AMD Architecture on EPYC
ROMA SOC架构
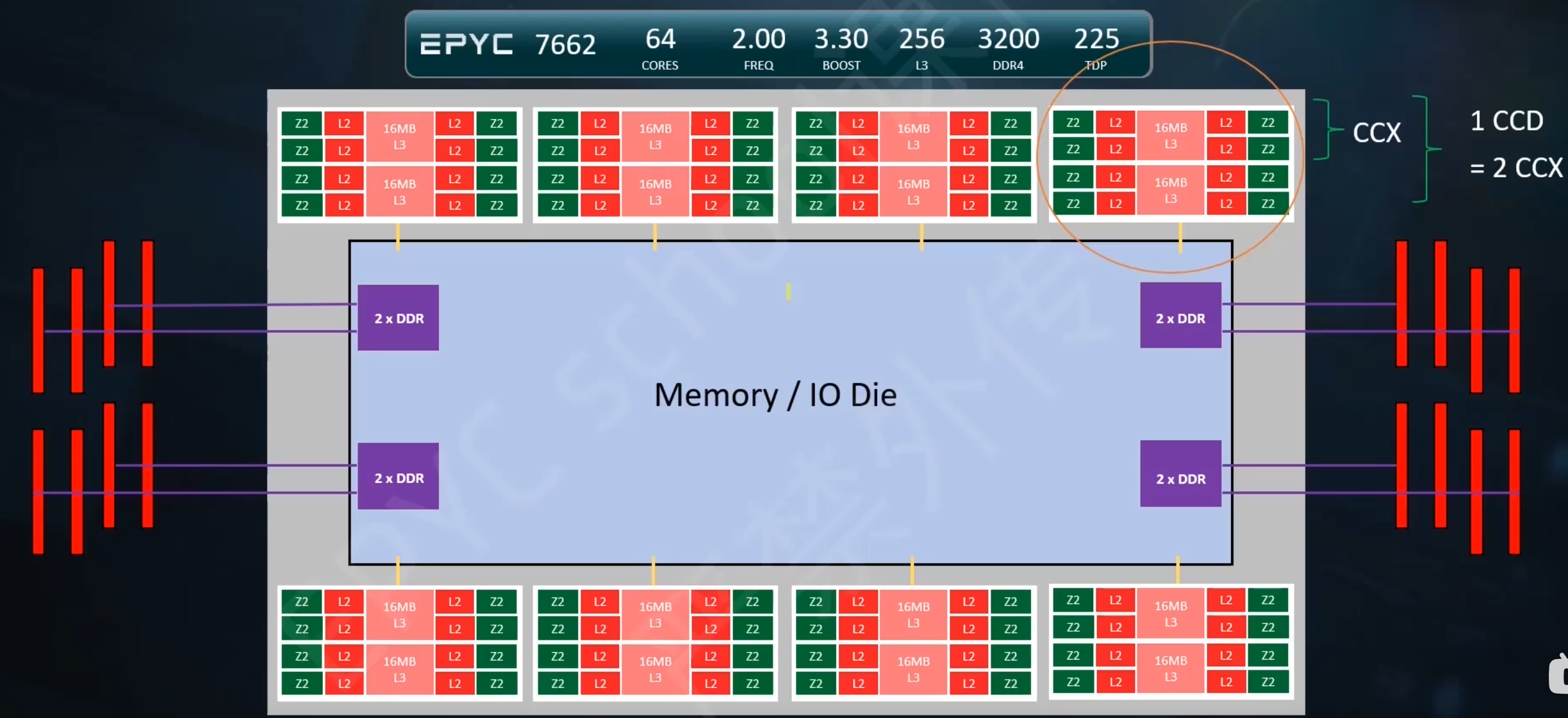
基本概念
CCD CCX
ROMA与MILAN架构比较
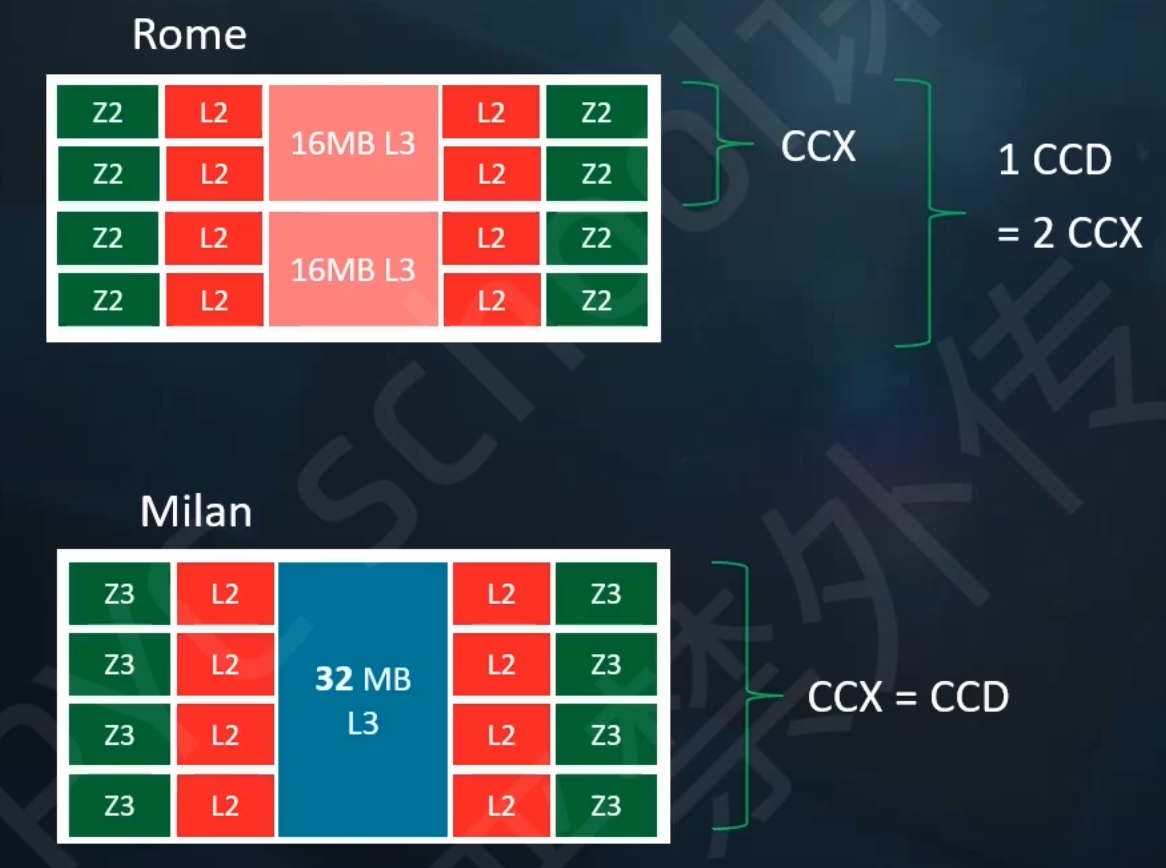
Roma使用Zen2核心,MILan使用Zen3核心。而且后者缓存更大,核心通信延迟更低。
计算CCD和CCX
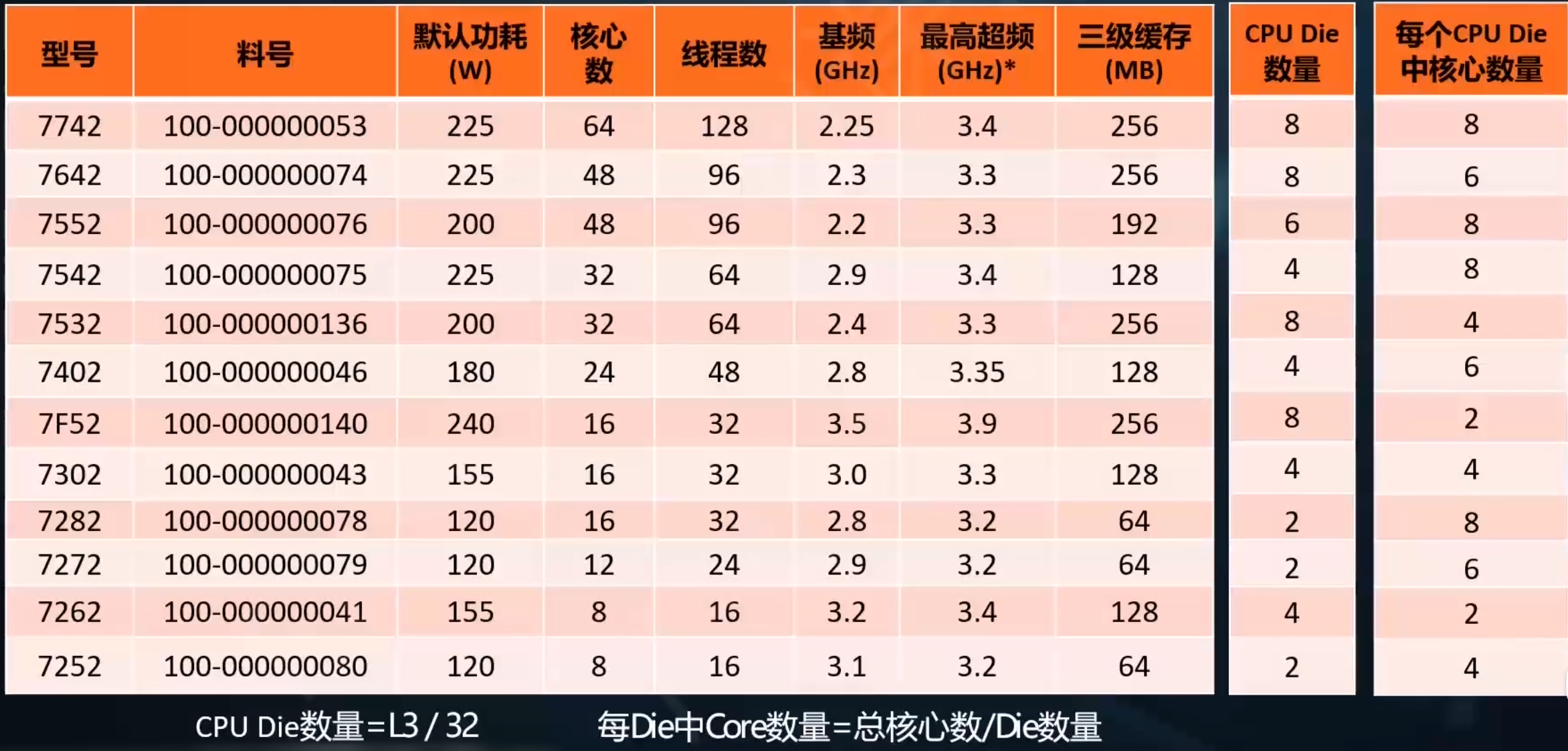
需要进一步的研究学习
暂无
遇到的问题
暂无
开题缘由、总结、反思、吐槽~~
参考文献
无
CCD CCX
Roma使用Zen2核心,MILan使用Zen3核心。而且后者缓存更大,核心通信延迟更低。
暂无
暂无
无
https://community.arm.com/arm-community-blogs/b/operating-systems-blog/posts/arm-neon-programming-quick-reference
暂无
暂无
https://blog.csdn.net/heliangbin87/article/details/79581113?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1.no_search_link&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1.no_search_link
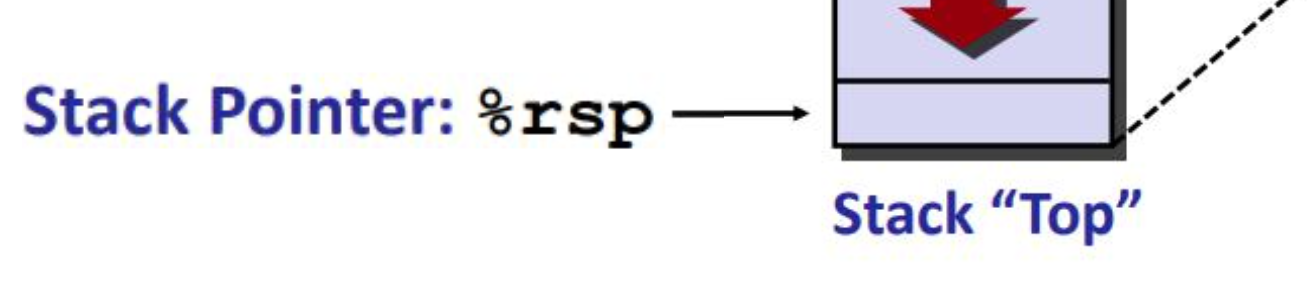
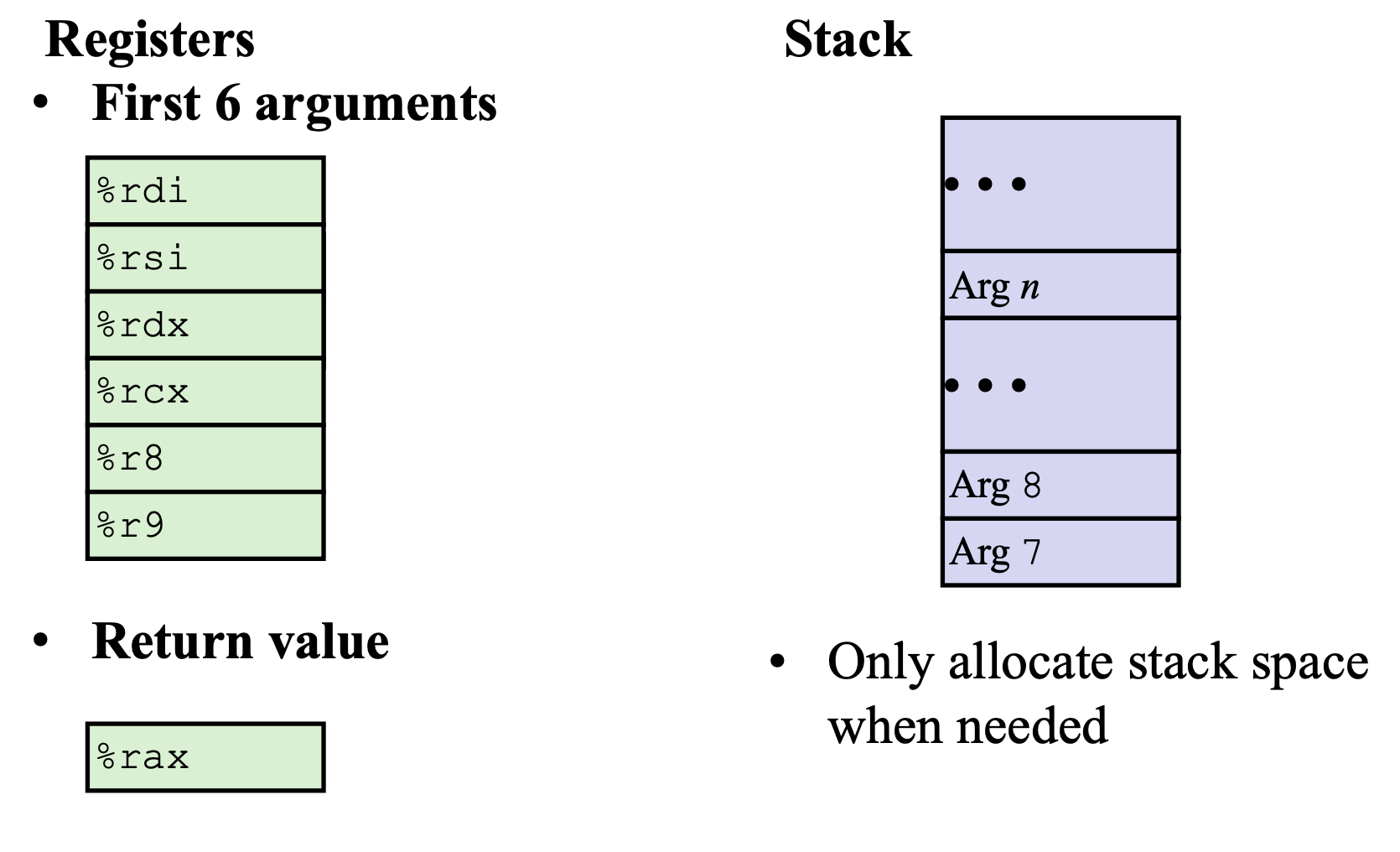
caller 调用者 callee 被调用者
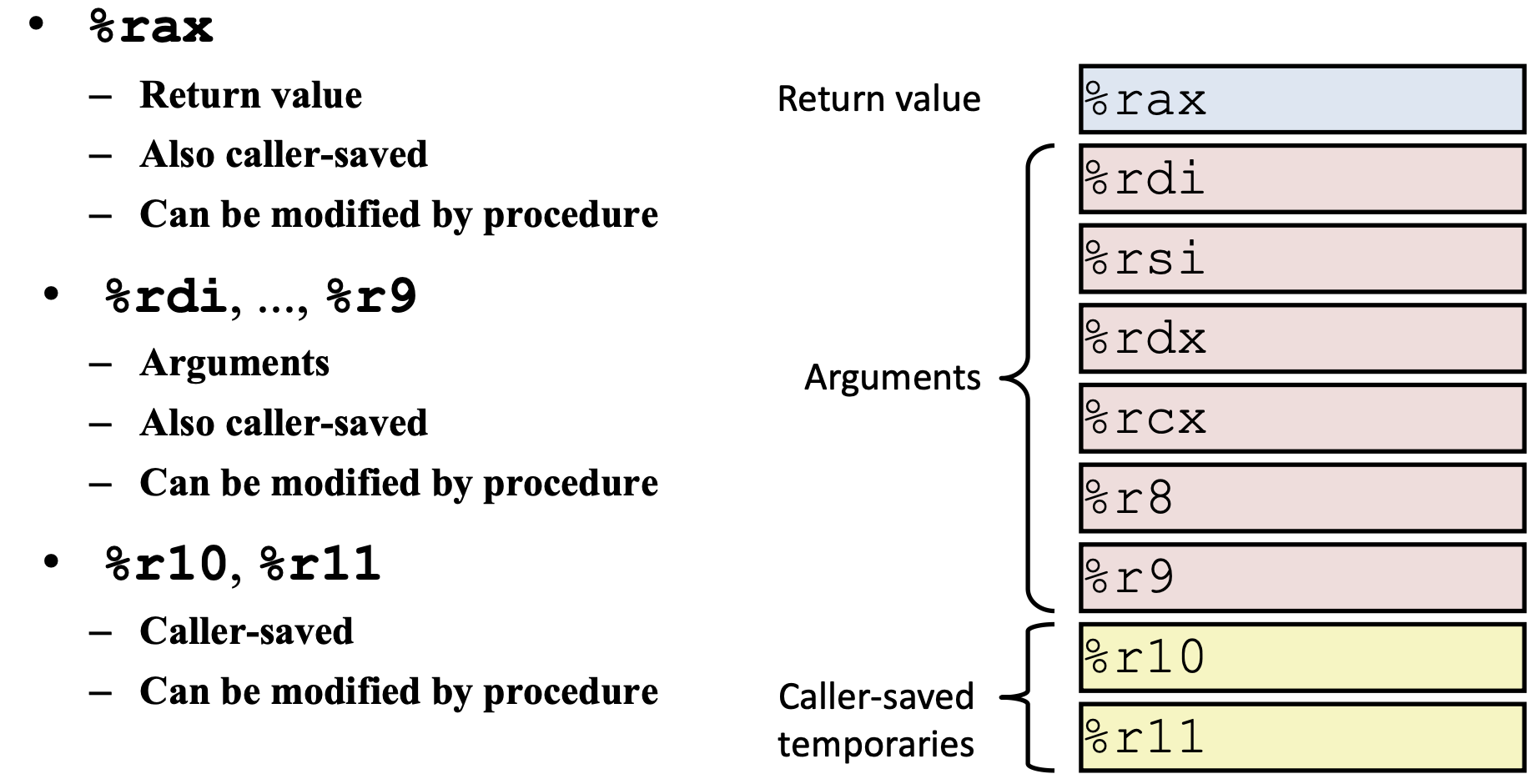
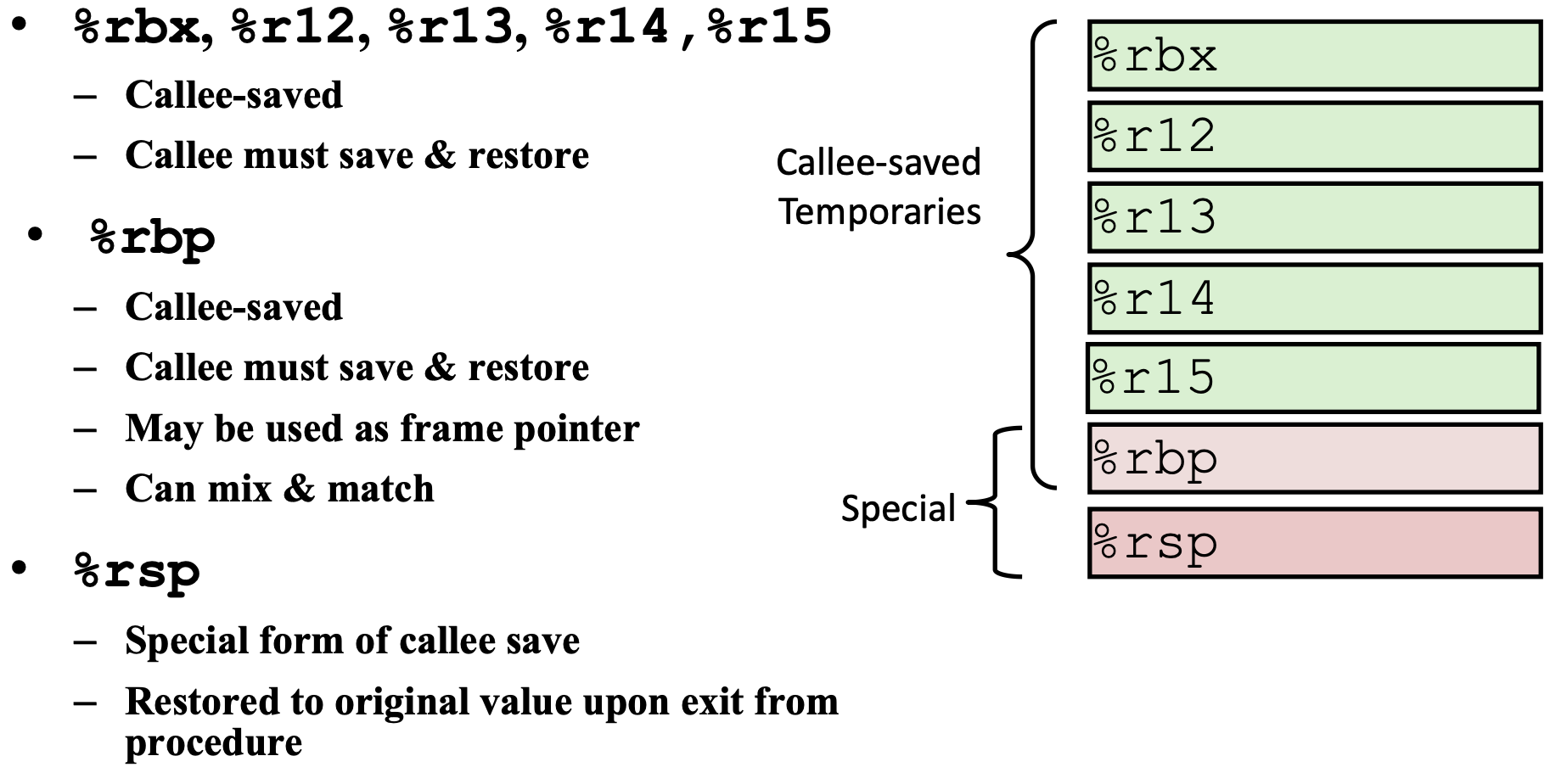
https://bkfish.github.io/2018/12/21/CSAPP又双叒叕来一遍之函数调用过程栈帧的变化/

暂无
暂无
无
SIMD全称Single Instruction Multiple Data,单指令多数据流,能够复制多个操作数,并把它们打包在大型寄存器的一组指令集。
通过使用矢量寄存器,指令译码后几个执行部件同时访问内存,一次性获得所有操作数进行运算。这个特点使SIMD特别适合于多媒体应用等数据密集型运算。如 AMD的3D NOW!技术
MMX是由57条指令组成的SIMD多媒体指令集,MMX将64位寄存当作2个32位或8个8位寄存器来用,只能处理整形计算,这样的64位寄存器有8组,分别命名为MM0~MM7.这些寄存器不是为MMX单独设置的,而是借用的FPU的寄存器,占用浮点寄存器进行运算(64位MMX寄存器实际上就是浮点数寄存器的别名),以至于MMX指令和浮点数操作不能同时工作。为了减少在MMX和浮点数模式切换之间所消耗的时间,程序员们尽可能减少模式切换的次数,也就是说,这两种操作在应用上是互斥的。
SSE为Streaming SIMD Extensions的缩写。Intel SSE指令通过128bit位宽的专用寄存器, 支持一次操作128bit数据. float是单精度浮点数, 占32bit, 那么可以使用一条SSE指令一次计算4个float数。注意这些SSE指令要求参数中的内存地址必须对齐于16字节边界。
