llvm Pass
简介
- Pass就是“遍历一遍IR,可以同时对它做一些操作”的意思。翻译成中文应该叫“传递”。
- 在实现上,LLVM的核心库中会给你一些 Pass类 去继承。你需要实现它的一些方法。
- ModulePass , CallGraphSCCPass, FunctionPass , or LoopPass, or RegionPass
- 最后使用LLVM的编译器会把它翻译得到的IR传入Pass里,给你遍历和修改。
作用
- 插桩: 在Pass遍历LLVM IR的同时,自然就可以往里面插入新的代码。
- 机器无关的代码优化:编译原理一课说:IR在被翻译成机器码前会做一些机器无关的优化。 但是不同的优化方法之间需要解耦,所以自然要各自遍历一遍IR,实现成了一个个LLVM Pass。 最终,基于LLVM的编译器会在前端生成LLVM IR后调用一些LLVM Pass做机器无关优化, 然后再调用LLVM后端生成目标平台代码。
- 静态分析: 像VSCode的C/C++插件就会用LLVM Pass来分析代码,提示可能的错误 (无用的变量、无法到达的代码等等)。
理解 llvm Pass
理解Pass API
Pass类是实现优化的主要资源。然而,我们从不直接使用它,而是通过清楚的子类使用它。当实现一个Pass时,你应该选择适合你的Pass的最佳粒度,适合此粒度的最佳子类,例如基于函数、模块、循环、强联通区域,等等。常见的这些子类如下:
ModulePass:这是最通用的Pass;它一次分析整个模块,函数的次序不确定。它不限定使用者的行为,允许删除函数和其它修改。为了使用它,你需要写一个类继承ModulePass,并重载runOnModule()方法。FunctionPass:这个子类允许一次处理一个函数,处理函数的次序不确定。这是应用最多的Pass类型。它禁止修改外部函数、删除函数、删除全局变量。为了使用它,需要写一个它的子类,重载runOnFunction()方法。BasicBlockPass:这个类的粒度是基本块。FunctionPass类禁止的修改在这里也是禁止的。它还禁止修改或者删除外部基本块。使用者需要写一个类继承BasicBlockPass,并重载它的runOnBasicBlock()方法。
被重载的入口函数runOnModule()、runOnFunction()、runOnBasicBlock()返回布尔值false,如果被分析的单元(模块、函数和基本块)保持不变,否则返回布尔值true。
Pass的执行顺序/依赖
- ChatGPT说默认顺序是:FunctionPass -> Module Pass -> LoopPass ?
- 当然我们是可以修改插入Pass的执行顺序的。
char PIMProf::AnnotationInjection::ID = 0;
// 注册 llvm pass
static RegisterPass<PIMProf::AnnotationInjection> RegisterMyPass(
"AnnotationInjection", "Inject annotators to uniquely identify each basic block.");
static void loadPass(const PassManagerBuilder &,
legacy::PassManagerBase &PM) {
PM.add(new PIMProf::AnnotationInjection());
}
// Ox 的代码 llvm pass 在EP_OptimizerLast 位置load
static RegisterStandardPasses clangtoolLoader_Ox(PassManagerBuilder::EP_OptimizerLast, loadPass);
// O0 的代码 llvm pass EP_EnabledOnOptLevel0 位置load
static RegisterStandardPasses clangtoolLoader_O0(PassManagerBuilder::EP_EnabledOnOptLevel0, loadPass);
流程
- 编写LLVM pass代码
- 配置编译环境(cmake or make)
- 运行(opt or clang)
1 代码框架
最简单框架hello.cpp如下,注意Important一定需要:
#include "llvm/Pass.h"
#include "llvm/IR/Function.h"
#include "llvm/Support/raw_ostream.h"
#include "llvm/IR/LegacyPassManager.h"
#include "llvm/Transforms/IPO/PassManagerBuilder.h"
using namespace llvm;
namespace {
// Important
struct Hello : public FunctionPass {
static char ID;
Hello() : FunctionPass(ID) {}
// Important
bool runOnFunction(Function &F) override {
errs() << "Hello: ";
errs().write_escaped(F.getName()) << '\n';
return false;
}
};
}
char Hello::ID = 0;
// Important:Register for opt
static RegisterPass<Hello> X("hello", "Hello World Pass");
// Important:Register for clang
static RegisterStandardPasses Y(PassManagerBuilder::EP_EarlyAsPossible,
[](const PassManagerBuilder &Builder, legacy::PassManagerBase &PM) {
PM.add(new Hello());
});
2 编译动态库
使用cmake
参考官方文档。
An example of a project layout is provided below.
