Anaconda和Miniconda都是针对数据科学和机器学习领域的Python发行版本,它们包含了许多常用的数据科学包和工具,使得安装和管理这些包变得更加简单。
解决了几个痛点:
- 不同python环境的切换(类似VirtualEnv)
- 高效的包管理工具(类似pip,特别是在Windows上好用)
Anaconda是一个全功能的Python发行版本,由Anaconda, Inc.(前称Continuum Analytics)提供。
- 它包含了Python解释器以及大量常用的数据科学、机器学习和科学计算的第三方库和工具,如NumPy、Pandas、Matplotlib、SciPy等。
- Anaconda还包含一个名为Conda的包管理器,用于安装、更新和管理这些库及其依赖项。
- Anaconda发行版通常较大(500MB),因为它预装了许多常用的包,适用于不希望从头开始搭建环境的用户。
Miniconda是Anaconda的轻量级版本(50MB),它也由Anaconda, Inc.提供。
- 与Anaconda不同,Miniconda只包含了Python解释器和Conda包管理器,没有预装任何其他包。这意味着用户可以根据自己的需求手动选择要安装的包,从而实现一个精简而高度定制化的Python环境。
- 对于希望从零开始构建数据科学环境或需要更细粒度控制的用户,Miniconda是一个很好的选择。
Install miniconda
According to the official website,
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
# choose local path to install, maybe ~/.local
# init = yes, will auto modified the .zshrc to add the miniconda to PATH
# If you'd prefer that conda's base environment not be activated on startup,
# set the auto_activate_base parameter to false:
conda config --set auto_activate_base false
you need to close all terminal(all windows in one section including all split windows), and reopen a terminal will take effect;
Python on windows
超时报错:CondaHTTPError: HTTP 000 CONNECTION FAILED for url <https://repo.anaconda.com/pkgs/main/linux-64/repodata.json>
面对如下报错
> conda create -n opensora-t00906153 python=3.8 -y
Channels:
- defaults
Platform: linux-64
Collecting package metadata (repodata.json): failed
CondaHTTPError: HTTP 000 CONNECTION FAILED for url <https://repo.anaconda.com/pkgs/main/linux-64/repodata.json>
Elapsed: -
An HTTP error occurred when trying to retrieve this URL.
HTTP errors are often intermittent, and a simple retry will get you on your way.
If your current network has https://repo.anaconda.com blocked, please file
a support request with your network engineering team.
'https//repo.anaconda.com/pkgs/main/linux-64'
修改~/.condarc
ssl_verify: true
show_channel_urls: true
channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- conda-forge
如果还是有超时错误,多半是下载多了被拦截
通过 curl -v http://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ 检查是不是请求被阻拦了。
