C Program Compile Problems
TODO:[5] please fix all in free time 重复了和另一篇
TODO:[5] please fix all in free time 重复了和另一篇
摘要
ABI被人熟知,就是编译时,接口不匹配导致运行时的动态库undefined symbol报错。
概要
C++ 基础知识和语法,包括C++11,C++17,C++23的各种语言支持。
C++编程语言历史 和 设计思路
支持范式模板编程 (generic programming)
支持面向对象编程 (object-oriented programming) 的拓展
平台依赖性:C++代码在不同的平台上需要重新编译,因为它直接与底层系统交互。Java代码是平台无关的,一次编译的字节码可以在任何支持Java虚拟机的平台上运行。
C++更适合系统级编程、游戏开发等需要更高的性能和底层控制的场景。
The default program entry function is main, but can be changed in two situations:
#define xxx main in header file to replace the name which maybe ignored by silly search bar in VSCODE.-exxx compile flag;)取决于上下文。C++ 语法的基本规则是:分号用来标识一条语句的结束,而有些结构并不是严格的语句,因此不需要分号。
声明(变量、类、结构体、枚举、函数原型、类型别名):都需要分号作为结束。
if, while, for)、复合语句({}) 不需要分号。#define, #include):不需要分号,因为它们不是 C++ 语法层面的内容。} 不需要分号,但声明类或结构体时 } 后要加分号。为什么类/结构体需要分号
C++ 中的类和结构体定义实际上是一种声明,它们的定义是一种复杂的声明语句,因此必须用分号来结束它们。
总结来说,分号用来结束语句,包括声明、表达式和执行体等,但当你定义一个复合结构(如函数定义、控制语句)时,不需要分号来结束复合结构的定义。
int getKthAncestor(int node, int k) {
int node= getKthAncestor(saved[node],--k);
return node;
}
//为什么第二行的node会提前被修改为0,导致传入函数getKthAncestor的saved[node]的node值为0
//如下去掉int,也不会错。因为int node 会初始化node为0
int getKthAncestor(int node, int k) {
node= getKthAncestor(saved[node],--k);
return node;
}
根据C++的作用域规则,内层的局部变量会覆盖外层的同名变量。因此,在第二行的语句中,node引用的是函数参数中的node,而不是你想要的之前定义的node。
为了避免这个问题,你可以修改代码,避免重复定义变量名。例如,可以将第二行的变量名改为newNode或其他不同的名称,以避免与函数参数名冲突。
运算符性质:
https://en.cppreference.com/w/cpp/language/types
https://en.cppreference.com/w/cpp/types/integer
//返回与平台相关的数值类型的极值
std::numeric_limits<double>::max()
std::numeric_limits<int>::min()
#include<limits.h>
INT_MAX
FLT_MAX (or DBL_MAX )
-FLT_MAX (or -DBL_MAX )
extern
const
constexpr //C++11引入的关键字,用于编译时的常量与常量函数。
volatile //是指每次需要引用某个变量的数据时,都必须从内存原地址读取,而不是编译器优化后寄存器间接读取.(必须写回内存,为了多进程并发而设计的。)
inline
static 作⽤:控制变量的存储⽅式和作用范围(可⻅性)。
避免
C++17 以后 局部的const static变量的初始化不是代码运行到才初始化,而是和全局static变量一样,在程序开始执行时初始化。
在 C++ 中,如果你希望 static 变量可以在多个文件中访问,直接写在头文件中是 不正确的,因为每个包含该头文件的源文件都会生成自己的独立 static 变量,导致它们互相独立,无法共享状态。
正确的解决方案
encounteredAclops 声明为 extern 变量,并将其定义在一个 .cpp 文件中。头文件:globals.h
源文件:globals.cpp
在其他源文件中使用:
#include "globals.h"
void someFunction() {
if (!encounteredAclops) {
// Do something
encounteredAclops = true;
}
}
通过 extern,所有引用 encounteredAclops 的源文件都会共享同一个变量。
如果每个源文件都需要独立的 encounteredAclops,你可以将 static bool encounteredAclops = false; 放在各自的源文件中,而不需要放在头文件中。这是因为 static 的作用域仅限于当前编译单元。
每个源文件:
static bool encounteredAclops = false;
void someFunction() {
if (!encounteredAclops) {
// Do something
encounteredAclops = true;
}
}
encounteredAclops 作为一个类的静态成员变量来实现共享状态。头文件:AclopsManager.h
#ifndef ACLOPS_MANAGER_H
#define ACLOPS_MANAGER_H
class AclopsManager {
public:
static bool encounteredAclops;
};
#endif // ACLOPS_MANAGER_H
源文件:AclopsManager.cpp
在其他源文件中使用:
#include "AclopsManager.h"
void someFunction() {
if (!AclopsManager::encounteredAclops) {
// Do something
AclopsManager::encounteredAclops = true;
}
}
这种方式既可以共享变量,又能保持代码组织清晰。
结论
- 如果需要共享变量:使用 extern 或类的静态成员变量。
- 如果需要独立变量:将 static 声明放在各自的源文件中。
- 不要直接在头文件中定义 static bool encounteredAclops,否则会导致每个包含头文件的源文件都生成自己的副本,违背初衷。
int MyClass::staticVariable = 10;多线程场景,修饰局部变量,会导致多线程共用,建议使用thread_local来避免竞争
static 局部变量在第一次被访问时初始化,且初始化过程是线程不安全的。如果两个线程几乎同时首次访问这个变量,可能会导致初始化竞争,进而引发未定义行为。
static 修饰初始化命令,只会执行一次,无论是否多次经过
问题场景:
static auto thread_core_map = GetCpuAffinityMap(device_id); 即使程序多次调用函数经过这行,但是这行命令也只会执行第一次。但是如果我把static关键词去除,就正常执行多次了。
当在一行代码中使用了 static 关键字时,变量的初始化只会在它第一次被执行时进行,之后即使多次经过这行代码,初始化的代码块也不会被重复执行。
在例子中,thread_core_map 是一个静态局部变量,它在第一次经过时会调用 GetCpuAffinityMap(device_id) 函数并保存结果。在后续的函数调用中,即使再次经过这行代码,GetCpuAffinityMap(device_id) 不会被重新调用,因为 thread_core_map 已经被初始化过了。
去除 static 后,thread_core_map 会在每次经过这行代码时重新初始化,也就是每次都会调用 GetCpuAffinityMap(device_id)。
解决方法:
如果你需要这行代码每次执行时都重新调用 GetCpuAffinityMap(device_id),那么应该去掉 static 关键字,或根据不同条件进行显式地重新初始化静态变量。
比如,可以这样实现惰性初始化或重置的功能:
static auto thread_core_map = GetCpuAffinityMap(device_id);
// 根据条件重新初始化
if (/* 条件 */) {
thread_core_map = GetCpuAffinityMap(device_id);
}
这样你就可以在特定条件下让 thread_core_map 被重新赋值。
如果你对静态变量的初始化行为没有问题,但是希望特定场景下重新执行初始化函数,可以根据场景调整条件逻辑。
当const修饰基本数据类型时,可以将其放置在类型说明符的前面或后面,效果是一样的。const关键字用于声明一个常量,即其值在声明后不可修改。
当const关键字位于指针变量或引用变量的左侧时,它用于修饰指针所指向的变量,即指针指向的内容为常量。当const关键字位于指针变量或引用变量的右侧时,它用于修饰指针或引用本身,即指针或引用本身是常量。
修饰指针指向的变量, 它指向的值不能修改:
修饰指针本身 ,它不能再指向别的变量,但指向(变量)的值可以修改。:
const int *const p3; //指向整形常量 的 常量指针 。它既不能再指向别的常量,指向的值也不能修改。
在C++, explicit 是一个关键字,用于修饰单参数构造函数,用于禁止隐式类型转换。
当一个构造函数被声明为 explicit 时,它指示编译器在使用该构造函数进行类型转换时只能使用显式调用,而不允许隐式的类型转换发生。
通过使用 explicit 关键字,可以防止一些意外的类型转换,提高代码的清晰性和安全性。它通常用于防止不必要的类型转换,特别是在单参数构造函数可能引起歧义或产生意外结果的情况下。
#include_next 的作用是
在寻找头文件时的头文件搜索优先级里,去除该文件所在的当前目录,主要是为C++头文件的重名问题提供一种解决方案。b.cpp想使用
自己拓展修改的stdlib.h, 那么在代码的目录下创建stdlib.h,并在该文件里#include_next "stdlib.h" 防止递归引用。#define PI 3.14159,在代码中将PI替换为3.14159。# 是 字符串化操作符(Stringizing operator)在 C/C++ 宏中,# 是 字符串化操作符(Stringizing operator),它的作用是将宏参数转换为字符串文字(string literal)。
当在宏中使用 #key 时,key 被转换为一个字符串文字,即在代码中实际变为 "key"(包括引号)。如果不加 #,key 将直接作为标记被使用,不会转为字符串。
示例:
以下是一个宏的例子,演示了 # 的作用:
宏定义:
#define TO_STRING(x) #x
#define CONCAT_AND_PRINT(a, b) printf("Concatenation: %s\n", TO_STRING(a##b));
宏使用:
int main() {
int HelloWorld = 42;
// 使用字符串化操作
printf("%s\n", TO_STRING(HelloWorld)); // 输出: HelloWorld
// 使用标记粘贴操作和字符串化操作
CONCAT_AND_PRINT(Hello, World); // 输出: Concatenation: HelloWorld
}
宏展开与作用:
TO_STRING(HelloWorld)
宏 TO_STRING 将参数 HelloWorld 转换为字符串文字,展开为:
HelloWorld
CONCAT_AND_PRINT(Hello, World)
a##b 将 Hello 和 World 拼接成 HelloWorld。TO_STRING(a##b) 将拼接后的标识符 HelloWorld 转换为字符串 "HelloWorld"。
展开为:Concatenation: HelloWorld## 是 C/C++ 宏预处理器的 标记粘贴操作符(Token-pasting operator)用于将宏参数和宏内的其他标记连接起来。具体来说,##Value 和 ##Initialized 这两个标记会与宏参数(如 valueName)进行拼接,形成新的标识符。
#define REGISTER_OPTION_CACHE(type, valueName, ...) \
static thread_local type valueName##Value; \
static thread_local bool valueName##Initialized = false; \
inline type GetWithCache##valueName() { \
if (!valueName##Initialized) { \
valueName##Value = __VA_ARGS__(); \
valueName##Initialized = true; \
} \
return valueName##Value; \
} \
inline void SetWithCache##valueName(type value) { \
valueName##Value = value; \
valueName##Initialized = true; \
}
宏展开解释
假设你在代码中使用了如下调用:
这将会将宏中的 type 替换为 int,valueName 替换为 MyValue,并且 __VA_ARGS__ 代表了传递给宏的可变参数 42。
展开后的代码:
static thread_local int MyValueValue;
static thread_local bool MyValueInitialized = false;
inline int GetWithCacheMyValue() {
if (!MyValueInitialized) {
MyValueValue = 42; // 使用了 __VA_ARGS__
MyValueInitialized = true;
}
return MyValueValue;
}
inline void SetWithCacheMyValue(int value) {
MyValueValue = value;
MyValueInitialized = true;
}
关键点解释:
valueName##Value 被展开为 MyValueValue。## 操作符将宏参数 MyValue 与 Value 连接,形成新的标识符 MyValueValue。valueName##Initialized 被展开为 MyValueInitialized,同样是将宏参数 MyValue 与 Initialized 连接,形成新的标识符 MyValueInitialized。结果
MyValueValue 存储了缓存的值(在这个例子中是 42)。MyValueInitialized 是一个布尔值,用来标记缓存是否已经初始化。GetWithCacheMyValue() 函数首先检查 MyValueInitialized 是否为 true,如果没有被初始化,它会使用 42 来初始化缓存并设置标志。SetWithCacheMyValue(int value) 函数允许你更新缓存的值,并将 MyValueInitialized 设置为 true。const int MAX_VALUE = 100;,声明一个名为MAX_VALUE的常量。typedef int Age;,为int类型创建了一个别名Age。例如:inline int add(int a, int b) { return a + b; },声明了一个内联函数add。
define主要用于宏定义,const用于声明常量,typedef用于创建类型别名,inline用于内联函数的声明。
为了避免同一个文件被include多次,C/C++中有两种方式,一种是#ifndef方式,一种是#pragma once方式。在能够支持这两种方式的编译器上,二者并没有太大的区别,但是两者仍然还是有一些细微的区别。
#include <iostream>
class MyClass {
public:
MyClass() {
std::cout << "Constructing MyClass" << std::endl;
}
~MyClass() {
std::cout << "Destructing MyClass" << std::endl;
}
};
int main() {
// 使用new动态分配内存,并调用构造函数
MyClass* obj = new MyClass();
// 执行一些操作...
