笔记¶
LLM Usage 1: prompt engineer
导言
常见的排行榜,国内外的GPT-like工具。
Interview
Keep in mind
- 只背⼋股⽂,是不⾏的,不太好进⼤公司。
- ⼤家要知道,⾯试官也是⼈,也知道候选⼈都在背⼋股⽂,⽽且⾯试官⾯过很多⼈,身经百战,你是背诵的,还是⾃⼰深刻理解过的,⾯试官⼀⾯你,就能知道你⼏⽄⼏两。也就是说,如果只会照本宣科的背⼋股⽂,⾯试会⽐较难受,碰到稍微严格的⾯试官,挖你细节,问到你不会为⽌,你会扛不住,⽆法根据情景说出⾃⼰的理解,这会给⾯试官很不好的印象,觉得你只会照猫画⻁。
- 在我看来,⽆论多么浅显的⼋股⽂,都要经过⾃⼰的实战经验,深度思考,再⽤⾃⼰的理解说出来,就算你的回答不是最好的答案,我觉得都没关系,你要让⾯试官看到你的潜⼒,看到你严谨的思维,清晰的表达。
编程风格 (TO DO:有待拓展:编程素养)
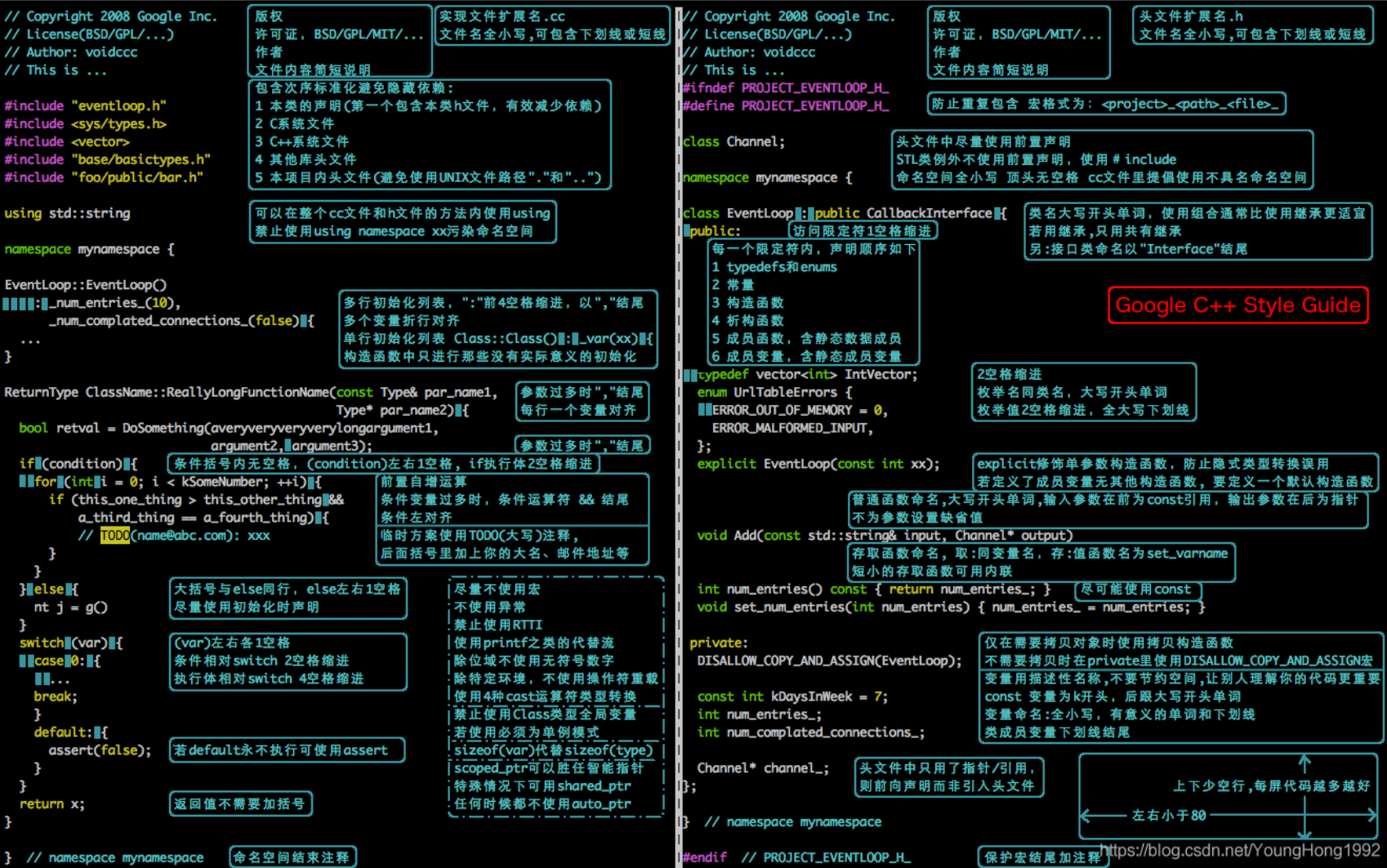
- 面向对象的数据结构思想:不要随便添加新的数据结构(边的信息),最好是在点的对象上添加。
- 让事情变得更简单、绝不重新发明轮子、尽可能使用经过验证的可靠技术。
- Time to use Class in C++
- Data and it's interface (复杂的数据/集合/容器和借口关系)
- 基类:数据,派生类:借口
- diff elements but in same one high level type (不同的事物,但是相同的抽象操作. )
- 基类:geometry(只是虚函数的框架),派生类:line, circle, Rectangle,相同操作:draw,calculate_area
- 基类:chart(只是虚函数的框架),派生类:line, bar, pie,相同操作:draw,push(add data)
- 数据格式以及初始化,要多态?
- Basic info & its specific application (信息的封装)
- 基类:基本信息,派生类:应用方向的基类
- useful utils (跨应用的常用轮子)
八股总结
- C++编程类
- 小贺 PDF
- 拓跋阿秀
- github interview c++
- 计网和操作系统
- 小林coding 图解
- 多进程通讯的方式,图解
- rdma, 下一代网络和互联技术
技术面
- 自我介绍
- 出彩经历介绍(项目、实习)
- STAR法则,也就是:“Situation: 事情是在什么情况下发生的;Task: 你的任务(难点)是什么;Action: 你的行动是什么;Result: 结果怎样。
- 时间占比如下,可以适当强调自己的工作 S+T:25% A:50% R:25%
- 技术测试(编程语法,和算法)
- 字节更看重编程,直接手撕各种算法
业务主管面
更宏观的问题:
- 职业规划为主:
- 详见 career blog
- 对各种事物的看法与价值观是否契合
- (越偏研究和长远发展的部门,问的越广泛。越偏业务的部门,问题越实际)
HR 面
面试官提问的:(生活相关的)
- 配偶,家庭成员
我提问的内容
- 工作内容:详细讨论了你去这个部门能做什么,准备安排你做什么,问你能不能胜任,保证了你是知道进去的工作内容。
- 薪酬:注意前面两面也有问你的期望,那时候不要说太少,本人当时就是期望薪酬定的太低了,HR直接就给了。后面想反悔也不行。
- 聊聊住址城市、升职,转正。
- 工作节奏(上下班,周末)
- 基本上都是8小时工作制,双休,午休一小时。弹性上班9点半到10点半。
需要进一步的研究学习
暂无
遇到的问题
暂无
开题缘由、总结、反思、吐槽~~
参考文献
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
无
Interview in english
Interview Preparation:
There is no set structure or format for your interview; it really just depends on the interviewer, and the direction the conversation goes, etc. You will likely be asked to explain something you worked on, and that would include some core skillset questions to check your understanding of your projects. Here are a few general suggestions to help you prepare:
1) Be prepared to speak at depth regarding any core skillset details in your background, for example: coding/technology-based questions; the two best ways to prepare for this would be to review your resume, and make sure you are able to talk at depth about skills you mentioned there, and to review the job description, and brush up on anything you might know, but feel you might not be able to go into detail about.
2) Ask good questions – about team, what we are up to, possible role/roles you might be a good fit for.
3) Read up on our website about our products and the company (many interviewers will ask what you know about us, and it is better to be prepared to answer - it shows interest in the company and what we are up to).
