IPCC Preliminary SLIC Optimization 5: MPI + OpenMP
AMD
| 技术路线 | 描述 | 总时间 | 加速比 | 备注 |
|---|---|---|---|---|
| Baseline | 串行程序 | 161.7s s | 1 | |
| more3omp | 前面都是可以证明的有效优化 omp_num=32 | 14.08s | ||
| more3omp | 前面都是可以证明的有效优化 omp_num=64 | 11.4s | ||
| deletevector | 把sz大小的3个vector,移到全局变量,但是需要提前知道sz大小/声明一个特别大的 | 10.64s | 可以看出写成全局变量也不会影响访问时间 | |
| enforce_Lscan | IPCC opt 4 | 8.49s | 19 | |
| enforce_Lscan_MPI_intel | intel icpc | 3.8s | 42.36 | |
| Baseline2-max ppm | 1.2GB ppm 10*1024*40*1024 | 928s | ||
| enforce_Lscan | Baseline2 | 43.79s | 21.2 | |
| enforce_Lscan_MPI_intel | intel icpc + 双节点两个时间 + MPI(DoRGBtoLABConversion) | 18.8s / 20s | 46.4 | |
| enforce_Lscan_intel | intel icpc + 单节点 | 15.8s | 58.74 | MPI(DoRGBtoLABConversion)负优化了2s |