SSE有8个128位寄存器,XMM0 ~XMM7。此外SSE还提供了新的控制/状态寄存器MXCSR。为了回答这个问题,我们需要了解CPU的架构。每个core是独占register的

addps xmm0, xmm1 ; reg-reg addps xmm0, [ebx] ; reg-mem sse提供了两个版本的指令,其一以后缀ps结尾,这组指令对打包单精度浮点值执行类似mmx操作运算,而第二种后缀ss
 1. SSE2则进一步支持双精度浮点数,由于寄存器长度没有变长,所以只能支持2个双精度浮点计算或是4个单精度浮点计算.另外,它在这组寄存器上实现了整型计算,从而代替了MMX.
2. SSE3支持一些更加复杂的算术计算.
3. SSE4增加了更多指令,并且在数据搬移上下了一番工夫,支持不对齐的数据搬移,增加了super shuffle引擎.
4. 由于2007年8月,AMD抢先宣布了SSE5指令集。之后Intel将新出的叫做AVX指令集。由于SSE5和AVX指令集功能类似,并且AVX包含更多的优秀特性,因此AMD决定支持AVX指令集
1. SSE2则进一步支持双精度浮点数,由于寄存器长度没有变长,所以只能支持2个双精度浮点计算或是4个单精度浮点计算.另外,它在这组寄存器上实现了整型计算,从而代替了MMX.
2. SSE3支持一些更加复杂的算术计算.
3. SSE4增加了更多指令,并且在数据搬移上下了一番工夫,支持不对齐的数据搬移,增加了super shuffle引擎.
4. 由于2007年8月,AMD抢先宣布了SSE5指令集。之后Intel将新出的叫做AVX指令集。由于SSE5和AVX指令集功能类似,并且AVX包含更多的优秀特性,因此AMD决定支持AVX指令集
Advanced Vector Extensions。较新的Intel CPU都支持AVX指令集, 它可以一次操作256bit数据, 是SSE的2倍,可以使用一条AVX指令一次计算8个float数。AVX指令要求内存地址对齐于32字节边界。


根据参考文章,其中用gcc编译AVX版代码时需要加-mavx选项.
 开启-O3选项,一般不用将代码改成多次计算和内存对齐。
开启-O3选项,一般不用将代码改成多次计算和内存对齐。
gcc -march=native -c -Q --help=target # 查看支持的指令集
g++ -O2 -ftree-vectorize -ftree-vectorizer-verbose=9 -S -c foo.cpp -o /dev/stdout | c++filt # 查看汇编
OBJDUMP # 反汇编
-Rpass=loop-vectorize
identifies loops that were successfully vectorized.
-Rpass-missed=loop-vectorize
identifies loops that failed vectorization and indicates if vectorization was specified.
-Rpass-analysis=loop-vectorize
identifies the statements that caused vectorization to fail.

