Wireguard Server 2 Server in OpenWRT
导言
proxy all network request in 192.168.233.0/24 to 192.168.31.0/24
导言
proxy all network request in 192.168.233.0/24 to 192.168.31.0/24
对比如下:
| UDP | TCP | |
|---|---|---|
| 是否连接 | 无连接 | 面向连接 |
| 是否可靠 | 不可靠传输,不使用流量控制和拥塞控制 | 可靠传输,使用流量控制和拥塞控制 |
| 是否有序 | 无序 | 有序,消息在传输过程中可能会乱序,TCP 会重新排序 |
| 传输速度 | 快 | 慢 |
| 连接对象个数 | 支持一对一,一对多,多对一和多对多交互通信 | 只能是一对一通信 |
| 传输方式 | 面向报文 | 面向字节流 |
| 首部开销 | 首部开销小,仅8字节 | 首部最小20字节,最大60字节 |
| 适用场景 | 适用于实时应用(IP电话、视频会议、直播等) | 适用于要求可靠传输的应用,例如文件传输 |
总结:
TCP 是面向连接,能保证数据的可靠性交付,因此经常用于:
UDP 面向无连接,它可以随时发送数据,再加上UDP本身的处理既简单又高效,因此经常用于:
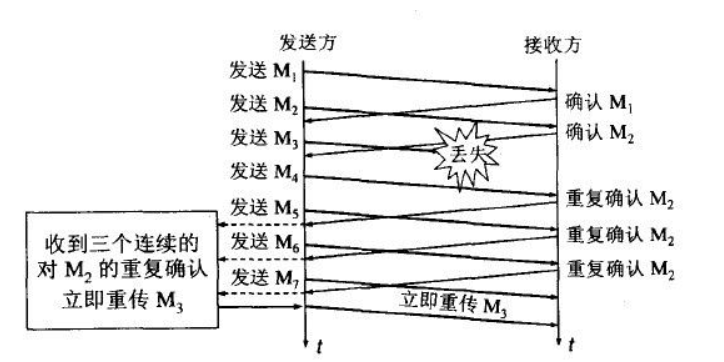
TCP主要提供了检验和、序列号/确认应答、超时重传、滑动窗口、拥塞控制和 流量控制等方法实现了可靠性传输。
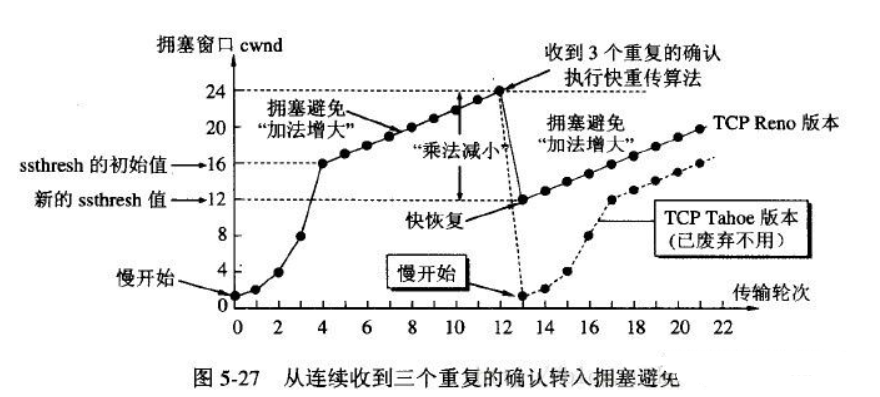
TCP 一共使用了四种算法来实现拥塞控制:
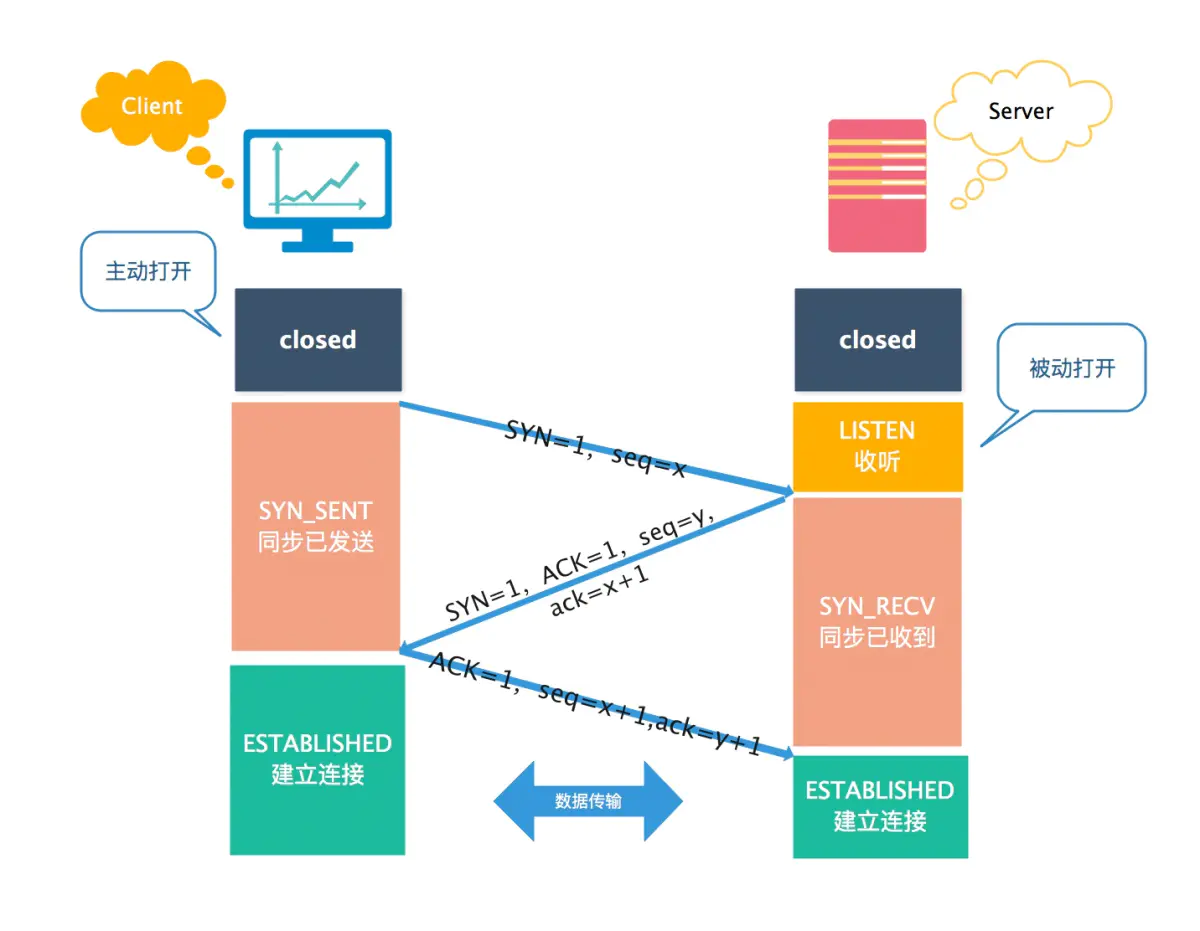
三次握手机制:
seq = x 作为初始序列号,ack = x + 1,同时选择一个随机数 seq = y 作为初始序列号,ack = y + 1,序列号为 seq = x + 1,理想状态下,TCP连接一旦建立,在通信双方中的任何一方主动关闭连接之前,TCP 连接都将被一直保持下去。
主要有三个原因:
在双方两次握手即可建立连接的情况下,假设客户端发送 A 报文段请求建立连接,由于网络原因造成 A 暂时无法到达服务器,服务器接收不到请求报文段就不会返回确认报文段。
客户端在长时间得不到应答的情况下重新发送请求报文段 B,这次 B 顺利到达服务器,服务器随即返回确认报文并进入 ESTABLISHED 状态,客户端在收到 确认报文后也进入 ESTABLISHED 状态,双方建立连接并传输数据,之后正常断开连接。
此时姗姗来迟的 A 报文段才到达服务器,服务器随即返回确认报文并进入 ESTABLISHED 状态,但是已经进入 CLOSED 状态的客户端无法再接受确认报文段,更无法进入 ESTABLISHED 状态,这将导致服务器长时间单方面等待,造成资源浪费。
第一次握手:客户端只是发送处请求报文段,什么都无法确认,而服务器可以确认自己的接收能力和对方的发送能力正常;
第二次握手:客户端可以确认自己发送能力和接收能力正常,对方发送能力和接收能力正常;
第三次握手:服务器可以确认自己发送能力和接收能力正常,对方发送能力和接收能力正常;
