C Program Compile Problems
TODO:[5] please fix all in free time 重复了和另一篇
TODO:[5] please fix all in free time 重复了和另一篇
编译是指编译器读取源程序(字符流),对之进行词法和语法的分析,将高级语言指令转换为功能等效的汇编代码。
#include语句以及一些宏插入程序文本中,得到main.i和sum.i文件。main.i和sum.i编译成文本文件main.s和sum.c的汇编语言程序。
低级的汇编语言为不同的高级语言提供了通用输出语言。main.s和sum.s翻译成机器语言的二进制指令,并打包成一种叫做可重定位目标程序的格式,并将结果保存在main.o和sum.o两个文件中。这种文件格式就比较接近elf格式了。main.o和sum.o,得到可执行目标文件,就是elf格式文件。
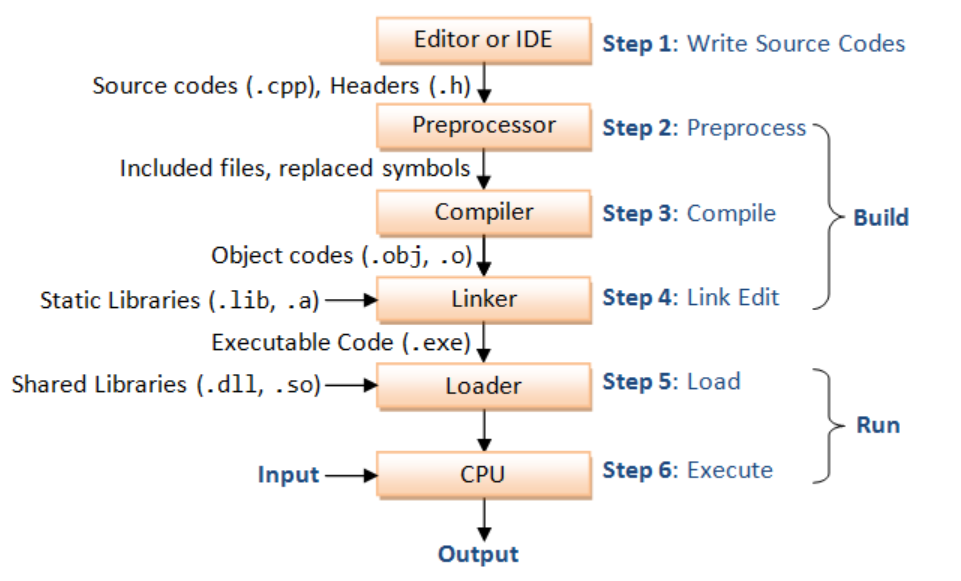
目标文件有三种形式:
.c 文件转化成 .i文件.gcc –E filename.cpp -o filename.i-E Preprocess only; do not compile, assemble or link.-C能保留头文件里的注释,如gcc -E -C circle.c -o circle.cgcc -save-temps -c -o main.o main.ccpp filename.cpp -o filename.i命令linemarkers类似# linenum filename flags的注释,这些注释是为了让编译器能够定位到源文件的行号,以便于编译器能够在编译错误时给出正确的行号。flags meaning除开注释被替换成空格,包括代码里的预处理命令:
#error "text" 的作用是在编译时生成一个错误消息,它会导致编译过程中断。 同理有#warning#define a b 对于这种伪指令,预编译所要做的是将程序中的所有a用b替换,但作为字符串常量的 a则不被替换。还有 #undef,则将取消对某个宏的定义,使以后该串的出现不再被替换。#ifdef SNIPER,#if defined SNIPER && SNIPER == 0,#ifndef,#else,#elif,#endif等。 这些伪指令的引入使得程序员可以通过定义不同的宏来决定编译程序对哪些代码进行处理。预编译程序将根据有关的文件,将那些不必要的代码过滤掉-DSNIPER=5#include "FileName"或者#include 等。
该指令将头文件中的定义统统都加入到它所产生的输出文件中,以供编译程序对之进行处理。LINE标识将被解释为当前行号(十进制数),FILE则被解释为当前被编译的C源程序的名称。
预编译程序对于在源程序中出现的这些串将用合适的值进行替换。#include "" vs #include <> 区别在于前者会在文件的当前目录寻找,但是后者只会在编译器编译的official路径寻找
通常的搜索顺序是:
#include 命令中以引号包括的文件名)。-iquote选项指定的目录,依照出现在命令行中的顺序进行搜索。只对 #include 命令中采用引号的头文件名进行搜索。-I开始, 依照出现在命令行中的顺序进行搜索。(可以使用-I/path/file只添加一个头文件,尤其是在编译的兼容性修改时)-isystem选项指定的目录,依照出现在命令行中的顺序进行搜索。C_INCLUDE_PATH,CPLUS_INCLUDE_PATH,OBJC_INCLUDE_PATH指定的路径再找系统默认目录(/usr/include、/usr/local/include、/usr/lib/gcc-lib/i386-linux/2.95.2/include......)
通过如下命令可以查看头文件搜索目录 gcc -xc -E -v - < /dev/null 或者 g++ -xc++ -E -v - < /dev/null*. 如果想改,需要重新编译gcc
g++ -H -v查看是不是项目下的同名头文件优先级高于sys-head-file.c/.h或者.i文件转换成.s文件,gcc –S filename.cpp -o filename.s,对应于-S Compile only; do not assemble or link.gcc –S filename.i -o filename.s 也是可行的。但是我遇到头文件冲突的问题error: declaration for parameter ‘__u_char’ but no such parametercc –S filename.cpp -o filename.s cc1命令-O3)如果想把 C 语言变量的名称作为汇编语言语句中的注释,可以加上 -fverbose-asm 选项:
请阅读 GNU assembly file一文
汇编器:将.s 文件转化成 .o文件,
gcc –c,-c Compile and assemble, but do not link.as;目标文件由段组成。通常一个目标文件中至少有两个段:
代码段:该段中所包含的主要是程序的指令。该段一般是可读和可执行的,但一般却不可写。
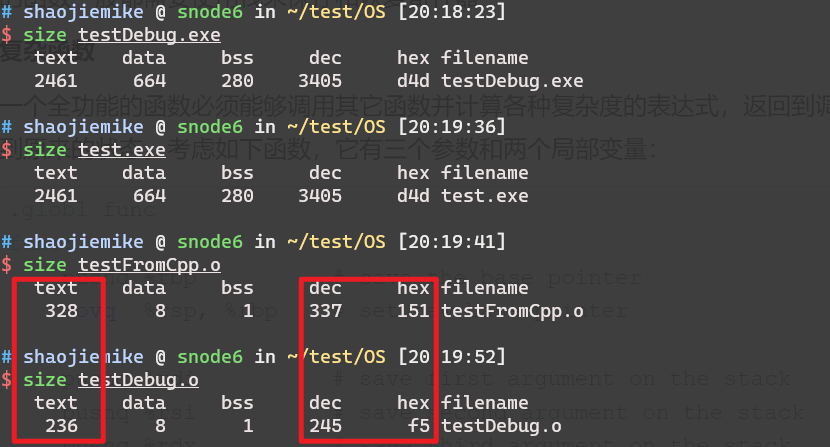
objdump -Sd ../build/bin/pivot > pivot1.s-S 以汇编代码的形式显示C++原程序代码,如果有debug信息,会显示源代码。nm file.o 查看目标文件中的符号表注意,这时候的目标文件里的使用的函数可能没定义,需要链接其他目标文件.a .so .o .dll(Dynamic Link Library的缩写,Windows动态链接库)
List symbol names in object files.
