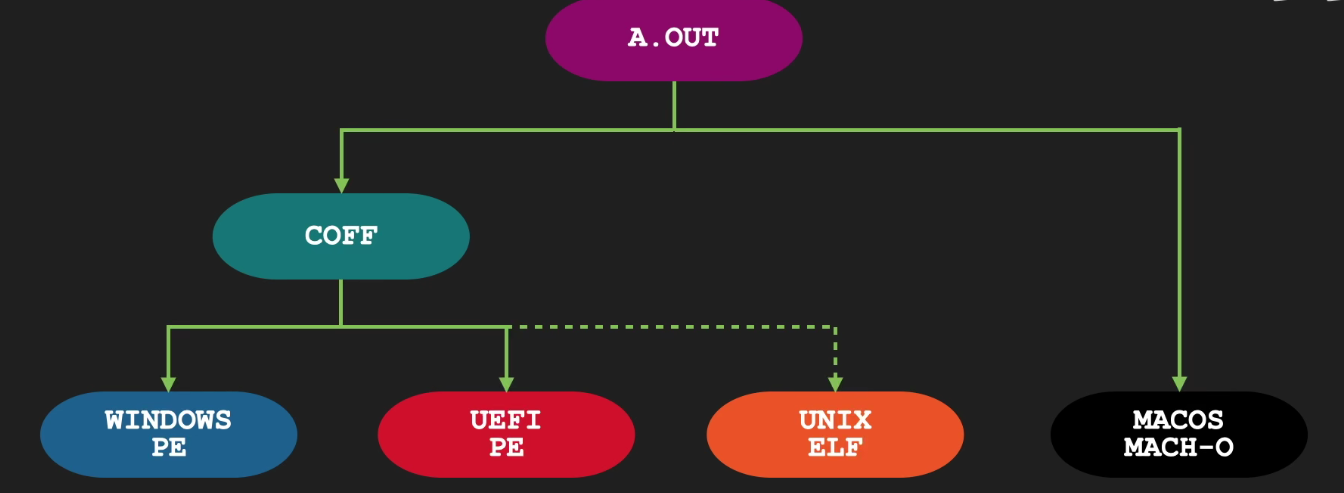
Address Translation
导言
Split address translation (virtual-to-physical mapping) part to individual post
导言
Split address translation (virtual-to-physical mapping) part to individual post
导言
This blog delves into Onur Mutlu's Address Translation work on Processing-in-Memory (PIM), titled "Utopia1: Fast and Efficient Address Translation via Hybrid Restrictive & Flexible Virtual-to-Physical Address Mappings."
编译是指编译器读取源程序(字符流),对之进行词法和语法的分析,将高级语言指令转换为功能等效的汇编代码。
#include语句以及一些宏插入程序文本中,得到main.i和sum.i文件。main.i和sum.i编译成文本文件main.s和sum.c的汇编语言程序。
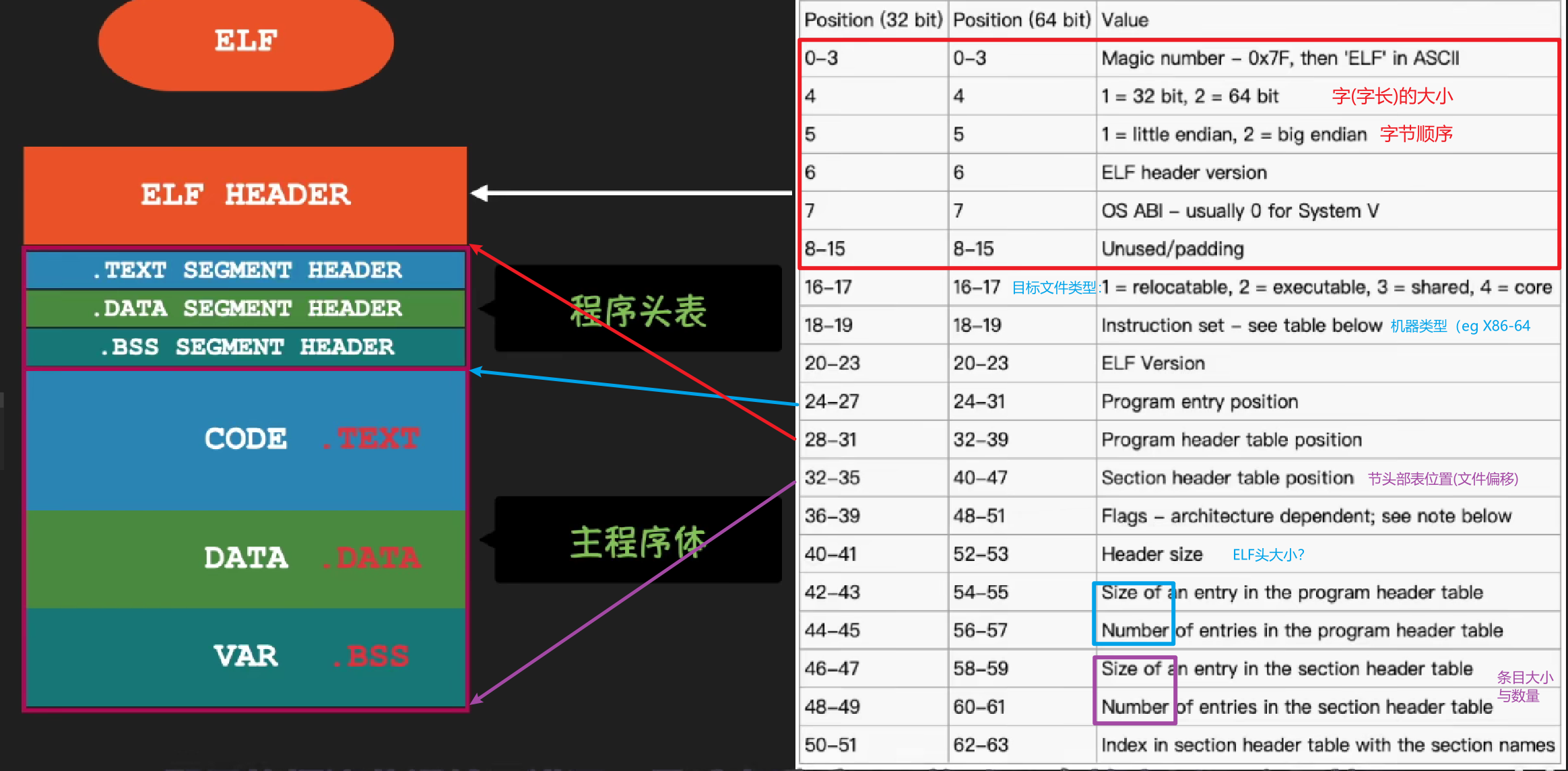
低级的汇编语言为不同的高级语言提供了通用输出语言。main.s和sum.s翻译成机器语言的二进制指令,并打包成一种叫做可重定位目标程序的格式,并将结果保存在main.o和sum.o两个文件中。这种文件格式就比较接近elf格式了。main.o和sum.o,得到可执行目标文件,就是elf格式文件。
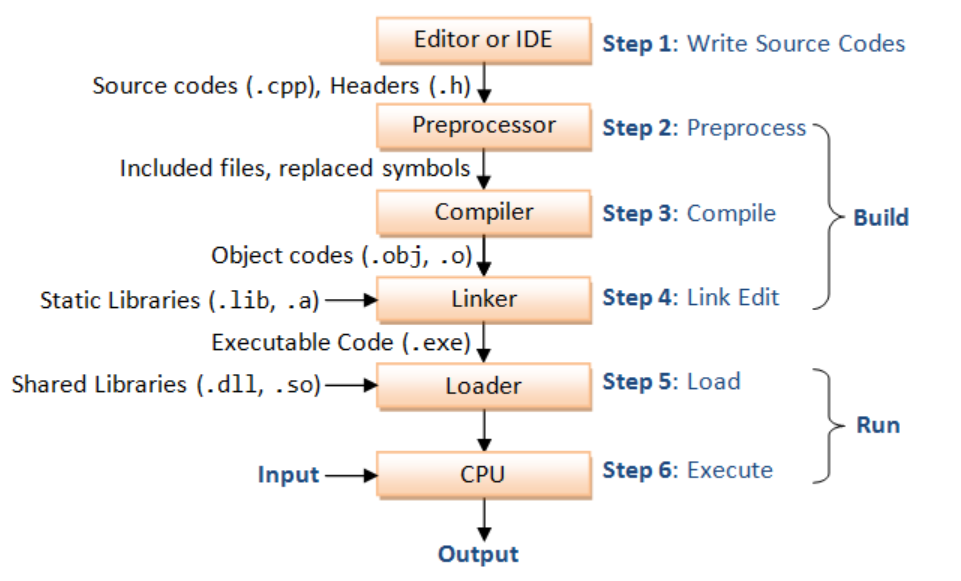
目标文件有三种形式:
.c 文件转化成 .i文件.gcc –E filename.cpp -o filename.i-E Preprocess only; do not compile, assemble or link.-C能保留头文件里的注释,如gcc -E -C circle.c -o circle.cgcc -save-temps -c -o main.o main.ccpp filename.cpp -o filename.i命令linemarkers类似# linenum filename flags的注释,这些注释是为了让编译器能够定位到源文件的行号,以便于编译器能够在编译错误时给出正确的行号。flags meaning除开注释被替换成空格,包括代码里的预处理命令:
#error "text" 的作用是在编译时生成一个错误消息,它会导致编译过程中断。 同理有#warning#define a b 对于这种伪指令,预编译所要做的是将程序中的所有a用b替换,但作为字符串常量的 a则不被替换。还有 #undef,则将取消对某个宏的定义,使以后该串的出现不再被替换。#ifdef SNIPER,#if defined SNIPER && SNIPER == 0,#ifndef,#else,#elif,#endif等。 这些伪指令的引入使得程序员可以通过定义不同的宏来决定编译程序对哪些代码进行处理。预编译程序将根据有关的文件,将那些不必要的代码过滤掉-DSNIPER=5#include "FileName"或者#include 等。
该指令将头文件中的定义统统都加入到它所产生的输出文件中,以供编译程序对之进行处理。LINE标识将被解释为当前行号(十进制数),FILE则被解释为当前被编译的C源程序的名称。
预编译程序对于在源程序中出现的这些串将用合适的值进行替换。#include "" vs #include <> 区别在于前者会在文件的当前目录寻找,但是后者只会在编译器编译的official路径寻找
通常的搜索顺序是:
#include 命令中以引号包括的文件名)。-iquote选项指定的目录,依照出现在命令行中的顺序进行搜索。只对 #include 命令中采用引号的头文件名进行搜索。-I开始, 依照出现在命令行中的顺序进行搜索。(可以使用-I/path/file只添加一个头文件,尤其是在编译的兼容性修改时)-isystem选项指定的目录,依照出现在命令行中的顺序进行搜索。C_INCLUDE_PATH,CPLUS_INCLUDE_PATH,OBJC_INCLUDE_PATH指定的路径再找系统默认目录(/usr/include、/usr/local/include、/usr/lib/gcc-lib/i386-linux/2.95.2/include......)
