Overview of Compute system
“Those who cannot remember the past are condemned to repeat it.” —George Santayana, 1905
"Our technology,our machines,is part of our humanity.We created them to extend ourself,and that is what is unique about human beings. - Ray Kurzweil
Computation in brain and machines¶
Brain¶
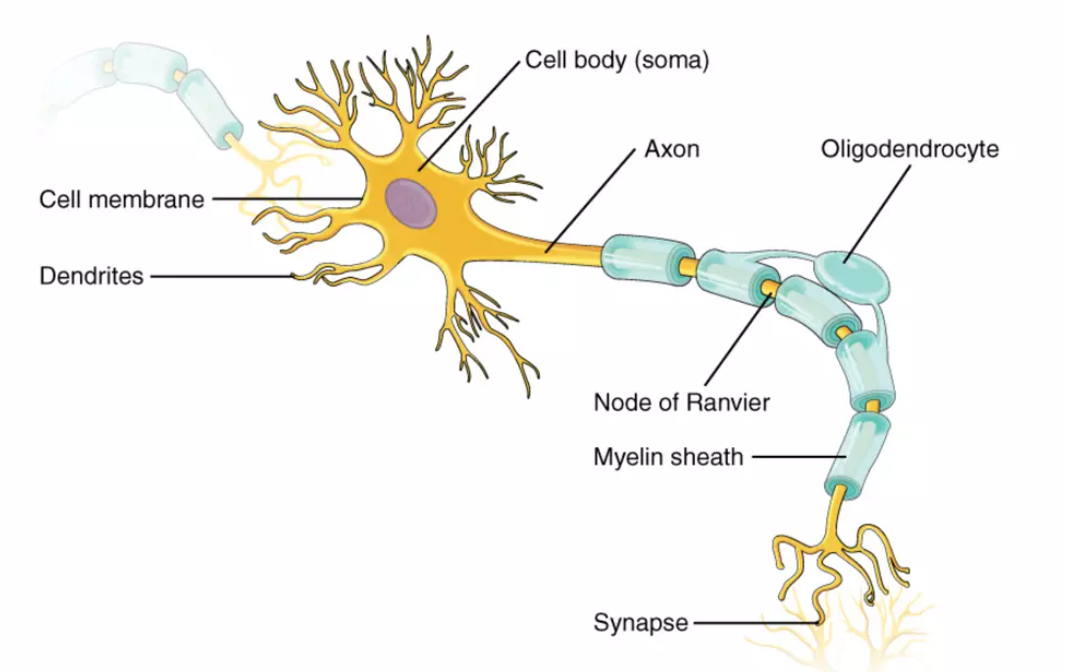
- 1.3kg, 占 2% 的人体总总量12
- \(10^{11}\) 神经元(neuron), \(10^{14}\) 突触连接(synapses)
- 操作频率 异步平均
10Hz, 不超过100Hz

Machine¶
- M1 Ultra的晶体管数量达到了1140亿个,等于\(1.14×10^{11}\)
- Kunpeng 920 是 200亿,等于\(2×10^{10}\)
- 操作频率 同步平均
3GHz
计算机系统¶
描述和评价一个计算机系统¶
全面描述和评价一个计算机系统,自顶向下可以从结果的角度考虑以下几个方面:
- 性能:计算机系统的性能是一个重要指标。可以评估其处理能力、内存和存储访问速度、网络传输速度等。关注系统的响应时间、吞吐量和并发处理能力等方面。
- 能源效率:计算机系统的能源效率是指其在能源消耗方面的表现。评估系统的功耗、能耗比、节能机制、休眠模式等。
- 可靠性:计算机系统的可靠性是指其正常运行的稳定性和可预测性。评估系统的故障率、容错能力、恢复能力和冗余设计等。
- 扩展性:计算机系统的扩展性是指其在面对不断增长的工作负载时能够有效地扩展。考察系统的可扩展性、可伸缩性和负载均衡能力。
- 安全性:计算机系统的安全性是指其对数据和资源的保护能力。评估系统的认证和授权机制、数据加密、防火墙、漏洞修复等安全措施。
- 可维护性:计算机系统的可维护性是指其易于管理和维护的程度。关注系统的模块化设计、可读性、可测试性、文档化程度等。
- 兼容性:计算机系统的兼容性是指其与其他系统和软件的互操作性。评估系统的标准遵循程度、协议支持、数据格式兼容等。
- 用户体验:计算机系统的用户体验是指其易用性和用户满意度。考虑系统的界面设计、交互方式、错误处理和反馈等。
计算机系统的抽象层次¶
ISA 是软硬件设计的分界线
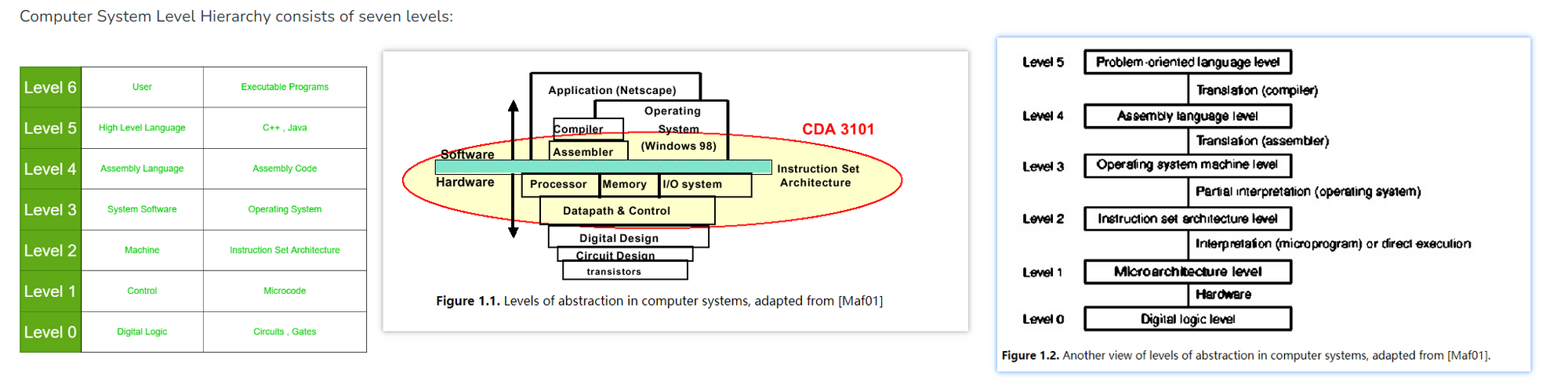
当从底向上分析和描述计算机系统时,以下是一些关键方面和层级可以考虑:
- 计算机硬件层级:
- 处理器架构:描述处理器的指令集、流水线设计、多核处理器等特性。
- 存储器子系统:包括内存层次结构、缓存设计、虚拟内存管理等。
- 输入/输出设备:涉及外设接口、驱动程序、数据传输和控制等。
- 操作系统层级:
- 内核设计:描述操作系统内核的架构、进程管理、调度算法、内存管理、文件系统等。
- 设备驱动程序:介绍操作系统对硬件设备的管理和控制。
- 文件系统:描述文件组织、存储和访问的方式。
- 网络层级:
- 网络协议栈:涉及传输层(如TCP/IP)、网络层(如IP)、链路层等协议和相关技术。
- 路由和交换:描述网络路由算法、交换机和路由器的设计和配置。
- 软件层级:
- 应用层:描述各种应用程序和服务,如Web应用、数据库管理系统、图像处理等。
- 软件开发框架和工具:涉及编程语言、开发工具、集成开发环境(IDE)等。
- 系统架构(多机系统):
- 分布式系统:描述多个计算机节点协同工作的体系结构、通信协议和数据一致性。
- 云计算架构:包括云服务模型(如IaaS、PaaS、SaaS)、云平台架构和资源管理等。
在分析和描述每个层级时,可以考虑架构设计的特点、优势和限制,以及与其他层级的交互和依赖关系。通过自底向上的分析,可以逐步理解计算机系统的构成和功能,揭示不同层级之间的关联和影响,从而全面理解和描述计算机系统。
计算机系统的一般/通用设计¶