no symbols
常用选项 -CD
-C 选项告诉 nm 将 C++ 符号的 mangled 名称转换为原始的、易于理解的名称。常用于.a的静态库。-D / --dynamic:显示动态符号,这在查看共享库(如 .so 文件)时非常有用。输出
| 符号类型 | 描述 |
|---|---|
| A | 符号值是绝对的。在进一步的连接中,不会被改变。 |
| B | 符号位于未初始化数据段(known as BSS). |
| C | 共用(common)符号. 共用符号是未初始化的数据。在连接时,多个共用符号可能采用一个同样的名字,如果这个符号在某个地方被定义,共用符号被认为是未定义的引用. |
| D | 已初始化数据段的符号 |
| G | 已初始化数据段中的小目标(small objective)符号. 一些目标文件格式允许更有效的访问小目标数据,比如一个全局的int变量相对于一个大的全局数组。 |
| I | 其他符号的直接应用,这是GNU扩展的,很少用了. N 调试符号. |
| R | 只读数据段符号. S 未初始化数据段中的小目标(small object)符号. |
| T | 代码段的符号. |
| U | 未定义符号. |
| V | 弱对象(weak object)符号. 当一个已定义的弱符号被连接到一个普通定义符号,普通定义符号可以正常使用,当一个未定义的弱对象被连接到一个未定义的符号,弱符号的值为0. |
| W | 一个没有被指定一个弱对象符号的弱符号(weak symbol)。 - a.out目标文件中的刺符号(stabs symbol). 这种情况下,打印的下一个值是其他字段,描述字段,和类型。刺符号用于保留调试信息. |
| ? | 未知符号类型,或者目标文件特有的符号类型. |
这个顺序是针对G++编译的,但是对于python查找库,有所不同,会从ldconfig设置开始
/lib,/usr/lib,/lib64(在64位系统上),/usr/lib64(在64位系统上)遍历 LD_LIBRARY_PATH 中的每个目录,并查找包括软链接在内的所有 .so 文件。
IFS=':' dirs="$LD_LIBRARY_PATH"
for dir in $dirs; do
find -L "$dir" -name "*.so" 2>/dev/null
done
ldconfig 命令用于配置动态链接器的运行时绑定。你可以使用它来查询系统上已知的库文件的位置()。
ldconfig 会扫描
/lib 和 /usr/lib,以及 /etc/ld.so.conf 中列出的目录),查找共享库文件(.so 文件),/etc/ld.so.cache。这个缓存文件会被动态链接器(ld.so 或 ld-linux.so)使用,以加快共享库的查找速度。# 查看所有是path 的库
ldconfig -v
# 永久添加一个新的库路
echo "/path/to/your/library" | sudo tee /etc/ld.so.conf.d/your-library.conf
sudo ldconfig
# 查询 libdw.so 的位置:
ldconfig -p | grep libdw
ldd会显示动态库的链接关系,中间的nm为U没关系,只需要最终.so对应符号是T即可。ldd 时避免对不可信的可执行文件运行,因为它可能会执行恶意代码。readelf -d 或 objdump -p 来查看库依赖。解析 ELF 文件
ldd 会首先读取输入的可执行文件或共享库(通常是 ELF 格式的文件)。
ELF(Executable and Linkable Format)是一种文件格式,用于存储可执行文件、目标代码、共享库等。
查找依赖项
ELF 文件包含一个段(section),其中列出了所需的共享库的名称和路径。这些信息存储在 ELF 的动态段(.dynamic)中。
ldd 通过解析这些信息,识别出需要加载的共享库。
使用动态链接器
ldd 通过调用动态链接器(如 ld-linux.so)来解析和加载这些共享库。
动态链接器负责在运行时加载库并解决符号(symbol),即将函数或变量名称映射到实际内存地址。
输出结果
ldd 列出每个依赖库的名称、路径以及它们在内存中的地址。
ldd 会显示“not found”的提示。ldd 显示not found的库,不一定程序在执行就找不到
比如conda的库,ldd就无法解析。猜测和python的运行逻辑有关,比如import的使用,自动搜索相关的lib目录。
通过使用ld命令,将编译好的目标文件连接成一个可执行文件或动态库。
Foo::bar(int,long)会变成bar__3Fooil。其中3是名字字符数见 Linux Executable file: Structure & Running
undefined reference to一旦链接器完成了符号解析这一步,就把代码中的每个符号引用和正好一个符号定义(即它的一个输入目标模块中的一个符号表条目)关联起来。此时,链接器就知道它的输入目标模块中的代码节和数据节的确切大小。现在就可以开始重定位步骤了,在这个步骤中,将合并输入模块,并为每个符号分配运行时地址。重定位由两步组成:
.data 节被全部合并成一个节,这个节成为输出的可执行目标文件的.data 节。当汇编器生成一个目标模块时,它并不知道数据和代码最终将放在内存中的什么位置。它也不知道这个模块引用的任何外部定义的函数或者全局变量的位置。所以,无论何时汇编器遇到对最终位置未知的目标引用,它就会生成一个重定位条目,告诉链接器在将目标文件合并成可执行文件时如何修改这个引用。
代码的重定位条目放在 .rel.text 中。已初始化数据的重定位条目放在 .rel.data 中。
下面 展示了 ELF 重定位条目的格式。
R_X86_64_PC32。重定位一个使用 32 位 PC 相对地址的引用。回想一下 3.6.3 节,一个 PC 相对地址就是距程序计数器(PC)的当前运行时值的偏移量。当 CPU 执行一条使用 PC 相对寻址的指令时,它就将在指令中编码的 32 位值加上 PC 的当前运行时值,得到有效地址(如 call 指令的目标),PC 值通常是下一条指令在内存中的地址。(将 PC 压入栈中来使用)R_X86_64_32。重定位一个使用 32 位绝对地址的引用。通过绝对寻址,CPU 直接使用在指令中编码的 32 位值作为有效地址,不需要进一步修改。typedef struct {
long offset; /* Offset of the reference to relocate */
long type:32, /* Relocation type */
symbol:32; /* Symbol table index */
long addend; /* Constant part of relocation expression */
} Elf64_Rela;
链接器通常从左到右解析依赖项,这意味着如果库 A 依赖于库 B,那么库 B 应该在库 A 之前被链接。
库顺序
假设有三个库 libA, libB, 和 libC,其中 libA 依赖 libB,而 libB 又依赖 libC。在 CMake 中,你应该这样链接它们:
这样的顺序确保了当链接器处理 libA 时,libB 和 libC 中的符号已经可用。



静态库static library就是将相关的目标模块打包形成的单独的文件。使用ar命令。
静态库的优点在于:
问题:
深入理解计算机系统P477,静态库例子
图 7-8 概括了链接器的行为。-static 参数告诉编译器驱动程序,链接器应该构建一个完全链接的可执行目标文件,它可以加载到内存并运行,在加载时无须更进一步的链接。-lvector 参数是 libvector.a 的缩写,-L. 参数告诉链接器在当前目录下查找 libvector.a。

共享库是以两种不同的方式来“共享”的:

如上创建了一个可执行目标文件 prog2l,而此文件的形式使得它在运行时可以和 libvector.so 链接。基本的思路是:
dlopen() interface.情况:在应用程序被加载后执行前时,动态链接器加载和链接共享库的情景。
核心思想:由动态链接器接管,加载管理和关闭共享库(比如,如果没有其他共享库还在使用这个共享库,dlclose函数就卸载该共享库。)。
.interp 节,这一节包含动态链接器的路径名,动态链接器本身就是一个共享目标(如在 Linux 系统上的 ld-linux.so). 加载器不会像它通常所做地那样将控制传递给应用,而是加载和运行这个动态链接器。然后,动态链接器通过执行下面的重定位完成链接任务:最后,动态链接器将控制传递给应用程序。从这个时刻开始,共享库的位置就固定了,并且在程序执行的过程中都不会改变。
情况:应用程序在运行时要求动态链接器加载和链接某个共享库,而无需在编译时将那些库链接到应用。
实际应用情况:
思路是将每个生成动态内容的函数打包在共享库中。
编译器yasm的参数-DPIE
如果同一份代码可能被加载到进程空间的任意虚拟地址上执行(如共享库和动态加载代码),那么就需要使用-fPIC生成位置无关代码。
可以加载而无需重定位的代码称为位置无关代码(Position-Independent Code,PIC)
在一个 x86-64 系统中,对同一个目标模块中符号的引用是不需要特殊处理使之成为 PIC。可以用 PC 相对寻址来编译这些引用,构造目标文件时由静态链接器重定位。
解决方法:延迟绑定(lazy binding),将过程地址的绑定推迟到第一次调用该过程时。
动机:使用延迟绑定的动机是对于一个像 libc.so 这样的共享库输出的成百上千个函数中,一个典型的应用程序只会使用其中很少的一部分。把函数地址的解析推迟到它实际被调用的地方,能避免动态链接器在加载时进行成百上千个其实并不需要的重定位。
结果:第一次调用过程的运行时开销很大,但是其后的每次调用都只会花费一条指令和一个间接的内存引用。
实现:延迟绑定是通过两个数据结构之间简洁但又有些复杂的交互来实现的,这两个数据结构是:GOT 和过程链接表(Procedure Linkage Table,PLT)。如果一个目标模块调用定义在共享库中的任何函数,那么它就有自己的 GOT 和 PLT。GOT 是数据段的一部分,而 PLT 是代码段的一部分。
首先,让我们介绍这两个表的内容。