通过如下命令可以查看头文件搜索目录 gcc -xc -E -v - < /dev/null 或者 g++ -xc++ -E -v - < /dev/null*. 如果想改,需要重新编译gcc
g++ -H -v查看是不是项目下的同名头文件优先级高于sys-head-file.c/.h或者.i文件转换成.s文件,gcc –S filename.cpp -o filename.s,对应于-S Compile only; do not assemble or link.gcc –S filename.i -o filename.s 也是可行的。但是我遇到头文件冲突的问题error: declaration for parameter ‘__u_char’ but no such parametercc –S filename.cpp -o filename.s cc1命令-O3)如果想把 C 语言变量的名称作为汇编语言语句中的注释,可以加上 -fverbose-asm 选项:
请阅读 GNU assembly file一文
汇编器:将.s 文件转化成 .o文件,
gcc –c,-c Compile and assemble, but do not link.as;目标文件由段组成。通常一个目标文件中至少有两个段:
代码段:该段中所包含的主要是程序的指令。该段一般是可读和可执行的,但一般却不可写。
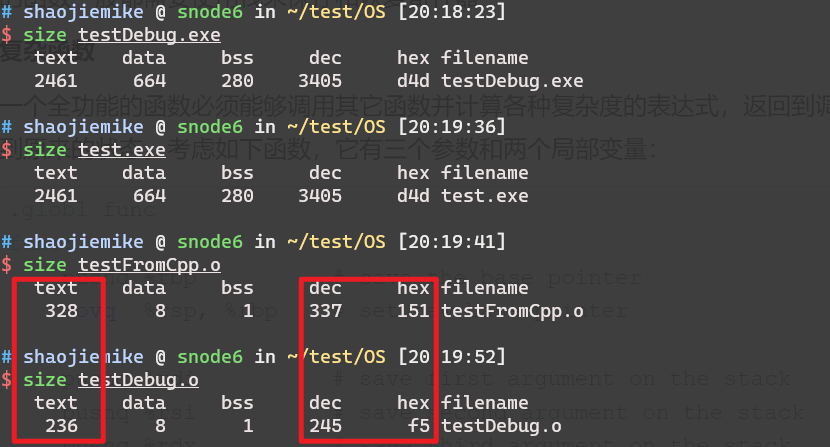
objdump -Sd ../build/bin/pivot > pivot1.s-S 以汇编代码的形式显示C++原程序代码,如果有debug信息,会显示源代码。nm file.o 查看目标文件中的符号表注意,这时候的目标文件里的使用的函数可能没定义,需要链接其他目标文件.a .so .o .dll(Dynamic Link Library的缩写,Windows动态链接库)
List symbol names in object files.
no symbols
常用选项 -CD
-C 选项告诉 nm 将 C++ 符号的 mangled 名称转换为原始的、易于理解的名称。常用于.a的静态库。-D / --dynamic:显示动态符号,这在查看共享库(如 .so 文件)时非常有用。输出
| 符号类型 | 描述 |
|---|---|
| A | 符号值是绝对的。在进一步的连接中,不会被改变。 |
| B | 符号位于未初始化数据段(known as BSS). |
| C | 共用(common)符号. 共用符号是未初始化的数据。在连接时,多个共用符号可能采用一个同样的名字,如果这个符号在某个地方被定义,共用符号被认为是未定义的引用. |
| D | 已初始化数据段的符号 |
| G | 已初始化数据段中的小目标(small objective)符号. 一些目标文件格式允许更有效的访问小目标数据,比如一个全局的int变量相对于一个大的全局数组。 |
| I | 其他符号的直接应用,这是GNU扩展的,很少用了. N 调试符号. |
| R | 只读数据段符号. S 未初始化数据段中的小目标(small object)符号. |
| T | 代码段的符号. |
| U | 未定义符号. |
| V | 弱对象(weak object)符号. 当一个已定义的弱符号被连接到一个普通定义符号,普通定义符号可以正常使用,当一个未定义的弱对象被连接到一个未定义的符号,弱符号的值为0. |
| W | 一个没有被指定一个弱对象符号的弱符号(weak symbol)。 - a.out目标文件中的刺符号(stabs symbol). 这种情况下,打印的下一个值是其他字段,描述字段,和类型。刺符号用于保留调试信息. |
| ? | 未知符号类型,或者目标文件特有的符号类型. |
这个顺序是针对G++编译的,但是对于python查找库,有所不同,会从ldconfig设置开始
/lib,/usr/lib,/lib64(在64位系统上),/usr/lib64(在64位系统上)遍历 LD_LIBRARY_PATH 中的每个目录,并查找包括软链接在内的所有 .so 文件。
IFS=':' dirs="$LD_LIBRARY_PATH"
for dir in $dirs; do
find -L "$dir" -name "*.so" 2>/dev/null
done
ldconfig 命令用于配置动态链接器的运行时绑定。你可以使用它来查询系统上已知的库文件的位置()。
ldconfig 会扫描
/lib 和 /usr/lib,以及 /etc/ld.so.conf 中列出的目录),查找共享库文件(.so 文件),/etc/ld.so.cache。这个缓存文件会被动态链接器(ld.so 或 ld-linux.so)使用,以加快共享库的查找速度。# 查看所有是path 的库
ldconfig -v
# 永久添加一个新的库路
echo "/path/to/your/library" | sudo tee /etc/ld.so.conf.d/your-library.conf
sudo ldconfig
# 查询 libdw.so 的位置:
ldconfig -p | grep libdw
ldd会显示动态库的链接关系,中间的nm为U没关系,只需要最终.so对应符号是T即可。ldd 时避免对不可信的可执行文件运行,因为它可能会执行恶意代码。readelf -d 或 objdump -p 来查看库依赖。解析 ELF 文件
ldd 会首先读取输入的可执行文件或共享库(通常是 ELF 格式的文件)。
ELF(Executable and Linkable Format)是一种文件格式,用于存储可执行文件、目标代码、共享库等。
查找依赖项
ELF 文件包含一个段(section),其中列出了所需的共享库的名称和路径。这些信息存储在 ELF 的动态段(.dynamic)中。
ldd 通过解析这些信息,识别出需要加载的共享库。
使用动态链接器
ldd 通过调用动态链接器(如 ld-linux.so)来解析和加载这些共享库。
动态链接器负责在运行时加载库并解决符号(symbol),即将函数或变量名称映射到实际内存地址。
输出结果
ldd 列出每个依赖库的名称、路径以及它们在内存中的地址。
ldd 会显示“not found”的提示。ldd 显示not found的库,不一定程序在执行就找不到
比如conda的库,ldd就无法解析。猜测和python的运行逻辑有关,比如import的使用,自动搜索相关的lib目录。
通过使用ld命令,将编译好的目标文件连接成一个可执行文件或动态库。
Foo::bar(int,long)会变成bar__3Fooil。其中3是名字字符数见 Linux Executable file: Structure & Running
undefined reference to一旦链接器完成了符号解析这一步,就把代码中的每个符号引用和正好一个符号定义(即它的一个输入目标模块中的一个符号表条目)关联起来。此时,链接器就知道它的输入目标模块中的代码节和数据节的确切大小。现在就可以开始重定位步骤了,在这个步骤中,将合并输入模块,并为每个符号分配运行时地址。重定位由两步组成:
.data 节被全部合并成一个节,这个节成为输出的可执行目标文件的.data 节。当汇编器生成一个目标模块时,它并不知道数据和代码最终将放在内存中的什么位置。它也不知道这个模块引用的任何外部定义的函数或者全局变量的位置。所以,无论何时汇编器遇到对最终位置未知的目标引用,它就会生成一个重定位条目,告诉链接器在将目标文件合并成可执行文件时如何修改这个引用。
代码的重定位条目放在 .rel.text 中。已初始化数据的重定位条目放在 .rel.data 中。
下面 展示了 ELF 重定位条目的格式。
R_X86_64_PC32。重定位一个使用 32 位 PC 相对地址的引用。回想一下 3.6.3 节,一个 PC 相对地址就是距程序计数器(PC)的当前运行时值的偏移量。当 CPU 执行一条使用 PC 相对寻址的指令时,它就将在指令中编码的 32 位值加上 PC 的当前运行时值,得到有效地址(如 call 指令的目标),PC 值通常是下一条指令在内存中的地址。(将 PC 压入栈中来使用)R_X86_64_32。重定位一个使用 32 位绝对地址的引用。通过绝对寻址,CPU 直接使用在指令中编码的 32 位值作为有效地址,不需要进一步修改。typedef struct {
long offset; /* Offset of the reference to relocate */
long type:32, /* Relocation type */
symbol:32; /* Symbol table index */
long addend; /* Constant part of relocation expression */
} Elf64_Rela;
链接器通常从左到右解析依赖项,这意味着如果库 A 依赖于库 B,那么库 B 应该在库 A 之前被链接。
库顺序
假设有三个库 libA, libB, 和 libC,其中 libA 依赖 libB,而 libB 又依赖 libC。在 CMake 中,你应该这样链接它们:
这样的顺序确保了当链接器处理 libA 时,libB 和 libC 中的符号已经可用。



静态库static library就是将相关的目标模块打包形成的单独的文件。使用ar命令。
静态库的优点在于:
问题:
深入理解计算机系统P477,静态库例子