可以换成科大源或者default 源。
- https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
- https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
# 激活环境(base),路径为指定的 conda 安装路径下的 `bin/activate` 文件
source /home/m00876805/anaconda3/bin/activate
# 或者 conda init zsh
# 使用以下命令创建一个名为"myenv"的虚拟环境(您可以将"myenv"替换为您喜欢的环境名称):
conda create --name myenv python=3.8
# list existed env
conda env list
/home/m00876805/anaconda3/bin/conda env list
# 查看具体环境的详细信息
conda env export --name <env_name>
# 激活,退出
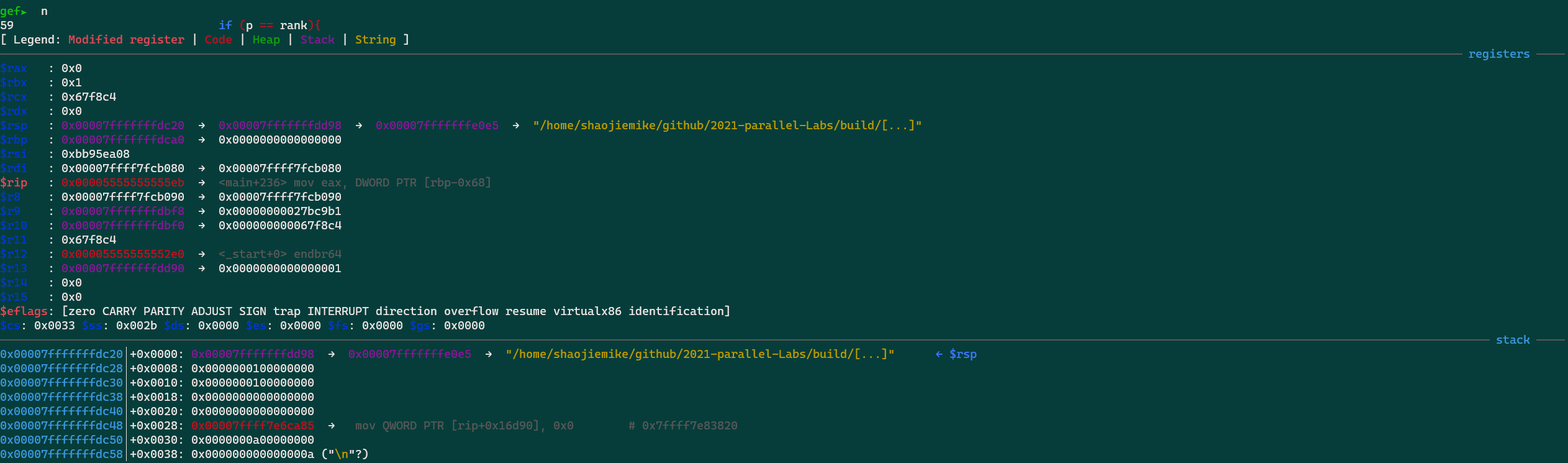
conda activate name
conda deactivate name
- 目的:
conda pack 用于将现有的 Conda 环境打包成一个压缩文件(如 .tar.gz),便于在其他系统上分发和安装。
- 打包内容: 打包的内容包括环境中的所有依赖、库和包(定制修改包),通常用于在不使用 Anaconda 或 Miniconda 的系统上还原环境。
- 恢复方式: 打包后的环境可以解压缩到指定位置,之后运行
conda-unpack 来修复路径,使其在新环境中正常工作。
conda-pack 可以将 Conda 环境打包成一个 .tar.gz 文件,以便于跨机器或系统移动和还原环境。以下是使用 conda-pack 打包和还原环境的步骤:
假设要打包的环境名为 my_env:
conda pack -n my_env -o my_env.tar.gz
这会在当前目录生成一个 my_env.tar.gz 文件。你可以将这个文件复制到其他系统或机器上解压还原。
在一个特定的 conda 环境目录(例如 /home/anaconda3)下还原和激活打包的环境,可以按以下步骤操作:
假设场景
- 目标
conda 激活路径:/home/anaconda3/bin/activate
- 打包文件:
my_env.tar.gz
- 解压后的环境名称:
my_env
步骤
- 解压文件到
conda 环境目录
首先,将打包文件解压到指定的 conda 环境目录下的 envs 目录:
mkdir -p /home/anaconda3/envs/my_env
tar -xzf my_env.tar.gz -C /home/anaconda3/envs/my_env --strip-components 1
这里的 --strip-components 1 会去掉 tar.gz 包中的顶层目录结构,使内容直接解压到 my_env 文件夹内。
- 激活并修复环境
激活该环境,并运行 conda-unpack 来修复路径:
source /home/anaconda3/bin/activate /home/anaconda3/envs/my_env
conda-unpack
现在,my_env 环境已在 /home/anaconda3 目录下的 envs 文件夹中完成还原,可以正常使用。
- 目的:
conda env export > freeze.yml 用于导出当前 Conda 环境的配置,包括所有安装的包和它们的版本信息,以 YAML 格式保存。
- 导出内容: 导出的内容主要是依赖项和版本号,而不包括包的实际二进制文件。适用于在相同或不同系统上重建环境。
- 恢复方式: 使用
conda env create -f freeze.yml 可以根据导出的 YAML 文件创建一个新环境。
conda list -e > requirements.txt 和 conda env export > freeze.yml
conda list -e > requirements.txt 和 conda env export > freeze.yml 都是用于记录和管理 Conda 环境中安装的包,但它们之间有一些关键的区别:
conda list -e > requirements.txt
conda install --yes --file requirements.txt
conda list -e
- 用途: 这个命令生成一个以简单文本格式列出当前环境中所有包及其版本的文件(
