IPCC Preliminary SLIC Optimization 2
chivier advise on IPCC amd_256
| 技术路线 | 描述 | 时间 | 加速比 | 备注 |
|---|---|---|---|---|
| Baseline | 串行程序 | 21872 ms | 1 | |
| 核心循环openmp | 未指定 | 8079ms | ||
| 核心循环openmp | 单节点64核 | 7690ms | 2.84 | |
| 换intel的ipcp | 基于上一步 | 3071 ms | 7.12 | |
| -xHOST | 其余不行,基于上一步 | 4012ms | ||
| -O3 | 基于上一步 | 3593ms |
node5
Intel(R) Xeon(R) Platinum 8153 CPU @ 2.00GHz
| 技术路线 | 描述 | 时间 | 加速比 | 备注 |
|---|---|---|---|---|
| Baseline | 串行程序 | 29240 ms | 1 | |
| 核心循环openmp | 未指定(htop看出64核) | 12244 ms | ||
| 去除无用计算+两个numk的for循环 | 080501 | 11953 ms 10054 ms | ||
| 计算融合(去除inv) | 080502 | 15702 ms 14923 ms 15438 ms 11987 ms | ||
| maxlab openmp | 基于第三行080503 | 13872 ms 11716 ms | ||
| 循环展开?? | 14436 ms 14232 ms 15680 ms |
-xCOMMON-AVX512 not supports
Please verify that both the operating system and the processor support Intel(R) X87, CMOV, MMX, FXSAVE, SSE, SSE2, SSE3, SSSE3, SSE4_1, SSE4_2, MOVBE, POPCNT, AVX, F16C, FMA, BMI, LZCNT, AVX2, AVX512F, ADX and AVX512CD instructions.
Please verify that both the operating system and the processor support Intel(R) X87, CMOV, MMX, FXSAVE, SSE, SSE2, SSE3, SSSE3, SSE4_1, SSE4_2, MOVBE, POPCNT, AVX, F16C, FMA, BMI, LZCNT and AVX2 instructions