图 7-8 概括了链接器的行为。-static 参数告诉编译器驱动程序,链接器应该构建一个完全链接的可执行目标文件,它可以加载到内存并运行,在加载时无须更进一步的链接。-lvector 参数是 libvector.a 的缩写,-L. 参数告诉链接器在当前目录下查找 libvector.a。

共享库是以两种不同的方式来“共享”的:

如上创建了一个可执行目标文件 prog2l,而此文件的形式使得它在运行时可以和 libvector.so 链接。基本的思路是:
dlopen() interface.情况:在应用程序被加载后执行前时,动态链接器加载和链接共享库的情景。
核心思想:由动态链接器接管,加载管理和关闭共享库(比如,如果没有其他共享库还在使用这个共享库,dlclose函数就卸载该共享库。)。
.interp 节,这一节包含动态链接器的路径名,动态链接器本身就是一个共享目标(如在 Linux 系统上的 ld-linux.so). 加载器不会像它通常所做地那样将控制传递给应用,而是加载和运行这个动态链接器。然后,动态链接器通过执行下面的重定位完成链接任务:最后,动态链接器将控制传递给应用程序。从这个时刻开始,共享库的位置就固定了,并且在程序执行的过程中都不会改变。
情况:应用程序在运行时要求动态链接器加载和链接某个共享库,而无需在编译时将那些库链接到应用。
实际应用情况:
思路是将每个生成动态内容的函数打包在共享库中。
编译器yasm的参数-DPIE
如果同一份代码可能被加载到进程空间的任意虚拟地址上执行(如共享库和动态加载代码),那么就需要使用-fPIC生成位置无关代码。
可以加载而无需重定位的代码称为位置无关代码(Position-Independent Code,PIC)
在一个 x86-64 系统中,对同一个目标模块中符号的引用是不需要特殊处理使之成为 PIC。可以用 PC 相对寻址来编译这些引用,构造目标文件时由静态链接器重定位。
解决方法:延迟绑定(lazy binding),将过程地址的绑定推迟到第一次调用该过程时。
动机:使用延迟绑定的动机是对于一个像 libc.so 这样的共享库输出的成百上千个函数中,一个典型的应用程序只会使用其中很少的一部分。把函数地址的解析推迟到它实际被调用的地方,能避免动态链接器在加载时进行成百上千个其实并不需要的重定位。
结果:第一次调用过程的运行时开销很大,但是其后的每次调用都只会花费一条指令和一个间接的内存引用。
实现:延迟绑定是通过两个数据结构之间简洁但又有些复杂的交互来实现的,这两个数据结构是:GOT 和过程链接表(Procedure Linkage Table,PLT)。如果一个目标模块调用定义在共享库中的任何函数,那么它就有自己的 GOT 和 PLT。GOT 是数据段的一部分,而 PLT 是代码段的一部分。
首先,让我们介绍这两个表的内容。
PLT[0] 是一个特殊条目,它跳转到动态链接器中。PLT[1](图中未显示)调用系统启动函数(__libc_start_main),它初始化执行环境,调用 main 函数并处理其返回值从 PLT[2] 开始的条目调用用户代码调用的函数。在我们的例子中,PLT[2] 调用 addvec,PLT[3](图中未显示)调用 printf。
上图a 展示了 GOT 和 PLT 如何协同工作,在 addvec 被第一次调用时,延迟解析它的运行时地址:
上图b 给出的是后续再调用 addvec 时的控制流:
静态库
动态库
shaojiemike@snode6 /lib/modules/5.4.0-107-generic/build [06:32:26]
> gcc -print-search-dirs
install: /usr/lib/gcc/x86_64-linux-gnu/9/
programs: =/usr/lib/gcc/x86_64-linux-gnu/9/:/usr/lib/gcc/x86_64-linux-gnu/9/:/usr/lib/gcc/x86_64-linux-gnu/:/usr/lib/gcc/x86_64-linux-gnu/9/:/usr/lib/gcc/x86_64-linux-gnu/:/usr/lib/gcc/x86_64-linux-gnu/9/../../../../x86_64-linux-gnu/bin/x86_64-linux-gnu/9/:/usr/lib/gcc/x86_64-linux-gnu/9/../../../../x86_64-linux-gnu/bin/x86_64-linux-gnu/:/usr/lib/gcc/x86_64-linux-gnu/9/../../../../x86_64-linux-gnu/bin/
libraries: =/usr/lib/gcc/x86_64-linux-gnu/9/:/usr/lib/gcc/x86_64-linux-gnu/9/../../../../x86_64-linux-gnu/lib/x86_64-linux-gnu/9/:/usr/lib/gcc/x86_64-linux-gnu/9/../../../../x86_64-linux-gnu/lib/x86_64-linux-gnu/:/usr/lib/gcc/x86_64-linux-gnu/9/../../../../x86_64-linux-gnu/lib/../lib/:/usr/lib/gcc/x86_64-linux-gnu/9/../../../x86_64-linux-gnu/9/:/usr/lib/gcc/x86_64-linux-gnu/9/../../../x86_64-linux-gnu/:/usr/lib/gcc/x86_64-linux-gnu/9/../../../../lib/:/lib/x86_64-linux-gnu/9/:/lib/x86_64-linux-gnu/:/lib/../lib/:/usr/lib/x86_64-linux-gnu/9/:/usr/lib/x86_64-linux-gnu/:/usr/lib/../lib/:/usr/lib/gcc/x86_64-linux-gnu/9/../../../../x86_64-linux-gnu/lib/:/usr/lib/gcc/x86_64-linux-gnu/9/../../../:/lib/:/usr/lib/
加载器:将可执行程序加载到内存并进行执行,loader和ld-linux.so。
将可执行文件加载运行
| 命令 | 描述 |
|---|---|
| ar | 创建静态库,插入、删除、列出和提取成员; |
| stringd | 列出目标文件中所有可以打印的字符串; |
| strip | 从目标文件中删除符号表信息; |
| nm | 列出目标文件符号表中定义的符号; |
| size | 列出目标文件中节的名字和大小; |
| readelf | 显示一个目标文件的完整结构,包括ELF 头中编码的所有信息。 |
| objdump | 显示目标文件的所有信息,最有用的功能是反汇编.text节中的二进制指令。 |
| ldd | 列出可执行文件在运行时需要的共享库。 |
ltrace 跟踪进程调用库函数过程 strace 系统调用的追踪或信号产生的情况 Relyze 图形化收费试用
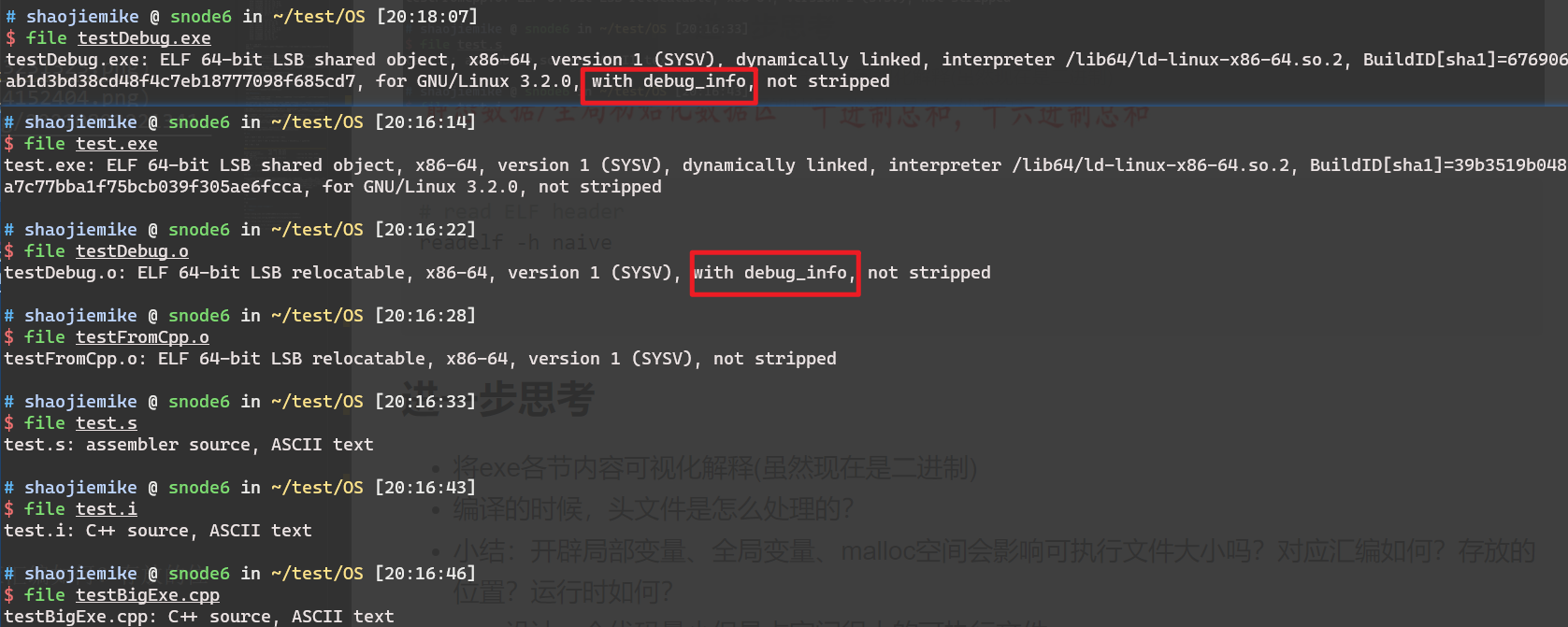
-g选项,可以生成调试信息,这样在gdb中可以查看源代码。objdump -g <archive_file>.a
# 如果.o文件有debugging symbols,会输出各section详细信息
Contents of the .debug_aranges section (loaded from predict-c.o):
# 没有则如下
cabac-a.o: file format elf64-x86-64
dct-a.o: file format elf64-x86-64
deblock-a.o: file format elf64-x86-64
gcc -E -g testBigExe.cpp -o testDebug.i相对于无-g的命令,只会多一行信息# 1 "/staff/shaojiemike/test/OS//"gcc -S -g testBigExe.cpp -o testDebug.s,对比之前的汇编文件,由72行变成9760行。具体解析参考 GNU assembly file一文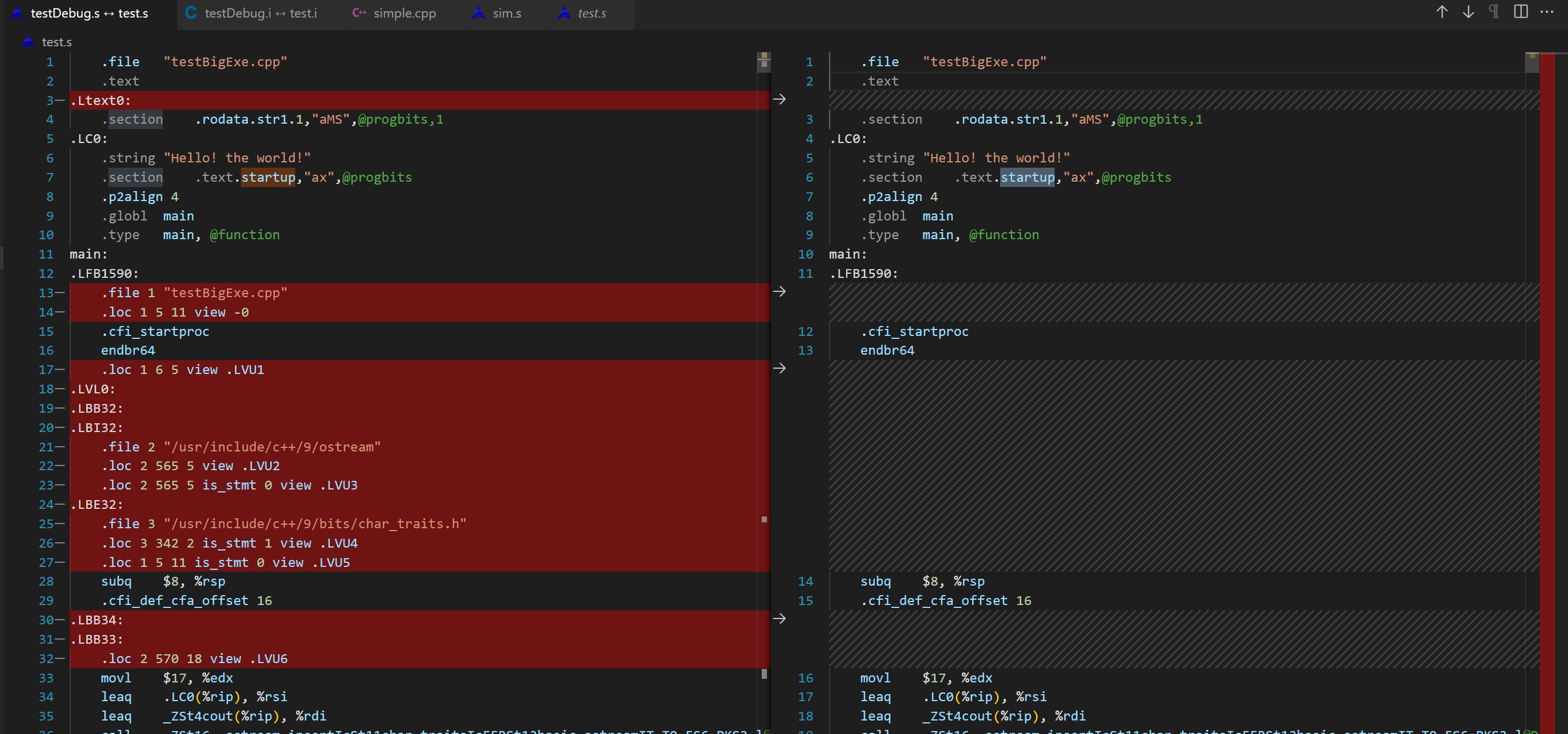
简单的#pragma omp for,编译后多出汇编代码如下。当前可以创建多少个线程默认汇编并没有显示的汇编指令。
call omp_get_num_threads@PLT
movl %eax, %ebx
call omp_get_thread_num@PLT
movl %eax, %ecx
call GOMP_barrier@PLT
某些atomic的导语会变成对应汇编
暂无
基础不牢,地动山摇。ya 了。
https://www.cnblogs.com/LiuYanYGZ/p/5574601.html
https://hansimov.gitbook.io/csapp/part2/ch07-linking/7.5-symbols-and-symbol-tables
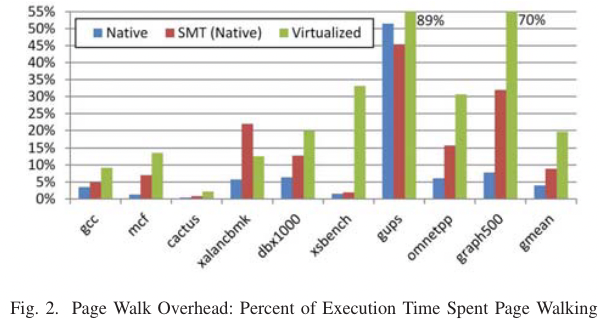
TLB的介绍,请看
大体上是应用访问越随机, 数据量越大,pgw开销越大。
ISCA 2013 shows the pgw overhead in big memory servers.