Contents of <project dir>/CMakeLists.txt:
find_package(LLVM REQUIRED CONFIG)
separate_arguments(LLVM_DEFINITIONS_LIST NATIVE_COMMAND ${LLVM_DEFINITIONS})
add_definitions(${LLVM_DEFINITIONS_LIST})
include_directories(${LLVM_INCLUDE_DIRS})
add_subdirectory(<pass name>)
Contents of <project dir>/<pass name>/CMakeLists.txt:
运行cmake编译。产生LLVMPassname.so文件
使用命令行
请阅读知乎的文章
3 使用
opt加载Pass
clang -c -emit-llvm main.c -o main.bc # 随意写一个C代码并编译到bc格式
opt -load path/to/LLVMHello.so -hello main.bc -o /dev/null
把源代码编译成IR代码,然后用opt运行Pass实在麻烦且无趣。
clang加载Pass
clang -Xclang -load -Xclang path/to/LLVMHello.so main.c -o main
# or
clang++ -Xclang -load -Xclang ./build/hello/libLLVMPassname.so test.cpp -o main
实践
插入代码
void InjectSimMagic2(Module &M, Instruction *insertPt, uint64_t arg0, uint64_t arg1, uint64_t arg2)
{
LLVMContext &ctx = M.getContext();
std::vector<Type *> argtype {
Type::getInt64Ty(ctx), Type::getInt64Ty(ctx), Type::getInt64Ty(ctx)
};
FunctionType *ty = FunctionType::get(
Type::getVoidTy(ctx), argtype, false
);
// template of Sniper's SimMagic0
InlineAsm *ia = InlineAsm::get(
