Nvidia
导言
Nvidia 的系列产品的基本参数
各系列定位¶
中国特供版¶
| GPU 型号 | 形态 | FP16 算力 (TFLOPS) (Dense, Tensor Core) |
显存容量 (GB) | 显存类型 | 显存带宽 (GB/s) | NVLink |
|---|---|---|---|---|---|---|
| B200 | SXM | 2250 | 180 | HBM3E | 7,700 | 1800 GB/s (18 links, NVLink5) |
| H200 | SXM | 989 | 141 | HBM3E | 4,800 | 900 GB/s (18 links, NVLink4) |
| H100 | SXM5 | 989 | 80 | HBM3 | 3,350 | 900 GB/s (18 links) |
| PCIe | 756 | 80 | HBM3 | 2,000 | 无(仅 PCIe) | |
| H800 | SXM5 | 989 | 80 | HBM3 | 3,350 | 450 GB/s(降规 NVLink) |
| H20 | SXM/PCIe | 148 | 96 | HBM3e | 4,096 | 无 NVLink(仅 PCIe 5.0 x16) |
| A100 | SXM4 | 312 | 40 / 80 | HBM2e | 1,555 / 2,039* | 600 GB/s (12 links) |
| PCIe | 312 | 40 / 80 | HBM2e | 1,555 / 2,039* | 通常无板载 NVLink 连接器 | |
| A800 | SXM4 | 312 | 40 / 80 | HBM2e | 1,555 / 2,039* | 300 GB/s(降规 NVLink) |
- 251208,特朗普宣布解禁H200中国销售。
- A800 对标 A100。H800 对标 H100。但是带宽有阉割
- 2023年10月17日,美国商务部工业和安全局(BIS)发布了针对芯片的出口管制新规,对包括英伟达高性能AI芯片在内的半导体产品施加新的出口管制;限制条款已经于10月23日生效。英伟达给美国SEC的备案文件显示,立即生效的禁售产品包括A800、H800和L40S这些功能最强大的AI芯片。5
- 对此NV推出新的HGX H20、L20、L2三款 AI 芯片产品,分别基于英伟达的Hopper和Ada架构,适用于云端训练、云端推理以及边缘推理。
集群要求(估计)¶
据评估,H100/H800是目前算力集群的主流实践方案:
- H100理论极限在5万张卡集群,最多达到10万P算力;
- H800最大实践集群在2万-3万张卡,共计4万P算力;
- A100最大实践集群为1.6万张卡,最多为9600P算力。5
- 新的H20芯片,理论极限在5万张卡集群,但每张卡算力为0.148P,共计近为7400P算力,低于H100/H800、A100。因此,H20集群规模远达不到H100的理论规模,基于算力与通信均衡度预估,合理的整体算力中位数为3000P左右,需增加更多成本、扩展更多算力才能完成千亿级参数模型训练。
商业考虑¶
- 中国是NV最大的市场之一,历来占其收入的五分之一左右。4
- 中国云计算公司目前约有80%的高端人工智能芯片来自英伟达,而这一比例在未来五年可能会下降到50%至60%。
集群超算 DGX,HGX,EGX,MGX¶
- NVIDIA DGX SYSTEMS:Purpose-Built for the AI Enterprise
- NVIDIA HGX AI 超级计算机:专为 AI 和 HPC 而打造
- NVIDIA EGX 平台: 从数据中心到边缘端强大安全的加速能力
- NVIDIA MGX: 通过模块化服务器设计将加速计算引入任何数据中心。
感觉GPT4的解释大差不差
NVIDIA的HGX、DGX和EGX是三个不同的产品系列,它们分别针对不同的市场和应用场景设计。下面是每个缩写的含义和它们的主要用途:
-
HGX (Hyper-scale GPU Accelerator):
- HGX是面向超大规模、高性能计算(HPC)和人工智能(AI)的数据中心设计的GPU加速平台。
- 它通常包含多个GPU,用于处理大规模并行计算任务,如深度学习训练、科学模拟等。
- HGX平台旨在提供最高的计算密度和效率,适用于构建超级计算机和大型数据中心。
-
DGX (Data-center Grade GPU Accelerator):
- DGX是NVIDIA设计的用于深度学习和AI应用的高端计算系统。