// 使用delete释放内存,并调用析构函数
delete obj;
return 0;
}
namespace 会影响 typedef 的作用范围,但不会直接限制 #define 宏的作用范围。
A.h, B.h 都需要string.h的头文件,然后B.h 会include A.h,那么我在B.h里是不是可以省略include string.h
不应该省略,
include的位置有什么规则和规律吗,头文件和cpp文件前都可以吗?
在编写代码时,往往A.cpp需要include A.h。那A.cpp需要的头文件,我是写在A.cpp里还是A.h里?
//值传递
change1(n);
void change1(int n){
n++;
}
//引用传递,操作地址就是实参地址 ,只是相当于实参的一个别名,在符号表里对应是同一个地址。对它的操作就是对实参的操作
change2(n);
void change2(int &n){
n++;
}
//特殊对vector
void change2(vector<int> &n)
//特殊对数组
void change2(int (&n)[1000])
//指针传递,其实是地址的值传递
change3(&n);
void change3(int *n){
*n=*n+1;
}
引用传递和指针传递的区别:
指针传递和引用传递的使用情景:
闭包(Closure)是指在程序中,函数可以捕捉并记住其作用域(环境)中的变量,即使在函数执行完成后,这些变量依然保存在内存中,并能在后续的函数调用中被使用。闭包的一个重要特性是,它不仅保存了函数本身的逻辑,还“闭合”了函数执行时的上下文环境(即该函数所在的作用域)。
闭包通常用于实现函数内部的状态保持、回调函数等场景。在 C++ 中,闭包通过 lambda 表达式 实现,lambda 表达式可以捕获外部变量并在其内部使用。
例子
auto add = [](int x) {
return [x](int y) {
return x + y;
};
};
auto add5 = add(5);
std::cout << add5(3); // 输出 8
add 函数返回了一个闭包,捕获了变量 x 的值。即使 x 在原作用域中不再可用,返回的闭包仍然可以访问并使用 x 的值。
匿名函数(lambda)和闭包的关系就如同类和类对象的关系
匿名函数和类的定义都只存在于源码(代码段)中,而闭包和类对象则是在运行时占用内存空间的实体;
虽然理论上可以通过类似void f(bool x = true)来实现默认值。
导致实际编码如下:

假设我们有一个模板类 Wrapper,我们希望禁止 VirtualGuardImpl 类型作为模板参数:
template <
typename T,
typename U = T,
typename = typename std::enable_if<!std::is_same<U, VirtualGuardImpl>::value>::type>
class Wrapper {
public:
void function() {
// 实现
}
};
在这个例子中,如果用户尝试创建 Wrapper<VirtualGuardImpl> 或 Wrapper<VirtualGuardImpl, VirtualGuardImpl> 的实例,编译器将报错,因为 std::enable_if 的条件不满足。但如果使用其他类型,比如 int 或自定义类型,就可以正常编译。
这段代码是 C++ 中的一个模板函数或模板类模板参数的定义,它使用了模板默认参数、std::enable_if 条件编译技术以及类型萃取(type traits)。下面是对这段代码的详细解释:
模板参数 U:
typename U = T 定义了一个模板类型参数 U,并给它一个默认值 T。这意味着如果在使用模板时没有指定 U 的话,它将默认使用模板参数 T 的值。std::enable_if:
std::enable_if 是一个条件编译技术,它只在给定的布尔表达式为 true 时启用某个模板。std::enable_if 后面的布尔表达式是 !std::is_same<U, VirtualGuardImpl>::value。这意味着只有当 U 不等于 VirtualGuardImpl 类型时,这个模板参数才有效。typename 关键字:
typename 关键字用于告诉编译器 std::enable_if 的结果是一个类型。std::enable_if 返回的是一个类型,如果条件为 true,它返回一个空的类型,否则会导致编译错误。std::is_same:
std::is_same<U, VirtualGuardImpl>::value 是一个编译时检查,用于判断 U 和 VirtualGuardImpl 是否是相同的类型。::value 是类型特征 std::is_same 的一个成员,它是一个布尔值,如果类型相同则为 true,否则为 false。组合解释:
U,默认值为 T,并且这个模板参数只有在 U 不是 VirtualGuardImpl 类型时才有效。#include <stdarg.h>
void Error(const char* format, ...)
{
va_list argptr;
va_start(argptr, format);
vfprintf(stderr, format, argptr);
va_end(argptr);
}
VA_LIST 是在C语言中解决变参问题的一组宏,变参问题是指参数的个数不定,可以是传入一个参数也可以是多个;可变参数中的每个参数的类型可以不同,也可以相同;可变参数的每个参数并没有实际的名称与之相对应,用起来是很灵活。
系统提供了vprintf系列格式化字符串的函数,用于编程人员封装自己的I/O函数。
int vprintf / vscanf (const char * format, va_list ap); // 从标准输入/输出格式化字符串
int vfprintf / vfsacanf (FILE * stream, const char * format, va_list ap); // 从文件流
int vsprintf / vsscanf (char * s, const char * format, va_list ap); // 从字符串
使用结构体
struct RowAndCol { int row;int col; };
RowAndCol r(string fn) {
/*...*/
RowAndCol result;
result.row = x;
result.col = y;
return result;
}
在 C++ 中,左值(lvalue) 和 右值(rvalue) 是两个重要的概念,用来描述表达式的值和内存的关系。它们帮助开发者理解变量的生命周期、赋值和对象管理,特别是在现代 C++ 中引入了右值引用后,优化了移动语义和资源管理。
左值(lvalue,locatable value) 是指在内存中有明确地址、可持久存在的对象,可以对其进行赋值操作。通俗地说,左值是能够取地址的值,可以出现在赋值操作符的左边。
特点:
& 运算符)。示例
在这个例子中,x 是一个左值,因为它表示了内存中的某个对象,并且可以通过赋值语句修改它的值。
右值(rvalue,readable value) 是没有明确地址、临时存在的对象,不能对其进行赋值操作。它们通常是字面值常量或表达式的结果。右值只能出现在赋值操作符的右边,表示一个临时对象或数据。
特点:
& 获取右值的地址)。示例
在这个例子中,10 和 y + 5 是右值,因为它们表示计算出的临时数据,并且不能直接对这些值进行赋值操作。
C++11 引入了 右值引用,即通过 && 符号表示。这使得右值也能通过引用进行操作,特别是在实现移动语义(move semantics)和避免不必要的拷贝时非常有用。右值引用允许我们通过右值管理资源,避免性能上的损失。
示例:右值引用与移动语义
#include <iostream>
#include <vector>
int main() {
std::vector<int> vec1 = {1, 2, 3};
std::vector<int> vec2 = std::move(vec1); // vec1 资源移动到 vec2
std::cout << "vec1 size: " << vec1.size() << std::endl;
std::cout << "vec2 size: " << vec2.size() << std::endl;
return 0;
}
在这个例子中,std::move 将 vec1 变为一个右值引用,使其内部的资源(如动态分配的内存)直接转移给 vec2,避免了拷贝。
通常,左值是表示持久存在的对象,可以通过取地址符 & 获取其地址,而右值是临时的、短暂存在的值,不能直接获取其地址。理解这两者对于编写高效的 C++ 代码和使用现代特性(如右值引用和移动语义)非常重要。
常见误区
x + y)通常是右值。&&)是 C++11 引入的新特性,用来优化资源管理和避免不必要的拷贝操作。在C++98/03中我们只能对普通数组和POD(plain old data,简单来说就是可以用memcpy复制的对象)类型可以使用列表初始化,如下:
在C++11中初始化列表被适用性被放大,可以作用于任何类型对象的初始化。如下:
X x1 = X{1,2};
X x2 = {1,2}; // 此处的'='可有可⽆
X x3{1,2};
X* p = new X{1,2};
//列表初始化也可以用在函数的返回值上
std::vector<int> func() {
return {};
}
聚合类型可以进行直接列表初始化
聚合类型包括
对于一个聚合类型,使用列表初始化相当于使用std::initializer_list对其中的相同类型T的每个元素分别赋值处理,类似下面示例代码;
struct CustomVec {
std::vector<int> data;
CustomVec(std::initializer_list<int> list) {
for (auto iter = list.begin(); iter != list.end(); ++iter) {
data.push_back(*iter);
}
}
};
⼩贺 C++ ⼋股⽂ PDF 的作者,电⼦书的内容整理于公众号「herongwei」
https://shaojiemike.notion.site/C-11-a94be53ca5a94d34b8c6972339e7538a
for(auto x : range).for(auto && x : range)for(const auto & x : range).使用begin end
vector<int>& nums1
unordered_set<int> nums_set(nums1.begin(), nums1.end());
unordered_set<int> result;
return vector<int>(result.begin(), result.end());
以下是整理和改正后的迭代器笔记。
运算支持:
+ 和 - 运算符,允许轻松地在迭代器位置上进行移动。[],使其用法与指针类似。it,可以通过 *(it + i) 或 it[i] 语法访问第 i 个元素。使用场景:
vector 和 deque 都提供随机访问迭代器。std::sort、std::nth_element)要求输入的迭代器必须是随机访问迭代器,以便快速定位和排序。begin() 到 end())和反向迭代器(rbegin() 到 rend()),二者在遍历方向上相反。转换:正向迭代器和反向迭代器可以相互转换,但类型不同,需要显式转换。
base() 成员函数可以返回一个指向反向迭代器当前元素的下一个位置的正向迭代器。注意:
rit.base() 指向的并不是 rit 当前元素本身,而是 rit 指向元素的下一个位置。C++ 提供了 rbegin() 和 rend() 来支持容器的反向遍历:
rbegin() 返回一个反向迭代器,指向容器的最后一个元素。rend() 返回一个反向迭代器,指向容器反向遍历时的“结束位置”,即第一个元素之前的一个位置。++it 而非 --it,因为反向迭代器的递增操作相当于在正向迭代器上进行递减操作。for (auto it = collection.rbegin(); it != collection.rend(); ++it) {
std::cout << *it << std::endl;
// 或者如果是键值对容器:
// std::cout << it->first << ", " << it->second << std::endl;
}
end() 和 begin()可以这样写:
std::prev 函数接受两个参数:一个是指向迭代器的参数,另一个是整数偏移量。它返回从指定迭代器开始向前移动指定偏移量后的迭代器。std::next 函数接受两个参数:一个是指向迭代器的参数,另一个是整数偏移量。它返回从指定迭代器开始向后移动指定偏移量后的迭代器。advance
std::advance 形似index的随机访问,函数的实现方式取决于迭代器的类型:
+= 运算符来实现移动。std::advance 的一个简单实现, 这个实现使用了 C++17 的 if constexpr 特性,以便在编译时选择不同的实现方式。:template <typename InputIt, typename Distance>
void advance(InputIt& it, Distance n) {
if constexpr (std::is_same_v<std::random_access_iterator_tag,
typename std::iterator_traits<InputIt>::iterator_category>) {
it += n; //如果迭代器是随机访问迭代器(后面解释),它会使用 += 运算符来移动;
} else {
if (n >= 0) {
while (n--) {
++it; //否则,它会使用循环来移动。
}
} else {
while (n++) {
--it;
}
}
}
}
bitset类型存储二进制数位。
std::bitset<16> foo;
std::bitset<16> bar (0xfa2);
std::bitset<16> baz (std::string("0101111001"));
//foo: 0000000000000000
//bar: 0000111110100010
//baz: 0000000101111001
将数转化为其二进制的字符串表示
int i = 3;
string bin = bitset<16>(i).to_string(); //bin = "0000000000000011"
bin = bin.substr(bin.find('1')); //bin = "11"
#include <utility>
pair<T1, T2> p1; //创建一个空的pair对象(使用默认构造),它的两个元素分别是T1和T2类型,采用值初始化。
pair<T1, T2> p1(v1, v2); //创建一个pair对象,它的两个元素分别是T1和T2类型,其中first成员初始化为v1,second成员初始化为v2。
make_pair(v1, v2); // 以v1和v2的值创建一个新的pair对象,其元素类型分别是v1和v2的类型。
p1 < p2; // 两个pair对象间的小于运算,其定义遵循字典次序:如 p1.first < p2.first 或者 !(p2.first < p1.first) && (p1.second < p2.second) 则返回true。
p1 == p2; // 如果两个对象的first和second依次相等,则这两个对象相等;该运算使用元素的==操作符。
p1.first; // 返回对象p1中名为first的公有数据成员
p1.second; // 返回对象p1中名为second的公有数据成员
#include <tuple> // 包含 tuple
std::tuple<int, std::string, double> t1(1, "one", 1.0);
// 使用 make_tuple 函数
auto t2 = std::make_tuple(2, "two", 2.5);
//使用 tuple 时,访问/修改元素使用 std::get<index>。
std::cout << "Tuple t2: ("
<< std::get<0>(t2) << ", "
<< std::get<1>(t2) << ", "
<< std::get<2>(t2) << ")"
<< std::endl;
std::string s0 ("Initial string");
// constructors used in the same order as described above:
std::string s1;
std::string s2 (s0);
std::string s3 (s0, 8, 3);
std::string s4 ("A character sequence");
std::string s5 ("Another character sequence", 12);
std::string s6a (10, 'x');
std::string s6b (10, 42); // 42 is the ASCII code for '*'
std::string s7 (s0.begin(), s0.begin()+7);
std::cout << "s1: " << s1 << "\ns2: " << s2 << "\ns3: " << s3;
std::cout << "\ns4: " << s4 << "\ns5: " << s5 << "\ns6a: " << s6a;
std::cout << "\ns6b: " << s6b << "\ns7: " << s7 << '\n';
//output
s1:
s2: Initial string
s3: str
s4: A character sequence
s5: Another char
s6a: xxxxxxxxxx
s6b: **********
s7: Initial
读取空格分割的
使用insert()在指向位置的右边插入
// inserting into a string
#include <iostream>
#include <string>
std::string str="to be question";
std::string str2="the ";
std::string str3="or not to be";
std::string::iterator it;
// used in the same order as described above:
str.insert(6,str2); // to be (the )question
str.insert(10,"to be "); // to be not (to be )that is the question
it = str.insert(str.begin()+5,','); // to be(,) not to be: that is the question
str.insert(6,str3,3,4); // to be (not )the question
str.insert(10,"that is cool",8); // to be not (that is )the question
str.insert(str.end(),3,'.'); // to be, not to be: that is the question(...)