可见三次握手才能让双方都确认自己和对方的发送和接收能力全部正常,这样就可以愉快地进行通信了。
TCP 实现了可靠的数据传输,原因之一就是 TCP 报文段中维护了序号字段和确认序号字段,通过这两个字段双方都可以知道在自己发出的数据中,哪些是已经被对方确认接收的。这两个字段的值会在初始序号值得基础递增,如果是两次握手,只有发起方的初始序号可以得到确认,而另一方的初始序号则得不到确认。
因为三次握手已经可以确认双方的发送接收能力正常,双方都知道彼此已经准备好,而且也可以完成对双方初始序号值得确认,也就无需再第四次握手了。
SYN洪泛攻击属于 DOS 攻击的一种,它利用 TCP 协议缺陷,通过发送大量的半连接请求,耗费 CPU 和内存资源。
原理:
[SYN/ACK] 包(第二个包)之后、收到客户端的 [ACK] 包(第三个包)之前的 TCP 连接称为半连接(half-open connect),SYN_RECV(等待客户端响应)状态。如果接收到客户端的 [ACK],则 TCP 连接成功,[SYN] 包,服务器回复 [SYN/ACK] 包,并等待客户的确认。由于源地址是不存在的,服务器需要不断的重发直至超时。[SYN] 包将长时间占用未连接队列,影响了正常的 SYN,导致目标系统运行缓慢、网络堵塞甚至系统瘫痪。检测:当在服务器上看到大量的半连接状态时,特别是源 IP 地址是随机的,基本上可以断定这是一次 SYN 攻击。
防范:
服务端:
客户端:
客户端认为这个连接已经建立,如果客户端向服务端发送数据,服务端将以RST包(Reset,标示复位,用于异常的关闭连接)响应。此时,客户端知道第三次握手失败。
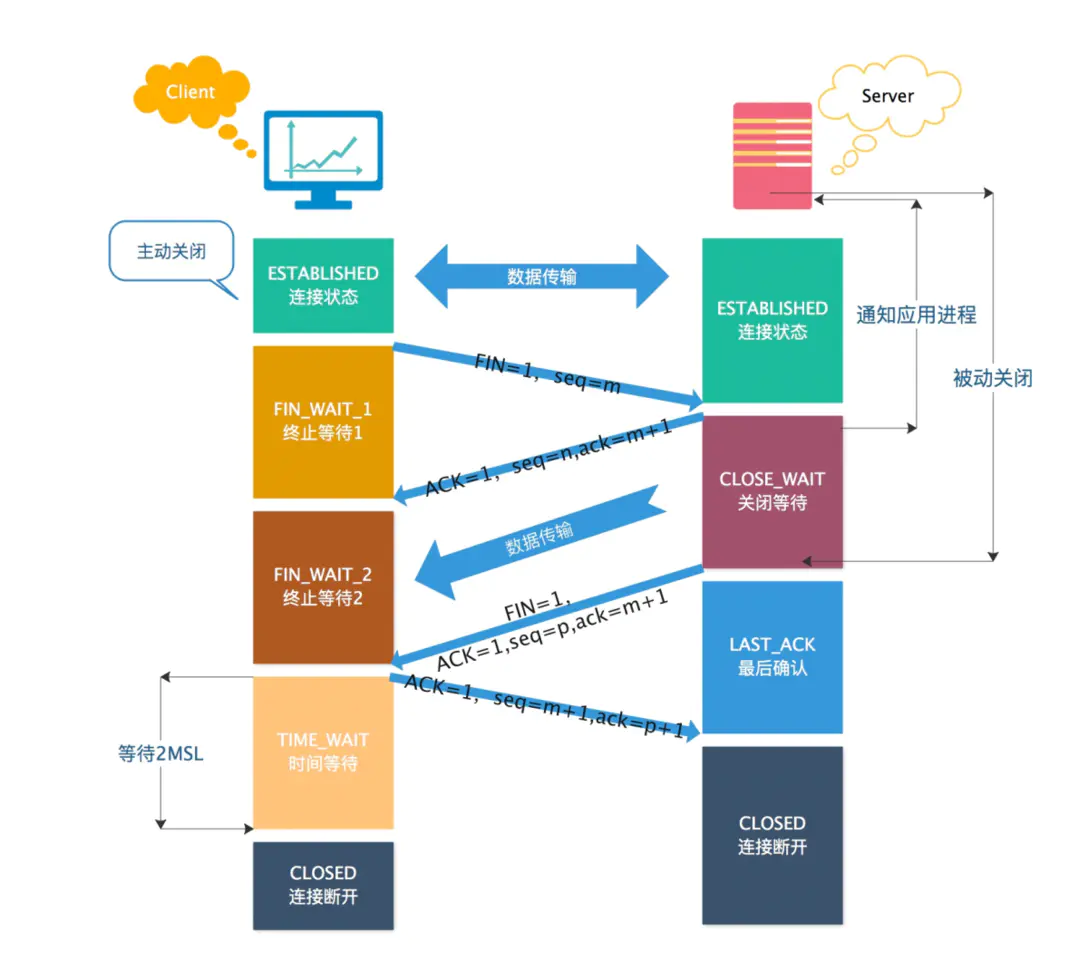
第一次挥手:客户端向服务端发送连接释放报文(FIN=1,ACK=1),主动关闭连接,同时等待服务端的确认。
序列号 seq = u,即客户端上次发送的报文的最后一个字节的序号 + 1
确认号 ack = k, 即服务端上次发送的报文的最后一个字节的序号 + 1
第二次挥手:服务端收到连接释放报文后,立即发出确认报文(ACK=1),序列号 seq = k,确认号 ack = u + 1。
这时 TCP 连接处于半关闭状态,即客户端到服务端的连接已经释放了,但是服务端到客户端的连接还未释放。这表示客户端已经没有数据发送了,但是服务端可能还要给客户端发送数据。
第三次挥手:服务端向客户端发送连接释放报文(FIN=1,ACK=1),主动关闭连接,同时等待 A 的确认。
序列号 seq = w,即服务端上次发送的报文的最后一个字节的序号 + 1。
确认号 ack = u + 1,与第二次挥手相同,因为这段时间客户端没有发送数据
第四次挥手:客户端收到服务端的连接释放报文后,立即发出确认报文(ACK=1),序列号 seq = u + 1,确认号为 ack = w + 1。
此时,客户端就进入了 TIME-WAIT 状态。注意此时客户端到 TCP 连接还没有释放,必须经过 2*MSL(最长报文段寿命)的时间后,才进入 CLOSED 状态。而服务端只要收到客户端发出的确认,就立即进入 CLOSED 状态。可以看到,服务端结束 TCP 连接的时间要比客户端早一些。
服务器在收到客户端的 FIN 报文段后,可能还有一些数据要传输,所以不能马上关闭连接,但是会做出应答,返回 ACK 报文段.