4) Access to a computer with an internet connection is typically required for your interviews
self-introduction in English
"Hello, I am a graduate student majoring in Computer Science and Technology at the University of Science and Technology of China. I am currently pursuing/pəˈsjuːɪŋ/ a master's degree. I completed my undergraduate studies at the same university and had the opportunity to participate in both the ASC and ISC competitions during my undergraduate years.
In my graduate studies, I have primarily focused on research related to High-Performance Computing. This includes projects such as static code analysis for Kunpeng processors, participation in program parallelization and acceleration optimization competitions, and exploring PIM (Processing in Memory) computing.
Through my academic and research experiences, I have developed a dual/ˈduːəl/ expertise /ˌekspɜːˈtiːz/ in computer microarchitecture and practical/ˈpræktɪkl/ application optimization. I have honed/hoʊnd/ the ability to swiftly identify program hotspots when faced with new applications, leveraging/ˈlevərɪdʒ/ the unique characteristics of computer systems to achieve efficient deployment and enhance program performance.
Furthermore, I have taken a keen/kiːn/ interest in emerging technologies such as artificial intelligence and machine learning. I aspire to apply these skills flexibly in fields like AI for science/HPC and AI program deployment. Thank you for considering my candidacy/ˈkændɪdəsi/ for this opportunity."
项目的介绍和关键字
参考文献
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
https://www.nowcoder.com/discuss/401041683767468032
Disordered Ideas
- What'sNext 副业。量化金融,落地快:1.每一次策略的修改都直接影响下一次能不能赚钱;性能优化也是。
-
Bigger 量化金融,负责资金统一管理。adapator,股票,证券,期货,外汇
-
自动交易工具:数据接口,交易接口
重要说明:
这里存放着未被整理、分类,和仔细对比讨论过的 ideas。
Balance (Efficient) work & life time
导言
"Balancing work and personal life is the cornerstone of a successful and productive career."
2.3: Health Quantify
fitness
| 230910 | 230922 | |
|---|---|---|
| Neck | 39cm | |
| bust | 89cm | |
| the whole body | 110cm | |
| waist | 84cm | |
| hipline | 95cm | |
| Upper Arm Circumference | 27cm | |
| Forearm circumference | 23.4cm | |
| Thigh Girth | 57cm | 54.6cm |
| calf Grith | 38.4cm | 36.5cm |
| weight | 65.4kg | 65.9kg |
stretching
- 弓箭步/站立版坐位体前屈,大小腿后侧
- 后提脚踝,并大腿,前倾,拉伸大腿前侧
- 侧面压腿,翘脚尖
Running
- 隔天跑
- 抬头收腹,挺直上半身
- 双手拔枪摆动,且向后用力摆
- 重心在脚底,而且前脚掌着地,而且离地后迅速向前收缩。膝盖弯曲
- 放松轻盈。
walking / Posture
- 抬头,收腹提背(收肋骨,吐腹部)
- 臀大腿发力,减少小腿发力。
- 足弓发力
Problem
- 体态:肋骨外翻(肋骨高于锁骨),核心不足,
- 表现:腰围代偿性增粗,粗大腿,粗小腿
Plan
- 早上床上拉伸,
- 侧卧抬腿
- 抱膝
- 工作:按压拉伸小腿。时刻注意腹式呼吸体态。
- 晚饭前跑步,拉伸
- 晚上床上拉伸
锻炼 不能 瘦小腿。正确的走路姿势才行
这个说得很在点子上,我是在19年末的时候通过改变走路发力方式瘦小腿的。与其说瘦腿,其实更是和大腿相比看起来更匀称,我之前的小腿肚站起来时候和大腿一样粗,站直的时候膝盖甚至是合不上的。经过反思,发现我日常走路的时候时间长了经常会感到小腿酸胀,这其实一直是在用小腿走路,我在这期间尝试过跑步,虽小有成效,但停下来就又会恢复原状。这种情况导致的小腿粗是一个比较复杂的原理,但我最后通过大半年的时间对走路方式进行了调整,现在虽然小腿不算细,但和大腿比起来看起来已经相当正常了,我的调整策略如下: 走路时注意重心靠后,也就是后背中间的位置,同时双肩放松,这样你会不自觉地挺胸抬头,同时为保持平衡感觉到腹部有牵引感。走路时大腿内侧和屁股发力,重点来了:保持脚后跟尽量贴住地面(踮脚走路是大忌),迈步时脚后跟先接触地面,在前脚后跟接触地面之前,后脚后跟不要离开地面。简单来说就是用脚后跟走路,你会发现这个过程中小腿是几乎不怎么发力的,时间久了只要不是肥胖型自然会瘦下来。
参考文献
Komga
简介
漫画或者PDF的jellyfin版本 , 类似的还有 基于docker的smanga
选择
Rather than browse rouman online, high-resolution pivix pictures seems more worthy to be downloaded and maintained.