wikichip: skylake
前后端的设计
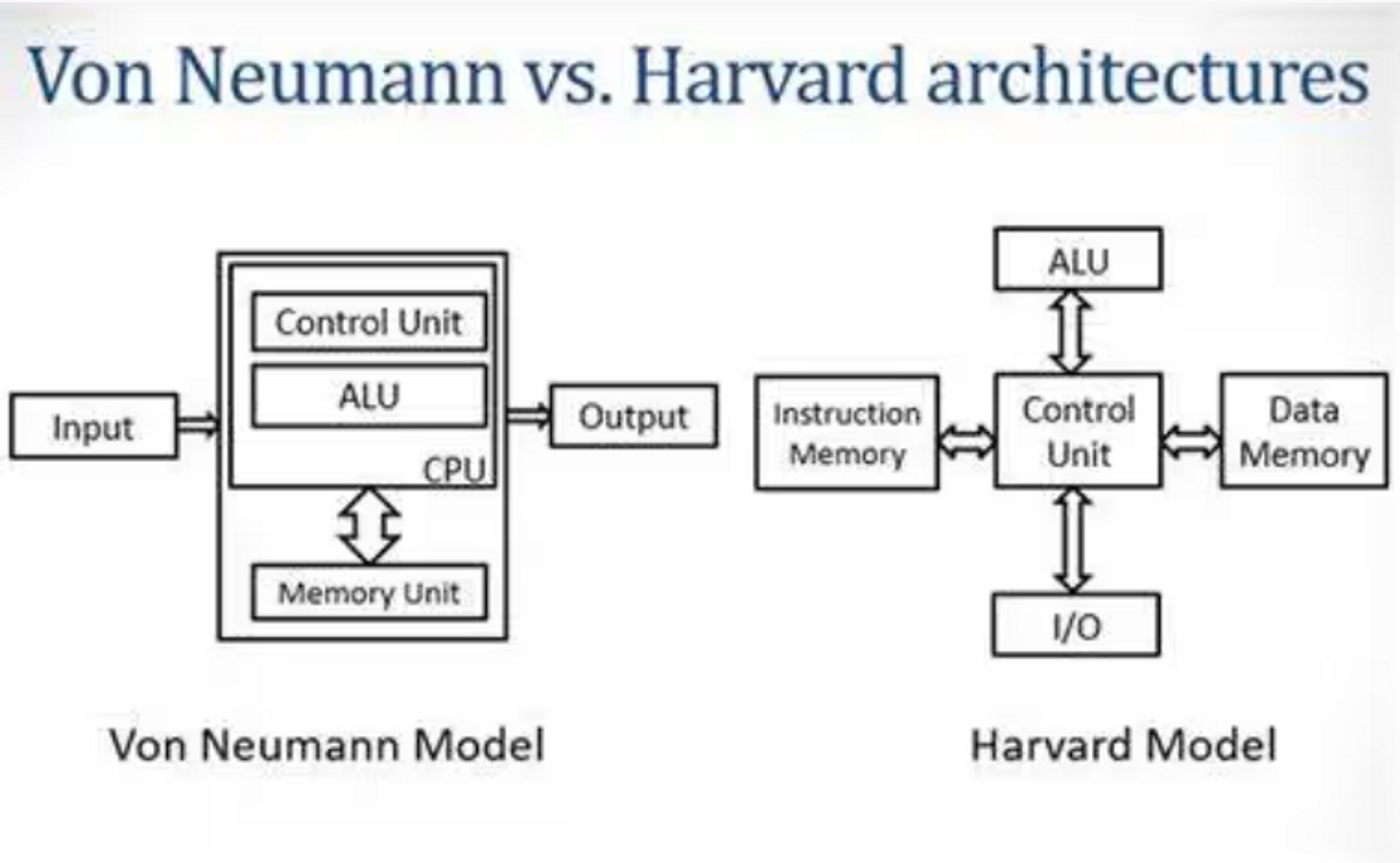
冯·诺依曼架构(Von Neumann Architecture)和哈佛架构(Harvard Architecture)关注计算机系统中指令和数据存储方式。
- 冯·诺依曼架构的抽象关注点主要在于指令的执行流程、存储器的管理和数据的传输。指令按照顺序从存储器中加载到CPU,CPU依次执行指令并将结果存回存储器。这种架构的优点是简单、通用,适用于各种通用计算任务。
- 哈佛架构的抽象关注点主要在于指令流和数据流的独立处理。指令和数据在各自的存储器中,CPU可以同时从指令存储器和数据存储器中提取信息,实现并行操作。这种架构的优点是高效的指令和数据访问,适用于嵌入式系统和信号处理等领域。
产业的需求¶
AI Models
发展趋势¶
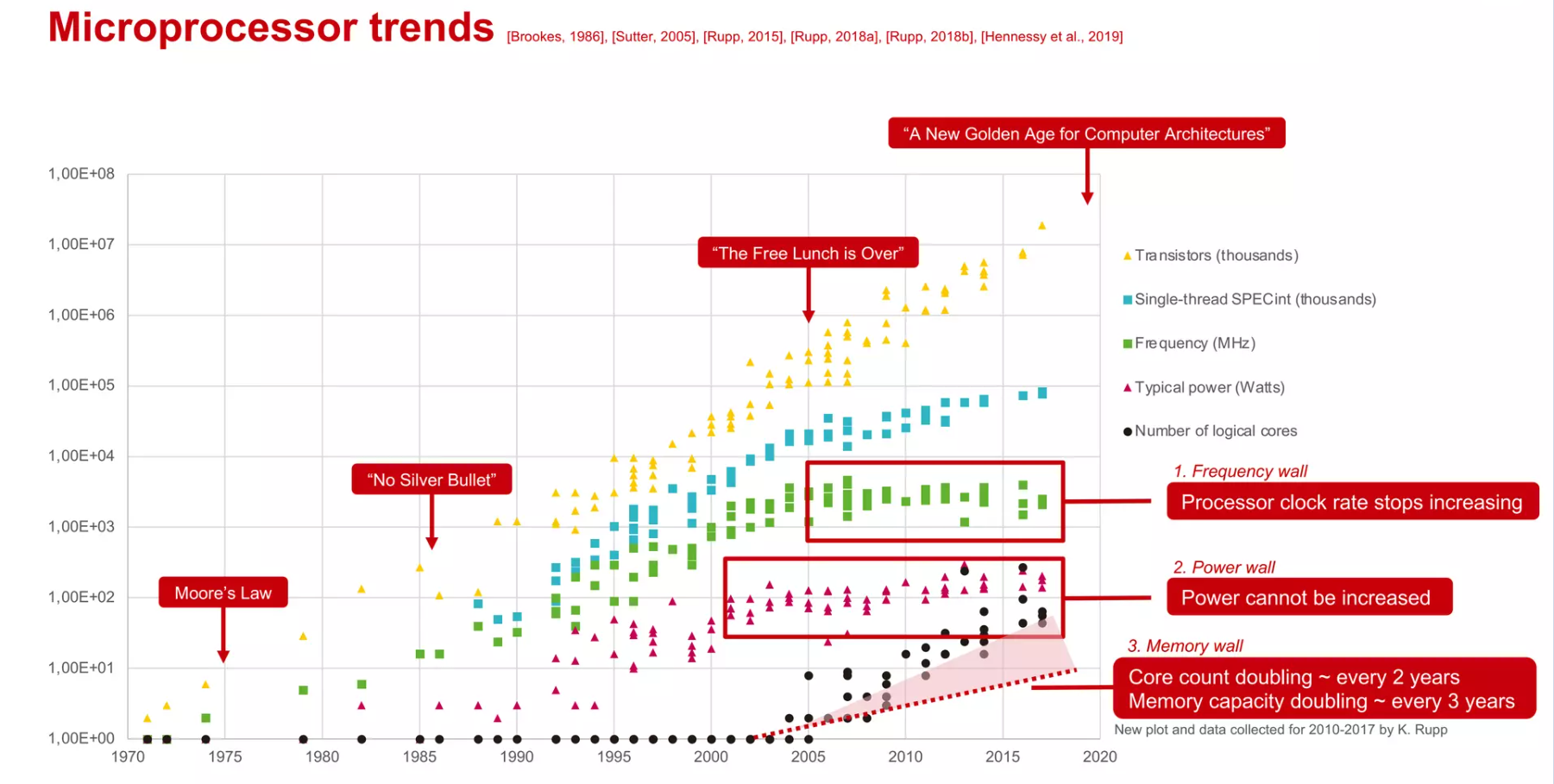
- No Silver Bullet — 这句话来自弗雷德·布鲁克斯的一篇论文,指出软件工程没有万能的解决方案(即“银弹”)能迅速和轻易地提升生产力和质量。
- The Free Lunch is Over — 这是赫伯特·萨特尔指出的一个概念,意味着仅依靠硬件的性能提升来推动软件性能的时代已经结束,软件开发者现在需要更多关注并行计算和代码优化来提升性能。
- A New Golden Age for Computer Architecures — 由于摩尔定律和丹纳德缩放结束所带来的计算机架构的新机遇,特定领域的语言和架构、开放指令集以及改进的安全性将引领这个新时代的到来。
摩尔定律的放缓和多核收益的衰弱¶
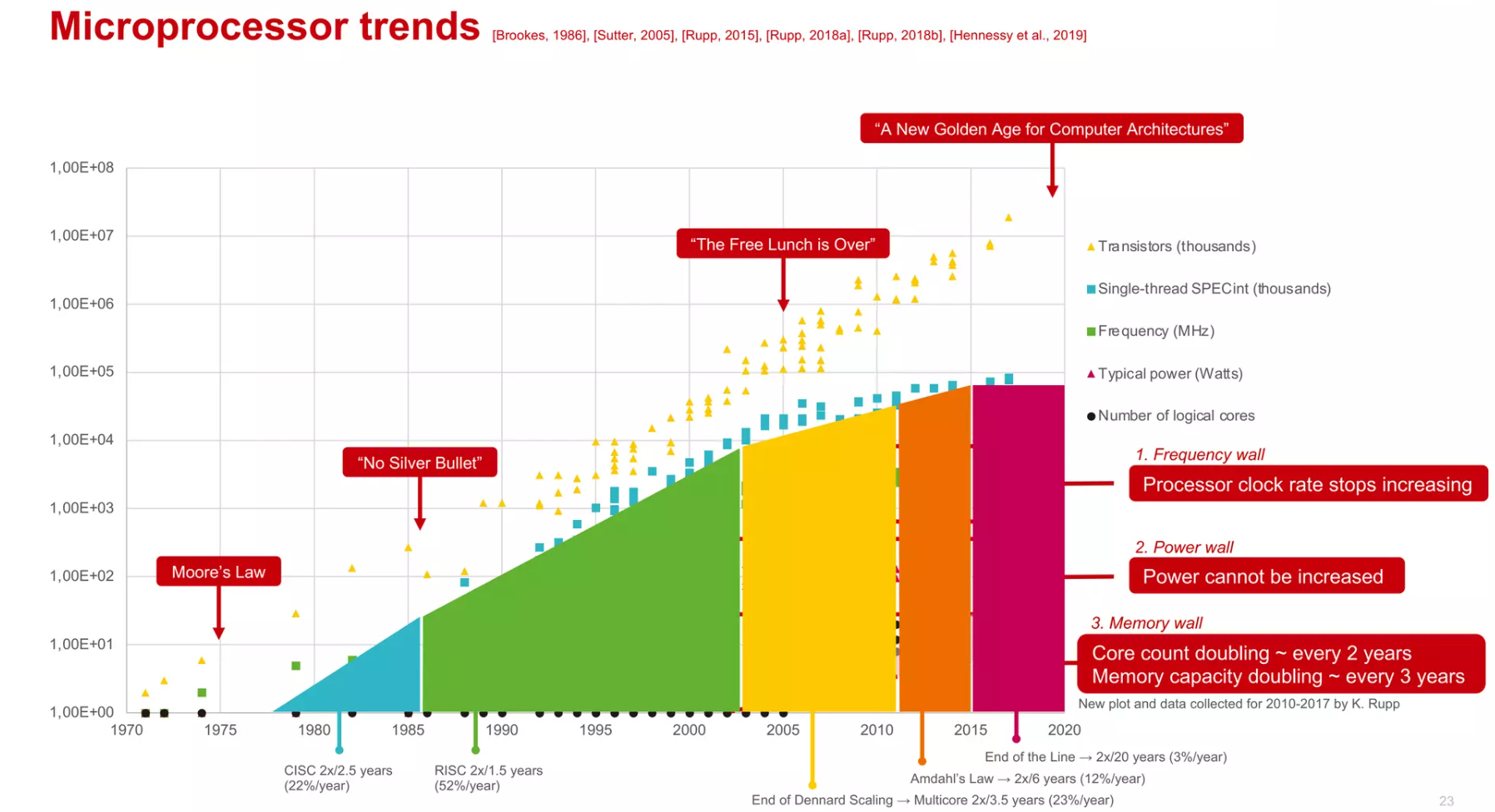
- 摩尔定律由Gordon Moore博士在1965年提出:“集成电路上可以容纳的晶体管数目在大约每经过18个月便会增加一倍,性能也提升一倍。时至今日,虽然晶体管的集成度还在提高,只是逐渐放缓,但是性能的提升却被物理规律所限制。一个处理器上的晶体管的数目越来越多,但是因为功耗和互连的限制,并不能直接提供很高的性能,即晶体管没有充分的利用起来。
- 丹纳德缩放(Dennard scaling),也称为动态缩放或者是电力、电压和尺寸的缩放,是1974年由罗伯特·丹纳德(Robert Dennard)和他的同事在IBM提出的。丹纳德缩放描述了一个观察到的现象:随着晶体管尺寸缩小,它们的功率密度保持不变。
- 解释:如果所有的尺寸维度都缩小一定比例,电压也降低相应的比例,那么频率可以增加而功耗保持不变。这意味着晶体管可以变得更小、更快且效率更高。
- 失效:然而,进入21世纪后,当晶体管尺寸缩小到接近原子层级时,丹纳德缩放原则不再适用,因为无法进一步降低电压而不影响晶体管的功能和可靠性。(也称为Post-Dennardian:随着工艺尺寸的缩小,chip的供电电压保持不变。)此外,量子效应和电力泄漏开始占主导地位,导致功率密度增加。因此,芯片设计者不得不寻找新的方法来继续提升计算性能,比如多核处理器(Interconnect也是问题)、异构计算和能效优化设计。
- Dark silicon,也叫“暗硅”。意思是说,由于功耗的限制,一个很高端的处理器,比如多核的,其实同一时刻只能有很少的一部分门电路能够工作,其余的大部分处于不工作的状态,这部分不工作的门电路,就叫做“暗硅”。
Post-Dennardian下爆炸的功耗密度
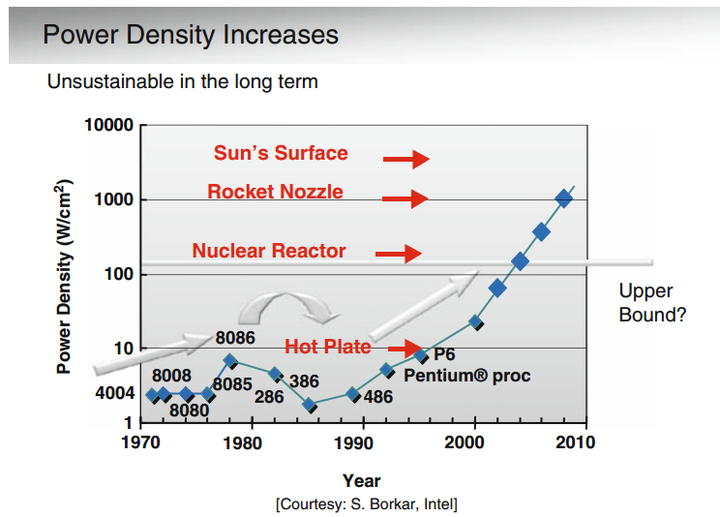 14
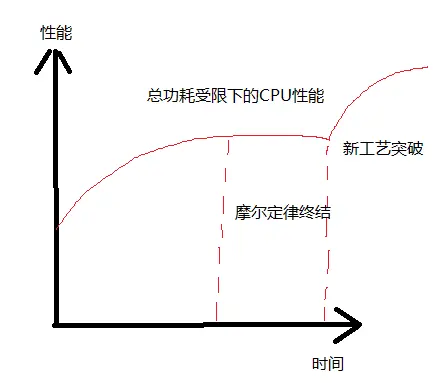
14- 芯片设计者不得不面对的事实是:芯片性能要稳定提高,但是功耗却不能更高。未来的CPU发展很有可能会是下图的情况,由于总功耗的限制,CPU的性能在有限范围内不断小幅升级,但是终至枯竭,急需新的封装工艺,加工工艺,电池工艺和材料物理的突破,再来一次革命。
Dark silicon 分析(非睿频)
对于一个65nm下的4核处理器,假如额定功耗允许其四个核心能够同时全速工作。当工艺尺寸缩小到32nm的时候,以前4核处理器的面积将能够容纳16个新的核(因为每个核的面积变得只有以前的1/4了),但是新工艺下的处理器仍然只能有4个核工作。13