str.insert(15,1,':'); // to be not to be(:) that is the question
// ???
str.insert (it+2,str3.begin(),str3.begin()+3); // (or )
插入char不同的方法
str3 = str1;
三种情况
// string::erase
#include <iostream>
#include <string>
int main ()
{
std::string str ("This is an example sentence.");
std::string str1(str) ;
std::cout << str << '\n';
// "This is an example sentence."
str.erase (10,8); // ^^^^^^^^
//去除index=10的连续8个元素,
//去除从index=3开始的所有元素, 后面全删除
str1.erase (3);
// "Thi"
std::cout << str << '\n';
// "This is an sentence."
str.erase (str.begin()+9); // ^
//去除itr指向的元素
std::cout << str << '\n';
// "This is a sentence."
str.erase (str.begin()+5, str.end()-9); // ^^^^^
//去除[first,last).的元素
std::cout << str << '\n';
// "This sentence."
return 0;
}
npos是一个常数,表示size_t的最大值(Maximum value for size_t)。许多容器都提供这个东西,用来表示不存在的位置,类型一般是std::container_type::size_type。
isdigit 是 C 标准库中的函数,用于检查一个字符是否为数字字符。它定义在
要检查一个 std::string 是否以某个前缀开头,std::string 没有直接提供“检查前缀”的方法,但可以使用 compare 或 find 方法实现。
方法 1:使用 compare 检查前缀
std::string::compare 可以比较字符串的部分内容,适合用于前缀检查。
#include <iostream>
#include <string>
bool hasPrefix(const std::string& str, const std::string& prefix) {
return str.compare(0, prefix.size(), prefix) == 0;
}
int main() {
std::string text = "Hello, world!";
std::string prefix = "Hello";
if (hasPrefix(text, prefix)) {
std::cout << "The string starts with the prefix." << std::endl;
} else {
std::cout << "The string does not start with the prefix." << std::endl;
}
return 0;
}
方法 2:使用 find 检查前缀
可以使用 std::string::find,但需要确认找到的位置是否是 0 才能确定是前缀。
#include <iostream>
#include <string>
bool hasPrefix(const std::string& str, const std::string& prefix) {
return str.find(prefix) == 0;
}
int main() {
std::string text = "Hello, world!";
std::string prefix = "Hello";
if (hasPrefix(text, prefix)) {
std::cout << "The string starts with the prefix." << std::endl;
} else {
std::cout << "The string does not start with the prefix." << std::endl;
}
return 0;
}
方法 3:使用 std::string::starts_with (C++20)
如果你使用的是 C++20 或更高版本,可以直接使用 starts_with 方法。
#include <iostream>
#include <string>
int main() {
std::string text = "Hello, world!";
std::string prefix = "Hello";
if (text.starts_with(prefix)) {
std::cout << "The string starts with the prefix." << std::endl;
} else {
std::cout << "The string does not start with the prefix." << std::endl;
}
return 0;
}
总结
starts_with。compare 或 find,推荐 compare,因为它可以直接比较前缀而不需要判断位置。std::string::rfind 是 C++ 标准库提供的一个方法,用于从字符串的末尾向前查找指定的子字符串或字符。它的功能与 find 类似,但查找方向是从右向左,适用于需要从字符串末尾开始定位子字符串的情况。
函数原型
size_t rfind(const std::string& str, size_t pos = std::string::npos) const;
size_t rfind(const char* s, size_t pos = std::string::npos) const;
size_t rfind(char c, size_t pos = std::string::npos) const;
参数说明
const char*)。pos 位置向前查找,默认值为 std::string::npos,表示从末尾开始查找。返回值
std::string::npos。使用示例
#include <iostream>
#include <string>
int main() {
std::string text = "Hello, world! Hello, C++!";
size_t pos = text.rfind("Hello");
if (pos != std::string::npos) {
std::cout << "'Hello' found at position: " << pos << std::endl;
} else {
std::cout << "'Hello' not found." << std::endl;
}
return 0;
}
输出:
#include <iostream>
#include <string>
int main() {
std::string text = "abcdefgabc";
size_t pos = text.rfind('a');
if (pos != std::string::npos) {
std::cout << "'a' found at position: " << pos << std::endl;
} else {
std::cout << "'a' not found." << std::endl;
}
return 0;
}
输出:
如果想要从特定位置向前查找,可以指定 pos 参数。例如,从索引 10 向前查找字符 'o':
#include <iostream>
#include <string>
int main() {
std::string text = "Hello, world! Hello, C++!";
size_t pos = text.rfind('o', 10);
if (pos != std::string::npos) {
std::cout << "'o' found at position: " << pos << std::endl;
} else {
std::cout << "'o' not found." << std::endl;
}
return 0;
}
输出:
在这些示例中,rfind 帮助我们从右向左查找字符串或字符,适用于查找最后一次出现的位置或从右边指定位置向左查找的需求。
undo xxx aaa 4 to 10在 C++ 中,可以使用 std::regex、std::stringstream 或 std::find_if 等方法对字符串进行解析和分割。以下提供一种基于 std::regex 的方法来提取单个数字和范围(如 4 to 10)。
#include <vector>
#include <regex> //important
// 解析字符串中的所有单个数字和范围
void parseNumbers(const std::string& input, std::vector<std::pair<int, int>>& ranges) {
// 在 C++ 中,使用 R"(...)" 定义原始字符串,可以避免转义字符
std::regex rangePattern(R"(\b(\d+)\s+to\s+(\d+)\b)"); // 匹配范围形式
std::smatch match;
std::string::const_iterator searchStart(input.cbegin());
// 找到所有的范围
while (std::regex_search(searchStart, input.cend(), match, rangePattern)) {
int start = std::stoi(match[1]);
int end = std::stoi(match[2]);
ranges.emplace_back(start, end);
searchStart = match.suffix().first; // 更新搜索起点
}
}
int main() {
std::string input = "undo xxx aaa 1 2 4 to 10";
std::vector<std::pair<int, int>> ranges;
parseNumbers(input, ranges);
// 输出范围
return 0;
}
顺序容器包括vector、deque、list、forward_list、array、string,
关联容器包括set、map,
关联容器和顺序容器有着根本的不同:关联容器中的元素是按关键字来保存和访问的。与之相对,顺序容器中的元素是按它们在容器中的位置来顺序保存和访问的。
为何map和set的插入删除效率比用其他序列容器高?
因为对于关联容器来说,不需要做内存拷贝和内存移动。说对了,确实如此。map和set容器内所有元素都是以节点的方式来存储,其节点结构和链表差不多,指向父节点和子节点。
插入的时候只需要稍做变换,把节点的指针指向新的节点就可以了。删除的时候类似,稍做变换后把指向删除节点的指针指向其他节点就OK了。这里的一切操作就是指针换来换去,和内存移动没有关系。
链表,或者数组(如果父节点的数组下标是 i,那么它的左孩子就是 i * 2 + 1,右孩子就是 i * 2 + 2。)
链式结构如下,注意左右孩子节点
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode(int x) : val(x), left(NULL), right(NULL) {}
};
TreeNode* a = new TreeNode();
a->val = 9;
a->left = NULL;
a->right = NULL;
深度遍历: 前/中/后序遍历。
注意:这里前中后,其实指的就是中间节点/根节点的遍历顺序
堆(Heap)是计算机科学中一类特殊的数据结构的统称。
堆通常是一个可以被看做一棵完全二叉树的数组对象。
堆满足下列性质:
堆总是一棵完全二叉树。
make_heap()将区间内的元素转化为heap.
push_heap()对heap增加一个元素.pop_heap()对heap取出下一个元素.sort_heap()对heap转化为一个已排序群集.#include <algorithm>
int myints[] = {10,20,30,5,15};
vector<int> v(myints,myints+5);
vector<int>::iterator it;
make_heap (v.begin(),v.end());//male_heap就是构造一棵树,使得每个父结点均大于等于其子女结点
cout << "initial max heap : " << v.front() << endl;
pop_heap (v.begin(),v.end());//pop_heap不是删除某个元素而是把第一个和最后一个元素对调后[first,end-1]进行构树,最后一个不进行构树
v.pop_back();//删除最后一个的结点
cout << "max heap after pop : " << v.front() << endl;
v.push_back(99);//在最后增加一个结点
push_heap (v.begin(),v.end());//重新构树
cout << "max heap after push: " << v.front() << endl;
//请在使用这个函数前,确定序列符合堆的特性,否则会报错!
