更详细在这里
scontrol show job 7454119
squeue -u USERNAME #来查看目前处于运行中的作业。
format=jobid,jobname,partition,nodelist,alloccpus,state,end,start,submit
sacct --format=$format -j 7454119
[sca3190@ln121%bscc-a5 ~]$ sacct -D -T -X -u sca3190 -S 2021-11-10T00:00:00 -E 2021-11-30T00:00:00 --format "JobID,User,JobName,Partition,QOS,Elapsed,Start,NodeList,State,ExitCode,workdir%70"
JobID User JobName Partition QOS Elapsed Start NodeList State ExitCode WorkDir
------------ --------- ---------- ---------- ---------- ---------- ------------------- --------------- ---------- -------- ----------------------------------------------------------------------
1050223 sca3190 LQCD amd_256 normal 19-23:25:24 2021-11-10T00:34:36 fa[0208,0211] NODE_FAIL 0:0 /public1/home/sca3190/VEC_REORDER_LQCD/src
[sca3190@ln121%bscc-a5 ~]$ sacct -D -T -X -u sca3190 -S 2021-11-10T00:00:00 -E 2021-11-30T00:00:00 --format "JobID,User,JobName,Partition,QOS,Elapsed,Start,NodeList,State,ExitCode,workdir%70,Timelimit,Submitline%20,Submit,Layout"
JobID User JobName Partition QOS Elapsed Start NodeList State ExitCode WorkDir Timelimit SubmitLine Submit Layout
------------ --------- ---------- ---------- ---------- ---------- ------------------- --------------- ---------- -------- ---------------------------------------------------------------------- ---------- -------------------- ------------------- ---------