假设两代工艺之间,缩放因子是S,S大于1(典型值是1.41)。那么:上图中S是64nm/32nm = 2。
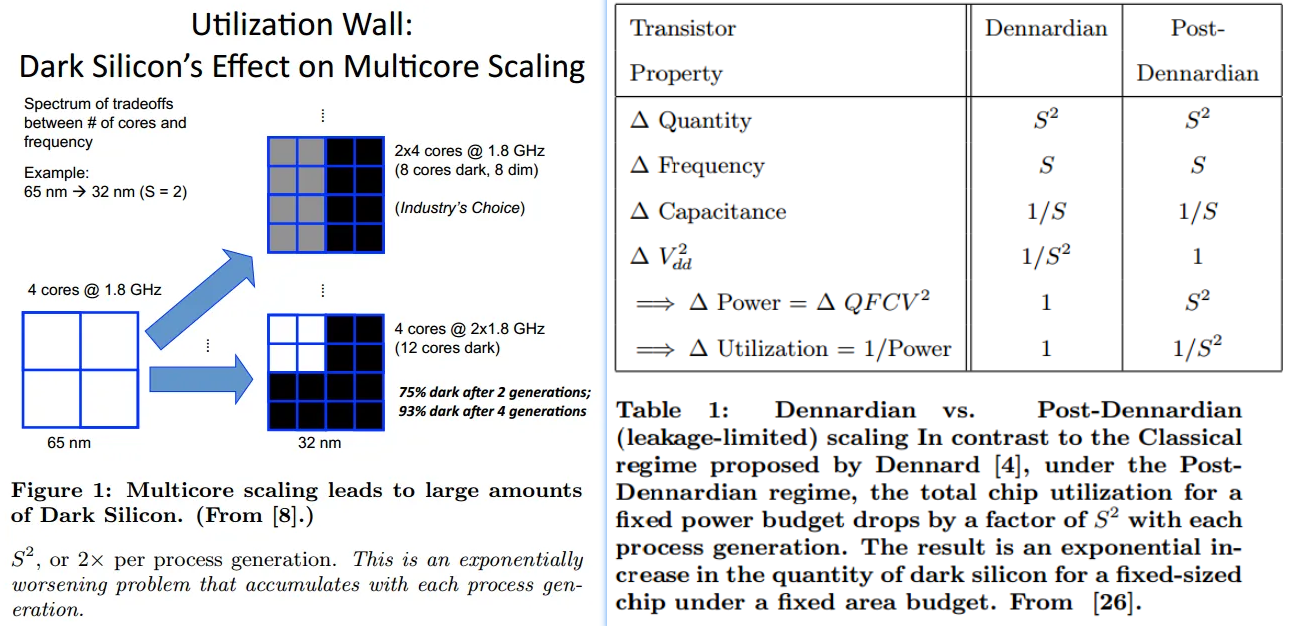
- 芯片的晶体管数量将乘以\(S^2\),变成4倍;
- 晶体管的切换频率(频率)可以乘以S,变成2倍;
-
因此计算能力峰值将乘以\(S^3\),变成8倍;
-
晶体管的电容将减小S,因为特征尺寸减小了,变成1/2;
- 总功耗将变成以前的\(S^2 \times S \times \frac{1}{S} = S^2\)倍(总功耗与晶体管数量和切换频率成正比,和电容成反比, Post-Dennardian电压不变),即4倍;
-
为了保持总功耗不变,芯片的利用率将只能变成以前的\(\frac{1}{S^2}\),即1/4;
-
所以对于上例,虽然总共有16个核,仍然只能有4个核可以工作。当然了,这4个核可以运行S倍的频率(2倍频),所以实际上整个chip的性能还是增加了2倍,尽管很遗憾整个chip中有12个核处于“暗硅”状态。
- 阿姆达尔定律(Amdahl's Law, 1967年)在并行计算中用来预测使用多个处理器与单个处理器相比理论上的最大性能提升。
- 如果一个程序有一部分代码无法并行化(比如,10%的代码必须串行执行),那么即使在无限多的处理器的理想情况下,最大的性能提升也只能是10倍,因为那10%的代码决定了整个程序的最小执行时间。
- 在实际应用中,由于不是所有的任务都能完全并行化,阿姆达尔定律表明性能提升存在一个明显的上限。所以,即使技术不断进步,处理器核心数量翻倍,我们也不能期望性能提升与处理器核心数量增加成正比。这就是文本中所说的“性能预计每6年才能翻一倍,相当于每年12%的提升”的含义。这反映出即使硬件的发展速度很快,实际的应用性能提升仍然受限于代码的可并行化程度。
- 牧本定律由1987年牧村次夫提出,半导体产品的发展历程总是在“标准化”和“定制化”之间交替摆动,大概每十年摆动一次,揭示了半导体产品性能功耗和开发效率之间的平衡,这对于处理器来说,就是专用结构和通用结构之间的平衡—专用结构性能功耗优先,通用结构开发效率优先。
- 贝尔定律是由戈登贝尔在1972年提出的一个观察,即每隔10年,会出现新一代计算机(新编程平台、新网络连接、新用户接口、新使用方式),形成新的产业,贝尔定律指明了未来一个新的发展趋势,这将会是一个处理器需求再度爆发的时代,不同的领域、不同行业对芯片需求会有所不同,比如集成不同的传感器、不同的加速器等等。
异构计算和Domain-Specific Architectures¶
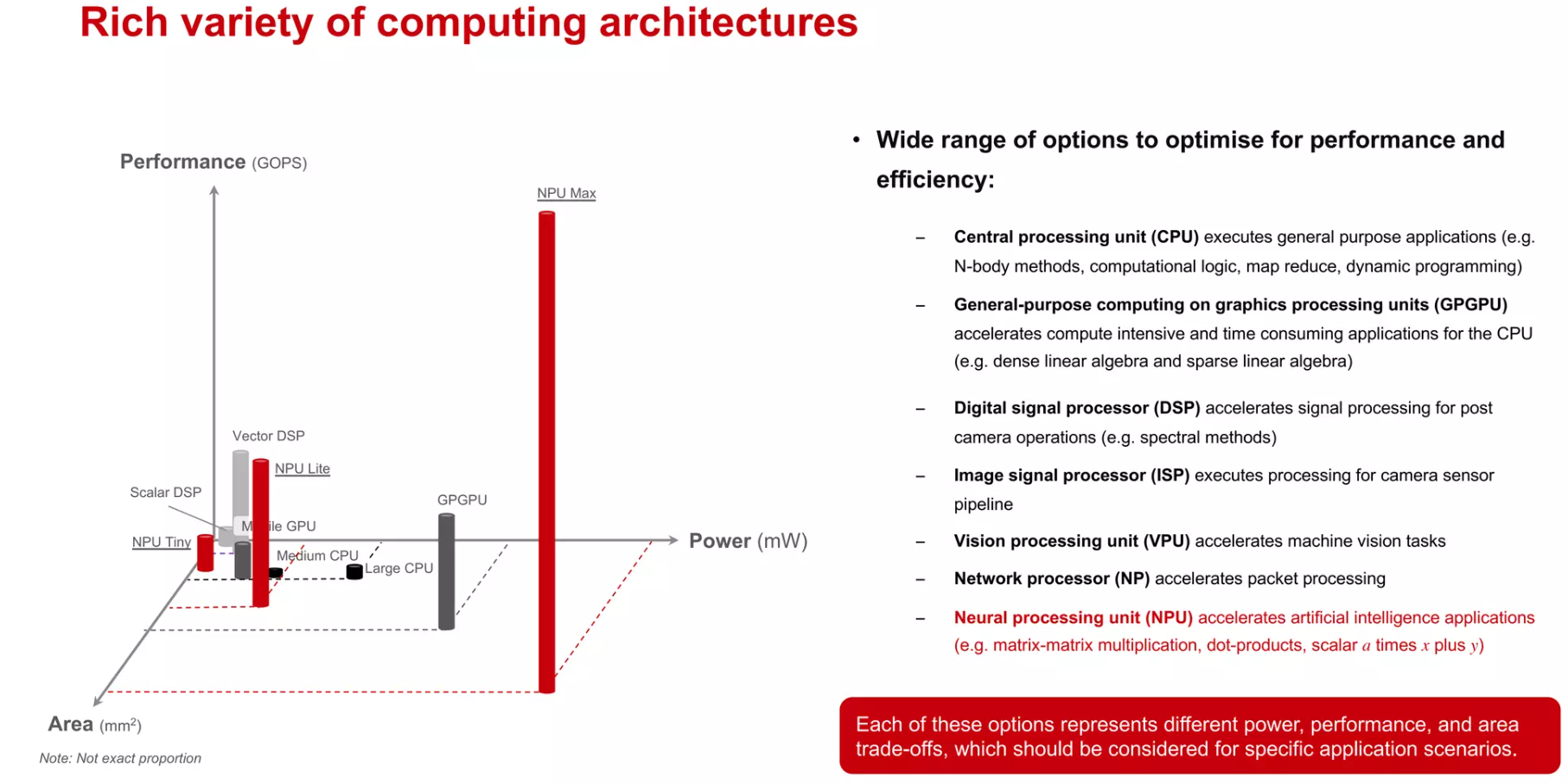
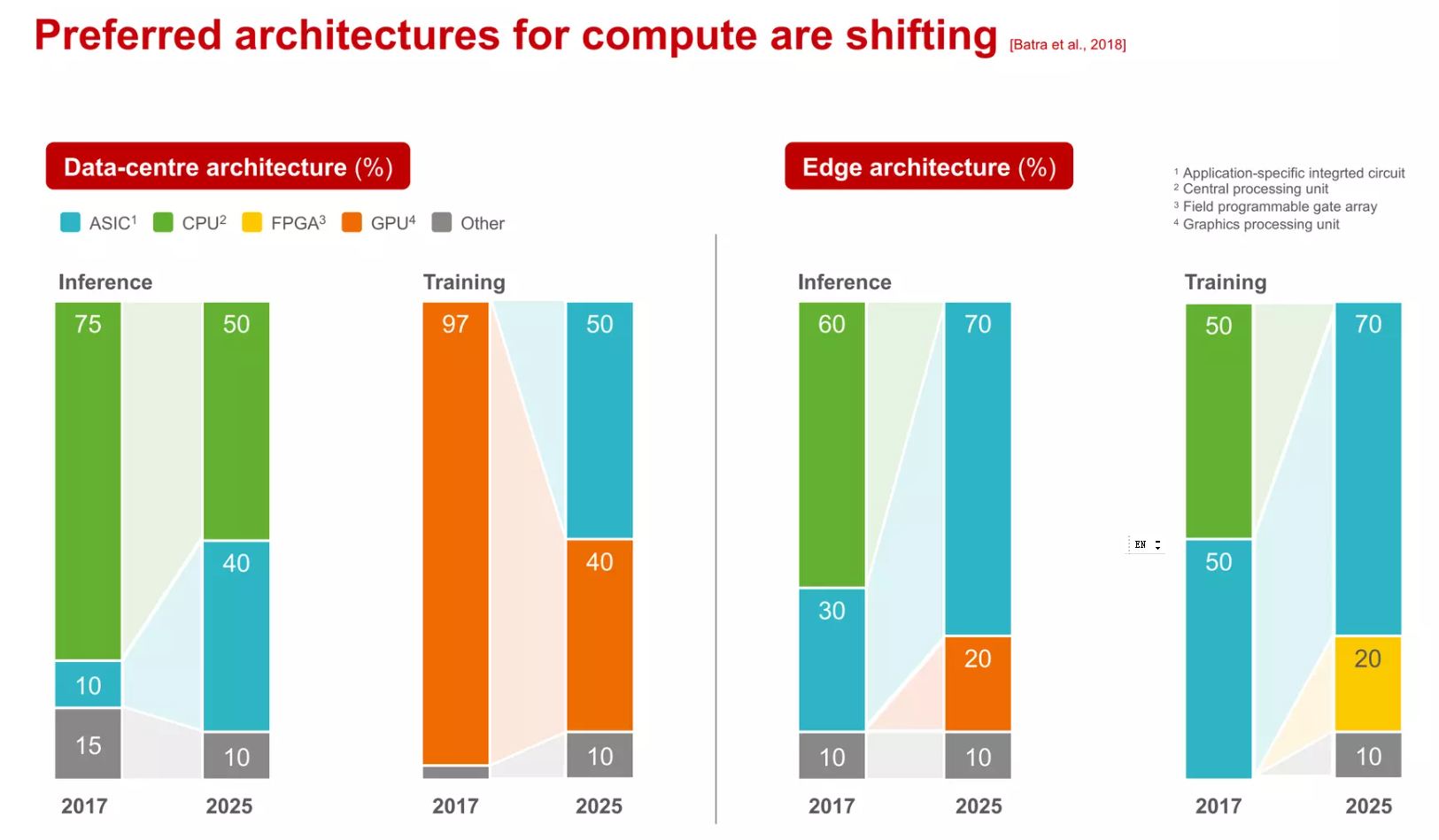
从寒武纪的“DIANNAO”到Google的TPU再到华为的达芬奇,AI芯片的设计呈现出百花齐放的场景。有单一针对卷积神经网络的ASIC加速器,有支持简单编程的通用型处理器;有的通过硬件可重构进行算法映射,有的通过VLIW指令支持高并发运算;有一个超大矩阵支持大规模AI运算,有通过众核进行任务切割运算;有的作为协处理器,有的可以独立运行。可以说计算机发展史中出现的各种架构在其中都有体现。
性能模型¶
Analytical model¶
- CPU
- Roofline模型
- ECM模型
- GPU
- Memory-level and Thread-level Parallelism Awareness6
Mechanistic Performance Model¶
A mechanistic model has the advantage of directly displaying the performance effects of individual, underlying mechanisms, expressed in terms of program characteristics and machine parameters, such as Instruction-Level Parallelism (ILP), misprediction rates, processor width, and pipeline depth.(1) 10