PLT[0] 是一个特殊条目,它跳转到动态链接器中。PLT[1](图中未显示)调用系统启动函数(__libc_start_main),它初始化执行环境,调用 main 函数并处理其返回值从 PLT[2] 开始的条目调用用户代码调用的函数。在我们的例子中,PLT[2] 调用 addvec,PLT[3](图中未显示)调用 printf。
上图a 展示了 GOT 和 PLT 如何协同工作,在 addvec 被第一次调用时,延迟解析它的运行时地址:
上图b 给出的是后续再调用 addvec 时的控制流:
静态库
动态库
shaojiemike@snode6 /lib/modules/5.4.0-107-generic/build [06:32:26]
> gcc -print-search-dirs
install: /usr/lib/gcc/x86_64-linux-gnu/9/
programs: =/usr/lib/gcc/x86_64-linux-gnu/9/:/usr/lib/gcc/x86_64-linux-gnu/9/:/usr/lib/gcc/x86_64-linux-gnu/:/usr/lib/gcc/x86_64-linux-gnu/9/:/usr/lib/gcc/x86_64-linux-gnu/:/usr/lib/gcc/x86_64-linux-gnu/9/../../../../x86_64-linux-gnu/bin/x86_64-linux-gnu/9/:/usr/lib/gcc/x86_64-linux-gnu/9/../../../../x86_64-linux-gnu/bin/x86_64-linux-gnu/:/usr/lib/gcc/x86_64-linux-gnu/9/../../../../x86_64-linux-gnu/bin/
libraries: =/usr/lib/gcc/x86_64-linux-gnu/9/:/usr/lib/gcc/x86_64-linux-gnu/9/../../../../x86_64-linux-gnu/lib/x86_64-linux-gnu/9/:/usr/lib/gcc/x86_64-linux-gnu/9/../../../../x86_64-linux-gnu/lib/x86_64-linux-gnu/:/usr/lib/gcc/x86_64-linux-gnu/9/../../../../x86_64-linux-gnu/lib/../lib/:/usr/lib/gcc/x86_64-linux-gnu/9/../../../x86_64-linux-gnu/9/:/usr/lib/gcc/x86_64-linux-gnu/9/../../../x86_64-linux-gnu/:/usr/lib/gcc/x86_64-linux-gnu/9/../../../../lib/:/lib/x86_64-linux-gnu/9/:/lib/x86_64-linux-gnu/:/lib/../lib/:/usr/lib/x86_64-linux-gnu/9/:/usr/lib/x86_64-linux-gnu/:/usr/lib/../lib/:/usr/lib/gcc/x86_64-linux-gnu/9/../../../../x86_64-linux-gnu/lib/:/usr/lib/gcc/x86_64-linux-gnu/9/../../../:/lib/:/usr/lib/
加载器:将可执行程序加载到内存并进行执行,loader和ld-linux.so。
将可执行文件加载运行
| 命令 | 描述 |
|---|---|
| ar | 创建静态库,插入、删除、列出和提取成员; |
| stringd | 列出目标文件中所有可以打印的字符串; |
| strip | 从目标文件中删除符号表信息; |
| nm | 列出目标文件符号表中定义的符号; |
| size | 列出目标文件中节的名字和大小; |
| readelf | 显示一个目标文件的完整结构,包括ELF 头中编码的所有信息。 |
| objdump | 显示目标文件的所有信息,最有用的功能是反汇编.text节中的二进制指令。 |
| ldd | 列出可执行文件在运行时需要的共享库。 |
ltrace 跟踪进程调用库函数过程 strace 系统调用的追踪或信号产生的情况 Relyze 图形化收费试用
-g选项,可以生成调试信息,这样在gdb中可以查看源代码。objdump -g <archive_file>.a
# 如果.o文件有debugging symbols,会输出各section详细信息
Contents of the .debug_aranges section (loaded from predict-c.o):
# 没有则如下
cabac-a.o: file format elf64-x86-64
dct-a.o: file format elf64-x86-64
deblock-a.o: file format elf64-x86-64
gcc -E -g testBigExe.cpp -o testDebug.i相对于无-g的命令,只会多一行信息# 1 "/staff/shaojiemike/test/OS//"gcc -S -g testBigExe.cpp -o testDebug.s,对比之前的汇编文件,由72行变成9760行。具体解析参考 GNU assembly file一文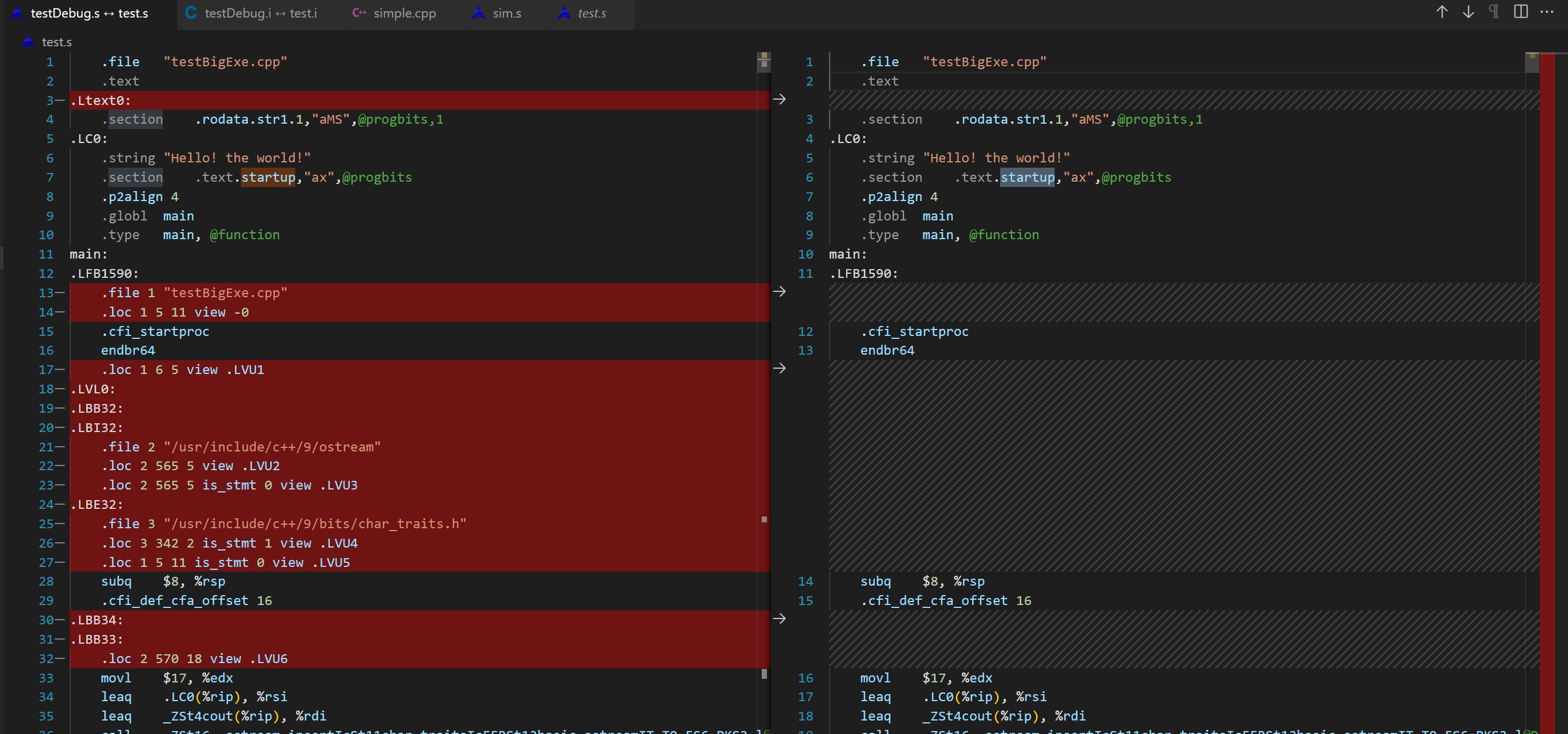
简单的#pragma omp for,编译后多出汇编代码如下。当前可以创建多少个线程默认汇编并没有显示的汇编指令。
call omp_get_num_threads@PLT
movl %eax, %ebx
call omp_get_thread_num@PLT
movl %eax, %ecx
call GOMP_barrier@PLT
某些atomic的导语会变成对应汇编
暂无
基础不牢,地动山摇。ya 了。
https://www.cnblogs.com/LiuYanYGZ/p/5574601.html
https://hansimov.gitbook.io/csapp/part2/ch07-linking/7.5-symbols-and-symbol-tables
常见的问题:
主要原因是头文件的include的使用不同,还有一些接口的改变。
$ make obj-intel64/inscount0.so
g++
# Warning Options
-Wall -Werror -Wno-unknown-pragmas -Wno-dangling-pointer
# Program Instrumentation Options
-fno-stack-protector
# Code-Gen-Options
-fno-exceptions -funwind-tables -fasynchronous-unwind-tables -fPIC
# C++ Dialect
-fabi-version=2 -faligned-new -fno-rtti
# define
-DPIN_CRT=1 -DTARGET_IA32E -DHOST_IA32E -DTARGET_LINUX
# include
-I../../../source/include/pin
-I../../../source/include/pin/gen
-isystem /staff/shaojiemike/Download/pin-3.28-98749-g6643ecee5-gcc-linux/extras/cxx/include
-isystem /staff/shaojiemike/Download/pin-3.28-98749-g6643ecee5-gcc-linux/extras/crt/include
-isystem /staff/shaojiemike/Download/pin-3.28-98749-g6643ecee5-gcc-linux/extras/crt/include/arch-x86_64
-isystem /staff/shaojiemike/Download/pin-3.28-98749-g6643ecee5-gcc-linux/extras/crt/include/kernel/uapi
-isystem /staff/shaojiemike/Download/pin-3.28-98749-g6643ecee5-gcc-linux/extras/crt/include/kernel/uapi/asm-x86
-I../../../extras/components/include
-I../../../extras/xed-intel64/include/xed
-I../../../source/tools/Utils
-I../../../source/tools/InstLib
# Optimization Options
-O3 -fomit-frame-pointer -fno-strict-aliasing
-c -o obj-intel64/inscount0.o inscount0.cpp
g++ -shared -Wl,--hash-style=sysv ../../../intel64/runtime/pincrt/crtbeginS.o -Wl,-Bsymbolic -Wl,--version-script=../../../source/include/pin/pintool.ver -fabi-version=2
-o obj-intel64/inscount0.so obj-intel64/inscount0.o
-L../../../intel64/runtime/pincrt
-L../../../intel64/lib
-L../../../intel64/lib-ext
-L../../../extras/xed-intel64/lib
-lpin -lxed ../../../intel64/runtime/pincrt/crtendS.o -lpindwarf -ldl-dynamic -nostdlib -lc++ -lc++abi -lm-dynamic -lc-dynamic -lunwind-dynamic