But first you need a much bigger NAS.
安装
- 通过Docker安装(Docker on Windows 体验不好)
- 通过java运行
Windows
- 由于在portainer.io里路径有问题,选择直接在docker里点击
image run创建容器。 - 如果输入数据来源多,建议设置子目录
data/1anddata/2。 and Please think carefully because restart container will triger the following bugs: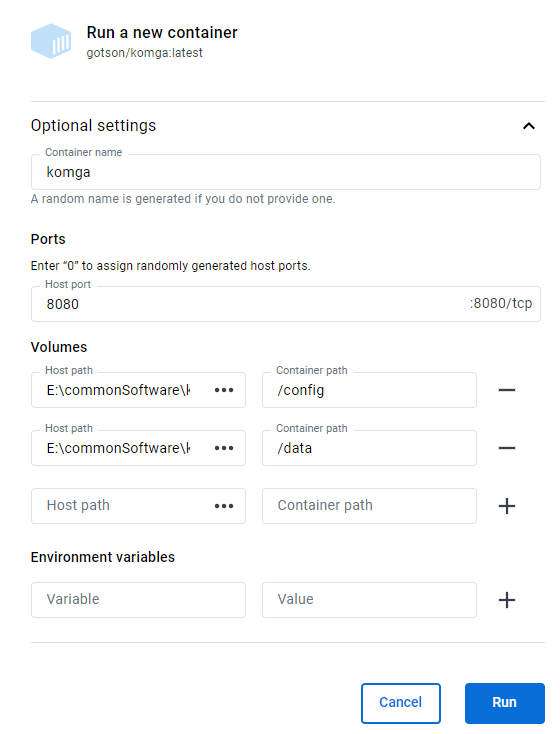
But docker on Windows remains many bugs:
- Failed to restart the docker engine
- deadlock between first free volume to delete container and first stop already stepped container to free related volume.
Linux docker
In http://brainiac.acsalab.com:2333/
step1: map remote data to local visual disk
- map windows disk to linux
- map Nas disk to linux
sudo mount.cifs //synology.acsalab.com/Entertainment /synology -o user=xxx vers=3.0
Step2 : docker
采取第一种, 在 portainer.io的local的stack里使用docker compose部署
---
version: '3.3'
services:
komga:
image: gotson/komga
container_name: komga
volumes:
- type: bind
source: /mnt/e/commonSoftware/komga/config # Database and Komga configurations
target: /config
- type: bind
source: /mnt/e/commonSoftware/komga/data # Location of your data directory on disk. Choose a folder that contains both your books and your preferred import location for hardlinks to work.