ty,
"\tmov $0, %rax \n"
"\tmov $1, %rbx \n"
"\tmov $2, %rcx \n"
"\txchg %bx, %bx\n",
"imr,imr,imr,~{rax},~{rbx},~{rcx},~{dirflag},~{fpsr},~{flags}",
true
);
Value *val0 = ConstantInt::get(IntegerType::get(ctx, 64), arg0);
Value *val1 = ConstantInt::get(IntegerType::get(ctx, 64), arg1);
Value *val2 = ConstantInt::get(IntegerType::get(ctx, 64), arg2);
std::vector<Value *> arglist {val0, val1, val2};
CallInst::Create(
ia, arglist, "", insertPt);
}
这段代码使用内联汇编嵌入到 LLVM IR 中,指令如下:
其中:
- mov $0, %rax 将立即数 arg0 装载到通用寄存器 %rax 中。
- mov $1, %rbx 将立即数 arg1 装载到通用寄存器 %rbx 中。
- mov $2, %rcx 将立即数 arg2 装载到通用寄存器 %rcx 中。
- xchg %bx, %bx 是一条无操作指令,用于保证该汇编代码的原子性。
打印每个BBL内的汇编指令
由于直接打印的是llvm IR的表示,想要打印特定架构比如x86的汇编代码,其实需要进行llvm后端的转换。(取巧,可执行文件反汇编,然后根据插入的汇编桩划分)