| manualSIMD | 13.9s | |||
| stream | 13.6s | |||
| vec2mallocOMP | 11.0s | |||
| mmap | 10.6s | |||
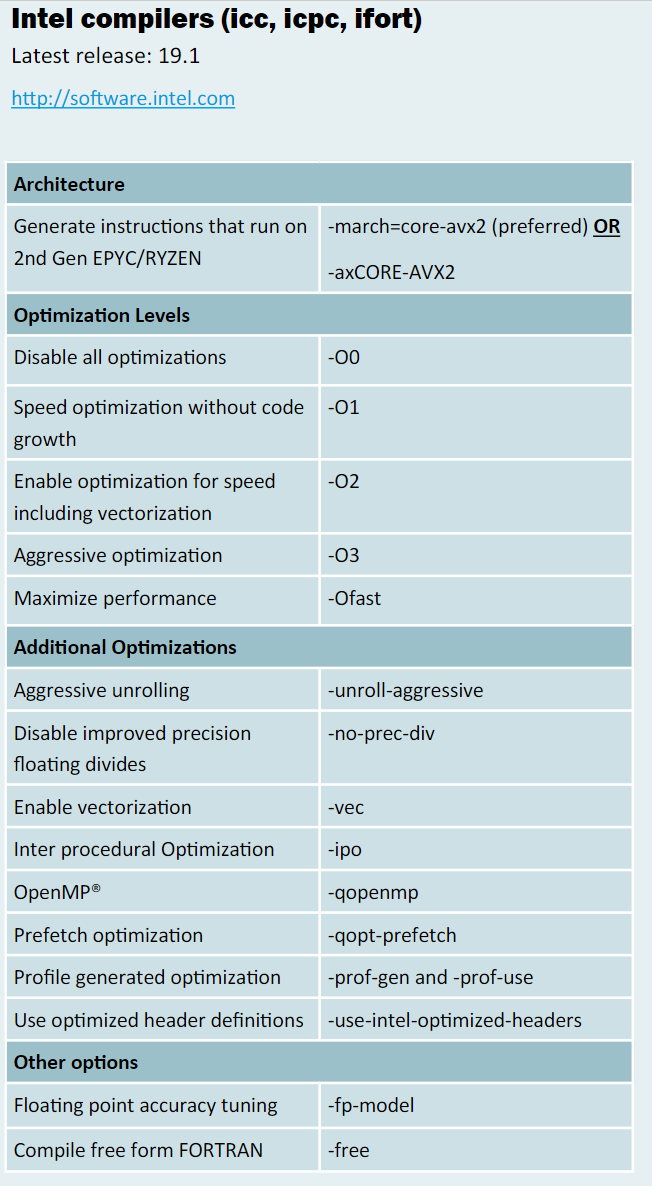
| + -O3 | enforce_Lscan_intel | 16.2s | ||
| + -xHost | 结果不对 | 17.8s | ||
| -Ofast | 16.9s | |||
| -ipo | 15.9s | |||
| -O3 -ipo | 16.8s | |||
| -O3 -march=core-avx2 -fma -ftz -fomit-frame-pointer | 16.0s | |||
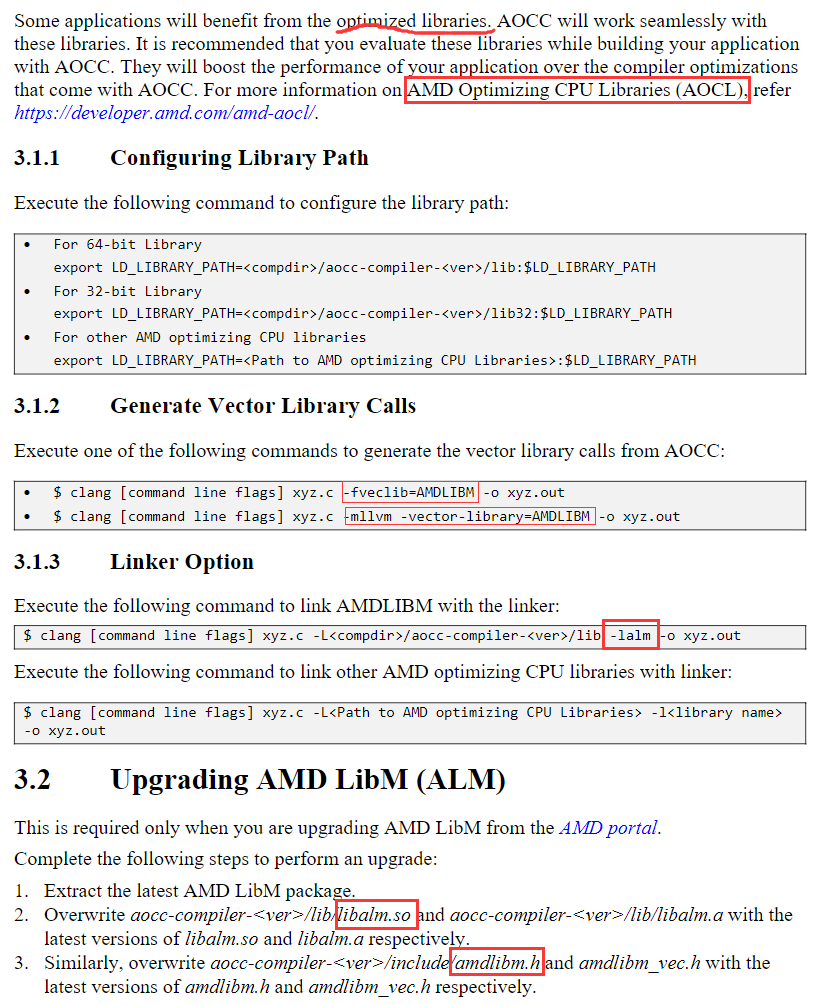
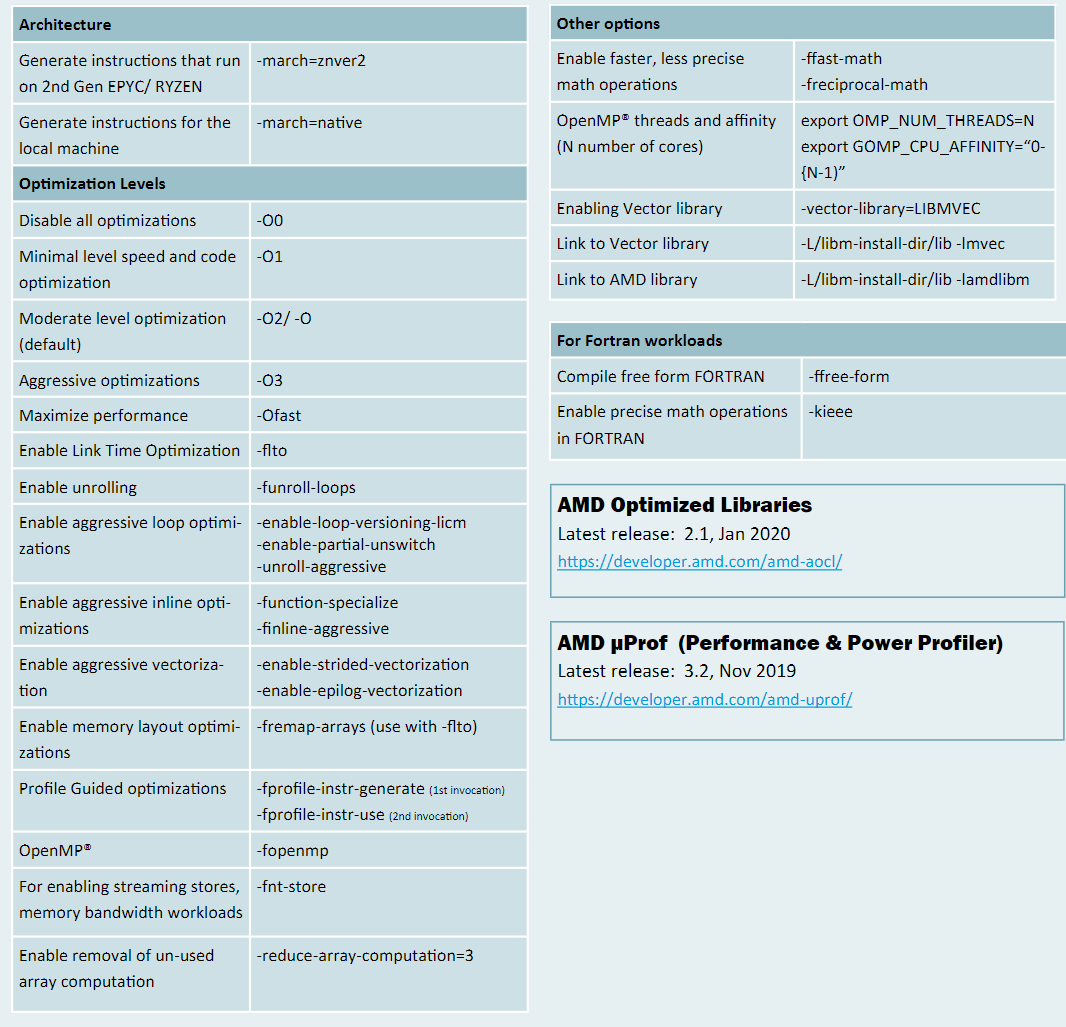
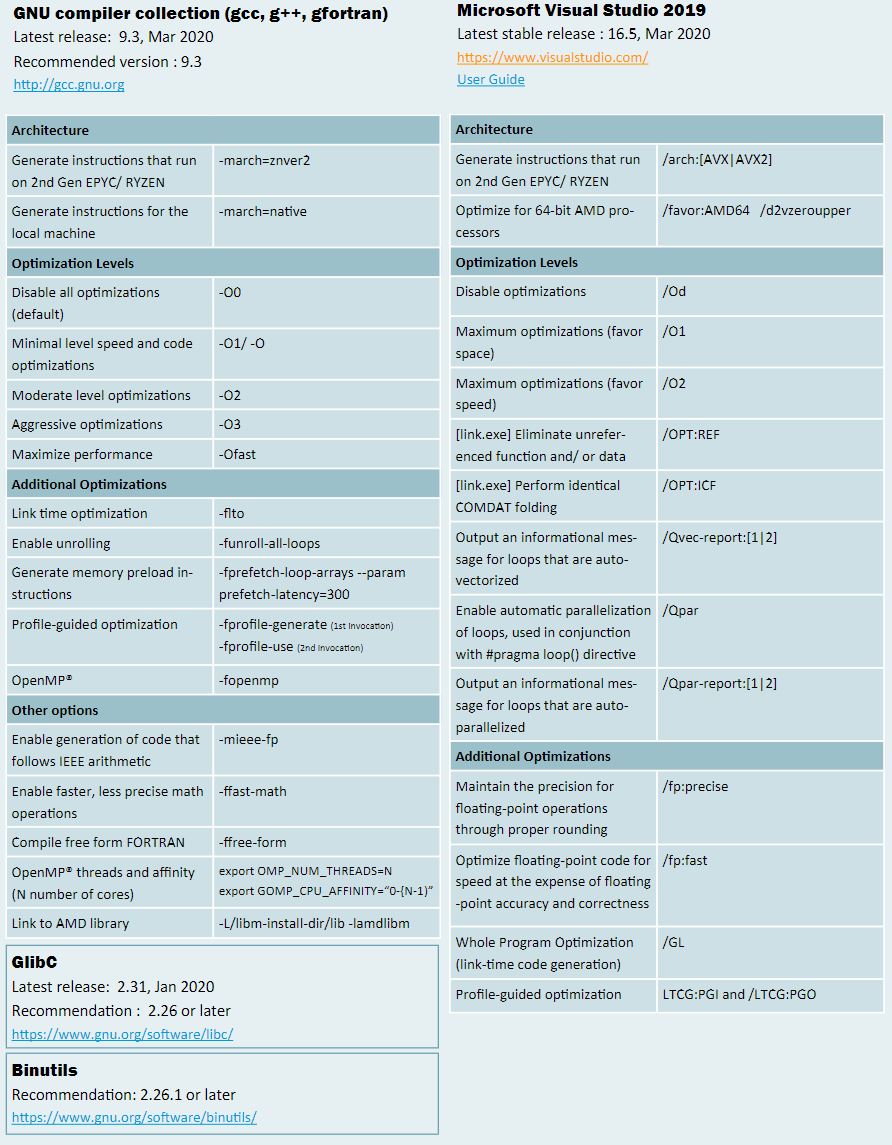
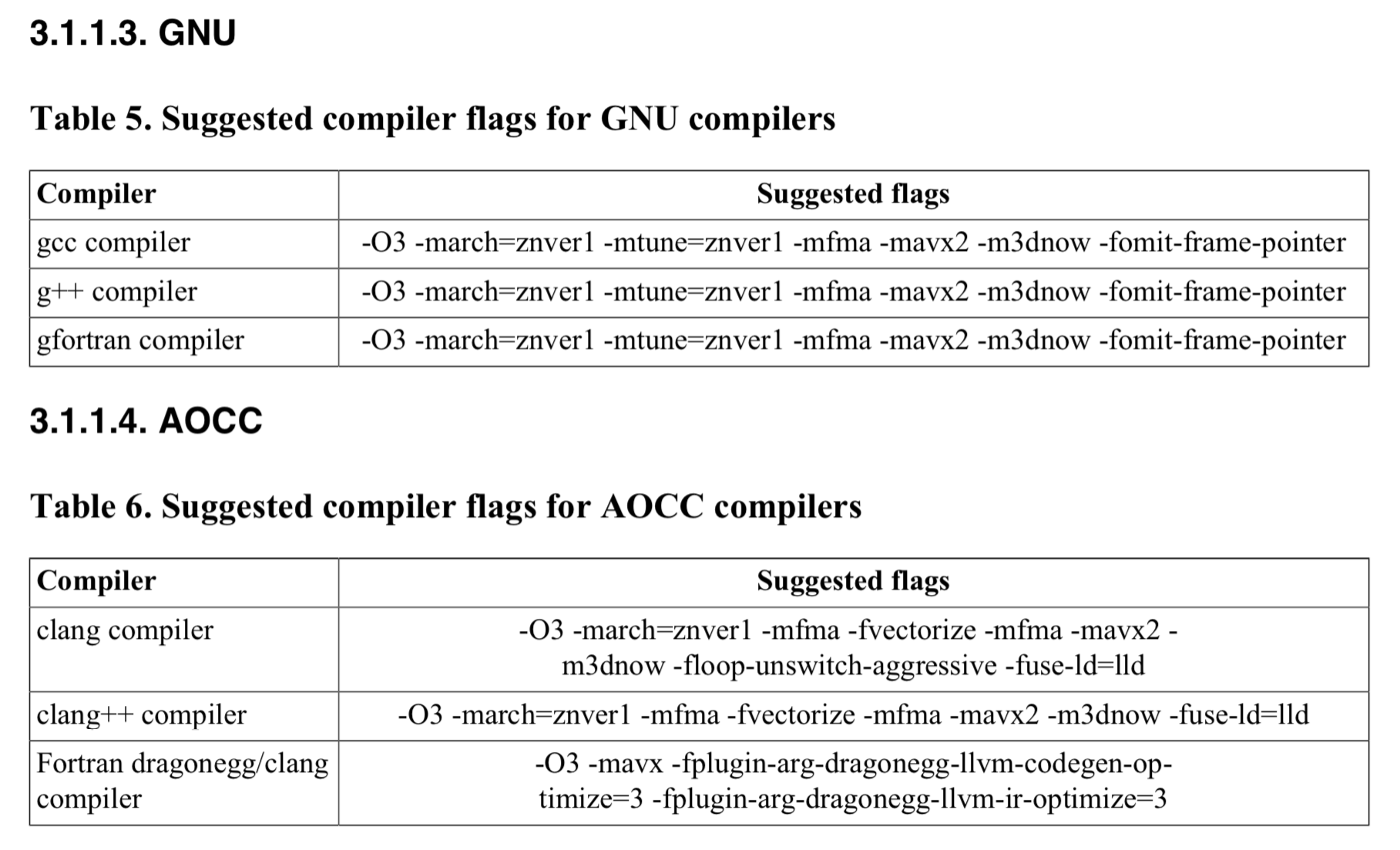
| g++ suggested options | -O3 -march-znver1 -mtune=znver1 -fma -mavx2 -m3dnow -fomit-frame-pointer | 18.1s | ||
| g++ suggested options2 | -O3 -march-znver2 -mtune=znver2 -fma -mavx2 -m3dnow -fomit-frame-pointer | 19.79s | ||