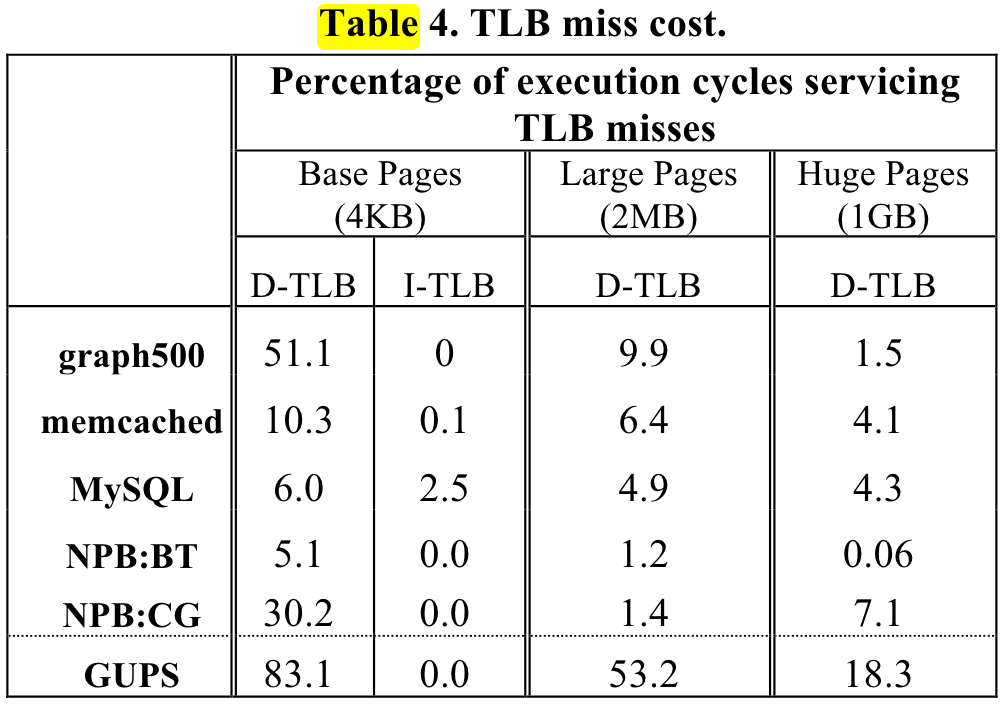
or ISCA 2020 Guvenilir 和 Patt - 2020 - Tailored Page Sizes.pdf
# shaojiemike @ snode6 in ~/github/hugoMinos on git:main x [11:17:05]
$ cpuid -1 -l 2
CPU:
0x63: data TLB: 2M/4M pages, 4-way, 32 entries
data TLB: 1G pages, 4-way, 4 entries
0x03: data TLB: 4K pages, 4-way, 64 entries
0x76: instruction TLB: 2M/4M pages, fully, 8 entries
0xff: cache data is in CPUID leaf 4
0xb5: instruction TLB: 4K, 8-way, 64 entries
0xf0: 64 byte prefetching
0xc3: L2 TLB: 4K/2M pages, 6-way, 1536 entries
# if above command turns out empty
cpuid -1 |grep TLB -A 10 -B 5
# will show sth like
L1 TLB/cache information: 2M/4M pages & L1 TLB (0x80000005/eax):
instruction # entries = 0x40 (64)
instruction associativity = 0xff (255)
data # entries = 0x40 (64)
data associativity = 0xff (255)
L1 TLB/cache information: 4K pages & L1 TLB (0x80000005/ebx):
instruction # entries = 0x40 (64)
instruction associativity = 0xff (255)
data # entries = 0x40 (64)
data associativity = 0xff (255)
L2 TLB/cache information: 2M/4M pages & L2 TLB (0x80000006/eax):
instruction # entries = 0x200 (512)
instruction associativity = 2-way (2)
data # entries = 0x800 (2048)
data associativity = 4-way (4)
L2 TLB/cache information: 4K pages & L2 TLB (0x80000006/ebx):
instruction # entries = 0x200 (512)
instruction associativity = 4-way (4)
data # entries = 0x800 (2048)
data associativity = 8-way (6)
default there is no hugopage(usually 4MB) to use.
$ cat /proc/meminfo | grep huge -i
AnonHugePages: 8192 kB
ShmemHugePages: 0 kB
FileHugePages: 0 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
Hugetlb: 0 kB
explained is here.
cat /sys/kernel/mm/transparent_hugepage/enabled but achieve this needs some details.echo 20 > /proc/sys/vm/nr_hugepages. And you need to write speacial C++ code to use the hugo page# using mmap system call to request huge page
mount -t hugetlbfs \
-o uid=<value>,gid=<value>,mode=<value>,pagesize=<value>,size=<value>,\
min_size=<value>,nr_inodes=<value> none /mnt/huge
But there is a blog using unmaintained tool hugeadm and iodlr library to do this.
sudo apt install libhugetlbfs-bin
sudo hugeadm --create-global-mounts
sudo hugeadm --pool-pages-min 2M:64
So meminfo is changed
$ cat /proc/meminfo | grep huge -i
AnonHugePages: 8192 kB
ShmemHugePages: 0 kB
FileHugePages: 0 kB
HugePages_Total: 64
HugePages_Free: 64
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
Hugetlb: 131072 kB
using iodlr library
Measurement tools from code
# shaojiemike @ snode6 in ~/github/PIA_huawei on git:main x [17:40:50]
$ ./investigation/pagewalk/tlbstat -c '/staff/shaojiemike/github/sniper_PIMProf/PIMProf/gapbs/sssp.inj -f /staff/shaojiemike/github/sniper_PIMProf/PIMProf/gapbs/benchmark/kron-20.wsg -n1'
command is /staff/shaojiemike/github/sniper_PIMProf/PIMProf/gapbs/sssp.inj -f /staff/shaojiemike/github/sniper_PIMProf/PIMProf/gapbs/benchmark/kron-20.wsg -n1
K_CYCLES K_INSTR IPC DTLB_WALKS ITLB_WALKS K_DTLBCYC K_ITLBCYC DTLB% ITLB%
324088 207256 0.64 733758 3276 18284 130 5.64 0.04
21169730 11658340 0.55 11802978 757866 316625 24243 1.50 0.11
平均单次开销(开始到稳定): dtlb miss read need 24~50 cycle ,itlb miss read need 40~27 cycle
案例的时间分布:
65000 100000超内存前,即使是全部在计算,都是0.24% 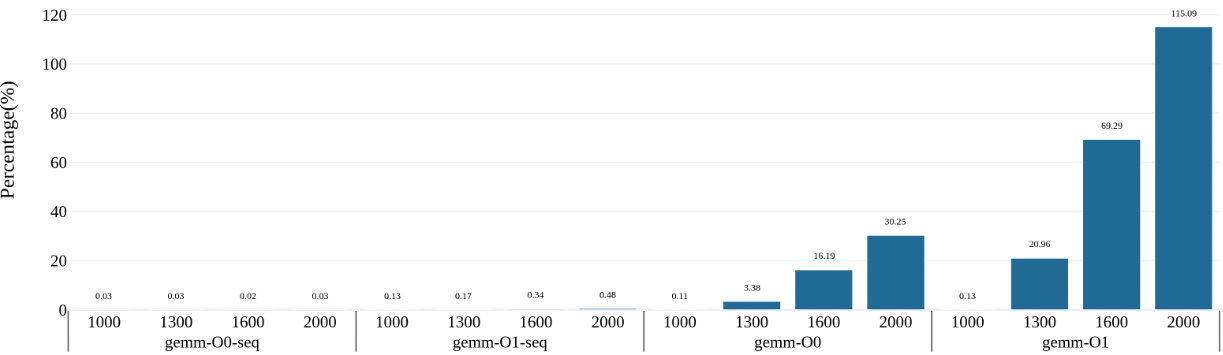
the gemm's core line is
for(int i=0; i<N; i++){
// ignore the overflow, do not influence the running time.
for(int j=0; j<N; j++){
for(int l=0; l<N; l++){
// gemm
// ans[i * N + j] += matrix1[i * N + l] * matrix2[l * N + j];
// for gemm sequantial
ans[i * N + j] += matrix1[i * N + l] * matrix2[j * N + l];
}
}
}
and real time breakdown is as followed. to do
manual code to test if tlb entries is run out
$ ./tlbstat -c '../../test/manual/bigJump.exe 1 10 100'
command is ../../test/manual/bigJump.exe 1 10 100
K_CYCLES K_INSTR IPC DTLB_WALKS ITLB_WALKS K_DTLBCYC K_ITLBCYC DTLB% ITLB%
2002404 773981 0.39 104304528 29137 2608079 684 130.25 0.03
$ perf stat -e mem_uops_retired.all_loads -e mem_uops_retired.all_stores -e mem_uops_retired.stlb_miss_loads -e mem_uops_retired.stlb_miss_stores ./bigJump.exe 1 10 500
Number read from command line: 1 10 (N,J should not big, [0,5] is best.)
result 0
Performance counter stats for './bigJump.exe 1 10 500':
10736645 mem_uops_retired.all_loads
532100339 mem_uops_retired.all_stores
57715 mem_uops_retired.stlb_miss_loads
471629056 mem_uops_retired.stlb_miss_stores
In this case, tlb miss rate up to 47/53 = 88.6%
using big hash table
Any algorithm that does random accesses into a large memory region will likely suffer from TLB misses. Examples are plenty: binary search in a big array, large hash tables, histogram-like algorithms, etc.
暂无
暂无
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
无
This set consists of
| volume | Descriptions | pages(size) |
|---|---|---|
| volume 1 | Basic Architecture | 500 pages(3MB) |
| volume 2 (combined 2A, 2B, 2C, and 2D) | full instruction set reference | 2522 pages(10.8MB) |
| volume 3 (combined 3A, 3B, 3C, and 3D) | system programming guide | 1534 pages(8.5MB) |
| volume 4 | MODEL-SPECIFIC REGISTERS (MSRS) | 520 pages |
volume3: Memory management(paging), protection, task management, interrupt and exception handling, multi-processor support, thermal and power management features, debugging, performance monitoring, system management mode, virtual machine extensions (VMX) instructions, Intel® Virtualization Technology (Intel® VT), and Intel® Software Guard Extensions (Intel® SGX).
more graph and easier to read.
