Turing Machine & P versus NP problem
导言
在回顾数理逻辑的时候,又想起了NP问题,和NP完全的问题
导言
在回顾数理逻辑的时候,又想起了NP问题,和NP完全的问题
导言
There's a perennial curiosity surrounding the inception of ideas in research. How do researchers stumble upon those brilliant concepts that pave the way for groundbreaking work? The answer lies in a certain logic—a methodology that can be learned and applied to discover remarkable ideas in the realm of research.
导言
The paper on DAMOV's Processing-in-Memory (PIM) architecture organizes its Network-on-Chip (NoC) in a mesh topology, with an alternative Dragonfly topology.
启发来源1
与排除自指的数学体系类型论
(即使排除了自指,还是不完备的)
数理逻辑的奥秘在于,它试图将人类主观的推理思维过程客观化,并建立起主观推理与客观证明之间的联系。通过对形式语言的公理化来达到自然语言的公理化目标。
存在一个数 = 存在最小的在抽象代数里,代数结构(algebraic structure)是指装备了一个及以上的运算(最一般地,可以允许有无穷多个运算)的非空集合。一般研究的代数结构有群、环、域、格、模、域代数和向量空间等等。在数学中,更具体地说,在抽象代数中,代数结构是一个集合(称为载体集或底层集合),它在它上定义了一个或多个满足公理的有限运算。
例子: 整数集合与加法形成一个群,因为整数的加法满足上述条件。
环:
例子: 整数集合与加法和乘法形成一个环,因为整数的加法和乘法满足上述条件。
域:
简而言之,这些结构是数学中用来研究运算规则和性质的工具。在计算机学习中,这些抽象概念可以用来建模和解决各种问题,例如在优化算法、密码学、图形学等领域。如果有具体的问题或关注的方面,请告诉我,我将尽力提供更详细的解释。
暂无
暂无
秋招,百度的高铁柱面试官说,定义问题是很关键的一件事。能不能形式化的定义。(我已经很久没有注意这件事了,确实很重要。
二项分布(Binomial Distribution)是概率论中常见的离散概率分布,用于描述在n重伯努利实验中成功事件发生的次数。
n重伯努利实验是指进行了n次独立重复的伯努利试验。伯努利试验是一种只有两个可能结果的随机试验,通常称为成功(S)和失败(F)。每次试验成功的概率为p,失败的概率为1-p。特点是每次试验只有两种可能的结果,通常表示为成功和失败。
在二项分布中,我们关注的是在n次独立重复试验中成功事件发生的次数(记为X),其中每次试验成功的概率为p。二项分布的概率质量函数可以表示为:
P(X = k)表示在n次试验中成功事件发生k次的概率。
泊松分布(Poisson Distribution)是一种离散概率分布,用于描述在一段固定时间或空间内随机事件发生的次数。它的特点是事件发生的次数是离散的且无限可数,且事件发生的概率在整个时间或空间内是恒定的。
在泊松分布中,我们关注的是在给定的时间或空间内,事件发生的次数(记为X)。泊松分布的概率质量函数可以表示为:
其中,P(X = k)表示在给定时间或空间内事件发生k次的概率。λ是事件发生的平均次数,即单位时间或空间内事件发生的平均频率。e是自然对数的底数,k!表示k的阶乘。
泊松分布常用于描述稀有事件的发生情况,例如单位时间内电话呼叫次数、单位面积内放射性粒子的撞击次数等。通过泊松分布,我们可以计算在给定平均发生率下,事件发生特定次数的概率,从而进行概率推断和预测。