| g++ -Ofast | 16.9s | |||
| aocc -Ofast | 16.3s | |||
| aocc suggested options | 16.2s |
MPI编程
由于是打算两节点两进程MPI,虽然没有OpenMP的共享内存,但是也希望通信能少一点。
PerformSuperpixelSegmentation_VariableSandM
下面关于同步区域的想法是错误的: 因为中心点移动会十分不确定,所以全部同步是最好的。
- 第一部分core的思路
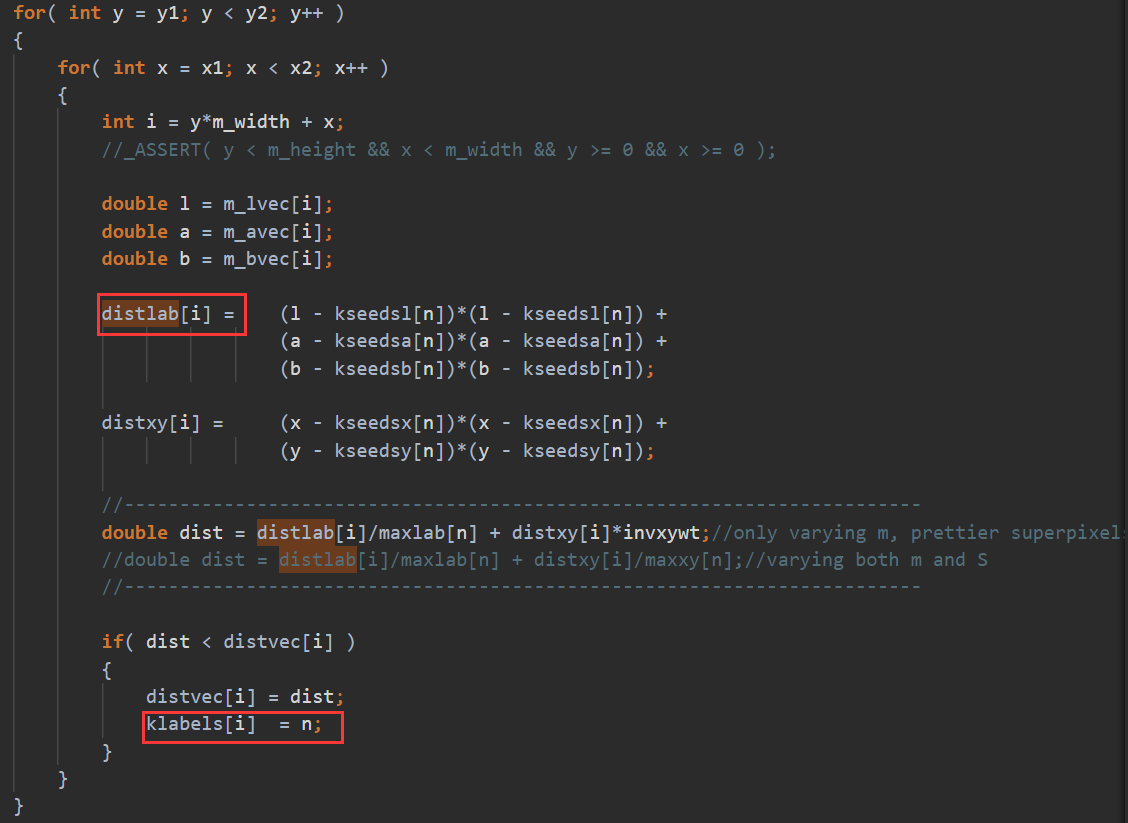
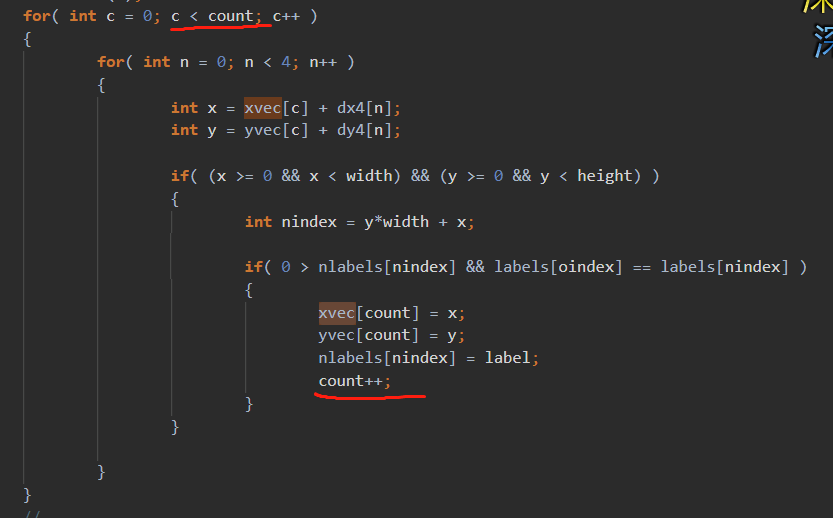
- 上面numk个中心点直接一分为2,需要同步的是中间相连的$\(width*(3S)\)$个中心点(由于PerturbSeeds扰动,而且offset比较大,应该是中间相邻的2排,大约3S的高度的区域,上下1.5S高度)。
- distlab需要后面覆盖前面的(当然是计算了的区域)。klabels是取distvec更小对应的那个,应该要写个自定义归约。
- numk个中心点有奇数行和偶数行,经过思考后是一样的。
- 第二部分各中心maxlab的思路(从sz里提取numk个中心的数据)

- sz直接一分为2,最小同步的话,就是中间相邻中心点maxlab要max归约。
- 第三部分计算sz里的numk个中心点的质心和
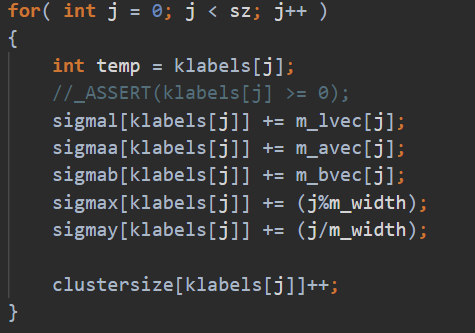
- 同理,sz直接一分为2,vector相加归约同步
DoRGBtoLABConversion 0.61s
用MPI_Send写,但是一开始没注意是阻塞的,但是为什么这么慢呢?