sort_heap (v.begin(),v.end());//把树的结点的权值进行排序,排序后,序列将失去堆的特性
std::cout << "sorted array : ";
for (int i = 0; i < v.size(); ++i) {
std::cout << v[i] << ' ';
}
std::cout << std::endl;
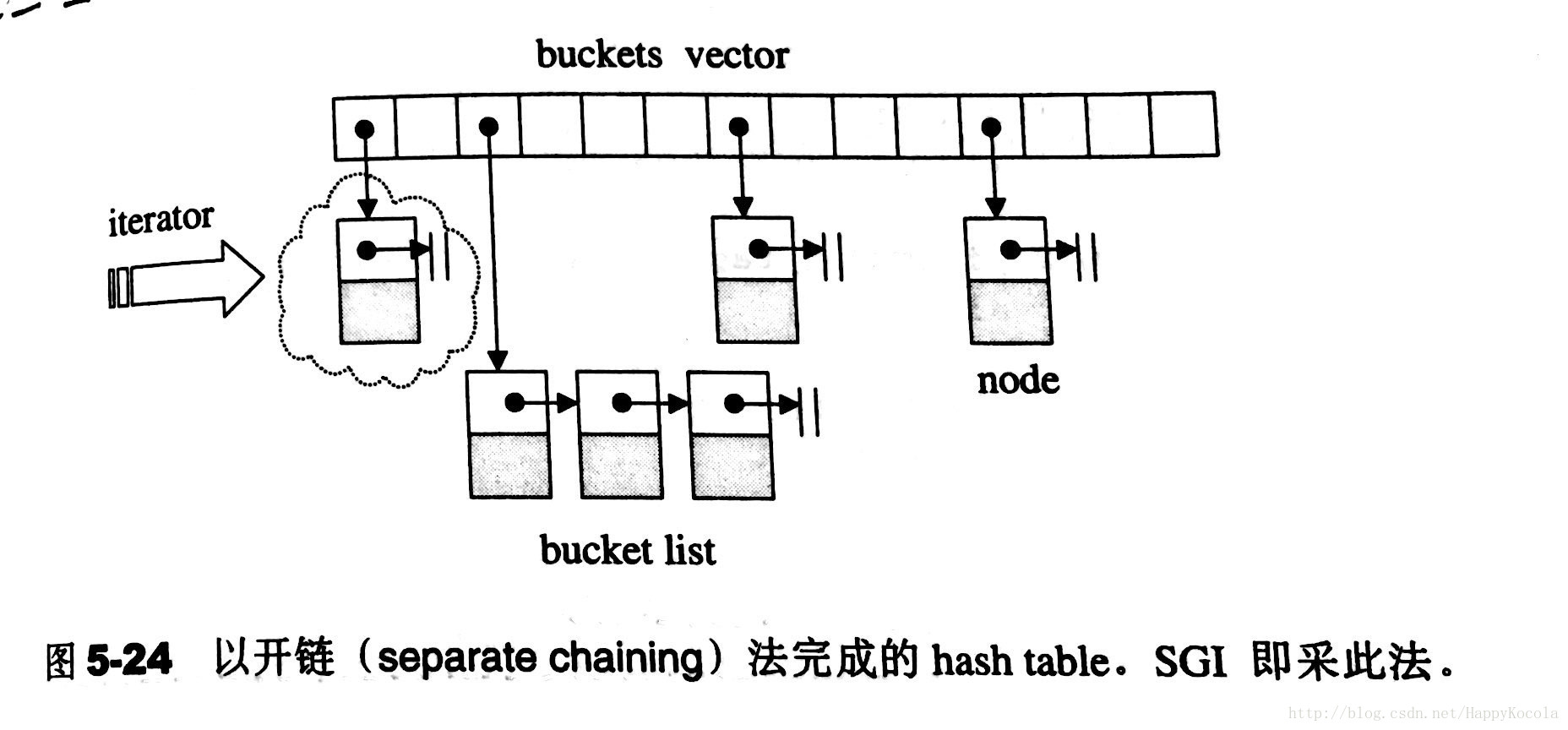
hash_map VS unordered_map
hash_map,unordered_map本质是一样的,只不过 unordered_map被纳入了C++标准库标准:
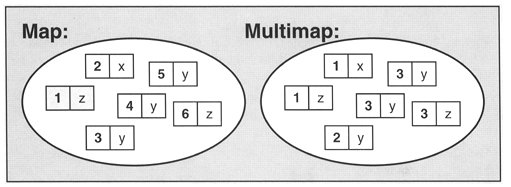
hash_map,标准库的不同实现者将提供一个通常名为hash_map的非标准散列表。因为这些实现不是遵循标准编写的,所以它们在功能和性能保证上都有微妙的差别。unordered_map,以防止与这些非标准实现的冲突,并防止在其代码中有hash_table的开发人员无意中使用新类。unordered_map更具描述性,因为它暗示了类的映射接口和其元素的无序性质。map不允许相同key值存在,multimap则允许相同的key值存在。
| 特性 | map | unordered_map |
|---|---|---|
| 元素排序 | 严格弱序 | 无 |
| 常见实现 | 平衡树或红黑树 | 哈希表 |
| 查找时间 | O(log(n)) | 平均 O(1),最坏 O(n)(哈希冲突) |
| 插入时间 | O(log(n)) + 重新平衡 | 同查找时间 |
| 删除时间 | O(log(n)) + 重新平衡 | 同查找时间 |
| 需要比较器 | 只需 < 运算符 |
只需 == 运算符 |
| 需要哈希函数 | 不需要 | 需要 |
| 常见用例 | 当无法提供良好哈希函数或哈希 | 在大多数其他情况下。当顺序不重要时 |
| 函数太慢,或者需要有序时 |
自己实现的map需要自己去new一些节点,当节点特别多, 而且进行频繁的删除和插入的时候,内存碎片就会存在,而STL采用自己的Allocator分配内存,以内存池的方式来管理这些内存,会大大减少内存碎片,从而会提升系统的整体性能。
注意到很多代码使用 std::unordered_map 因为“哈希表更快”。但是对于小map,具有很高的内存开销。
网上有许多map和unorderd_map的比较,但是都是大例子。
下载一个,比较N比较小时的速度。前面是插入,后面是读取时间。编译g++ -std=c++11 -O3 map.cpp -o main
map的value是int,默认为0。可以直接++
#include <map>
#include <unordered_map>
//c++11以上
map<string,int> m3 = {
{"string",1}, {"sec",2}, {"trd",3}
};
map<string,string> m4 = {
{"first","second"}, {"third","fourth"},
{"fifth","sixth"}, {"begin","end"}
};
operator[]为不存在键,构造默认值
比如对于std::map<std::string, int> m; m["apple"]++;
m["apple"]++ 会首先检查 apple 是否存在于容器中。在 C++ 中,map 和 unordered_map 容器的默认值取决于它们存储的值类型的默认构造方式。具体来说:
int, long 等),默认值是 0。对于浮点型(如 float, double 等),默认值是 0.0。
指针类型:
指针类型的默认值是 nullptr。
自定义类型:
自定义类型的默认值是该类型默认构造函数构造的对象。如果没有显式定义默认构造函数,则编译器会提供一个默认的构造函数,通常将所有成员初始化为默认值。
标准库类型:
std::string),默认值是空字符串 ""。std::vector,默认值是一个空的 vector。// insert 不能覆盖元素,已经存在会失败
mapStudent.insert(map<int, string>::value_type (1, "student_one"));
// 数组方式可以覆盖
mapStudent[1] = "student_one";
用pair来获得是否insert成功,程序如下
pair<map<int, string>::iterator, bool> Insert_Pair;
Insert_Pair = mapStudent.insert(map<int, string>::value_type (1, "student_one"));
我们通过pair的第二个变量来知道是否插入成功,它的第一个变量返回的是一个map的迭代器,如果插入成功的话Insert_Pair.second应该是true的,否则为false。
//unordered_map 类模板中,还提供有 at() 成员方法,和使用 [ ] 运算符一样,at() 成员方法也需要根据指定的键,才能从容器中找到该键对应的值;
//不同之处在于,如果在当前容器中查找失败,该方法不会向容器中添加新的键值对([]会插入默认值),而是直接抛出out_of_range异常。
cnt.at(num)
// c++17 支持
for (auto &[num, c] : cnt) {
}
for (auto &[x, _] : cnt) {
//sth
}
// 否则
for (auto it = cnt.begin(); it != cnt.end(); ++it) {
auto& key = it->first;
auto& value = it->second;
// 使用 key 和 i 进行操作
}
通过 find() 方法得到的是一个正向迭代器,有 2 种情况:
常用于 一个值是否存在 的相关问题
set(关键字即值,即只保存关键字的容器);使用红黑树,自动排序,关键字唯一。multiset(关键字可重复出现的set);unordered_set(用哈希函数组织的set);unordered_multiset(哈希组织的set,关键字可以重复出现)。map和set都是C++的关联容器,其底层实现都是红黑树(RB-Tree)。由于 map 和set所开放的各种操作接口,RB-tree 也都提供了,所以几乎所有的 map 和set的操作行为,都只是转调 RB-tree 的操作行为。
map和set区别在于:
[ ]将关键码作为下标去执行查找,如果关键码不存在,则插入一个具有该关键码和mapped_type类型默认值的元素至map中,因此下标运算符[ ]在map应用中需要慎用,默认红黑树,使用std::less 作为比较器, 升序序列。
| 存放数据类型 | 排序规则 |
|---|---|
| 整数、浮点数等 | 按从小到大的顺序排列 |
| 字符串 | 按字母表顺序排列 |
| 指针 | 按地址升序排列 |
| 指向某元素的指针 | 按指针地址递增的顺序排列 |
| 类(自定义) | 可以自定义排序规则 |
// 自定义比较器,按降序排列
struct Greater {
bool operator()(const int& a, const int& b) const {
return a > b;
}
};
std::set<int, Greater> s = {5, 3, 8, 1, 4};
template < class T, // set::key_type/value_type
class Compare = less<T>, // set::key_compare/value_compare
class Alloc = allocator<T> // set::allocator_type
> class set;
//初始化
set<char> vowel {'a','e','i','o','u'};
template <class T, class Compare, class Alloc>
bool operator== ( const set<T,Compare,Alloc>& lhs,
const set<T,Compare,Alloc>& rhs ); // 和map类似的,重载相等判断
auto hash_p = [](const pair<int, int> &p) -> size_t {
static hash<long long> hash_ll;
return hash_ll(p.first + (static_cast<long long>(p.second) << 32));
};
unordered_set<pair<int, int>, decltype(hash_p)> points(0, hash_p); //(0,hash_p)分别为迭代器的开始和结束的标记(数组多为数据源)
//多用于数组 set<int> iset(arr,arr+sizeof(arr)/sizeof(*arr));
类似的例子1
auto hash = [](const std::pair<int, int>& p){ return p.first * 31 + p.second; };
std::unordered_set<std::pair<int, int>, decltype(hash)> u_edge_(8, hash);
上面的不是用lambda expression隐函数,而是定义函数的写法
//增改
insert()–在集合中插入元素
emplace() 最大的作用是避免产生不必要的临时变量
erase()–删除集合中的元素
//删除 set 容器中值为 val 的元素
//第 1 种格式的 erase() 方法,其返回值为一个整数,表示成功删除的元素个数;
size_type erase (const value_type& val);
//删除 position 迭代器指向的元素
//后 2 种格式的 erase() 方法,返回值都是迭代器,其指向的是 set 容器中删除元素之后的第一个元素。
iterator erase (const_iterator position);
//删除 [first,last) 区间内的所有元素
iterator erase (const_iterator first, const_iterator last);
clear()–删除集合中所有元素
//查询
find()–返回一个指向被查找到元素的迭代器。返回值:该函数返回一个迭代器,该迭代器指向在集合容器中搜索的元素。如果找不到该元素,则迭代器将指向集合中最后一个元素之后的位置end
count()- 查找的bool结果
size()–集合中元素的数目
swap()–交换两个集合变量
并查集的基本操作
UnionFind(int n):每个元素初始化为自己的父节点。int find(int x):查找某个元素的根节点,并进行路径压缩以优化后续查找。int find(int x):将两个元素所在的集合合并为一个集合。核心是
#include <iostream>
#include <vector>
using namespace std;
class UnionFind {
public:
vector<int> parent;
vector<int> rank;
UnionFind(int n) {
parent.resize(n);
rank.resize(n, 0);
for (int i = 0; i < n; ++i) {
parent[i] = i;
}
}
int find(int x) {
if (parent[x] != x) {
parent[x] = find(parent[x]); // 路径压缩
}
return parent[x];
}
void unite(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX != rootY) {
if (rank[rootX] < rank[rootY]) {
parent[rootX] = rootY;
} else if (rank[rootX] > rank[rootY]) {
parent[rootY] = rootX;
} else {
parent[rootY] = rootX;
rank[rootX]++;
}
}
}
bool connected(int x, int y) {
return find(x) == find(y);
}
};
int main() {
int n = 5;
UnionFind uf(n);
uf.unite(0, 1);
uf.unite(1, 2);
uf.unite(3, 4);
cout << "Is 0 and 2 connected? " << (uf.connected(0, 2) ? "Yes" : "No") << endl; // Yes
cout << "Is 0 and 3 connected? " << (uf.connected(0, 3) ? "Yes" : "No") << endl; // No
return 0;
}
#include <iostream>
#include <map>
using namespace std;
class UnionFind {
public:
map<int, int> parent;
map<int, int> rank;
// 初始化
void makeSet(int x) {
parent[x] = x;
rank[x] = 0;
}
// 查找根节点,并进行路径压缩
int find(int x) {
if (parent.find(x) == parent.end()) {
makeSet(x); // 如果 x 不存在,先初始化
}
if (parent[x] != x) {
parent[x] = find(parent[x]); // 路径压缩
}
return parent[x];
}
// 合并两个集合
void unite(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX != rootY) {
if (rank[rootX] < rank[rootY]) {
parent[rootX] = rootY;
} else if (rank[rootX] > rank[rootY]) {
parent[rootY] = rootX;
} else {
parent[rootY] = rootX;
rank[rootX]++;
}
}
}
// 判断两个元素是否在同一个集合中
bool connected(int x, int y) {
return find(x) == find(y);
}
};
int main() {
UnionFind uf;
// 初始化一些元素
uf.makeSet(1);
uf.makeSet(2);
uf.makeSet(3);
uf.makeSet(4);