接下来可能会继续发送数据,在数据发送完后,服务器会向客户单发送 FIN 报文,表示数据已经发送完毕,请求关闭连接。服务器的ACK和FIN一般都会分开发送,从而导致多了一次,因此一共需要四次挥手。
主要有两个原因:
第四次挥手时,客户端第四次挥手的 ACK 报文不一定会到达服务端。服务端会超时重传 FIN/ACK 报文,此时如果客户端已经断开了连接,那么就无法响应服务端的二次请求,这样服务端迟迟收不到 FIN/ACK 报文的确认,就无法正常断开连接。
MSL 是报文段在网络上存活的最长时间。客户端等待 2MSL 时间,即「客户端 ACK 报文 1MSL 超时 + 服务端 FIN 报文 1MSL 传输」,就能够收到服务端重传的 FIN/ACK 报文,然后客户端重传一次 ACK 报文,并重新启动 2MSL 计时器。如此保证服务端能够正常关闭。
如果服务端重发的 FIN 没有成功地在 2MSL 时间里传给客户端,服务端则会继续超时重试直到断开连接。
TCP 要求在 2MSL 内不使用相同的序列号。客户端在发送完最后一个 ACK 报文段后,再经过时间 2MSL,就可以保证本连接持续的时间内产生的所有报文段都从网络中消失。这样就可以使下一个连接中不会出现这种旧的连接请求报文段。或者即使收到这些过时的报文,也可以不处理它。
或者说,如果三次握手阶段、四次挥手阶段的包丢失了怎么办?如“服务端重发 FIN丢失”的问题。
简而言之,通过定时器 + 超时重试机制,尝试获取确认,直到最后会自动断开连接。
具体而言,TCP 设有一个保活计时器。服务器每收到一次客户端的数据,都会重新复位这个计时器,时间通常是设置为 2 小时。若 2 小时还没有收到客户端的任何数据,服务器就开始重试:每隔 75 分钟发送一个探测报文段,若一连发送 10 个探测报文后客户端依然没有回应,那么服务器就认为连接已经断开了。
从服务器来讲,短时间内关闭了大量的Client连接,就会造成服务器上出现大量的TIME_WAIT连接,严重消耗着服务器的资源,此时部分客户端就会显示连接不上。
从客户端来讲,客户端TIME_WAIT过多,就会导致端口资源被占用,因为端口就65536个,被占满就会导致无法创建新的连接。
解决办法:
服务器可以设置 SO_REUSEADDR 套接字选项来避免 TIME_WAIT状态,此套接字选项告诉内核,即使此端口正忙(处于 TIME_WAIT状态),也请继续并重用它。
调整系统内核参数,修改/etc/sysctl.conf文件,即修改net.ipv4.tcp_tw_reuse 和 tcp_timestamps
net.ipv4.tcp_tw_reuse = 1 表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭;
net.ipv4.tcp_tw_recycle = 1 表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭。
TIME_WAIT 是主动断开连接的一方会进入的状态,一般情况下,都是客户端所处的状态;服务器端一般设置不主动关闭连接。
TIME_WAIT 需要等待 2MSL,在大量短连接的情况下,TIME_WAIT会太多,这也会消耗很多系统资源。对于服务器来说,在 HTTP 协议里指定 KeepAlive(浏览器重用一个 TCP 连接来处理多个 HTTP 请求),由浏览器来主动断开连接,可以一定程度上减少服务器的这个问题。
现在有一个数据部分长度为8192B的数据需要通过UDP在以太网上传播,经过分片化为多个IP数据报片,这些片中的数据部分长度都有哪些?(假设按照最大长度分片), 计网习题
暂无
暂无
无
vpn:英文全称是“Virtual Private Network”,翻译过来就是“虚拟专用网络”。vpn通常拿来做2个事情:
一句话,vpn在IP层工作,而ss在TCP层工作。

理解 VPN 路由(以及任何网络路由)配置的关键是认识到一个 IP packet 如何被传输,以下描述的是极度简化后的单向传输过程:
为什么机器 A 的本地路由表里会有 172.29.1.0/24 这个网段的路由规则?通常情况下,这是 OpenVPN 服务端推送给客户端,由客户端在建立 VPN 连接时自动添加的。也可以由服务端自定义,比如wireguard
这个时候,如果机器 B 想要回复 A(比如发个 ACK),就会出问题,因为 packet 的来源地址还是 10.8.0.123, 而 10.8.0.0/24 网段并不属于当前局域网,是 VPN 服务端私有的——机器 B 往 10.8.0.123 发送的 ACK 会在某个位置(比如默认网关)遇到 "host unreachable" 而被丢弃。对于机器 A 来说,表面现象可能是连接超时或 ping 不通。
解决方法是,在 packet 离开 VPN 服务端时,将其「伪装」成来自 172.29.0.3(举例VPN 服务端的局域网地址),这样机器 B 发送的 ACK 就能顺利回到 VPN 服务端,然后发给机器 A. 这就是所谓的 SNAT。
在 Linux 系统中由 iptables 来管理,具体命令是:
连接 OpenVPN 的两个 client 之间可以互相通信,这是因为服务端推送的路由里包含了对应的网段。但是想从 Client A 到达 Client B 所在局域网的其他机器,还需要额外的配置。因为 OpenVPN 服务端缺少 Client B 局域网相关的路由规则。
# server.conf
push "route 172.29.0.0 255.255.0.0" # client -> Client B 给客户端推送 172.29.0.0/16 网段的路由(即这个网段的IP的信息都经过VPN)
route 172.29.0.0 255.255.0.0 #在 OpenVPN Server 上添加 172.29.0.0/16 网段的路由,具体下一跳是哪里,由 client-config 里的 iroute 指定
# 启用 client-config, 目录里的文件名对应 client.crt 的 Common Name
client-config-dir /etc/openvpn/ccd
# /etc/openvpn/ccd/client-b
iroute 172.29.0.0 255.255.0.0 # 告诉 OpenVPN Server, 172.29.0.0/16 的下一跳应该是 client-b (根据名字来)
在前两节所给的配置基础上,只需要再加一点配置,就能实现 OpenVPN 服务端所在局域网与客户端所在局域网的互访。配置内容是,在各自局域网的默认网关上添加路由,将对方局域网网段的下一跳设为 OpenVPN 服务端 / 客户端所在机器,同时用 iptables 配置相应的 SNAT 规则。
Based on the info in clashio, we select some cheap vpns to try.