target: /data/komga
- type: bind
source: /etc/timezone #alternatively you can use a TZ environment variable, like TZ=Europe/London
target: /etc/timezone
read_only: true
ports:
- 2333:8080 # 应用内部的 8080 到机器的2333端口。由于机器的8080被qBit占用了
user: "1000:1000"
# remove the whole environment section if you don't need it
environment:
- <ENV_VAR>=<extra configuration>
restart: unless-stopped
Docker in Ugreen Nas
- easy pull official
komgaimage - set mount disk
- set port
komga V.S. smanga V.S Kavita
- exhentai-manga-manager only on widnows
- smanga,
- 优点: 1. 带标签和收藏,维持三级目录, 2. 独特的目录设计。
- 缺点: 1. png读取正常,但是zip解压过于缓慢 2. PDF的支持暂时欠缺: 1. 无法阅读 2. PDF阅读与decompress的冲突 3. 元数据不能自由编辑,只能编辑标签。 4. 不能读取根目录的文件,但是能选择单行本,或许可以解决这个问题,但是需要尝试。 5. 无法读到过深的文件夹。
- 小结:本来寄希望于这个all in one, 但是问题太多,还是只适合刮削好的资源。 可以不断完善和尝试。
- 举例:所有韩漫,
- Kavita
- 优点: 1. 纯zip文件能读到深处的文件夹 2. 日漫带标签和收藏,有缩略图。 3. 元数据能自由编辑
- 缺点: 1. 奇怪的文件名识别规则,导致 2. 杂乱的类型(zip, png, pdf)会导致目录混乱 3. 不能读取根目录的文件
- 小结:适合高度组织过后的内容
- 举例:2022单行本,零散日漫单行本。和calibre处理后的文件。
- komga
- 优点: 1. 维持原始目录结构,稳定简洁。 2. 元数据能自由编辑 3. 根目录文件能识别
- 缺点: 1. 没有收藏,保存和标签等功能,不适合碎片化连续看。
- 小结:适合混乱的内容,靠文件夹的并列和包含关系,维护逻辑关系。
- 举例:杂志(没有子文件夹包裹,识别不了),漫之学院(太大),日漫大合集(混乱的结构)
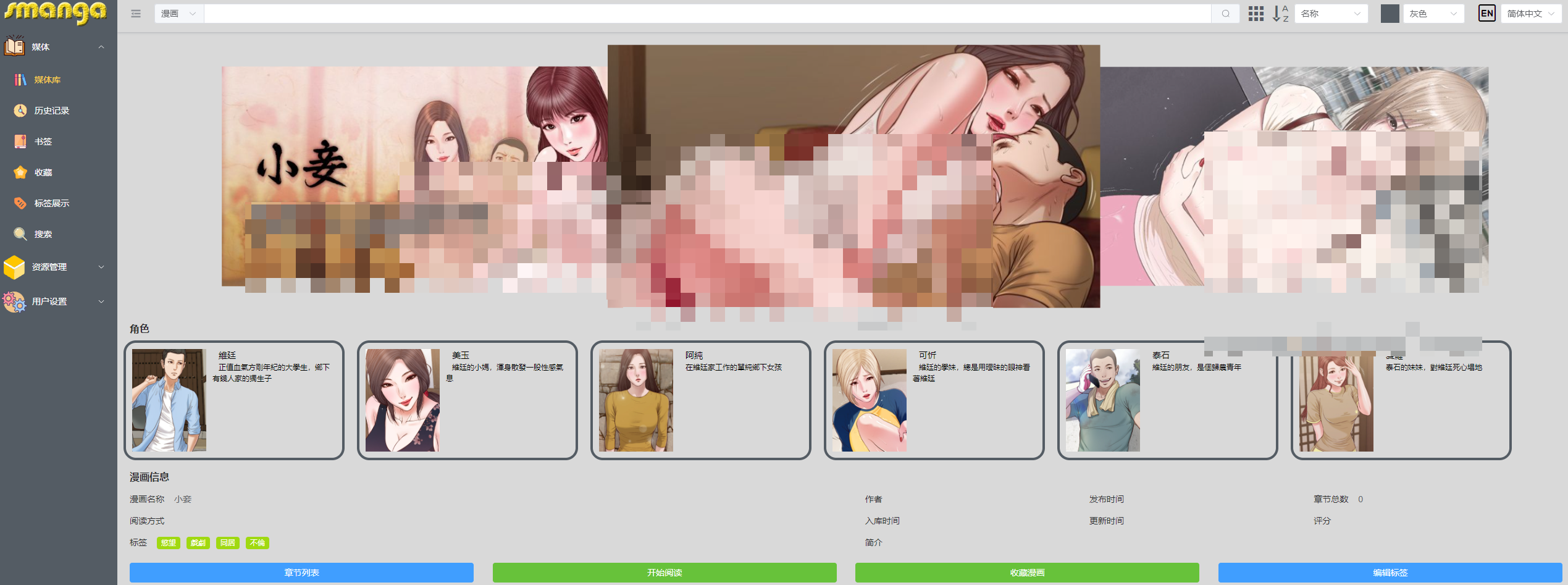
需要图书/漫画刮削
有刮削建议 smanga
有封面图和备注详细角色和类型信息。
| dockers | komga | smanga | Kavita |