uf.makeSet(5);
// 合并一些集合
uf.unite(1, 2);
uf.unite(2, 3);
uf.unite(4, 5);
// 查询
cout << "Is 1 and 3 connected? " << (uf.connected(1, 3) ? "Yes" : "No") << endl; // Yes
cout << "Is 1 and 4 connected? " << (uf.connected(1, 4) ? "Yes" : "No") << endl; // No
// 动态添加新元素并合并
uf.unite(6, 7);
cout << "Is 6 and 7 connected? " << (uf.connected(6, 7) ? "Yes" : "No") << endl; // Yes
return 0;
}
C++ 中的容器适配器 stack、queue 和 priority_queue 依赖不同的基础容器来实现特定的数据结构行为。每种容器适配器都有特定的成员函数要求,默认选择的基础容器是为了更好地满足这些要求。
| 容器适配器 | 基础容器筛选条件 | 默认使用的基础容器 |
|---|---|---|
| stack | 基础容器需包含以下成员函数: | deque |
- empty() |
||
- size() |
||
- back() |
||
- push_back() |
||
- pop_back() |
||
满足条件的基础容器有 vector、deque、list。 |
||
| queue | 基础容器需包含以下成员函数: | deque |
- empty() |
||
- size() |
||
- front() |
||
- back() |
||
- push_back() |
||
- pop_front() |
||
满足条件的基础容器有 deque、list。 |
||
| priority_queue | 基础容器需包含以下成员函数: | vector |
- empty() |
||
- size() |
||
- front() |
||
- push_back() |
||
- pop_back() |
||
满足条件的基础容器有 vector、deque。 |
堆栈,先进先出
stack<int> minStack;
minStack = stack<int>();
// 支持初始化,但是注意将整个数组元素推入堆栈,堆栈的顶部元素top将是数组的第一个元素。
std::vector<int> elements = {1, 2, 3, 4, 5};
std::stack<int> myStack(elements.begin(), elements.end());
//增
s.push(x); // 复制 x 到栈中
std::stack<std::pair<int, int>> s;
s.emplace(1, 2); // 在栈中直接构造 std::pair<int, int> (1, 2)
//删
minStack.pop(); //该函数仅用于从堆栈中删除元素,并且没有返回值。因此,我们可以说该函数的返回类型为void。
//改
//查
!minStack.empty()
top_value = minStack.top();
stIn.size() //该函数返回堆栈容器的大小,该大小是堆栈中存储的元素数量的度量。
push() adds a copy of an already constructed object into the queue as a parameter.
emplace() constructs a new object in-place at the end of the queue.
If your usage pattern is one where you create a new object and add it to the container, you shortcut a few steps(creation of a temporary object and copying it) by using emplace().
注意pop仅用于从堆栈中删除元素,并且没有返回值, 一般用法如下
stack不支持clear, 除开一个个pop
#include <queue>
// 初始化
queue<int> q;
// 相对于stack的操作, 没有top(), 但新增
q.front() 返回队首元素的值,但不删除该元素
q.back() 返回队列尾元素的值,但不删除该元素
直接用空的队列对象赋值
使用swap,这种是最高效的,定义clear,保持STL容器的标准。
deque 容器也擅长在序列尾部添加或删除元素(时间复杂度为O(1)),而不擅长在序列中间添加或删除元素。
#include <deque>
using namespace std;
std::deque<int> d;
//相对于stack queue支持迭代器,前两者可以强制通过reinterpret_cast来使用迭代器
begin() 返回指向容器中第一个元素的迭代器。
end() 返回指向容器最后一个元素所在位置后一个位置的迭代器,通常和 begin() 结合使用。
rbegin() 返回指向最后一个元素的迭代器。
rend() 返回指向第一个元素所在位置前一个位置的迭代器。
cbegin() 和 begin() 功能相同,只不过在其基础上,增加了 const 属性,不能用于修改元素。
cend() 和 end() 功能相同,只不过在其基础上,增加了 const 属性,不能用于修改元素。
crbegin() 和 rbegin() 功能相同,只不过在其基础上,增加了 const 属性,不能用于修改元素。
crend() 和 rend() 功能相同,只不过在其基础上,增加了 const 属性,不能用于修改元素。
size() 返回实际元素个数。
max_size() 返回容器所能容纳元素个数的最大值。这通常是一个很大的值,一般是 232-1,我们很少会用到这个函数。
resize() 改变实际元素的个数。
empty() 判断容器中是否有元素,若无元素,则返回 true;反之,返回 false。
shrink _to_fit() 将内存减少到等于当前元素实际所使用的大小。
at() 使用经过边界检查的索引访问元素。
front() 返回第一个元素的引用。
back() 返回最后一个元素的引用。
assign() 用新元素替换原有内容。
push_back() 在序列的尾部添加一个元素。
push_front() 在序列的头部添加一个元素。
pop_back() 移除容器尾部的元素。
pop_front() 移除容器头部的元素。
insert() 在指定的位置插入一个或多个元素。
erase() 移除一个元素或一段元素。
clear() 移出所有的元素,容器大小变为 0。
swap() 交换两个容器的所有元素。
emplace() 在指定的位置直接生成一个元素。
emplace_front() 在容器头部生成一个元素。和 push_front() 的区别是,该函数直接在容器头部构造元素,省去了复制移动元素的过程。
emplace_back() 在容器尾部生成一个元素。和 push_back() 的区别是,该函数直接在容器尾部构造元素,省去了复制移动元素的过程。
// 但是对于原始数据需要提供类型
vec.emplace_back<std::array<int, 4>>({1,2,3,4});
// or
vec.emplace_back(std::array<int, 4>{{1, 2, 3, 4}});
//降序队列(默认less<>), map/set默认也是使用less,但是是升序序列
priority_queue <int>q;
priority_queue <int,vector<int>,less<int> >q;
//升序队列
priority_queue <int,vector<int>,greater<int> > q;
自定义降序1 : class & struct
class _c{
public:
bool operator () (const pair<int, int> &p, const pair<int, int> &q) const {
return p.first < q.first;
}
};
priority_queue<pair<int, int>, vector<pair<int, int>>, _c> pq;
struct Compare {
bool operator()(const std::pair<TimeType, ipType>& a, const std::pair<TimeType, ipType>& b) const {
if (a.first == b.first)
return a.second < b.second; // 第一元素相等时按第二元素降序
return a.first > b.first; // 第一元素按升序排列
}
};
class MyClass {
public:
std::priority_queue<std::pair<TimeType, ipType>, std::vector<std::pair<TimeType, ipType>>, Compare> _arpQueue;
};
自定义降序2 : decltype
class MyClass {
public:
// 比较函数作为静态成员函数
static bool cmp(const std::pair<TimeType, ipType>& a, const std::pair<TimeType, ipType>& b) {
if (a.first == b.first)
return a.second < b.second; // 第一元素相等时按第二元素降序
return a.first > b.first; // 第一元素按升序排列
}
// 使用比较函数指针初始化优先队列
std::priority_queue<std::pair<TimeType, ipType>, std::vector<std::pair<TimeType, ipType>>, decltype(&MyClass::cmp)> _arpQueue{cmp};
};
一般是题目要求自己实现链表,而不是使用STL提供的链表list。
// 单链表
struct ListNode {
int val; // 节点上存储的元素
ListNode *next; // 指向下一个节点的指针
ListNode(int x) : val(x), next(NULL) {} // 节点的构造函数
};
ListNode* head = new ListNode(5);
//或者
ListNode* head = new ListNode();
head->val = 5;
while(result != nullptr && result->val == val){
ListNode* tmp_free = result;
result = result->next;
delete tmp_free; // 注意释放空间
}
nullptr是一个关键字,可以在所有期望为NULL的地方使用。
STL list 容器,又称双向链表容器,即该容器的底层是以双向链表的形式实现的。
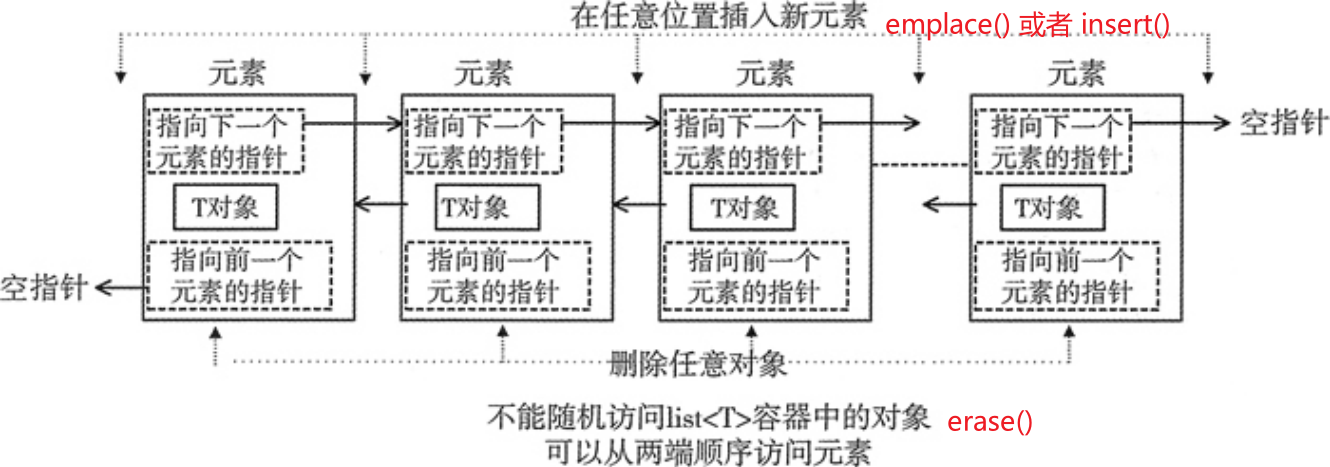
find()语法,经常使用unorder_map<key, list<xxx>::iterator> listMap保存元素位置来加速查找。for (it = list.begin(); it != list.end(); it++) if (it->key == key) break;//插入
push_front:在链表头部插入元素。
emplace_front(value_type&& val)
push_back:在链表尾部插入元素。
emplace_back(value_type&& val)
insert:在指定位置插入元素。list1.insert(list1.begin(), 0);
emplace(iterator pos, value_type val)
//删除
pop_front:删除链表头部的元素。
pop_back:删除链表尾部的元素。
erase:删除指定位置的元素。
remove:删除所有匹配的元素。
clear:清空链表。
//查询
size:返回链表的大小。
empty:检查链表是否为空。
front:返回链表的第一个元素。
back:返回链表的最后一个元素。
reverse:反转链表。
sort:对链表进行排序。
数组 int a[1000] = {0}; 的分配位置
在 C/C++ 中,数组 int a[1000] = {0}; 的分配位置取决于它的声明位置。具体来说:
static 类型,那么它会被分配在栈上。栈上的内存分配速度快,但栈的大小有限,通常为几 MB 到几十 MB,具体取决于操作系统和编译器设置。
静态区(Static):
static 类型,那么它会被分配在静态区。静态区的内存分配在程序启动时完成,持续到程序结束,不会在每次函数调用时重新分配。
堆上(Heap):
malloc、calloc、new 等)分配的,那么它会被分配在堆上。总结
static 数组。static 数组。malloc、calloc、new)分配的数组。//直接初始化为0
int a[SIZE]={0};
#include<string.h>
int a[SIZE];
memset(a, 0, sizeof(a));
memset(a, 0, sizeof(int)*1000);//这里的1000是数组大小,需要多少替换下就可以了。
注意 memset是按照字节进行赋值,即对每一个字节赋相同值。除开0和-1,其他值都是不安全的,不会赋值期望的值。比如int是四个字节。
memset(a,127,sizeof(a)),全部初始化为int的较大值,即2139062143(int 最大值为2147483647);memset(a,128,sizeof(a)),全部初始化为一个很小的数,比int最小值略大,为-2139062144。//区分
//calloc() 函数是动态申请内存函数之一,相当于用malloc函数申请并且初始化一样,calloc函数会将申请的内存全部初始化为0。
int *res = (int*)calloc(numsSize, sizeof(int));
//方法二:
int *res = (int*)malloc(numsSize * sizeof(int));
memset(res, 0, numsSize * sizeof(int));
//错误写法: memset(res, 0, sizeof(res)); res是指针变量,不管 res 指向什么类型的变量,sizeof( res ) 的值都是 4。
int *p = new int();//此时p指向内存的单变量被初始化为0
int *p = new int (5);//此时p指向内存的单变量被初始化为5