暂无
暂无
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
https://www.intel.com/content/www/us/en/developer/articles/technical/intel-sdm.html
要运行可执行目标文件 prog,我们可以在 Linux shell 的命令行中输入它的名字:
linux> ./prog
因为 prog 不是一个内置的 shell 命令,所以 shell 会认为 prog 是一个可执行目标文件。
执行完上述操作后,其实可执行文件的真正指令和数据都没有别装入内存中。操作系统只是通过可执行文件头部的信息建立起可执行文件和进程虚拟内存之间的映射关系而已。

除了一些头部信息,在加载过程中没有任何从磁盘到内存的数据复制。直到 CPU 引用一个被映射的虚拟页时才会进行复制,此时,操作系统利用它的页面调度机制自动将页面从磁盘传送到内存。
比如,现在程序的入口地址为 0x08048000 ,刚好是代码段的起始地址。当CPU打算执行这个地址的指令时,发现页面 0x8048000 ~ 0x08049000 (一个页面一般是4K)是个空页面,于是它就认为是个页错误。此时操作系统根据虚拟地址空间与可执行文件间的映射关系找到页面在可执行文件中的偏移,然后在物理内存中分配一个物理页面,并在虚拟地址页面与物理页面间建立映射,最后把EXE文件中页面拷贝到内存的物理页面,进程重新开始执行。该过程如下图所示:
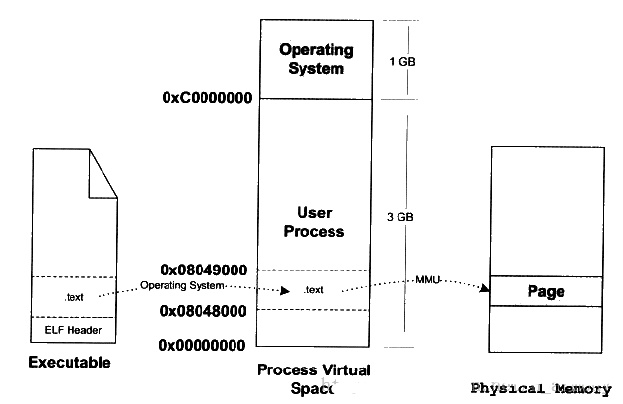
接下来,加载器跳转到程序的入口点,也就是 _start函数的地址。这个函数是在系统目标文件 ctrl.o 中定义的,对所有的 C 程序都是一样的。_start 函数调用系统启动函数 __libc_start_main,该函数定义在 libc.so 中。它初始化执行环境,调用用户层的 main 函数,处理 main 函数的返回值,并且在需要的时候把控制返回给内核。
# shaojiemike @ snode6 in ~/github/sniper_PIMProf/PIMProf/gapbs on git:dev o [15:15:29]
$ size /usr/lib/llvm-10/bin/llvm-mca
text data bss dec hex filename
144530 6056 8089 158675 26bd3 /usr/lib/llvm-10/bin/llvm-mca
# shaojiemike @ snode6 in ~/github/sniper_PIMProf/PIMProf/gapbs on git:dev o [15:18:14]
$ l /usr/lib/llvm-10/bin/llvm-mca
-rwxr-xr-x 1 root root 153K Apr 20 2020 /usr/lib/llvm-10/bin/llvm-mca
是一种用于管理计算机内存的算法,旨在有效地分配和释放内存块,以防止碎片化并提高内存的使用效率。这种算法通常用于操作系统中,以管理系统内核和进程的内存分配。
Buddy 内存分配算法的基本思想是将物理内存划分为大小相等的块,每个块大小都是 2 的幂次方。每个块可以分配给一个正在运行的进程或内核。当内存被分配出去后,它可以被分割成更小的块,或者合并成更大的块,以适应不同大小的内存需求。
算法的名称 "Buddy" 来自于分配的块之间的关系,其中一个块被称为 "buddy",它是另一个块的大小相等的邻居。这种关系使得在释放内存时,可以尝试将相邻的空闲块合并成更大的块,从而减少内存碎片。
Buddy 内存分配算法的工作流程大致如下:
初始时,整个可用内存被视为一个大块,大小是 2 的幂次方。
当一个进程请求内存分配时,算法会搜索可用的块,找到大小合适的块来满足请求。如果找到的块比所需的稍大,它可以被分割成两个相等大小的 "buddy" 块,其中一个分配给请求的进程。
当一个进程释放内存时,该块会与其 "buddy" 块合并,形成一个更大的块。然后,这个更大的块可以与其它相邻的块继续合并,直到达到较大的块。
Buddy 内存分配算法在一些操作系统中用于管理内核和进程的物理内存,尤其在嵌入式系统和实时操作系统中,以提高内存使用效率和避免碎片化问题。
是一个用于教育目的的微内核操作系统
我们可window写程序占满16G内存
但是linux,用了3GB就会seg fault
猜想是不是有单进程内存限制 https://www.imooc.com/wenda/detail/570992
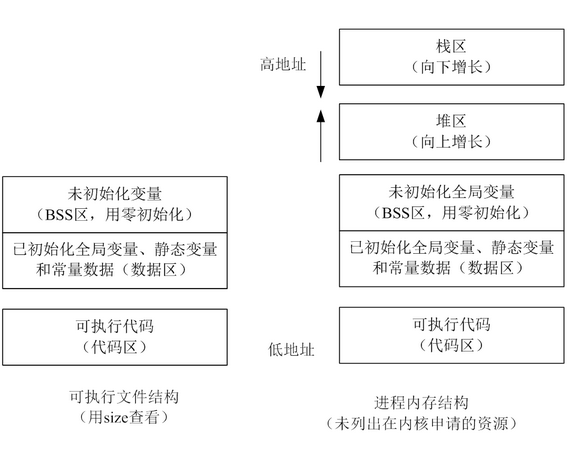
而且malloc alloc的空间在堆区,我们可以明显的发现这个空间是被栈区包住的,有限的。windows是如何解决这个问题的呢? 1. 首先这个包住是虚拟地址,通过页表映射到的物理地址是分开的 2. 根据第一点,可以实现高地址动态向上移动
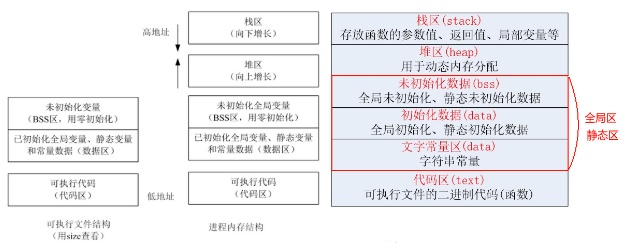
动态数据区一般就是“堆栈”。“栈 (stack)”和“堆(heap)”是两种不同的动态数据区,栈是一种线性结构,堆是一种链式结构。进程的每个线程都有私有的“栈”,所以每个线程虽然 代码一样,但本地变量的数据都是互不干扰。一个堆栈可以通过“基地址”和“栈顶”地址来描述。全局变量和静态变量分配在静态数据区,本地变量分配在动态数 据区,即堆栈中。程序通过堆栈的基地址和偏移量来访问本地变量。
当进程初始化时,系统会自动为进程创建一个默认堆,这个堆默认所占内存的大小为1M。堆对象由系统进行管理,它在内存中以链式结构存在。
/etc/security/limits.conf
# shaojiemike @ node5 in ~ [6:35:51]
$ ulimit -a
-t: cpu time (seconds) unlimited
-f: file size (blocks) unlimited
-d: data seg size (kbytes) unlimited
-s: stack size (kbytes) 8192
-c: core file size (blocks) 0
-m: resident set size (kbytes) unlimited
-u: processes 513967
-n: file descriptors 1024
-l: locked-in-memory size (kbytes) 65536
-v: address space (kbytes) unlimited
-x: file locks unlimited
-i: pending signals 513967
-q: bytes in POSIX msg queues 819200
-e: max nice 0
-r: max rt priority 0
-N 15: unlimited
ulimit -HSn 4096 # H指定了硬性大小,S指定了软性大小,n表示设定单个进程最大的打开文件句柄数量。硬限制是实际的限制,而软限制,是warnning限制,只会做出warning
lsof
文件句柄数
这些限制一般不会限制内存。
调用malloc(size_t size)函数分配内存成功,总会分配size字节VM(再次强调不是RAM),并返回一个指向刚才所分配内存区域的开端地址。分配的内存会为进程一直保留着,直到你显示地调用free()释放它(当然,整个进程结束,静态和动态分配的内存都会被系统回收)。
GNU libc库提供了二个内存分配函数,分别是malloc()和calloc()。glibc函数malloc()总是通过brk()或mmap()系统调用来满足内存分配需求。函数malloc(),根据不同大小内存要求来选择brk(),还是mmap(),阈值 MMAP_THRESHOLD=128Kbytes是临界值。小块内存(<=128kbytes),会调用brk(),它将数据段的最高地址往更高处推(堆从底部向上增长)。大块内存,则使用mmap()进行匿名映射(设置标志MAP_ANONYMOUS)来分配内存,与堆无关,在堆之外。
malloc不是直接分配内存的,是第一次访问的时候才分配的?
https://www.zhihu.com/question/20836462
暂无
暂无
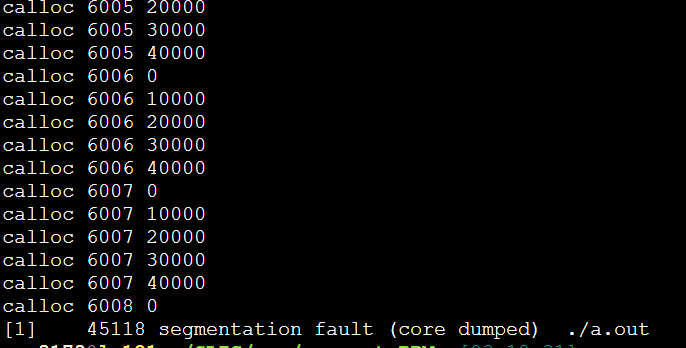 每次都是6008这里,40000*6008*3/1024/1024=687MB
每次都是6008这里,40000*6008*3/1024/1024=687MB
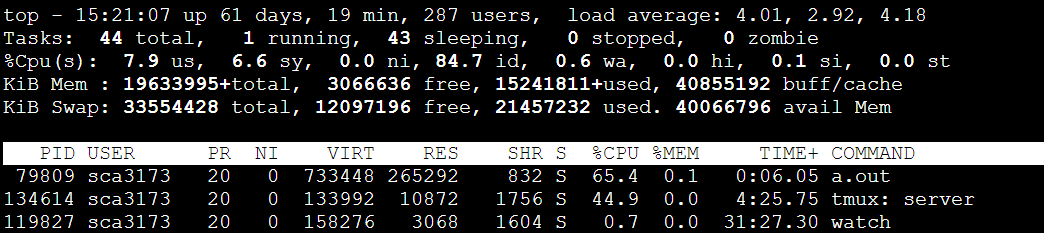 733448/1024=716MB
733448/1024=716MB
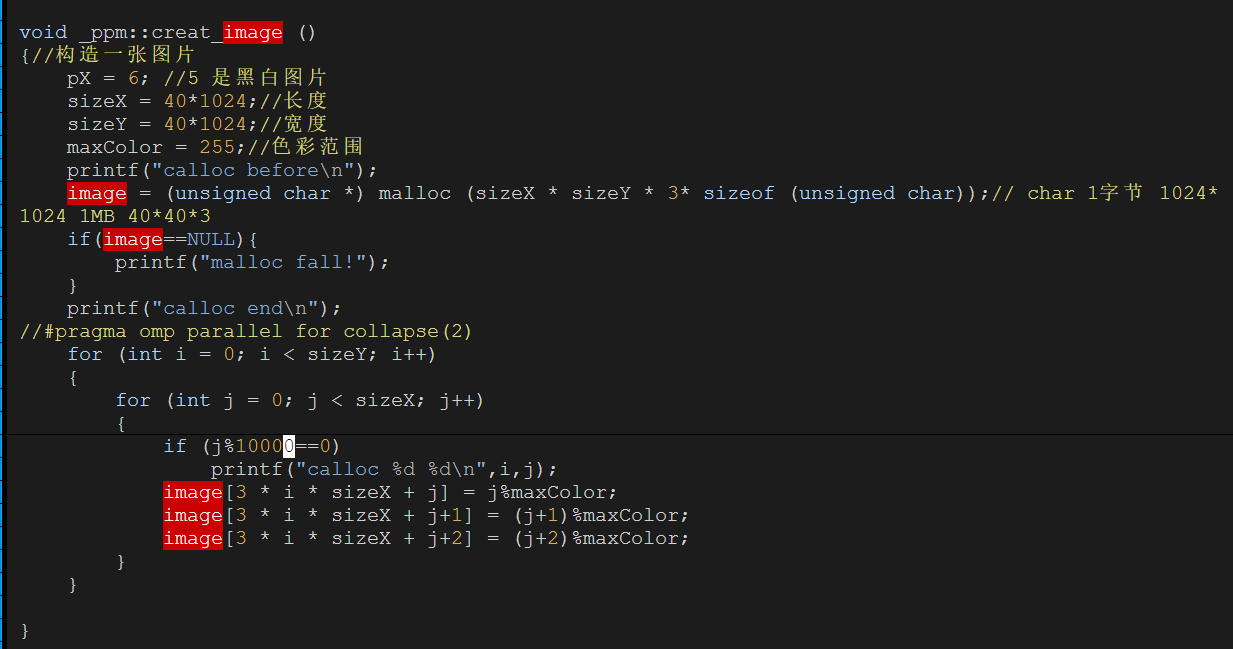
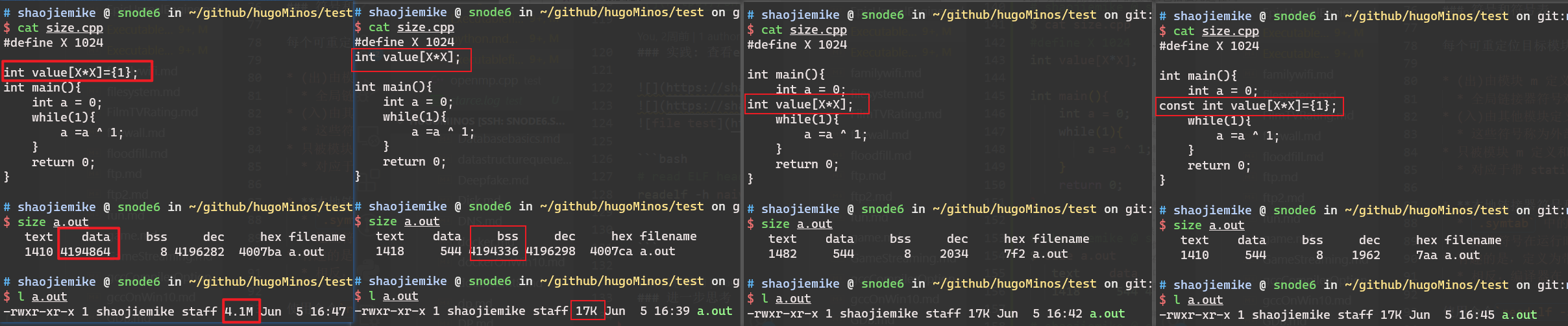
 问了大师兄,问题竟然是malloc的传入参数错误的类型是int,导致存不下3*40*1024*40*1024。应该用size_t类型。(size_t是跨平台的非负整数安全类型)
问了大师兄,问题竟然是malloc的传入参数错误的类型是int,导致存不下3*40*1024*40*1024。应该用size_t类型。(size_t是跨平台的非负整数安全类型)
https://blog.csdn.net/shenzi/article/details/3972437?utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.base&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-1.base

可执行目标文件的格式类似于可重定位目标文件的格式。
.text、.rodata 和 .data 节与可重定位目标文件中的节是相似的,除了这些节已经被重定位到它们最终的运行时内存地址以外。.init 节定义了一个小函数,叫做 _init,程序的初始化代码会调用它。.rel 节。7.4 可重定位目标文件一节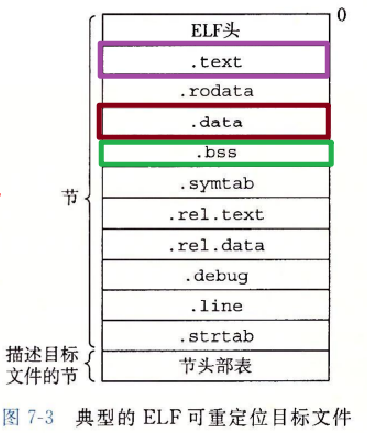
夹在 ELF 头和节头部表之间的都是节。一个典型的 ELF 可重定位目标文件包含下面几个节:
