Thread
导言
通过多线程来利用多核是常见的加速方法,但是随着代码的开发,运行时可能有30~40个子线程共存,但是这些线程的重要程度往往是不同的,OS默认调度是感知不到线程的重要性,
因此需要:
- 使用线程优先级来提高线程的重要性。
- 通过主动绑核来隔离各个线程。
基础知识
切换开销
线程在核间切换的开销是极小的(Java uses lots of threads but threads have become significantly faster and cheaper with the NPTL in Linux 2.6.),与其考虑切换开销,不如注意不同优先级线程同一个核竞争的问题。
静态/动态优先级 与 调度域
- 基本概念:
- 静态/动态优先级:见 深入理解Linux内核 - 第七章 进程调度 - 调度算法。
- 调度域:见 深入理解Linux内核 - 第七章 进程调度 - 多处理器系统中任务队列的平衡 - 调度域1
物理机调度会感知到超线程,NUMA结构,并避免在之间调度

创建
在C++中,有几种方式可以实现线程的创建。下面是一些常见的方法:
1. 使用 C++11 标准库的 std::thread 类
这是C++11标准引入的线程库,使用起来非常方便。你可以直接创建一个 std::thread 对象并传递一个函数或可调用对象(如lambda表达式)。
示例代码:
#include <iostream>
#include <thread>
void threadFunction() {
std::cout << "Hello from thread!" << std::endl;
}
int main() {
std::thread t(threadFunction); // 创建线程,立刻执行 threadFunction
t.join(); // 等待线程执行完毕
return 0;
}
std::thread t(threadFunction); 子线程会立刻执行
使用 std::thread 创建的子线程会立刻开始执行。具体来说,当你创建 std::thread 对象并将函数或可调用对象传递给它时,线程会立即开始执行你传递的函数或代码块。
例如,以下代码中的子线程会在创建后立即执行 threadFunction:
#include <iostream>
#include <thread>
void threadFunction() {
std::cout << "Hello from thread!" << std::endl;
}
int main() {
std::thread t(threadFunction); // 创建线程,子线程立刻开始执行
t.join(); // 等待子线程执行完毕
return 0;
}
在这段代码中,一旦执行到 std::thread t(threadFunction); 这行代码,子线程会立刻开始执行 threadFunction。主线程则继续执行后面的代码。在调用 t.join(); 之前,主线程和子线程是并行执行的。
需要注意的是,如果不调用 t.join();,主线程可能会在子线程完成之前就结束,从而导致子线程的输出可能不会被看到。因此,通常会使用 join() 来确保主线程等待子线程执行完毕。
2. 使用 std::async 和 std::future
std::async 可以用于异步执行任务,返回一个 std::future 对象,你可以通过这个对象获取任务的执行结果。
示例代码:
#include <iostream>
#include <future>
int asyncFunction() {
return 42;
}
int main() {
std::future<int> result = std::async(asyncFunction); // 异步执行函数
std::cout << "Result: " << result.get() << std::endl; // 获取结果
return 0;
}
3. 使用 POSIX 线程(Pthreads)
在使用较早的C++版本或在一些特定的操作系统(如Linux)下,pthread 是创建和管理线程的常用方式。需要包含 <pthread.h> 头文件。
示例代码:
#include <iostream>
#include <pthread.h>
void* threadFunction(void*) {
std::cout << "Hello from POSIX thread!" << std::endl;
return nullptr;
}
int main() {
pthread_t thread;
pthread_create(&thread, nullptr, threadFunction, nullptr); // 创建POSIX线程