超几何分布(Hypergeometric Distribution)是一种离散概率分布,用于描述从有限总体中进行抽样时,抽取的样本中具有某种特征的个数的分布。它与二项分布相似,但有一些关键区别。
在超几何分布中,我们考虑从总体中抽取固定大小的样本,总体中有M个具有某种特征的元素和N-M个没有该特征的元素。我们关注的是在抽样过程中,样本中具有该特征的元素的个数(记为X)。
超几何分布的概率质量函数可以表示为:
其中,P(X = k)表示样本中具有该特征的元素个数为k的概率。C(M, k)表示在M个具有该特征的元素中选择k个元素的组合数,C(N-M, n-k)表示在N-M个没有该特征的元素中选择n-k个元素的组合数,C(N, n)表示在总体中选择n个元素的组合数。
超几何分布常用于从有限总体中进行抽样,并研究样本中某种特征的出现情况。它的特点是,随着抽样数量的增加,成功事件的概率不再是恒定的,因为每次抽样都会影响总体中元素的可选性。通过超几何分布,我们可以计算在给定总体和抽样大小的情况下,样本中具有该特征的元素个数的概率分布。
几何分布描述的是在独立重复试验中,第一次成功事件A发生所需的试验次数。每次试验都有成功(S)和失败(F)两种可能结果,且成功概率为p。几何分布的概率质量函数可以表示为:
其中,P(X = k)表示第一次成功事件发生在第k次试验的概率。
负二项分布描述的是在独立重复试验中,成功事件发生r次所需的试验次数。每次试验都有成功(S)和失败(F)两种可能结果,且成功概率为p。负二项分布的概率质量函数可以表示为:
其中,P(X = k)表示成功事件发生r次在第k次试验的概率。C(k-1, r-1)表示组合数,表示在前k-1次试验中取r-1次成功的组合数。
常用密度函数表示
正态分布,也称为高斯分布(Gaussian Distribution),是统计学中最重要且广泛应用的连续概率分布之一。
正态分布的概率密度函数(Probability Density Function, PDF)可以用以下公式表示:
其中,f(x)表示随机变量X的概率密度函数。μ表示分布的均值(期望值),σ表示标准差,π表示圆周率,exp表示自然对数的指数函数。
正态分布具有以下特点:
均匀分布(Uniform Distribution)是一种简单而常见的概率分布,它在指定的区间内的取值具有相等的概率。在均匀分布中,每个可能的取值都具有相同的概率密度。
均匀分布的概率密度函数(Probability Density Function, PDF)可以用以下公式表示:
f(x) = 1 / (b - a),如果 a ≤ x ≤ b
f(x) = 0,其他情况
其中,f(x)表示随机变量X的概率密度函数。a和b分别表示分布的下限和上限。
指数分布(Exponential Distribution)是一种连续概率分布,常用于描述事件发生的时间间隔。它是一种特殊的连续随机变量的分布,具有单峰、右偏的特点。
指数分布的概率密度函数(Probability Density Function, PDF)可以用以下公式表示:
f(x) = λ * exp(-λx),如果 x ≥ 0
f(x) = 0,其他情况
其中,f(x)表示随机变量X的概率密度函数,λ是分布的参数,被称为率参数。
指数分布具有以下特点:
指数分布在实际应用中具有广泛的应用。例如,它常用于描述随机事件的到达时间、服务时间、寿命等。在可靠性工程和排队论中,指数分布经常用于模拟和分析各种事件的发生和持续时间。
伽马分布(Gamma Distribution)是一种连续概率分布,它常用于描述正数随机变量的分布,如事件的等待时间、寿命等。伽马分布是指数分布的推广形式,它可以具有更灵活的形状。
伽马分布的概率密度函数(Probability Density Function, PDF)可以用以下公式表示:
$$ f(x) = (1 / (Γ(k) * θ^k)) * x^{k-1} * exp(-x/θ)$$,如果 x ≥ 0 0,其他情况