对应的makefile规则在source/tools/Config/makefile.default.rules
# Build the intermediate object file.
$(OBJDIR)%$(OBJ_SUFFIX): %.cpp
$(CXX) $(TOOL_CXXFLAGS) $(COMP_OBJ)$@ $<
# Build the tool as a dll (shared object).
$(OBJDIR)%$(PINTOOL_SUFFIX): $(OBJDIR)%$(OBJ_SUFFIX)
$(LINKER) $(TOOL_LDFLAGS) $(LINK_EXE)$@ $< $(TOOL_LPATHS) $(TOOL_LIBS)
UINT64 undefined bug: inscount0.cpp include pin.H which includes types_foundation.PH由于old pintool 基于 pin2.14。作为对比也分析inscount0.so的编译过程
g++
# Warning Options
-Wall -Werror -Wno-unknown-pragmas
# Program Instrumentation Options
-fno-stack-protector
# Code-Gen-Options
-fPIC
# define
-DBIGARRAY_MULTIPLIER=1 -DTARGET_IA32E -DHOST_IA32E -DTARGET_LINUX
-I../../../source/include/pin
-I../../../source/include/pin/gen
-I../../../extras/components/include
-I../../../extras/xed-intel64/include
-I../../../source/tools/InstLib
# Optimization Options
-O3 -fomit-frame-pointer -fno-strict-aliasing
-c -o obj-intel64/inscount0.o inscount0.cpp
同时multipim 的scons的编译细节如下,去除与pin无关的参数:
g++
# Warning Options
-Wall -Wno-unknown-pragmas
# c++ language
-std=c++0x
# Code-Gen-Options
-fPIC
# debug
-g
# Program Instrumentation Options
-fno-stack-protector
# Preprocessor Options ???TODO:
-MMD
# machine-dependent
-march=core2
# C++ Dialect
-D_GLIBCXX_USE_CXX11_ABI=0
-fabi-version=2
# define
-DBIGARRAY_MULTIPLIER=1 -DUSING_XED
-DTARGET_IA32E -DHOST_IA32E -DTARGET_LINUX
-DPIN_PATH="/staff/shaojiemike/github/MultiPIM_icarus0/pin/intel64/bin/pinbin" -DZSIM_PATH="/staff/shaojiemike/github/MultiPIM_icarus0/build/opt/libzsim.so" -DMT_SAFE_LOG
-Ipin/extras/xed-intel64/include
-Ipin/source/include/pin
-Ipin/source/include/pin/gen
-Ipin/extras/components/include
# Optimization Options
-O3 -funroll-loops -fomit-frame-pointer
-c -o build/opt/simple_core.os build/opt/simple_core.cpp
对比后,pin3.28 相对 pin2.14 编译时,
-DPIN_CRT=1// pin/extras/crt/include/freebsd/3rd-party/include/elf.h
> typedef uint16_t Elf32_Section;
> typedef uint16_t Elf64_Section;
// /usr/include/wordexp.h
remove __THROW
First apply the two change to old pintool
暂无
暂无
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
无
#ifndef _LIBCPP_TYPE_VIS
# if !defined(_LIBCPP_DISABLE_VISIBILITY_ANNOTATIONS)
# define _LIBCPP_TYPE_VIS __attribute__ ((__visibility__("default")))
# else
# define _LIBCPP_TYPE_VIS
# endif
#endif
#ifndef _LIBCPP_THREAD_SAFETY_ANNOTATION
# ifdef _LIBCPP_HAS_THREAD_SAFETY_ANNOTATIONS
# define _LIBCPP_THREAD_SAFETY_ANNOTATION(x) __attribute__((x))
# else
# define _LIBCPP_THREAD_SAFETY_ANNOTATION(x)
# endif
#endif // _LIBCPP_THREAD_SAFETY_ANNOTATION
class _LIBCPP_TYPE_VIS _LIBCPP_THREAD_SAFETY_ANNOTATION(capability("mutex")) mutex
{
}
It's part of code from __mutex_base
暂无
暂无
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
无
-M option is designed for auto-generate Makefile rules from g++ command.-E option to STOP after preprocessor during the compilation-w option to DISABLE/suppress all warnings.Using a complex g++ command as an example:
g++ -Wall -Werror -Wno-unknown-pragmas -DPIN_CRT=1 -fno-stack-protector -fno-exceptions -funwind-tables -fasynchronous-unwind-tables -fno-rtti -DTARGET_IA32E -DHOST_IA32E -fPIC -DTARGET_LINUX -fabi-version=2 -faligned-new -I../../../source/include/pin -I../../../source/include/pin/gen -isystem /staff/shaojiemike/Download/pin-3.28-98749-g6643ecee5-gcc-linux/extras/cxx/include -isystem /staff/shaojiemike/Download/pin-3.28-98749-g6643ecee5-gcc-linux/extras/crt/include -isystem /staff/shaojiemike/Download/pin-3.28-98749-g6643ecee5-gcc-linux/extras/crt/include/arch-x86_64 -isystem /staff/shaojiemike/Download/pin-3.28-98749-g6643ecee5-gcc-linux/extras/crt/include/kernel/uapi -isystem /staff/shaojiemike/Download/pin-3.28-98749-g6643ecee5-gcc-linux/extras/crt/include/kernel/uapi/asm-x86 -I../../../extras/components/include -I../../../extras/xed-intel64/include/xed -I../../../source/tools/Utils -I../../../source/tools/InstLib -O3 -fomit-frame-pointer -fno-strict-aliasing -Wno-dangling-pointer
-M inscount0.cpp -o Makefile_bk
In Makefile_bk
inscount0.o: inscount0.cpp \
# sys header
/usr/include/stdc-predef.h \
/staff/shaojiemike/Download/pin-3.28-98749-g6643ecee5-gcc-linux/extras/cxx/include/iostream \
/usr/lib/gcc/x86_64-linux-gnu/11/include/float.h
# usr header
../../../source/include/pin/pin.H \
../../../extras/xed-intel64/include/xed/xed-interface.h \
... more header files
-MM not include sys header file-MF filename config the Makefile rules write to which file instead of to stdout.-M -MG is designed to generate Makefile rules when there is header file missing, treated it as generated in normal.-M -MP will generated M-rules for dependency between header filesheader1.h includes header2.h. So header1.h: header2.h in Makefile-MD == -M -MF file without default option -Efile has a suffix of .d, e.g., inscount0.d for -c inscount0.cpp-MMD == -MD not include sys header file暂无
暂无
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
无
摘要
ABI被人熟知,就是编译时,接口不匹配导致运行时的动态库undefined symbol报错。
Pin 是一个动态二进制插桩工具:
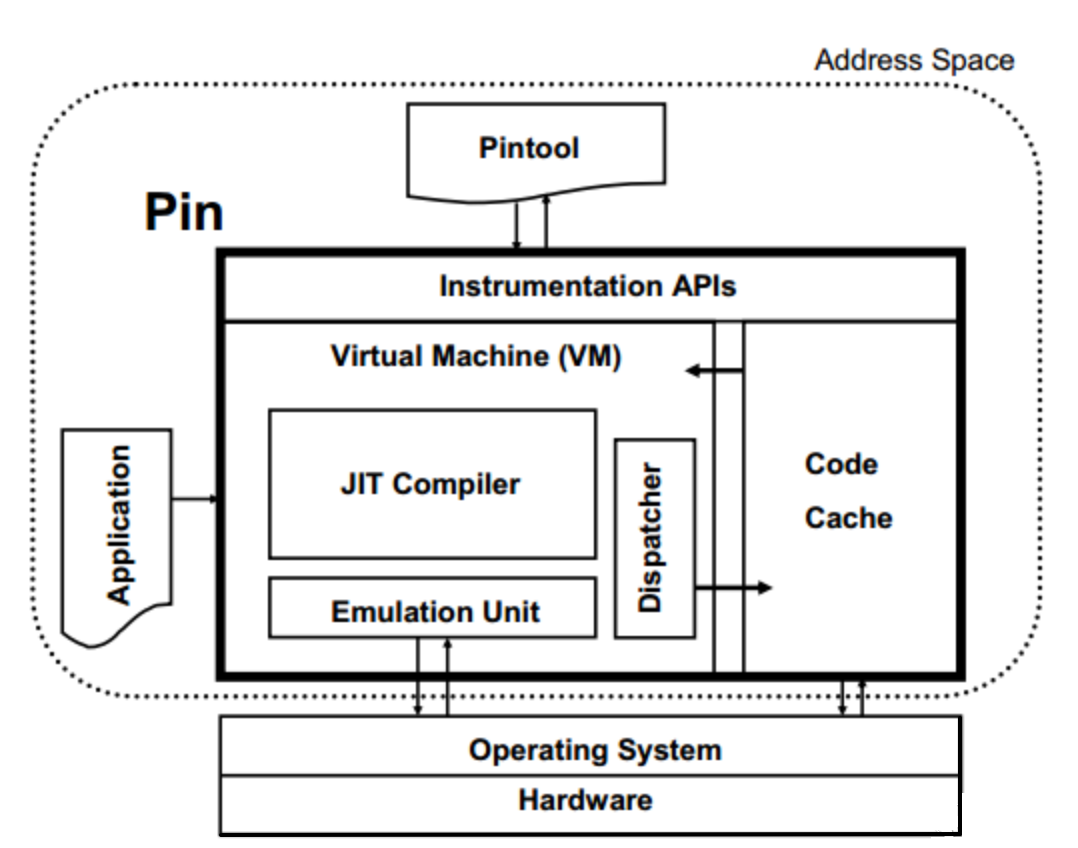
Pin机制类似Just-In-Time (JIT) 编译器,Trace插桩的基本流程(以动态基本块BBLs为分析单位):
通过一个例子来说明动态基本块BBLs与 汇编代码的BB的区别
switch(i)
{
case 4: total++;
case 3: total++;
case 2: total++;
case 1: total++;
case 0:
default: break;
}
上述代码会编译成下面的汇编, 对于实际执行时跳转从.L7进入的情况,BBLs包括四条指令,但是BB只会包括一条。
Pin会将cpuid, popf and REP prefixed 指令在执行break 成很多BBLs,导致执行的基本块比预想的要多。(主要原因是这些指令有隐式循环,所以Pin会将其拆分成多个BBLs)
kit from Intel websiteThis part is always needed by pintool, for example Zsim, Sniper.
When you meet the following situation, you should consider update your pin version even you can ignore this warning by use flags like -ifeellucky under high compatibility risk.
shaojiemike@snode6 ~/github/ramulator-pim/zsim-ramulator/pin [08:05:47]
> ./pin
E: 5.4 is not a supported linux release
because this will easily lead to the problem
PIN_Init之前调用PIN_InitSymbols。for (SEC sec = IMG_SecHead(img); SEC_Valid(sec); sec = SEC_Next(sec))
{
for (RTN rtn = SEC_RtnHead(sec); RTN_Valid(rtn); rtn = RTN_Next(rtn))
{
// Prepare for processing of RTN, an RTN is not broken up into BBLs,
// it is merely a sequence of INSs
RTN_Open(rtn);
for (INS ins = RTN_InsHead(rtn); INS_Valid(ins); ins = INS_Next(ins))
{
count++;
}
// to preserve space, release data associated with RTN after we have processed it
RTN_Close(rtn);
}
}
最重要的是
TRACE_AddInstrumentFunction Add a function used to instrument at trace granularityINS_AddInstrumentFunction() Add a function used to instrument at instruction granularityIMG_AddInstrumentFunction() Use this to register a call back to catch the loading of an imageINS_InsertPredicatedCall()// Forward pass over all instructions in bbl
for( INS ins= BBL_InsHead(bbl); INS_Valid(ins); ins = INS_Next(ins) )
// Forward pass over all instructions in routine
for( INS ins= RTN_InsHead(rtn); INS_Valid(ins); ins = INS_Next(ins) )
// Visit every basic block in the trace
for (BBL bbl = TRACE_BblHead(trace); BBL_Valid(bbl); bbl = BBL_Next(bbl))
{
// Insert a call to docount before every bbl, passing the number of instructions
BBL_InsertCall(bbl, IPOINT_BEFORE, (AFUNPTR)docount, IARG_UINT32, BBL_NumIns(bbl), IARG_END);
}
UINT32 memOperands = INS_MemoryOperandCount(ins);
// Iterate over each memory operand of the instruction.
for (UINT32 memOp = 0; memOp < memOperands; memOp++){
if (INS_MemoryOperandIsRead(ins, memOp)||INS_MemoryOperandIsWritten(ins, memOp)
//xxx
}
最重要的是
示例分析
// IPOINT_BEFORE 时运行的分析函数
VOID printip(VOID* ip) { fprintf(trace, "%p\n", ip); }
// Pin calls this function every time a new instruction is encountered
VOID InstructionFuc(INS ins, VOID* v)
{
// Insert a call to printip before every instruction, and pass it the IP
// IARG_INST_PTR:指令地址 一类的全局变量???
