdAMD Jaguar
JALU01 - A scheduler for ALU instructions.
JFPU01 - A scheduler floating point operations.
JLSAGU - A scheduler for address generation.
Retire Control Unit
llvm-mca 假设指令在模拟开始之前已经全部解码并放入队列中。因此,指令提取和解码阶段没有被计算。未考虑前端的性能瓶颈。此外,llvm-mca 不模拟分支预测。
处理器的默认 dispatch width值等于LLVM’s scheduling model里的IssueWidth值。
An instruction can be dispatched if:
reorder buffer负责跟踪命令,使之按照程序顺序retired结束。其默认值为 MicroOpBufferSize 。
各种Buffered resources 被视作scheduler resources.
每个处理器调度器实现一个指令缓冲区。指令必须在调度程序的缓冲区中等待,直到输入寄存器操作数可用。只有在那个时候,指令才符合执行的条件,并且可能会被发出(可能是乱序的)以供执行。 llvm-mca 在调度模型的帮助下计算指令延迟。
llvm-mca 的调度器旨在模拟多处理器调度器。调度器负责跟踪数据依赖关系,并动态选择指令消耗哪些处理器资源。它将处理器资源单元和资源组的管理委托给资源管理器。资源管理器负责选择指令消耗的资源单元。例如,如果一条指令消耗了一个资源组的1cy,则资源管理器从该组中选择一个可用单元;默认情况下,资源管理器使用循环选择器来保证资源使用在组的所有单元之间均匀分配。
llvm-mca’s scheduler internally groups instructions into three sets:
retire control unit
load/store unit (LSUnit)用来模拟乱序memory操作
The rules are:
假设 loads do not alias (-noalias=true) store operations.Under this assumption, younger loads are always allowed to pass older stores. ???
LSUnit不打算跑alias analysis来预测何时load与store不相互alias???
in the case of write-combining memory, rule 3 could be relaxed to allow reordering of non-aliasing store operations.???
LSUnit不管的其余三点:
llvm-mca 不知道序列化操作或内存屏障之类的指令。 LSUnit 保守地假设同时具有“MayLoad”和未建模副作用的指令的行为类似于“软”load-barrier。这意味着,它在不强制刷新load队列的情况下序列化加载。类似地,“MayStore”和具有未建模副作用的指令被视为store障碍。完整的memory-barrier是具有未建模副作用的“MayLoad”和“MayStore”指令。LLVM的实现是不准确的,但这是我们目前使用 LLVM 中可用的当前信息所能做的最好的事情。
load/store barrier会占用在load/store 队列里占用一项。 当load/store barrier是其队列里oldest项时,其会被执行

有序处理器被建模为单个 InOrderIssueStage 阶段。它绕过 Dispatch、Scheduler 和 Load/Store 单元。一旦它们的操作数寄存器可用并且满足资源要求,就会发出指令。根据LLVM的调度模型中IssueWidth参数的值,可以在一个周期内发出多条指令。一旦发出,指令就会被移到 IssuedInst 集,直到它准备好retire。 llvm-mca 确保按顺序提交写入。但是,如果 RetireOOO 属性for at least one of its writes为真,则允许指令提交写入并无序retire???
某些指令在该模型中并不能被准确的模拟。为了几条指令而修改模型不是个好的选择,一般通过CustomBehaviour类对某些指令进行特殊建模:自定义数据依赖,以及规避、单独处理特殊情况。
为此,llvm-mca设置了一个通用的以及多个特殊的CustomBehaviour类。下面两种情况下会使用通用类:
-disable-cb选项但是注意目前只有in-order流水线实现了CustomBehaviour类,out-order流水线将来也会支持。
该类主要通过checkCustomHazard()函数来实现,通过当前指令和真正流水线中执行的指令,来判断当前指令需要等待几个周期才能发射。
如果想对没有实现的目标添加CustomBehaviour类,可以参考已有的实现,比如在/llvm/lib/Target/AMDGPU/MCA/目录下。
关于自定义的视图的添加路径,如果没有输出从未在MC layer classes (MCSubtargetInfo, MCInstrInfo, etc.)里出现过的新后端值,请把实现加入/tools/llvm-mca/View/。相反,请加入/lib/Target/<TargetName>/MCA/目录。
关于Custom Views所需内容,需要写特殊的CustomBehaviour类来覆写CustomBehaviour::getViews()函数,根据位置的不同还有三种实现getStartViews(), getPostInstrInfoViews(),getEndViews()。
调度模型不仅用于计算指令延迟和吞吐量,还用于了解可用的处理器资源以及如何模拟它们。
llvm mca进行分析的质量不可避免地受到llvm中调度模型质量的影响。
一些额外Info? 1.
吞吐量瓶颈?