需要进一步的研究学习
暂无
遇到的问题
暂无
开题缘由、总结、反思、吐槽~~
复现PIMProf论文时,用到了使用 llvm pass来插入特殊汇编
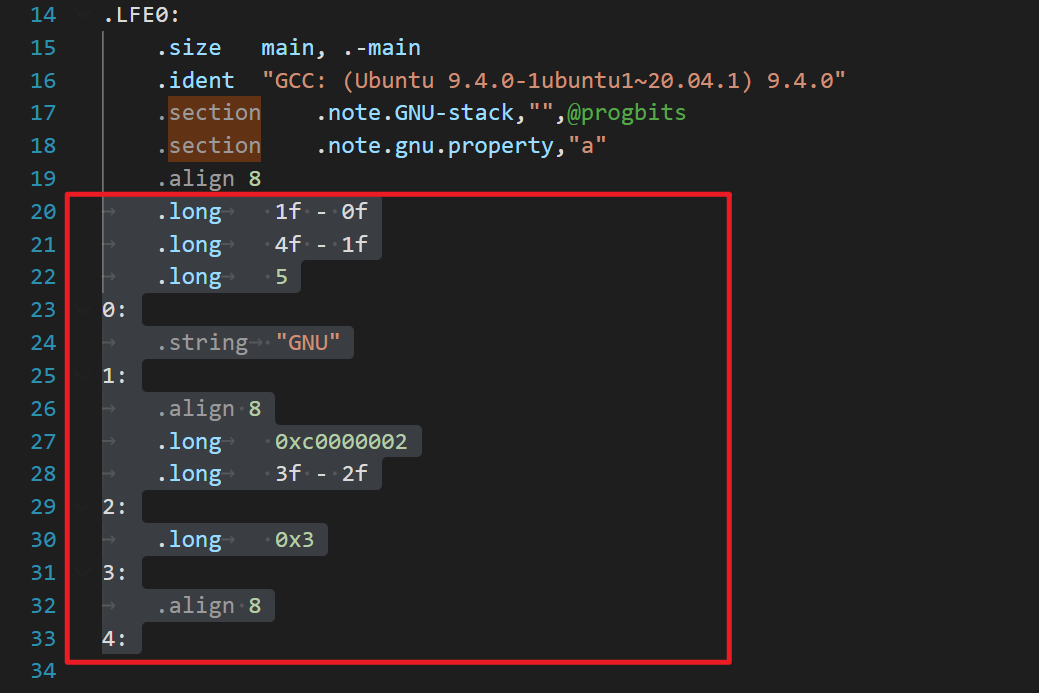
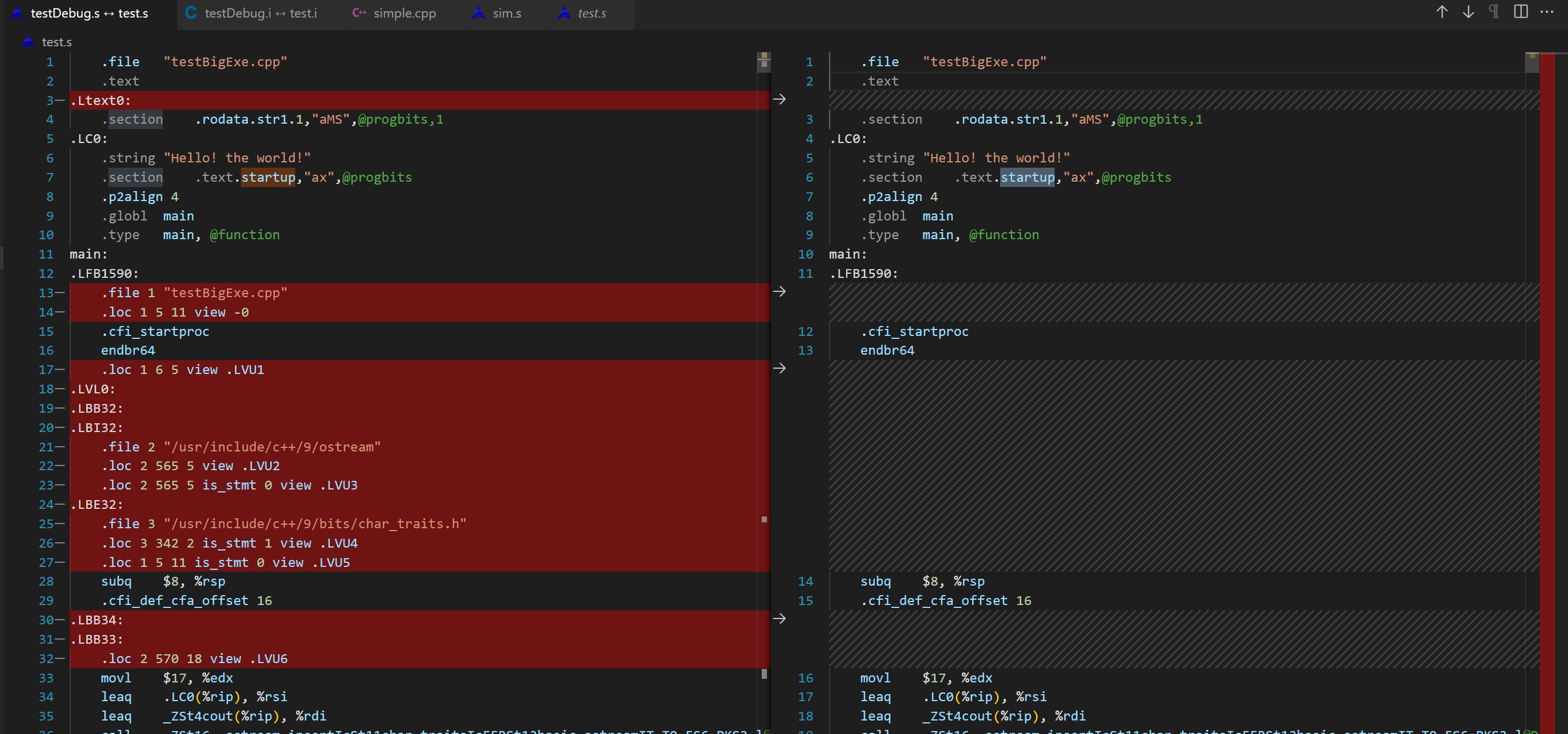

 [^1]
[^1]
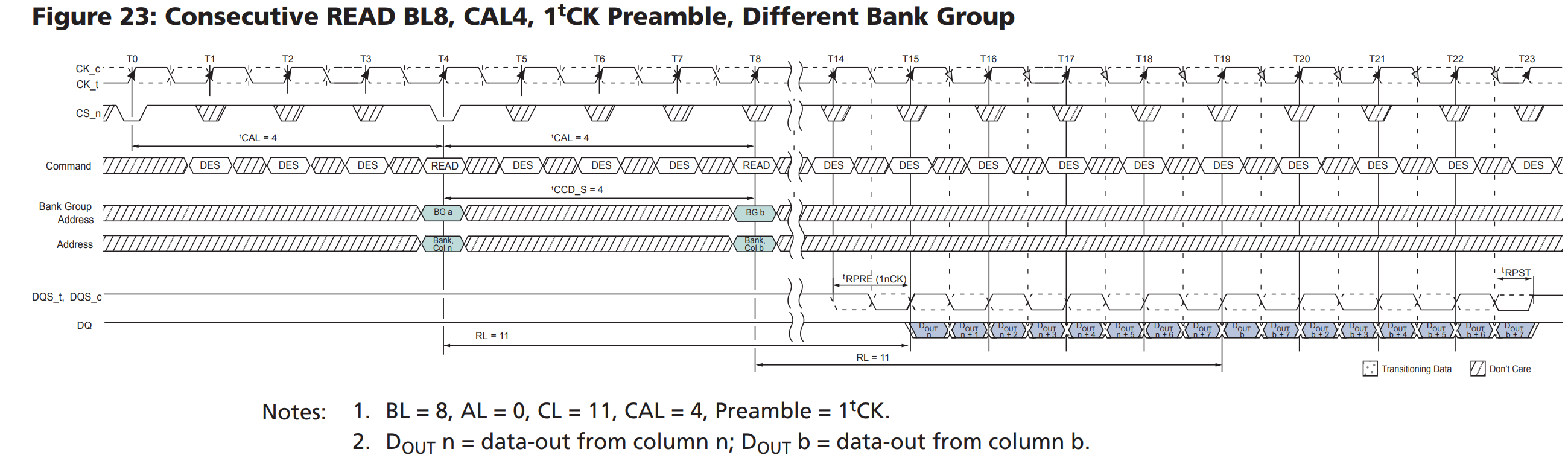
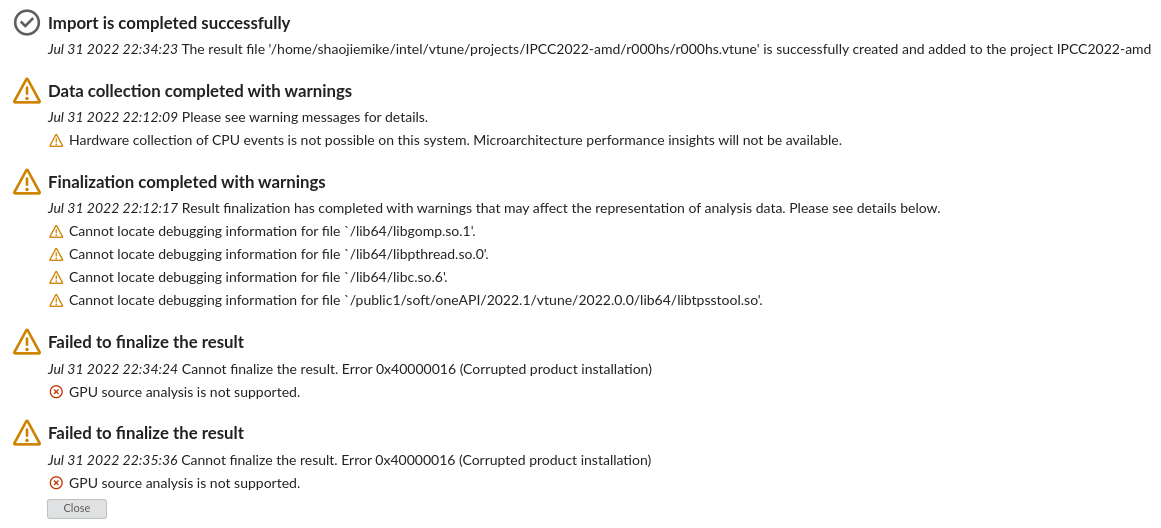
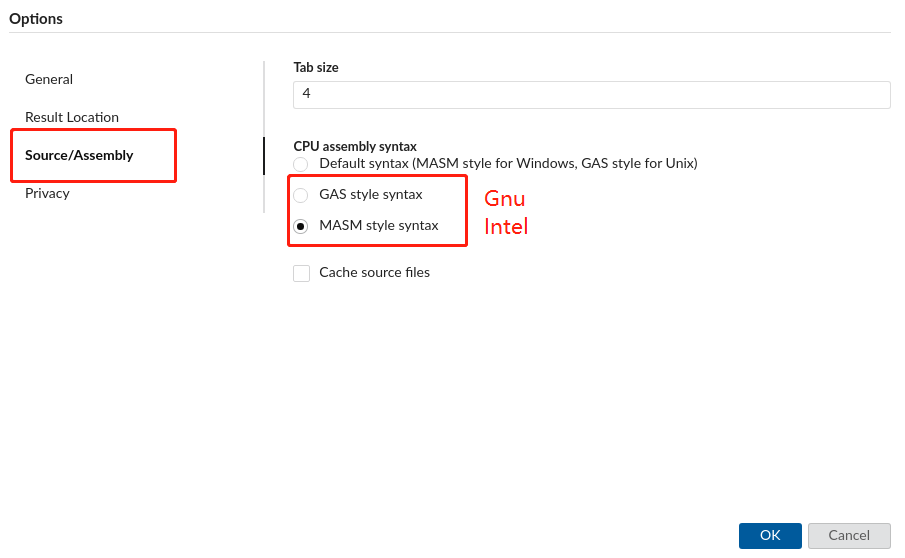
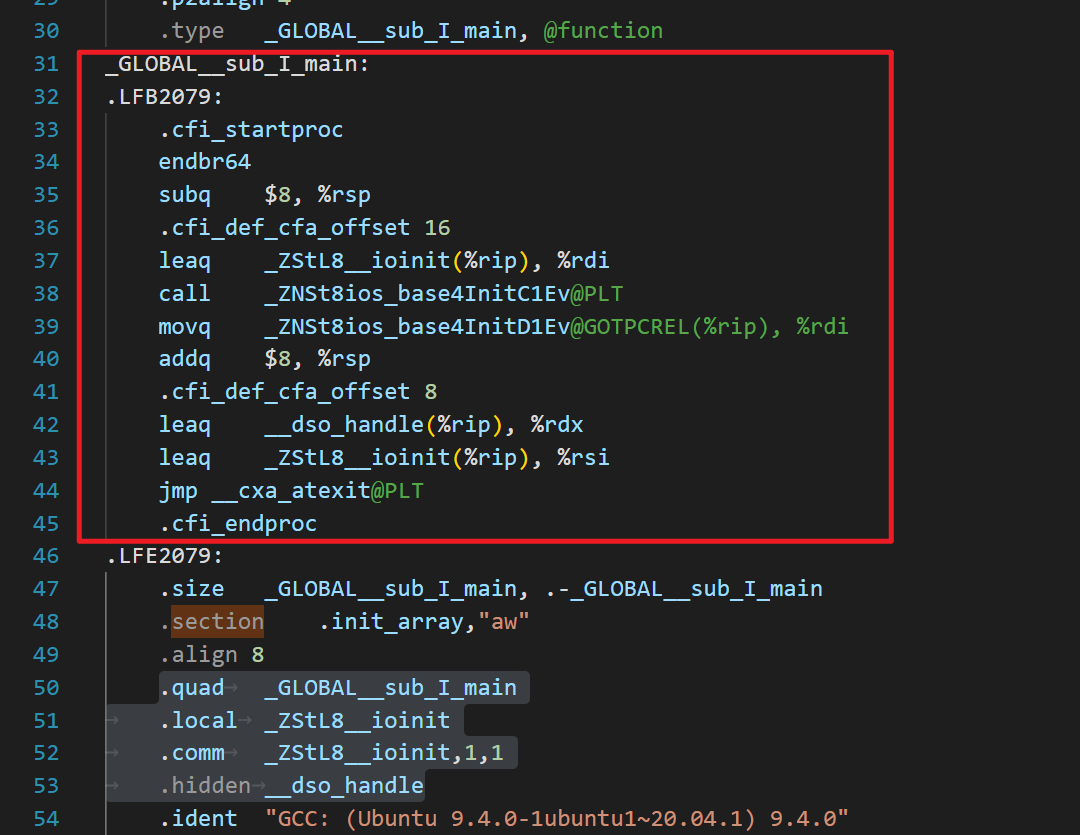