| name | 每月价格(¥/GB/off on holiday) | 每月单价(GB/¥) | 每年单价(GB/¥) | 节点数与稳定性 | 使用速度感觉 |
|---|---|---|---|---|---|
| fastlink 2019 | 20/100/-30% | 5 | 100+, 节点速度高达5Gbps | 峰值 5Gbps (1) | |
| totoro 2023 | 15/100/-20%(2) | 6.6 | ??? | ??? | |
| 冲浪猫 2022 | 16/200/-12%(3) | 12.5 | ??? | 峰值 1Gbps | |
| 奈云机场 2021 | 10.6/168/-30%(4) | 15.8 | 230624购买,240109几天全面掉线 | 峰值 5Gbps (6) | |
| FatCat 2023 | 6/60/-20% | 10 | ??? | 峰值 xx Gbps |
detail info in table
150¥*0.88My Choice: 单价,大小,速度,优惠码有效期
现在组合:奈云机场(2) + fastlink。 等fastlink过期了(1),看要不要转成 冲浪猫。
&flag=clash下载config.yamlNyacloud 喵云:只有10个节点 8¥/40GB/0.03Gbps or 17¥/128GB/0.2Gbps 平均 5GB/¥
边界网关协议(Border Gateway Protocol,BGP)就是互联网的邮政服务。当有人把一封信投进邮筒时,邮政服务就会处理这封邮件,并选择一条快速、高效的路线将这封信投递给收件人。同样地,当有人通过互联网提交数据时,BGP 负责寻找数据能传播的所有可用路径,并选择最佳的路由,这通常意味着在自治系统之间跳跃。1
BGP不仅能够解决速度问题,还可以解决绕过线路故障: 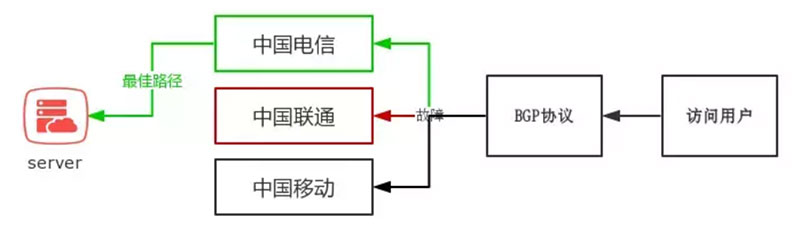
中文翻译是国际私用出租线路,是指用户专用的跨国的数据、话音等综合信息业务的通信线路。通俗地说,也就是指传统的跨境专线。
延迟更低40ms、速度更快, 但是价格贵1 元 / GB。
Anycast 是一种网络寻址和路由方法,可以将传入请求路由到各种不同的位置或“节点”。在 CDN 的上下文中,Anycast 通常会将传入的流量路由到距离最近并且能够有效处理请求的数据中心。选择性路由使 Anycast 网络能够应对高流量、网络拥塞和 DDoS 攻击。
brook vpn+ Amazon American node
导言
我想写关于 linux 网络命令 ip iptables ufw 的相关文档来全面表述linux网络的构成和如何控制管理
防火墙是一种网络安全设备,主要是通过硬件和软件的作用于内部和外部网络的环境间产生一种保护的屏障,从而实现对计算机不安全网络因素的阻断。 * 所有流入流出的所有网络通信均要经过此防火墙。 * 功能 * 访问控制、隔离保护 * 组成 * 服务访问政策、验证工具、包过滤和应用网关
POSTROUTING链发挥作用。PREROUTING链中发挥作用,以便让包进入FORWARD表。
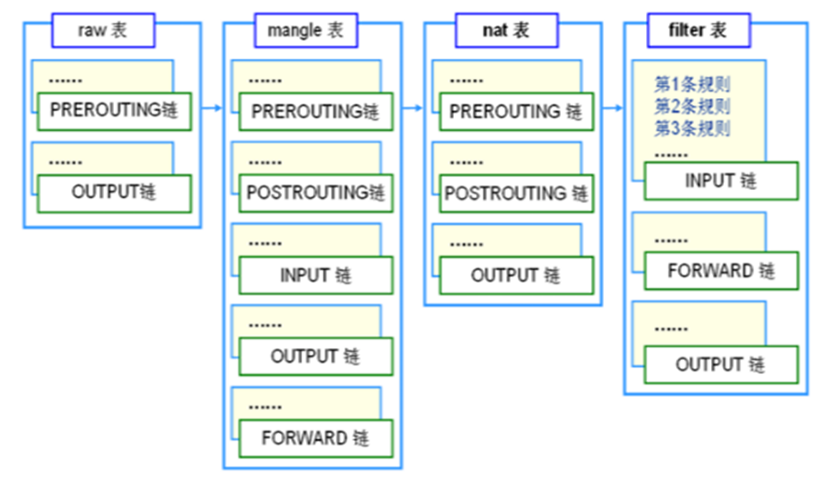
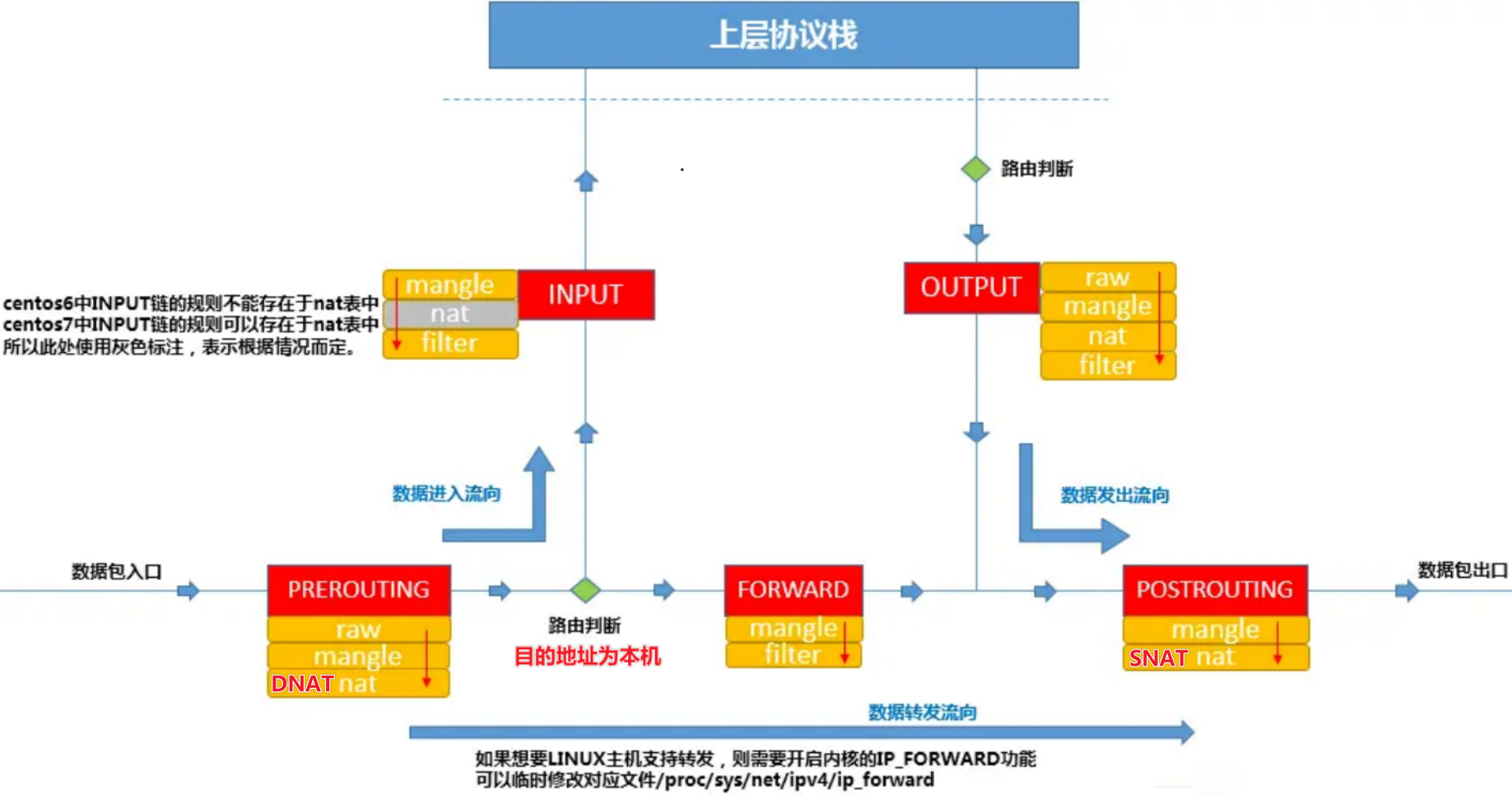
与iptables表的对应关系
| nftables簇 | iptables实用程序 |
|---|---|
| ip | iptables |
| ip6 | ip6tables |
| inet | iptables和ip6tables |
| arp | arptables |
| bridge | ebtables |
ip(即IPv4)是默认簇,如果未指定簇,则使用该簇。inet。inet允许统一ip和ip6簇,以便更容易地定义规则。table inet warp {
chain warp-in {
type filter hook input priority mangle; policy accept;
ip6 saddr 2606:4700:d0::a29f:c001 udp sport 1701 @th,72,24 set 0x0
}
chain warp-out {
type filter hook output priority mangle; policy accept;
ip6 daddr 2606:4700:d0::a29f:c001 udp dport 1701 @th,72,24 set 0x46c997
}
}
type 可以是filter、route或者nat。hook 在IPv4/IPv6/Inet地址簇中,可以是prerouting、input、forward、output或者postrouting。其他地址簇中的钩子列表请参见nft(8)。对于每条链,内核会按照顺序依次检查 iptables 防火墙规则,如果发现有匹配的规则目录,则立刻执行相关动作,停止继续向下查找规则目录;如果所有的防火墙规则都未能匹配成功,则按照默认策略处理。
$ sudo iptables -vnL
Chain INPUT (policy ACCEPT 2211K packets, 855M bytes)