汇编代码,支持命名和嵌套
高级语言,通过内联汇编实现
int foo(int a, int b) {
__asm volatile("# LLVM-MCA-BEGIN foo");
a += 42;
__asm volatile("# LLVM-MCA-END");
a *= b;
return a;
}
但是,这会干扰循环矢量化等优化,并可能对生成的代码产生影响。具体影响请对比汇编代码。
Google学术搜llvm-mca,一堆论文。但是不急着看,因为没有预备知识,没有问题的去看论文。效率和收获很低的,而且会看不懂。
mc-ruler是整合了llvm-mca的cmake,可以打印指定部分的代码分析信息。如果之后要测试可能用得上。
如何和大神交流呢+提问的艺术
无
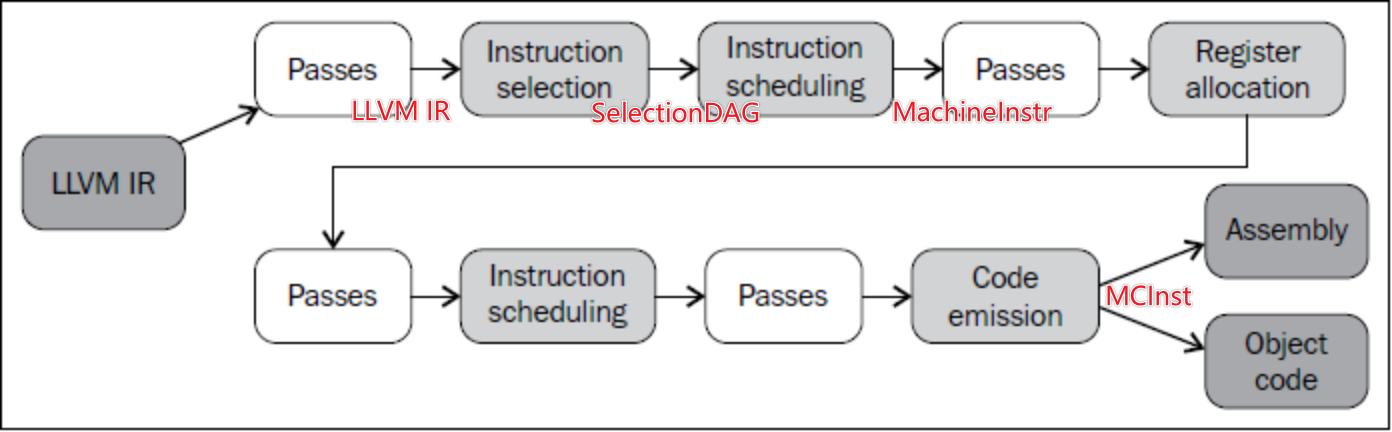
-O3的优化,而且其顺序对结果也有影响。详细解释各阶段:
后端的实现分散在LLVM源代码树的不同目录中。代码生成背后的主要程序库位于lib目录和它的子文件夹CodeGen、MC、TableGen、和Target中, 具体参考文档
Tablegen位置在类似 llvm/lib/Target/X86/X86.td的地方
程序优化选项 -O3 是通过启用 LLVM Pass Manager 并按照顺序执行包含多个具体优化 Pass 的过程实现的。包括:
这些 Pass 的执行范围涵盖 LLVM IR 与 LLVM 后端。
TableGen的输入文件使用扩展名“.td”(TableGen的缩写),它们可以描述如下内容:
Instruction Scheduling - 描述调度器行为、指令之间的时间关系,以及如何将指令插入到调度图中的规则等。
TableGen自动化了目标机指令集的大部分工作,同时也使得自定义目标机变得相对容易。
实现一个简单的LLVM IR后端,将LLVM IR转换为x86汇编代码,能line by line的输出。
参考LLVM官方文档中的“Writing an LLVM Backend”以及“TableGen Backends”
暂无
暂无
https://getting-started-with-llvm-core-libraries-zh-cn.readthedocs.io/zh_CN/latest/ch06.html#id2
导言
个人形象管理的第一部分,也是最简单的部分,外貌部分的穿搭。
Pass类是实现优化的主要资源。然而,我们从不直接使用它,而是通过清楚的子类使用它。当实现一个Pass时,你应该选择适合你的Pass的最佳粒度,适合此粒度的最佳子类,例如基于函数、模块、循环、强联通区域,等等。常见的这些子类如下:
ModulePass:这是最通用的Pass;它一次分析整个模块,函数的次序不确定。它不限定使用者的行为,允许删除函数和其它修改。为了使用它,你需要写一个类继承ModulePass,并重载runOnModule()方法。FunctionPass:这个子类允许一次处理一个函数,处理函数的次序不确定。这是应用最多的Pass类型。它禁止修改外部函数、删除函数、删除全局变量。为了使用它,需要写一个它的子类,重载runOnFunction()方法。BasicBlockPass:这个类的粒度是基本块。FunctionPass类禁止的修改在这里也是禁止的。它还禁止修改或者删除外部基本块。使用者需要写一个类继承BasicBlockPass,并重载它的runOnBasicBlock()方法。被重载的入口函数runOnModule()、runOnFunction()、runOnBasicBlock()返回布尔值false,如果被分析的单元(模块、函数和基本块)保持不变,否则返回布尔值true。
char PIMProf::AnnotationInjection::ID = 0;
// 注册 llvm pass
static RegisterPass<PIMProf::AnnotationInjection> RegisterMyPass(
"AnnotationInjection", "Inject annotators to uniquely identify each basic block.");
static void loadPass(const PassManagerBuilder &,
legacy::PassManagerBase &PM) {
PM.add(new PIMProf::AnnotationInjection());
}
// Ox 的代码 llvm pass 在EP_OptimizerLast 位置load
static RegisterStandardPasses clangtoolLoader_Ox(PassManagerBuilder::EP_OptimizerLast, loadPass);
// O0 的代码 llvm pass EP_EnabledOnOptLevel0 位置load
static RegisterStandardPasses clangtoolLoader_O0(PassManagerBuilder::EP_EnabledOnOptLevel0, loadPass);
最简单框架hello.cpp如下,注意Important一定需要:
#include "llvm/Pass.h"
#include "llvm/IR/Function.h"
#include "llvm/Support/raw_ostream.h"
#include "llvm/IR/LegacyPassManager.h"
#include "llvm/Transforms/IPO/PassManagerBuilder.h"
using namespace llvm;
namespace {
// Important
struct Hello : public FunctionPass {
static char ID;
Hello() : FunctionPass(ID) {}
// Important
bool runOnFunction(Function &F) override {
errs() << "Hello: ";
errs().write_escaped(F.getName()) << '\n';
return false;
}
};
}
char Hello::ID = 0;
// Important:Register for opt
static RegisterPass<Hello> X("hello", "Hello World Pass");
// Important:Register for clang
static RegisterStandardPasses Y(PassManagerBuilder::EP_EarlyAsPossible,
[](const PassManagerBuilder &Builder, legacy::PassManagerBase &PM) {
PM.add(new Hello());
});
参考官方文档。
An example of a project layout is provided below.