1050223 sca3190 LQCD amd_256 normal 19-23:25:24 2021-11-10T00:34:36 fa[0208,0211] NODE_FAIL 0:0 /public1/home/sca3190/VEC_REORDER_LQCD/src UNLIMITED 2021-11-10T00:11:29
1个task 64核
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=1
#SBATCH --cpus-per-task=64
建议sbatch 加入-t, --time=minutes time limit
#SBATCH -t 5:00
第二年参加IPCC发现去年的一个程序跑了很久。

导出excel 获得jobID 1050223
$ sacct -D -T -X -u sca3190 -S 2021-11-10T00:00:00 -E 2021-11-30T00:00:00 --format "JobID,JobName,State,workdir%70"
JobID JobName State WorkDir
------------ ---------- ---------- ----------------------------------------------------------------------
1050223 LQCD NODE_FAIL /public1/home/sca3190/VEC_REORDER_LQCD/src
NODE_FAIL - Job terminated due to failure of one or more allocated nodes.
查看提交脚本,没有什么问题。
#!/bin/bash
#SBATCH -o ./slurmlog/job_%j_rank%t_%N_%n.out
#SBATCH -p amd_256
#SBATCH -J LQCD
#SBATCH --nodes=2
#SBATCH --ntasks-per-node=64
#SBATCH --exclude=
#SBATCH --cpus-per-task=1
#SBATCH --mail-type=FAIL
#SBATCH [email protected]
source /public1/soft/modules/module.sh
module purge
CC=mpiicc
CXX=mpiicpc
CXX_FLAGS=""
raw_flags="-fPIC -I../include -std=c++11 -march=core-avx2"