- 它通常是一种集成解决方案,包括GPU、CPU、内存和存储,以及用于深度学习和AI的软件和工具。
- DGX系统被设计为即插即用,适用于研究机构、大学和企业,用于加速AI研究和商业AI应用的部署。
-
EGX (Edge GPU Accelerator):
- EGX是针对边缘计算环境设计的GPU加速平台。
- 它旨在将AI的能力带到网络边缘,例如在零售、制造、物流、智慧城市等场景中进行实时数据处理和分析。
- EGX平台通常更小巧、能效更高,适合安装在距离数据源更近的位置,以减少延迟并提高响应速度。
这些平台代表了NVIDIA在不同计算领域的战略布局,旨在提供专门针对各种计算需求的优化解决方案。由于我的最后更新是在2023年4月,这些平台的最新细节可能有所变化。
GeForce 提供家庭娱乐¶
PC,与AMD(原ATi)的Radeon系列显卡竞争
GTX¶
- 从2004年的Geforce 6800系列开始就有“GT”的代号,GT:频率提升版本"GeForce Technology"的缩写,代表着中高端显卡或者是加强版显卡,比如6600GT和6800GT,
- 到了2005年的7800系列之后便引入了“GTX”的代号,直接代表着高端或者顶级显卡。
- 进入GTX400系列(2010年)以后,当时还有象征中低端的“GTS”命名,后来就连“GTS”也没有了,全部的独立显卡统称为“GTX”,仅用后面的数字大小来区分性能等级,至今GTX1000系列显卡一直延续着这样的命名方式。
RTX¶
- 对于已经沿用了多年的GTX前缀,NVIDIA终于在最新的GTX20系列(2018年)有所改变了,高端的2080和2080TI统称为“RTX”,这里的“RT”就代表着光线追踪(ray tracing的缩写),象征着RTX2080显卡拥有非常强大的光线追踪性能。其实光线追踪技术本身并不新鲜,但是由于计算量需求庞大,往往为了渲染一帧图片都需要传统电脑消耗数个小时乃至数天的时间,但是RTX20显卡采用的“图灵”架构引入了RT计算单元,使其光线追踪性能超越上一代显卡的六倍,拥有了即时处理游戏光追的条件,NVIDIA认为这是一个划时代的进化,于是果断把沿用多年的“GTX”改名为“RTX”。
- NVIDIA RTX显卡是首个包含RT Core的图形卡。这种专用光线追踪硬件每秒可以投射超过10 gigarays的光线,从而可以在游戏中提供类似电影的实时照明。RTX显卡的光线追踪性能最高可提高6倍,因而可以实现实时光线追踪效果。
- RTX显卡也是首个提供Tensor Core的设备,这些Tensor Core能够提供超过100 teraflop的AI处理,以利用NVIDIA DLSS提高游戏性能。
Tesla用于大规模的并联电脑运算¶
- NVIDIA推出了CUDA。开发者利用C语言,再通过CUDA编译器,就能利用显核运算。开发者可忽略图形处理技术,而直接利用熟悉的C语言。开发者和科学家,就可以利用显示核心,研究物理、生化和勘探等领域。
- 可实现极高精度
- 最大的差别是特斯拉计算卡(Tesla )属于运算卡,没有图形输出功能
Tegra 移动端 SOC system on chip¶
- 基于ARM架构的通用处理器(CPU)。Tegra是一种采用单片机系统设计(system-on-a-chip)芯片,它集成了ARM架构处理器和NVIDIA的GeforceGPU,并内置了其它功能,产品主要面向小型设备。和Intel以PC为起点的x86架构相比,ARM架构的Tegra更像是以手机处理器为起点做出的发展。它不能运行x86 PC上的Windows XP等操作系统,但在手机上应用多年的ARM架构轻量级操作系统更能适应它高速低功耗的需求
- 2008年2月11日,NVIDIA发布了用于智能手机与PDA平台的Tegra APX 2500
65 nm 600 MHz
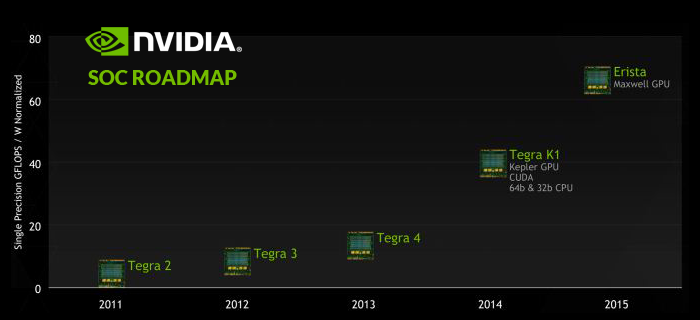
- Tegra X1的分数几乎是Tegra K1,再之前是Tegra 1/2/3/4
- Switch采用了Nvidia Tegra T210处理器,属于Tegra X1系列。目前各类主机以及手机、平板都是将CPU与GPU整合在一块芯片上,并不像电脑还需有个独显。而Tegra系列便是Nvidia专门为手持设备开发的系统芯片,Tegra为Nvidia自产主机SHIELD以及Google手机Nexus、小米平板等设备提供过技术支持,图像处理性能介于A8X与A9X之间,是的,Tegra常拿来与移动端处理器对比,感情Switch就是用的一手机CPU啊,还是三年前的!