Contents of <project dir>/CMakeLists.txt:
find_package(LLVM REQUIRED CONFIG)
separate_arguments(LLVM_DEFINITIONS_LIST NATIVE_COMMAND ${LLVM_DEFINITIONS})
add_definitions(${LLVM_DEFINITIONS_LIST})
include_directories(${LLVM_INCLUDE_DIRS})
add_subdirectory(<pass name>)
Contents of <project dir>/<pass name>/CMakeLists.txt:
运行cmake编译。产生LLVMPassname.so文件
请阅读知乎的文章
clang -c -emit-llvm main.c -o main.bc # 随意写一个C代码并编译到bc格式
opt -load path/to/LLVMHello.so -hello main.bc -o /dev/null
把源代码编译成IR代码,然后用opt运行Pass实在麻烦且无趣。
clang -Xclang -load -Xclang path/to/LLVMHello.so main.c -o main
# or
clang++ -Xclang -load -Xclang ./build/hello/libLLVMPassname.so test.cpp -o main
void InjectSimMagic2(Module &M, Instruction *insertPt, uint64_t arg0, uint64_t arg1, uint64_t arg2)
{
LLVMContext &ctx = M.getContext();
std::vector<Type *> argtype {
Type::getInt64Ty(ctx), Type::getInt64Ty(ctx), Type::getInt64Ty(ctx)
};
FunctionType *ty = FunctionType::get(
Type::getVoidTy(ctx), argtype, false
);
// template of Sniper's SimMagic0
InlineAsm *ia = InlineAsm::get(
ty,
"\tmov $0, %rax \n"
"\tmov $1, %rbx \n"
"\tmov $2, %rcx \n"
"\txchg %bx, %bx\n",
"imr,imr,imr,~{rax},~{rbx},~{rcx},~{dirflag},~{fpsr},~{flags}",
true
);
Value *val0 = ConstantInt::get(IntegerType::get(ctx, 64), arg0);
Value *val1 = ConstantInt::get(IntegerType::get(ctx, 64), arg1);
Value *val2 = ConstantInt::get(IntegerType::get(ctx, 64), arg2);
std::vector<Value *> arglist {val0, val1, val2};
CallInst::Create(
ia, arglist, "", insertPt);
}
这段代码使用内联汇编嵌入到 LLVM IR 中,指令如下:
其中:
由于直接打印的是llvm IR的表示,想要打印特定架构比如x86的汇编代码,其实需要进行llvm后端的转换。(取巧,可执行文件反汇编,然后根据插入的汇编桩划分)
暂无
暂无
复现PIMProf论文时,用到了使用 llvm pass来插入特殊汇编
| 伪指令 | 描述 |
|---|---|