INS_InsertCall(ins, IPOINT_BEFORE, (AFUNPTR)printip, IARG_INST_PTR, IARG_END);
}
int main(int argc, char* argv[])
{
// Initialize pin
if (PIN_Init(argc, argv)) return Usage();
// 登记InstructionFuc为以指令粒度插桩时每条指令触发的函数
INS_AddInstrumentFunction(InstructionFuc, 0);
// 登记PrintFuc为程序结束时触发的函数
PIN_AddFiniFunction(PrintFuc, 0);
// 部署好触发机制后开始运行程序
PIN_StartProgram();
return 0;
}
目标:以样例插桩工具的源码为对象,熟悉pin的debug流程。
以官方教程为例子:
uname -a #intel64
cd source/tools/ManualExamples
# source/tools/Config/makefile.config list all make option
make all OPT=-O0 DEBUG=1 TARGET=intel64 |tee make.log|my_hl
# or just select one: make obj-intel64/inscount0.so
# $(OBJDIR)%$(PINTOOL_SUFFIX) - Default rule for building tools.
# Example: make obj-intel64/mytool.so
测试运行
下面介绍Pin 提供的debug工具:
首先创建所需的-g的stack-debugger.so和应用fibonacci.exe
其中OPT=-O0选项来自官方文档Using Fast Call Linkages小节,说明需要OPT=-O0选项来屏蔽makefile中的-fomit-frame-pointer选项,使得GDB能正常显示stack trace(函数堆栈?)
$ ../../../pin -appdebug -t obj-intel64/stack-debugger.so -- obj-intel64/fibonacci.exe 1000
Application stopped until continued from debugger.
Start GDB, then issue this command at the prompt:
target remote :33030
使用pin的-appdebug选项,在程序第一条指令前暂停,并启动debugger窗口。在另一个窗口里gdb通过pid连接:
$ gdb fibonacci #如果没指定应用obj-intel64/fibonacci.exe
(gdb) target remote :33030 #连接gdb端口
(gdb) file obj-intel64/fibonacci.exe #如果没指定应用, 需要指定程序来加载symbols
(gdb) b main #continue 等正常操作
能够在上一小节的debug窗口里,通过自定义debug指令打印自定义程序相关信息(比如当前stack使用大小)
Pintool “stack-debugger” 能够监控每条分配stack空间的指令,并当stack使用达到阈值时stop at a breakpoint。
这功能由两部分代码实现,一个是插桩代码,一个是分析代码。
static VOID Instruction(INS ins, VOID *)
{
if (!EnableInstrumentation) // ROI(Region of interest)开始插桩测量
return;
if (INS_RegWContain(ins, REG_STACK_PTR)) //判断指令是不是会改变stack指针(allocate stack)
{
IPOINT where = IPOINT_AFTER;
if (!INS_IsValidForIpointAfter(ins))
where = IPOINT_TAKEN_BRANCH; //寻找stack空间判断函数插入位置(指令执行完的位置)。如果不是after, 就是taken branch
INS_InsertIfCall(ins, where, (AFUNPTR)OnStackChangeIf, IARG_REG_VALUE, REG_STACK_PTR,
IARG_REG_VALUE, RegTinfo, IARG_END); // 插入OnStackChangeIf函数,如果OnStackChangeIf()返回non-zero, 执行下面的DoBreakpoint函数
INS_InsertThenCall(ins, where, (AFUNPTR)DoBreakpoint, IARG_CONST_CONTEXT, IARG_THREAD_ID, IARG_END);
}
}
所需的两个函数的分析代码如下:
static ADDRINT OnStackChangeIf(ADDRINT sp, ADDRINT addrInfo)
{
TINFO *tinfo = reinterpret_cast<TINFO *>(addrInfo);
// The stack pointer may go above the base slightly. (For example, the application's dynamic
// loader does this briefly during start-up.)
//
if (sp > tinfo->_stackBase)
return 0;
// Keep track of the maximum stack usage.
//
size_t size = tinfo->_stackBase - sp;
if (size > tinfo->_max)
tinfo->_max = size; //更新stack使用大小
// See if we need to trigger a breakpoint.
//
if (BreakOnNewMax && size > tinfo->_maxReported)
return 1;
if (BreakOnSize && size >= BreakOnSize)
return 1;
return 0;
}
static VOID DoBreakpoint(const CONTEXT *ctxt, THREADID tid)
{
TINFO *tinfo = reinterpret_cast<TINFO *>(PIN_GetContextReg(ctxt, RegTinfo));
// Keep track of the maximum reported stack usage for "stackbreak newmax".
//
size_t size = tinfo->_stackBase - PIN_GetContextReg(ctxt, REG_STACK_PTR);
if (size > tinfo->_maxReported)
tinfo->_maxReported = size;
ConnectDebugger(); // Ask the user to connect a debugger, if it is not already connected.
// Construct a string that the debugger will print when it stops. If a debugger is
// not connected, no breakpoint is triggered and execution resumes immediately.
//
tinfo->_os.str("");
tinfo->_os << "Thread " << std::dec << tid << " uses " << size << " bytes of stack.";
PIN_ApplicationBreakpoint(ctxt, tid, FALSE, tinfo->_os.str());
}
OnStackChangeIf函数监控当前的stack使用并判断是否到达阈值。DoBreakpoint函数连接debugger窗口,然后触发breakpoint,并打印相关信息。
也可以使用-appdebug_enable参数,取消在第一条指令前开启GDB窗口的功能,而是在触发如上代码的break时,才开启GDB窗口的连接。
而上述代码中的ConnectDebugger函数实现如下:
static void ConnectDebugger()
{
if (PIN_GetDebugStatus() != DEBUG_STATUS_UNCONNECTED) //判断是不是已有debugger连接
return;
DEBUG_CONNECTION_INFO info;
if (!PIN_GetDebugConnectionInfo(&info) || info._type != DEBUG_CONNECTION_TYPE_TCP_SERVER) //PIN_GetDebugConnectionInfo()获取GDB所需的tcp连接端口
return;
*Output << "Triggered stack-limit breakpoint.\n";
*Output << "Start GDB and enter this command:\n";
*Output << " target remote :" << std::dec << info._tcpServer._tcpPort << "\n";
*Output << std::flush;
if (PIN_WaitForDebuggerToConnect(1000*KnobTimeout.Value())) //等待其余GDB窗口的连接
return;
*Output << "No debugger attached after " << KnobTimeout.Value() << " seconds.\n";
*Output << "Resuming application without stopping.\n";
*Output << std::flush;
}
这部分讲述了如何debug Pintool中的问题。(对Pintool的原理也能更了解
为此,pin使用了-pause_tool n 暂停n秒等待gdb连接。
../../../pin -pause_tool 10 -t /staff/shaojiemike/github/sniper_PIMProf/pin_kit/source/tools/ManualExamples/obj-intel64/stack-debugger.so -- obj-intel64/fibonacci.exe 1000
Pausing for 10 seconds to attach to process with pid 3502000
To load the debug info to gdb use:
*****************************************************************
set sysroot /not/existing/dir
file
add-symbol-file /staff/shaojiemike/github/sniper_PIMProf/pin_kit/source/tools/ManualExamples/obj-intel64/stack-debugger.so 0x7f3105f24170 -s .data 0x7f31061288a0 -s .bss 0x7f3106129280
*****************************************************************
注意gdb对象既不是pin也不是stack-debugger.so,而是intel64/bin/pinbin。原因是intel64/bin/pinbin是pin执行时的核心程序,通过htop监控可以看出。
# shaojiemike @ snode6 in ~/github/sniper_PIMProf/pin_kit/source/tools/ManualExamples on git:dev x [19:57:26]
$ gdb ../../../intel64/bin/pinbin
(gdb) attach 3502000
这时GDB缺少了stack-debugger.so的调试信息,需要手动添加。这里的add-symbol-file命令是在pin启动时打印出来的,直接复制粘贴即可。
(gdb) add-symbol-file /staff/shaojiemike/github/sniper_PIMProf/pin_kit/source/tools/ManualExamples/obj-intel64/stack-debugger.so 0x7f3105f24170 -s .data 0x7f31061288a0 -s .bss 0x7f3106129280
(gdb) b main #或者 b stack-debugger.cpp:94
gef➤ info b
Num Type Disp Enb Address What
1 breakpoint keep y <MULTIPLE>
1.1 y 0x00000000000f4460 <main> # 无法访问的地址,需要去除
1.2 y 0x00007f3105f36b65 in main(int, char**) at stack-debugger.cpp:94
(gdb) del 1.1
(gdb) c
stack-debugger.so的调试信息,无法设置断点。暂无
暂无
导言
电脑玩家经常说RGB是最重要的,对于程序员来说,彩色的terminal有助于快速的分辨输出的有效信息。为此有一些有意思的彩色输出命令。
还有些必备的
a RUST fast version oftdlr
Tips: OpenSSL development headers
get a "failed to run custom build command for openssl-sys" error message. The package is calledlibssl-dev on Ubuntu.
部分支持中文,支持多平台
curl命令直接访问或者交互式awesome-shell里多看看。
set_tsj.sh
oh my zsh : hyq version
虽然这个ohmyzsh好用,但是我用惯了hyq的模板, 从github上下载后解压就安装了zsh模板。(之后可以考虑传到云盘或者cloudflare)
有时候hyq模版有些兼容性问题,比较老的zsh不支持(大约是5.0.2到5.5.1的版本)。这时候只能手动安装了,包括主题和插件。请看zsh一文。
zsh_history 支持多端口同步,实时保存
HISTFILE=~/.zsh_history
SAVEHIST=30000 # 最多 10000 条命令的历史记录
setopt APPEND_HISTORY # 退出 zsh 会话时,命令不会被覆盖式地写入到历史文件,而是追加到该文件的末尾
setopt INC_APPEND_HISTORY # 会话进行中也会将命令追加到历史文件中
setopt SHARE_HISTORY # 所有会话中输入的命令保存到一个共享的历史列表中
export HIST_SAVE_FREQ=10 # 每10次命令保存一次
ulimit -c unlimited
echo '$HOME/core-%e.%p.%h.%t' > /proc/sys/kernel/core_pattern
cd ~
大部分Linux 系统自带的 screen 命令来多终端控制
外部控制:
screen -S namescreen -r namescreen -lsscreen -X -S name kill内部控制:
CtrlA + d 分离CtrlA + x 终端上锁,CtrlA + k 是killCtrlA + S 上下分屏,CtrlA + | 左右分屏。screen -S name创建会话后,需要在新窗口中执行screen来创建额外的终端;这样分屏之后才有两个以上的终端可以使用。CtrlA + w 查看终端CtrlA + [数字] 切换到第几个CtrlA + Tab 返回上一个CtrlA + X 关闭分屏CtrlA + : 进入命令模式,输入resize -v 100或者resize -h 100调整大小。## Install
cd
git clone https://github.com/gpakosz/.tmux.git
ln -s -f .tmux/.tmux.conf
cp .tmux/.tmux.conf.local .