其中,f(x)表示随机变量X的概率密度函数,k和θ是分布的参数,k被称为形状参数,θ被称为尺度参数,Γ(k)表示伽马函数(Gamma function)。
伽马分布具有以下特点:
伽马分布在实际应用中具有广泛的应用。例如,在可靠性工程中,它常用于描述零部件的寿命和故障时间。在金融领域,伽马分布被用于模拟和分析资产价格的变动。
贝塔分布(Beta Distribution)是一种连续概率分布,它定义在区间[0, 1]上,并且常用于描述概率分布、比例、概率参数等随机变量的分布。
贝塔分布的概率密度函数(Probability Density Function, PDF)可以用以下公式表示:
$\(f(x) = (x^{α-1} * (1-x)^{β-1}) / B(α, β)\)$,如果 0 ≤ x ≤ 1 0,其他情况
其中,f(x)表示随机变量X的概率密度函数,α和β是分布的两个形状参数,B(α, β)表示贝塔函数(Beta function)。
贝塔分布具有以下特点:
贝塔分布在实际应用中具有广泛的应用。它常被用于贝叶斯统计推断、可靠性分析、A/B测试、市场份额预测等领域。此外,贝塔分布还与其他概率分布有着密切的关联,例如伯努利分布、二项分布和贝叶斯推断中的共轭先验分布等。
泊松过程(Poisson Process)是一种随机过程,用于描述在固定时间间隔内随机事件发生的模式。泊松过程的关键特征是事件在时间上的独立性和固定的平均发生率。它可以用于建模各种事件的发生,例如电话呼叫到达、事故发生、信号传输等。
当一个随机过程其未来状态的条件概率分布仅依赖于当前状态;换句话说,在给定现在状态时,它与过去状态(即该过程的历史路径)是条件独立的,那么此随机过程即具有马尔可夫性质。
马尔可夫链(Markov Chain, MC)是概率论和数理统计中具有马尔可夫性质(Markov property)且存在于离散的指数集(index set)和状态空间(state space)内的随机过程(stochastic process)
适用于连续指数集的马尔可夫链被称为马尔可夫过程(Markov process)
马尔可夫决策过程(Markov Decision Process, MDP)是序贯决策(sequential decision)的数学模型,用于在系统状态具有马尔可夫性质的环境中模拟智能体可实现的随机性策略与回报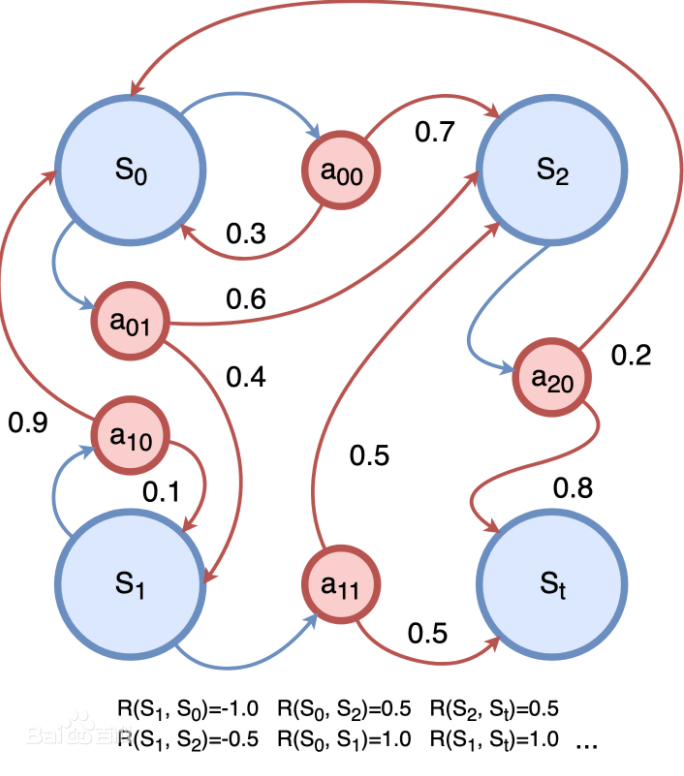
平稳过程(Stationary Process)是一种随机过程,其统计特性在时间上保持不变。具体而言,一个平稳过程在不同时间段内具有相同的概率分布和统计特性,如均值、方差和自协方差。
布朗运动(Brownian Motion),也被称为维纳过程(Wiener Process),是一种随机过程,以英国生物学家罗伯特·布朗(Robert Brown)的名字命名。布朗运动是一种连续时间、连续空间的随机运动,它在各个时间点上的位置是随机的。
布朗运动的特点包括:
布朗运动在物理学、金融学、生物学等领域具有广泛的应用。它可以用来描述微粒在流体中的扩散、金融市场中的价格变动、细胞内分子的运动等随机现象。布朗运动的数学描述采用随机微分方程,其中包括随机增量项,用来表示随机性和不确定性。
鞅过程(Martingale Process)是一种随机过程,它在概率论和数学金融领域中具有重要的应用。鞅过程是一种随机变量序列,它满足一定的条件,其中最重要的性质是条件期望的无偏性。
具体而言,设{X(t), t ≥ 0}是一个随机过程,定义在一个概率空间上,关于时间t的随机变量。如果对于任意的s ≤ t,条件期望E[X(t) | X(s)]等于X(s),即 E[X(t) | X(s)] = X(s),那么这个随机过程被称为鞅过程。
换句话说,鞅过程在任意时刻的当前值的条件期望等于过去时刻的值,表明鞅过程在平均意义上不随时间变化而漂移。
一个典型的实际案例是赌博游戏中的赌徒之行。