int *p = new int[100]()//此时p指向数组首元素,且数组元素被初始化为0
//c++11 允许列表初始化,因此也有了以下几种形式形式
int *p = new int{}//p指向的单变量被初始化为0
int *p = new int{8}//p指向变量被初始化为8
int *p = new int[100]{}//p指向的数组被初始化为0
int *p = new int[100]{1,2,3}//p指向数组的前三个元素被初始化为1,2,3,后边97个元素初始化为0;
建议老实用vector
int ***array;
// 假定数组第一维为 m, 第二维为 n, 第三维为h
// 动态分配空间
array = new int **[m];
for( int i=0; i<m; i++ )
{
array[i] = new int *[n];
for( int j=0; j<n; j++ )
{
array[i][j] = new int [h];
}
}
//释放
for( int i=0; i<m; i++ )
{
for( int j=0; j<n; j++ )
{
delete[] array[i][j];
}
delete[] array[i];
}
delete[] array;
Leetcode support VLA
#include <array>
// array<typeName, nElem> arr;
array<int, 5> ai;
array<double, 4> ad = {1.1,1.2,1.2,1.3};
//通过如下创建 array 容器的方式,可以将所有的元素初始化为 0 或者和默认元素类型等效的值:
std::array<double, 10> values {};
//使用该语句,容器中所有的元素都会被初始化为 0.0。
//二维
std::array<std::array<int, 2>, 3> m = { {1, 2}, {3, 4}, {5, 6} };

vector是变长的连续存储:
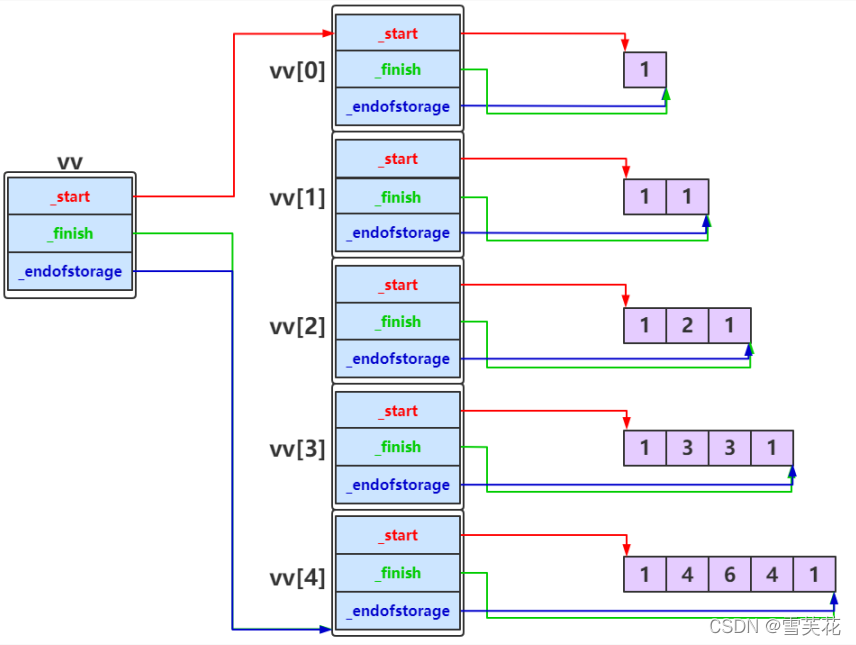
vector<vector<int>> v2d(3,vector<int>(0)); // 间隔 6 个int
// vector<set<int>> v2d(3); // 间隔 12 个int
// vector<unordered_set<int>> v2d(3); // 间隔 14 个int
// vector<map<int,int>> v2d(3); // 间隔 12 个int
// vector<unordered_map<int,int>> v2d(3); // 间隔 14 个int
const int STEP = 6;
for(int i = 0; i<v2d.size(); i++){
cout << " " << &v2d[i] << endl;
for(int j=0; j<STEP; j++)
cout << " " << hex << *(int *)((void *)(&v2d[i])+j*4);
cout << endl;
}
// add elements to v2d[0]
const int ADDNUM = 10;
for(int i = 0; i<ADDNUM; i++){
v2d[0].emplace_back(2);
// v2d[0].insert(i);
// v2d[0][i]=i*i;
}
// check the space change
cout << "Ele[0] size : " << v2d[0].size() << endl;
for(int i = 0; i<v2d.size(); i++){
cout << " " << &v2d[i] << endl;
}
//check ele[0] location
cout << endl;
for(int i = 0; i<ADDNUM; i++){
cout << " " << &v2d[0][i];
}
vector具体底层实现
(1)扩容
vector的底层数据结构是数组。
当vector中的可用空间耗尽时,就要动态第扩大内部数组的容量。直接在原有物理空间的基础上追加空间?这不现实。数组特定的地址方式要求,物理空间必须地址连续,而我们无法保证其尾部总是预留了足够空间可供拓展。一种方法是,申请一个容量更大的数组,并将原数组中的成员都搬迁至新空间,再在其后方进行插入操作。新数组的地址由OS分配,与原数据区没有直接的关系。新数组的容量总是取作原数组的两倍。
(2)插入和删除
插入给定值的过程是,先找到要插入的位置,然后将这个位置(包括这个位置)的元素向后整体移动一位,然后将该位置的元素复制为给定值。删除过程则是将该位置以后的所有元素整体前移一位。
(2)vector的size和capacity
size指vector容器当前拥有的元素个数,capacity指容器在必须分配新存储空间之前可以存储的元素总数,capacity总是大于或等于size的。
size() – 返回目前存在的元素数。即: 元素个数
capacity() – 返回容器能存储 数据的个数。 即:容器容量
reserve() --设置 capacity 大小
resize() --设置 size ,重新指定有效元素的个数 ,区别与reserve()指定 容量的大小
clear() --清空所有元素,把size设置成0,capacity不变
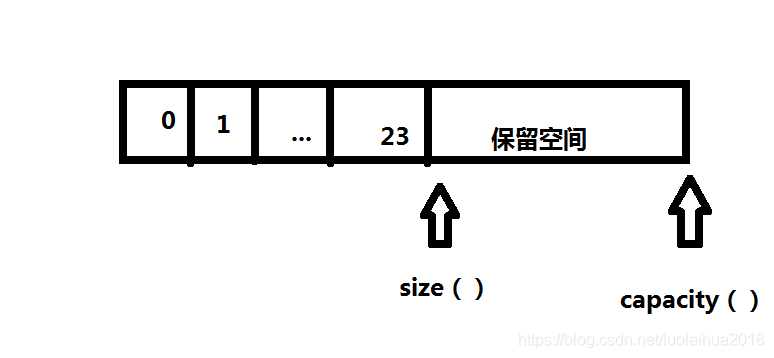
针对capacity这个属性,STL中的其他容器,如list map set deque,由于这些容器的内存是散列分布的,因此不会发生类似realloc()的调用情况,因此我们可以认为capacity属性针对这些容器是没有意义的,因此设计时这些容器没有该属性。
在STL中,拥有capacity属性的容器只有vector和string。
共同点
(1.)都和数组相似,都可以使用标准数组的表示方法来访问每个元素(array和vector都对下标运算符[ ]进行了重载)
(2.)三者的存储都是连续的,可以进行随机访问
不同点
(0.)数组是不安全的,array和vector是比较安全的(有效的避免越界等问题)
(1.)array对象和数组存储在相同的内存区域(栈)中,vector对象存储在自由存储区(堆)malloc和new的空间也是在堆上,原因是栈的空间在编译代码的时候就要确定好,堆空间可以运行时分配。
(2.)array可以将一个对象赋值给另一个array对象,但是数组不行
(3.)vector属于变长的容器,即可以根据数据的插入和删除重新构造容器容量;但是array和数组属于定长容器
(4.)vector和array提供了更好的数据访问机制,即可以使用front()和back()以及at()(at()可以避免a[-1]访问越界的问题)访问方式,使得访问更加安全。而数组只能通过下标访问,在写程序中很容易出现越界的错误
(5.)vector和array提供了更好的遍历机制,即有正向迭代器和反向迭代器
(6.)vector和array提供了size()和Empty(),而数组只能通过sizeof()/strlen()以及遍历计数来获取大小和是否为空
(7.)vector和array提供了两个容器对象的内容交换,即swap()的机制,而数组对于交换只能通过遍历的方式逐个交换元素
(8.)array提供了初始化所有成员的方法fill()
(9.)由于vector的动态内存变化的机制,在插入和删除时,需要考虑迭代的是否有效问题
(10.)vector和array在声明变量后,在声明周期完成后,会自动地释放其所占用的内存。对于数组如果用new[ ]/malloc申请的空间,必须用对应的delete[ ]和free来释放内存
//创建一个vector,元素个数为nSize
vector(int nSize)
//指定值初始化,ilist5被初始化为包含7个值为3的int
//vector(int nSize,const t& t)
//创建一个vector,元素个数为nSize,且值均为t
vector<int> ilist5(7,3);
//区分列表初始化, 包含7 和 3两个元素
vector<int> ilist5{7,3};
array 与 vector 默认初始化
std::array 和 std::vector 的默认初始化:对于类类型,未显式初始化的元素会调用默认构造函数进行初始化。
未初始化:
new 或其他方式动态分配内存并且没有显式初始化,那么这些元素将包含未定义的值(即“乱码”)。//改变大小,预分配空间,增加 vector 的容量(capacity),但 size 保持不变。
vals.reserve(cnt.size());
// 将 vector 大小调整为 10,用 0 填充新位置
vec.resize(10, 0);
二维vector
// 二维vector, 两个维度的长度都未知时:
std::vector<std::vector<int>> matrix;
// 假设我们知道行数,但列数未知
int numRows = 3;
// 预先分配行数
matrix.resize(numRows);
// 动态添加列
matrix[0].push_back(1);
matrix[0].push_back(2);
matrix[1].push_back(3);
matrix[1].push_back(4);
matrix[2].push_back(5);
其余情况
//已知一个维度,第二维度为空
// vector<vector<bool>> name (xSize, vector<bool>(ySize, false));
vector<vector<int>> alphaIndexList{26, vector<int>(0)};
//或者
vector<int> alphaIndexList[26];
alphaIndexList[i].push_back(x);
//两个都不知道 ,也可以使用指针
vector<int>* todo;
todo= &alphaIndexList[i];
int n = todo->size(); // (*todo).size();
for(auto &x: *todo)
vector 也支持中间insert元素,但是性能远差于list。
void push_back(const T& x) //向量尾部增加一个元素X
void emplace_back(const T& x)
//iterator insert(iterator it,const T& x) :向量中迭代器指向元素前增加一个元素x
result.insert(result.begin()+p,x); :在result的index为p的位置插入元素
iterator insert(iterator it,int n,const T& x) :向量中迭代器指向元素前增加n个相同的元素x
iterator insert(iterator it,const_iterator first,const_iterator last):向量中迭代器指向元素前插入另一个相同类型向量的[first,last)间的数据
iterator erase(iterator it) :删除向量中迭代器指向元素
iterator erase(iterator first,iterator last):删除向量中[first,last)中元素
void pop_back() :删除向量中最后一个元素
void clear() :清空向量中所有元素
void swap(vector&) :交换两个同类型向量的数据
void assign(int n,const T& x) :设置向量中前n个元素的值为x
void assign(const_iterator first,const_iterator last):向量中[first,last)中元素设置成当前向量元素
#include <algorithm> //或者#include <bits/stdc++.h>
reverse(a.begin(), a.end());
std::reverse(a,a+5); //转换0~5下标的元素
元素排序
如果需要元素有序,考虑stable_sort
#include <algorithm> // 包含 sort 函数
#include <functional> // 包含 std::greater 比较器
//默认是从低到高,加入std::greater<int>() 变成从高到低排序
sort(nums.begin(),nums.end(),std::greater<int>());
//vector of pair
vector<pair<int, char>> arr = {{a, 'a'}, {b, 'b'}, {c, 'c'}};
//c++11 using lambda and auto
std::sort(v.begin(), v.end(), [](auto &left, auto &right) {
return left.second < right.second;
});
// or
sort(arr.begin(), arr.end(),
[](const pair<int, char> & p1, const pair<int, char> & p2) {
return p1.first > p2.first;
}
);
//origin
struct sort_pred {
bool operator()(const std::pair<int,int> &left, const std::pair<int,int> &right) {
return left.second < right.second;
}
};
std::sort(v.begin(), v.end(), sort_pred());
vector<int> Arrs {1,2,3,4,5,6,7,8,9}; // 假设有这么个数组,要截取中间第二个元素到第四个元素:2,3,4
vector<int>::const_iterator First = Arrs.begin() + 1; // 找到第二个迭代器
vector<int>::const_iterator Second = Arrs.begin() + 3; // 找到第三个迭代器
vector<int> Arrs2(First, Second); // 将值直接初始化到Arrs2
迭代器是指可在容器对象上遍访的对象
或者assign()功能函数实现截取
assign() 功能函数是vector容器的成员函数。原型:
1:void assign(const_iterator first,const_iterator last);//两个指针,分别指向开始和结束的地方
2:void assign(size_type n,const T& x = T()); //n指要构造的vector成员的个数, x指成员的数值,他的类型必须与vector类型一致!