- Our proposed mechanistic model, in contrast, is built up from internal processor structure and does not need detailed processor simulation to fit or infer the model; however, we do use detailed simulation to demonstrate the accuracy of the model after it has been constructed.10
Interval analysis based on traced data
- CPU: Interval Model - Sniper - Zsim - llvm-mca
- GPU: GPUMech(MICRO14) MDM(MiCRO20) GCoM(ISCA22)
Detailed timing simulations¶
cycle-level simulation
- CPU: gem5
- GPU: GPUSim
RTL simulation¶
Others: machine learning performance model¶
Empirical and hybrid approaches typically lump together program characteristics and/or microarchitecture effects, often characterizing multiple effects with a single parameter.10
性能关键指标 - 处理器峰值计算能力¶
| Arch | Product | SP Scalar/core | DP Scalar/core | SP SIMD/core | DP SIMD/core | Total SP/chip | Total DP/chip |
|---|---|---|---|---|---|---|---|
| ARMv8 | Kunpeng 920 (Internally: Hi1620) | 7.9Gflops7 | 7.9Gflops | 31.9 Gflops | 7.9 Gflops | 1536 Gflops(48 cores) | 384 Gflops |
| X86 | Intel(R) Xeon(R) Platinum 8358 CPU @ 2.60GHz | 972.8 Gflops (32 cores)8 | |||||
| GPU | Nvidia H100 | 354.1 Gflops (per SM) | 180.5 Gflops | 51 Tflops (144 SM)9 | 26 Tflops | ||
| GPU | Nvidia H100 + Tensor Cores | 756 Tflops (144 SM)9 | 51 Tflops |
1 TFLOPS is equivalent to 1,000 GFLOPS
芯片设计 成本与收益的tradeoff¶
工艺的限制是设计的当前理论上限。各种现实的成本考虑进一步限制了设计。
芯片设计:功耗,良率,增大的边际效应
芯片性能确实受到其部件数量(如晶体管数量)、时钟频率和缓存大小的影响,但芯片设计和制造涉及到一系列复杂的权衡和限制,这就是为什么制造商不会无限制地增加芯片的大小、频率和缓存。主要的限制因素包括:
-
热设计功耗(TDP):随着芯片尺寸的增加或时钟频率的提高,芯片产生的热量也会增加。处理这些额外热量需要更复杂的冷却系统。此外,高温可能导致硬件损坏或性能下降。因此,制造商必须在性能和可实现的热管理之间找到平衡。
-
功耗和能效:增加晶体管数量、缓存大小和时钟频率会导致功耗增加。这不仅影响能效,还会增加电力成本,并可能超过现有系统的电源供应能力。在移动设备和便携式电脑中,这一点尤其重要,因为它直接影响电池寿命。