MPIOPT=
computetimes="ibug_buffer"
taskname=so_${CC}_${CXX}_${CXX_FLAGS}
export OMP_NUM_THREADS=$SLURM_CPUS_PER_TASK
module load intel/20.4.3
module load mpi/intel/20.4.3
make clean
make CC=$CC CXX=$CXX CXX_FLAGS="${CXX_FLAGS}${raw_flags}" TARGET=$taskname
mpirun ./$taskname 0.005 ../data/ipcc_gauge_48_96 48 48 48 96 12 24 24 12 > ./log/3_$taskname$computetimes.log
查看Log文件
sca3190@ln121%bscc-a5 src]$ cat slurmlog/job_1050223_rank0_fa0208_0.out
rm -rf liblattice.so dslash.o lattice_fermion.o lattice_gauge.o invert.o check.o load_gauge.o main
mpiicpc -fPIC -I../include -std=c++11 -march=core-avx2 -o dslash.o -c dslash.cpp
mpiicpc -fPIC -I../include -std=c++11 -march=core-avx2 -o lattice_fermion.o -c lattice_fermion.cpp
mpiicpc -fPIC -I../include -std=c++11 -march=core-avx2 -o lattice_gauge.o -c lattice_gauge.cpp
mpiicpc -fPIC -I../include -std=c++11 -march=core-avx2 -o invert.o -c invert.cpp
mpiicpc -fPIC -I../include -std=c++11 -march=core-avx2 -o check.o -c check.cpp
mpiicpc -fPIC -I../include -std=c++11 -march=core-avx2 -o load_gauge.o -c load_gauge.cpp
mpiicpc --shared dslash.o lattice_fermion.o lattice_gauge.o invert.o check.o load_gauge.o -o liblattice.so
mpiicpc -fPIC -I../include -std=c++11 -march=core-avx2 -Wl,-rpath=./ -lmpi -o so_mpiicc_mpiicpc_ main.cpp -L./ -llattice