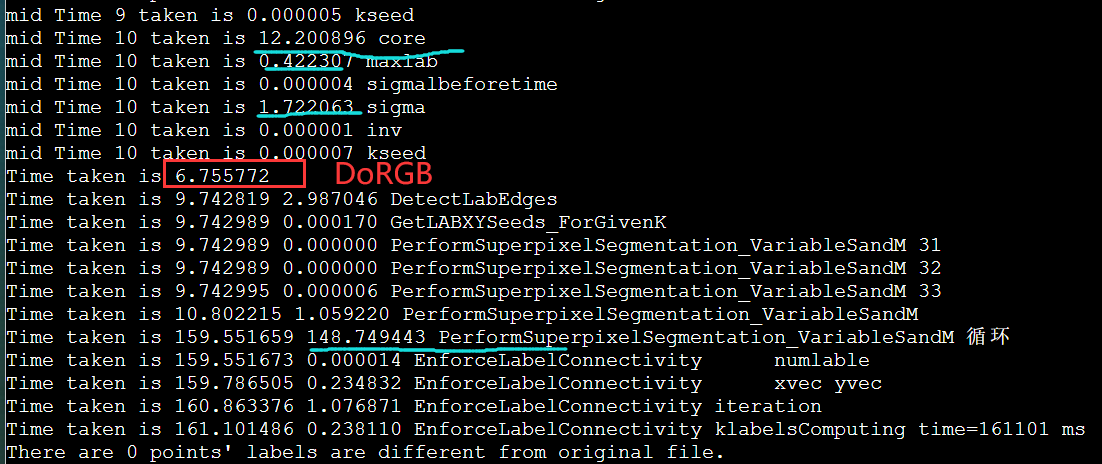
对比之前的enforce_Lscan 8.49s
- DoRGBtoLABConversion 0.56s
- PerformSuperpixelSegmentation_VariableSandM 5.52s
- core 0.53s
- maxlab 0.02s
- sigma 0.03s
- DetectLabEdges 0.31s
- EnforceLabelConnectivity 1.19s
- PerformSuperpixelSegmentation_VariableSandM 0.88s
慢了10~20倍猜测:
1. printf的原因? no 不打印也一样
2. omp_num的值不对? maybe no
3. 不在两个节点上? no 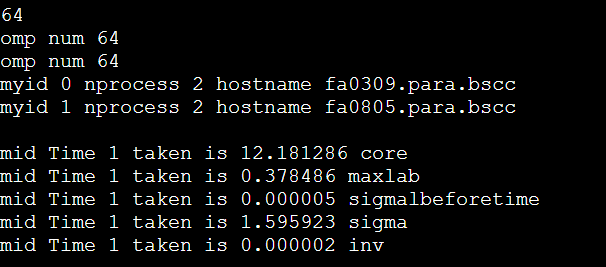 4. g++ mpicxx? no
5. 没有用IB ? 貌似也不是
6. openmpi不支持openmp ? 探究方向
4. g++ mpicxx? no
5. 没有用IB ? 貌似也不是
6. openmpi不支持openmp ? 探究方向
好像是openmp没正常运行omp_num的值为 1,32,64时间都一样。感觉是混合编程的编译问题, 而且好像是假Openmp并行,哪里有锁的样子。突然想起来,Quest的混合变成cmake需要打开multthread类似的支持,但是这里并没用。
好像也不是mpi_init_thread的问题
尝试intelmpi
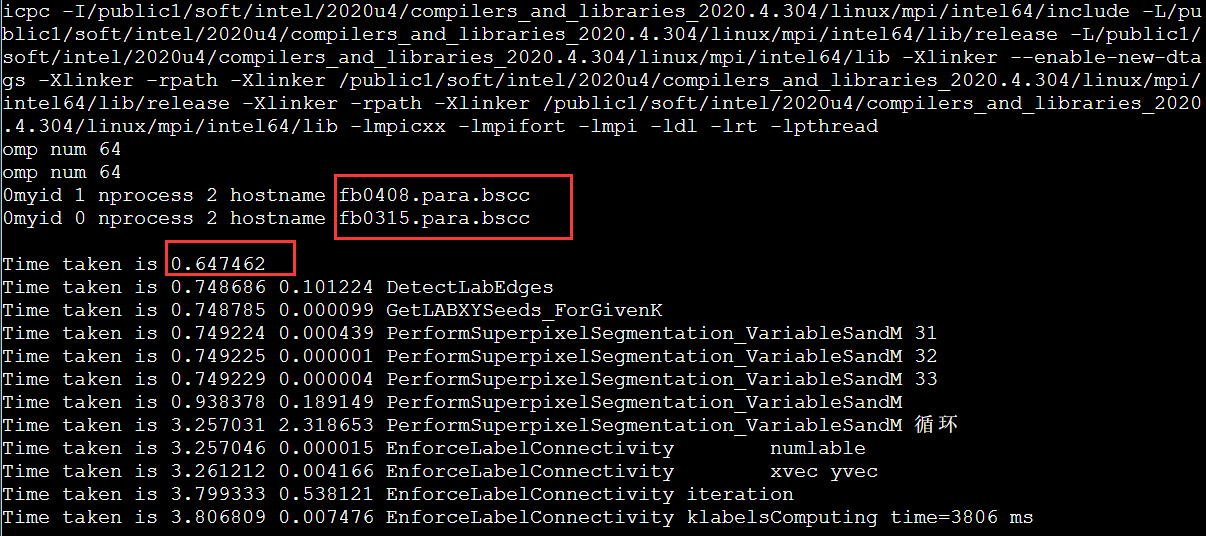
果然有奇效。(结果是对的,后面我没截图了)。看到这里,可能你会觉得这个问题是OpenMPI有地方不支持openmp。但是后面有神奇的事情,如果NODELIST是fa,而不是fb就不能跑,会直接卡住。😰