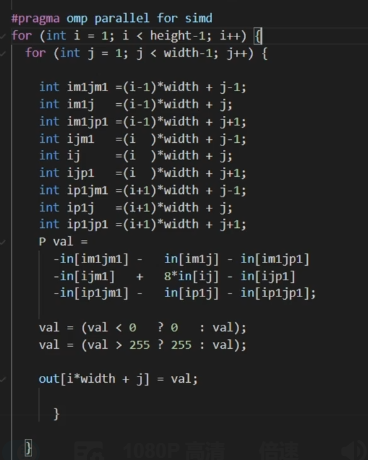 循环展开8次
循环展开8次
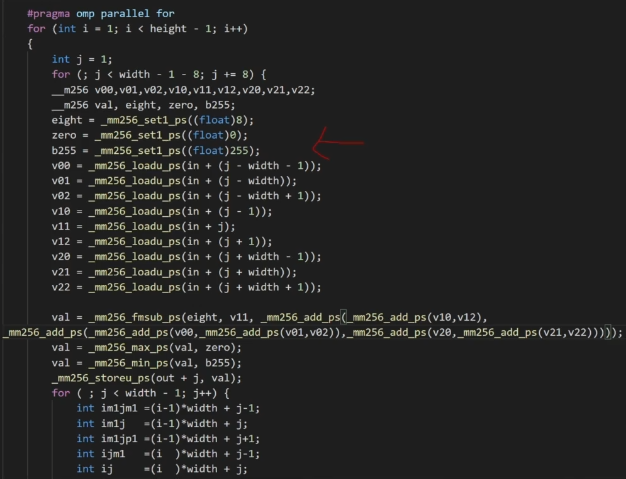
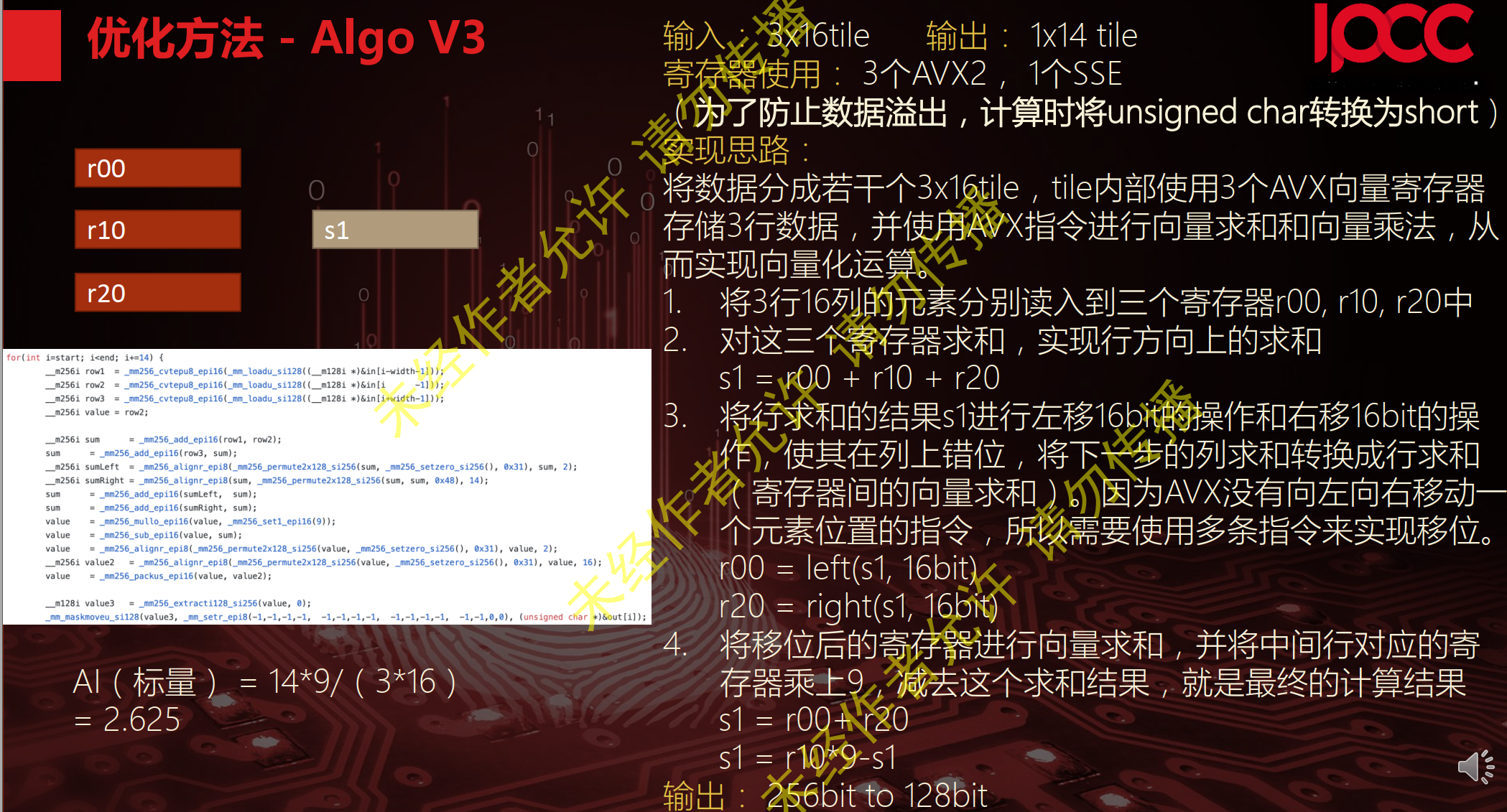
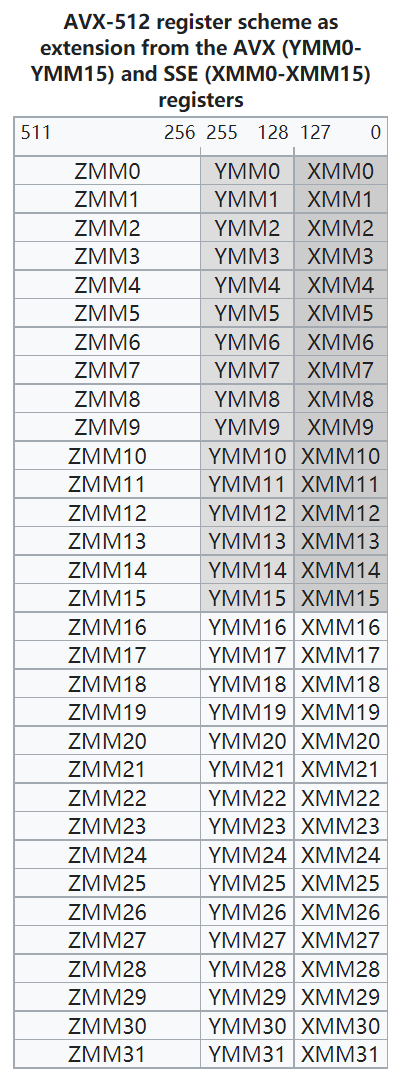
暂无
暂无
https://www.dazhuanlan.com/2020/02/01/5e3475c89d5bd/
https://software.intel.com/sites/landingpage/IntrinsicsGuide/
现代计算机微架构是最复杂的几个人造系统。在上面预测,解释和优化软件是困难的。我们需要其运行行为的可信模型,但是事实是稀缺的。
本文设计和实现了一种构建X86指令的延迟,吞吐量和端口使用的可信模型。并仔细探究了这三个指标的定义。尤其是latency的值在不同的操作数情况时是如何确定的。
同时其结果也是机器可读的。并且对已有的所有Intel架构都进行了测试。
官网有结果 http://www.uops.info
We also plan to release the source code of our tool as open source
balabala~
我们的工具可以用来优化llvm-mca等软件。
Future work includes adapting our algorithms to AMD x86 CPUs. 官网已经实现了。
We would also like to extend our approach tocharacterize other undocumented performance-relevant aspects of the pipeline, e.g., regarding micro and macro-fusion, or whether instructions use the simple decoder, the complex decoder, or the Microcode-ROM.
暂无
暂无
无
动态优化逐渐显现出是一种解决传统静态汇编困难的好方法。 但是市面上有大量的针对开发静态优化的编译器框架,但是少有针对动态优化的。
我们实现了一种动态分析和优化的框架,为DynamoRIO动态代码修改系统提供了一种创建额外模块的交互界面。通过简单轻量的API就可以提炼许多DynamoRIO运行时的底层细节,但是只能在单指令流下,而且不同指令显示的细节也是不同的。