-
制造复杂性和成本:更大的芯片或更高密度的晶体管布局会增加制造复杂性,从而增加生产成本。此外,更大的芯片会降低晶圆上每个芯片的产量,进一步提高成本。
-
芯片产量和良率:随着芯片尺寸的增加,产生瑕疵的概率也会增加,从而影响良品率。低良品率会显著增加每个有效芯片的成本。
-
时钟频率的限制:提高时钟频率会增加信号传播延迟和电磁干扰,这可能导致数据损坏或处理错误。此外,由于电子元件间的传播延迟,存在一个物理极限,超过这个极限,提高频率不再提升性能。
-
缓存的权衡:虽然增加缓存可以提高性能,但它也会增加芯片的尺寸、功耗和成本。此外,过大的缓存可能导致边际效益递减,即超过一定大小后,每增加一点缓存所带来的性能提升会越来越少。
-
市场需求和应用场景:最后,芯片设计还受到市场需求和特定应用场景的影响。例如,高性能服务器芯片和用于移动设备的芯片会有非常不同的设计考虑。
因此,芯片制造商在设计时必须在性能、成本、能效、热管理和市场需求之间进行平衡。这就是为什么我们看到不同类型的芯片针对不同的应用和市场需求而有不同的设计。
性能关键指标 - 访存与互联速度¶
建议研究 https://www.francisz.cn/2022/05/12/lmbench/
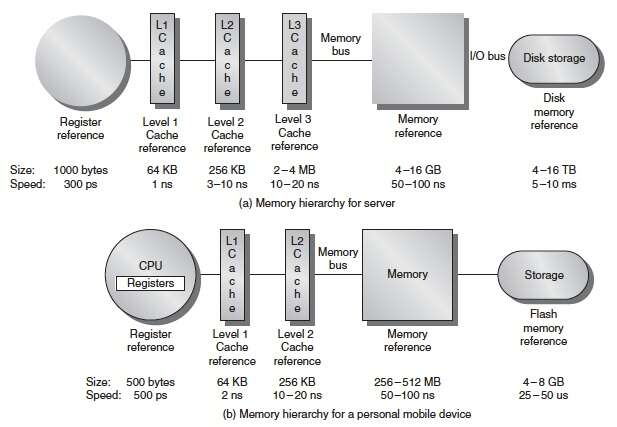
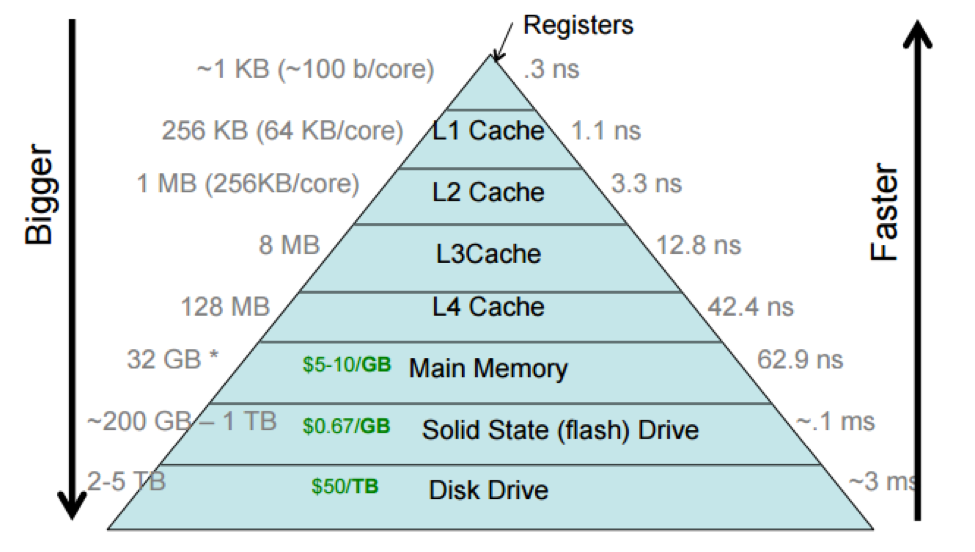
Memory hierarchy Latency / Size¶
| Type\Level | Register | L1 Cache | L2 Cache | LLC | DRAM (2666Mhz DDR4) | SSD | HHD | Ethernet Network |
|---|---|---|---|---|---|---|---|---|
| Latency(cycle) | 1 | 3 | 9-30 | 30-60 | 150-300 | 15k-30k | ||
| Latency(ns) | 0.3 | 1 | 3-10 | 10-20 | 50-100 | 5k-10k | 30ms=3*10^7 ns | |
| Bandwidth(GB/s) | 3000 | 80 | 28 | 25 | 21.3 * n | 0.5 | 0.2 | 0.1 |
| Size | 1KB | 64KB | 256KB | 2-4MB | 8-512GB | 8-16TB | 16TB | |
| Price | 19RMB/GB DDR4 | 250RMB/TB | 65-125RMB/TB | |||||
| Area | ||||||||
| Power |
Explaination in detail
- Assume
1KBregisters flush using1 cyclein3GHzCPU, So bandwidth is3TB/s. - 2666Mhz DDR4:
2.666Gbps * 64bit / 8 = 21.3GB/s,
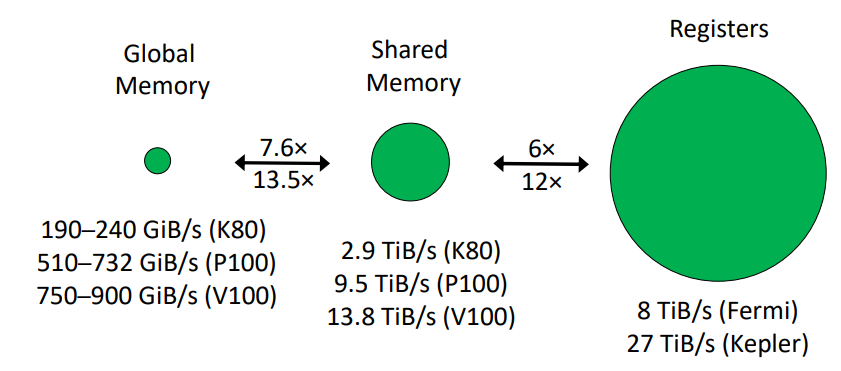
A100 Memory hierarchy
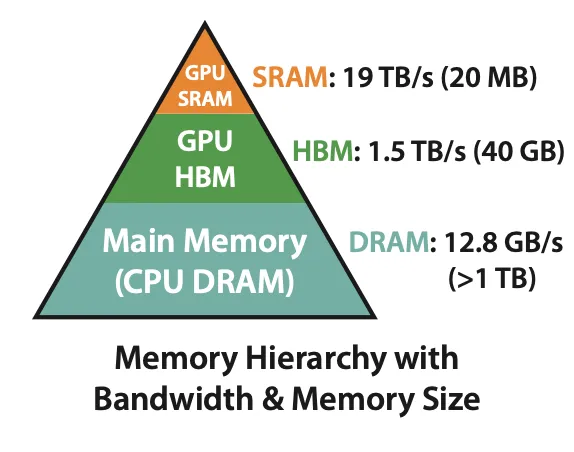
以 A100 來說,HBM 大概有 40 GB ~ 80 GB 左右,且 HBM 的 bandwidth 為 1.5–2.0TB/s,再往上一層的 memory 稱為 SRAM,總容量大概有 192 KB * 108 (streaming multiproecssors) 左右,雖然大小少很多,但是他的 bandwidth 可以達到 19TB/s

Address Translation Latency¶
- Utopia:Figure 4 shows the average PTW latency (in processor cycles) for Radix and ECH. We observe that Radix spends
137cycles and ECH86cycles, on average, to complete the PTW. - measure real PTW cost ???