# or
cd ~/resources
# wget https://gitee.com/shaojiemike/oh-my-tmux/repository/blazearchive/master.zip?Expires=1629202041&Signature=Iiolnv2jN6GZM0hBWY09QZAYYPizWCutAMAkhd%2Bwp%2Fo%3D
unzip oh-my-tmux-master.zip -d ~/
ln -s -f ~/oh-my-tmux-master/.tmux.conf ~/.tmux.conf
cp ~/oh-my-tmux-master/.tmux.conf.local ~/.tmux.conf.local
针对不同语言有许多可选插件
### Ubuntu install emacs27
#### 问题:
dpkg-deb: error: paste subprocess was killed by signal (Broken pipe)
Errors were encountered while processing:
/var/cache/apt/archives/emacs27-common_27.1~1.git86d8d76aa3-kk2+20.04_all.deb
E: Sub-process /usr/bin/dpkg returned an error code (1)
版本解决,强制安装 sudo apt-get -o Dpkg::Options::="--force-overwrite" install emacs27-common
### install doom
中文教程 https://www.bilibili.com/read/cv11371146
Install LUA
curl -R -O http://www.lua.org/ftp/lua-5.4.4.tar.gz
tar zxf lua-5.4.4.tar.gz
cd lua-5.4.4
make all test
sudo make install # usr/bin
Install
cd ~/github
git clone https://github.com/skywind3000/z.lua.git
# vim ~/.zshrc
alias zz='z -c' # 严格匹配当前路径的子路径
alias zi='z -i' # 使用交互式选择模式
alias zf='z -I' # 使用 fzf 对多个结果进行选择
alias zb='z -b' # 快速回到父目录
#eval "$(lua /path/to/z.lua --init zsh)" # ZSH 初始化
eval "$(lua ~/github/z.lua/z.lua --init zsh)"
常用命令
# 弹出栈顶 (cd 到上一次的老路径),和 "z -0" 相同
$ z -
# 显示当前的 dir stack
$ z --
# 交互式
z -i foo # 进入交互式选择模式,让你自己挑选去哪里(多个结果的话)
z -I foo # 进入交互式选择模式,但是使用 fzf 来选择
# 匹配
z foo$
z foo # 跳转到包含 foo 并且权重(Frecent)最高的路径
z foo bar # 跳转到同时包含 foo 和 bar 并且权重最高的路径
z -r foo # 跳转到包含 foo 并且访问次数最高的路径
z -t foo # 跳转到包含 foo 并且最近访问过的路径
z -l foo # 不跳转,只是列出所有匹配 foo 的路径
z -c foo # 跳转到包含 foo 并且是当前路径的子路径的权重最高的路径
z -e foo # 不跳转,只是打印出匹配 foo 并且权重最高的路径
z -i foo # 进入交互式选择模式,让你自己挑选去哪里(多个结果的话)
z -I foo # 进入交互式选择模式,但是使用 fzf 来选择
z -b foo # 跳转到父目录中名称以 foo 开头的那一级
缺点:
rg (Fast & Good multi-platform compatibility) > ag > ack(ack-grep) 🔥
# ripgrep(rg) 但是readme说这样有bugs
sudo apt-get install ripgrep
# 可执行文件 (推荐)
wget https://github.com/BurntSushi/ripgrep/releases/download/13.0.0/ripgrep-13.0.0-x86_64-unknown-linux-musl.tar.gz
tar -zxvf ripgrep-13.0.0-x86_64-unknown-linux-musl.tar.gz
mv ./ripgrep-13.0.0-x86_64-unknown-linux-musl/rg ~/.local/bin
repgrep(rg) 常用选项
--no-ignore 忽略.gitignore之类的文件,也搜索忽略的文件。(默认是不搜索的)-t txt 指定搜索类型rg 'content' ABC/*.cpp搜索和正则ABC/*.cpp匹配的文件find . -name "*xxx*"
# ubuntu
sudo apt install fzf
# GIT install
git clone --depth 1 https://github.com/junegunn/fzf.git ~/.fzf
~/.fzf/install
source ~/.zshrc
# Vim-plugin
Plug 'junegunn/fzf', { 'do': { -> fzf#install() } }
# 使用
fzf --preview 'less {}'
# 安装了bat
fzf --preview "batcat --style=numbers --color=always --line-range :500 {}"
https://github.com/extrawurst/gitui/releases
lazydocker
bash脚本输出颜色文本示例
RED='\033[0;31m'
NC='\033[0m'
# No Color
printf "I ${RED}love${NC} Stack Overflow\n"
echo -e "\033[5;36m Orz 旧容器(镜像)已清理\033[0m"
颜色编号如下
| 颜色 | 编号 |
|---|---|
| Black | 0;30 |
| Dark Gray | 1;30 |
| Red | 0;31 |
| Light Red | 1;31 |
| Green | 0;32 |
| Light Green | 1;32 |
| Brown/Orange | 0;33 |
| Yellow | 1;33 |
| Blue | 0;34 |
| Light Blue | 1;34 |
| Purple | 0;35 |
| Light Purple | 1;35 |
| Cyan | 0;36 |
| Blue | 0;37 |
| Light Cyan | 1;36 |
| Light Gray | 0;37 |
| White | 1;37 |
通过regular expressions自定义高亮各种log文件
install需要 lex
颜色支持(3浅中深 * 6颜色 * 背景色反转)
# 前面 123 是深浅 , 4是下划线
# 字母大写是背景色反转
-r : red -g : green -y : yellow -b : blue -m : magenta -c : cyan -w : white
正则标记log关键词
绿色和红色
-e : extended regular expressions
-i : ignore case
hl -ei -g '(start(|ing|ed))' -r '(stop(|ping|ped))'
## ip 匹配
curl --trace-ascii - www.baidu.com|hl -ei -1R '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}'
命令配置文件 hl_ha.cfg
默认设置
export HL_CONF=/staff/shaojiemike/github/hl/config_files
echo $HL_CONF │/staff/shaojiemike/github/hl/config_files
-%c : specifies the beginning of a range colorized in color 'c'
-. : specifies the end of the previous range
Colorize hl configurations :
example Commands
lD # ls by date
lW # ls by week
ifconfig -a | hl --ifconfig
# ping tcpdump fdisk apt-get diff
# ip ibstat iptables passwd
errors
常用方式
在~/.zshrc 里如下配置:
export HL_CONF=/home/shaojiemike/github/hl/config_files
function my_hl(){ hl -eg '\$\{?[A-Z_]+\}?' -ec ' ([A-Z_-]+) ' -eic '(nothing|note)' -eiy ' (-([a-z_-]+))' -eiy '0x[0-9a-z]+' --errors -eig '(yes)' -eir '((^| )no($| ))|(none)|(not)|(null)|(please)|( id )' -ir error -ir wrong -ib '(line)|(file)' -eiy '(warn(|ing))|(wait)|(idle)|(skip)' -im return -ic '(checking)' -eiy ' (__(.*)__) ' -ei1W '((\w*/[.A-Za-z0-9_/-]*[A-Za-z0-9_/-]*)("|$)?)|((\w*/[.A-Za-z0-9_/-]*[A-Za-z0-9_/-]*)(")? ) ' -3B '[0-9][0-9.]+' -3B ' ([0-9])|(#[0-9]+)' -eig '(start(|ing))' -eir '(end(|ing))' }
alias ifconfig='ifconfig | hl --ifconfig'
alias ip='ip a|hl --ip '
alias df='df -h |hl --df'
alias ibstat='ibstat |hl --ibstat'
编译时如此使用make 2>&1|my_hl
http://127.0.0.1:19999/。想要WebUI运行 sudo netdata -i node5.acsalab.com
# install
curl -LO https://github.com/ClementTsang/bottom/releases/download/0.6.8/bottom_0.6.8_amd64.deb
sudo dpkg -i bottom_0.6.8_amd64.deb
# 使用
btm
类似s-tui可以观察CPU 温度,频率
bmon是类 Unix 系统中一个基于文本,简单但非常强大的网络监视和调试工具
Compile yourself
Install libconfuse
sh wget https://github.com/martinh/libconfuse/releases/download/v2.8/confuse-2.8.zip unzip confuse-2.8.zip && cd confuse-2.8 PATH=/usr/local/opt/gettext/bin:$PATH ./configure make make install Install bmon
sh git clone https://github.com/tgraf/bmon.git cd bmon ./autogen.sh ./configure make make install bmon
https://github.com/jarun/nnn#quickstart
很复杂,插件和快捷键超级多
sh # 版本很低 3.0 sudo apt-get install nnn # Q 退出
https://github.com/ranger/ranger
https://github.com/sayanarijit/xplr
sh cargo install --locked --force xplr
概要
C++ 基础知识和语法,包括C++11,C++17,C++23的各种语言支持。
C++编程语言历史 和 设计思路
支持范式模板编程 (generic programming)
支持面向对象编程 (object-oriented programming) 的拓展
平台依赖性:C++代码在不同的平台上需要重新编译,因为它直接与底层系统交互。Java代码是平台无关的,一次编译的字节码可以在任何支持Java虚拟机的平台上运行。
C++更适合系统级编程、游戏开发等需要更高的性能和底层控制的场景。
The default program entry function is main, but can be changed in two situations:
#define xxx main in header file to replace the name which maybe ignored by silly search bar in VSCODE.-exxx compile flag;)取决于上下文。C++ 语法的基本规则是:分号用来标识一条语句的结束,而有些结构并不是严格的语句,因此不需要分号。
声明(变量、类、结构体、枚举、函数原型、类型别名):都需要分号作为结束。
if, while, for)、复合语句({}) 不需要分号。#define, #include):不需要分号,因为它们不是 C++ 语法层面的内容。} 不需要分号,但声明类或结构体时 } 后要加分号。为什么类/结构体需要分号
C++ 中的类和结构体定义实际上是一种声明,它们的定义是一种复杂的声明语句,因此必须用分号来结束它们。
总结来说,分号用来结束语句,包括声明、表达式和执行体等,但当你定义一个复合结构(如函数定义、控制语句)时,不需要分号来结束复合结构的定义。
int getKthAncestor(int node, int k) {
int node= getKthAncestor(saved[node],--k);
return node;
}