| .file | 指定由哪个源文件生成的汇编代码。 |
| .data | 表示数据段(section)的开始地址 |
| .text | 指定下面的指令属于代码段。 |
| .string | 表示数据段中的字符串常量。 |
| .globl main | 指明标签main是一个可以在其它模块的代码中被访问的全局符号 。 |
| .align | 数据对齐指令 |
| .section | 段标记 |
| .type | 设置一个符号的属性值 |
.type name , description%function 表示该符号用来表示一个函数名%object 表示该符号用来表示一个数据对象至于其它的指示你可以忽略。
从最简单的C文件入手
运行gcc -S -O3 main.c -o main.s,得到main.s文件
.file "simple.cpp"
.text
.section .text.startup,"ax",@progbits
.p2align 4
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
endbr64
xorl %eax, %eax
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0"
.section .note.GNU-stack,"",@progbits
.section .note.gnu.property,"a"
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:
.section .rodata.str1.1,"aMS",@progbits,1rodata.str1.1是一个标号(label), 意思是只读数据段的字符串常量aMS是一个属性值:@progbits: 表示该段的类型是程序数据段(PROGBITS),这种类型的段包含程序的代码和数据。1: 表示该段的对齐方式是2^1 = 2个字节(按字节对齐)。如果不写这个数字,默认对齐到当前机器的字长。.section .text.startup,"ax",@progbits 其中ax表示该段是可分配的(allocatable)和可执行的(executable)。.section .note.GNU-stack"指令用于告诉链接器是否允许在堆栈上执行代码。.section .note.gnu.property"指令用于指定一些属性,这里是一个GNU特性标记。.text.startup” section,其首地址为“.globl main”。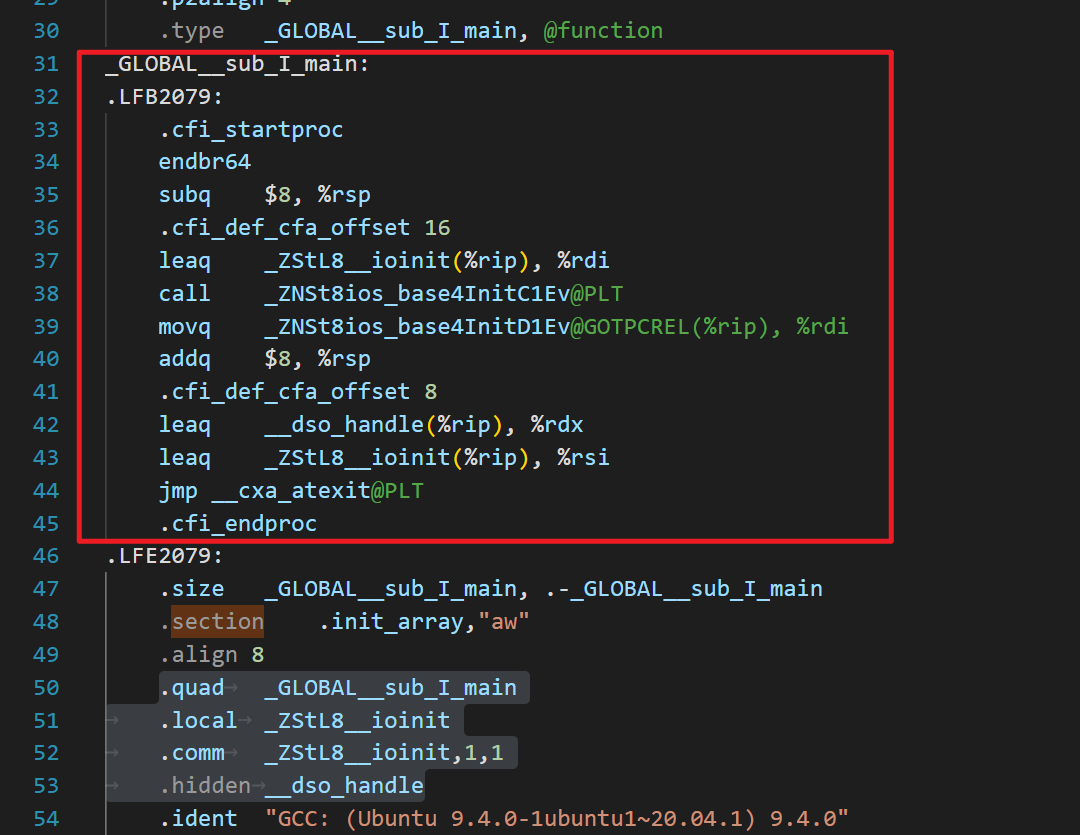
_GLOBAL__sub_I_xxx”的section中。ios_base::Init()",并注册了一个在程序退出时调用的析构函数 "__cxa_atexit"。.init_array" section中,定义了一个"_GLOBAL__sub_I_main"的地址,这是在程序启动时需要调用的所有C++全局和静态对象的初始化函数列表,编译器链接这个列表并在程序启动时依次调用这些初始化函数。其中四条指令都定义了一些符号或变量,并分配了一些内存空间,这些在程序里的意义如下:
.quad _GLOBAL__sub_I_main":在程序启动时,将调用所有全局静态对象的构造函数。这些构造函数被放在一个名为"_GLOBAL__sub_I_xxx"的section中,而每个section都是由一个指向该section所有对象的地址列表所引用。这里的".quad _GLOBAL__sub_I_main"是为了将"_GLOBAL__sub_I_main"函数的地址添加到该列表中。
.local _ZStL8__ioinit":这条指令定义了一个本地符号"_ZStL8__ioinit",它表示C++标准输入输出的初始化过程。由于该符号是一个本地符号,所以只能在编辑该文件的当前单元中使用该符号。