假设有一个赌徒在每轮游戏中抛掷硬币,正面朝上赢得1单位的奖励,反面朝上输掉1单位的赌注。我们可以用一个鞅过程来描述赌徒的资金变化。假设赌徒的初始资金为0单位,并且在每轮游戏中抛硬币的结果是一个独立的随机事件。赌徒的资金变化可以表示为一个鞅过程{X(t), t ≥ 0},其中X(t)表示赌徒在时间t时的资金。
在这个例子中,条件期望的无偏性意味着在任意时刻t,赌徒的当前资金的条件期望等于过去时刻的资金,即 E[X(t) | X(s)] = X(s),其中s ≤ t。
这意味着赌徒在每轮游戏中没有系统性地赢或输。无论他之前的赢利或亏损情况如何,当前的资金预期值等于他之前的资金。
鞅过程在金融市场建模、随机控制理论、概率论等领域有广泛的应用。它在金融中可以用来描述资产价格的动态演化、期权定价、风险度量等。在概率论中,鞅过程是一类重要的随机过程,其具有丰富的性质和数学结构,被广泛研究和应用。
大数定理(Law of Large Numbers)是概率论中的一条重要定理,描述了随机变量序列的均值的收敛性质。它指出,当随机变量的样本容量足够大时,样本均值将接近于随机变量的期望值。
中心极限定理(Central Limit Theorem)是概率论和统计学中的重要结果之一。它描述了在一定条件下,当独立随机变量的数量足够大时,它们的平均值的分布将近似于正态分布。
中心极限定理的主要内容如下:
假设有n个独立随机变量X1, X2, ..., Xn,它们具有相同的分布和参数。这些随机变量的和S_n = X1 + X2 + ... + Xn的分布在n趋近于无穷大时,以及适当的标准化后,将近似于正态分布。
具体而言,当n足够大时,S_n的近似分布可以用正态分布来描述。
在参数估计中,确实需要事先假设或确定一个概率分布模型(注意不是确定的模型,不然可以根据结果直接算出参数)。参数估计的前提是我们假设观测数据来自于某个特定的概率分布,而我们的目标是估计这个概率分布中的未知参数。
具体来说,参数估计的过程通常包括以下步骤:
需要注意的是,参数估计的准确性和可靠性依赖于所假设的概率分布模型的正确性和数据的充分性。如果所假设的概率分布模型与实际情况不符,或者观测数据过少或存在较大的噪声,估计结果可能会出现偏差或不准确的情况。
因此,在参数估计之前,我们需要对问题进行合理的假设和模型选择,并在数据收集和估计方法的过程中考虑到模型假设的合理性和数据的质量。
贝叶斯定理是概率论中的一个基本定理,描述了在观测到新的证据(观测数据)后,如何更新对某个事件的概率估计。
假设有两个事件 A 和 B,其中事件 A 是我们要推断或估计的事件,而事件 B 是观测到的证据。贝叶斯定理表述如下:
P(A|B) = (P(B|A) * P(A)) / P(B)
其中:
P(A|B) 是在观测到事件 B 后事件 A 发生的条件概率,也称为后验概率。P(B|A) 是在事件 A 发生的条件下观测到事件 B 的概率,也称为似然函数。P(A) 是事件 A 的先验概率,即在观测到事件 B 之前对事件 A 发生的估计。P(B) 是事件 B 的边际概率,即观测到事件 B 的概率。贝叶斯定理的核心思想是通过观测到的证据(事件 B),更新对事件 A 的概率估计。它将先验概率和似然函数结合起来,得到后验概率。具体而言,贝叶斯定理可以用于根据已知信息更新模型参数、进行推断、进行分类等。
贝叶斯定理在贝叶斯统计学中具有重要的应用,它允许我们利用已有知识(先验)和新的证据(似然函数)来更新对未知事件的估计(后验)。通过不断地更新先验概率,我们可以根据新的观测数据获得更准确和可靠的后验概率估计。
在贝叶斯统计中,先验分布和后验概率分布是两个关键概念,用于描述我们对参数的初始信念和通过观测数据更新后的信念。
先验分布和后验概率分布之间的关系可以用贝叶斯定理来表示:
后验概率分布 ∝ 先验分布 × 似然函数
其中,似然函数描述了观测数据出现的可能性。通过将先验分布与观测数据的似然函数相乘,并进行适当的归一化,可以得到后验概率分布。