使用-xAVX,或者-xHOST 来选择可用的最先进指令集
Please verify that both the operating system and the processor support Intel(R) X87, CMOV, MMX, FXSAVE, SSE, SSE2, SSE3, SSSE3, SSE4_1, SSE4_2, POPCNT and AVX instructions.
-fast bugs
ld: cannot find -lstdc++
ld: cannot find -lstdc++
/public1/soft/intel/2020u4/compilers_and_libraries_2020.4.304/linux/compiler/lib/intel64_lin/libiomp5.a(ompt-general.o): In function `ompt_pre_init':
(.text+0x2281): warning: Using 'dlopen' in statically linked applications requires at runtime the shared libraries from the glibc version used for linking
/var/spool/slurm/d/job437118/slurm_script: line 23: ./SLIC_slurm_intel_o3: No such file or directory
AMD EPYC 7~~2
icpc -Ofast -march=core-avx2 -ipo -mdynamic-no-pic -unroll-aggressive -no-prec-div -fp-mode fast=2 -funroll-all-loops -falign-loops -fma -ftz -fomit-frame-pointer -std=c++11 -qopenmp SLIC_openmp.cpp -o SLIC_slurm_intel_o3
后续优化
基于核心的openmp并行
去除无用计算
计算融合(减少访存次数)
- 将inv去除(效果存疑)
- maxlab openmp并行(由于不是计算密集的,是不是要循环展开)
需要进一步的研究学习
暂无
遇到的问题
暂无
开题缘由、总结、反思、吐槽~~
参考文献
无
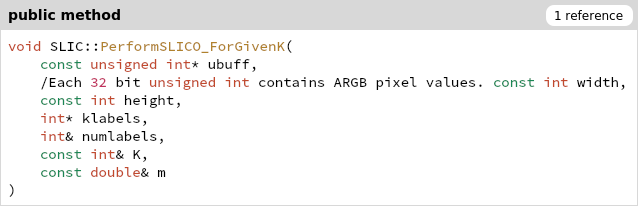 一开始所有的RGB颜色在ubuff里,klabel存分类结果
一开始所有的RGB颜色在ubuff里,klabel存分类结果