pkts bytes target prot opt in out source destination
0 0 ACCEPT all -- tun0 * 0.0.0.0/0 0.0.0.0/0
-t filter -v 显示详细信息,-n显示具体ip和端口数值policy ACCEPT 当前链的默认策略 ACCEPTpkts:对应规则匹配到的报文的个数。命令部分:-j + 如下动作
* ACCEPT:允许数据包通过。
* DROP:直接丢弃数据包,不给任何回应信息,这时候客户端会感觉自己的请求泥牛入海了,过了超时时间才会有反应。
* REJECT:拒绝数据包通过,必要时会给数据发送端一个响应的信息,客户端刚请求就会收到拒绝的信息。
* SNAT:源地址转换,解决内网用户用同一个公网地址上网的问题。
* MASQUERADE:是SNAT的一种特殊形式,适用于动态的、临时会变的ip上。
* DNAT:目标地址转换。
* REDIRECT:在本机做端口映射。
* LOG:在/var/log/messages文件中记录日志信息,然后将数据包传递给下一条规则,也就是说除了记录以外不对数据包做任何其他操作,仍然让下一条规则去匹配。
Add a NAT rule to translate all traffic from the 192.168.0.0/24 subnet to the host's public IP:
$sudo iptables -t nat -A POSTROUTING -s 192.168.0.0/24 -j MASQUERADE
$ sudo iptables -t nat -vnL --line-numbers
Chain POSTROUTING (policy ACCEPT 19 packets, 1551 bytes)
num pkts bytes target prot opt in out source destination
6 0 0 MASQUERADE all -- * * 192.168.0.0/24 0.0.0.0/0
$ sudo iptables -t nat -D POSTROUTING 6 #delete
to finished
暂无
暂无
https://blog.csdn.net/weixin_45649763/article/details/103338747
https://juejin.cn/post/7108726951304495135
https://icloudnative.io/posts/using-nftables/
导言
电脑直接传输特别慢平均10M
群晖DS220j文件传输速度、外网访问速度、moment套件使用情况以及耗电情况。 最高写入速度为105MB/S,最高读取速度为110MB/S。
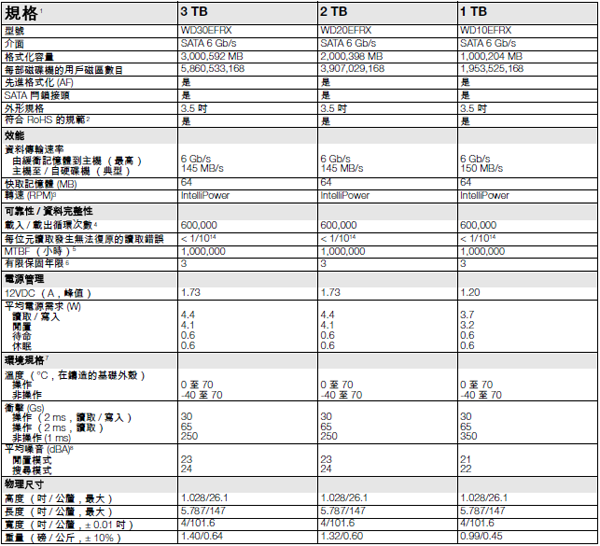
西数红盘 2T。 145MB/s。
知乎评测: 局域网实际拷贝速度还不错,基本能达到千兆水平。下图是拷贝GB级文件(如电影)的截图,拷贝照片和音乐之类的小文件会慢不少,10MB大小的文件写入速度有60MB/s左右,更小的文件就只有30MB/s了。
路由器是Redmi AX3000wifi6 WAN口和LAN口都是千兆口 2000Mbit 3000Mbit
电脑的网口是B450 迫击炮的主板 千兆口
电脑连路由器的的网线是cat.6A的
电脑连墙壁接口的是cat.5e的
网线,DS220J 送的是cat.5e
只要网线够短,cat.5e至少有5Gb/s,一般都不是瓶颈。1
网线直连电脑和群晖的机器,用这根CAT.6A,速度也很慢。
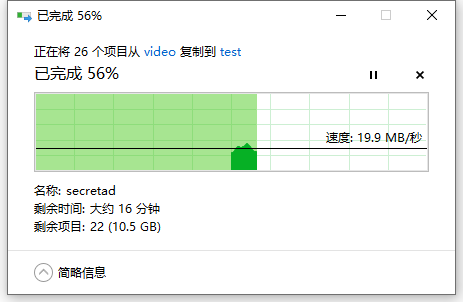
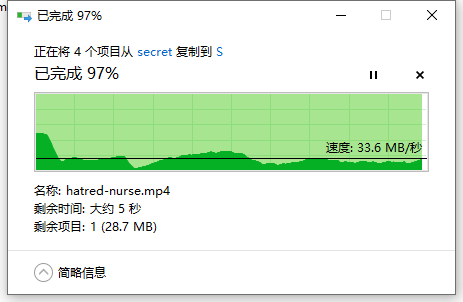
(结果第二天就好多了,路由器平均50M,直连能跑满,感觉原因在于路由器缓存转发的问题,端口都是千兆的)
diskgenius
控制面板 开启ssh
ssh -p 2333 [email protected]
sudo -s
sh-4.4# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/md0 2.3G 1.1G 1.2G 50% /
devtmpfs 225M 0 225M 0% /dev
tmpfs 243M 24K 243M 1% /dev/shm
tmpfs 243M 15M 228M 7% /run
tmpfs 243M 0 243M 0% /sys/fs/cgroup
tmpfs 243M 1.5M 241M 1% /tmp
/dev/vg1/volume_1 1.8T 1.5T 289G 85% /volume1
/dev/vg3/volume_3 4.0T 2.0G 4.0T 1% /volume3
/dev/vg3/volume_4 4.0T 89M 4.0T 1% /volume4
# 磁盘读性能
sh-4.4# hdparm -Tt /dev/vg1/volume_1
/dev/vg1/volume_1:
Timing cached reads: 1092 MB in 2.00 seconds = 545.67 MB/sec