首先没找到官方手册说明不同,然后研究一下这两个分区的不同。好吧从IB,cpu,内存都没区别。
限制nodelist再跑一遍。
加上打印时间,用fb分区
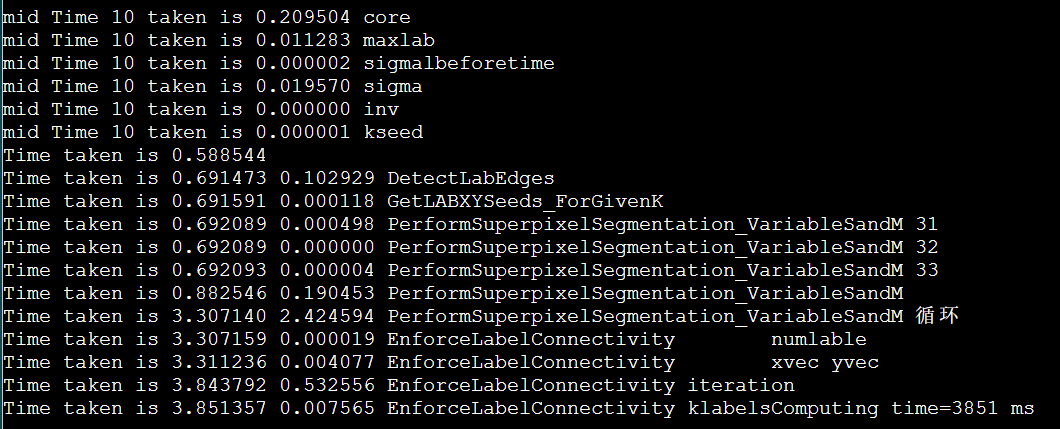
这个问题又没有了,但是fa分区由于经常跑可能会热一些。
最大的ppm例子
由于时间已经进5s了。所以我们需要更大的例子,再讨论2节点的开销收益,之前的例子是256034000。
这里生成了1024040960的ppm.再大ppm程序的数组都申请不到栈空间了,需要重新数据结构。
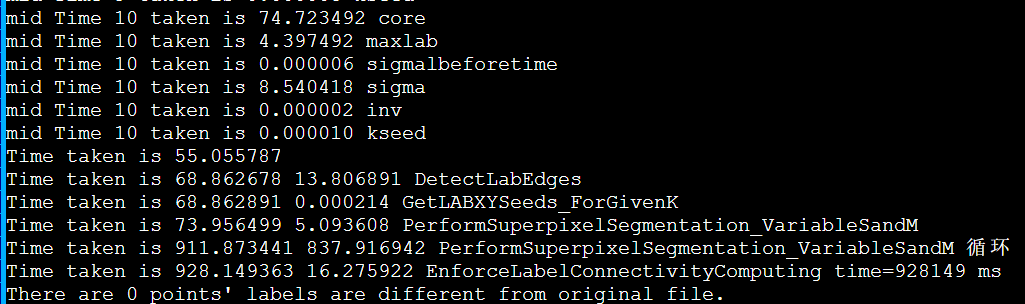
重跑当前最快的enforce_Lscan
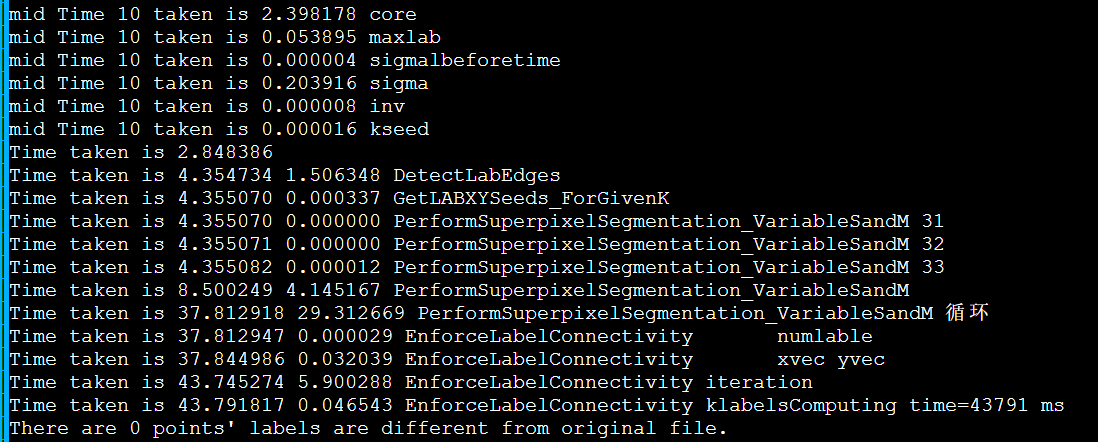
icpc + enforce_Lscan_MPI(DoRGBtoLABConversion)
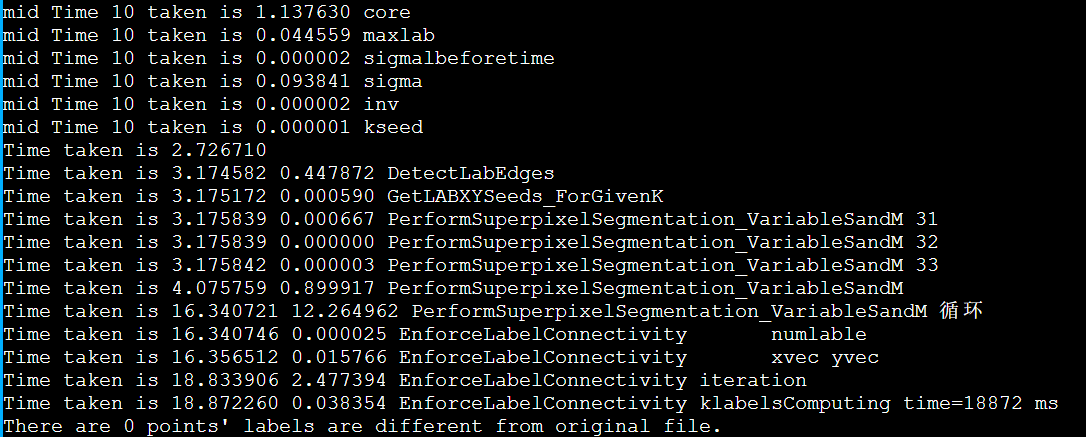 icpc + enforce_Lscan
icpc + enforce_Lscan
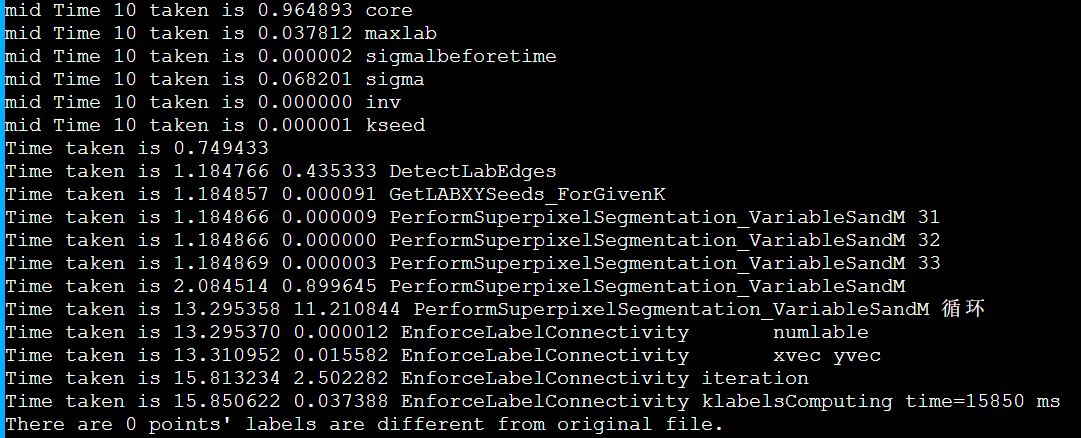 g++ suggested options
g++ suggested options
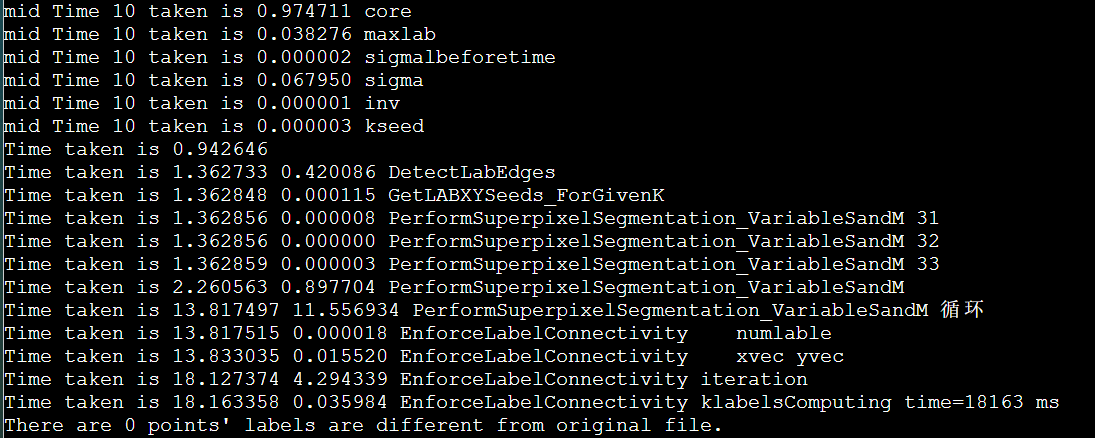 icpc + manualSIMD + lessLscan
icpc + manualSIMD + lessLscan
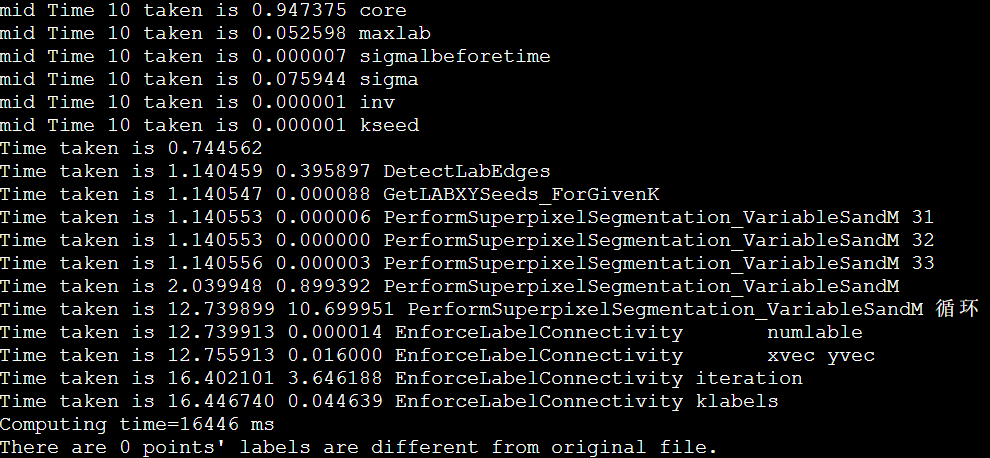 icpc + manualSIMD + LscanSimple
icpc + manualSIMD + LscanSimple