.data 节中,也不岀现在 .bss 节中。.bss 来表示未初始化的数据是很普遍的。它起始于 IBM 704 汇编语言(大约在 1957 年)中“块存储开始(Block Storage Start)”指令的首字母缩写,并沿用至今。.data 和 .bss 节的简单方法是把 “bss” 看成是“更好地节省空间(Better Save Space)” 的缩写。.symtab 中都有一张符号表(除非程序员特意用 STRIP 命令去掉它)。.symtab 符号表不包含局部变量的条目。-g 选项调用编译器驱动程序时,才会得到这张表。.text 节中机器指令之间的映射。-g 选项调用编译器驱动程序时,才会得到这张表。.symtab 和 .debug 节中的符号表,以及节头部中的节名字。字符串表就是以 null 结尾的字符串的序列。每个可重定位目标模块 m 都有一个符号表.symtab,它包含 m 定义和引用的符号的信息。在链接器的上下文中,有三种不同的符号:
对应于带 static 属性的 C 函数和全局变量。这些符号在模块 m 中任何位置都可见,但是不能被其他模块引用。
本地链接器符号和本地程序变量的不同是很重要的。
.symtab 中的符号表不包含对应于本地非静态程序变量的任何符号。static 属性的本地过程变量是不在栈中管理的。使用命令readelf -s simple.o 可以读取符号表的内容。
示例程序的可重定位目标文件 main.o 的符号表中的最后三个条目。

外部符号 sum 的引用。
type 通常要么是数据,要么是函数。

编译的时候,头文件是怎么处理的?
data 与 bbs在存储时怎么区分全局与静态变量
.rel.text .rel.data的实例分析线程和进程都可以用多核,但是线程共享进程内存(比如,openmp)
超线程注意也是为了提高核心的利用率,当有些轻量级的任务时(读写任务)核心占用很少,可以利用超线程把一个物理核心当作多个逻辑核心,一般是两个,来使用更多线程。AMD曾经尝试过4个。

正在运行的程序,叫进程。每个进程都有完全属于自己的,独立的,不被干扰的内存空间。此空间,被分成几个段(Segment),分别是Text, Data, BSS, Heap, Stack。
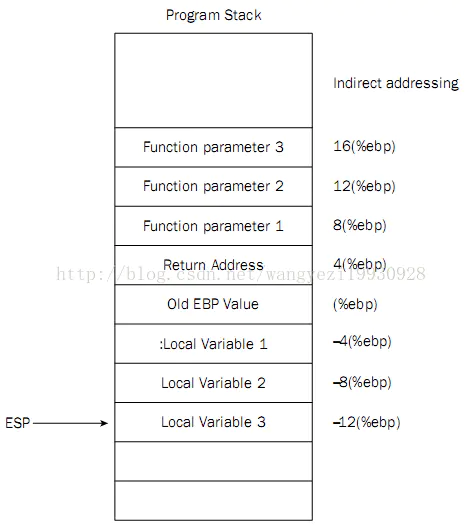
push pop %ebp 涉及到编译器调用函数的处理方式 application binary interface (ABI).EAX 寄存器中返回,浮点值在 ST0 x87 寄存器中返回。寄存器 EAX、ECX 和 EDX 由调用方保存,其余寄存器由被叫方保存。x87 浮点寄存器 调用新函数时,ST0 到 ST7 必须为空(弹出或释放),退出函数时ST1 到 ST7 必须为空。ST0 在未用于返回值时也必须为空。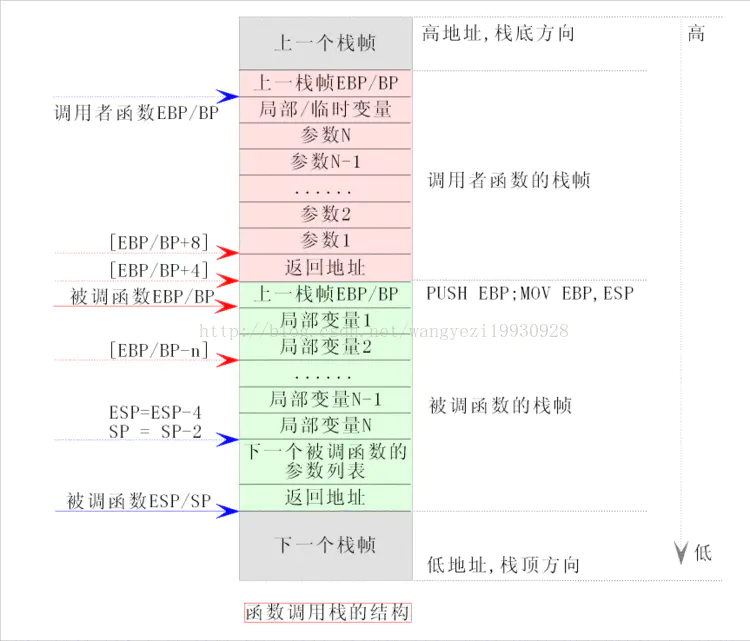
0000822c <func>:
822c: e52db004 push {fp} ; (str fp, [sp, #-4]!) 如果嵌套调用 push {fp,lr}
8230: e28db000 add fp, sp, #0
8234: e24dd014 sub sp, sp, #20
8238: e50b0010 str r0, [fp, #-16]
823c: e3a03002 mov r3, #2
8240: e50b3008 str r3, [fp, #-8]
8244: e51b3008 ldr r3, [fp, #-8]
8248: e51b2010 ldr r2, [fp, #-16]
824c: e0030392 mul r3, r2, r3
8250: e1a00003 mov r0, r3
8254: e24bd000 sub sp, fp, #0
8258: e49db004 pop {fp} ; (ldr fp, [sp], #4) 如果嵌套调用 pop {fp,lr}
825c: e12fff1e bx lr ; MOV PC,LR
00008260 <main>:
8260: e92d4800 push {fp, lr}
8264: e28db004 add fp, sp, #4
8268: e24dd008 sub sp, sp, #8
826c: e3a03019 mov r3, #25
8270: e50b3008 str r3, [fp, #-8]
8274: e51b0008 ldr r0, [fp, #-8]
8278: ebffffeb bl 822c <func>
827c: e3a03000 mov r3, #0
8280: e1a00003 mov r0, r3
8284: e24bd004 sub sp, fp, #4
8288: e8bd8800 pop {fp, pc}
arm PC = x86 EIP ARM 为什么这么设计,就是为了返回地址不存栈,而是存在寄存器里。但是面对嵌套的时候,还是需要压栈。
由编译器自动分配释放,存放函数的参数值、返回值、局部变量等。在程序运行过程中实时加载和释放,因此,局部变量的生存周期为申请到释放该段栈空间。
WIndow系统一般是2MB。Linux可以查看ulimit -s ,通常是8M
栈空间最好保持在cache里,太大会存入内存。持续地重用栈空间有助于使活跃的栈内存保持在CPU缓存中,从而加速访问。进程中的每个线程都有属于自己的栈。向栈中不断压入数据时,若超出其容量就会耗尽栈对应的内存区域,从而触发一个页错误。
函数参数传递一般通过寄存器,太多了就存入栈内。
栈区(stack segment):由编译器自动分配释放,存放函数的参数的值,局部变量的值等。
局部变量空间是很小的,我们开一个a[1000000]就会导致栈溢出;而全局变量空间在Win 32bit 下可以达到4GB,因此不会溢出。
或者malloc使用堆的区域,但是记得free。
用于动态内存分配。堆在内存中位于BSS区和栈区之间。一般由程序员分配和释放,若程序员不释放,程序结束时有可能由OS回收。
分配的堆内存是经过字节对齐的空间,以适合原子操作。堆管理器通过链表管理每个申请的内存,由于堆申请和释放是无序的,最终会产生内存碎片。堆内存一般由应用程序分配释放,回收的内存可供重新使用。若程序员不释放,程序结束时操作系统可能会自动回收。
用户堆,每个进程有一个,进程中的每个线程都从这个堆申请内存,这个堆在用户空间。所谓内训耗光,一般就是这个用户堆申请不到内存了,申请不到分两种情况,一种是你 malloc 的比剩余的总数还大,这个是肯定不会给你了。第二种是剩余的还有,但是都不连续,最大的一块都没有你 malloc 的大,也不会给你。解决办法,直接申请一块儿大内存,自己管理。
除非特殊设计,一般你申请的内存首地址都是偶地址,也就是说你向堆申请一个字节,堆也会给你至少4个字节或者8个字节。
堆有一个堆指针(break brk),也是按照栈的方式运行的。内存映射段是存在在break brk指针与esp指针之间的一段空间。
在Linux中当动态分配内存大于128K时,会调用mmap函数在esp到break brk之间找一块相应大小的区域作为内存映射段返回给用户。
当小于128K时,才会调用brk或者sbrk函数,将break brk向上增长(break brk指针向高地址移动)相应大小,增长出来的区域便作为内存返回给用户。
两者的区别是
内存映射段销毁时,会释放其映射到的物理内存,
而break brk指向的数据被销毁时,不释放其物理内存,只是简单将break brk回撤,其虚拟地址到物理地址的映射依旧存在,这样使的当再需要分配小额内存时,只需要增加break brk的值,由于这段虚拟地址与物理地址的映射还存在,于是不会触发缺页中断。只有在break brk减少足够多,占据物理内存的空闲虚拟内存足够多时,才会真正释放它们。
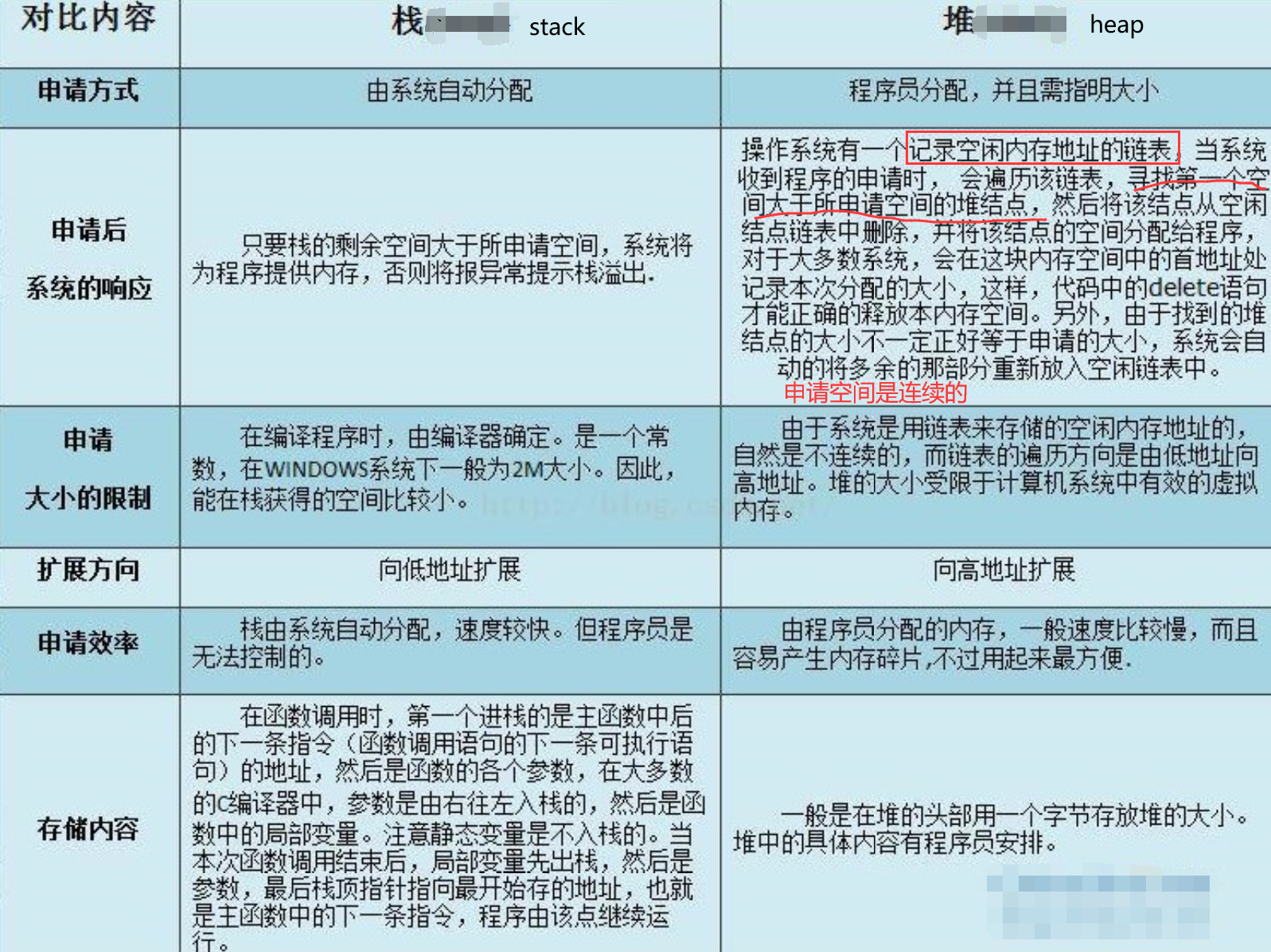
对栈而言,则不存在碎片问题,因为栈是先进后出的队列,永远不可能有一个内存块从栈中间弹出。
vmtouch 可以查看内存中加载的磁盘页表
用户进程内存空间,也是系统内核分配给该进程的VM(虚拟内存),但并不表示这个进程占用了这么多的RAM(物理内存)。这个空间有多大?命令top输出的VIRT值告诉了我们各个进程内存空间的大小(进程内存空间随着程序的执行会增大或者缩小)。
虚拟地址空间在32位模式下它是一个4GB的内存地址块。在Linux系统中, 内核进程和用户进程所占的虚拟内存比例是1:3,如下图。而Windows系统为2:2(通过设置Large-Address-Aware Executables标志也可为1:3)。这并不意味着内核使用那么多物理内存,仅表示它可支配这部分地址空间,根据需要将其映射到物理内存。
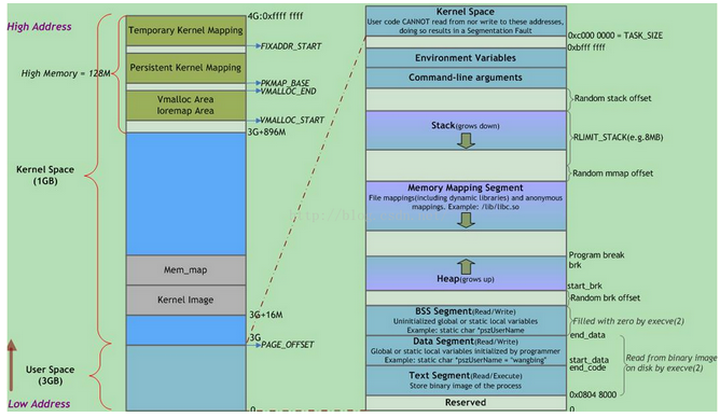
值得注意的是,每个进程的内核虚拟地址空间都是映射到相同的真实物理地址上,因为都是共享同一份物理内存上的内核代码。除此之外还要注意内核虚拟地址空间总是存放在虚拟内存的地址最高处。
其中,用户地址空间中的蓝色条带对应于映射到物理内存的不同内存段,灰白区域表示未映射的部分。这些段只是简单的内存地址范围,与Intel处理器的段没有关系。
上图中Random stack offset和Random mmap offset等随机值意在防止恶意程序。Linux通过对栈、内存映射段、堆的起始地址加上随机偏移量来打乱布局,以免恶意程序通过计算访问栈、库函数等地址。
execve(2)负责为进程代码段和数据段建立映射,真正将代码段和数据段的内容读入内存是由系统的缺页异常处理程序按需完成的。另外,execve(2)还会将BSS段清零。
VIRT = SWAP + RES # 总虚拟内存=动态 + 静态
RES >= CODE + DATA + SHR. # 静态内存 = 代码段 + 静态数据段 + 共享内存
MEM = RES / RAM
DATA CODE RES VIRT
before allocation: 124 4 408 3628
after 5MB allocation: 5008 4 476 8512 //malloc 5M, DATA和VIRT增加5M, RES不变
after 2MB initialization: 5008 4 2432 8512 //初始化 2M, DATA和VIRT不变, RES增加2M
//如果最后加上free(data), DATA, RES, VIRT又都会相应的减少,回到最初的状态
top 里按f 可以选择要显示的内容。
暂无
暂无
Light-weight Contexts: An OS Abstraction for Safety and Performance
https://blog.csdn.net/zy986718042/article/details/73556012