|---|---|---|---|
| 单一大PDF文件加载 | 缓慢 | 缓慢 | |
| 格式支持 | zip,cbz,pdf | 部分zip不支持bug,不支持cbz | zip,pdf ,cbz |
| 如何支持单文件夹多图片 | 每个文件夹单独压缩成zip反而支持 | ||
| 自定义元数据 | |||
| 任意位置标签 | |||
| 已知bug | 容器会自动关机(有待进一步测试) | ||
| 总体评价 | 基础完善稳定,但是定制化不足 | 有用的定制化 | 全,但是不维持原目录有点恶心,导致必须按照类型整理。 |
Manga vs comic
"Manga" 和 "comic" 是两个术语,通常用于描述不同地区和文化中的漫画,其中 "manga" 常用于日本漫画,而 "comic" 通常用于西方漫画,包括美国漫画。
- Manga(漫画):
- 地域: "Manga" 是日本的一种漫画形式,是日本漫画的通用术语。
-
特点: Manga 的特点包括从右到左的阅读顺序,经常包含有关日本文化和社会的元素,以及广泛的主题和风格。
-
Comic(漫画):
- 地域: "Comic" 是一个通用的英语词汇,用于描述西方国家的漫画,主要是美国漫画。
- 特点: Comic 的特点包括从左到右的阅读顺序,以及通常较大的页数和较大的漫画行业。
需要注意的是,"manga" 和 "comic" 不仅仅是描述漫画的词汇,它们还代表了不同的创作风格、文化和产业。虽然在某些上下文中可能会使用这两个词汇来泛指漫画,但在讨论时最好根据具体的地域和文化使用适当的术语。
其余未汉化版本
推荐文件结构
kativa
- Kavita enforces that all files are within folders from the library root. Files at library root will be ignored.
- kativa 会将不符合文件夹命名
Series Name的新文件(e.g.,abc.cbz),当作新的作品单独列出在根目录。这十分傻逼,对内容的共振度的要求也太高了。出现一个命名不规范的文件就会乱套。 - kativa 对文件类型也会做特殊处理,对png, cbz, zip文件会有不同的阅读器,最搞笑的是 kativa会把子章节cbz的同名图片单独用个文件夹放置,而不是识别出章节的封面图,kativa会读取子章节cbz的内容当作封面图。
smanga
可以看得出作者有特殊的设计。
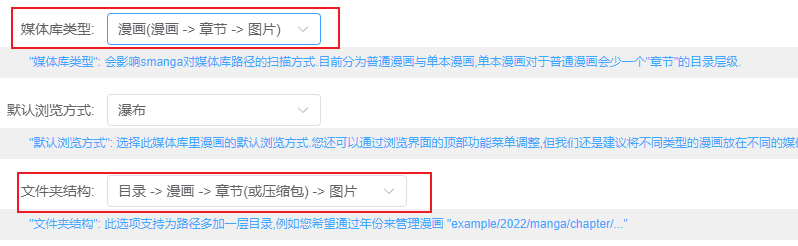
但是美中不足的是对于子文件夹的支持不够,太深的文件读取不到。
单行本
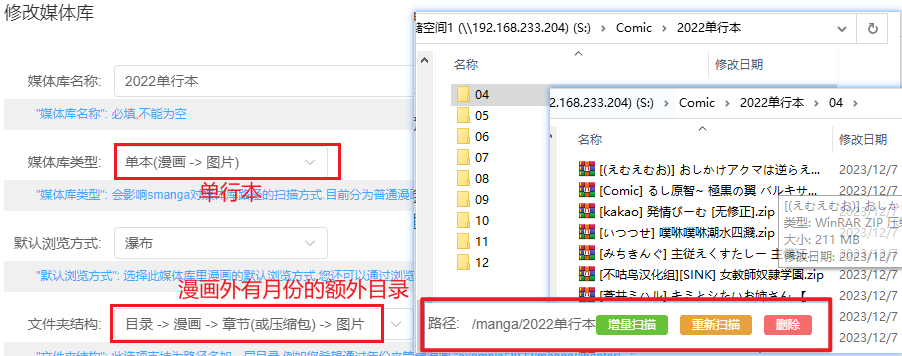
理论如此,但是实际貌似会卡住。
komga
Komga支持CBZ/CBR、EPUB、PDF格式。对于漫画而言,个人觉得cbz1是最简单、兼容性最高的格式。
建议的文件结构如下:
.