该API不仅可以用来优化,也可以instrumentation,热点分析和动态翻译。
为了展现架构的有效性,我们实现了若干优化,一些例子有40%提升,基于DynamoRIO平均有12%加速。
随着现代软件的复杂,还有动态load,共享库等特性,静态分析越来越衰弱。静态分析器去分析整个程序是困难或者不可能的,而静态优化又受限于静态代码分析器的准确性。而且静态优化过多会导致出错时难以debug。
就是这个动态框架好,使用范围广,前途光明
https://github.com/DynamoRIO/dynamorio/blob/master/api/samples/bbbuf.c
暂无
暂无
无





多线程SMT (Simultaneous multithreading)
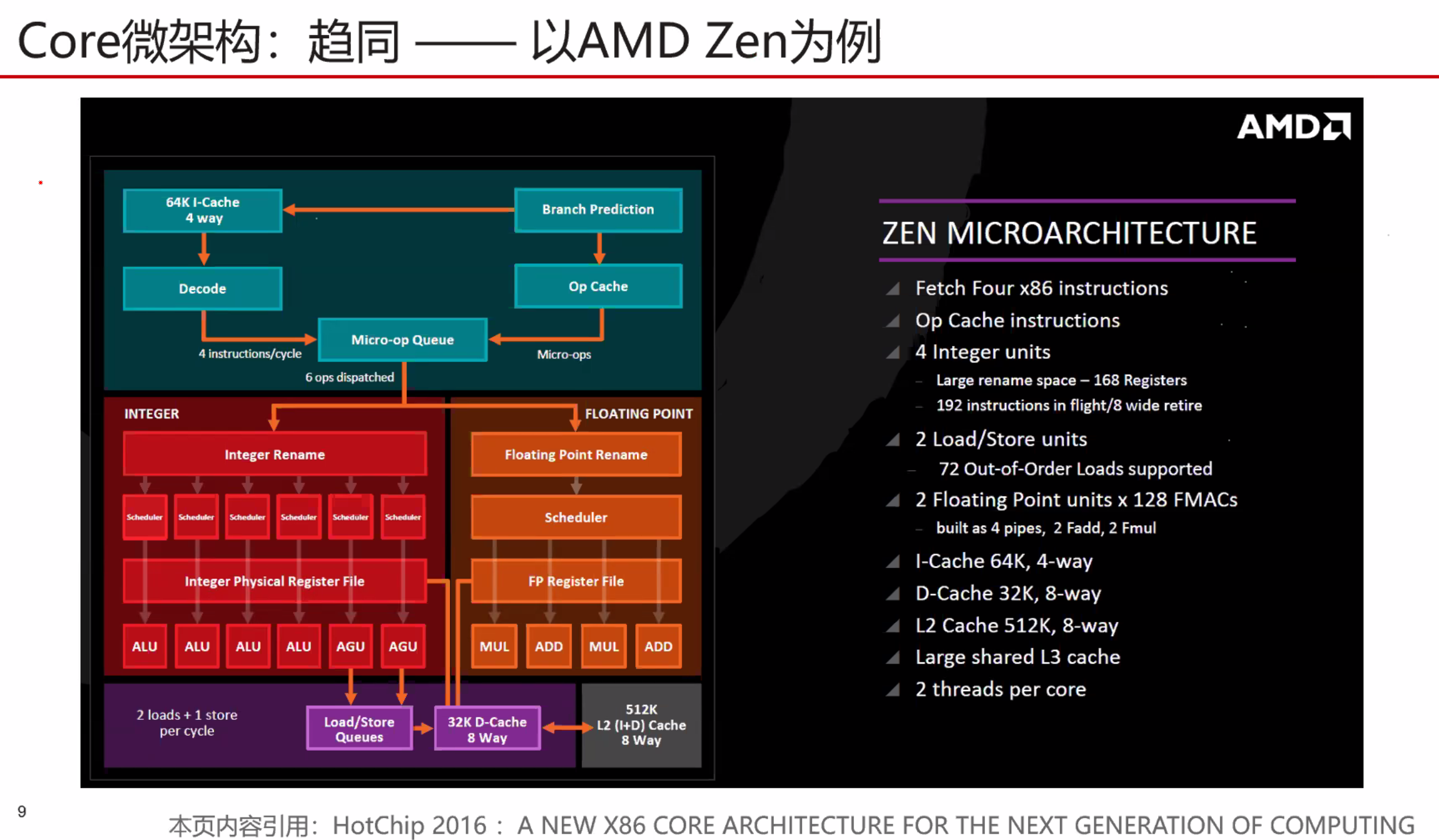
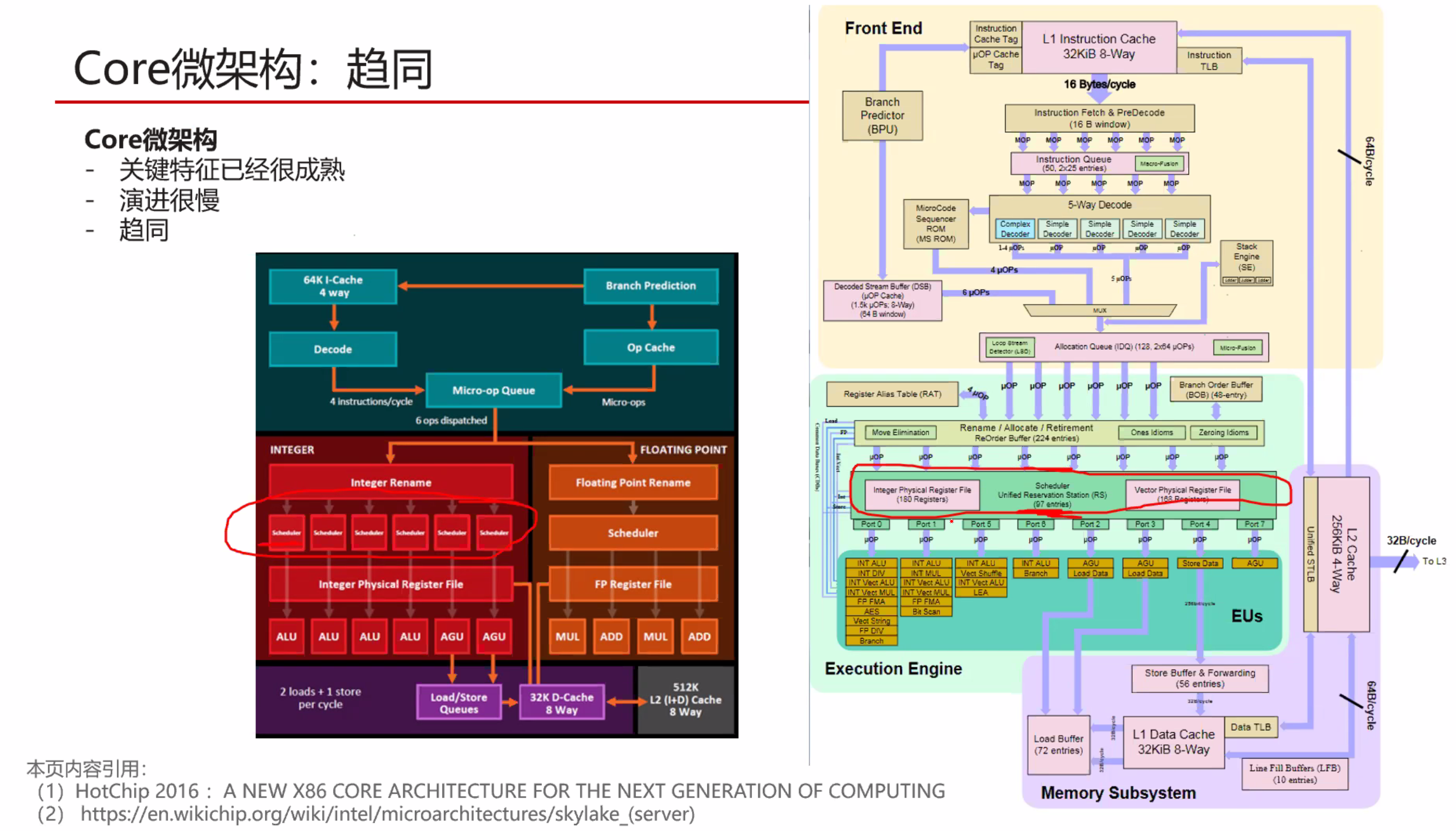 统一的调度器复杂度超级高,只有Intel实现了,但是效果很好。
统一的调度器复杂度超级高,只有Intel实现了,但是效果很好。
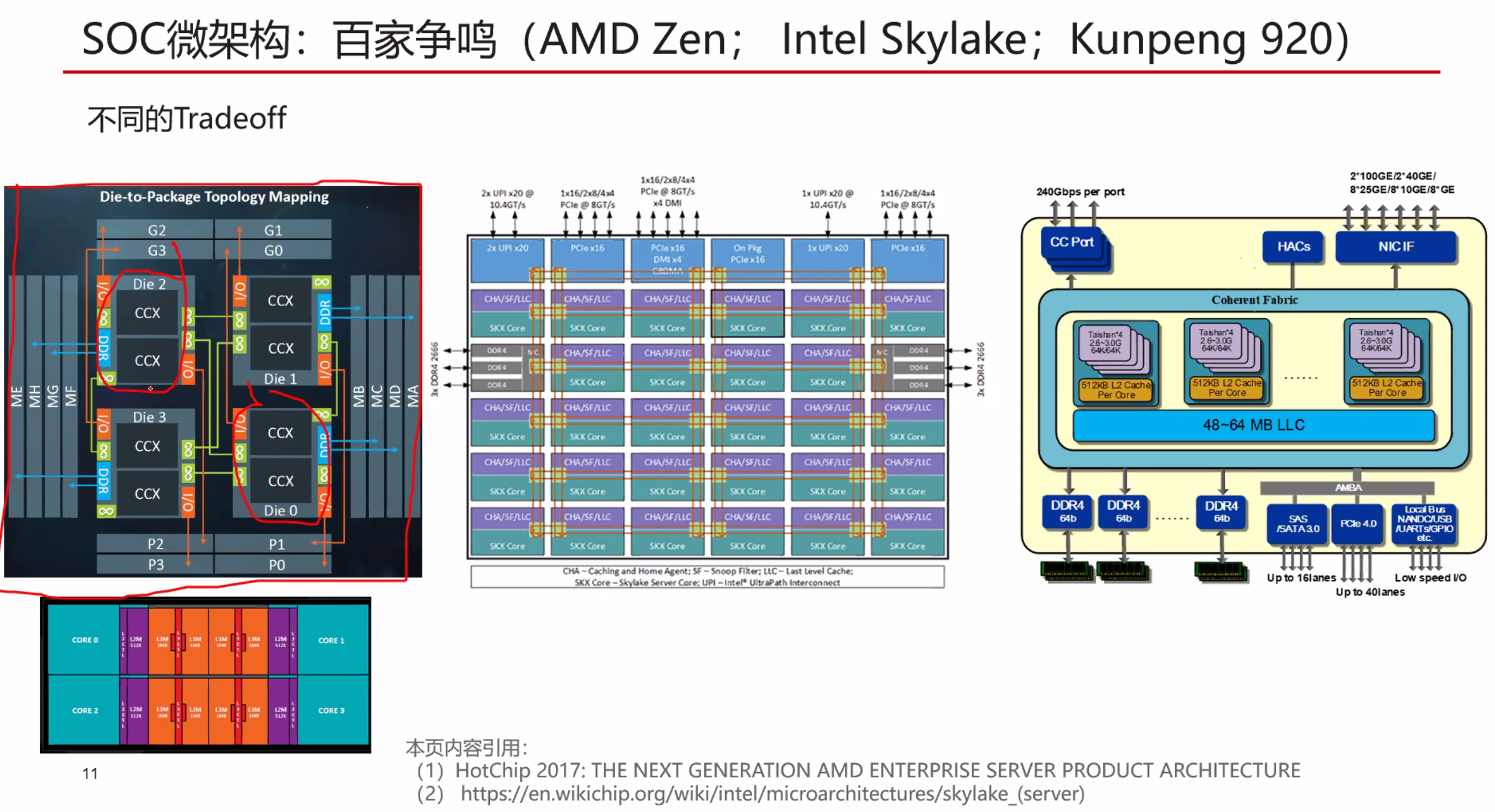
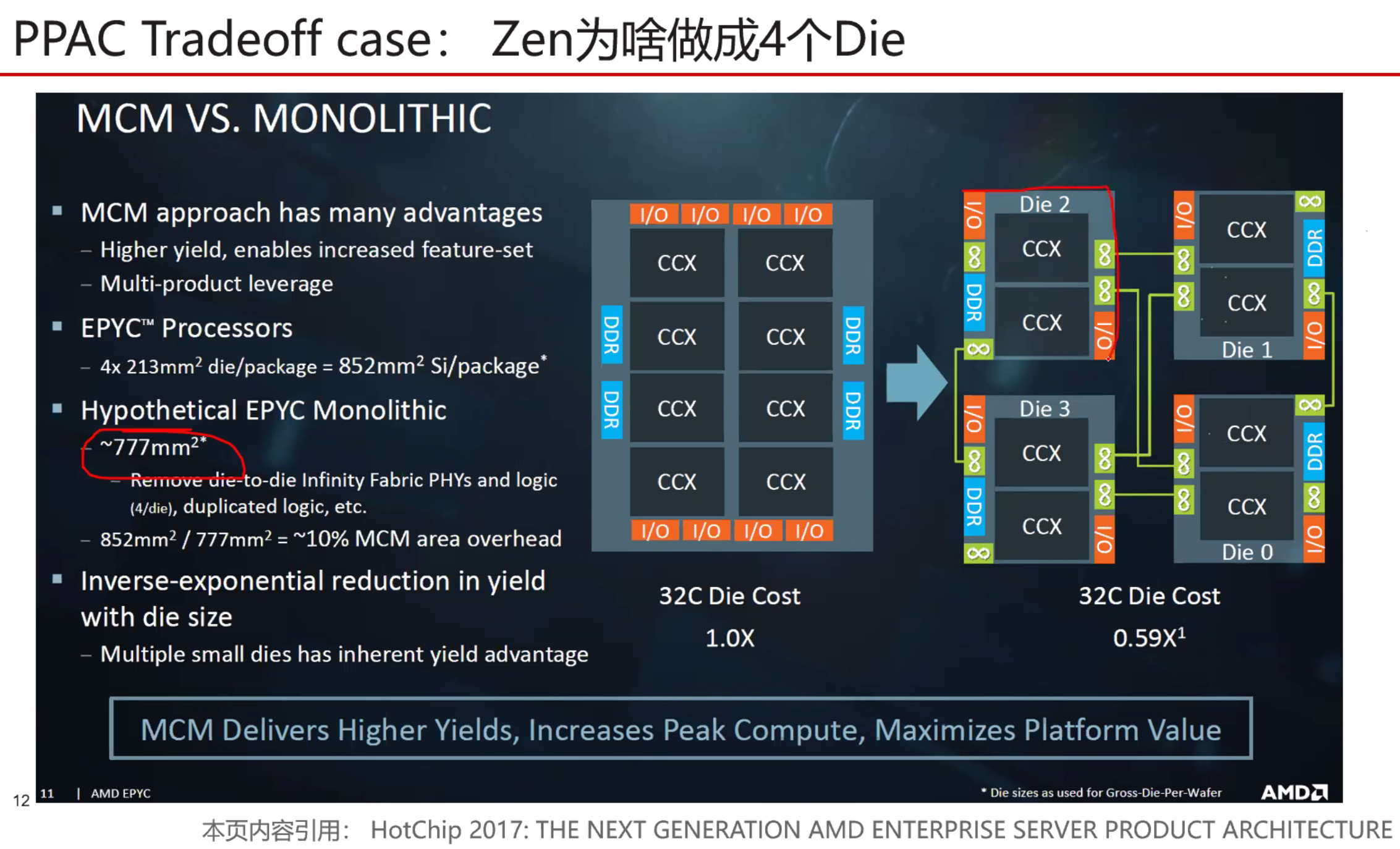 良品率会更高
良品率会更高

 自研OpenBLAS+ ,毕申编译器,自研MPI
自研OpenBLAS+ ,毕申编译器,自研MPI

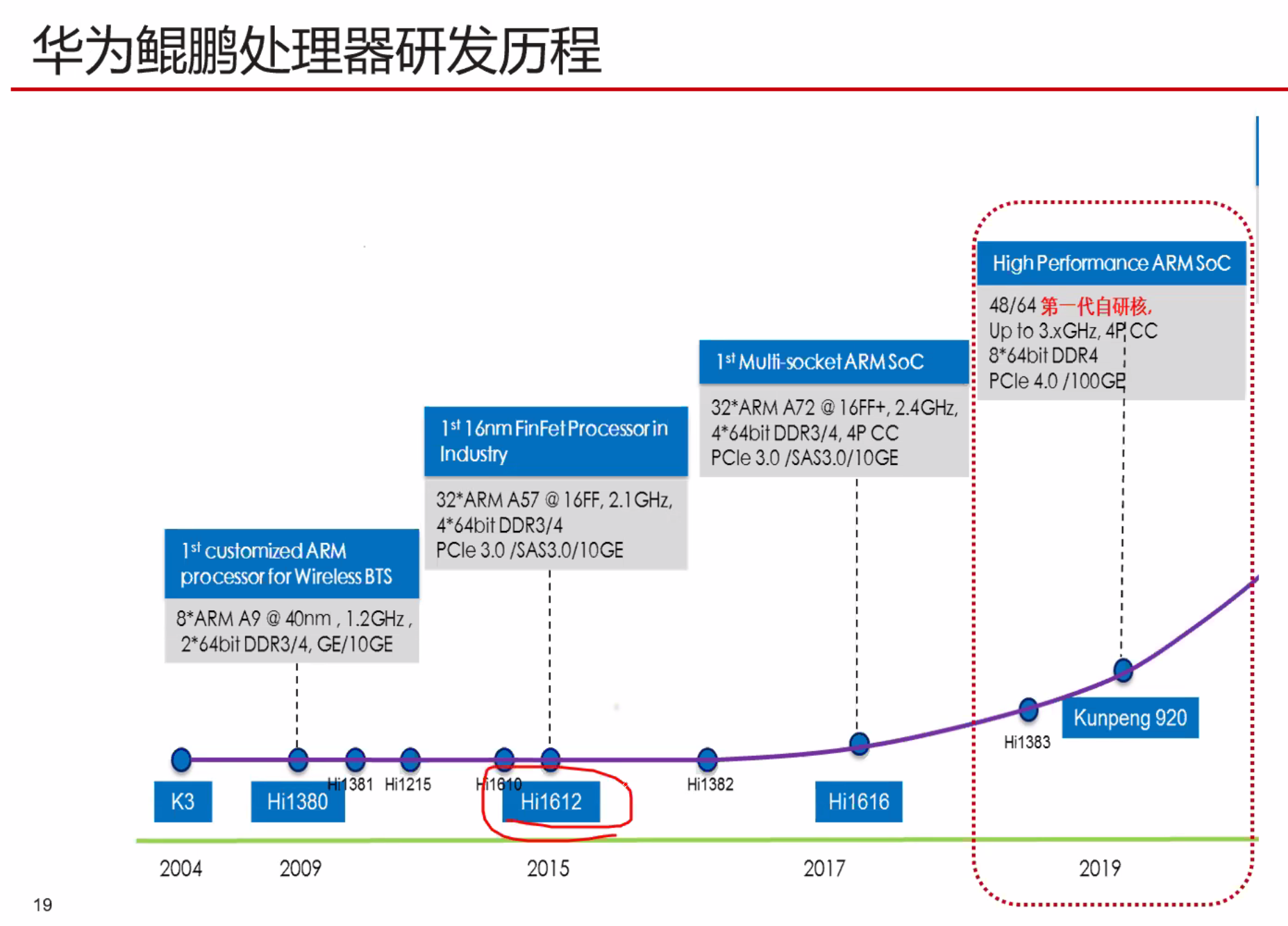

片间一致性可以到达4P到16P???。Intel可以达到8P
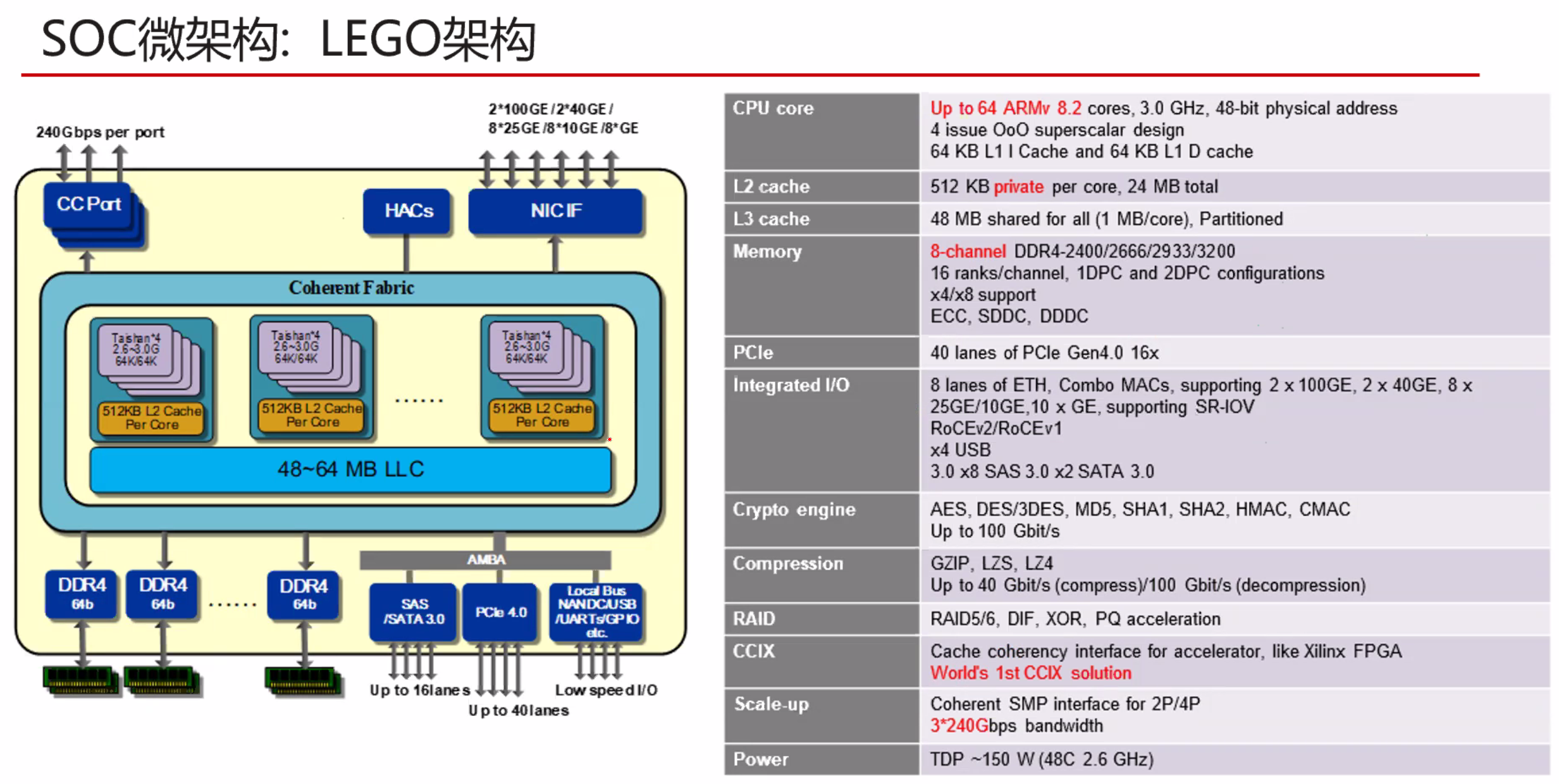
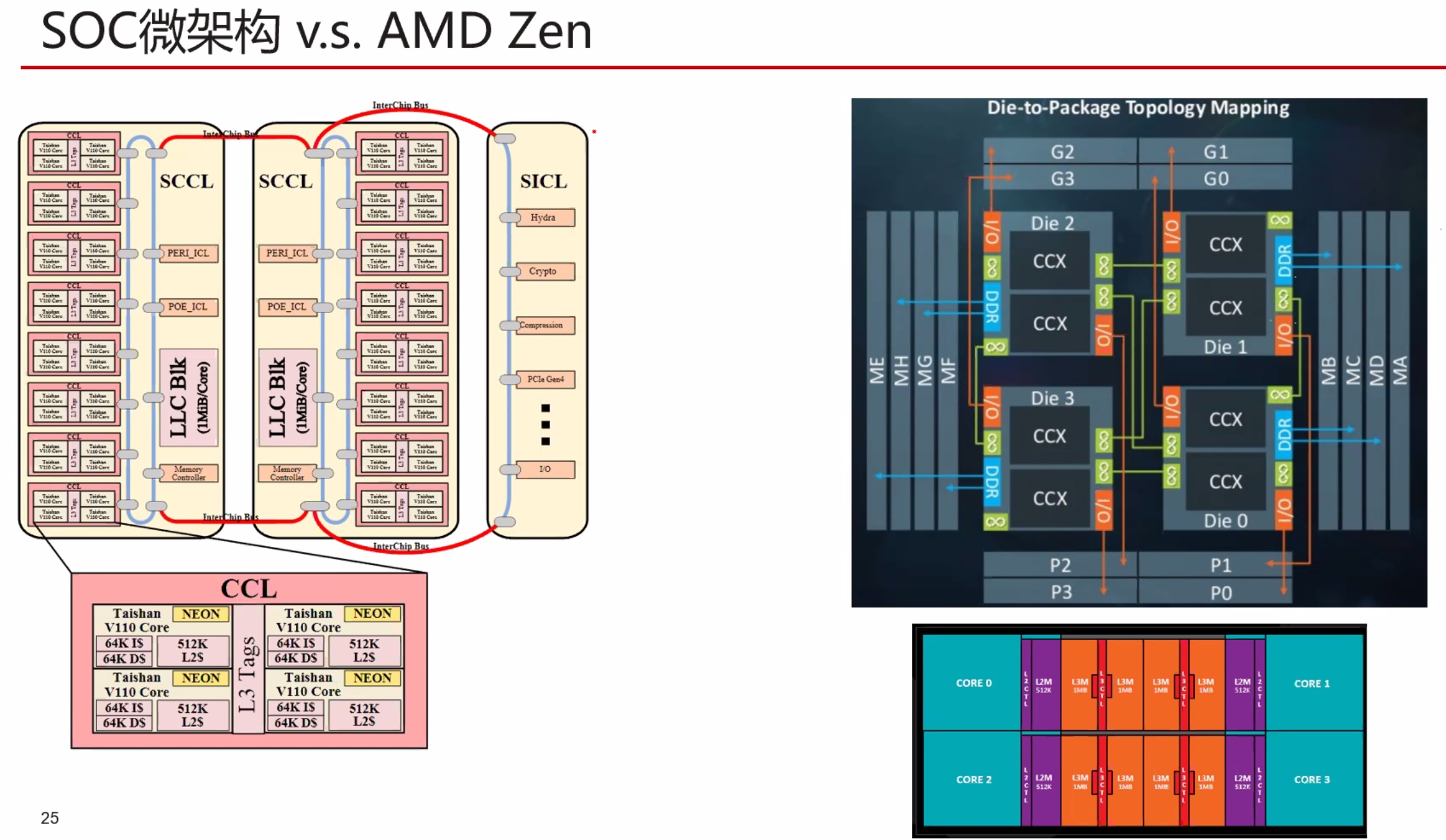
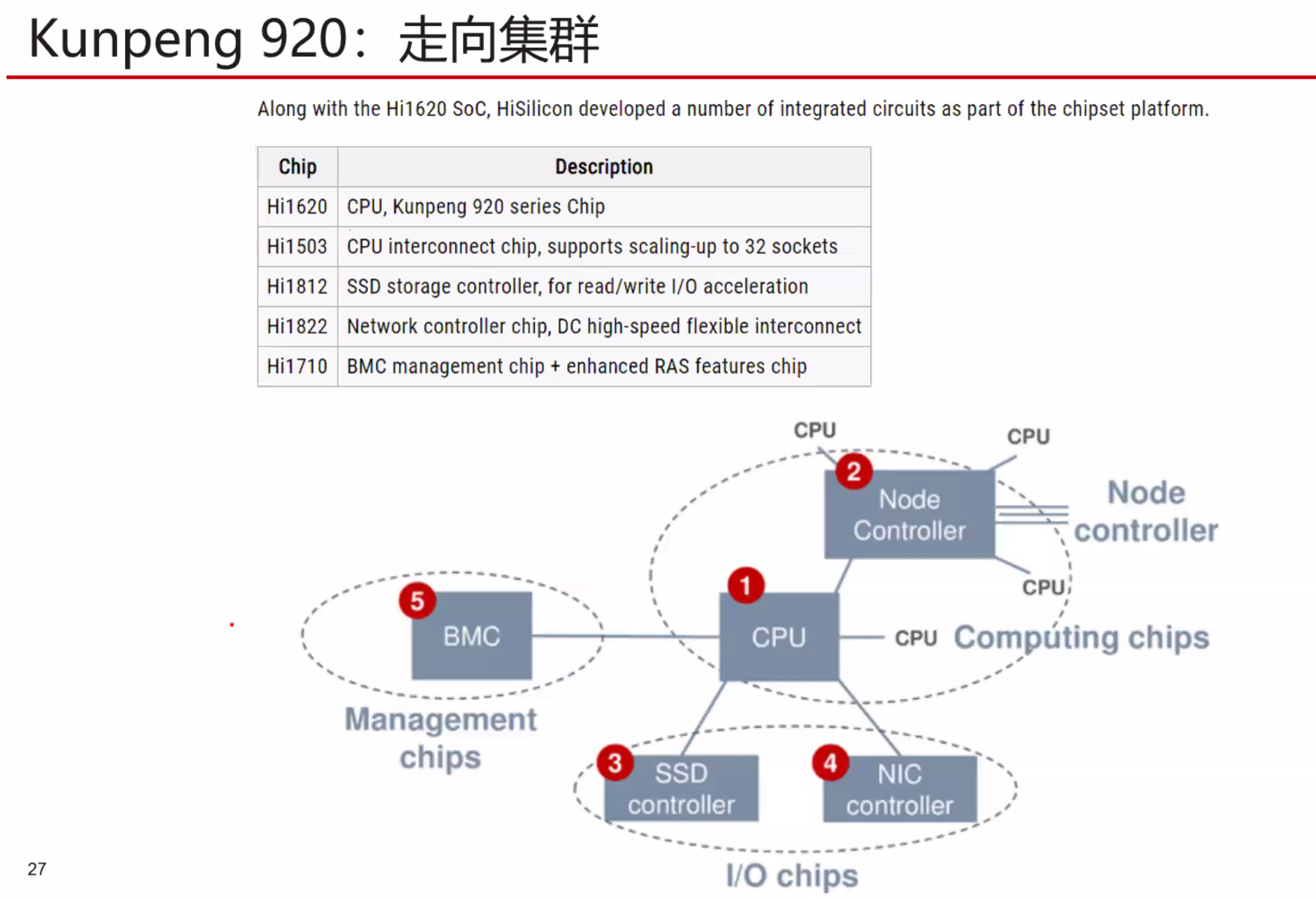
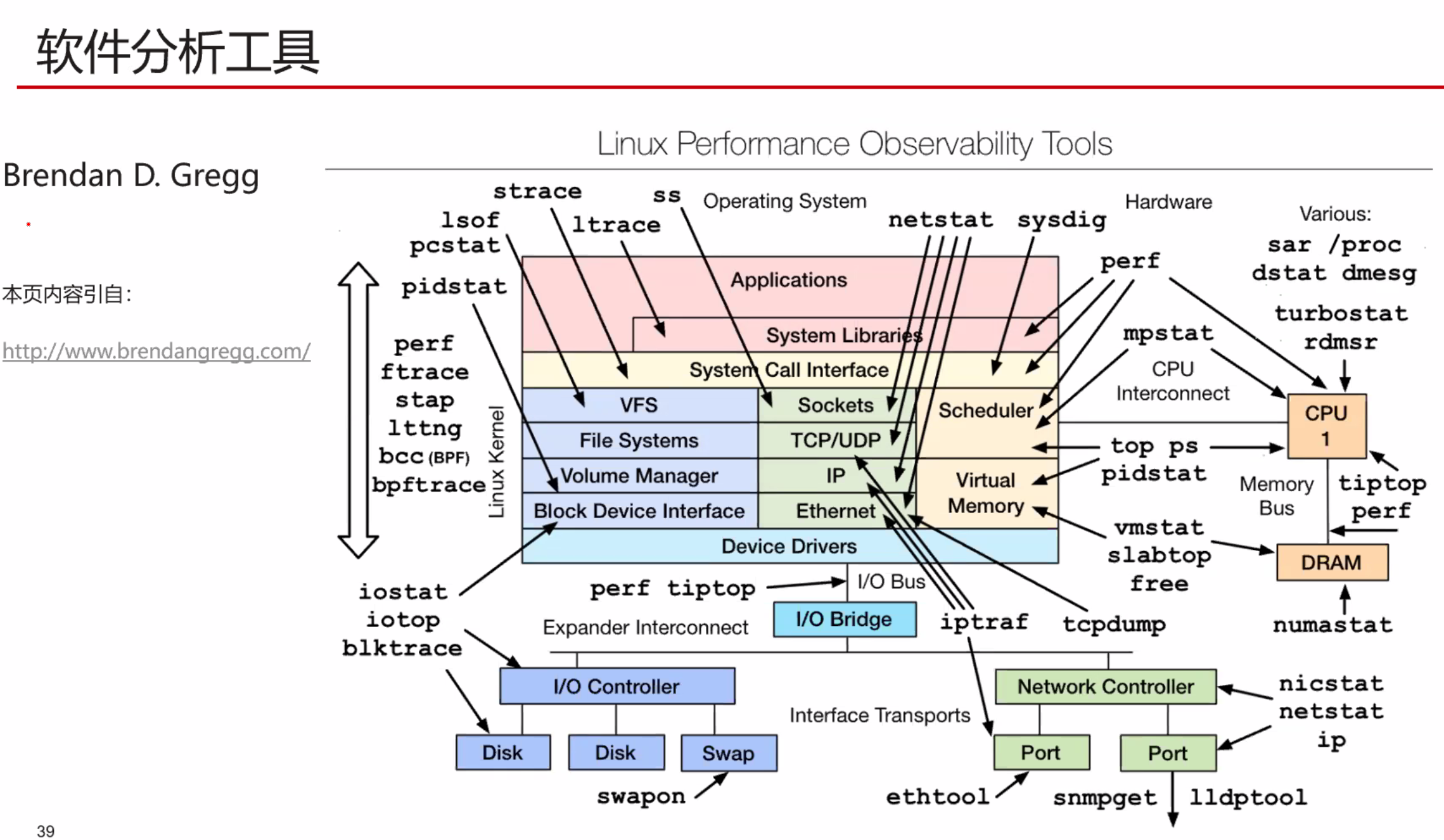

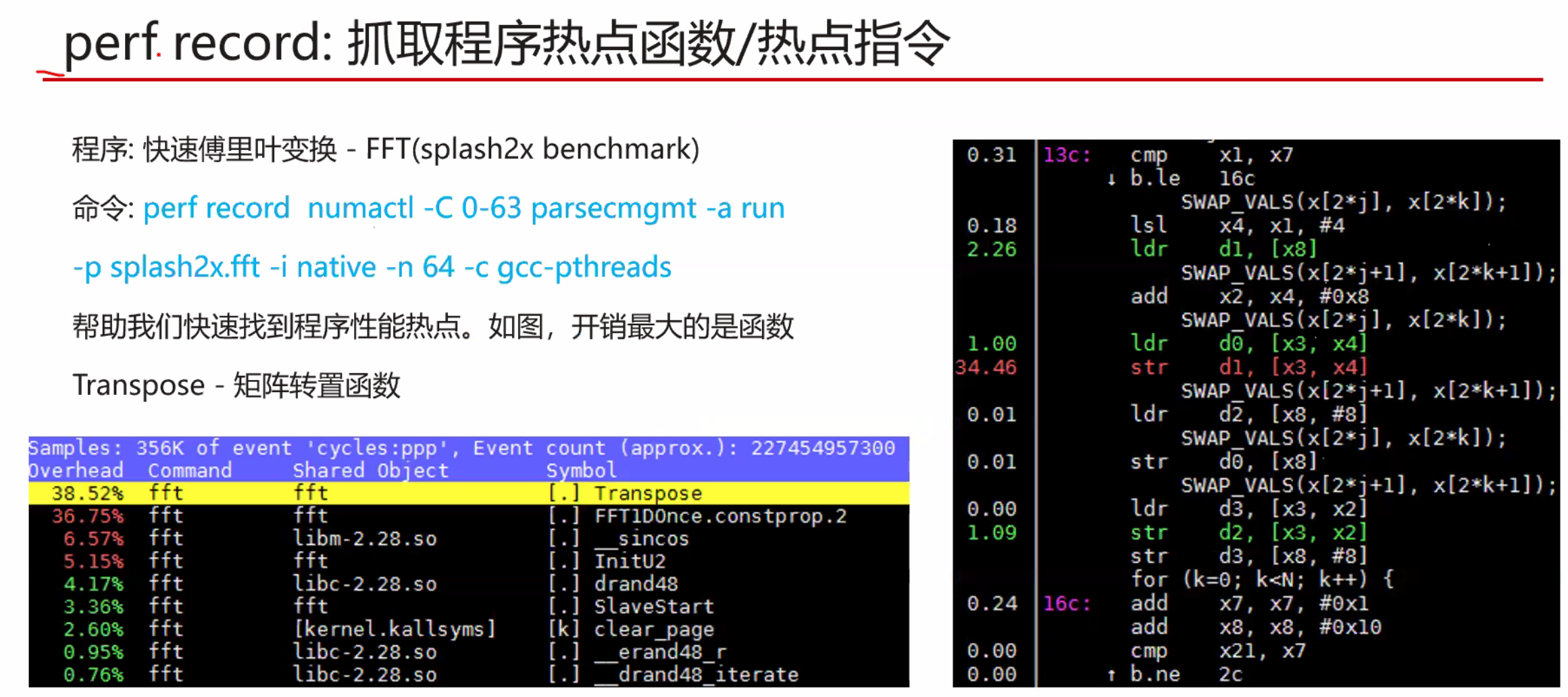
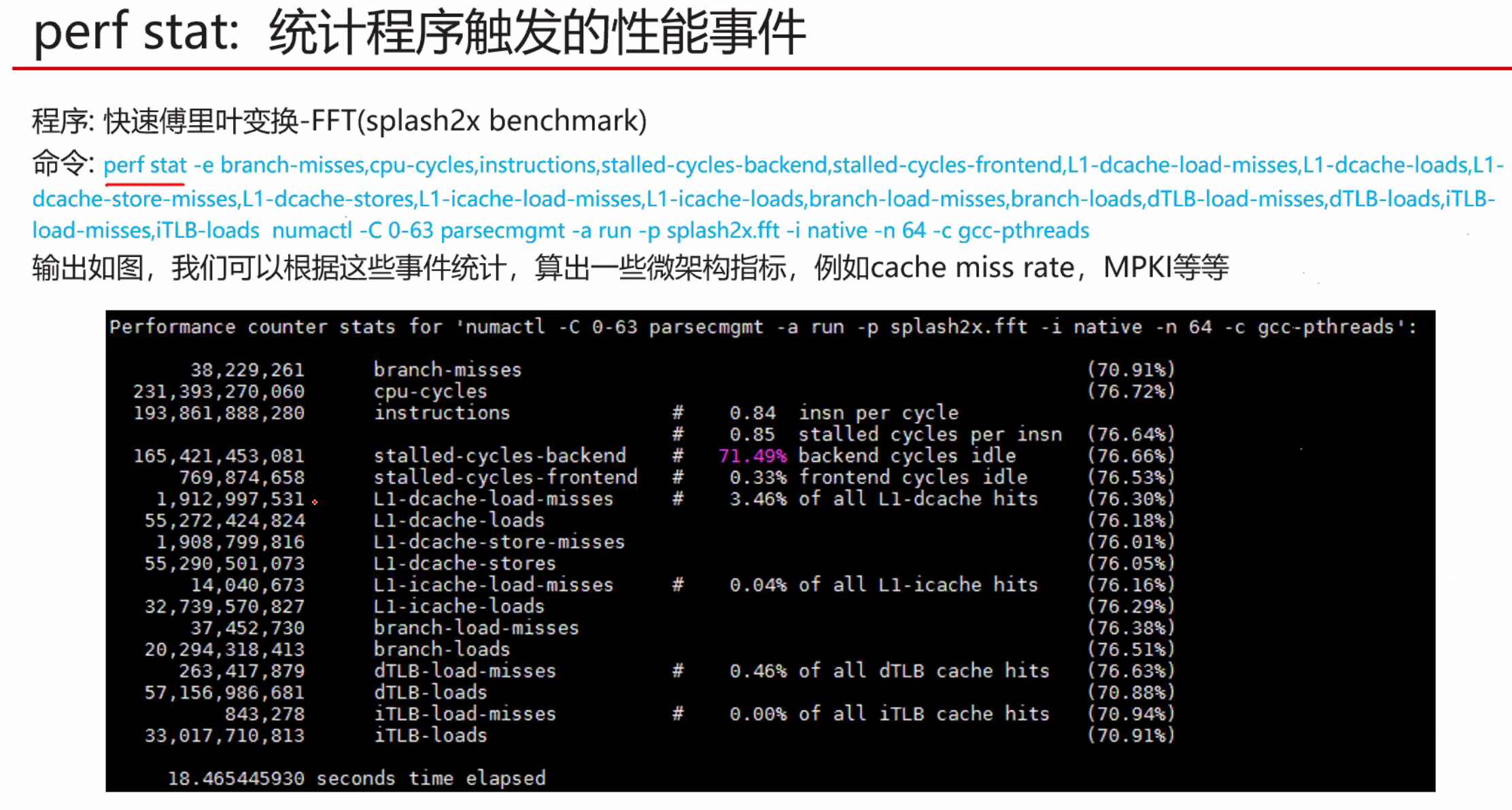
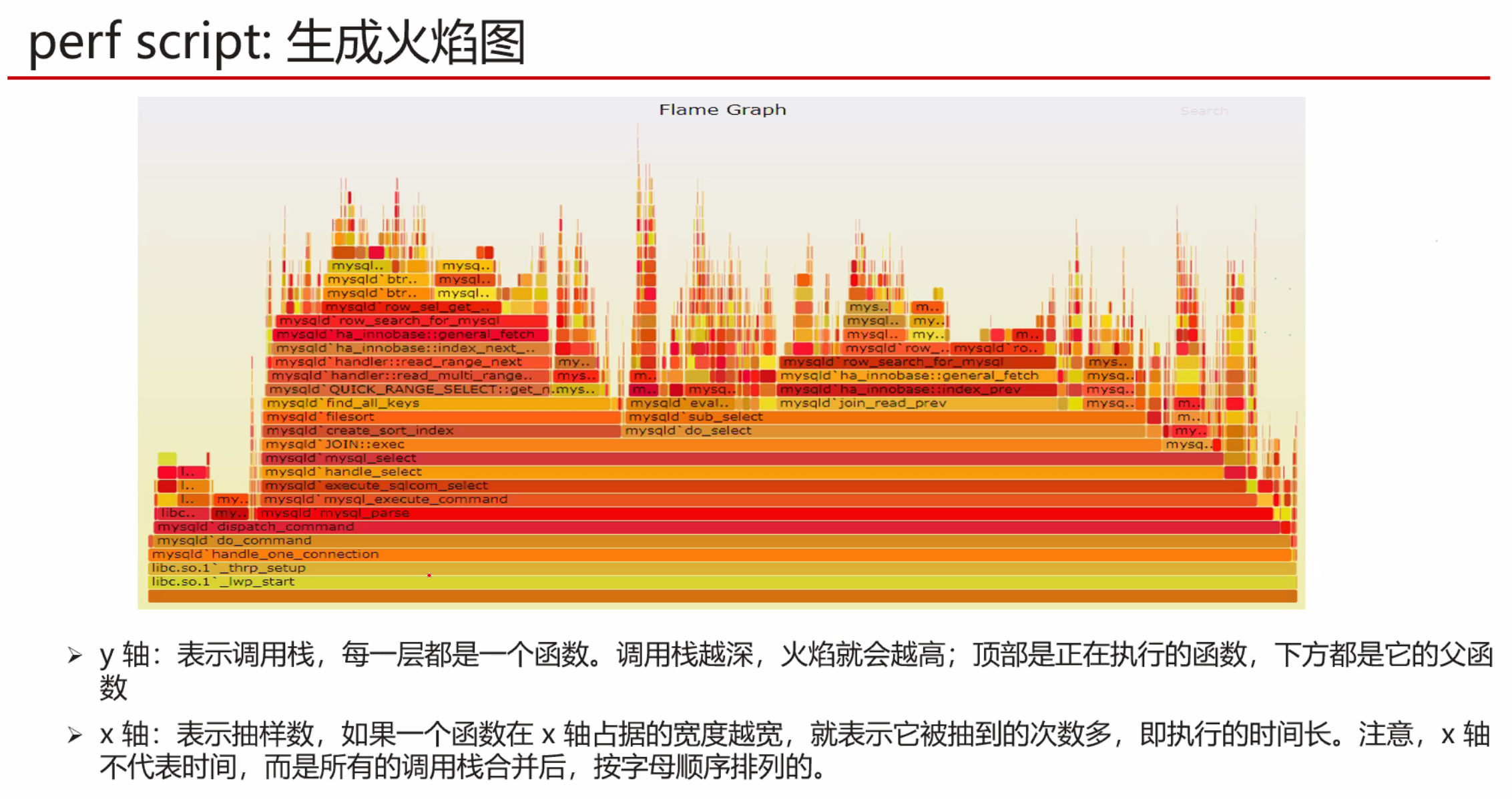
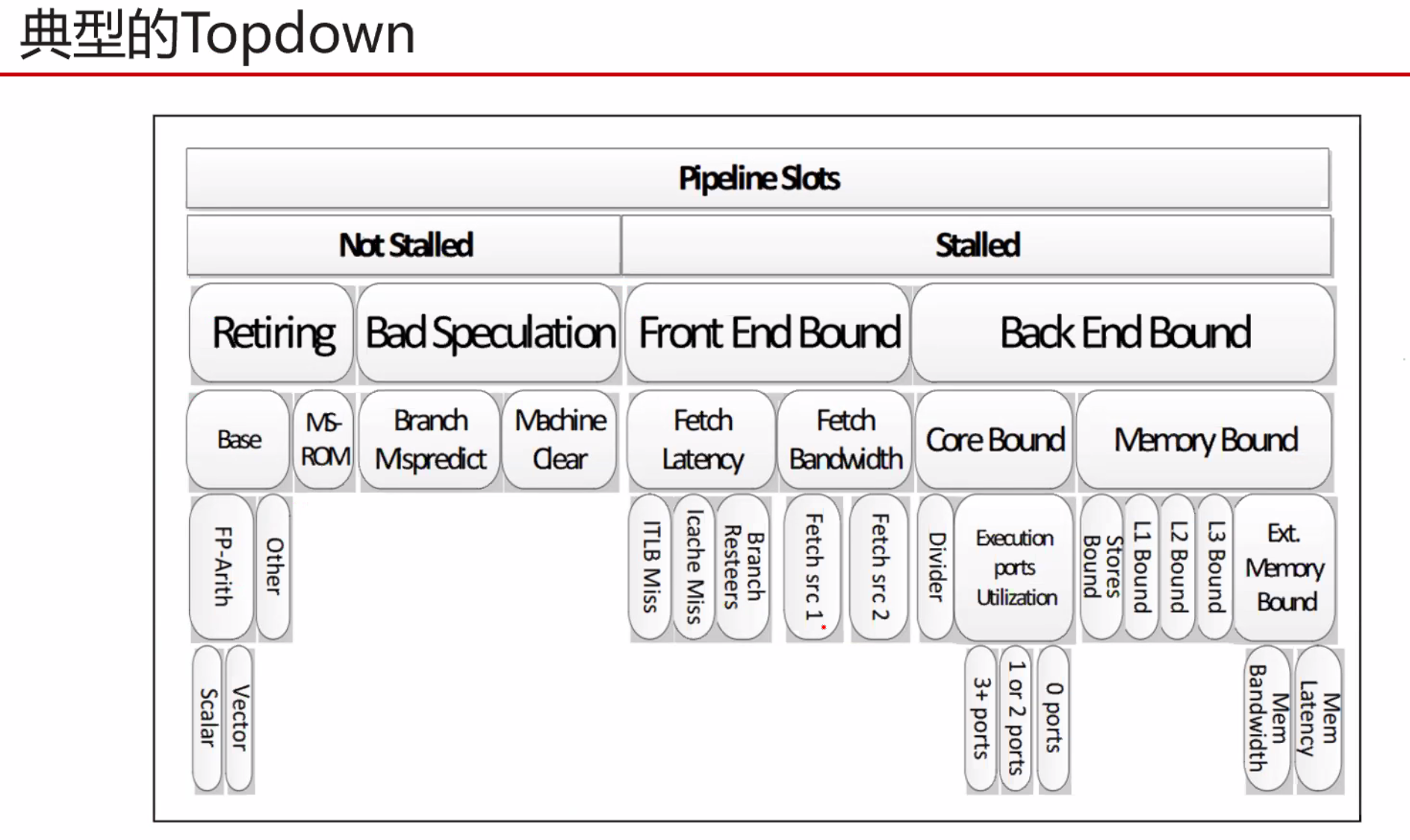