https://blog.csdn.net/qq_38769551/article/details/103099014
https://blog.csdn.net/ywcpig/article/details/52303745
https://zhuanlan.zhihu.com/p/23643064
https://www.bilibili.com/video/BV1N3411y7Mr?spm_id_from=444.41.0.0
GLIBC(GNU C Library)是Linux系统中的标准C库,它提供了许多与程序执行和系统交互相关的功能。GLIBC是应用程序与操作系统之间的接口,提供了许多系统调用的包装函数和其他基础功能,使应用程序能够访问操作系统提供的服务和资源。
GLIBC的主要功能包括:
上下文切换与GLIBC之间没有直接关系。上下文切换是操作系统的概念,是在进程或线程之间切换执行权的过程。GLIBC作为C库,封装了一些系统调用和基础功能,但并不直接参与上下文切换的过程。
然而,GLIBC的性能和效率可以影响上下文切换的开销。GLIBC的实现方式、性能优化以及与操作系统内核的协作方式,可能会对上下文切换的效率产生影响。例如,GLIBC的线程库(如pthread)的设计和性能特性,以及对锁、条件变量等同步原语的实现方式,都可能会影响多线程上下文切换的开销。
因此,尽管GLIBC本身不直接执行上下文切换,但它的设计和实现对于多线程编程和系统性能仍然具有重要的影响。
在PPA。改系统的glibc十分的危险,ssh连接,ls命令等,都需要用到。会导致ssh连接中断等问题。
不推荐,可能会遇到库依赖。比如缺少bison和gawk。详细依赖见
mkdir $HOME/glibc/ && cd $HOME/glibc
wget http://ftp.gnu.org/gnu/libc/glibc-2.32.tar.gz
tar -xvzf glibc-2.32.tar.gz
mkdir build
mkdir glibc-2.32-install
cd build
~/glibc/glibc-2.32/configure --prefix=$HOME/glibc/glibc-2.32-install
make
make install
您可以使用以下方法来查找libstdc++库的位置:
g++或gcc命令查找:如果您的系统上安装了g++或gcc编译器,您可以使用以下命令来查找libstdc++库的位置:或者
ldconfig命令查找:ldconfig是Linux系统中用于配置动态链接器的命令。您可以运行以下命令来查找libstdc++库的路径:/usr/lib或/usr/lib64。您可以在这些目录中查找libstdc++的库文件。如果您找到了libstdc++库的路径,您可以将其添加到CMakeLists.txt中的CMAKE_CXX_FLAGS变量中,如之前的回答中所示。
请注意,如果您正在使用的是Clang编译器(clang++),则默认情况下它将使用libc++作为C++标准库,而不是libstdc++。如果您确实希望使用libstdc++,需要显式指定使用-stdlib=libstdc++标志。例如:
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
无
According to 2007 paper
进程或线程的上下文切换可以在多种情况下发生,下面列举了一些常见的情况:
需要注意的是,上下文切换是操作系统内核的责任,它根据调度策略和内核的算法来管理进程和线程的切换。上下文切换的具体发生时机和行为取决于操作系统的设计和实现。
保存下来的上下文,会存储在系统内核中,并在任务重新调度执行时再次加载进来。这样就能保证任务原来的状态不受影响,让任务看起来还是连续运行。
包括以下几个方面:
相对于进程上下文切换,线程上下文切换通常更快,这是因为线程共享相同的地址空间和其他资源,因此上下文切换只需要切换线程的执行状态和部分寄存器,省去了一些额外的开销。
以下是线程上下文切换相对于进程上下文切换的一些优势和省去的时间开销:
尽管线程上下文切换相对较快,但仍然需要一些时间和开销,包括以下方面:
需要注意的是,线程上下文切换的快速性是相对于进程上下文切换而言的,具体的开销和时间取决于系统的设计、硬件的性能和操作系统的实现。不同的操作系统和硬件平台可能会有不同的上下文切换开销。
如果要能清晰的回答这一点,需要对OS的页表管理和上下午切换的流程十分了解。
Page Table Isolation(页面表隔离)是一种为了解决Meltdown等CPU安全漏洞而提出的硬件优化机制。
其主要思想是将操作系统内核和用户空间的页面表隔离开来,实现内核地址空间与用户地址空间的隔离。
具体来说,Page Table Isolation 主要包括以下措施:
这种机制可以阻止用户程序直接读取内核内存,防止Meltdown类攻击获得内核敏感信息。
当前主流的x86处理器通过在TLB中添加PTI(Page Table Isolation)位实现了此机制,来隔离内核地址空间。这成为了重要的安全优化之一。
由于PTI的存在,内核维护了两套 页表。
用户态切换的额外开销包括:
进程上下文标识符(PCID) 是一项 CPU 功能,它允许我们在切换页表时通过在 CR3 中设置一个特殊位来跳过刷新整个 TLB。这使得切换页表(在上下文切换或内核进入/退出时)更便宜。但是,在支持 PCID 的系统上,上下文切换代码必须将用户和内核条目都从 TLB 中清除。用户 PCID TLB 刷新将推迟到退出到用户空间,从而最大限度地降低成本。有关PCID / INVPCID详细信息,请参阅 intel.com/sdm。
在没有 PCID 支持的系统上,每个 CR3 写入都会刷新整个 TLB。这意味着每个系统调用、中断或异常都会刷新 TLB
对于同一个进程的不同线程,当它们运行在不同的物理核心上时,其Intel PCID (进程上下文ID)是相同的。
主要原因如下:
PCID是用于区分不同进程地址空间的标识符。同一进程的线程共享相同的地址空间。 所以操作系统会为同一进程的所有线程分配相同的PCID,无论它们运行在哪个物理核心上。 当线程在物理核心之间迁移时,不需要改变PCID,因为地址空间没有改变。 线程迁移后,新的核心会重新使用原有的PCID加载地址翻译表,而不是分配新的PCID。 这确保了同进程不同线程使用统一的地址映射,TLB内容可以直接重用,无需刷新。 相反,不同进程之间必须使用不同的PCID,才能隔离地址映射,避免TLB冲突。 所以操作系统只会在进程切换时改变PCID,而线程切换保持PCID不变。
综上,对于同一进程的不同线程,无论运行在哪个物理核心,其PCID都是相同的。这使线程可以重用TLB项,是多线程架构的重要优化手段。同进程线程使用统一PCID,不同进程必须使用独立PCID。
PCID(Process Context Identifier)和 ASID(Address Space Identifier)都是用于优化页表切换的技术
Quantifying the cost of context switch
sched setaffinity() and sched setscheduler()SCHED FIFO and give them the maximum priority.# shaojiemike @ hades0 in ~/github/contextSwitch2007 on git:master x [15:59:39] C:10
$ sudo ./measureSwitch
time2 with context swith: 1.523668 1.509177 1.507308
measureSwitch: array_size = 0, stride = 0, min time2 = 1.507308008149266
# shaojiemike @ hades0 in ~/github/contextSwitch2007 on git:master x [16:04:15]
$ sudo ./measureSingle
time1 without context switch: 0.727125 0.655041 0.689502
measureSingle: array_size = 0, stride = 0, min time1 = 0.655041355639696
us microseconds, 论文里是3.8 us,我们的机器是0.85 us。Tsuna的2010年的博客 code in https://github.com/tsuna/contextswitch 机器配置在实验结果后。
gettid()futex来切换。包含futex system calls.开销sched_yield让出CPU使用权,强制发生进程切换.futex.只不过线程通过 pthread_create创建来执行函数, 而不是forkshed_yield().并且设置SCHED_FIFO 和 sched_prioritysched_yield()函数的作用是使当前进程放弃CPU使用权,将其重新排入就绪队列尾部。但是如果就绪队列中只有这一个进程,那么该进程会立即再次获得CPU时间片而继续执行。必须有其他等待进程且满足调度条件才会真正发生切换。# snode6
$ sudo taskset 0x3 ./timetctxsw2
2000000 thread context switches in 486078214ns (243.0ns/ctxsw)
$ sudo taskset 0x1 ./timetctxsw2
2000000 thread context switches in 1071542621ns (535.8ns/ctxsw)
# hades0
$ sudo taskset 0x3 ./timetctxsw2
2000000 thread context switches in 89479052ns (44.7ns/ctxsw)
$ sudo taskset 0x1 ./timetctxsw2
2000000 thread context switches in 566817108ns (283.4ns/ctxsw)
如上,snode6应该是550ns