.comm _ZStL8__ioinit,1,1":这条指令定义了一个名为"_ZStL8__ioinit"的未初始化的弱符号,并为该符号分配了1个大小的字节空间。这个弱符号定义了一个C++标准输入输出部分的全局状态对象。在全用动态库时,不同的动态库可能有自己的IO状态,所以为了确保C++输入输出的状态正确,需要为其指定一个单独的段来存储这些状态数据。在这里,".comm _ZStL8__ioinit,1,1"将会为"_ZStL8__ioinit"符号分配一个字节大小的空间。
.hidden __dso_handle":这条指令定义了一个隐藏的符号 "__dso_handle"。这个符号是一个链接器生成的隐式变量,其定义了一个指向被当前动态库使用的全局数据对象的一个指针。该符号在被链接进来的库中是隐藏的,不会被其他库或者main函数本身调用,但是在main返回后,可以用来检查库是否已经被卸载。
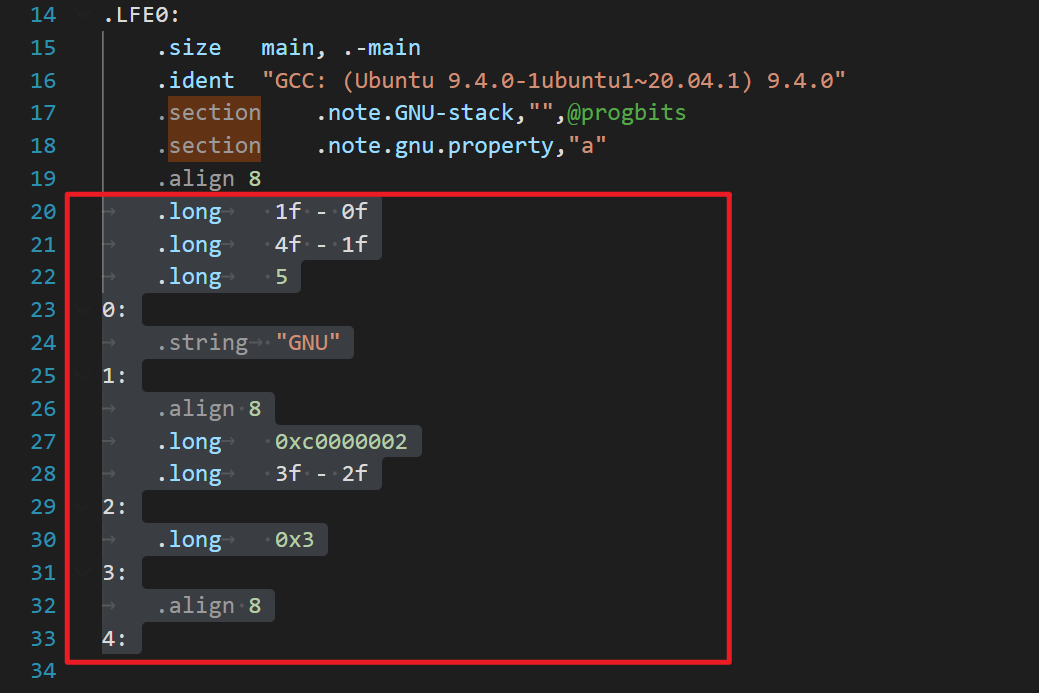
这段代码是一些特殊的指令和数据,主要是用于向可执行文件添加一些元数据(metadata)。这些元数据可能包含各种信息,如调试信息、特定平台的指令集支持等等。
具体来说:
.long 1f - 0f"建立了一个长整型数值,表示"1:"标签相对于当前指令地址(即0f)的偏移量。偏移量可以用来计算标签对应的指令地址,从而可用于跳转或计算指针偏移量。4f - 1f",即"4:"标签相对于"1:"标签的偏移量;.long 0xc0000002"表示这是一个特殊的属性标记,标识这个文件可以在Linux平台上执行。它是用来告诉操作系统这个程序是用特定指令集编译的。.long 0x3"表示另一个属性标记,表示这个文件可以加载到任意地址。总之,这些元数据可能对程序运行起到关键作用,但在大多数情况下可能都没有明显的作用,因此看起来没有用。
执行gcc -S -g testBigExe.cpp -o testDebug.s,对比之前的汇编文件,由72行变成9760行。
.LBE32:
.file 3 "/usr/include/c++/9/bits/char_traits.h"
.loc 3 342 2 is_stmt 1 view .LVU4
.loc 1 5 11 is_stmt 0 view .LVU5
.loc 3 342 2 表示当前指令对应的源代码文件ID为3,在第342行,第2列(其中第1列是行号,第2列是第几个字符),同时is_stmt为1表示这条指令是语句的起始位置。.loc 1 5 11 表示当前指令对应的源代码文件ID为1,在第5行,第11列,同时is_stmt为0表示这条指令不是语句的起始位置。view .LVU4 表示当前指令所处的作用域(scope)是.LVU4。作用域是指该指令所在的函数、代码块等一段范围内的所有变量和对象的可见性。在这个例子中,.LVU4 是一个局部变量作用域,因为它是位于一个C++标准库头文件中的一个函数的起始位置。新增的这些 section 存储了 DWARF 调试信息。DWARF(Debugging With Attributed Record Formats)是一种调试信息的标准格式,包括代码中的变量、类型、函数、源文件的映射关系,以及代码的编译相关信息等等。
具体来说,这些 section 存储的内容如下:
.debug_info:包含程序的调试信息,包括编译单元、类型信息、函数和变量信息等。.debug_abbrev:包含了 .debug_info 中使用到的所有缩写名称及其对应的含义,用于压缩格式和提高效率。.debug_loc:存储每个程序变量或表达式的地址范围及其地址寄存器、表达式规则等信息。在调试时用来确定变量或表达式的值和范围。.debug_aranges:存储简化版本的地址范围描述,允许调试器加速地定位代码和数据的位置。.debug_ranges:存储每个编译单元(CU)的地址范围,每个范围都是一个有限开区间。.debug_line:存储源代码行号信息,包括每行的文件、行号、是否为语句起始位置等信息。.debug_str:包含了所有字符串,如文件名、函数名等,由于每个调试信息的数据都是字符串,因此这是所有调试信息的基础。需要注意的是,这些 section 中的信息是根据编译器的配置和选项生成的,因此不同编译器可能会生成略有不同的调试信息。
暂无
常见的web服务器有Apache、nginx、IIS
虽然 Ryujinx 模拟器项目本身是开源免费且合法的,但它默认情况下并不能直接运行市面上发行的各种商业游戏,因为它并不包含 Switch 系统固件,也没有游戏 ROM。
而按照国外的法规,如果你用户购买了主机和游戏,将其内容 DUMP (提取) 出来自己使用是合法的。
所以,无论是 Ryujinx 还是 Yuzu 等模拟器,想要开玩都需要先完成
prod.keys 密钥文件以及 Switch 的系统固件 (Firmware).NSP 或者 .XCI 格式率先支持了ARM和苹果 M 系列芯片
prod.keys 文件放进到 Ryujinx 目录中的 system 文件夹里,重启模拟器不是
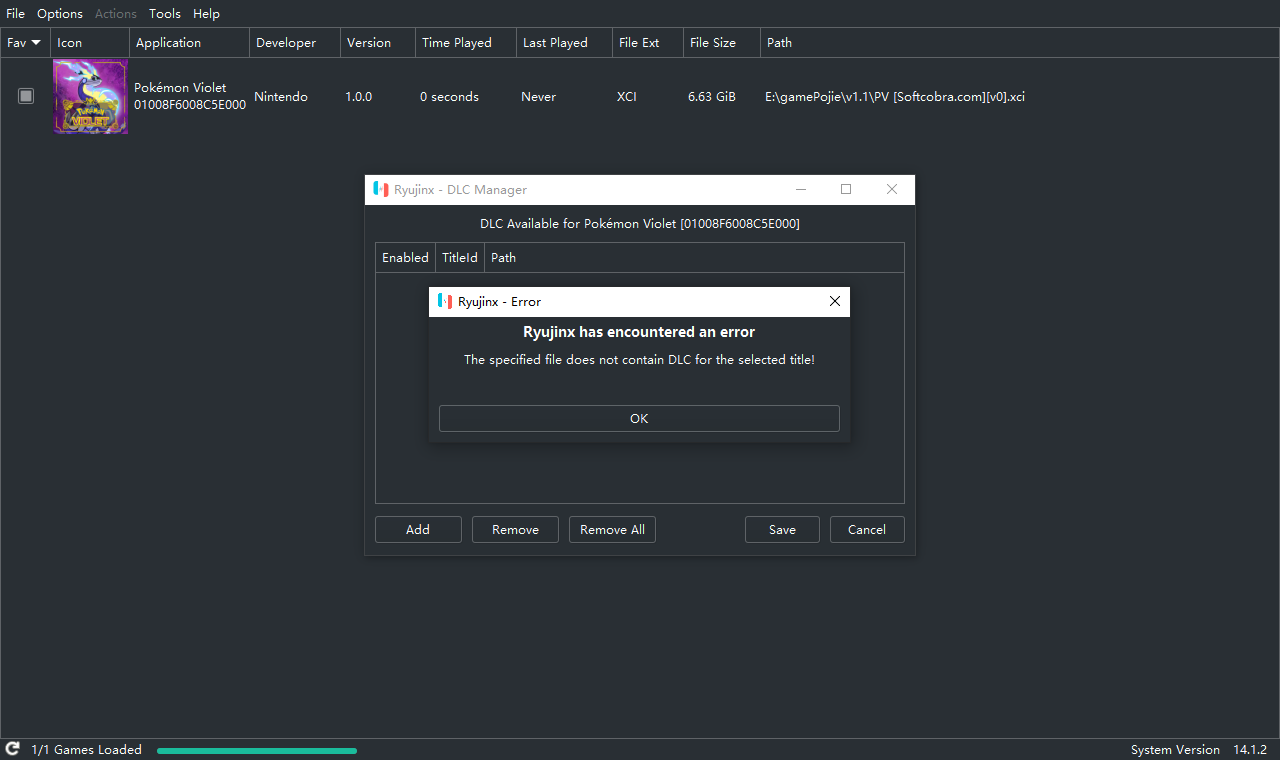
而是
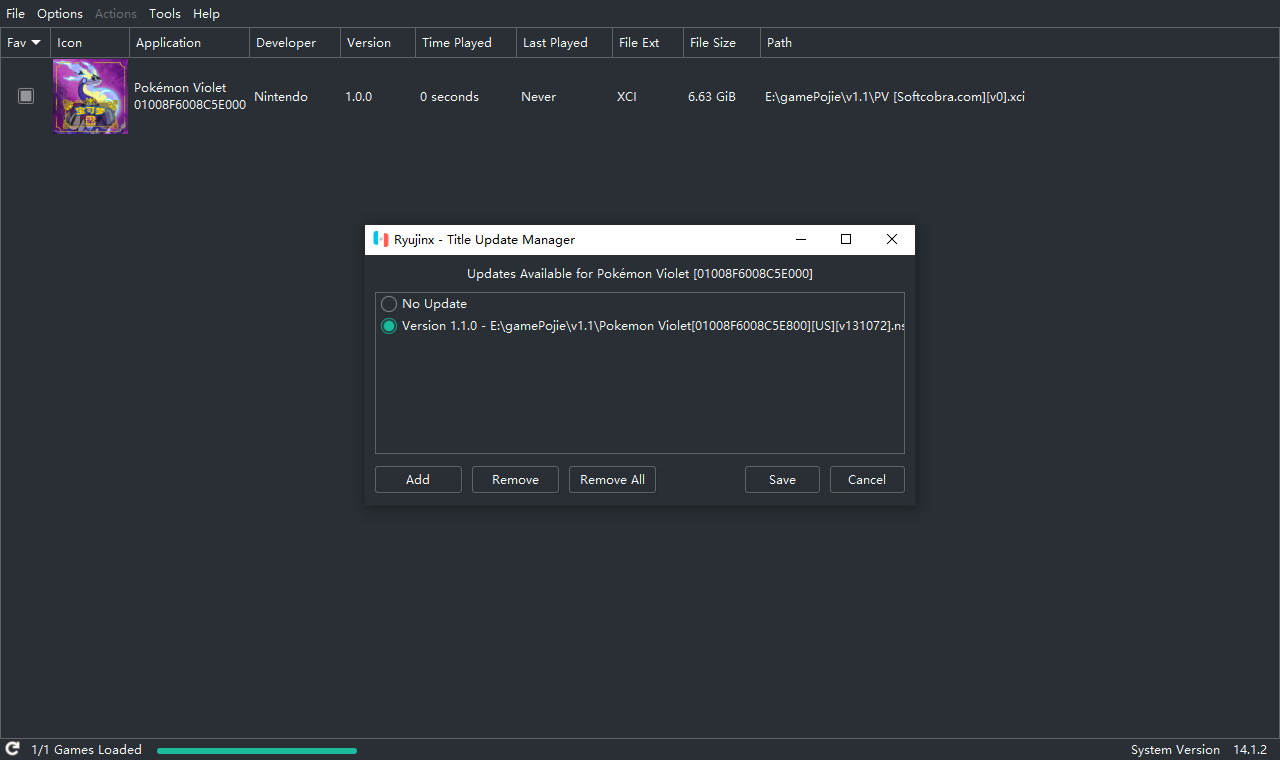
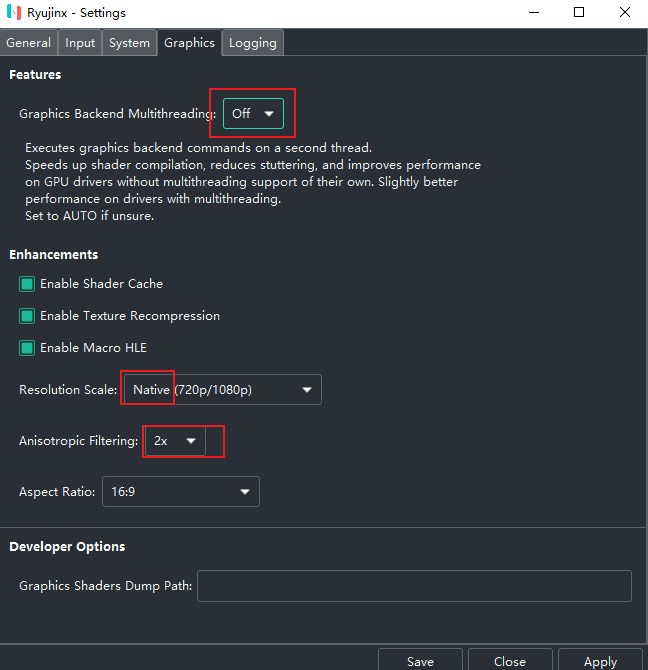
yuzu,奶刃2好像都是用这个
将你原来的User文件夹和ROM文件夹拖到新版模拟器文件夹的根目录即可。
将 prod.keys 文件放在Yuzu\user\keys
Yuzu\user\keysYuzu\user\nand\system\Contents\registeredhttps://www.playdanji.com/yuzu
https://www.playdanji.com/yuzujinshouzhi
Early Access版本是需要花钱订阅才能下载的。
github的release直接下载zip后解压替换即可。
游戏右键,打开存档位置。
F11
key和中文的问题,建议用之前好的文件
https://zhuanlan.zhihu.com/p/406048136
30帧720P
https://switch520.com/23050.html
v模式,暗场景会过曝。
贴吧老哥的放入目录
但是没什么用。
ini配置原理是,如下图对应配置目录
放入如下修改的ini文件来修改画质
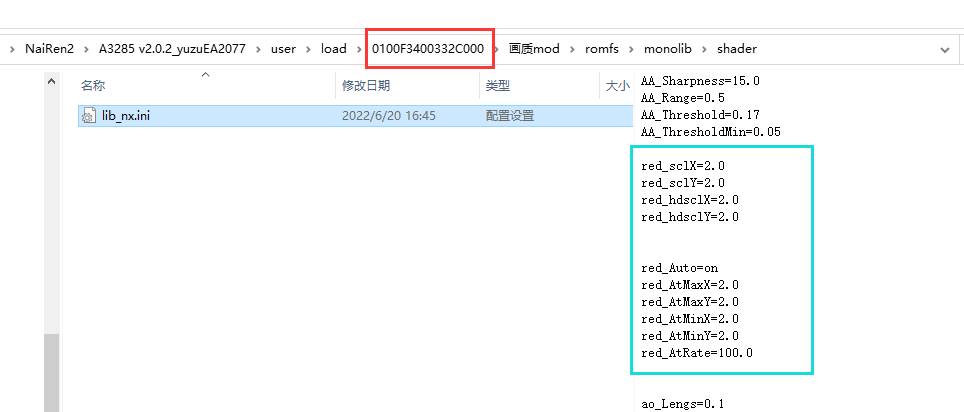
如下图成功
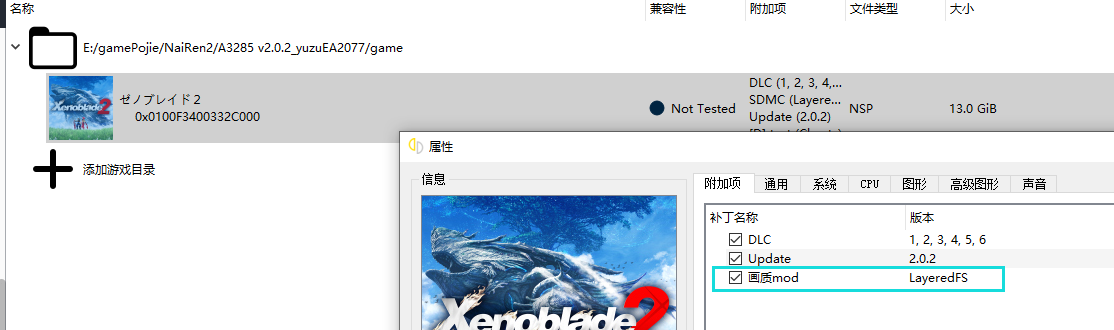
贴吧10楼:刚试了下,我把属性的mod选项关掉,然后把0100F3400332C000的画质mod删掉,效果一样有,所以效果应该只能在0100F3400332D001\画质mod\romfs\monolib\shader下的lib_nx.ini里改,其他的都没用
red_sclX=2.0
red_sclY=2.0
red_hdsclX=2.0
red_hdsclY=2.0
red_Auto=on
red_AtMaxX=2.0
red_AtMaxY=2.0
red_AtMinX=2.0
red_AtMinY=2.0
red_AtRate=100.0
2.0就是1440p,1.0就是原版720p。你们可以试试改其他的
60帧补丁实际效果远没有60帧而且一堆副作用,不用浪费时间了
按照B站设置,主要改了GLSL

游侠论坛的cemu模拟的效果就不错
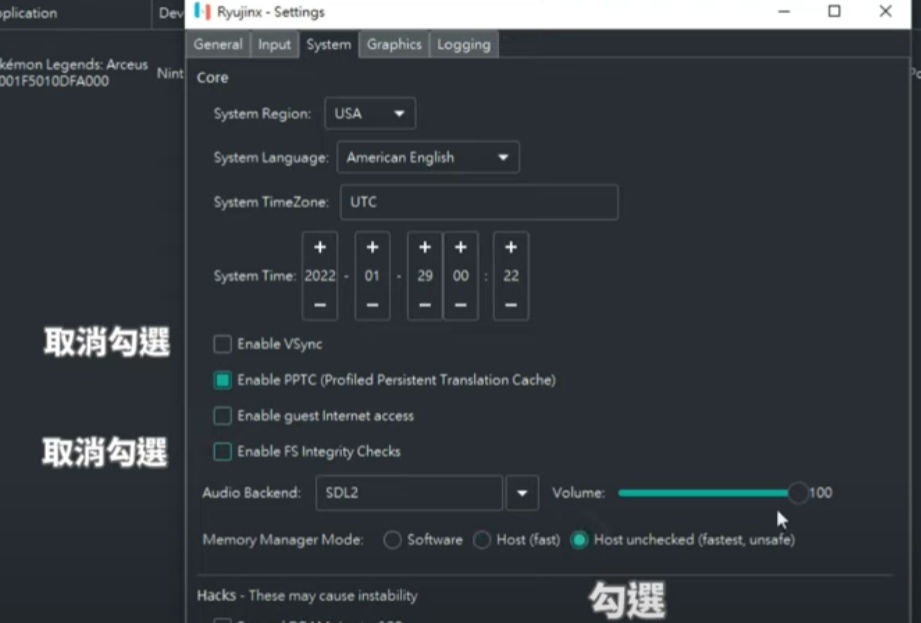