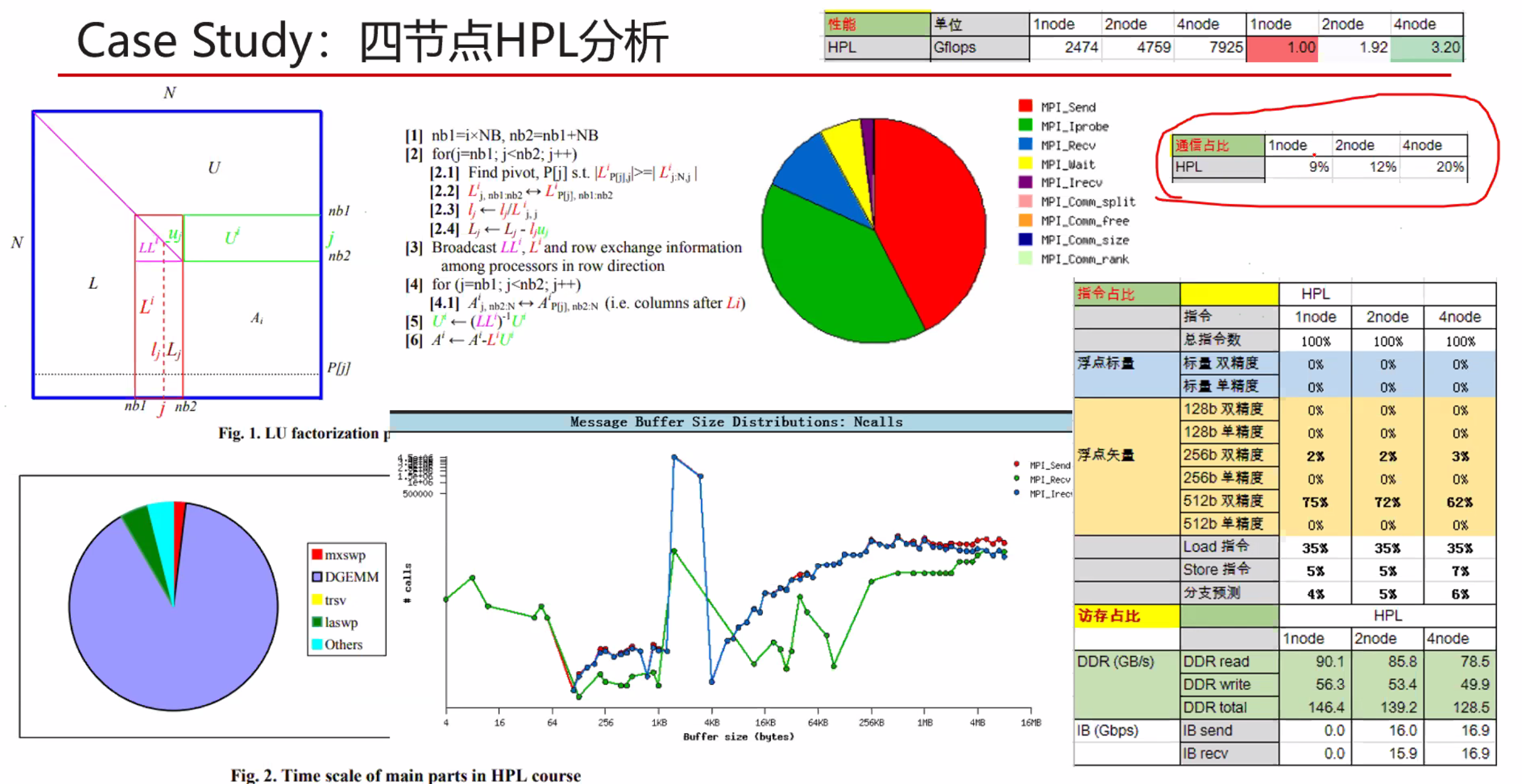
暂无
暂无
https://bbs.huaweicloud.com/blogs/268031
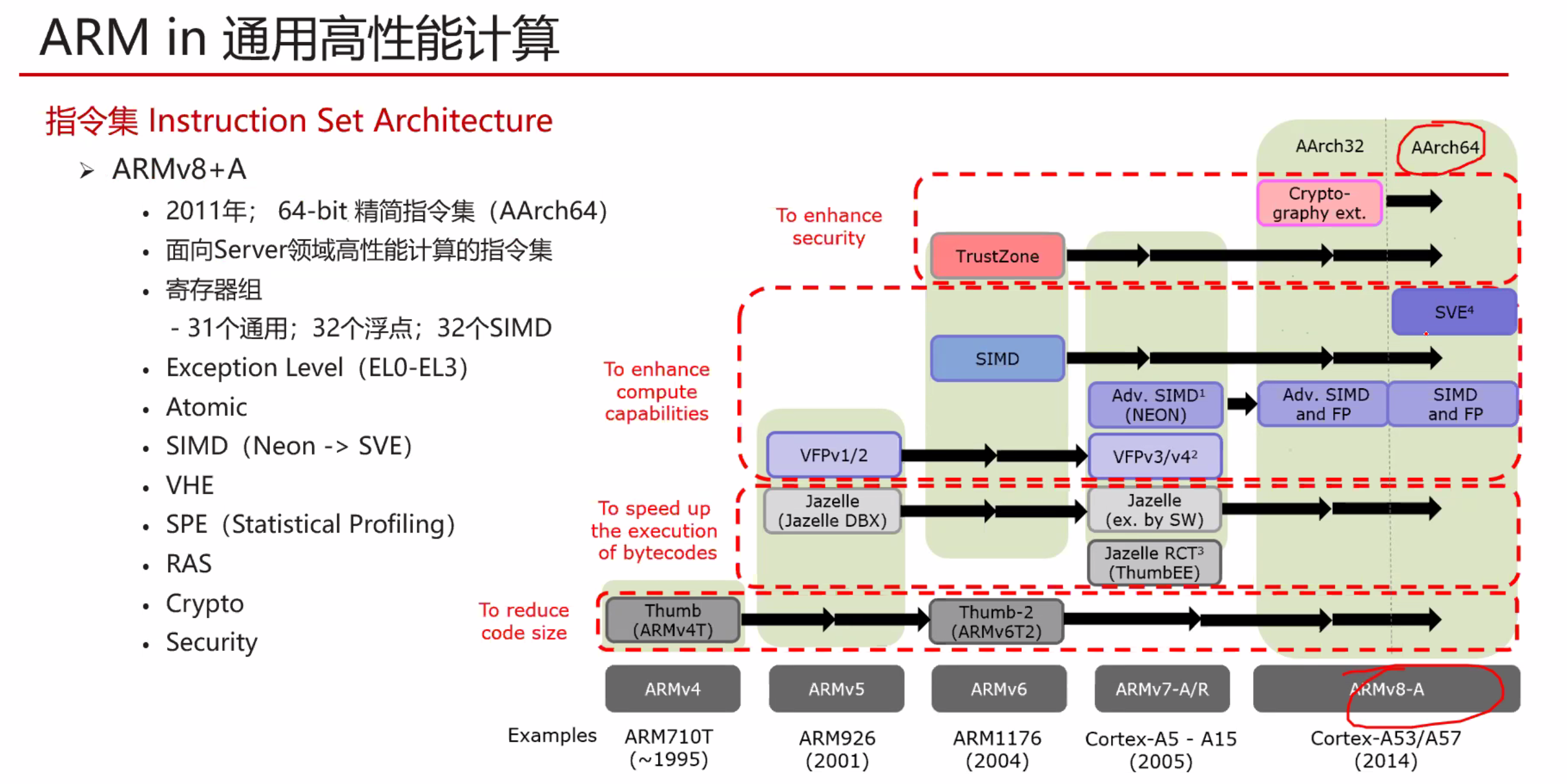
指令集架构(Instruction Set Architecture)是指一种类型CPU中用来计算和控制计算机系统的一套指令的集合。
指令集架构主要规定了指令格式、寻址访存(寻址范围、寻址模式、寻址粒度、访存方式、地址对齐等)、数据类型、寄存器。指令集通常包括三大类主要指令类型:运算指令、分支指令和访存指令。此外,还包括架构相关指令、复杂操作指令和其他特殊用途指令。因此,一种CPU执行的指令集架构不仅决定了CPU所要求的能力,而且也决定了指令的格式和CPU的结构。X86架构和ARMv8架构就是指令集架构的范畴。
所以不要说Nvidia是属于x86还是arm了,显卡应该是有自己的架构的。比如NV Tesla架构 、Fermi架构、Maxwell架构、Kepler架构、Turing架构。
而且X86具体到Intel,也有Skylake 架构 Ice lake 架构 Haswell架构等具体的实现
复杂指令集(CISC,complex instruction set computer)
RISC:Reduced Instruction Set Computer
$\(p(performance)=\frac{IPC*f}{Instruction\ Count}\)$
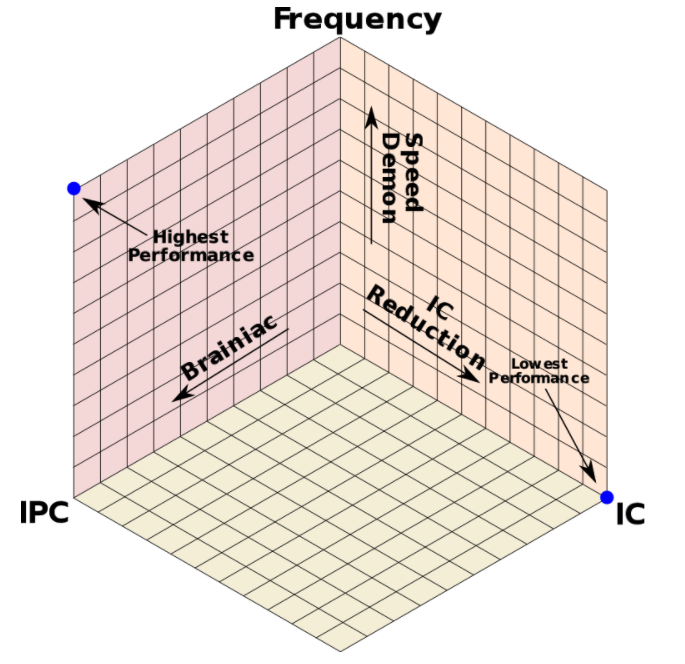
在计算机发展初期,计算机的优化方向是通过设置一些功能复杂的指令,把一些原来由软件实现的、常用的功能改用硬件的指令系统实现(减少IC),以此来提高计算机的执行速度。也就是为了减少程序的设计时间,逐渐开发出单一指令,复杂操作的程序代码。设计师只需写下简单的指令,再交给CPU去执行。
但是后来有人发现,整个指令集中,只有约20%的指令常常会被使用到,大约占了整个程序的80%;剩余80%的指令,只占了整个程序的20%。(典型的二八原则)
于是有人提出RISC尽量简化计算机指令功能的想法,主张硬件应该专心加速常用的指令,较为复杂的指令则利用常用的指令去组合。功能简单、能在一个节拍内执行完成的指令被保留,而较复杂的功能用一段子程序来实现,这种计算机系统就被称为精简指令系统计算机。