- Tegra X1整合了四颗Cortex-A57核心和四颗Cortex-A53核心,和骁龙810以及三星Exynos 7系列相同。而GPU部分则采用了Maxwell架构,共计256个流处理器,堪比入门独显了
- Super Switch有望搭载一块1080P OLED/mini LED显示屏,处理器升级为Tegra X1+/Xavier,配备64GB存储空间。
ION 低端上网本,集成¶
Quadro (视觉计算平台)¶
架构+产品+参数¶
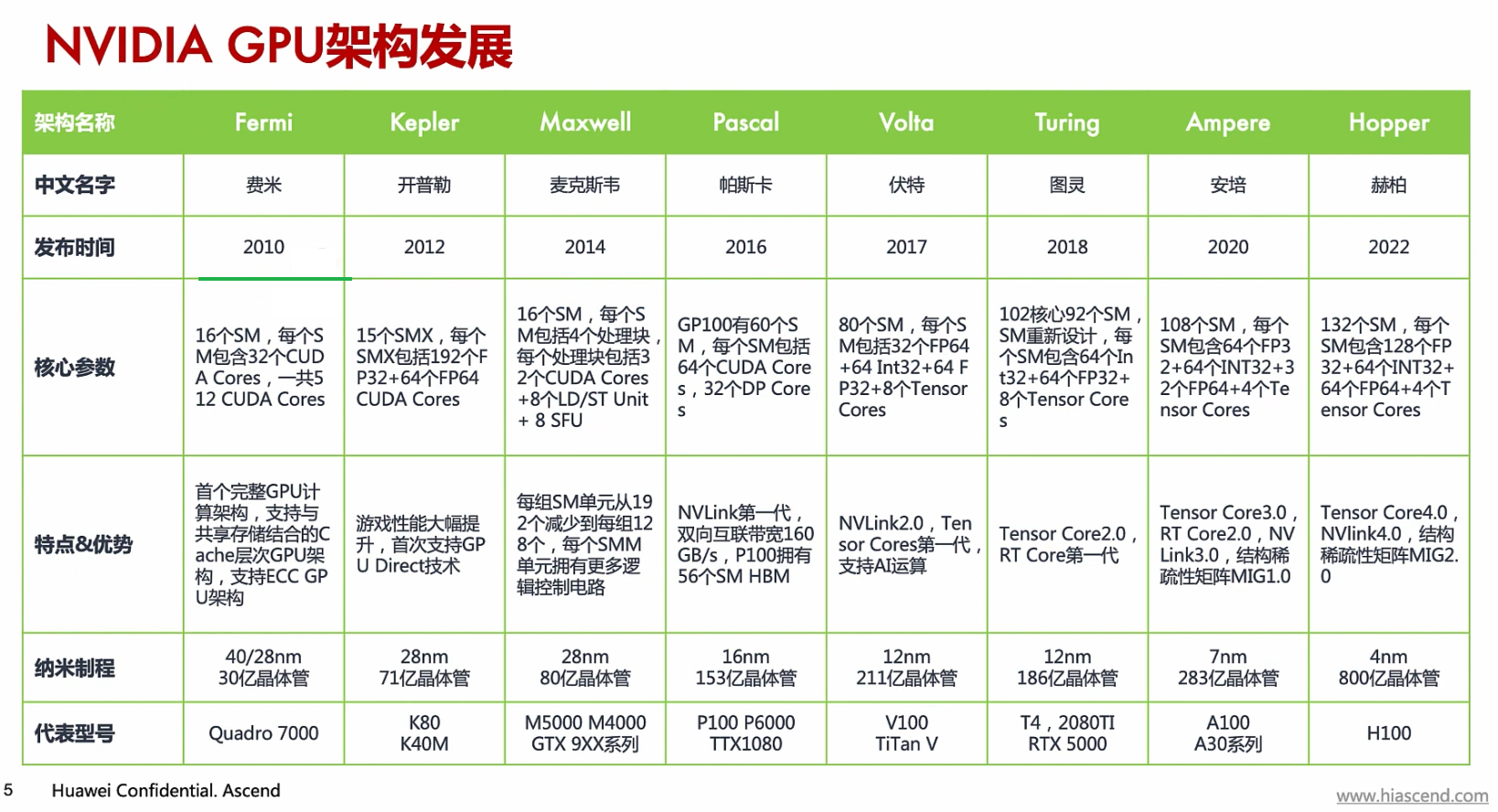
Older¶
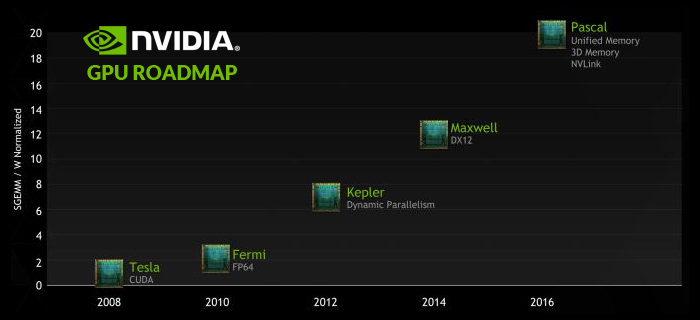
Maxwell 2014年¶
- GTX 980
- GeForce GTX TITAN X 28nm Maxwell架构 GM200
Pascal 2016年¶
- Pascal的GPC有6个SM,每个SM只含有64个CUDA Core,但是拥有64个FP32单元32个FP64单元,FP64与FP32比例达到了1:2,双精度性能大幅度提高,而Pascal的FP32单元可以同时执行2个FP16半精度运算,因此FP16浮点性能也同样获得极大提升
| 产品名 | 架构 | 核心 | cuda核心数 | 单双浮点性能 | 内存大小 | 内存带宽 | TDP |
|---|---|---|---|---|---|---|---|
| GTX1080 | Pascal | GP104 | |||||
| GTX1080Ti | Pascal | 16nm GP102 | 3584 | 11GB GDDR5X | 484GB/s显存带宽 | 250W | |
| P100 | Pascal | GP104 | 3584 | 5/10 Tflops | 12/16GB | 250W | |
| P40 | Pascal | GP100 | 3840 | 6/12 Tflops | 24GB GDDR5 | 250W |
Volta 2017年¶
| 产品名 | 架构 | 核心 | cuda核心数 | (Double/Single/Tensor)浮点性能 | 内存大小 | 内存带宽 | TDP |
|---|---|---|---|---|---|---|---|
| V100-PCIe | Volta | GP100 | 5120(640Tensor core) | 7/14/112 Tflops | 16/32GB HBM2 | 250W |
Turing 2018年¶
- RT core 硬件光追
- Tensor core 加速深度学习 DLSS
- VR + 采样 光栅性能