pthread_join(thread, nullptr); // 等待线程结束
return 0;
}
4. 使用Boost库
Boost库提供了丰富的线程管理功能,使用起来与标准库类似,但需要安装Boost库。
示例代码:
#include <boost/thread.hpp>
#include <iostream>
void threadFunction() {
std::cout << "Hello from Boost thread!" << std::endl;
}
int main() {
boost::thread t(threadFunction); // 创建Boost线程
t.join(); // 等待线程执行完毕
return 0;
}
5. 使用原生操作系统API
可以直接调用操作系统提供的API来创建线程,例如在Windows上使用 CreateThread,在Unix/Linux上使用 pthread_create。
Windows上的示例代码:
#include <windows.h>
#include <iostream>
DWORD WINAPI threadFunction(LPVOID lpParam) {
std::cout << "Hello from Windows thread!" << std::endl;
return 0;
}
int main() {
HANDLE thread = CreateThread(
nullptr, // 默认安全属性
0, // 默认堆栈大小
threadFunction, // 线程函数
nullptr, // 线程函数参数
0, // 默认创建标志
nullptr); // 返回线程ID
WaitForSingleObject(thread, INFINITE); // 等待线程结束
CloseHandle(thread); // 关闭线程句柄
return 0;
}
总结
- C++11
std::thread是最常用和推荐的方式,简单易用且跨平台。 std::async更适合用于需要返回值的异步操作。- POSIX
pthread适合在类Unix系统上使用,适应性强但需要更多的低层管理。 - Boost线程库 提供了丰富的功能,适合需要额外功能的场合。
- 操作系统API 更适合需要与操作系统深度集成的场景。
修改
线程独占的信息很少,一般就是线程名的获取和设置。
线程名
#include <sys/prctl.h>
if (prctl(PR_SET_NAME, ("ACL_thread")) != 0) {
ASCEND_LOGE("set thread name failed!");
}
char thread_name[16]; // 线程名称最大为16字节,包括终止符
if (prctl(PR_GET_NAME, thread_name, 0, 0, 0) == 0) {
std::cout << "Thread name: " << thread_name << std::endl;
} else {
std::cerr << "Error getting thread name" << std::endl;
}
处理器亲和性
如何结合Host端和Device端的设计细节来高效线程调度
nvidia-smi等知道busID,- 使用类似
lspci -vv |grep "Processing a" -A 6知道NUMA拓扑 numactl -H看内存分布
鲲鹏920的环形总线结构
192核,分为8个node,每个node的24核又分为6个cluster,每个cluster的4个核为最小单元。
- 简单测试: 使用
taskset -c 0-4 {command},可以实现命令绑定在编号0-3核上。 - 代码内实现:
c++内通过pthread_setaffinity_np函数实现。- 绑定到NUMA node后,利用OS的自动CPU负载均衡即可。
将线程A绑定到一个核心上后,从这个线程创建出的子线程应该是会继承这个pthread_setaffinity_np的效果, 还有Thread name
htop -p pid里a选项可以显示已有的亲和性设置ps -p pid可以看见CMD相同。
CPU负载均衡:线程的自动切换
线程在不同的 CPU 核之间切换是一种常见现象,这种行为被称为 CPU 负载均衡。它并不总是为了让线程变快,而是为了更好地管理系统资源和提高整体系统性能。以下是为什么会发生这种切换的原因:
- 负载均衡:
- 操作系统调度器 会尝试将 CPU 负载分布在所有可用的核心上,以防止某些核心过载或某些核心闲置。这种均衡有助于提高系统的整体性能和响应速度。
-
当一个核心的负载变得很高时,调度器可能会将一些线程移到其他较空闲的核心上执行,以平衡系统负载。
-
热管理:
-
多核处理器通常具有动态电源管理和温度控制机制。如果某个核心由于过度使用而变热,调度器可能会将线程切换到另一个较冷的核心,以避免过热并确保处理器稳定运行。