龙神模拟器,会经常闪退,暂时不知道解决办法(Cache PPTC rebuild?)。yuzu没有闪退的问题

暂无
暂无
之前买了正版的switch,游戏也入了两三千。旷/荒野之息,奥德赛,奶刃2都通关了。可惜被妈妈没收了~
想研究一下,PC模拟,记录踩坑过程
无
BitTorrent (简称 BT) 协议是和点对点(point-to-point)的协议程序不同,它是用户群对用户群(peer-to-peer, 或简写为 P2P) 传输协议, 它被设计用来高效地分发文件 (尤其是对于大文件、多人同时下载时效率非常高)。该协议基于HTTP协议,属于TCP/IP应用层。
将文件划分成多块(默认256Kb一块),每块可以从网络中不同的用户的BT客户端处并行下载。
比特彗星,包括其他 BT 软件(迅雷除外,迅雷不是会员会限速,高速通道下载提高的速度一部分就是接触限速后获得的)都不会限制下载速度。
与迅雷不同,BT旨在“人人为我,我为人人”。用户和用户之间对等交换自己手中已有的资源。如果任何一方试图白嫖另外一方的资源,而自己不愿意上传自己的资源,那么那方就会被人视作吸血者而被踢出这个交换,下场是没有人会愿意和你交换数据,你的下载速度也就归零。
如果把上传速度限制为了10KB/s,10KB/s是BitComet上传最低限速,很大时候就这10KB会被包含DHT查询、向Tracker服务器注册,连接用户所产生的上传全部占满。在下载种子的时候,其他用户连上你是只能拿到1~2KB/s甚至一点都没有的。
现在的BT下载客户端都可以做到智能反吸血,所以基本想和交换数据的用户都把你当作Leecher(吸血鬼)Ban(封禁)处理了,故没有下载速度不足为奇。
一般来说,只要预留50KB/s的上传给其他网页浏览、聊天就可以了,在下载时应该尽量把上传留给那些和你交换资源的用户,这样才不会被他们视作你在吸血进而屏蔽你。
如果上传不足,就应该主动限制自己的下载速度,否则单位时间下载量远超过上传量反而会遭来更多的屏蔽,对下载速度提升更加不利。
.torrent 种子文件本质上是文本文件,包含Tracker信息和文件信息两部分。Tracker信息主要是BT下载中需要用到的Tracker服务器的地址和针对Tracker服务器的设置。
sudo XAUTHORITY=/home/qcjiang/.Xauthority qbittorrent以qBit的docker为例,参考linuxsever的docker-compose如下:(qBit相对于Transmission有多线程IO的优势) 也可以使用其余docker镜像
---
version: "2.1"
services:
qbittorrent:
image: lscr.io/linuxserver/qbittorrent:latest
container_name: qbittorrent
environment:
- PUID=0 # 这里是root 如果想以其他用戶A修改文件,可以改成其他用户的UID。通過id A 查看
- PGID=0
- TZ=Etc/UTC
- WEBUI_PORT=8080
volumes:
- /addDisk/DiskNo4/qBit:/config
- /addDisk/DiskNo4/bt:/downloads
network_mode: host
restart: unless-stopped
默认账号 admin 默认密码 adminadmin
然后通过webUI http://222.195.72.218:8080/管理。
如果不想网络通过wireguard,而是本地可以如下设置
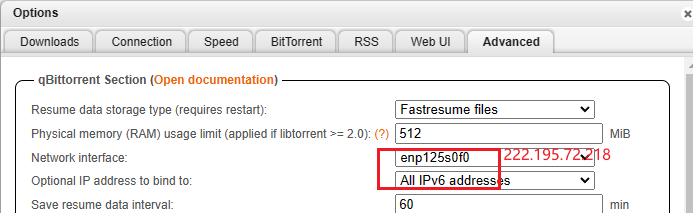

m站刷上传的时候,发现基本都是对方基本都是通过ipv6下载
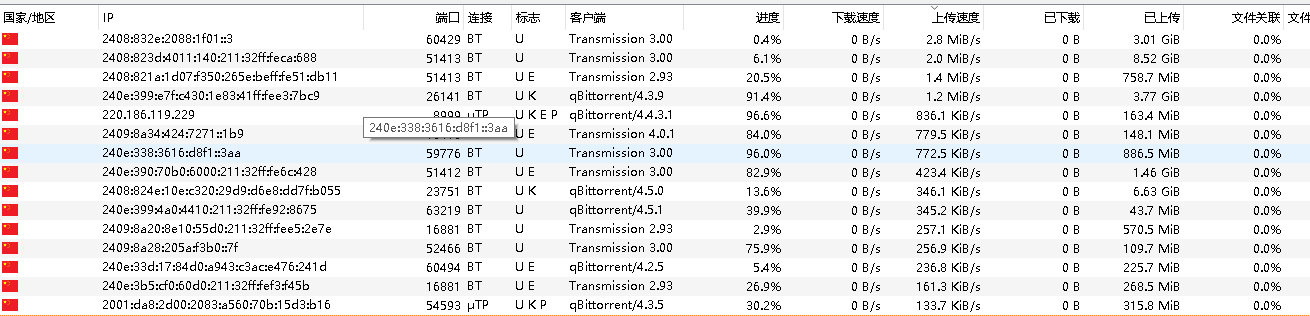 uTP是一种基于UDP的协议,它可以根据网络拥塞情况自动调节传输速度,从而减少对其他网络应用的影响。