简单来说,CISC任务处理能力强,适合桌面电脑和服务器。RISC通过精简CISC指令种类,格式,简化寻址方式,达到省电高效的效果,适合手机、平板、数码相机等便携式电子产品。

1978年6月8日,Intel 发布了新款16位微处理器 8086,也同时开创了一个新时代:X86架构诞生了。
X86指令集是美国Intel公司为其第一块16位CPU(i8086)专门开发的,美国IBM公司1981年推出的世界第一台PC机中的CPU–i8088(i8086简化版)使用的也是X86指令。
为了保证电脑能继续运行以往开发的各类应用程序以保护和继承丰富的软件资源,所以Intel公司所生产的所有CPU仍然继续使用X86指令集。
IA64,又称英特尔安腾架构(Intel Itanium architecture),使用在Itanium处理器家族上的64位指令集架构,由英特尔公司与惠普公司共同开发,2001年首次推出。
见 arm.md
1981年出现,由MIPS科技公司开发并授权,它是基于一种固定长度的定期编码指令集,并采用 导入/存储(Load/Store)数据模型。
mips是一个学院派的cpu,授权门槛极低,因此很多厂家都做mips或者mips衍生架构。我们平时接触到的mips架构cpu主要用在嵌入式领域,比如路由器。
目前最活跃的mips是中国的龙芯,其loongisa架构其实是mips的扩展。
Alpha是DEC公司推出的RISC指令集系统,基于Alpha指令集的CPU也称为Alpha AXP架构,是64位的 RISC微处理器,最初由DEC公司制造,并被用于DEC自己的工作站和服务器中。作为VAX的后续被开发,支持VMS操作系统,如 Digital UNIX。
侧重超算,目前貌似最活跃是中国申威,神威太湖之光的cpu
2010年提出,受到大家的支持。USTC有团队研究。
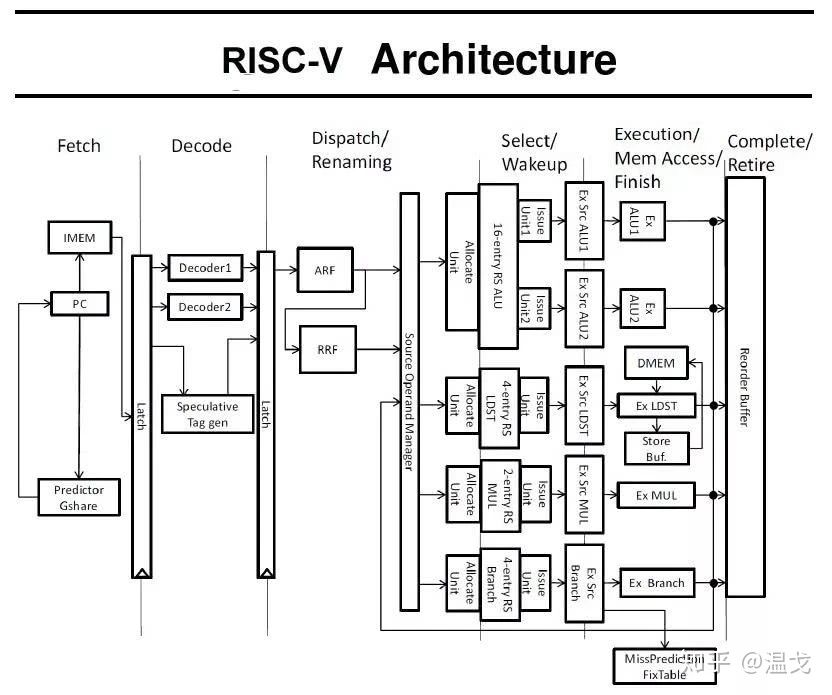
90年代,MIPS和Alpha作为知名RISC在与X86竞争计算机市场中失败,又在错过智能终端高速发展的机遇中走向衰弱。2010年发布的RISC-V作为从发明伊始即以开源为最大特色的RISC ISA受到全球学界、产业界的高度关注。全球顶级学府、科研机构、芯片巨头纷纷参与,各国政府出台政策支持RISC-V的发展和商业化。RISC-V有望成为X86和ARM之后ISA第三极。
实现指令集架构的物理电路被称为处理器的微架构(Micro-architecture)