Timing buffered disk reads: 456 MB in 3.03 seconds = 150.28 MB/sec
sh-4.4# hdparm -Tt /dev/md4
/dev/md4:
Timing cached reads: 1086 MB in 2.00 seconds = 542.89 MB/sec
Timing buffered disk reads: 838 MB in 3.00 seconds = 279.23 MB/sec
sh-4.4# hdparm -Tt /dev/mapper/vg3-volume_4
/dev/mapper/vg3-volume_4:
Timing cached reads: 1076 MB in 2.00 seconds = 537.13 MB/sec
Timing buffered disk reads: 592 MB in 3.01 seconds = 196.89 MB/sec
# 磁盘写性能
sh-4.4# dd if=/dev/vg3/volume_3 bs=1024 count=1000000 of=/1Gb.file
1000000+0 records in
1000000+0 records out
1024000000 bytes (1.0 GB, 977 MiB) copied, 13.0458 s, 78.5 MB/s
sh-4.4# dd if=/dev/vg1/volume_1 bs=1024 count=1000000 of=/1Gb.file
1000000+0 records in
1000000+0 records out
1024000000 bytes (1.0 GB, 977 MiB) copied, 18.837 s, 54.4 MB/s
群晖的docker里也有speedtest
https://post.smzdm.com/p/a5d23w98/
\\192.168.31.247 (双斜杠,右键home有选项:映射网络驱动器)\\tsjNas (需要在局域网下)\\222.195.90.2/ (需要开启路由器的SMB(137-139,445)端口转发,否则能ping通,但是不能访问)使用开机wireguard脚本连接上网
/volume1/xxx编辑脚本,赋予权限vi /etc/rc# 设置本地ssh eth0的222.195.90.2的高优先级,不至于开启wg断开ssh
ip ro add default via 222.195.90.254 dev eth0 table eth0-table
# 为了使得除开本地ssh网络走wg,需要删除屏蔽default的wg的DHCP
ip ro d default via 222.195.90.254 dev eth0 src 222.195.90.2 table main
# 防止服务端重启,Nas的wg客户端失联
ip ro a 114.214.233.0/24 via 222.195.90.254 dev eth0 src 222.195.90.2 table main
# 启动wg
wg-quick up wg1
Win10 无法直接取消,会报错"此连接不存在",参考文章1
需要删除两项 regedit注册表 计算机\HKEY_CURRENT_USER\SOFTWARE\Microsoft\Windows\CurrentVersion\Explorer\MountPoints2\##10.0.0.12#homes 和 计算机\HKEY_CURRENT_USER\Network 下对应的盘符即可。
如果要利用空间不要组RAID,通过添加存储池来使用每个盘。
RAID0也不要组,文件是打散的,虽然读和写块,但是是一个整体。坏一个就全坏了。
先配置存储池和存储空间

然后设置文件夹
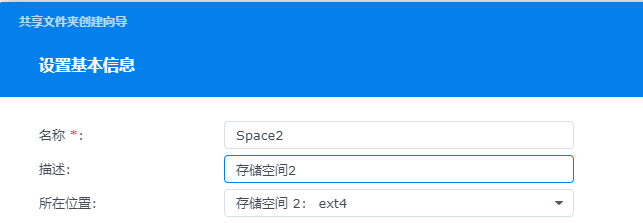
再重新映射盘符即可

若要激活硬盘: 已停用硬盘的分配状态会更改为未初始化,这表示此硬盘未安装 DSM,可以分配给存储池。请执行以下任何操作以激活硬盘:
原因内存和性能不行,建议升级DS220j+ 额外拓展内存
群晖DS220j文件传输速度、外网访问速度、moment套件使用情况以及耗电情况。 最高写入速度为105MB/S,最高读取速度为110MB/S。
西数红盘 2T。 145MB/s。
知乎评测: 局域网实际拷贝速度还不错,基本能达到千兆水平。下图是拷贝GB级文件(如电影)的截图,拷贝照片和音乐之类的小文件会慢不少,10MB大小的文件写入速度有60MB/s左右,更小的文件就只有30MB/s了。
很有可能之前设置了静态IP,然后换了网络环境,网络掩码变了自然完全找不到。唯一的办法就是一定要保存和记录下之前的静态IP。
> nc -z -v -u 4.shaojiemike.top 51822,wg是udpAllowedIPs = 192.168.31.0/24,10.0.233.1/24.然后ping 192.168.31.1测试配置详解参考中文文档