-
中断处理:
-
操作系统可能会将某些中断处理程序绑定到特定的核心上。当这些中断发生时,当前正在处理的线程可能会被暂停,并移到另一个核心继续执行。
-
资源竞争:
-
不同的核心共享某些资源(例如缓存、内存控制器等)。如果多个线程在同一个核心上运行,可能会导致资源争用。调度器可以通过在不同核心之间移动线程来减轻这种争用,从而提高性能。
-
调度策略:
- Linux 内核使用的调度策略(如 CFS:Completely Fair Scheduler)可能会认为在不同核心之间移动线程可以更公平地分配 CPU 时间片,从而提高系统的整体吞吐量。
是否会变快?线程在不同核心之间的切换本身不会让某个线程“变快”。相反,频繁的切换会引入一些开销(如缓存失效,线程状态切换等),在某些情况下甚至可能导致性能下降。
然而,通过均衡负载、管理热量和资源争用,操作系统调度器可以确保系统的稳定性和长时间运行时的性能一致性。因此,从全局来看,这种行为通常有利于提高系统的整体性能和响应能力,而不仅仅是单个线程的性能。
解决方法:如果你希望某个线程固定在一个核心上运行(避免在不同核心之间切换),可以使用 CPU 亲和性 来绑定线程到特定核心。但在大多数情况下,操作系统调度器会比手动绑定做得更好,除非你有非常特殊的性能要求。
使用 isolcpus 的内核设置可以隔离核心,但是这需要重启,有什么办法能不重启实现隔离吗
你可以使用 cset 工具来动态隔离 CPU 核心,而无需重启系统。cset(cpuset 的前端工具)允许你创建 CPU 和内存的分组,并将特定的任务分配到这些分组中,从而达到核心隔离的效果。以下是如何使用 cset 实现隔离的基本步骤:
- 安装 cset:
如果你的系统上还没有安装 cset,你可以使用包管理工具进行安装,例如在 Ubuntu 上:
- 创建 CPU 集(cpuset):
使用 cset 创建一个新的 CPU 集,比如将 CPU 2 和 3 隔离:
- 将任务分配到隔离的 CPU 集:
你可以将一个特定的任务(如进程 ID 或命令)绑定到刚才创建的 CPU 集中:
或者,如果你有一个运行中的进程,假设它的 PID 是 1234:
- 查看当前 CPU 集:
你可以通过以下命令查看所有 CPU 集和任务的分配情况:
- 移除 CPU 集:
如果你想恢复 CPU 核心的默认状态,可以删除创建的 CPU 集:
通过使用 cset,你可以在不重启系统的情况下灵活地管理 CPU 核心的分配和隔离。
请注意,cset 适用于需要较高实时性和性能隔离的应用场景。如果你的系统任务调度特别复杂,使用 cset 进行动态隔离可能需要更多的调试和配置。
数据竞争
进程内的多个线程共享地址空间,意味着共享全局变量,需要使用锁来避免写冲突
- 线程不拥有系统资源,但它可以与同属一个进程的其他线程共享进程的资源。
- 线程有自己的程序计数器、寄存器集合和栈。
使用互斥锁访问全局变量
- 共享访问:
- 全局变量可以被进程中的所有线程访问和修改。
- 数据竞争:
- 当多个线程同时访问和修改同一个全局变量时,可能会发生数据竞争(race condition),导致不可预测的结果。
- 线程安全:
- 如果全局变量被多个线程访问,需要确保对这些变量的访问是线程安全的。这通常通过使用互斥锁(mutexes)、读写锁(read-write locks)、原子操作(atomic operations)或其他同步机制来实现。
- 可见性:
- 在某些情况下,一个线程对全局变量的修改可能不会立即对其他线程可见。这与处理器缓存、编译器优化以及内存屏障(memory barriers)的使用有关。
- 初始化:
- 全局变量的初始化在多线程环境中需要特别注意,以确保在任何线程访问变量之前,变量已经被正确初始化。
为了确保线程安全,可以使用互斥锁:
#include <iostream>
#include <thread>
#include <vector>
#include <mutex>
int globalVariable = 0;
std::mutex globalMutex; // 互斥锁
void incrementGlobal() {
std::lock_guard<std::mutex> lock(globalMutex); // 锁定互斥锁
globalVariable++;
}
int main() {
std::vector<std::thread> threads;
for (int i = 0; i < 10; ++i) {
threads.push_back(std::thread(incrementGlobal));
}
for (auto& thread : threads) {
thread.join();
}