slurmstepd: error: *** JOB 1050223 ON fa0208 CANCELLED AT 2022-04-20T14:45:43 DUE TO NODE FAILURE, SEE SLURMCTLD LOG FOR DETAILS ***
[[email protected]] check_exit_codes (../../../../../src/pm/i_hydra/libhydra/demux/hydra_demux_poll.c:121): unable to run bstrap_proxy (pid 59376, exit code 256)
[[email protected]] poll_for_event (../../../../../src/pm/i_hydra/libhydra/demux/hydra_demux_poll.c:159): check exit codes error
[[email protected]] HYD_dmx_poll_wait_for_proxy_event (../../../../../src/pm/i_hydra/libhydra/demux/hydra_demux_poll.c:212): poll for event error
[[email protected]] HYD_bstrap_setup (../../../../../src/pm/i_hydra/libhydra/bstrap/src/intel/i_hydra_bstrap.c:772): error waiting for event
[[email protected]] main (../../../../../src/pm/i_hydra/mpiexec/mpiexec.c:1938): error setting up the boostrap proxies
猜测原因是: 卡在编译了。
以后最好不要在sbatch脚本里编译
暂无
暂无
无

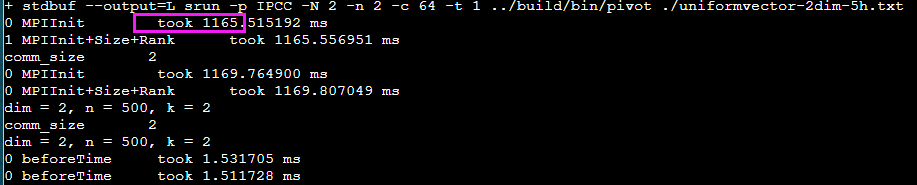
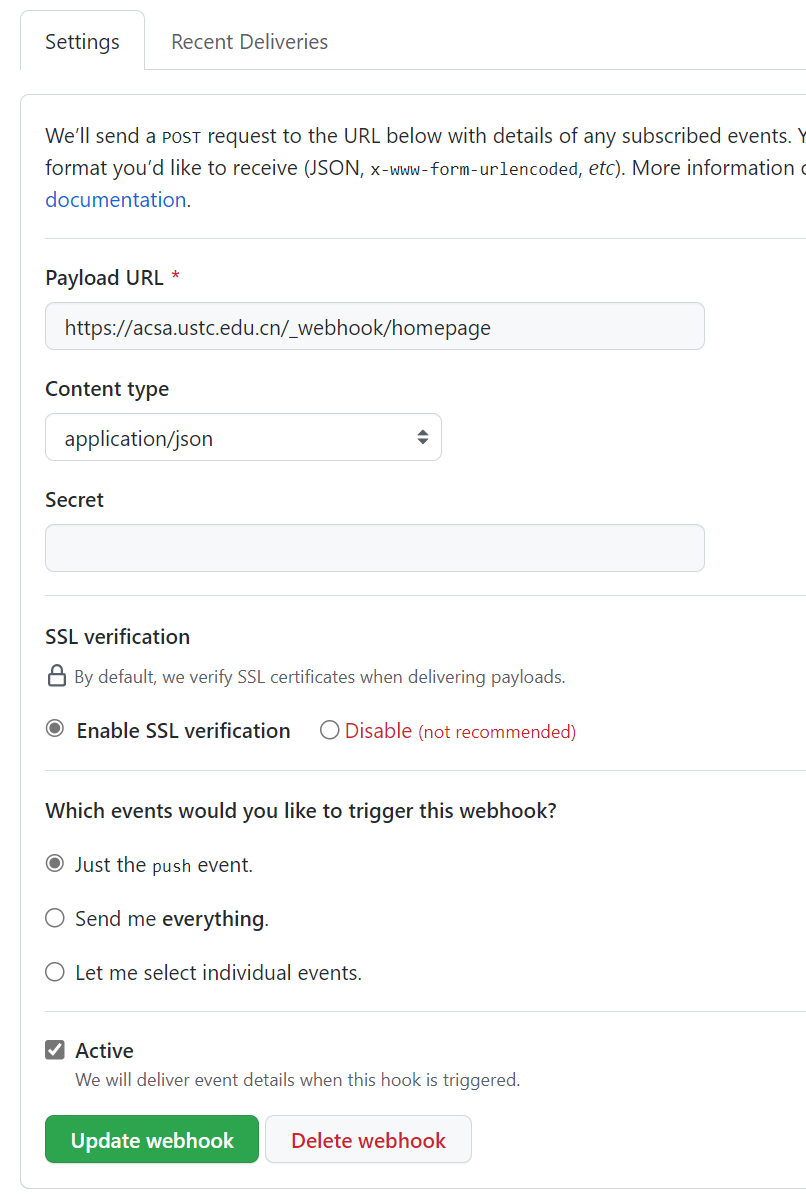
 还是不行,猜测是
还是不行,猜测是


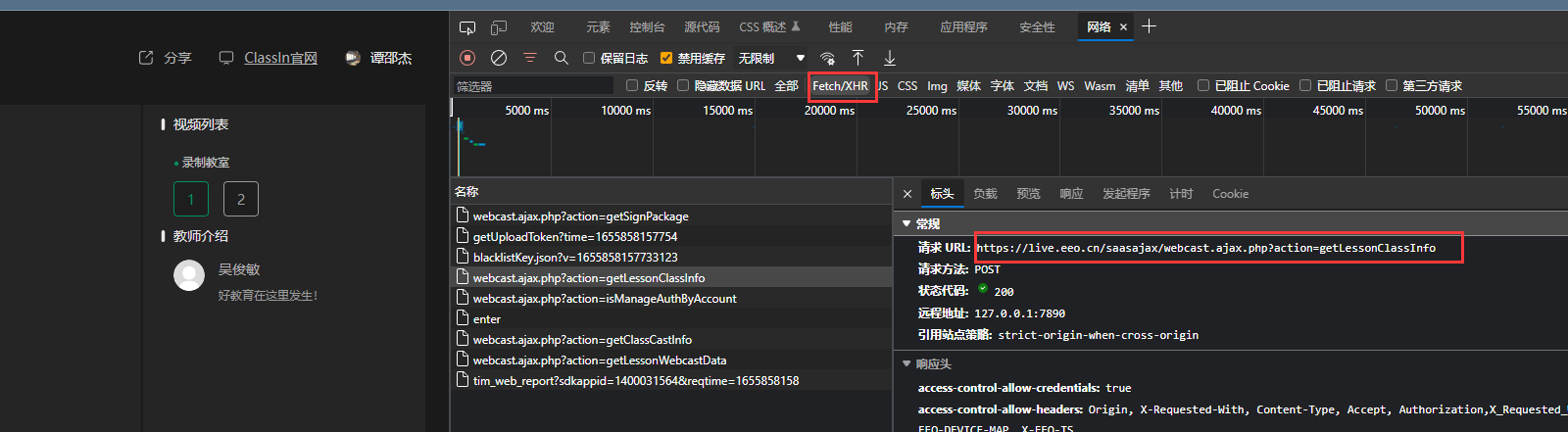


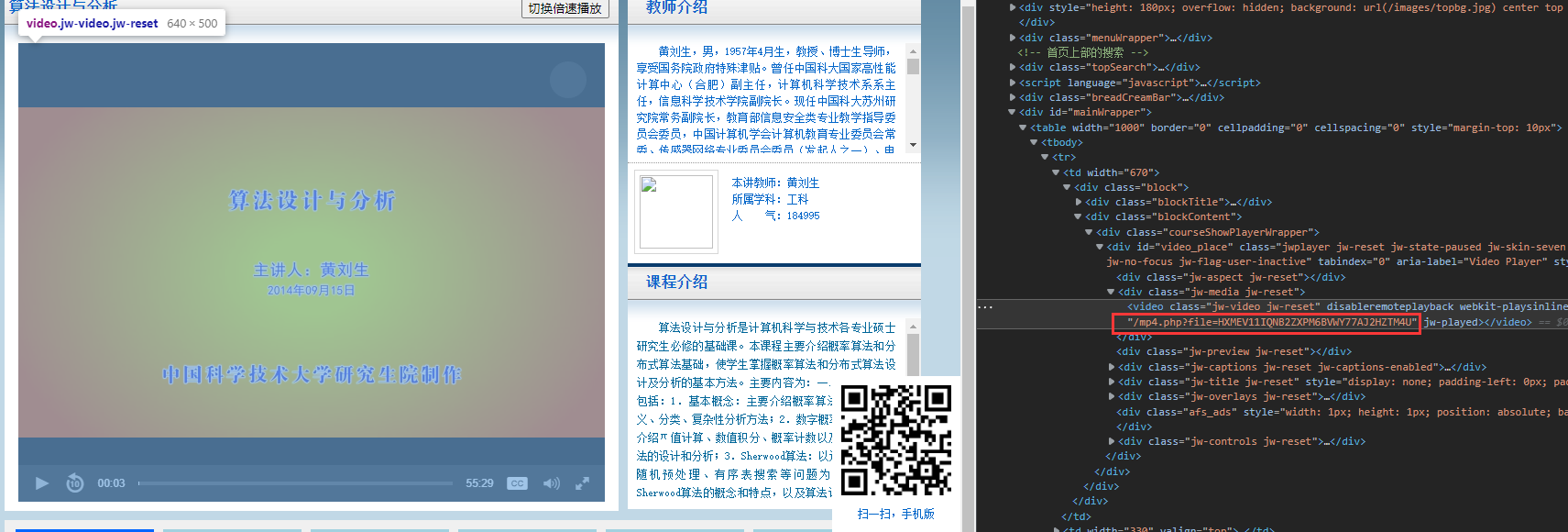 但是不打开网站没有php返回,网页只能得到。
但是不打开网站没有php返回,网页只能得到。
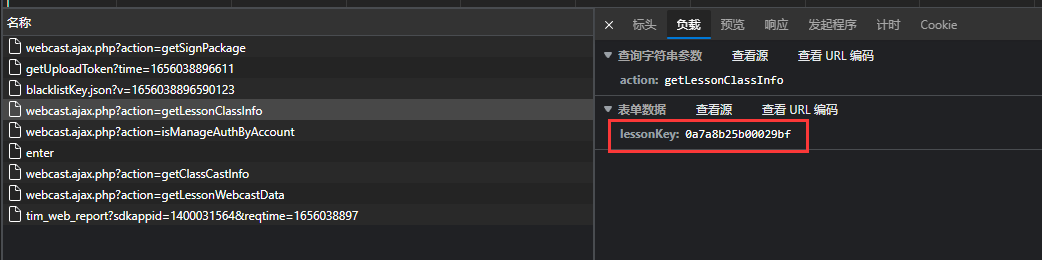
 可通过下面API返回需要的, 可以见
可通过下面API返回需要的, 可以见 data输入
data输入
 返回数据
返回数据