 计算出的全体edges,只有一部分在后面一个地方用了196个中心以及周围8个节点。
计算出的全体edges,只有一部分在后面一个地方用了196个中心以及周围8个节点。
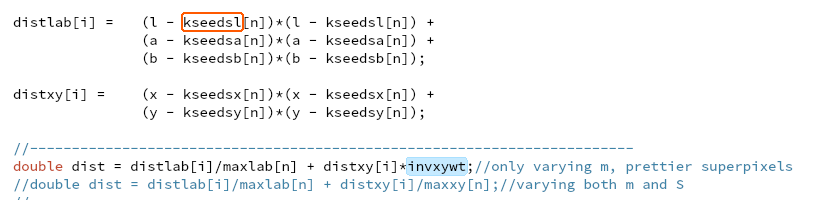

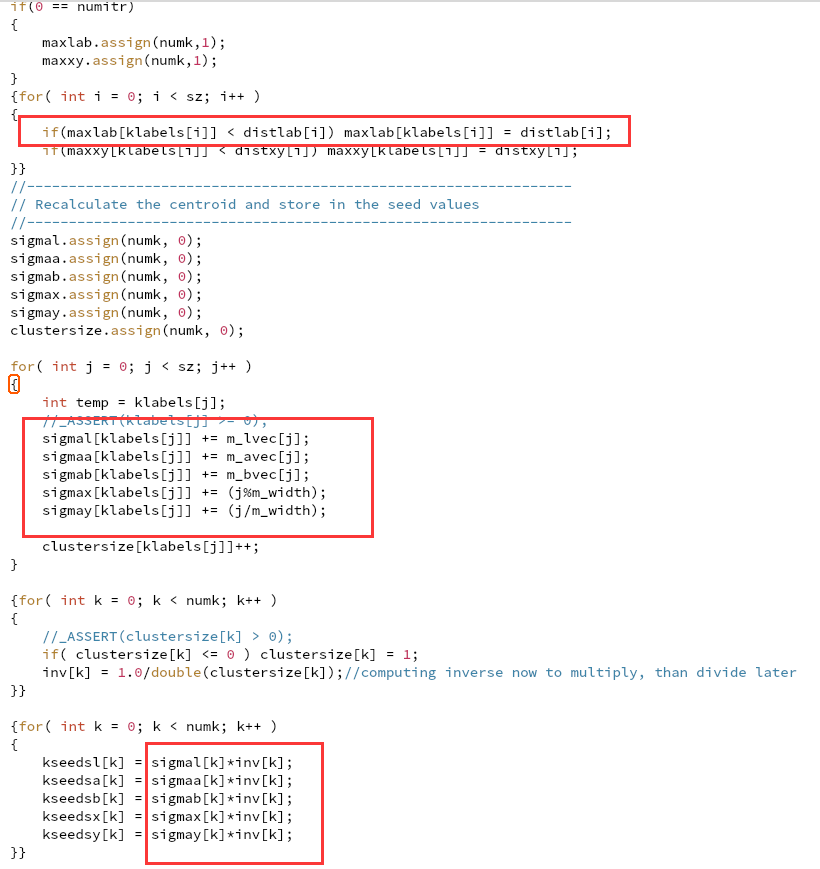
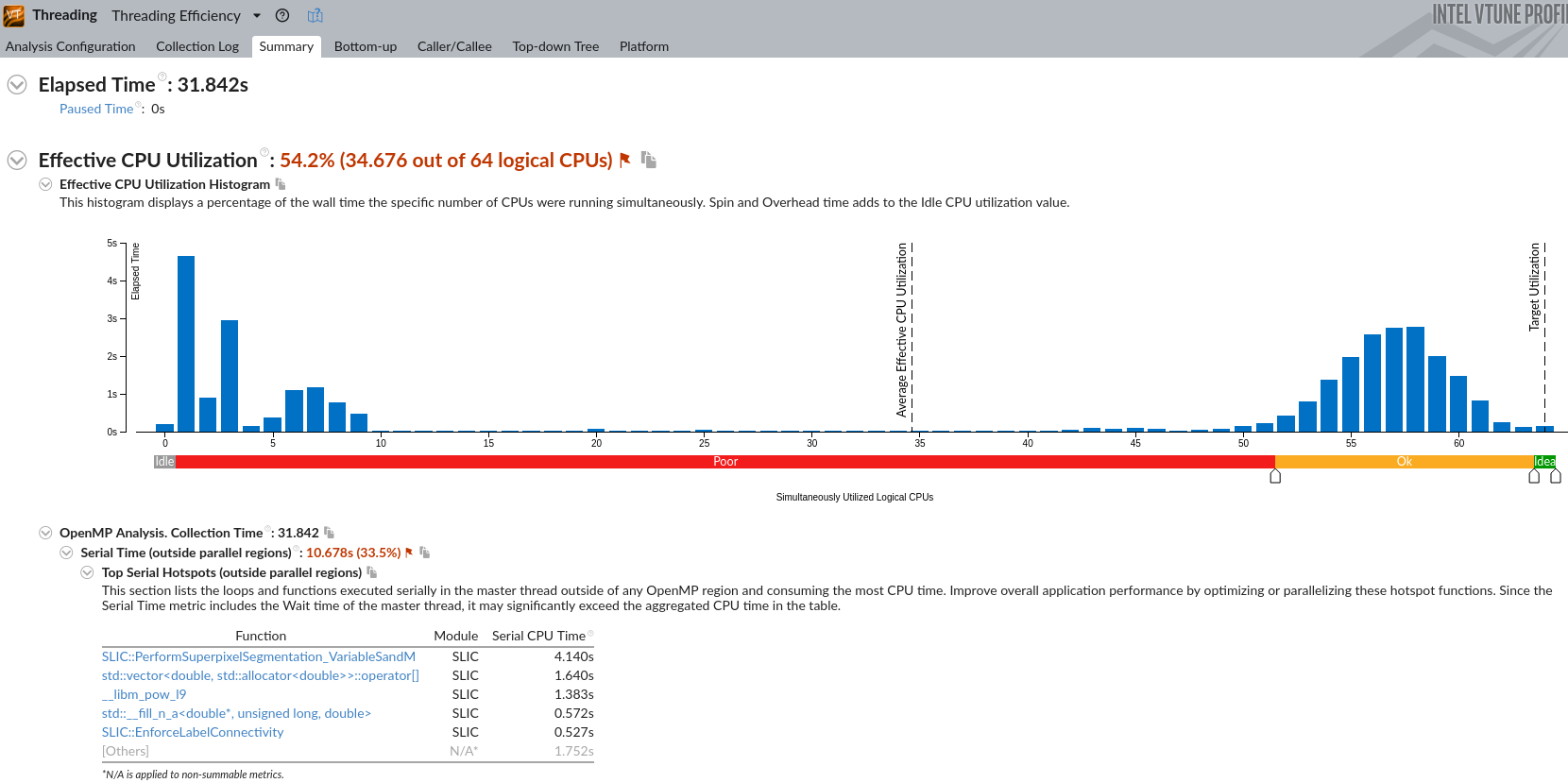
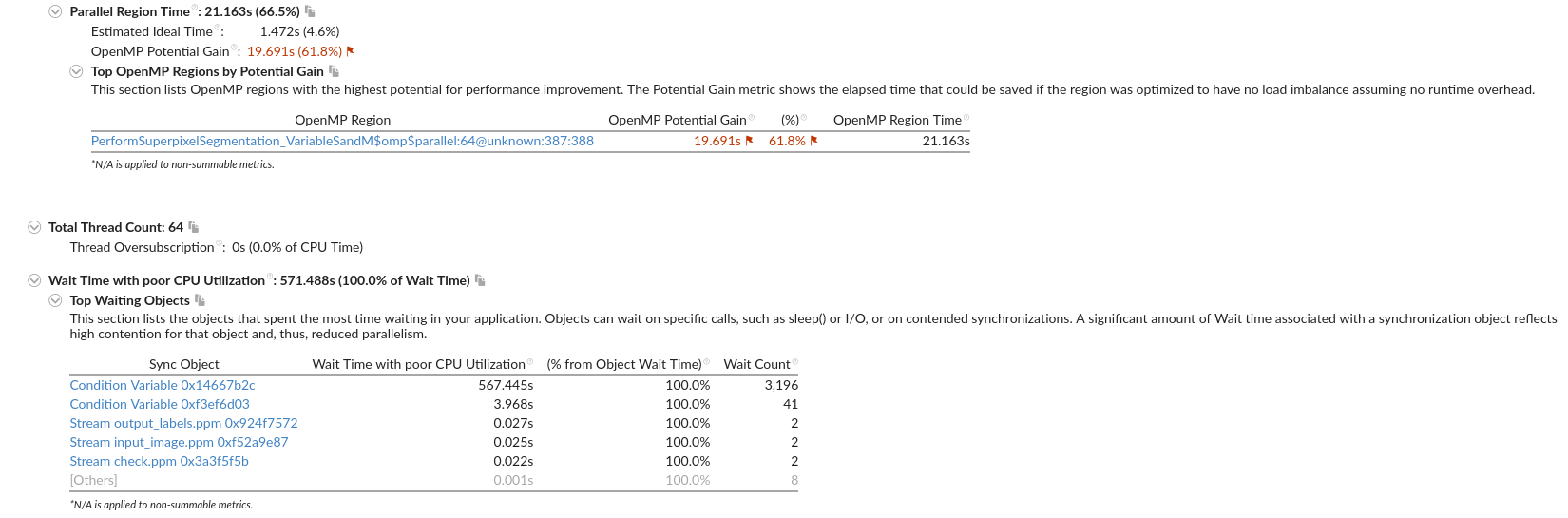
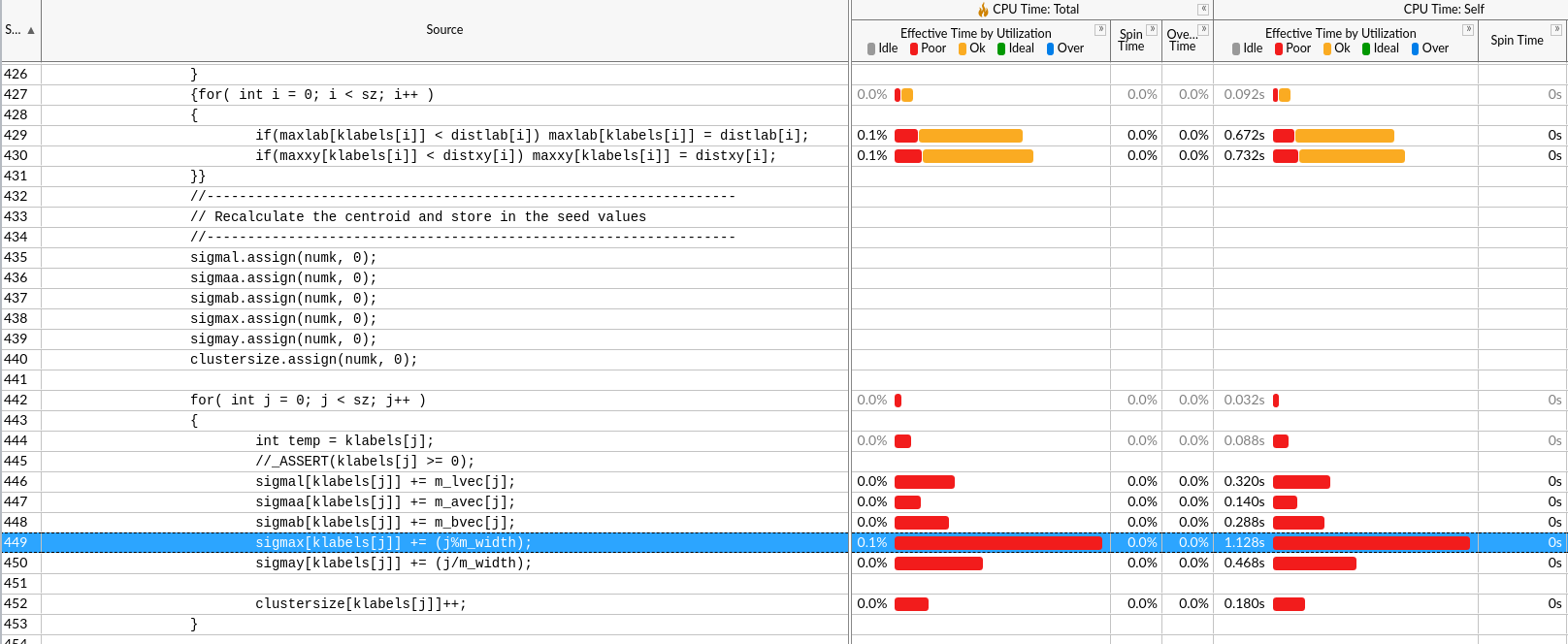












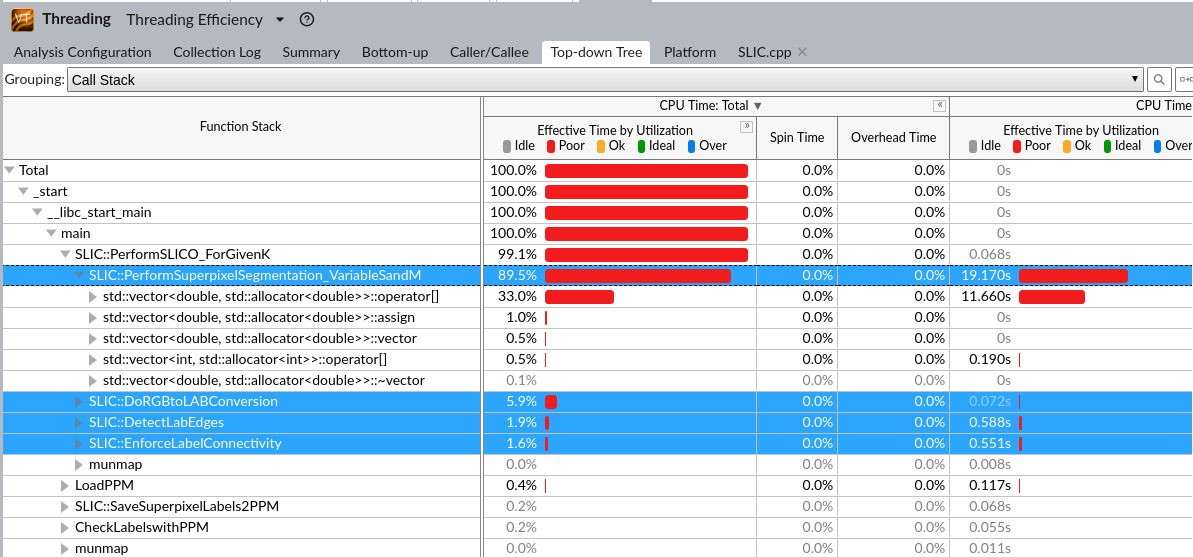


 没什么用
没什么用

 由于是2S*2S,相邻中心的周围区域是有一部分重叠的(如图中黄色荧光笔区域),相当于聚类到各个中心,注意由于中心对自己dist=0,是不可能某一中心距离其他中心更近。
由于是2S*2S,相邻中心的周围区域是有一部分重叠的(如图中黄色荧光笔区域),相当于聚类到各个中心,注意由于中心对自己dist=0,是不可能某一中心距离其他中心更近。




 X,Y,Z会分别除以0.950456、1.0、1.088754。
X,Y,Z会分别除以0.950456、1.0、1.088754。