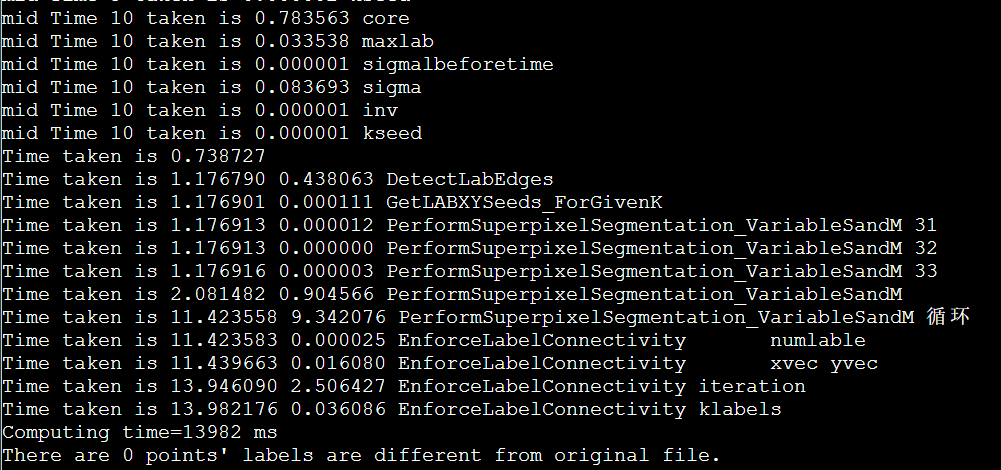 icpc + manualSIMD + LscanSimple + stream
icpc + manualSIMD + LscanSimple + stream
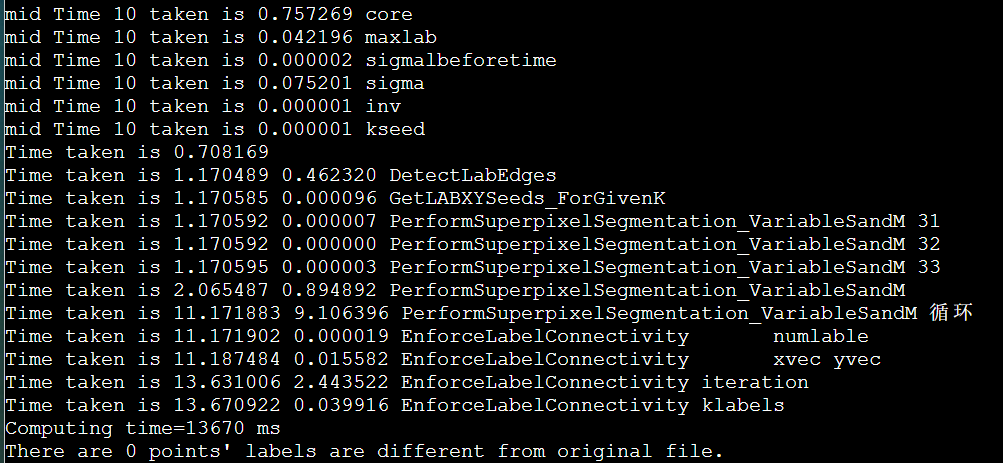 icpc + manualSIMD + LscanSimple + stream + mallocOMPinit
icpc + manualSIMD + LscanSimple + stream + mallocOMPinit
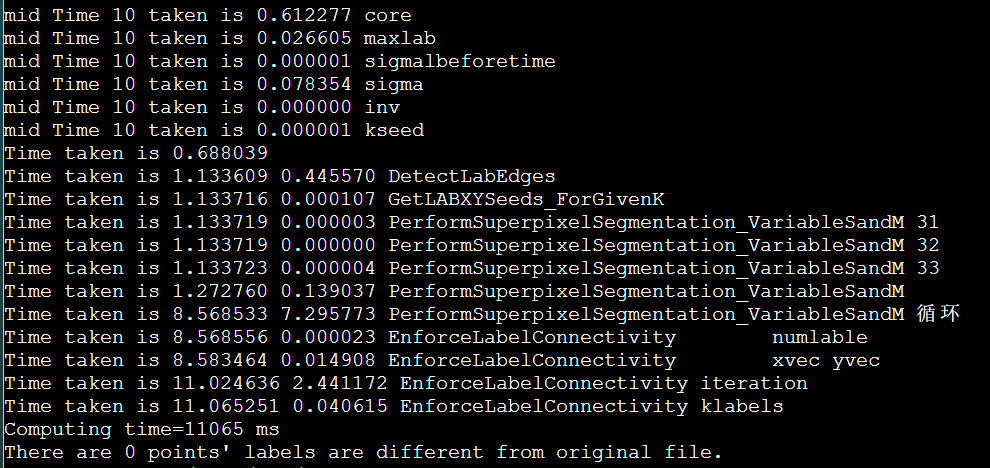 icpc + manualSIMD + LscanSimple + stream + mallocOMPinit + mmap
icpc + manualSIMD + LscanSimple + stream + mallocOMPinit + mmap
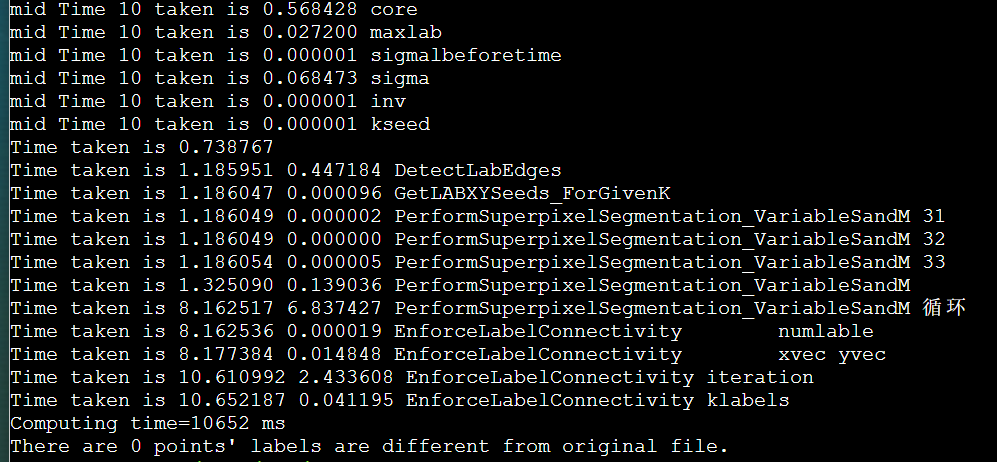 icpc + manualSIMD + LscanSimple + stream + mallocOMPinit + mmap + unrollLoop
icpc + manualSIMD + LscanSimple + stream + mallocOMPinit + mmap + unrollLoop
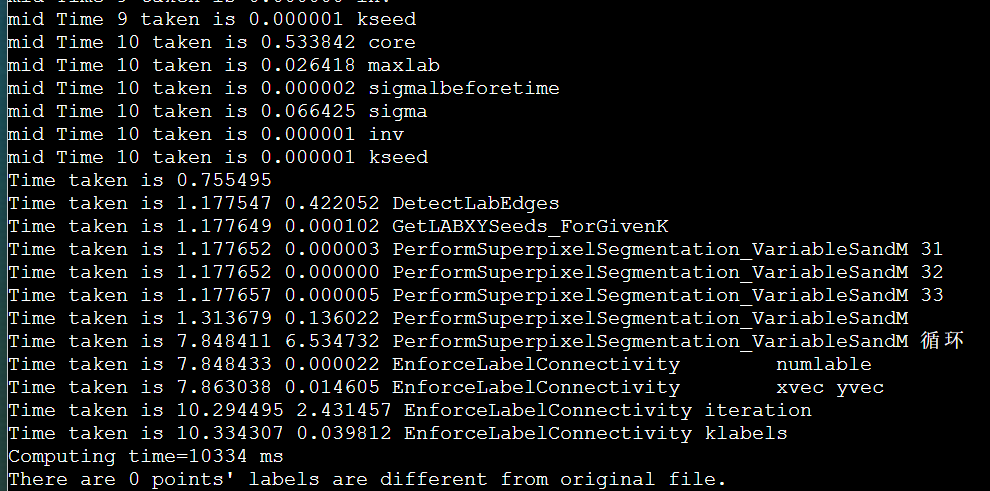
放弃的原因
https://www.bilibili.com/video/BV1a44y1q782 58mins-58min50s
需要进一步的研究学习
暂无
遇到的问题
- 混合编程写的有问题,双节点不快反慢。怎么写呢?