requirements.txt)。
- 内容: 列出的内容通常仅包括包的名称和版本,而不包含环境的依赖关系、渠道等信息。
- 安装方式: 通过
conda install --yes --file requirements.txt 可以尝试使用 Conda 安装这些列出的包。这种方式适合简单的包管理,但可能在处理复杂依赖时存在问题。
conda env export
- 用途: 这个命令生成一个 YAML 文件(
freeze.yml),它包含了当前环境的完整配置,包括所有包、版本、渠道等信息。
- 内容: 导出的 YAML 文件包含了完整的依赖关系树,可以确保在重建环境时完全匹配原始环境的状态。
- 安装方式: 通过
conda env create -f freeze.yml 可以根据 YAML 文件创建一个新的环境,确保与原环境一致。
关系与总结
- 复杂性:
conda env export 更加全面和可靠,适合重建相同的环境;而 conda list -e 更简单,适合快速记录包。
- 使用场景: 对于需要准确重建环境的情况,使用
freeze.yml 是更好的选择;而对于简单的包列表管理,requirements.txt 可能足够用。
因此,如果你的目标是确保环境的一致性,使用 conda env export 和 freeze.yml 是推荐的做法;如果只是想快速记录并安装一组包,requirements.txt 是一个方便的选择。
在conda命令无效时使用pip命令来代替
while read requirement; do conda install --yes $requirement || pip install $requirement; done < requirements.txt
The double pipe (“||”) is a control operator that represents the logical OR operation. It is used to execute a command or series of commands only if the previous command or pipeline has failed or has returned a non-zero status code.
conda create -n 新环境名称 --clone 原环境名称 --copy
虽然是完全复制,但是pip install -e安装的包会因为源文件的改动而失效
pip install -e 是用于在开发模式下安装 Python 包的命令,允许你在不复制包文件的情况下,将项目源代码直接安装到 Python 环境中,并保持源代码与环境中的包同步更新。这对于开发过程中频繁修改和测试代码非常有用。
以下是 pip install -e 的使用方法:pip install -e /path/to/project
详细解释:
- /path/to/project:项目的根目录,通常包含 setup.py 文件。setup.py 文件定义了包的名称、依赖、入口点等信息。
- -e 选项:表示“可编辑安装”(editable),意味着它不会复制项目文件到 Python 环境的 site-packages 目录,而是创建一个符号链接,指向原始项目路径。这样你可以在原路径下修改源代码,Python 环境中的包会实时反映这些修改。
通过 pip freeze 命令更好地查看
- 通过
pip freeze 命令更好地查看:
如果你想明确区分哪些包是通过 pip install -e 安装的,可以使用 pip freeze 命令。与 pip list 不同,pip freeze 会将包的版本和安装源显示出来。对于 -e(editable mode)安装的包,pip freeze 会有特殊标记。
运行以下命令:
输出示例:
-e git+https://github.com/example/project.git@abc123#egg=my_project
numpy==1.21.0
requests==2.25.1
在这里,带有 -e 标记的行表示这个包是通过 pip install -e 安装的,后面跟的是包的源代码路径(例如 Git 仓库 URL 或本地路径),而不是直接列出包的版本号。
-
输出解析:
-
-e 标记:表示这个包是以开发模式安装的。
- 普通包:对于直接通过
pip install 安装的包(不是开发模式),它们会以 包名==版本号 的形式列出。
git URL 或本地路径:开发模式下安装的包会指向源代码的路径,通常是 git 仓库 URL 或本地路径(如果是通过本地文件系统安装的)。
https://blog.csdn.net/Mao_Jonah/article/details/89502380