- time breakdown of ALU, Address Translaton and Mem-access ???
20-40%of the instructions reference memory3- compulsory miss rate is
1%or less, caches with more realistic miss rates of2-10%.
TLB¶
Measurement tools from code
PIM Latency¶
UPMEM:
- CPU2MRAM 256bytes ~150us
- 线程同步 ~45us
Interconnect Bandwidth¶
CPU 2 CPU
SMP(symmetric multiprocessing) Interface
ice lake(2021) 3* UPI *20 134.4GB/s
kunpeng 920(2019年1月) 240 Gbps per port
CPU 2 GPU
- PCIe 3.0 * 16
15.75GB/s - PCIe 4.0 * 16
31.5GB/s - PCIe 5.0 * 16
128GB/s
CPU 2 Mem
- DDR4 single-lane
25.6GB/s - Customer Device 2-lanes
51.2GB/s - Server Device 16-lanes
409.6GB/s
GPU 2 GMem
- RTX3090 GDDR6x
1TB/s - A100 HBM2
1.5TB/s - H100 HBM3
3TB/s
Device 2 Device
- Ethernet Network
1Gbps-10Gbps - InfiniBand Network
40Gbps-800Gbps - RoCEv2 up to around
400Gbps
Union chip in Soc
M2 Ultra(2023年6月) is built using a second-generation 5-nanometer process and uses Apple’s groundbreaking UltraFusion technology to connect the die of two M2 Max chips, doubling the performance.
UltraFusion uses a silicon interposer that connects the dies with more than 10,000 signals, providing over 2.5TB/s of low-latency interprocessor bandwidth.
M2 Ultra Up to 192GB of unified memory, 800 GB/s memory bandwidth
Real SuperComputer Design¶
大模型推理芯片Groq (存算一体+软件定义硬件 2024年2月)
Groq芯片采用14nm制程工艺,搭载230MB片上共享SRAM,内存带宽达80TB/s,FP16算力为188TFLOPS,int8算力为750TOPS。15
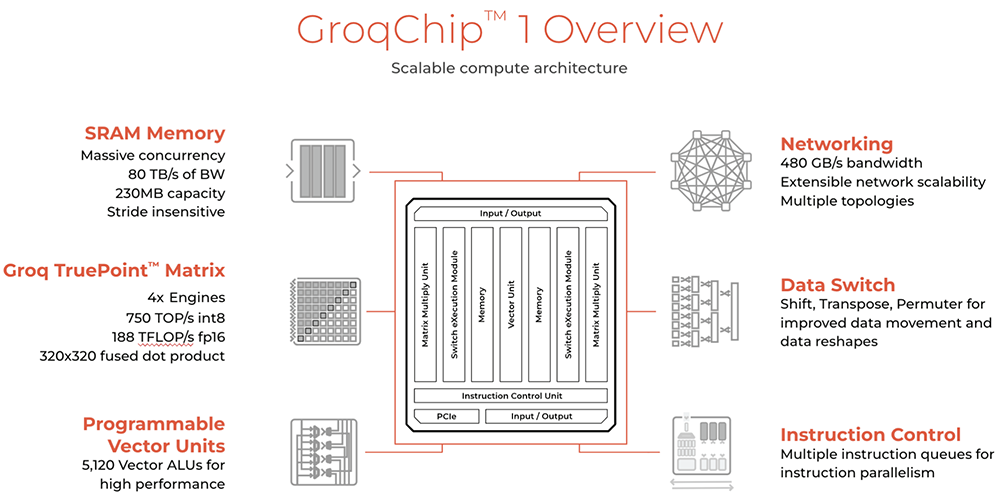
与很多大模型芯片不同的是,Groq的芯片没有HBM、没有CoWoS,因此不受HBM供应短缺的限制。
在对Meta Llama 2模型做推理基准测试时,Groq将576个芯片互连。按照此前Groq分享的计算方法,英伟达GPU需要大约1030J来生成token,而Groq每token大约需要13J,也就是说推理速度是原来的10倍,成本是原来的1/10,或者说性价比提高了100倍。
Groq拿一台英伟达服务器和8机架Groq设备做对比,并声称非常确定配备576个LPU的Groq系统运行成本不到英伟达DGX H100的1/10,而后者的运行价格已超过40万美元。等于说Groq系统能实现10倍的速度下,总成本只有1/10,即消耗的空间越多,就越省钱。
疑问: 单个芯片内存少,要500个芯片左右,推理可以支持这么多的并行度吗?