- 那段串行代码真的不能并行吗?
- 向量化为什么没有提升呢,是要循环展开吗?
姜师兄建议
- MPI非阻塞通信 gather reduce
- 手动向量化
开题缘由、总结、反思、吐槽~~
参考文献
无
 200~400行不等seg fault。
200~400行不等seg fault。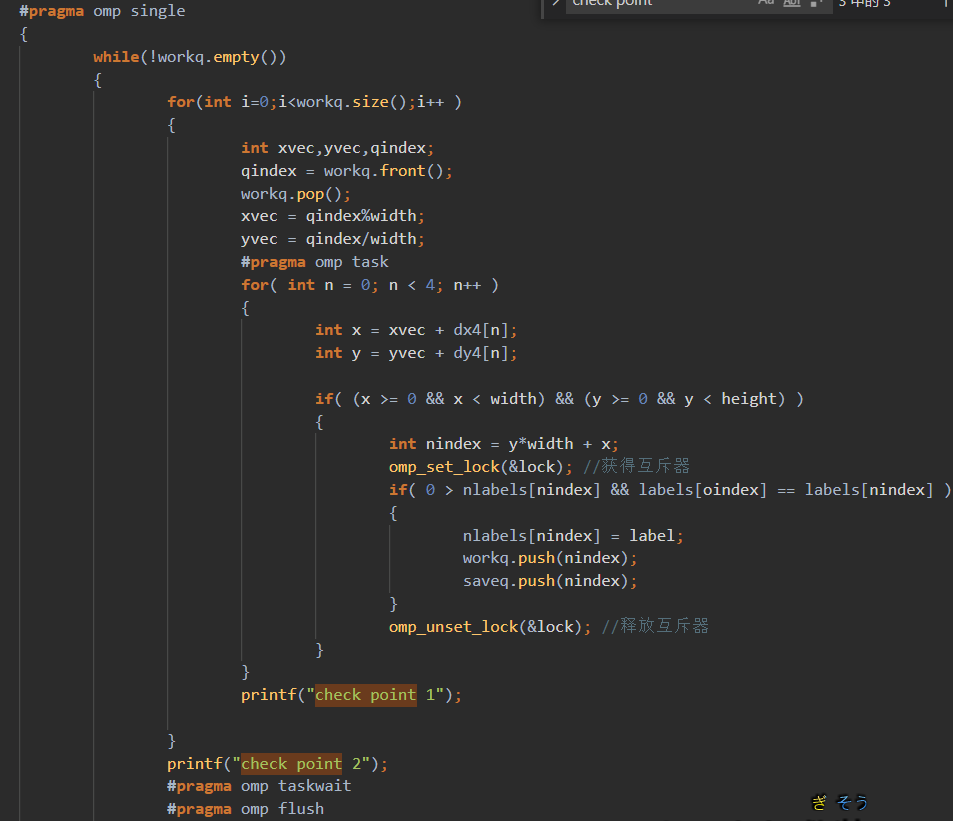 可以看出至少前面是正常的。
可以看出至少前面是正常的。
 多运行几次,有时候segfault,有时corruption,我服了。
多运行几次,有时候segfault,有时corruption,我服了。
 但是位置好像还是在上面的循环
但是位置好像还是在上面的循环
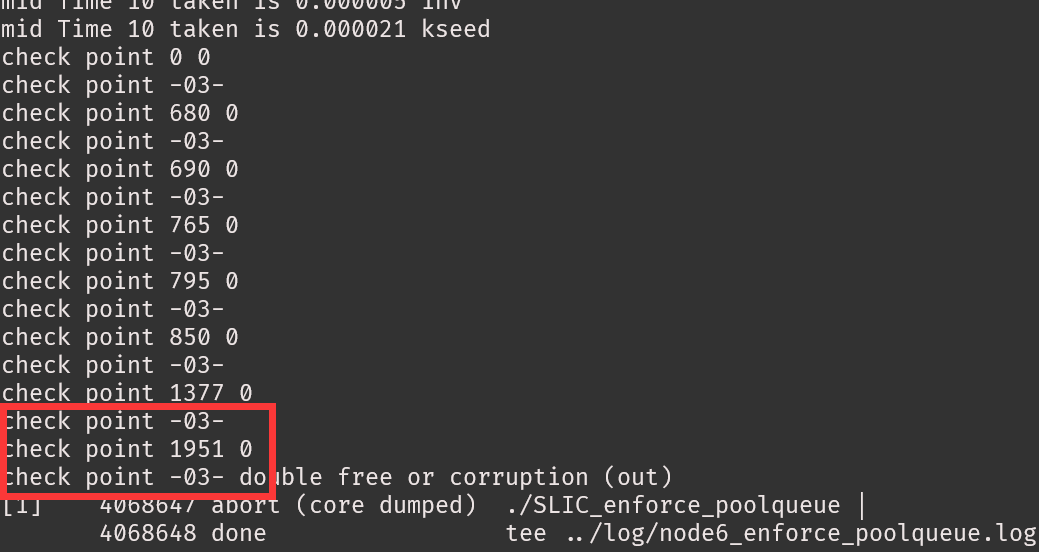 每次报错位置还不一样,但是迭代的点还是对的。
每次报错位置还不一样,但是迭代的点还是对的。
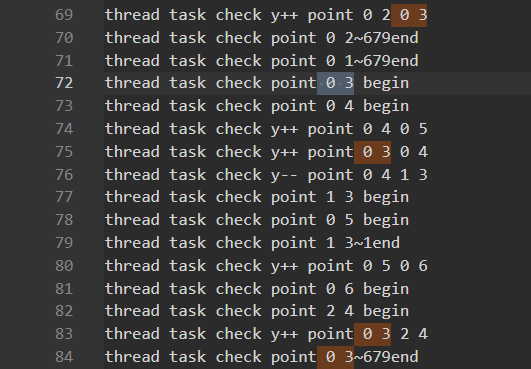 1. (0,2)调用(0,3),(0,3)调用(0,4)很正常。但是(0,3)竟然调用了(2,4),这说明(0,3)循环到(1,3)时,发现(1,4)是已经处理的,而(2,4)是未处理的。进一步说明了(0,4)在被(0,3)创建了之后,先一步循环到(1,4),并将其处理。