//为什么第二行的node会提前被修改为0,导致传入函数getKthAncestor的saved[node]的node值为0
//如下去掉int,也不会错。因为int node 会初始化node为0
int getKthAncestor(int node, int k) {
node= getKthAncestor(saved[node],--k);
return node;
}
根据C++的作用域规则,内层的局部变量会覆盖外层的同名变量。因此,在第二行的语句中,node引用的是函数参数中的node,而不是你想要的之前定义的node。
为了避免这个问题,你可以修改代码,避免重复定义变量名。例如,可以将第二行的变量名改为newNode或其他不同的名称,以避免与函数参数名冲突。
运算符性质:
https://en.cppreference.com/w/cpp/language/types
https://en.cppreference.com/w/cpp/types/integer
//返回与平台相关的数值类型的极值
std::numeric_limits<double>::max()
std::numeric_limits<int>::min()
#include<limits.h>
INT_MAX
FLT_MAX (or DBL_MAX )
-FLT_MAX (or -DBL_MAX )
extern
const
constexpr //C++11引入的关键字,用于编译时的常量与常量函数。
volatile //是指每次需要引用某个变量的数据时,都必须从内存原地址读取,而不是编译器优化后寄存器间接读取.(必须写回内存,为了多进程并发而设计的。)
inline
static 作⽤:控制变量的存储⽅式和作用范围(可⻅性)。
避免
C++17 以后 局部的const static变量的初始化不是代码运行到才初始化,而是和全局static变量一样,在程序开始执行时初始化。
在 C++ 中,如果你希望 static 变量可以在多个文件中访问,直接写在头文件中是 不正确的,因为每个包含该头文件的源文件都会生成自己的独立 static 变量,导致它们互相独立,无法共享状态。
正确的解决方案
encounteredAclops 声明为 extern 变量,并将其定义在一个 .cpp 文件中。头文件:globals.h
源文件:globals.cpp
在其他源文件中使用:
#include "globals.h"
void someFunction() {
if (!encounteredAclops) {
// Do something
encounteredAclops = true;
}
}
通过 extern,所有引用 encounteredAclops 的源文件都会共享同一个变量。
如果每个源文件都需要独立的 encounteredAclops,你可以将 static bool encounteredAclops = false; 放在各自的源文件中,而不需要放在头文件中。这是因为 static 的作用域仅限于当前编译单元。
每个源文件:
static bool encounteredAclops = false;
void someFunction() {
if (!encounteredAclops) {
// Do something
encounteredAclops = true;
}
}
encounteredAclops 作为一个类的静态成员变量来实现共享状态。头文件:AclopsManager.h
#ifndef ACLOPS_MANAGER_H
#define ACLOPS_MANAGER_H
class AclopsManager {
public:
static bool encounteredAclops;
};
#endif // ACLOPS_MANAGER_H
源文件:AclopsManager.cpp
在其他源文件中使用:
#include "AclopsManager.h"
void someFunction() {
if (!AclopsManager::encounteredAclops) {
// Do something
AclopsManager::encounteredAclops = true;
}
}
这种方式既可以共享变量,又能保持代码组织清晰。
结论
- 如果需要共享变量:使用 extern 或类的静态成员变量。
- 如果需要独立变量:将 static 声明放在各自的源文件中。
- 不要直接在头文件中定义 static bool encounteredAclops,否则会导致每个包含头文件的源文件都生成自己的副本,违背初衷。
int MyClass::staticVariable = 10;多线程场景,修饰局部变量,会导致多线程共用,建议使用thread_local来避免竞争
static 局部变量在第一次被访问时初始化,且初始化过程是线程不安全的。如果两个线程几乎同时首次访问这个变量,可能会导致初始化竞争,进而引发未定义行为。
static 修饰初始化命令,只会执行一次,无论是否多次经过
问题场景:
static auto thread_core_map = GetCpuAffinityMap(device_id); 即使程序多次调用函数经过这行,但是这行命令也只会执行第一次。但是如果我把static关键词去除,就正常执行多次了。
当在一行代码中使用了 static 关键字时,变量的初始化只会在它第一次被执行时进行,之后即使多次经过这行代码,初始化的代码块也不会被重复执行。
在例子中,thread_core_map 是一个静态局部变量,它在第一次经过时会调用 GetCpuAffinityMap(device_id) 函数并保存结果。在后续的函数调用中,即使再次经过这行代码,GetCpuAffinityMap(device_id) 不会被重新调用,因为 thread_core_map 已经被初始化过了。
去除 static 后,thread_core_map 会在每次经过这行代码时重新初始化,也就是每次都会调用 GetCpuAffinityMap(device_id)。
解决方法:
如果你需要这行代码每次执行时都重新调用 GetCpuAffinityMap(device_id),那么应该去掉 static 关键字,或根据不同条件进行显式地重新初始化静态变量。
比如,可以这样实现惰性初始化或重置的功能:
static auto thread_core_map = GetCpuAffinityMap(device_id);
// 根据条件重新初始化
if (/* 条件 */) {
thread_core_map = GetCpuAffinityMap(device_id);
}
这样你就可以在特定条件下让 thread_core_map 被重新赋值。
如果你对静态变量的初始化行为没有问题,但是希望特定场景下重新执行初始化函数,可以根据场景调整条件逻辑。
当const修饰基本数据类型时,可以将其放置在类型说明符的前面或后面,效果是一样的。const关键字用于声明一个常量,即其值在声明后不可修改。
当const关键字位于指针变量或引用变量的左侧时,它用于修饰指针所指向的变量,即指针指向的内容为常量。当const关键字位于指针变量或引用变量的右侧时,它用于修饰指针或引用本身,即指针或引用本身是常量。
修饰指针指向的变量, 它指向的值不能修改:
修饰指针本身 ,它不能再指向别的变量,但指向(变量)的值可以修改。:
const int *const p3; //指向整形常量 的 常量指针 。它既不能再指向别的常量,指向的值也不能修改。
在C++, explicit 是一个关键字,用于修饰单参数构造函数,用于禁止隐式类型转换。
当一个构造函数被声明为 explicit 时,它指示编译器在使用该构造函数进行类型转换时只能使用显式调用,而不允许隐式的类型转换发生。
通过使用 explicit 关键字,可以防止一些意外的类型转换,提高代码的清晰性和安全性。它通常用于防止不必要的类型转换,特别是在单参数构造函数可能引起歧义或产生意外结果的情况下。
#include_next 的作用是
在寻找头文件时的头文件搜索优先级里,去除该文件所在的当前目录,主要是为C++头文件的重名问题提供一种解决方案。b.cpp想使用
自己拓展修改的stdlib.h, 那么在代码的目录下创建stdlib.h,并在该文件里#include_next "stdlib.h" 防止递归引用。#define PI 3.14159,在代码中将PI替换为3.14159。# 是 字符串化操作符(Stringizing operator)在 C/C++ 宏中,# 是 字符串化操作符(Stringizing operator),它的作用是将宏参数转换为字符串文字(string literal)。
当在宏中使用 #key 时,key 被转换为一个字符串文字,即在代码中实际变为 "key"(包括引号)。如果不加 #,key 将直接作为标记被使用,不会转为字符串。
示例:
以下是一个宏的例子,演示了 # 的作用:
宏定义:
#define TO_STRING(x) #x
#define CONCAT_AND_PRINT(a, b) printf("Concatenation: %s\n", TO_STRING(a##b));
宏使用:
int main() {
int HelloWorld = 42;
// 使用字符串化操作
printf("%s\n", TO_STRING(HelloWorld)); // 输出: HelloWorld
// 使用标记粘贴操作和字符串化操作
CONCAT_AND_PRINT(Hello, World); // 输出: Concatenation: HelloWorld
}
宏展开与作用:
TO_STRING(HelloWorld)
宏 TO_STRING 将参数 HelloWorld 转换为字符串文字,展开为:
HelloWorld
CONCAT_AND_PRINT(Hello, World)
a##b 将 Hello 和 World 拼接成 HelloWorld。TO_STRING(a##b) 将拼接后的标识符 HelloWorld 转换为字符串 "HelloWorld"。
展开为:Concatenation: HelloWorld## 是 C/C++ 宏预处理器的 标记粘贴操作符(Token-pasting operator)用于将宏参数和宏内的其他标记连接起来。具体来说,##Value 和 ##Initialized 这两个标记会与宏参数(如 valueName)进行拼接,形成新的标识符。
#define REGISTER_OPTION_CACHE(type, valueName, ...) \
static thread_local type valueName##Value; \
static thread_local bool valueName##Initialized = false; \
inline type GetWithCache##valueName() { \
if (!valueName##Initialized) { \
valueName##Value = __VA_ARGS__(); \
valueName##Initialized = true; \
} \
return valueName##Value; \
} \
inline void SetWithCache##valueName(type value) { \
valueName##Value = value; \
valueName##Initialized = true; \
}
宏展开解释
假设你在代码中使用了如下调用:
这将会将宏中的 type 替换为 int,valueName 替换为 MyValue,并且 __VA_ARGS__ 代表了传递给宏的可变参数 42。
展开后的代码:
static thread_local int MyValueValue;
static thread_local bool MyValueInitialized = false;
inline int GetWithCacheMyValue() {
if (!MyValueInitialized) {
MyValueValue = 42; // 使用了 __VA_ARGS__
MyValueInitialized = true;
}
return MyValueValue;
}
inline void SetWithCacheMyValue(int value) {
MyValueValue = value;
MyValueInitialized = true;
}
关键点解释:
valueName##Value 被展开为 MyValueValue。## 操作符将宏参数 MyValue 与 Value 连接,形成新的标识符 MyValueValue。valueName##Initialized 被展开为 MyValueInitialized,同样是将宏参数 MyValue 与 Initialized 连接,形成新的标识符 MyValueInitialized。结果
MyValueValue 存储了缓存的值(在这个例子中是 42)。MyValueInitialized 是一个布尔值,用来标记缓存是否已经初始化。GetWithCacheMyValue() 函数首先检查 MyValueInitialized 是否为 true,如果没有被初始化,它会使用 42 来初始化缓存并设置标志。SetWithCacheMyValue(int value) 函数允许你更新缓存的值,并将 MyValueInitialized 设置为 true。const int MAX_VALUE = 100;,声明一个名为MAX_VALUE的常量。typedef int Age;,为int类型创建了一个别名Age。例如:inline int add(int a, int b) { return a + b; },声明了一个内联函数add。
define主要用于宏定义,const用于声明常量,typedef用于创建类型别名,inline用于内联函数的声明。
为了避免同一个文件被include多次,C/C++中有两种方式,一种是#ifndef方式,一种是#pragma once方式。在能够支持这两种方式的编译器上,二者并没有太大的区别,但是两者仍然还是有一些细微的区别。
#include <iostream>
class MyClass {
public:
MyClass() {
std::cout << "Constructing MyClass" << std::endl;
}
~MyClass() {
std::cout << "Destructing MyClass" << std::endl;
}
};
int main() {
// 使用new动态分配内存,并调用构造函数
MyClass* obj = new MyClass();
// 执行一些操作...