NVIDIA GH200 Grace (2023年5月)
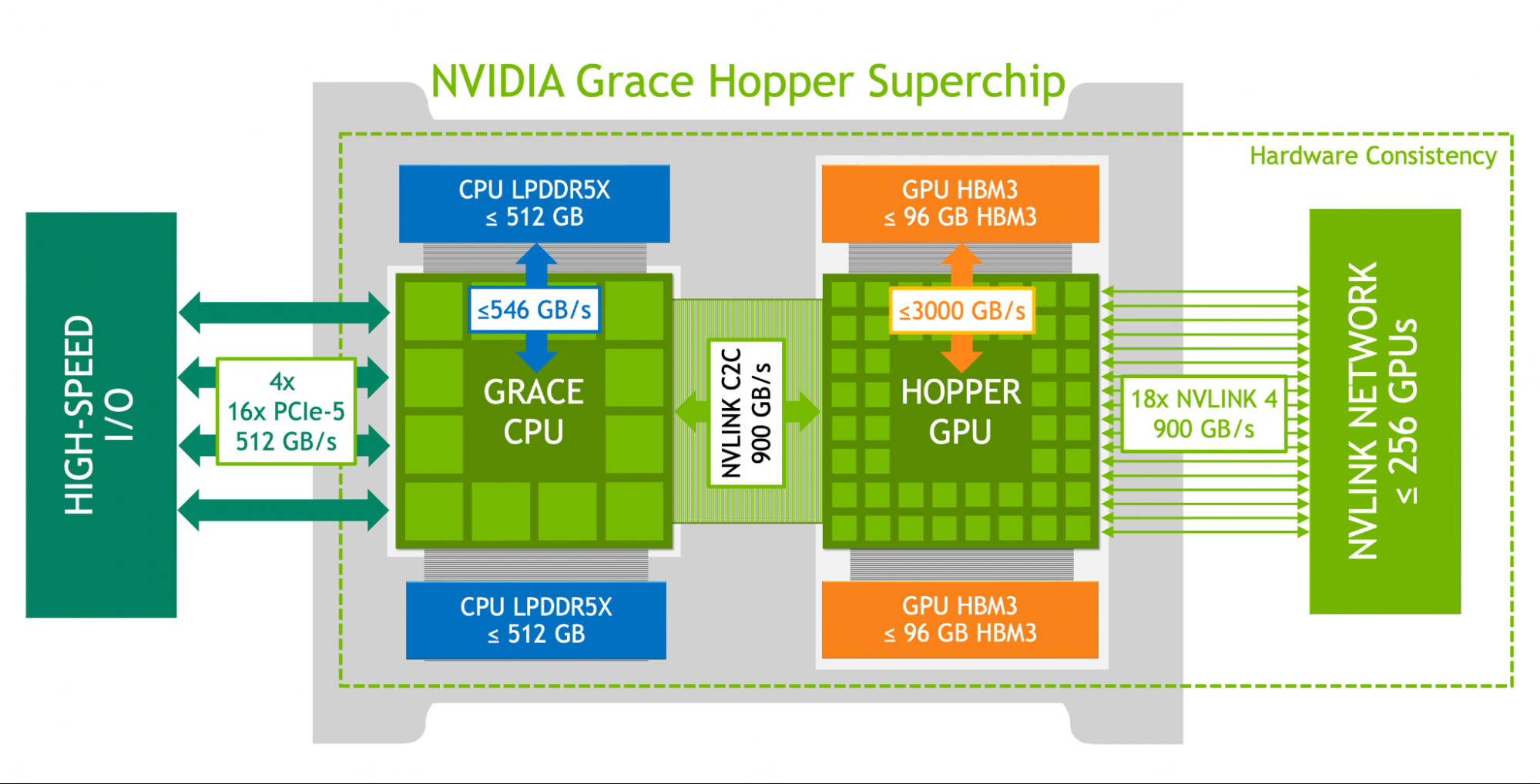
除了各部分的带宽都令人震惊。值得注意的几点:
- NVIDIA Grace CPU 是 72x Arm Neoverse V2 内核 + 高带宽高容量LPDDR5x
- 赛博斗蛐蛐: NVLINK C2C(900GB/s) 还是比 Apple 的 UltraFusion(2.5TB/s) 差一倍。
- 144TB的总内存是,包括CPU的LPDDR5x的。\(144TB = 256 * (512GB + 96GB)\)
- Nvidia对于显卡内存稀缺给出的答案: 异构计算 + CPU2GPU高带宽 + CPU大内存 + 统一的地址转换服务
Frontier supercomputer (2021年)
- 1 HPC and AI Optimized 3rd Gen AMD EPYC CPU
- 4 Purpose Built AMD Instinct 250X GPUs
- System Interconnect: Multiple Slingshot NICs providing
100 GB/snetwork bandwidth.
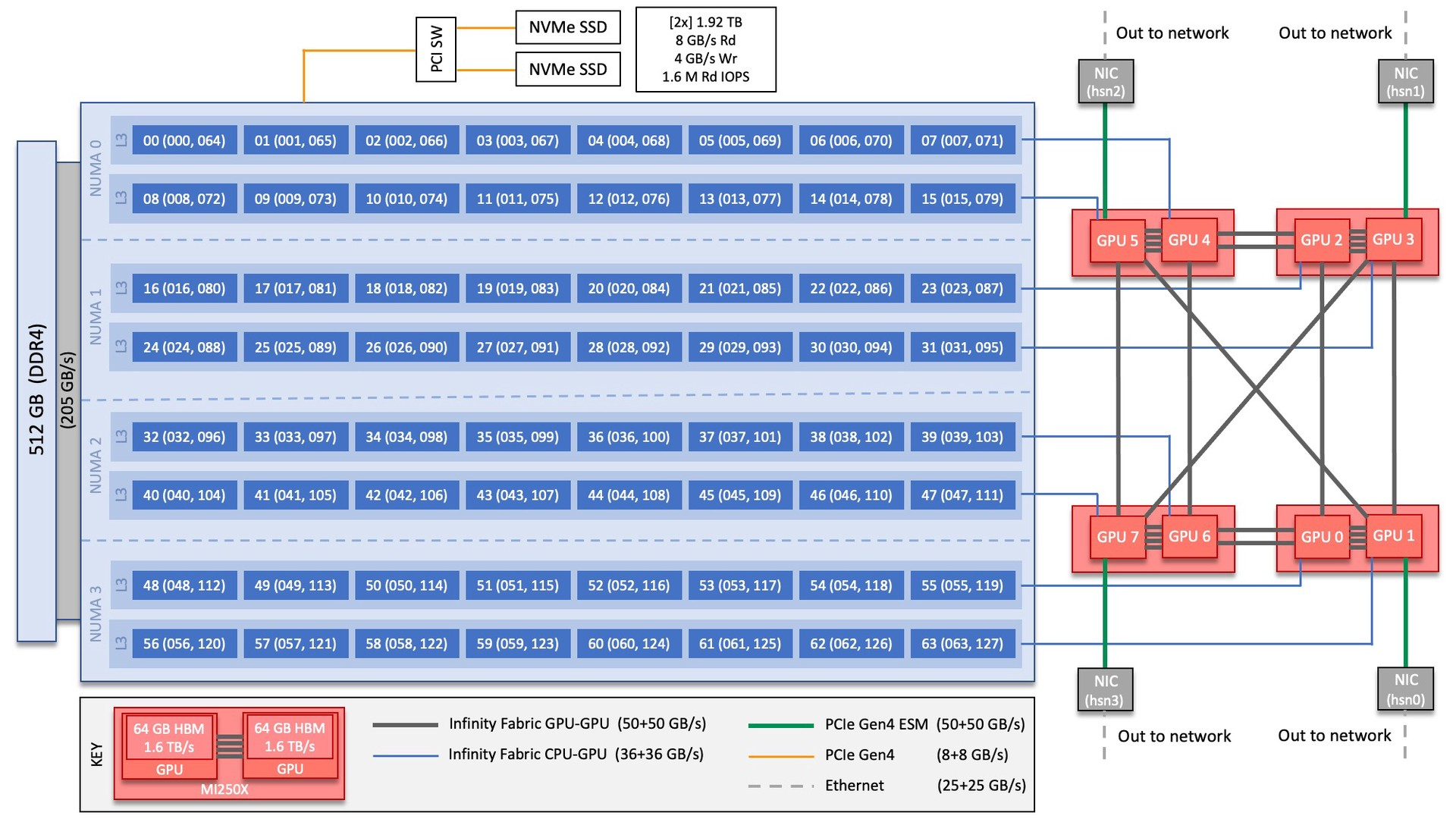
HUAWEI Atlas900 (2019年9月)
资料较少,随便找了些软文。
- 1024颗昇腾910 AI, 每颗 7nm昇腾910AI处理器内置32个达芬奇AI Core
- 总算力达到256P~1024P FLOPS @FP16
- 共享内存?
- 昇腾910 AI处理器和CPU之间: PCIe 4.0(速率16Gb/s)???