1. (0,2)调用(0,3),(0,3)调用(0,4)很正常。但是(0,3)竟然调用了(2,4),这说明(0,3)循环到(1,3)时,发现(1,4)是已经处理的,而(2,4)是未处理的。进一步说明了(0,4)在被(0,3)创建了之后,先一步循环到(1,4),并将其处理。

 2. (0,4)先循环到(1,4),反手还调用(1,3)。然后由于(0,3)调用了(2,4)。导致(0,4)循环到后面以为到(2,4)就截止了。
3. 虽然我说不出有什么问题,但是这不受控制的混乱调用,肯定不是我们想见的。
2. (0,4)先循环到(1,4),反手还调用(1,3)。然后由于(0,3)调用了(2,4)。导致(0,4)循环到后面以为到(2,4)就截止了。
3. 虽然我说不出有什么问题,但是这不受控制的混乱调用,肯定不是我们想见的。
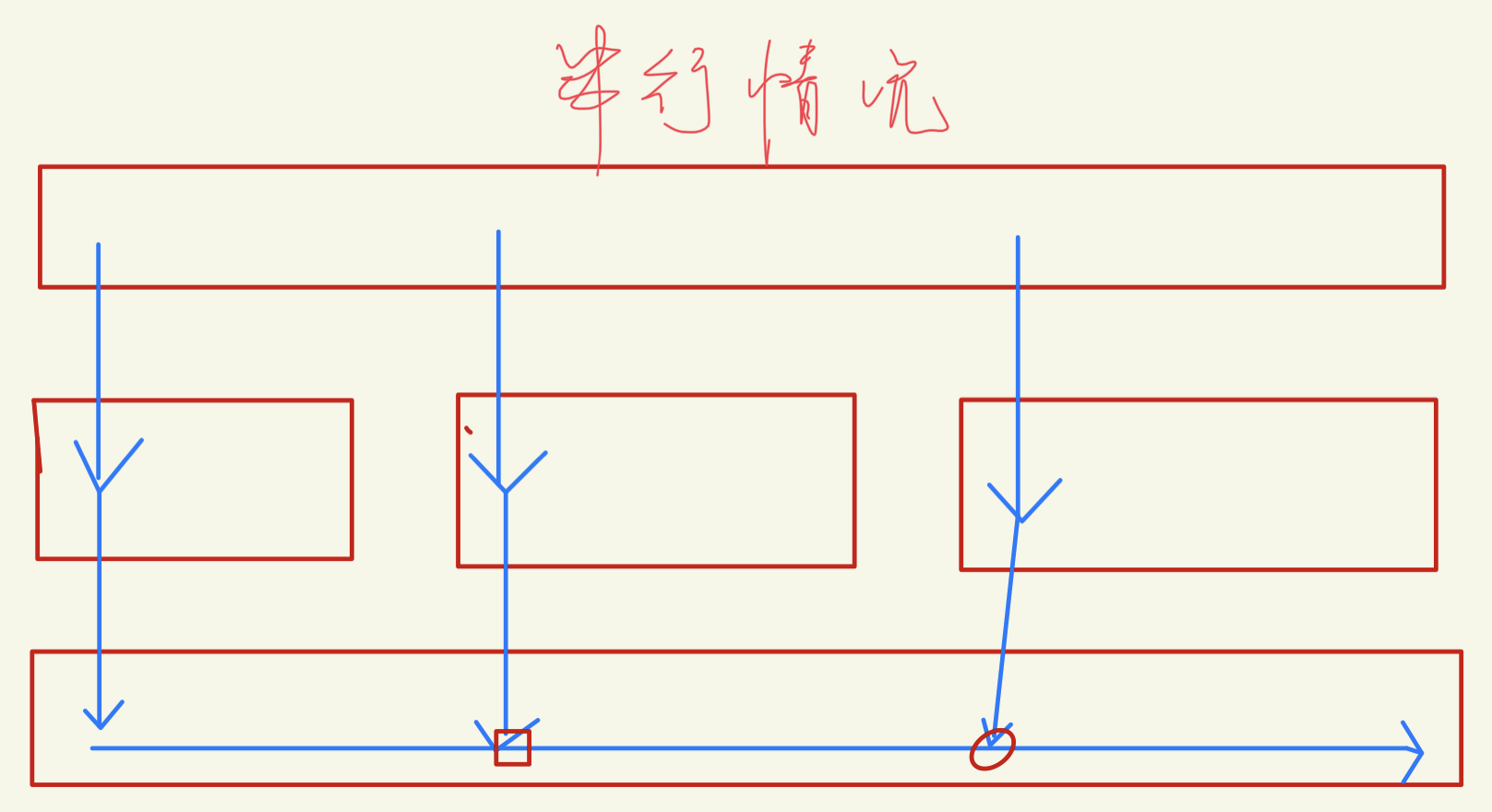
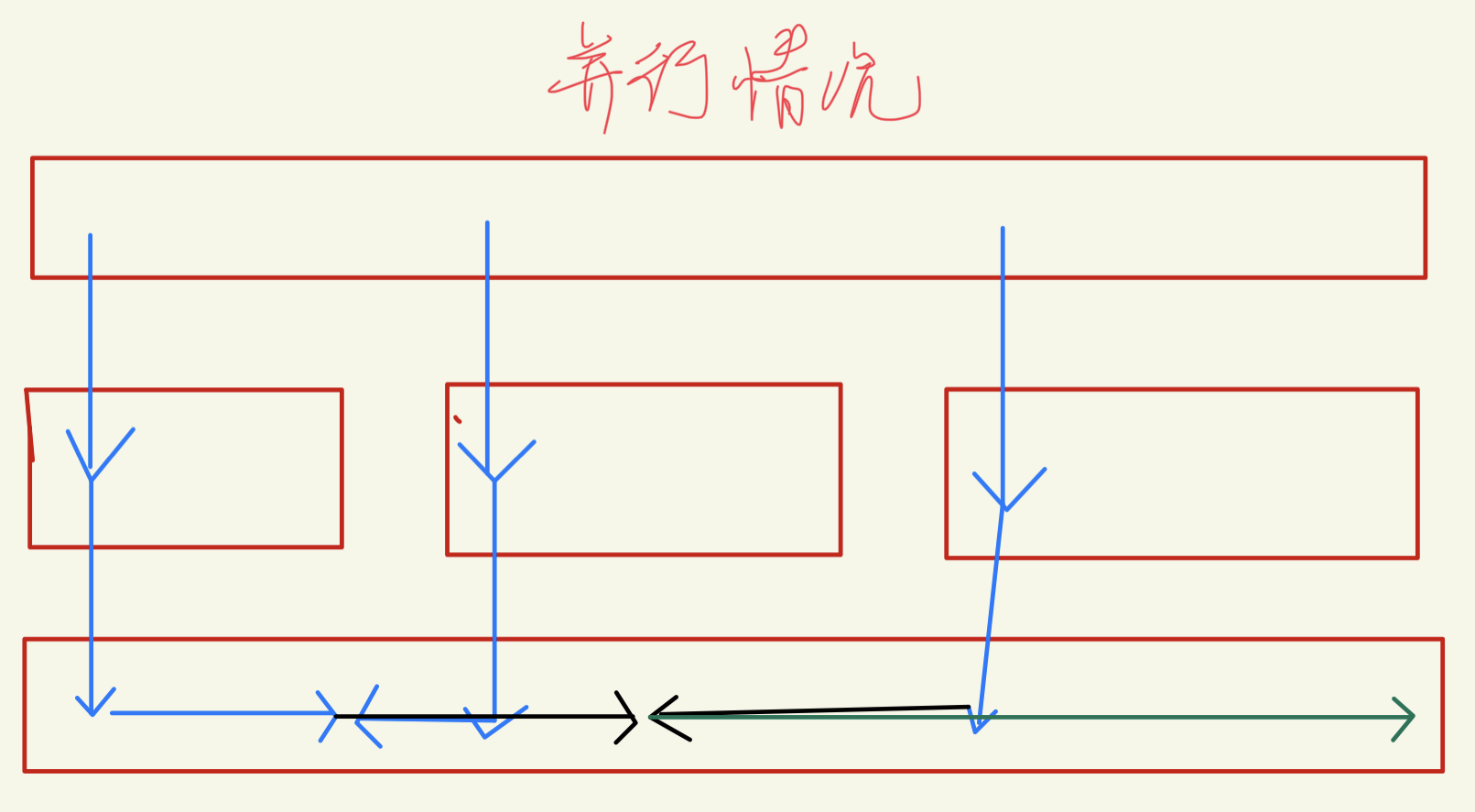
 这个原因感觉是一开始只有1个,然后一般也就产生1/2个任务。将其初始任务改成64个就行。
这个原因感觉是一开始只有1个,然后一般也就产生1/2个任务。将其初始任务改成64个就行。