[peer]里设定字段 PersistentKeepalive = 25,表示每隔 25 秒发送一次 ping 来检查连接。虽然AllowedIPs = 0.0.0.0/0与AllowedIPs = 0.0.0.0/1, 128.0.0.0/1包含的都是全部的ip。
但是前者在iptable里为default dev wg1,后者为两条0.0.0.0/1 dev wg1和128.0.0.0/1 dev wg1。
由于路由的ip匹配遵循最长前缀匹配规则,如果路由表里原本有一条efault dev eth0。使用前者会导致混乱。但是使用后者,由于两条的优先级会更高,会屏蔽掉原本的default规则。
前者的iptable修改如下:(macbook上)
> ip route
default via link#18 dev utun3
default via 192.168.233.1 dev en0
10.0.233.5/32 via 10.0.233.5 dev utun3
224.0.0.0/4 dev utun3 scope link
224.0.0.0/4 dev en0 scope link
255.255.255.255/32 dev utun3 scope link
255.255.255.255/32 dev en0 scope link
后者的iptable修改如下
> ip route
0.0.0.0/1 dev utun3 scope link
default via 192.168.233.1 dev en0
default via link#18 dev utun3
10.0.233.5/32 via 10.0.233.5 dev utun3
128.0.0.0/1 dev utun3 scope link
224.0.0.0/4 dev en0 scope link
224.0.0.0/4 dev utun3 scope link
255.255.255.255/32 dev en0 scope link
255.255.255.255/32 dev utun3 scope link
建议看WireGuard 教程:WireGuard 的工作原理 和WireGuard 基础教程:wg-quick 路由策略解读,详细解释了wg是如何修改路由表规则的。
默认会产生51840的路由table,ip rule优先级较高。可以通过配置文件中添加PostUp来修改最后一个default的路由规则。
root@snode6:/etc/wireguard# cat wg0.conf
[Interface]
Address = 192.168.253.5/32,fd00::aaaa:5/128
PrivateKey = eGj5skRAGJu8d………………1PVfu0lY=
# PublicKey = VWe0wBVztgX………………xd7/kZ2CVJlEvS51c=
#Table必须有,不然默认的还是会修改ip rule
Table = 51820
#DNS = 1.1.1.1 #指定DNS服务器
#启动时运行: %i 是指wg的路由, 默认修改default, metric 一般不用指定
PostUp = /sbin/ip -4 route replace default dev %i table default metric 1
PostUp = /sbin/ip -6 route replace default dev %i table default metric 1
#down后运行
PostDown = /sbin/ip -4 route delete default dev %i table default metric 1
PostDown = /sbin/ip -6 route delete default dev %i table default metric 1
PostUp会产生下面的规则
OpenVPN原理通过在main添加all规则来实现
# shaojiemike @ node5 in ~ [22:29:05]
$ ip route show table main
0.0.0.0/1 via 192.168.255.5 dev tun1
Macbook上的应用上的ClashX Pro的增强模式类似, 会添加如下配置,将基本所有流量代理(除开0.0.0.0/8)
> ip route
1.0.0.0/8 via 198.18.0.1 dev utun3
2.0.0.0/7 via 198.18.0.1 dev utun3
4.0.0.0/6 via 198.18.0.1 dev utun3
8.0.0.0/5 via 198.18.0.1 dev utun3
16.0.0.0/4 via 198.18.0.1 dev utun3
32.0.0.0/3 via 198.18.0.1 dev utun3
64.0.0.0/2 via 198.18.0.1 dev utun3
128.0.0.0/1 via 198.18.0.1 dev utun3 #前面接受所有的ip,然后转换成198.18.0.1
198.18.0.1/32 via 198.18.0.1 dev utun3 #接受转换后的198.18.0.1,由于最长前缀匹配
明显有代理死循环问题,如何解决???