大多数情况下,一种处理器的微架构是针对一种特定指令集架构进行物理实现。少部分处理器架构设计为了更好的兼容性,会在电路设计上实现多个指令集架构。虽然,指令集架构可以授权给多家企业,但微架构的设计细节,也就是对指令的物理实现方式是各家厂商绝对保密的。
暂无
暂无
https://www.zhihu.com/question/423489755/answer/1622380842
鸡蛋从哪头打破,怎么会有哪种更合适呢?对个人生活和社会发展又有什么意义呢?Swift写这段故事,其实是讽刺当时法国和英国的时政,认为真正重要的事情得不到关注、而在一些毫无意义的事情上争论不休。
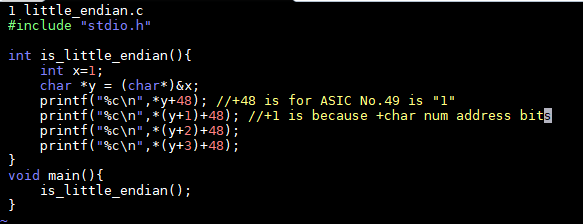
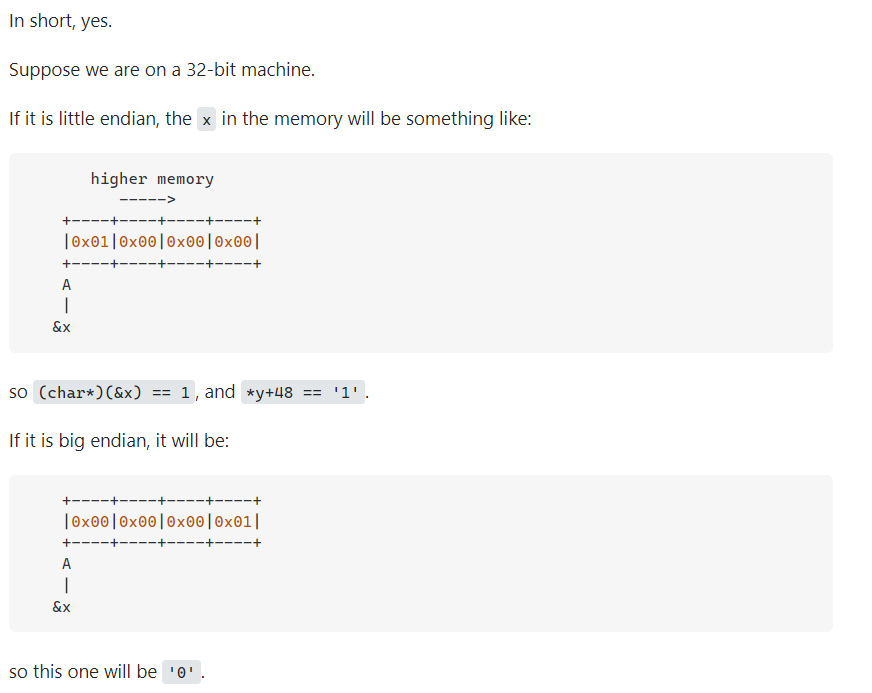
Motorola的PowerPC系列CPU采用Big-Endian方式存储数据,
而Intel的x86系列则采用Little-Endian方式存储数据。
JAVA虚拟机中多字节类型数据的存放顺序,也就是JAVA字节序是Big-Endian。
很多的ARM,DSP(Digital signal processor)都为小端模式。有些ARM处理器还可以随时在程序中(在ARM Cortex 系列使用REV、REV16、REVSH指令)进行大小端的切换。
得益于高级语言的发展,在现在的软件开发基本不需关心字节序(除非是socket编程),如Java这类跨平台移植的语言由虚拟机屏蔽了字节序问题。
对于大小端的处理也和编译器的实现有关,在C语言中,默认是小端(但在一些对于单片机的实现中却是基于大端,比如Keil 51C),Java是平台无关的,默认是大端。在网络上传输数据普遍采用的都是大端
华为鲲鹏AArch64 和 Intel x86 都是little-endian

暂无
暂无
无
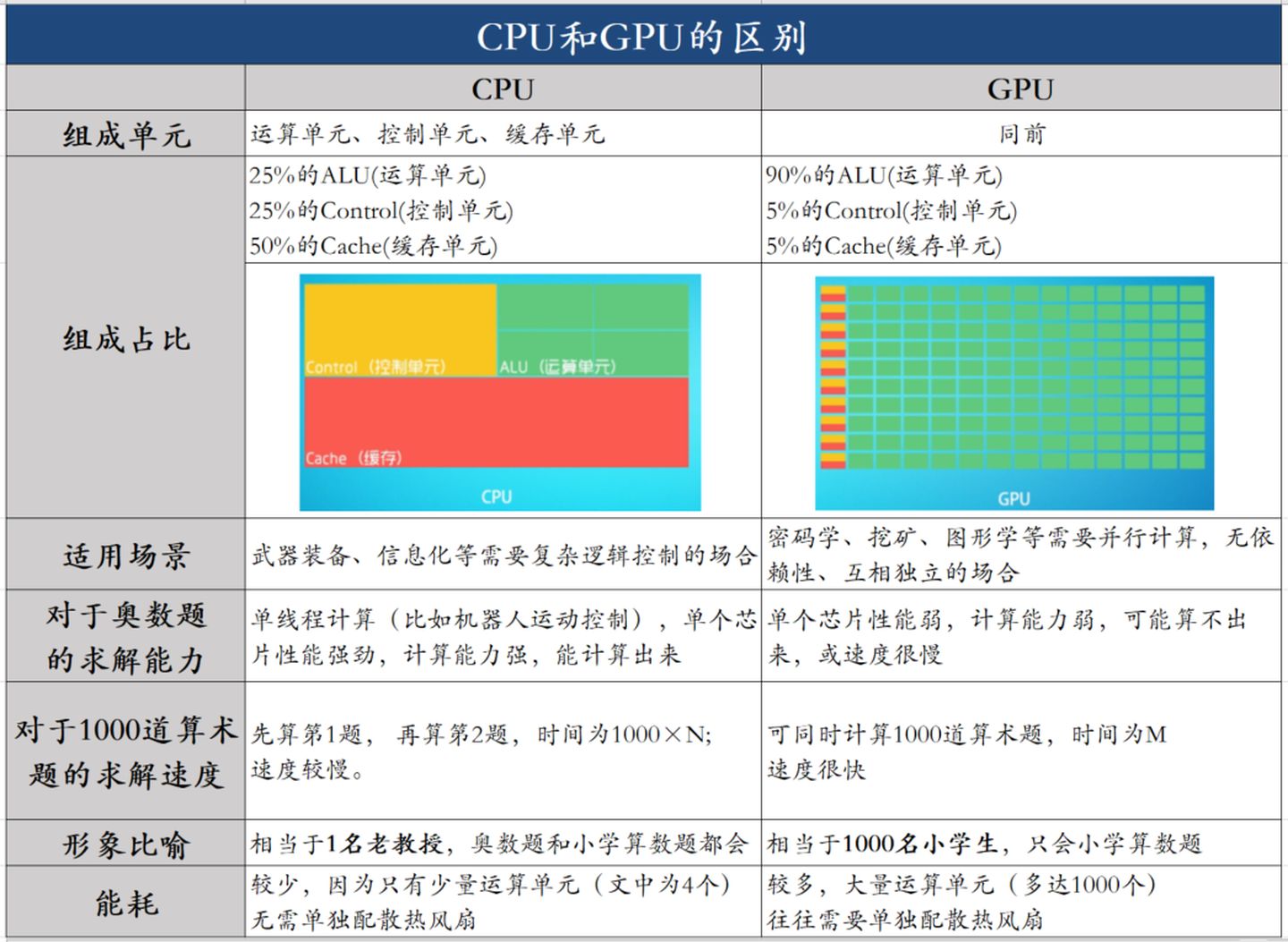
低延时的设计思路
相比之下计算能力只是CPU很小的一部分。擅长逻辑控制,串行的运算。
大吞吐量设计思路
0 cycles and can happen every cycle.[^2]对带宽大的密集计算并行性能出众,擅长的是大规模并发计算。
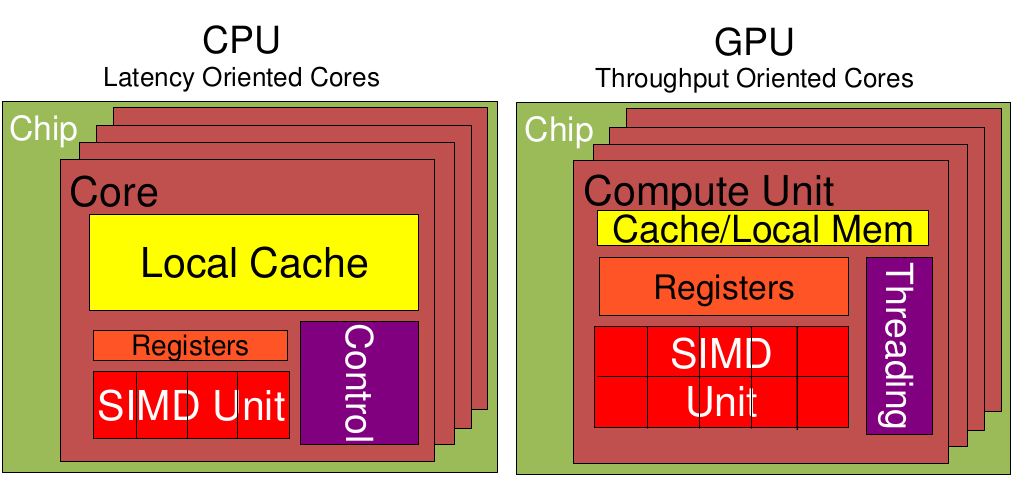
| 对比项 | CPU | GPU | 说明 |
|---|---|---|---|
| Cache, local memory | 多 | 低延时 | |
| Threads(线程数) | 多 | ||