| 产品名 | 架构 | 核心 | cuda核心数 | 单双浮点性能 | 内存大小 | 内存带宽 | TDP |
|---|---|---|---|---|---|---|---|
| GTX1650 | Turing | 896 | 4GB | 128位 128GB/s | 75W | ||
| RTX2060 | Turing | 1920 | 6GB | 192位 336GB/s | 160W | ||
| RTX2080Ti | Turing | 4352 | 11GB | 352位 | 260W |
Ampere 2020年¶
- Ampere被看作是Turing的平稳升级
- 7nm + NVIDIA第八代GPU提供了迄今为止最大的性能飞跃,集AI训练和推理于一身
- 新的Turing RT核心和Tensor核心
| 产品名 | 架构 | 核心 | cuda核心数 | (Double/Single/Single Tensor/FP16 Tensor)浮点性能 | 内存大小 | 内存带宽 | TDP |
|---|---|---|---|---|---|---|---|
| RTX3070 | Ampere | 5888 | 8GB GDDR6X | 256位 | 220W | ||
| RTX3090 | Ampere | GA102 | 10496 | 24GB GDDR6X | 384位 | 350W | |
| A100-SXM | Ampere | GA100-883AA-A1 | 6912 | 9.7/19.5/152/312 Tflops | 40/80GB HBM2e | 2,039 GB/s | 400W |
| A800 | Ampere |
Ada Lovelace 2022年9月¶
- 继承了2020年发布的Ampere架构
- 采用台积电新的5 nm“4N”工艺
| 产品名 | 架构 | 核心 | cuda核心数 | (Double/Single/Single+Tensor/FP16+Tensor)浮点性能 | 内存大小 | 内存带宽 | TDP |
|---|---|---|---|---|---|---|---|
| RTX 4090 | Ada Lovelace | AD102 | 16384 | 24GB GDDR6X | 384-bit 21 Gbps 1TB/s | 450W | |
| RTX 4090 D | Ada Lovelace | ||||||
| L2 | Ada Lovelace | 24GB GDDR6X | 300GB/s | TBD | |||