reference at(int pos) :返回pos位置元素的引用
reference front() :返回首元素的引用
reference back() :返回尾元素的引用
iterator begin() :返回向量头指针,指向第一个元素
iterator end() :返回向量尾指针,指向向量最后一个元素的下一个位置
reverse_iterator rbegin() :反向迭代器,指向最后一个元素
reverse_iterator rend() :反向迭代器,指向第一个元素之前的位置
// 判断函数
bool empty() const :判断向量是否为空,若为空,则向量中无元素
// 大小函数
int size() const :返回向量中元素的个数
int capacity() const :返回当前向量所能容纳的最大元素值
int max_size() const :返回最大可允许的vector元素数量值
返回表示
#include<functional>
auto hash_p = [](const pair<int, int> &p) -> size_t {
static hash<long long> hash_ll;
return hash_ll(p.first + (static_cast<long long>(p.second) << 32));//64位高低一半存储x和y
};
static_cast 用于良性类型转换,一般不会导致意外发生,风险很低。
hash <K> 模板专用的算法取决于实现,但是如果它们遵循 C++14 标准的话,需要满足一些具体的要求。这些要求如下:
https://www.runoob.com/w3cnote/cpp-vector-container-analysis.html
【C++容器】数组和vector、array三者区别和联系 https://blog.51cto.com/liangchaoxi/4056308
https://blog.csdn.net/y601500359/article/details/105297918
———————————————— 版权声明:本文为CSDN博主「stitching」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/qq_40250056/article/details/114681940
———————————————— 版权声明:本文为CSDN博主「FishBear_move_on」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/haluoluo211/article/details/80877558
———————————————— 版权声明:本文为CSDN博主「SOC罗三炮」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/luolaihua2018/article/details/109406092
———————————————— 版权声明:本文为CSDN博主「鱼思故渊」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/yusiguyuan/article/details/40950735


java 21 SDK seems not contain Java Control Panel (javacpl.exe), you need to install Java SE Development Kit 8u381 which include JDK 1.8 and JRE 1.8https://www.topcoder.com to allowed website (Attention: https)ContestAppletProd.jnlp127.0.0.1 proxy and HTTP TUNE 1 to connect to server暂无
暂无
无
strings, lists, tuples
调参需要测试间隔值
enumerate 函数结合 for 循环遍历 list,以修改 list 中的元素。enumerate 函数返回一个包含元组的迭代器,其中每个元组包含当前遍历元素的索引和值。在 for 循环中,我们通过索引 i 修改了列表中的元素。# 对于 二维list appDataDict
baseline = appDataDict[0][0] # CPU Total
for i, line in enumerate(appDataDict):
for j, entry in enumerate(line):
appDataDict[i][j] = round(entry/baseline, 7)
itertools --- 为高效循环而创建迭代器的函数
x = round(x,3)# 保留小数点后三位
%c 格式化字符及其ASCII码
%s 格式化字符串
%d 格式化整数
%u 格式化无符号整型
%o 格式化无符号八进制数
%x 格式化无符号十六进制数
%X 格式化无符号十六进制数(大写)
%f 格式化浮点数字,可指定小数点后的精度
%e 用科学计数法格式化浮点数
%E 作用同%e,用科学计数法格式化浮点数
%g %f和%e的简写
%G %F 和 %E 的简写
%p 用十六进制数格式化变量的地址
' '.join(pass_list) and pass_list.split(" ")
对齐"\n".join(["%-10s" % item for item in List_A])
text = "Hello, world!"
if text.startswith("Hello"):
print("The string starts with 'Hello'")
else:
print("The string does not start with 'Hello'")
Python2.6 开始,通过 {} 和 : 来代替以前的 %
>>>"{} {}".format("hello", "world") # 不设置指定位置,按默认顺序
'hello world'
>>> "{1} {0} {1}".format("hello", "world") # 设置指定位置
'world hello world'
# 字符串补齐100位,<表示左对齐
variable = "Hello"
padded_variable = "{:<100}".format(variable)
数字处理
https://www.runoob.com/python/python-lists.html
切片
格式:[start_index:end_index:step]
不包括end_index的元素
二维数组
排序
# take second element for sort
def takeSecond(elem):
return elem[2]
LCData.sort(key=takeSecond)
# [1740, '黄业琦', 392, '第 196 场周赛'],
# [1565, '林坤贤', 458, '第 229 场周赛'],
# [1740, '黄业琦', 458, '第 229 场周赛'],
# [1509, '林坤贤', 460, '第 230 场周赛'],
# [1740, '黄业琦', 460, '第 230 场周赛'],
# [1779, '黄业琦', 558, '第 279 场周赛'],
对应元素相加到一个变量
对于等长的
list1 = [1, 2, 3, 4, 5]
list2 = [6, 7, 8, 9, 10]
result = [x + y for x, y in zip(list1, list2)]
print(result)
如果两个列表的长度不同,你可以使用zip_longest()函数来处理它们。zip_longest()函数可以处理不等长的列表,并使用指定的填充值填充缺失的元素。
from itertools import zip_longest
list1 = [1, 2, 3, 4, 5]
list2 = [6, 7, 8]
result = [x + y for x, y in zip_longest(list1, list2, fillvalue=0)]
print(result)
如果是二维list
list1 = [[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]
list2 = [[10, 11, 12],
[13, 14, 15]]
rows = max(len(list1), len(list2))
cols = max(len(row) for row in list1 + list2)
result = [[0] * cols for _ in range(rows)]
for i in range(rows):
for j in range(cols):
if i < len(list1) and j < len(list1[i]):
result[i][j] += list1[i][j]
if i < len(list2) and j < len(list2[i]):
result[i][j] += list2[i][j]
print(result)
# 将一个二维列表的所有元素除以一个数A
result = [[element / A for element in row] for row in list1]
empty dict
a_dict = {'color': 'blue'}
for key in a_dict:
print(key)
# color
for key in a_dict:
print(key, '->', a_dict[key])
# color -> blue
for item in a_dict.items():
print(item)
# ('color', 'blue')
for key, value in a_dict.items():
print(key, '->', value)
# color -> blue
key和value支持tuple元组,常用于保存函数入参与结果映射
类似c++ 的 pair<int,int>
class RoPE3D(nn.Module):
def __init__(self, freq=10000.0, interpolation_scale=(1, 1, 1)):
super().__init__()
self.cache = {}
def get_cos_sin(self, dim, seq_len, device, dtype, interpolation_scale=1):
if (dim, seq_len, device, dtype) not in self.cache:
# ...
self.cache[dim, seq_len, device, dtype] = (cos, sin)
return self.cache[dim, seq_len, device, dtype]
if (dim, seq_len, device, dtype) not in self.cache 的条件判断self.cache 的键是类似 (128, 100, "cuda", torch.float32) 的元组。(dim, seq_len, device, dtype) 这个完整元组不在字典中时,条件为 True,才会执行后续代码。如果元组中的任意一个元素不同(如 seq_len 变化),则会被视为不同的键。
关于 self.cache[...] = (cos, sin) 的赋值
(dim, seq_len, device, dtype) 的四元组,用于唯一标识一组计算参数。(cos值张量, sin值张量) 的二元组,因为这两个张量总是成对出现。self.cache[(128, 100, "cuda", float32)] = (cos_tensor, sin_tensor)进一步解释这种设计的目的:
cos/sin,不同参数组合会生成不同的键。你可以通过一个简单例子验证:
key 支持tuple元组, 但是不能json.dump()
但是这样就不支持json.dump, json.dump() 无法序列化 Python 中元组(tuple)作为字典的 key,这会导致 json.dump() 函数在写入此类字典数据时会进入死循环或陷入卡住状态
tinydict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
tinydict['Age'] = 8 # 更新
tinydict['School'] = "RUNOOB" # 添加
合并
以下是两种常用的方法:
方法一:使用in操作符: in操作符返回一个布尔值,True表示存在,False表示不存在。
Copy code
my_dict = {"key1": "value1", "key2": "value2", "key3": "value3"}
# 判断是否存在指定的键
if "key2" in my_dict:
print("Key 'key2' exists in the dictionary.")
else:
print("Key 'key2' does not exist in the dictionary.")
方法二:使用dict.get()方法: dict.get()方法在键存在时返回对应的值,不存在时返回None。根据需要选择适合的方法进行判断。
Copy code
my_dict = {"key1": "value1", "key2": "value2", "key3": "value3"}
# 判断是否存在指定的键
if my_dict.get("key2") is not None:
print("Key 'key2' exists in the dictionary.")
else:
print("Key 'key2' does not exist in the dictionary.")