std::cout << "Final value of globalVariable: " << globalVariable << std::endl;
return 0;
}
在这个同步版本中,我们使用 std::mutex 和 std::lock_guard 来确保每次只有一个线程可以修改全局变量,从而避免了数据竞争。
总之,虽然线程可以访问同一个全局变量,但必须小心处理并发访问,以确保程序的正确性和稳定性。
单例模式,全局(互斥锁)来监控,所有线程
要实现一个全局的 class 来统计进程中所有出现的线程的 TID,并为每个 TID 分配一个 CPU 核心,可以按照以下步骤进行设计。
- 提供注册线程和分配核心的功能。
- 提供一个静态实例,以确保全局唯一性。
#include <iostream>
#include <map>
#include <thread>
#include <mutex>
#include <sys/syscall.h>
#include <unistd.h>
class ThreadManager {
public:
// 获取ThreadManager实例
static ThreadManager& getInstance() {
static ThreadManager instance;
return instance;
}
// 注册线程并分配核心
void registerThread() {
std::lock_guard<std::mutex> lock(mutex_);
pid_t tid = syscall(SYS_gettid); // 获取当前线程的TID
if (threadMap_.find(tid) == threadMap_.end()) {
int core = getNextCore();
threadMap_[tid] = core;
std::cout << "Thread " << tid << " assigned to core " << core << std::endl;
}
}
// 获取分配给特定TID的核心
int getCore(pid_t tid) {
std::lock_guard<std::mutex> lock(mutex_);
auto it = threadMap_.find(tid);
if (it != threadMap_.end()) {
return it->second;
}
return -1; // 如果未找到TID,则返回-1
}
private:
std::map<pid_t, int> threadMap_; // 线程ID和核心的映射表
std::mutex mutex_; // 保护threadMap_的互斥锁
int nextCore_; // 下一个分配的核心号
ThreadManager() : nextCore_(0) {} // 构造函数初始化nextCore_
// 获取下一个核心号(简单轮询策略)
int getNextCore() {
int core = nextCore_;
nextCore_ = (nextCore_ + 1) % std::thread::hardware_concurrency(); // 轮询分配核心
return core;
}
// 禁止复制构造和赋值操作符
ThreadManager(const ThreadManager&) = delete;
ThreadManager& operator=(const ThreadManager&) = delete;
};
// 测试线程函数
void threadFunction() {
ThreadManager::getInstance().registerThread(); // 注册线程
// 线程的其他操作
}
int main() {
std::thread t1(threadFunction);
std::thread t2(threadFunction);
t1.join();
t2.join();
return 0;
}
-
ThreadManager 类:
- 采用了单例模式来确保全局唯一性。
registerThread()函数用于在threadMap_中注册线程的 TID 并分配核心号。getCore()函数用于获取特定 TID 的分配核心。
-
线程注册:
- 在每个线程中调用
ThreadManager::getInstance().registerThread()来注册线程的 TID 并分配核心。
- 在每个线程中调用
待研究
- pthread to learn
- 父子线程进程的退出影响
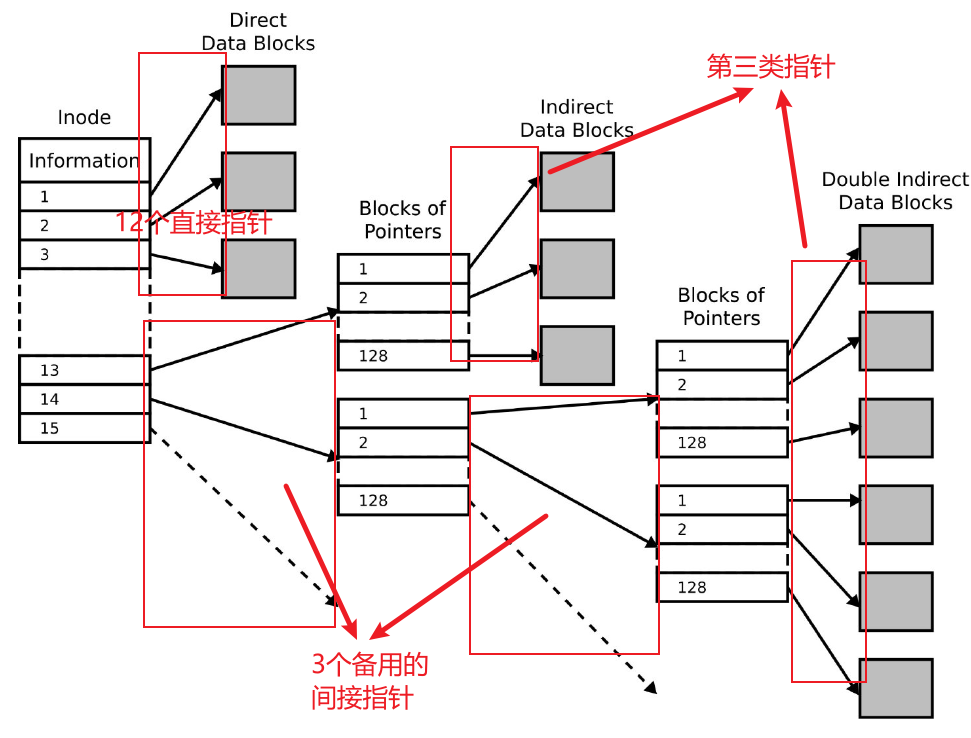
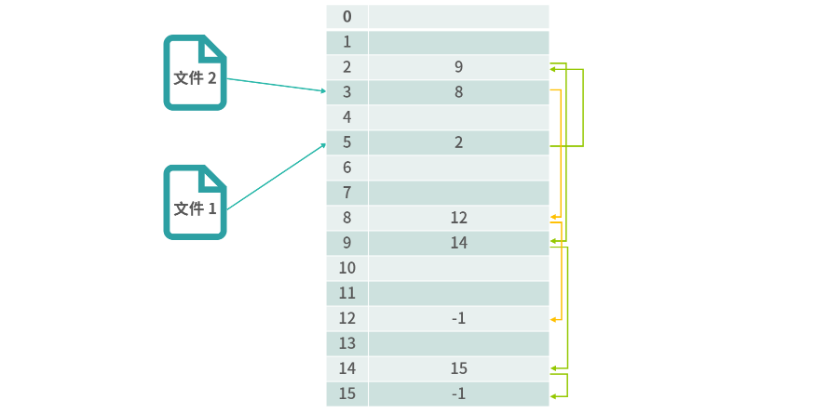 链表结构解决了文件和物理块映射的问题。
链表结构解决了文件和物理块映射的问题。