└── libraryManga
├── 我 推 的 孩 子
│ ├── 第 1话.cbz
│ └── 第 9话 .cbz
└── 辉夜大小姐想让我告白
├── 01话 .cbz
└── 02话.cbz
3 directories, 4 files
libraryManga表示库名,下一层结构区分不同的漫画,更下一层则存储漫画文件- komga相对于kavita的异同
- 都不会识别根目录下的文件
- 但是komga不会管Series文件夹的子文件夹,会认为不存在,全部打散。kavata由于命名的原因会将Series文件夹的子文件夹内的内容当作新的系列,提到根目录显示。
内容的组织
需要考虑的点
内容的组织考虑的是一个平衡,每个lib下应该只有40个左右的内容。
- 根据类别分类:
- 韩漫,日漫,杂志
- 根据时间分类:每个月大约有50部左右
下载的内容的特点:
- 日漫,很多是单行本没有系列的,所以系列的这一级文件夹可以使用时间代替
- 有些库太大了,估计有一千本漫画(漫之学院),必须分开。
- 有些库还是识别不了
合集/A/PDF/*
实践
看多少,刮削多少。
内容的刮削
calibre + ehentai
见 Calibre and its Pugins for e-hentai Books 一文
失败:BangumiKomga
- 一个从Bangumi获取元数据并填充的Python脚本。
- 但是自动识别刮削的成功率很低,强烈建议在Bangumi中先找到对应漫画后把链接贴到Komga系列作品链接处,标签写为
cbl,配置好后在目录下运行python processMetadata.py,即可近乎完美的给漫画加上海报和信息了 - 但是Bangumi又没有本子的内容
集成订阅平台:tachidesk
尝试后发现是,类似RSS的漫画网页集成浏览器(B站,腾讯漫画,18+漫画)。实现订阅,跟踪,一键下载。 由于生态很不错,不用担心订阅链接失效。
Bugs docker stopped in UGREEEN
我猜测是内存不够
kavita自动关机
[Kavita] [2023-12-08 07:21:00.508 +00:00 194] [Information] Serilog.AspNetCore.RequestLoggingMiddleware HTTP GET /api/image/series-cover?seriesId=759&apiKey=39714029-85f9-446c-9834-9ad384fda00d responded 304 in 0.9718 ms
[Kavita] [2023-12-08 07:21:50.010 +00:00 188] [Information] Serilog.AspNetCore.RequestLoggingMiddleware HTTP POST /api/account/refresh-token responded 200 in 2630.1327 ms
[Kavita] [2023-12-08 07:21:50.043 +00:00 193] [Information] Serilog.AspNetCore.RequestLoggingMiddleware HTTP GET /api/license/valid-license?forceCheck=false responded 200 in 17.1837 ms
[Kavita] [2023-12-08 07:21:50.045 +00:00 182] [Information] Serilog.AspNetCore.RequestLoggingMiddleware HTTP POST /hubs/messages/negotiate?negotiateVersion=1 responded 200 in 5.7189 ms
[Kavita] [2023-12-08 07:21:50.131 +00:00 168] [Information] Serilog.AspNetCore.RequestLoggingMiddleware HTTP GET /api/device responded 200 in 107.7960 ms
Server is shutting down. Please allow a few seconds to stop any background jobs...
You may now close the application window.
[Kavita] [2023-12-08 07:21:55.785 +00:00 179] [Information] Serilog.AspNetCore.RequestLoggingMiddleware HTTP POST /hubs/messages/negotiate?negotiateVersion=1 responded 200 in 0.1795 ms
[Kavita] [2023-12-08 07:21:55.789 +00:00 45] [Information] Microsoft.Hosting.Lifetime Application is shutting down...
[Kavita] [2023-12-08 07:22:26.562 +00:00 179] [Fatal] Host terminated unexpectedly
System.AggregateException: One or more hosted services failed to stop. (The operation was canceled.)