shaojiemike@shaojiemikedeMacBook-Air ~/github/hugoMinos (main*) [10:59:32]
> ip route get 198.18.0.42
198.18.0.42 via 198.18.0.1 dev utun3 src 198.18.0.1
shaojiemike@shaojiemikedeMacBook-Air ~/github/hugoMinos (main*) [10:59:38]
> ip route get 198.18.0.1
198.18.0.1 dev utun3 src 198.18.0.1
wireguard-go: 安装客户端 wg-quick up config wireguard-tools: 安装服务端 wg
wg-quick up wg1wg-quick down wg1wg显示全部,或者wg show wg1显示wg1fd00::aaaa:5/128、brainiac1# cat wg-tsj.conf
[Interface]
PrivateKey = xxx
ListenPort = 51828
Address = 10.0.233.7/32, fd00::aaaa:5/128
Table = 51820
#DNS = 1.1.1.1
# 使用iptable修改ipv6的路由规则
PostUp = /sbin/ip -4 route replace default dev %i table default metric 1
PostUp = /sbin/ip -6 route replace default dev %i table default metric 1
PostDown = /sbin/ip -4 route delete default dev %i table default metric 1
PostDown = /sbin/ip -6 route delete default dev %i table default metric 1
[Peer]
#AllowedIPs = 0.0.0.0/0,::/0
PublicKey = xxx
AllowedIPs = 0.0.0.0/1, 128.0.0.0/1
Endpoint = 4.shaojiemike.top:51822
PersistentKeepalive = 30
修改sysctl.conf文件的net.ipv4.ip_forward参数。其值为0,说明禁止进行IP转发;如果是1,则说明IP转发功能已经打开。
需要执行指令sysctl -p 后新的配置才会生效。
注意中间需要NAT转换, 相当于把kunpeng机器的请求,隐藏成snode6的请求。在后一次wireguard转发时,就不会被过滤掉。
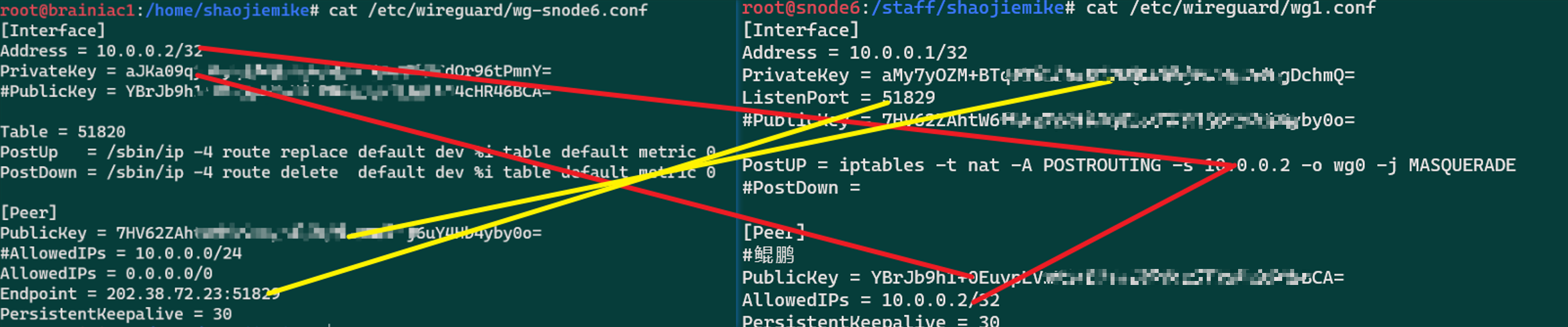
PostUp = iptables -t nat -A POSTROUTING -s 10.1.0.0/24 ! -o %i -j MASQUERADE
PostDown = iptables -t nat -D POSTROUTING -s 10.1.0.0/24 ! -o %i -j MASQUERADE || true
由于换了wg服务端,导致nas变成闭环的网络了。最后是通过群晖助手(Synology Assistant / Web Assistant)的设置静态ip才连接上机器,但是iptable被设置乱了。
静态连接上机器,首先在网页管理页面切换成DHCP(静态ip的DNS解析有误),iptable变成如下
sh-4.4# ip ro
default via 222.195.90.254 dev eth0 src 222.195.90.2
10.0.233.0/24 dev wg1 proto kernel scope link src 10.0.233.3
222.195.90.0/24 dev eth0 proto kernel scope link src 222.195.90.2
sh-4.4# ip ro s t eth0-table
222.195.90.0/24 via 222.195.90.2 dev eth0
注意iptable的修改是实时生效的。
为了让nas上网我们需要满足两点
# 重要项如下
sh-4.4# ip rule
3: from 222.195.90.2 lookup eth0-table (ping 和 ssh ip 222.195.90.2的会使用这个规则)
32766: from all lookup main (ping 和 ssh 其余ip 比如wg的10.0.233.3的会使用这个规则)
# 1. 设置本地ssh eth0的222.195.90.2的高优先级,不至于开启wg断开ssh
# 使用命令添加: ip ro add default via 222.195.90.254 dev eth0 table eth0-table
sh-4.4# ip route show table eth0-table
default via 222.195.90.254 dev eth0
222.195.90.0/24 via 222.195.90.2 dev eth0
# 2. 为了使得除开本地ssh网络走wg,需要删除屏蔽default的wg的DHCP(如果提前删,导致机器ssh连接不上了,重新插拔网线,让DHCP重新配置):
# 使用命令添加:ip ro d default via 222.195.90.254 dev eth0 src 222.195.90.2 table main,
# 3. 防止服务端重启,Nas的wg客户端失联
# 使用命令添加:ip ro a 114.214.233.0/24 via 222.195.90.254 dev eth0 src 222.195.90.2 table main
# 4. 测试: ping域名能正常运行
# 其余方法:为了使得除开本地ssh网络走wg,也可以不删除,在DHCP的前面添加wg的网络通路
# 使用命令添加: ip ro add default dev wg1 proto kernel scope link src 10.0.233.3 table main
sh-4.4# ip r s t main
default dev wg1 proto kernel scope link src 10.0.233.3
使用wg1配置如下:
sh-4.4# cat /etc/wireguard/wg1.conf
[Interface]
PrivateKey = xxx
ListenPort = xxx
Address = 10.0.xxx.xxx/24
Table = 51820
PostUp = /sbin/ip -4 route replace default dev %i table default metric 1
PostDown = /sbin/ip -4 route delete default dev %i table default metric 1
[Peer]
PublicKey = xxx
AllowedIPs = 0.0.0.0/1, 128.0.0.0/1
Endpoint = 114.xxx.xxx.xxx:xxx
PersistentKeepalive = 25
要保留没有wg的时候访问服务端的eth0(114.214.233.xxx)的通路
目的:需要ssh和ping ipv4成功
修改netplan的配置文件
# shaojiemike @ node5 in ~ [22:29:11]
$ cat /etc/netplan/acsa.yaml
network:
version: 2
renderer: networkd
ethernets:
eno0:
dhcp4: false
dhcp6: false
accept-ra: false
addresses:
- 202.38.73.217/24
- 2001:da8:d800:730::217/64
gateway4: 202.38.73.254
gateway6: 2001:da8:d800:730::1
nameservers:
addresses:
- 202.38.64.1
routing-policy:
- from: 202.38.73.217
table: 1
priority: 2
routes:
- to: 0.0.0.0/0
via: 202.38.73.254
table: 1
$netplan apply
routing-policy会产生
# shaojiemike @ node5 in ~ [22:30:33]
$ ip rule
0: from all lookup local
2: from 202.38.73.217 lookup 1
32766: from all lookup main
32767: from all lookup default
# 也可以手动添加
ip rule add from 202.38.73.217 table 1 pref 2
或者
ip rule add from 202.38.73.217 lookup 1 pref 2
由于2优先级高,使得ping和ssh的返回信包(源地址为自身机器IP的包)走table1 规则,而不是走
routes使得所有的table1都会走学校的路由器(202.38.73.254)
$ ip route show table 1
default via 202.38.73.254 dev eno0 proto static
# 也可以通过`ip route add`
$ ip route add default via 202.38.73.254 dev eno0 proto static table 1
开启wg后,网络请求源地址变成了10.0.33.2。不是202.38.73.217
但是外界ping的是202.38.73.217。返回包交换所以会产生源地址为202.38.73.217的包
暂无
暂无
WireGuard 基础教程:使用 Phantun 将 WireGuard 的 UDP 流量伪装成 TCP
/etc/hosts文件即可修改环回的地址。但是十分不建议这样做,很可能导致本地服务崩溃ssh -L 1313:localhost:8020 [email protected]将服务器localhost:1313上的内容转发到本地8020端口hugo server -D -d ~/test/public默认会部署在localhost上hugo server --bind=202.38.72.23 --baseURL=http://202.38.72.23:1313 -D -d ~/test/public暂无
暂无
https://blog.nnwk.net/article/107