贝叶斯统计的核心思想是通过不断地更新先验分布,利用观测数据提供的信息,得到后验概率分布,并在此基础上做出推断和决策。先验分布提供了先验知识和信念,而后验概率分布则是在考虑观测数据后对参数的更新和修正。
点估计(Point Estimation)是参数估计的一种方法,它通过使用样本数据来估计总体参数的具体值。点估计的目标是找到一个单一的估计值,作为对未知参数的最佳猜测。
无偏性是点估计的性质之一。一个无偏估计是指在重复抽样的情况下,估计值的期望等于被估计参数的真实值。换句话说,如果一个估计值的期望与真实参数值相等,则该估计值是无偏的。
最大似然估计的基本思想是,在给定观测数据的情况下,寻找使得观测数据的联合概率密度函数(或概率质量函数)最大化的参数值。具体步骤包括以下几个步骤:
最大似然估计具有一些良好的性质,例如在大样本下,最大似然估计的估计值具有渐近正态分布,且具有一致性和渐进有效性等特性。最大似然估计在统计学和机器学习等领域中广泛应用,用于估计参数、构建模型和进行推断。
EM算法的基本思想是通过引入隐变量,将含有缺失数据的问题转化为完全数据的问题。具体步骤如下:
EM算法通过迭代的方式逐步优化参数的估计值,使得在每次迭代中似然函数都得到增大,从而逐渐逼近最优参数值。由于每次迭代中的E步和M步都可以分别求解,因此EM算法在理论上保证了在每一步都能得到似然函数的增加。然而,EM算法并不能保证收敛到全局最优解,可能陷入局部最优解。
EM算法在许多统计学和机器学习问题中都有广泛的应用,特别是在存在隐变量的概率模型、混合模型、高斯混合模型等领域中。它为解决这些问题提供了一种有效的参数估计方法。
频率学派和贝叶斯学派是统计学中两种不同的观点或方法论。
频率学派(Frequentist Approach)注重使用频率或概率的概念进行推断和估计。在频率学派中,参数被视为固定但未知的,通过基于样本数据的统计量来推断参数的值。频率学派强调利用大量的重复抽样来研究统计性质,并通过估计量的偏差、方差和置信区间等指标来评估估计的准确性和可靠性。
贝叶斯学派(Bayesian Approach)则采用贝叶斯定理和概率论的观点来进行推断和估计。在贝叶斯学派中,参数被视为随机变量,其先验分布和样本数据的条件下的后验分布共同决定了参数的估计。贝叶斯学派注重将先验知识或信念结合到推断过程中,并使用后验分布来提供关于参数的概率分布以及置信区间等信息。
贝叶斯估计是贝叶斯学派中一种参数估计的方法。它利用贝叶斯定理计算参数的后验分布,并将后验分布作为参数的估计。贝叶斯估计不仅考虑了样本数据的信息,还结合了先验知识或信念,因此可以提供更全面和灵活的估计结果。贝叶斯估计还可以通过调整先验分布的参数或选择不同的先验分布来灵活地处理不同的问题和背景。
需要注意的是,频率学派和贝叶斯学派并不是相互排斥的,它们是统计学中不同的方法论和观点,各自有其适用的领域和优势。在实际应用中,可以根据问题的特点、数据的性质以及研究目的来选择适合的学派和方法。
区间估计是统计学中一种参数估计的方法,用于估计未知参数的范围或区间。与点估计不同,区间估计提供了一个范围,该范围内有一定的置信度(置信水平)包含了真实参数值。
区间估计的基本思想是通过样本数据来构建一个区间,该区间涵盖了真实参数值的可能范围。在频率学派中,常用的区间估计方法包括置信区间。置信区间是基于样本数据计算出来的一个区间,其具体形式为"估计值 ± 误差",其中误差由抽样误差和估计误差组成。
置信区间的置信水平表示该区间在重复抽样中包含真实参数值的概率。例如,95%的置信水平意味着在多次重复抽样中,有95%的置信区间会包含真实参数值。
区间估计的优势在于提供了对未知参数范围的估计,并提供了对估计结果的不确定性的量化。它能够更全面地反映估计的可靠性,并且可以与其他区间进行比较,进行统计推断和假设检验等。
需要注意的是,区间估计并不提供关于真实参数值的具体点估计,而是提供了一个范围。不同的置信水平会得到不同宽度的区间,较高的置信水平通常会导致较宽的区间。在应用中,选择适当的置信水平需要权衡估计的准确性和置信区间的宽度。
暂无
暂无
无