AI Infra: 10k-GPU cluster
导言
- 为什么需要万卡集群
- 万卡集群的使用难点
- 应对方案
导言
导言
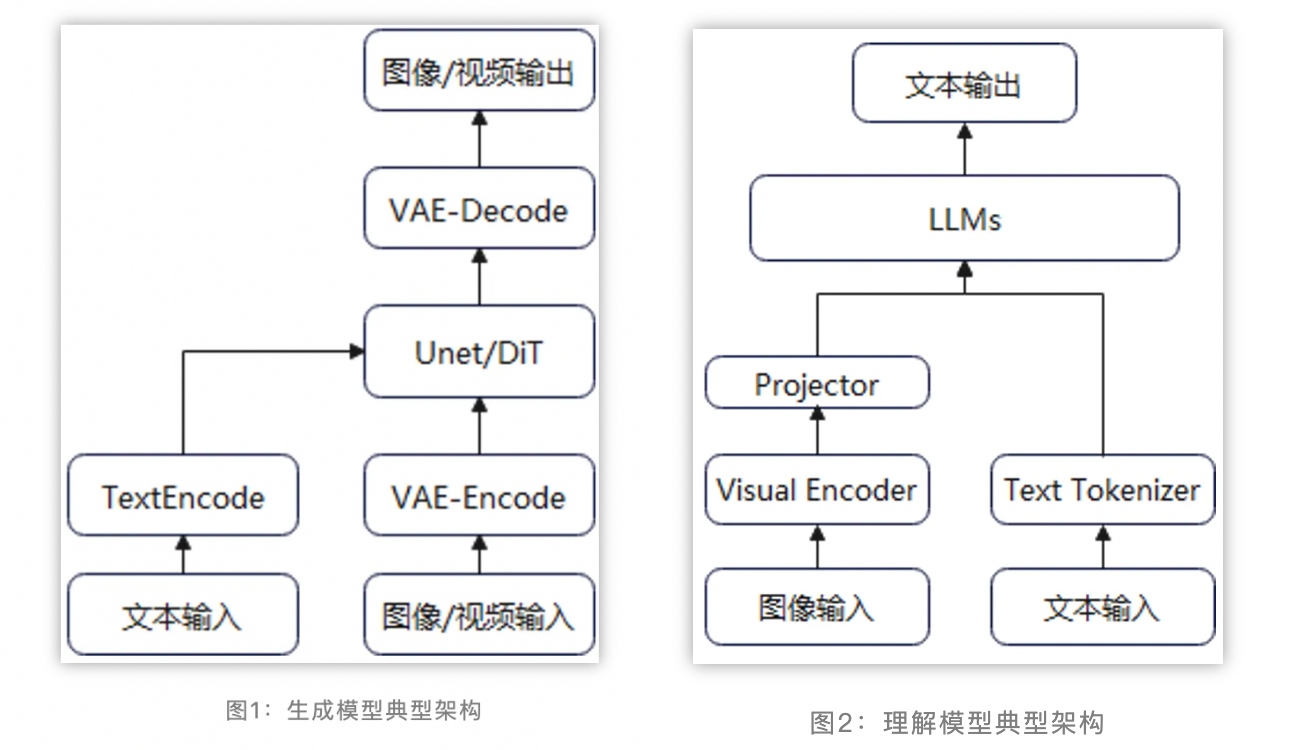
当前主流的多模态生成模型(如图像生成text2image和视频生成text2video)主要采用Latent Stable Diffusion的方案框架。为了减少计算量,图像/视频等模态的数据(噪声)先经过VAE压缩得到Latent Vector,然后在文本信息的指导下进行去噪,最后生成符合预期的图像或视频。
排行榜: (T2I, ImageEdit, T2V, I2V, )
当前主流的多模态生成模型(如图像生成和视频生成)主要采用Latent Stable Diffusion的方案框架。为了减少计算量,图像/视频等模态的数据(噪声)先经过VAE压缩得到Latent Vector,然后在文本信息的指导下进行去噪,最后生成符合预期的图像或视频。
导言
明白设计(数据构造,模型设计, 训练流程)的有效性,是抓住问题核心的关键。有助于在众多的AI论文里筛选出有效结论。
通过这些宝贵的信息,才能渐渐知道能被时间检验过的经验是什么。
本文将聚焦于归档 有效性相关的工作。
导言
导言
和AIGC 生图相关
导言
RL 涉及到 推理,推理的流程细节不是很明晰。
导言
训练由于要计算并更新梯度,一般是计算密集。但是推理一般是访存密集。
导言
训练由于要计算并更新梯度,一般是计算密集。但是推理一般是访存密集。
导言
本来在多模态组,结果被拉去优化TX的dspv3部署,还是要熟悉相关概念逻辑。