machine| system calls | process context switches | thread context switches | thread context switches 2 ---|---|---|---|---| snode6| 428.6| 2520.3| 2606.3(1738.9)| 277.8| snode6| 427.7| 2419.8| 2249.0(2167.9)| 401.1| snode6| 436.0| 2327.1| 2358.8(1727.8)| 329.3| hades| 65.8| 1806.4| 1806.4| 64.6| hades| 65.5| 1416.4| 1311.6| 282.7| hades| 80.8| 2153.1| 1903.4| 64.3| icarus| 74.1| 1562.3| 1622.3| 51.0| icarus| 74.1| 1464.6| 1274.1| 232.6| icarus| 73.9| 1671.8| 1302.1| 38.0| vlab| 703.4| 5126.3| 4897.7| 826.1| vlab| x| x| x| x| vlab| 697.1| 10651.4| 4476.0| 843.9*| docker |||| docker |||| docker ||||
说明:
No CPU affinity 和 With CPU affinity 和 With CPU affinity to CPU 0()内为。额外添加设置SCHED_FIFO 和 sched_priority的结果。* 意味着没有sudo权限。报错sched_setscheduler(): Operation not permittedx 报错taskset: 设置 pid 30727 的亲和力失败: 无效的参数问题:
shed_yield().并且设置SCHED_FIFO 和 sched_priority运行strace -ff -tt -v taskset -a 1 ./timetctxsw2. 应该是不需要strace的,为什么需要记录syscall的信息呢?
# snode6
2000000 thread context switches in 22987942914ns (11494.0ns/ctxsw)
# snode6 without strace
$ sudo taskset -c 1 ./timetctxsw2
2000000 thread context switches in 1073826309ns (536.9ns/ctxsw)
$ sudo taskset -a 1 ./timetctxsw2
2000000 thread context switches in 1093753292ns (546.9ns/ctxsw)
$ sudo taskset 1 ./timetctxsw2
2000000 thread context switches in 1073456816ns (536.7ns/ctxsw)
# hades
2000000 thread context switches in 20945815905ns (10472.9ns/ctxsw)
# icarus
2000000 thread context switches in 19053536242ns (9526.8ns/ctxsw)
2000000 thread context switches in 17573109017ns (8786.6ns/ctxsw)
2000000 thread context switches in 18538271021ns (9269.1ns/ctxsw)
猜想:
shaojiemike @ snode6 in ~/github/contextswitch on git:master o [19:46:27]
$ sudo ./cpubench.sh
model name : Intel(R) Xeon(R) CPU E5-2695 v4 @ 2.10GHz
2 physical CPUs, 18 cores/CPU, 2 hardware threads/core = 72 hw threads total
hades1# ./cpubench.sh
model name : AMD EPYC 7543 32-Core Processor 1.5 ~ 3.7GHz
2 physical CPUs, 32 cores/CPU, 2 hardware threads/core = 128 hw threads total
# shaojiemike @ icarus0 in ~/github/contextswitch on git:master o [20:41:39] C:1
$ ./cpubench.sh
model name : Intel(R) Xeon(R) Platinum 8358 CPU @ 2.60GHz
2 physical CPUs, 32 cores/CPU, 1 hardware threads/core = 64 hw threads total
ubuntu@VM7096-huawei:~/github/contextswitch$ sudo ./cpubench.sh
model name : Intel(R) Xeon(R) Silver 4110 CPU @ 2.10GHz
2 physical CPUs, 8 cores/CPU, 2 hardware threads/core = 32 hw threads total
machine| OS | linux kernel | compile | glibc ---|---|---|---|---| snode6|Ubuntu 20.04.6 LTS|5.4.0-148-generic|gcc 9.4.0|GLIBC 2.31 hades|Ubuntu 22.04.2 LTS|5.15.0-76-generic|gcc 11.3.0|GLIBC 2.35-0ubuntu3.1 icarus|Ubuntu 22.04.2 LTS|5.15.0-75-generic|gcc 11.3.0|GLIBC 2.35-0ubuntu3.1 vlab|Ubuntu 22.04.2 LTS|5.15.81-1-pve|gcc 11.3.0|GLIBC 2.35-0ubuntu3.1
glic 版本使用ldd --version获得。OS影响调度算法,内核影响切换机制,编译器影响代码优化,GLIBC影响系统调用开销。
sched_setscheduler() 是一个用于设置进程调度策略的函数。它允许您更改进程的调度策略以及与之相关的参数。具体来说,sched_setscheduler() 函数用于将当前进程(通过 getpid() 获取进程ID)的调度策略设置为实时调度策略(SCHED_FIFO)。实时调度策略是一种优先级调度策略,它将进程分配给一个固定的时间片,并且仅当进程主动释放 CPU 或者其他高优先级的实时进程出现时,才会进行上下文切换。/sys/bus/node/devices/node0/cpumap 存储了与特定 NUMA 节点(NUMA node)关联的 CPU 核心映射信息。cpumap 文件中的内容表示与 node0 相关的 CPU 核心的映射。每个位置上的值表示相应 CPU 核心的状态,常见的取值有:node0。node0。
这种映射信息可以帮助系统管理员和开发人员了解系统的 NUMA 结构,以及每个 NUMA 节点上的 CPU 核心分布情况。通过查看这些信息,可以更好地优化任务和进程的分配,以提高系统的性能和效率。# shaojiemike @ snode6 in ~/github/contextswitch on git:master x [22:37:41] C:1
$ cat /sys/bus/node/devices/node0/cpumap
00,003ffff0,0003ffff
# shaojiemike @ snode6 in ~/github/contextswitch on git:master x [23:13:41]
$ cat /sys/bus/node/devices/node1/cpumap
ff,ffc0000f,fffc0000
# 与taskset结合 设置 亲和性
taskset `sed 's/,//g;s/^/0x/' /sys/bus/node/devices/node0/cpumap` exe
taskset 0x00003ffff00003ffff exe
根据1996的论文,需要考虑几个方面的内容:
http://lmbench.sourceforge.net/cgi-bin/man?keyword=lmbench§ion=8
#include <unistd.h> /pipe()的父子进程的write和read system calls实验环境:
根据Light-weight Contexts的数据:
注意,括号内为十次执行的标准差
解释与组成
在测量上下文切换开销时,进程和线程的切换开销可能会相对接近,这可能是由于以下几个原因:
TLB(Translation Lookaside Buffer)的刷新:TLB是用于高速缓存虚拟地址到物理地址映射的硬件结构。当发生进程或线程切换时,TLB中的缓存项可能需要刷新,以确保新的地址映射有效。虽然线程切换只涉及部分的TLB刷新,但刷新的开销相对较小,因此在总的上下文切换开销中可能没有明显拉开差距。
寄存器和上下文切换:无论是进程切换还是线程切换,都需要保存和恢复一部分寄存器的状态和执行上下文。这部分的开销在进程和线程切换中是相似的。
内核操作和调度开销:无论是进程还是线程切换,都需要涉及内核的操作和调度。这包括切换内核栈、更新调度信息、切换上下文等操作,这些开销在进程和线程切换中也是相似的。
需要注意的是,实际上下文切换的开销是受到多个因素的影响,如处理器架构、操作系统的实现、硬件性能等。具体的开销和差距会因系统的不同而有所差异。在某些情况下,线程切换的开销可能会稍微小一些,但在其他情况下,可能会存在较大的差距。因此,一般情况下,不能简单地将进程和线程的上下文切换开销归为相同或明显不同,具体的测量和评估需要结合实际系统和应用场景进行。
暂无
PIM 最优调度遇到的问题
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
Quantifying The Cost of Context Switch 2007,ExpCS
lmbench: Portable tools for performance analysis,1996 USENIX ATC
Light-weight Contexts: An OS Abstraction for Safety and Performance
参考 kernel 文档