| Registers | 多 | 多寄存器可以支持非常多的Thread,thread需要用到register,thread数目大,register也必须得跟着很大才行。 | |
| SIMD Unit | 多 | 单指令多数据流,以同步方式,在同一时间内执行同一条指令 |
其实最早用在显卡上的DDR颗粒与用在内存上的DDR颗粒仍然是一样的。后来由于GPU特殊的需要,显存颗粒与内存颗粒开始分道扬镳,这其中包括了几方面的因素:
因为显存可以在一个时钟周期内的上升沿和下降沿同时传送数据,所以显存的实际频率应该是标称频率的一半。
从GDDR5开始用两路传输,GDDR6采用四路传输(达到类似效果)。
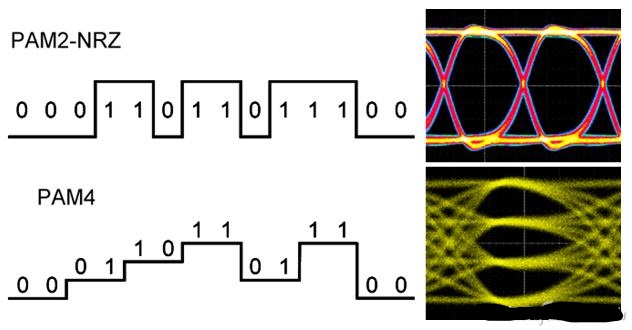
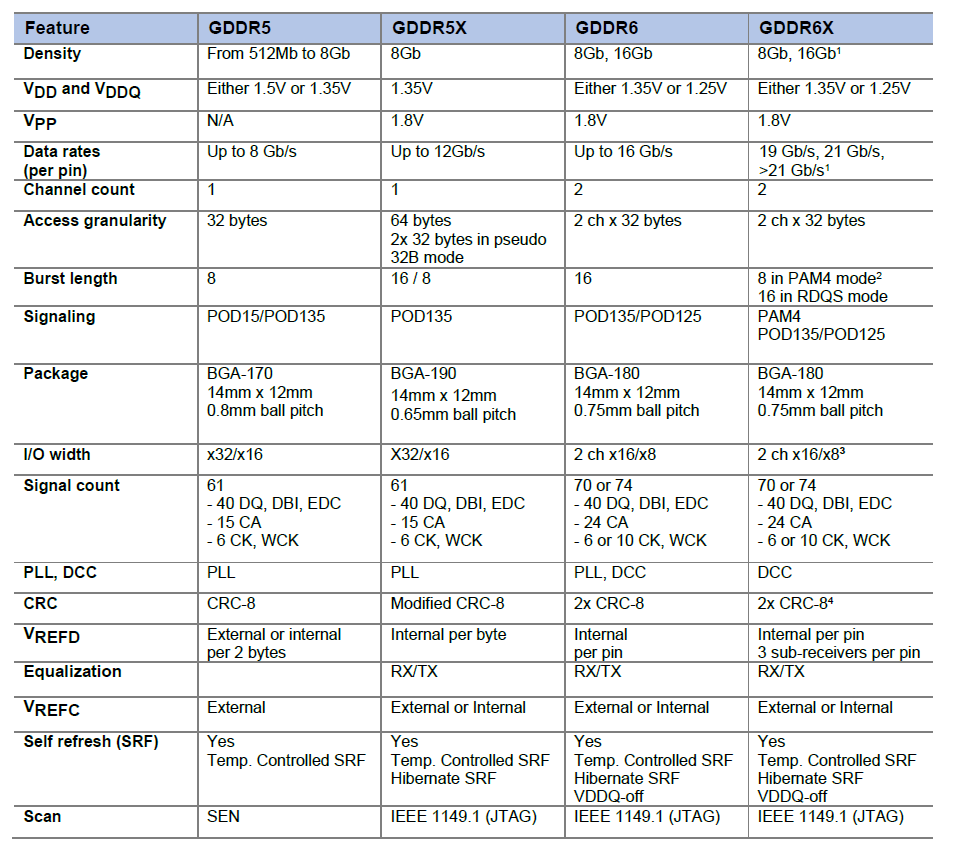
GDDR6X的频率估计应该至少从16Gbps(GDDR6目前的极限)起跳,20Gbps为主,这样在同样的位宽下,带宽比目前常见的14Gbps GDDR6大一半。比如在常见的中高端显卡256bit~384位宽下能提供512GB/s~768GB/s的带宽。
RTX 3090的GDDR6X显存位宽384bit,等效频率19Gbps到21Gbps,带宽可达912GB/s到1006GB/s,达到T级。(384*19/8=912)
RTX 3090 加速频率 (GHz) 1.7, 基础频率 (GHz) 1.4
912GB/s到1006GB/s 附近3.2 Gbps * 64 bits * 2 / 8 = 51.2GB/s可见两者差了20倍左右。
通过上面的例子,大致能知道: 需要高访存带宽和高并行度的SIMD的应用适合分配在GPU上。
https://zhuanlan.zhihu.com/p/156171120?utm_source=wechat_session
https://www.cnblogs.com/biglucky/p/4223565.html
https://www.zhihu.com/question/36825227/answer/69351247
https://baijiahao.baidu.com/s?id=1675253413370892973&wfr=spider&for=pc
https://zhuanlan.zhihu.com/p/62234511
https://kknews.cc/digital/x6v69xq.html
并行计算课程-CUDA 密码pa22 ↩↩↩