---> System.OperationCanceledException: The operation was canceled.
at System.Threading.CancellationToken.ThrowOperationCanceledException()
at System.Threading.CancellationToken.ThrowIfCancellationRequested()
at Hangfire.Processing.TaskExtensions.WaitOneAsync(WaitHandle waitHandle, TimeSpan timeout, CancellationToken token)
at Hangfire.Processing.BackgroundDispatcher.WaitAsync(TimeSpan timeout, CancellationToken cancellationToken)
at Hangfire.Server.BackgroundProcessingServer.WaitForShutdownAsync(CancellationToken cancellationToken)
at Microsoft.Extensions.Hosting.Internal.Host.StopAsync(CancellationToken cancellationToken)
--- End of inner exception stack trace ---
at Microsoft.Extensions.Hosting.Internal.Host.StopAsync(CancellationToken cancellationToken)
at Microsoft.Extensions.Hosting.HostingAbstractionsHostExtensions.WaitForShutdownAsync(IHost host, CancellationToken token)
at Microsoft.Extensions.Hosting.HostingAbstractionsHostExtensions.RunAsync(IHost host, CancellationToken token)
at Microsoft.Extensions.Hosting.HostingAbstractionsHostExtensions.RunAsync(IHost host, CancellationToken token)
at API.Program.Main(String[] args) in /home/runner/work/Kavita/Kavita/API/Program.cs:line 115
komga自动关机
查看对应docker日志, 猜测容器运行时,可能会受到资源限制,例如内存不足、CPU 使用过高等。如果容器超过了资源限制,可能会被系统强制关闭。
2023-12-07T11:28:39.022Z INFO 1 --- [taskProcessor-4] o.g.komga.application.tasks.TaskHandler : Task FindBooksWithMissingPageHash(libraryId='0EEB1WDMHPFT0', priority='0') executed in 722.922us
2023-12-07T11:28:39.080Z INFO 1 --- [taskProcessor-4] o.g.komga.application.tasks.TaskHandler : Executing task: FindDuplicatePagesToDelete(libraryId='0EEB1WDMHPFT0', priority='0')
2023-12-07T11:28:39.096Z INFO 1 --- [taskProcessor-4] o.g.komga.application.tasks.TaskEmitter : Sending tasks: []
2023-12-07T11:28:39.096Z INFO 1 --- [taskProcessor-4] o.g.komga.application.tasks.TaskHandler : Task FindDuplicatePagesToDelete(libraryId='0EEB1WDMHPFT0', priority='0') executed in 16.090346ms
2023-12-07T13:38:16.408Z INFO 1 --- [ionShutdownHook] o.s.b.w.e.tomcat.GracefulShutdown : Commencing graceful shutdown. Waiting for active requests to complete
2023-12-07T13:38:16.638Z INFO 1 --- [tomcat-shutdown] o.s.b.w.e.tomcat.GracefulShutdown : Graceful shutdown complete
2023-12-07T13:38:18.871Z INFO 1 --- [ionShutdownHook] com.zaxxer.hikari.HikariDataSource : SqliteTaskPool - Shutdown initiated...
2023-12-07T13:38:18.883Z INFO 1 --- [ionShutdownHook] com.zaxxer.hikari.HikariDataSource : SqliteTaskPool - Shutdown completed.
2023-12-07T13:38:18.887Z INFO 1 --- [ionShutdownHook] com.zaxxer.hikari.HikariDataSource : SqliteUdfPool - Shutdown initiated...
2023-12-07T13:38:18.889Z INFO 1 --- [ionShutdownHook] com.zaxxer.hikari.HikariDataSource : SqliteUdfPool - Shutdown completed.
____ __.
| |/ _|____ _____ _________
| < / _ \ / \ / ___\__ \
| | ( <_> ) Y Y \/ /_/ > __ \_
|____|__ \____/|__|_| /\___ (____ /
\/ \//_____/ \/
Version: 1.8.4
需要进一步的研究学习
暂无
遇到的问题
暂无
开题缘由、总结、反思、吐槽~~
参考文献
https://sspai.com/post/79100
1.3 making-money business
人的精力是有限的,投入到自己喜欢或者为生的事情上,其他的事情,专业的事情交给专业的人
1.2 Career
简介
工作回顾,当前工作,未来展望