这两种方法都可以用来判断字典中是否存在指定的键。
无序不重复序列
a= set() # 空set
thisset = set(("Google", "Runoob", "Taobao"))
>>> basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
>>> print(basket) # 这里演示的是去重功能
https://blog.csdn.net/weixin_63719049/article/details/125680242
^ 匹配字符串的开头
$ 匹配字符串的末尾。
. 匹配任意字符,除了换行符
a| b 匹配a或b
[a-zA-Z0-9] 匹配任何字母及数字
\d 匹配数字。等价于[0-9]。
[aeiou] 匹配中括号内的任意一个字母
[^aeiou] 除了aeiou字母以外的所有字符
\w 匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]'。
(\s*) 或者 ([\t ]*) 来匹配任意TAB和空格的混合字符
\s 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。
\S 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。
\b 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。
\B 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。
re* 匹配0个或多个的表达式。
re+ 匹配1个或多个的表达式。
re? 匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式
re{ n} 精确匹配 n 个前面表达式。
例如, o{2} 不能匹配 "Bob" 中的 "o",
但是能匹配 "food" 中的两个 o。
re{ n,} 匹配 n 个前面表达式。
例如, o{2,} 不能匹配"Bob"中的"o",
但能匹配 "foooood"中的所有 o。
"o{1,}" 等价于 "o+"。
"o{0,}" 则等价于 "o*"。
re{ n, m} 匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式
# find should use \ to represent the (6|12|3)
$ find ~/github/gapbs/ -type f -regex '.*/kron-\(6\|12\|3\).*'
/staff/shaojiemike/github/gapbs/kron-12.wsg
/staff/shaojiemike/github/gapbs/kron-3.sg
/staff/shaojiemike/github/gapbs/kron-3.wsg
/staff/shaojiemike/github/gapbs/kron-6.sg
/staff/shaojiemike/github/gapbs/kron-6.wsg
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;
而re.search匹配整个字符串,直到找到一个匹配。
从字符串的起始位置匹配
多个标志可以通过按位 OR(|) 它们来指定。如 re.I | re.M被设置成 I 和 M 标志:
matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)
if matchObj:
print "matchObj.group() : ", matchObj.group()
print "matchObj.group(1) : ", matchObj.group(1)
print "matchObj.group(2) : ", matchObj.group(2)
else:
print "No match!!"
打印部分内容
返回元组,可以指定开始,与结束位置。
result = re.findall(r'(\w+)=(\d+)', 'set width=20 and height=10')
print(result)
# [('width', '20'), ('height', '10')]
import re
# 打开x86汇编代码文件
with open(assembly) as f:
# 读取文件内容
content = f.read()
# 使用正则表达式匹配所有汇编指令,
pattern = r'\b([a-zA-Z]{3,6})\b.*'
# 匹配pattern,但是只将()内结果保存在matches中
matches = re.findall(pattern, content)
# 输出匹配结果
for match in matches:
print(match)
暂无
暂无
https://blog.csdn.net/weixin_39594191/article/details/111611346
https://www.runoob.com/python/python-reg-expressions.html
Python从设计之初就已经是一门面向对象的语言,正因为如此,在Python中创建一个类和对象是很容易的。
类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
实例化:创建一个类的实例,类的具体对象。
在Python中,类变量和实例变量是两个不同的概念:
类变量(Class Variable)
定义在类内部,但不在任何方法之内
用于定义与这个类相关的特征或属性
实例变量(Instance Variable)
定义在类内部的方法之内
例如:
class Person:
species = 'Human' # 类变量
def __init__(self, name):
self.name = name # 实例变量
p1 = Person('John')
p2 = Person('Mary')
print(p1.species) # Human
print(p2.species) # Human
print(p1.name) # John
print(p2.name) # Mary
综上,类变量用于定义类的通用属性,实例变量用于定义实例的独特属性。区分二者是理解Python面向对象的关键。
class Employee:
'所有员工的基类'
empCount = 0 # 类变量
def __init__(self, name, salary):
self.name = name
self.salary = salary
Employee.empCount += 1
def displayCount(self):
print "Total Employee %d" % Employee.empCount
def displayEmployee(self):
print "Name : ", self.name, ", Salary: ", self.salary
必须有一个额外的第一个参数名称, 按照惯例它的名称是 self,self 不是 python 关键字,换成其他词语也行。
通过继承创建的新类称为子类或派生类,被继承的类称为基类、父类或超类。
继承语法 class 派生类名(基类名)
调用基类的方法时,需要加上基类的类名前缀,且需要带上 self 参数变量。区别在于类中调用普通函数时并不需要带上 self 参数 ,这点在代码上的区别如下:
class Base:
def base_method(self):
print("Base method")
class Derived(Base):
def derived_method(self):
# 调用基类方法要加类名前缀
Base.base_method(self)
# 调用普通函数
print("Hello")
d = Derived()
d.derived_method()
# 输出
Base method
Hello
在Derived类中:
调用Base基类的方法base_method(),需要写成Base.base_method(self)
调用普通函数print(),直接写函数名即可
区别在于:
而对于普通函数,只需要直接调用即可,不需要self参数。
这与Python的名称空间和面向对象实现有关,是理解Python类继承的关键点。
__init__ : 构造函数,在生成对象时调用
__del__ : 析构函数,释放对象时使用
__repr__ : 打印,转换
__setitem__ : 按照索引赋值
__getitem__: 按照索引获取值
__len__: 获得长度
__cmp__: 比较运算
__call__: 函数调用
__add__: 加运算
__sub__: 减运算
__mul__: 乘运算
__truediv__: 除运算
__mod__: 求余运算
__pow__: 乘方
PyTorch 中如果继承torch.nn.Module,执行__call__会转接到forward方法
torch.nn.Module 的 __call__ 方法会调用 forward 方法,并且在调用 forward 之前和之后还会执行一些其他的操作,比如设置钩子(hooks)和调用 _check_forward_hooks 等。
以下是 torch.nn.Module 中 __call__ 方法的简化实现逻辑:
class Module:
def __call__(self, *input, **kwargs):
# 在调用 forward 之前执行一些操作
# 例如,调用 forward pre-hooks
for hook in self._forward_pre_hooks.values():
result = hook(self, input)
if result is not None:
if not isinstance(result, tuple):
result = (result,)
input = result
# 调用 forward 方法
result = self.forward(*input, **kwargs)
# 在调用 forward 之后执行一些操作
# 例如,调用 forward hooks
for hook in self._forward_hooks.values():
hook_result = hook(self, input, result)
if hook_result is not None:
result = hook_result
return result
__call__ 方法:当你实例化一个 Module 并调用它时(例如 model(input)),Python 会调用 __call__ 方法。forward 方法:__call__ 方法内部会调用 forward 方法,这是你需要在子类中重写的方法,用于定义前向传播的逻辑。forward 之前和之后,__call__ 方法会处理一些钩子。这些钩子可以用于调试、可视化或其他目的。在Python中可以通过特殊方法__iadd__来对+=符号进行重载。
__iadd__需要定义在类中,用于指定+=操作时的具体行为。例如:
class Vector:
def __init__(self, x, y):
self.x = x
self.y = y
def __iadd__(self, other):
self.x += other.x
self.y += other.y
return self
v1 = Vector(1, 2)
v2 = Vector(3, 4)
v1 += v2
print(v1.x, v1.y) # 4, 6
这里我们定义了__iadd__方法,用于实现两个Vector对象使用+=时的相加操作。
__iadd__方法的参数是另一个要相加的对象,在方法内部我们实现了两个向量的分量相加,并返回self作为结果。这样就实现了+=的运算符重载。
此外,Python还提供了__add__特殊方法用于重载+符号,但是__iadd__和__add__有以下区别:
所以对可变对象进行+=操作时,通常需要实现__iadd__方法。
面向过程是一种以事件为中心的编程思想,编程的时候把解决问题的步骤分析出来,然后用函数把这些步骤实现,在一步一步的具体步骤中再按顺序调用函数。
在日常生活或编程中,简单的问题可以用面向过程的思路来解决,直接有效,但是当问题的规模变得更大时,用面向过程的思想是远远不够的。所以慢慢就出现了面向对象的编程思想。世界上有很多人和事物,每一个都可以看做一个对象,而每个对象都有自己的属性和行为,对象与对象之间通过方法来交互。面向对象是一种以“对象”为中心的编程思想,把要解决的问题分解成各个对象,建立对象的目的不是为了完成一个步骤,而是为了描叙某个对象在整个解决问题的步骤中的属性和行为。
优点:
缺点:
优点:
缺点:
静态类型语言的
动态类型语言的
runtime 描述了程序运行时候执行的软件/指令, 在每种语言有着不同的实现。
可大可小,在 C 中,runtime 是库代码, 等同于 C runtime library,一系列 C 程序运行所需的函数。
在 Java 中,runtime 还提供了 Java 程序运行所需的虚拟机等。
总而言之,runtime 是一个通用抽象的术语,指的是计算机程序运行的时候所需要的一切代码库,框架,平台等。
在 Go 中, 有一个 runtime 库,其实现了垃圾回收,并发控制, 栈管理以及其他一些 Go 语言的关键特性。 runtime 库是每个 Go 程序的一部分,也就是说编译 Go 代码为机器代码时也会将其也编译进来。所以 Go 官方将其定位偏向类似于 C 语言中的库。
Go 中的 runtime 不像 Java runtime (JRE, java runtime envirement ) 一样,jre 还会提供虚拟机, Java 程序要在 JRE 下 才能运行。
作为支持指针的编程语言,C++将动态管理存储器资源的便利性交给了程序员。在使用指针形式的对象时(请注意,由于引用在初始化后不能更改引用目标 的语言机制的限制,多态性应用大多数情况下依赖于指针进行),程序员必须自己完成存储器的分配、使用和释放,语言本身在此过程中不能提供任何帮助。
某些语言提供了垃圾回收机制,也就是说程序员仅负责分配存储器和使用,而由语言本身负责释放不再使用的存储器,这样程序员就从讨厌的存储器管理的工作中脱身了。
C++的设计者Bjarne Stroustrup对此做出过解释:
“我有意这样设计C++,使它不依赖于自动垃圾回收(通常就直接说垃圾回收)。这是基于自己对垃圾回收系统的经验,我很害怕那种严重的空间和时间开销,也害怕由于实现和移植垃圾回收系统而带来的复杂性。还有,垃圾回收将使C++不适合做许多底层的工作,而这却正是它的一个设计目标。但我喜欢垃圾回收 的思想,它是一种机制,能够简化设计、排除掉许多产生错误的根源。 需要垃圾回收的基本理由是很容易理解的:用户的使用方便以及比用户提供的存储管理模式更可靠。而反对垃圾回收的理由也有很多,但都不是最根本的,而是关于实现和效率方面的。 已经有充分多的论据可以反驳:每个应用在有了垃圾回收之后会做的更好些。类似的,也有充分的论据可以反对:没有应用可能因为有了垃圾回收而做得更好。 并不是每个程序都需要永远无休止的运行下去;并不是所有的代码都是基础性的库代码;对于许多应用而言,出现一点存储流失是可以接受的;许多应用可以管理自己的存储,而不需要垃圾回收或者其他与之相关的技术,如引用计数等。 我的结论是,从原则上和可行性上说,垃圾回收都是需要的。但是对今天的用户以及普遍的使用和硬件而言,我们还无法承受将C++的语义和它的基本库定义在垃圾回收系统之上的负担。”
1.强类型语言:使之强制数据类型定义的语言。没有强制类型转化前,不允许两种不同类型的变量相互操作。强类型定义语言是类型安全的语言,如Rust, Java、C# 和 Python,比如Java中“int i = 0.0;”是无法通过编译的;
2.弱类型语言:数据类型可以被忽略的语言。与强类型语言相反, 一个变量可以赋不同数据类型的值,允许将一块内存看做多种类型,比如直接将整型变量与字符变量相加。C/C++、PHP都是弱类型语言,比如C++中“int i = 0.0;”是可以编译运行的;
注意,强类型语言在速度上略逊色于弱类型语言,使用弱类型语言可节省很多代码量,有更高的开发效率。而对于构建大型项目,使用强类型语言可能会比使用弱类型更加规范可靠。
a data-parallel languagedesigned specifically to target Intel’s vector extensions
Intel® Implicit SPMD Program Compiler
An open-source compiler for high-performance SIMD programming on the CPU and GPU
ispc is a compiler for a variant of the C programming language, with extensions for "single program, multiple data" (SPMD) programming.
暂无
暂无
https://blog.csdn.net/yuanmengong886/article/details/52572533