- 在集群层面,采用面向数据中心的CloudEngine 8800系列交换机,提供单端口100Gbps的交换速率, 支持100G RoCE。
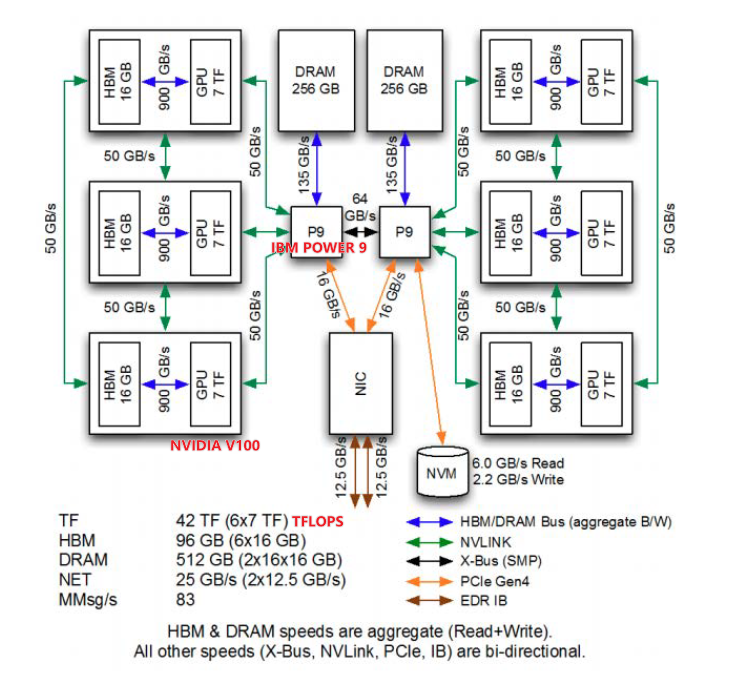
Summit SuperComputer (2018年6月)
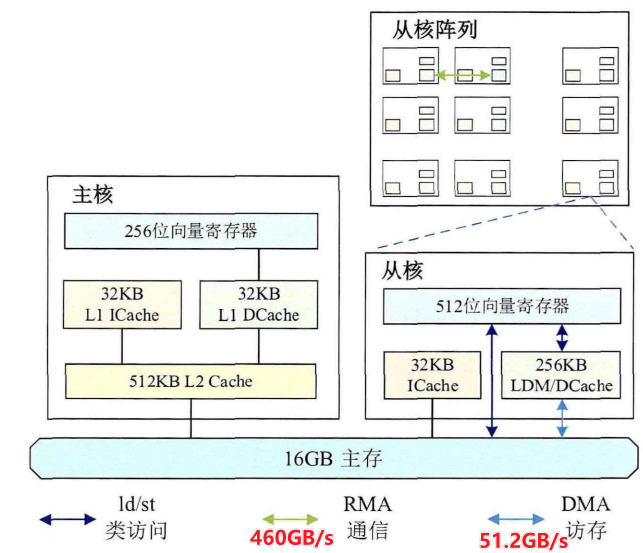
Next Shenwei SuperComputer (2018年6月)
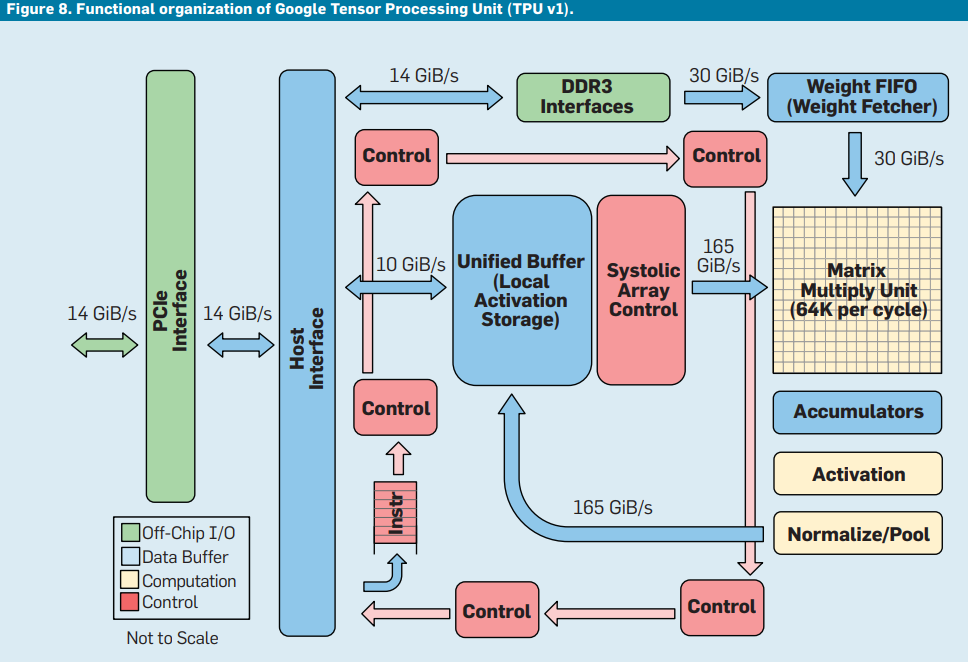
Google Tensor Processing Unit (TPU v1) (2015年)
“Domain-Specific architectures”
计算机领域的划分¶
计算机专业课程¶
计算机科学与技术专业的课程设置会因学校和国家的不同而有所差异,但通常包括以下核心课程:
- 编程基础:通常包括多门编程语言(如C/C++、Java、Python)的基础课程,教授编程概念、算法和数据结构等。
- 计算机体系结构:介绍计算机硬件和体系结构的基本原理,包括处理器、存储器、输入/输出设备等。
- 数据结构与算法:深入讲解各种常见数据结构(如链表、树、图)和算法(如排序、搜索、图算法),培养学生解决实际问题的能力。
- 操作系统:介绍操作系统的原理和设计,包括进程管理、内存管理、文件系统等内容。
- 数据库系统:学习数据库的基本原理和SQL语言,了解数据库的设计和管理。
- 网络与通信:介绍计算机网络的基本原理、协议和技术,包括网络体系结构、路由、传输控制协议(TCP)、因特网协议(IP)等。
- 软件工程:学习软件开发的方法和流程,包括需求分析、设计、编码、测试和维护等。
- 计算机安全:介绍计算机系统和网络的安全问题,包括密码学、网络安全、软件安全和信息安全管理等。
- 人工智能与机器学习:介绍人工智能和机器学习的基本概念和算法,包括神经网络、决策树、支持向量机等。
- 软件开发实践:实践性课程,学生通过实际项目开发,学习软件开发的实践技能和团队合作能力。
此外,还可能包括课程如计算理论、编译原理、图形学、嵌入式系统、分布式系统等,以及选修课程供学生根据个人兴趣和专业方向选择。
计算机产业的布局与计算机行业的分类¶
- 云计算:云计算是通过网络提供计算资源和服务的模式,包括基础设施即服务(IaaS)、平台即服务(PaaS)和软件即服务(SaaS)。在云计算领域,主要的参与者包括云服务提供商(如亚马逊AWS、微软Azure、谷歌云等),它们通过数据中心提供灵活的计算和存储资源,为用户提供可扩展的计算能力和服务。
- 人工智能(AI):人工智能是计算机科学的一个分支,涉及模拟和实现人类智能的技术和方法。AI在计算机产业中扮演了重要角色,包括机器学习、深度学习、自然语言处理和计算机视觉等领域。大型科技公司如谷歌、微软、IBM等在AI领域投入了大量资源,并开发了各种AI相关的工具、框架和平台。
- 边缘计算:边缘计算是一种分布式计算模型,将数据处理和分析推向边缘设备。这个领域涉及边缘设备、传感器、物联网技术和边缘计算平台等。大型云服务提供商也在布局边缘计算,以支持边缘设备上的实时计算和决策。
- 物联网(IoT):物联网是指将日常物品连接到互联网,实现物品之间的通信和互操作。物联网涉及传感器、嵌入式系统、网络和云平台等技术。各大科技公司和设备制造商都在物联网领域进行布局,以实现智能家居、智能城市、工业自动化等应用。
- 数据中心:数据中心是集中存储、处理和管理大量数据的设施,为云计算和大数据应用提供支持。数据中心通常由大型云服务提供商和企业自建,它们需要高性能计算、存储和网络设备来处理大规模的数据和应用。
- 超级计算机:超级计算机是具有强大计算能力的大型计算机系统,用于解决复杂的科学、工程和商业问题。超级计算机通常由政府、研究机构和大型企业建设和使用,它们在气候模拟、基因组学、物理模拟等领域发挥着重要作用。
开题缘由、总结、反思、吐槽~~¶
秋招的时候发现,对计算机系统,课程,学科,行业的全局的掌握确实很缺乏。
为了能更清晰的学习,应该自顶向下的了解和计算机相关的全局的知识。
实践¶
如何测量计算机系统的如上数值
参考文献¶
-
SC19: Parallel Transport Time-Dependent Density Functional Theory Calculations with Hybrid Functional on Summit ↩↩
-
What is InfiniBand Network and the Difference with Ethernet? ↩↩
-
Hitting the Memory Wall: Implications of the Obvious ↩
-
(ISCA09) An Analytical Model for a GPU Architecture with Memory-level and Thread-level Parallelism Awareness ↩
-
Kunpeng 920 (ARMv8) - Hardware-specific Support Alex Margolin UCX Hackathon, Dec. 2019 ↩
-
(TOCS09) A Mechanistic Performance Model for Superscalar Out-of-Order Processors ↩↩↩
-
Da Vinci - A scaleable architecture for neural network computing (updated v4) ↩↩