| L20 | Ada Lovelace | xx/60/60/119 Tflops | 48GB GDDR6X | 864GB/s | 275W |
Hopper¶
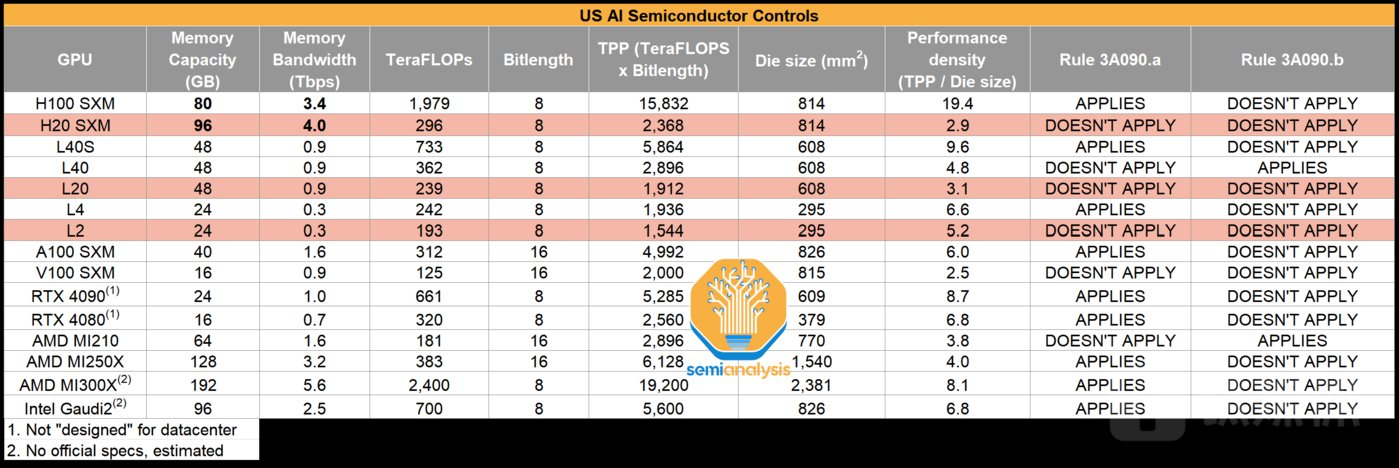
SXM (Server PCI Express Module)
| 产品名 | 架构 | 核心 | cuda核心数 | (Double/Single/Single+Tensor/FP16+Tensor)浮点性能 | 内存大小 | 内存带宽 | TDP |
|---|---|---|---|---|---|---|---|
| H100-SXM | Hopper | 34/67/989/1979 Tflops | 80GB HBM3 | 3TB/s | 700W | ||
| H20 | Hopper | xx/44/74/148 Tflops | 96GB HBM3 | 4TB/s | 400W |
或者
| 核心指标 | 数据类型 | H100 SXM5 (满血版) | H100 PCIe (插卡版) | 典型应用场景 |
|---|---|---|---|---|
| FP64 | 双精度 | 34 TFLOPS | 26 TFLOPS | 传统超算、科学模拟 |
| FP64 Tensor Core | 双精度 (Tensor) | 67 TFLOPS | 51 TFLOPS | 加速的科学计算 |
| FP32 | 单精度 | 67 TFLOPS | 51 TFLOPS | 图形、通用计算 |
| TF32 | Tensor Float 32 | 494 TFLOPS | 378 TFLOPS | 主流 AI 训练 (PyTorch 默认) |
| FP16 / BF16 | 半精度 | 989 TFLOPS | 756 TFLOPS | 高性能 AI 训练 & 推理 |
| FP8 | 8位浮点 | 1,979 TFLOPS | 1,513 TFLOPS | 大模型训练 & 推理 (H100 杀手锏) |
| INT8 | 8位整数 | 3,958 TOPS | 3,026 TOPS | 极致 AI 推理 |
fp16暴涨3倍
AI 训练速度暴增 (FP8 & FP16)
- A100 (FP16): 312 TFLOPS
- H100 (FP16): 989 TFLOPS
Next¶
明年英伟达B100 GPU产品很有可能不再向中国市场销售。5
AMD(原ATi) PS4 PS5¶
- PS4 PRO与Xbox One X两大主机皆是采用了AMD公司的捷豹(Jaguar)处理器
- PS4Pro 的APU GPU部分大概是RX470D?(或者1050Ti)