uTP是一种基于UDP的协议,它可以根据网络拥塞情况自动调节传输速度,从而减少对其他网络应用的影响。
BT连接是一种基于TCP的协议,它可以保证数据的完整性和可靠性,但是可能会占用较多的网络带宽和资源。
在qBittorrent中,标志U K E P分别表示以下含义:
U:表示你正在上传数据给对方,或者对方正在从你那里下载数据。
K:表示对方支持uTP协议,即基于UDP的传输协议。
E:表示对方使用了加密连接,即通过加密算法保护数据的安全性。
P:表示对方使用了代理服务器或VPN服务,即通过第三方网络隐藏自己的真实IP地址。
收集下载者信息的服务器,并将此信息提供给其他下载者,使下载者们相互连接起来,传输数据。
指一个下载任务中所有文件都被某下载者完整的下载,此时下载者成为一个种子。发布者本身发布的文件就是原始种子。
发布者提供下载任务的全部内容的行为;下载者下载完成后继续提供给他人下载的行为。
上傳資料量 / 下傳資料量的比率,是一種BT的良心度,沒實際作用.(一般为了良心,至少大于1)
BitComet的概念,相对于种子任务的上传能够控制。
长效种子就是你不开启任务做种,只要你启动了比特彗星,软件挂后台,当有其他用户也是用比特彗星下载你列表里的存在的文件时候就会被认为是长效种子 。
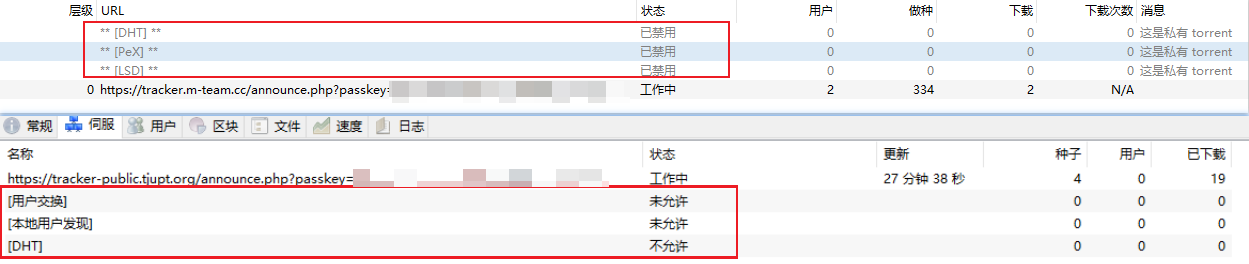
.DHT全称叫分布式哈希表(Distributed Hash Table),是一种分布式存储方法。在不需要服务器的情况下,每个客户端负责一个小范围的路由,并负责存储一小部分数据,从而实现整个DHT网络的寻址和存储。新版BitComet允许同行连接DHT网络和Tracker,也就是说在完全不连上Tracker服务器的情况下,也可以很好的下载,因为它可以在DHT网络中寻找下载同一文件的其他用户。
类似Tracker的根据种子特征码返回种子信息的网络。
在BitComet中,无须作任何设置即可自动连接并使用DHT网络,完全不需要用户干预。
Peer Exchange (PEX), 每个peer客户端的用户列表,可以互相交换通用。可以将其理解为“节点信息交换”。前面说到了 DHT 网络是没有中心服务器的,那么我们的客户端总不能满世界去喊:“我在下载这个文件,快来连我吧.”(很大声)。所以就通过各个 BT 客户端自带的节点去同步路由表实现 DHT 网络连接。
LSD(LPD)就是本地网络资源,内网下载,没什么几把用的东西,可能学校等私有网络好使
網絡業務提供商(Internet Service Provider,簡稱ISP),互聯網服務提供商,即向廣大用户綜合提供互聯網接入業務、信息業務、和增值業務的電信運營商。
bittorrent.anti_leech_min_byte
设定反吸血保护流量:要求对方在指定时间(秒)内需要上传的最少流量(byte), 取值范围:1-10000。
bittorrent.anti_leech_min_stable_sec
设定反吸血保护时间:指定与对方连接多长时间(秒)后开始检查流量(byte),取值范围:1-10000。
需要
文件下载后不能移动,不能删除,不能重命名(但可以在软件内改)。 一但BT 软件找不到文件,或删除了任务,就无法做种上传了。
可以在Bitcomet高级设置里设置时段限速
分享上传也需要频繁读取硬盘。
以Bitcomet为例,该软件就是通过磁盘缓存技术减小频繁随机读写对硬盘的损伤。
磁盘缓存就是利用物理内存作为缓冲,将下载下的数据先存放于内存中,然后定期的一次性写入硬盘,以减少对硬盘的写入操作,很大的程度上降低了磁盘碎片。
因为通常我们设置内存(磁盘缓存)为每任务XX兆,意味着,这个缓冲区可以存放数兆甚至几十兆的“块”,基本上可以杜绝碎片了。
现在BT软件都是自动设置缓存的,它是根据你物理内存的大小分配的。
路由器下载?