// 使用delete释放内存,并调用析构函数
delete obj;
return 0;
}
namespace 会影响 typedef 的作用范围,但不会直接限制 #define 宏的作用范围。
A.h, B.h 都需要string.h的头文件,然后B.h 会include A.h,那么我在B.h里是不是可以省略include string.h
不应该省略,
include的位置有什么规则和规律吗,头文件和cpp文件前都可以吗?
在编写代码时,往往A.cpp需要include A.h。那A.cpp需要的头文件,我是写在A.cpp里还是A.h里?
//值传递
change1(n);
void change1(int n){
n++;
}
//引用传递,操作地址就是实参地址 ,只是相当于实参的一个别名,在符号表里对应是同一个地址。对它的操作就是对实参的操作
change2(n);
void change2(int &n){
n++;
}
//特殊对vector
void change2(vector<int> &n)
//特殊对数组
void change2(int (&n)[1000])
//指针传递,其实是地址的值传递
change3(&n);
void change3(int *n){
*n=*n+1;
}
引用传递和指针传递的区别:
指针传递和引用传递的使用情景:
闭包(Closure)是指在程序中,函数可以捕捉并记住其作用域(环境)中的变量,即使在函数执行完成后,这些变量依然保存在内存中,并能在后续的函数调用中被使用。闭包的一个重要特性是,它不仅保存了函数本身的逻辑,还“闭合”了函数执行时的上下文环境(即该函数所在的作用域)。
闭包通常用于实现函数内部的状态保持、回调函数等场景。在 C++ 中,闭包通过 lambda 表达式 实现,lambda 表达式可以捕获外部变量并在其内部使用。
例子
auto add = [](int x) {
return [x](int y) {
return x + y;
};
};
auto add5 = add(5);
std::cout << add5(3); // 输出 8
add 函数返回了一个闭包,捕获了变量 x 的值。即使 x 在原作用域中不再可用,返回的闭包仍然可以访问并使用 x 的值。
匿名函数(lambda)和闭包的关系就如同类和类对象的关系
匿名函数和类的定义都只存在于源码(代码段)中,而闭包和类对象则是在运行时占用内存空间的实体;
虽然理论上可以通过类似void f(bool x = true)来实现默认值。
导致实际编码如下:

假设我们有一个模板类 Wrapper,我们希望禁止 VirtualGuardImpl 类型作为模板参数:
template <
typename T,
typename U = T,
typename = typename std::enable_if<!std::is_same<U, VirtualGuardImpl>::value>::type>
class Wrapper {
public:
void function() {
// 实现
}
};
在这个例子中,如果用户尝试创建 Wrapper<VirtualGuardImpl> 或 Wrapper<VirtualGuardImpl, VirtualGuardImpl> 的实例,编译器将报错,因为 std::enable_if 的条件不满足。但如果使用其他类型,比如 int 或自定义类型,就可以正常编译。
这段代码是 C++ 中的一个模板函数或模板类模板参数的定义,它使用了模板默认参数、std::enable_if 条件编译技术以及类型萃取(type traits)。下面是对这段代码的详细解释:
模板参数 U:
typename U = T 定义了一个模板类型参数 U,并给它一个默认值 T。这意味着如果在使用模板时没有指定 U 的话,它将默认使用模板参数 T 的值。std::enable_if:
std::enable_if 是一个条件编译技术,它只在给定的布尔表达式为 true 时启用某个模板。std::enable_if 后面的布尔表达式是 !std::is_same<U, VirtualGuardImpl>::value。这意味着只有当 U 不等于 VirtualGuardImpl 类型时,这个模板参数才有效。typename 关键字:
typename 关键字用于告诉编译器 std::enable_if 的结果是一个类型。std::enable_if 返回的是一个类型,如果条件为 true,它返回一个空的类型,否则会导致编译错误。std::is_same:
std::is_same<U, VirtualGuardImpl>::value 是一个编译时检查,用于判断 U 和 VirtualGuardImpl 是否是相同的类型。::value 是类型特征 std::is_same 的一个成员,它是一个布尔值,如果类型相同则为 true,否则为 false。组合解释:
U,默认值为 T,并且这个模板参数只有在 U 不是 VirtualGuardImpl 类型时才有效。#include <stdarg.h>
void Error(const char* format, ...)
{
va_list argptr;
va_start(argptr, format);
vfprintf(stderr, format, argptr);
va_end(argptr);
}
VA_LIST 是在C语言中解决变参问题的一组宏,变参问题是指参数的个数不定,可以是传入一个参数也可以是多个;可变参数中的每个参数的类型可以不同,也可以相同;可变参数的每个参数并没有实际的名称与之相对应,用起来是很灵活。
系统提供了vprintf系列格式化字符串的函数,用于编程人员封装自己的I/O函数。
int vprintf / vscanf (const char * format, va_list ap); // 从标准输入/输出格式化字符串
int vfprintf / vfsacanf (FILE * stream, const char * format, va_list ap); // 从文件流
int vsprintf / vsscanf (char * s, const char * format, va_list ap); // 从字符串
使用结构体
struct RowAndCol { int row;int col; };
RowAndCol r(string fn) {
/*...*/
RowAndCol result;
result.row = x;
result.col = y;
return result;
}
在 C++ 中,左值(lvalue) 和 右值(rvalue) 是两个重要的概念,用来描述表达式的值和内存的关系。它们帮助开发者理解变量的生命周期、赋值和对象管理,特别是在现代 C++ 中引入了右值引用后,优化了移动语义和资源管理。
左值(lvalue,locatable value) 是指在内存中有明确地址、可持久存在的对象,可以对其进行赋值操作。通俗地说,左值是能够取地址的值,可以出现在赋值操作符的左边。
特点:
& 运算符)。示例
在这个例子中,x 是一个左值,因为它表示了内存中的某个对象,并且可以通过赋值语句修改它的值。
右值(rvalue,readable value) 是没有明确地址、临时存在的对象,不能对其进行赋值操作。它们通常是字面值常量或表达式的结果。右值只能出现在赋值操作符的右边,表示一个临时对象或数据。
特点:
& 获取右值的地址)。示例
在这个例子中,10 和 y + 5 是右值,因为它们表示计算出的临时数据,并且不能直接对这些值进行赋值操作。
C++11 引入了 右值引用,即通过 && 符号表示。这使得右值也能通过引用进行操作,特别是在实现移动语义(move semantics)和避免不必要的拷贝时非常有用。右值引用允许我们通过右值管理资源,避免性能上的损失。
示例:右值引用与移动语义
#include <iostream>
#include <vector>
int main() {
std::vector<int> vec1 = {1, 2, 3};
std::vector<int> vec2 = std::move(vec1); // vec1 资源移动到 vec2
std::cout << "vec1 size: " << vec1.size() << std::endl;
std::cout << "vec2 size: " << vec2.size() << std::endl;
return 0;
}
在这个例子中,std::move 将 vec1 变为一个右值引用,使其内部的资源(如动态分配的内存)直接转移给 vec2,避免了拷贝。
通常,左值是表示持久存在的对象,可以通过取地址符 & 获取其地址,而右值是临时的、短暂存在的值,不能直接获取其地址。理解这两者对于编写高效的 C++ 代码和使用现代特性(如右值引用和移动语义)非常重要。
常见误区
x + y)通常是右值。&&)是 C++11 引入的新特性,用来优化资源管理和避免不必要的拷贝操作。在C++98/03中我们只能对普通数组和POD(plain old data,简单来说就是可以用memcpy复制的对象)类型可以使用列表初始化,如下:
在C++11中初始化列表被适用性被放大,可以作用于任何类型对象的初始化。如下:
X x1 = X{1,2};
X x2 = {1,2}; // 此处的'='可有可⽆
X x3{1,2};
X* p = new X{1,2};
//列表初始化也可以用在函数的返回值上
std::vector<int> func() {
return {};
}
聚合类型可以进行直接列表初始化
聚合类型包括
对于一个聚合类型,使用列表初始化相当于使用std::initializer_list对其中的相同类型T的每个元素分别赋值处理,类似下面示例代码;
struct CustomVec {
std::vector<int> data;
CustomVec(std::initializer_list<int> list) {
for (auto iter = list.begin(); iter != list.end(); ++iter) {
data.push_back(*iter);
}
}
};
⼩贺 C++ ⼋股⽂ PDF 的作者,电⼦书的内容整理于公众号「herongwei」
https://shaojiemike.notion.site/C-11-a94be53ca5a94d34b8c6972339e7538a