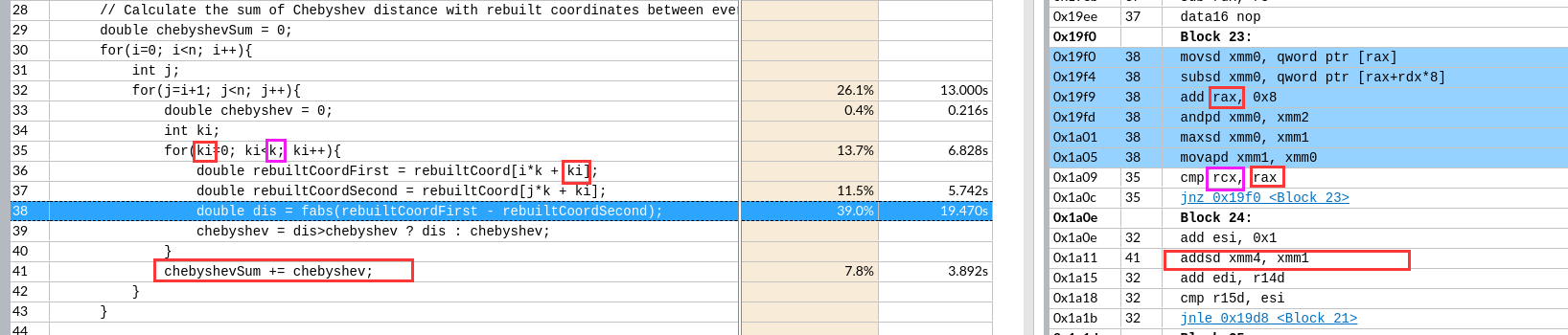
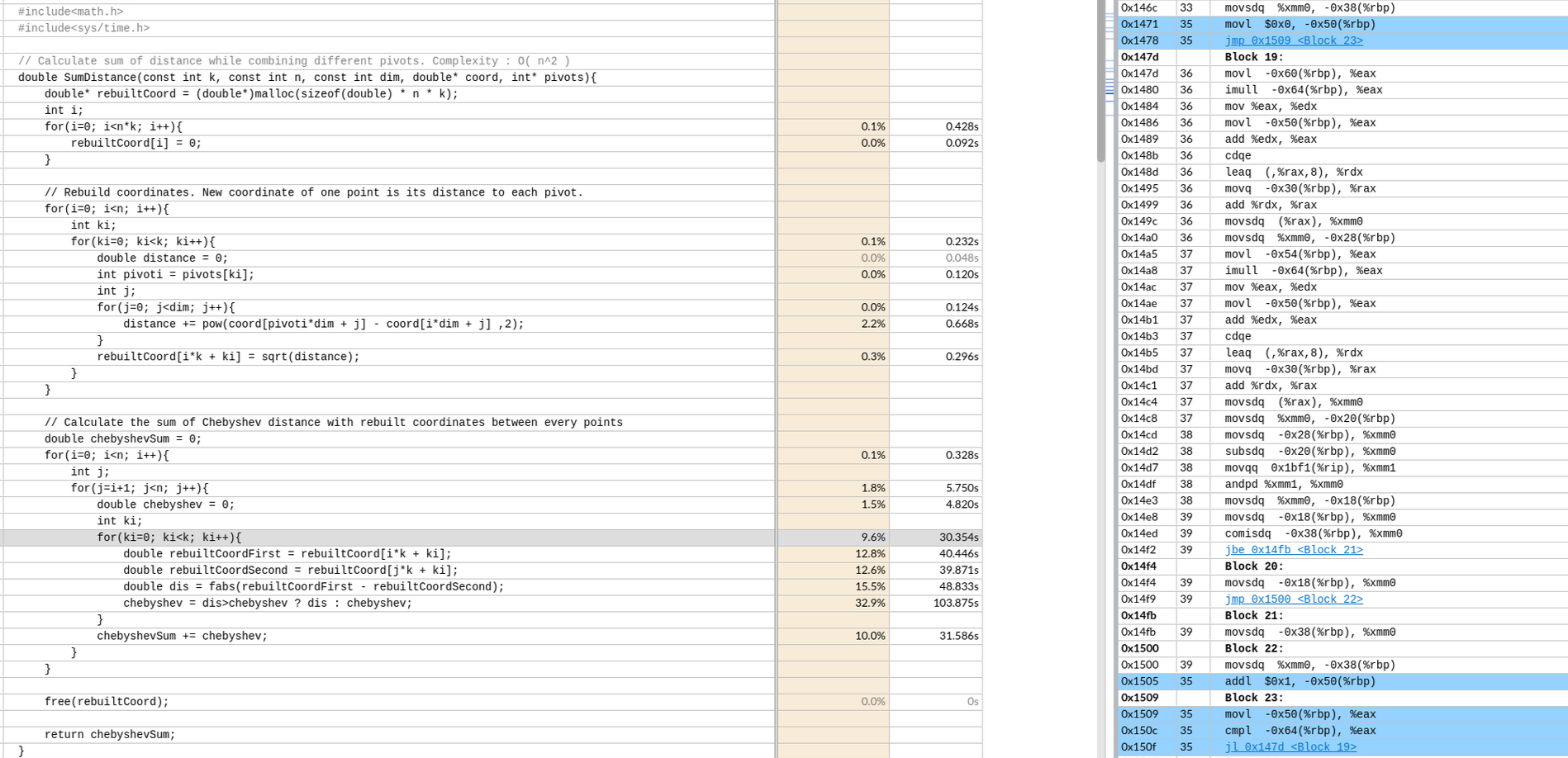 偏移 -64 是k
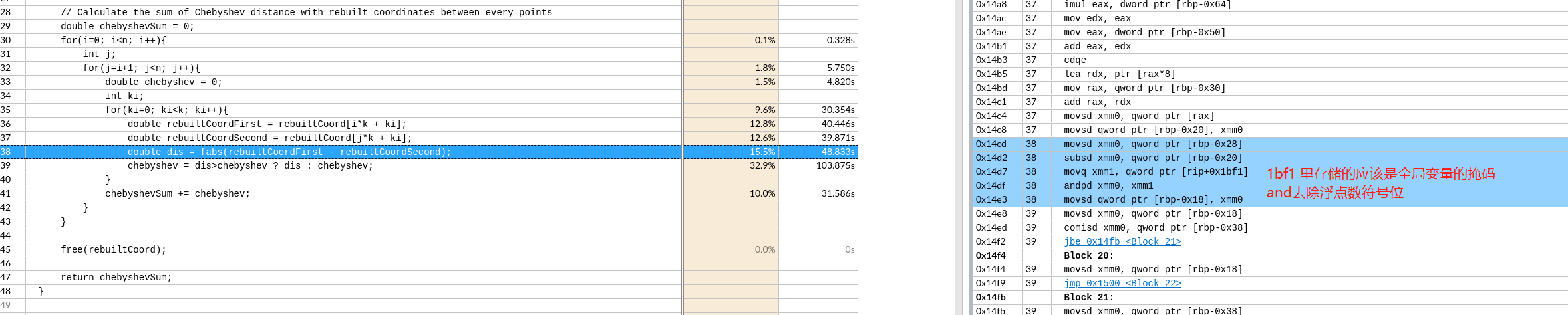
偏移 -64 是k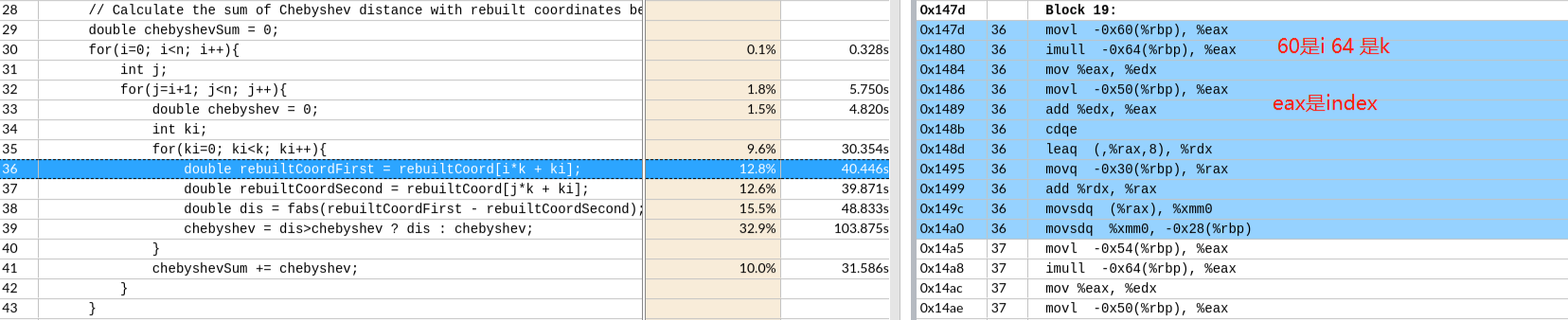 CDQE复制EAX寄存器双字的符号位(bit 31)到RAX的高32位。
CDQE复制EAX寄存器双字的符号位(bit 31)到RAX的高32位。



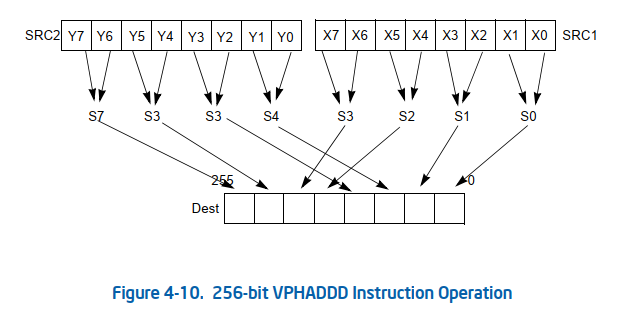
 下图是avx512的
下图是avx512的
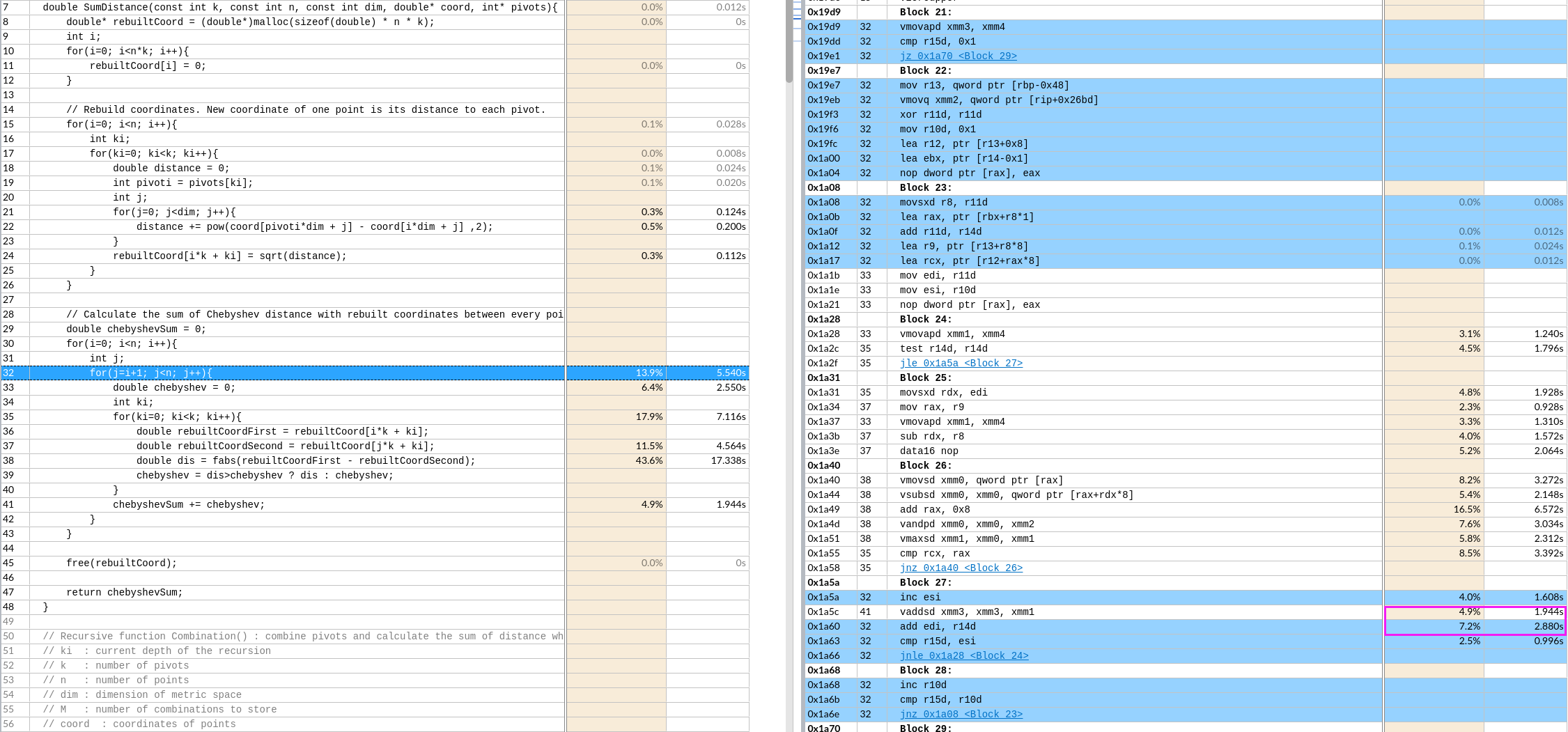
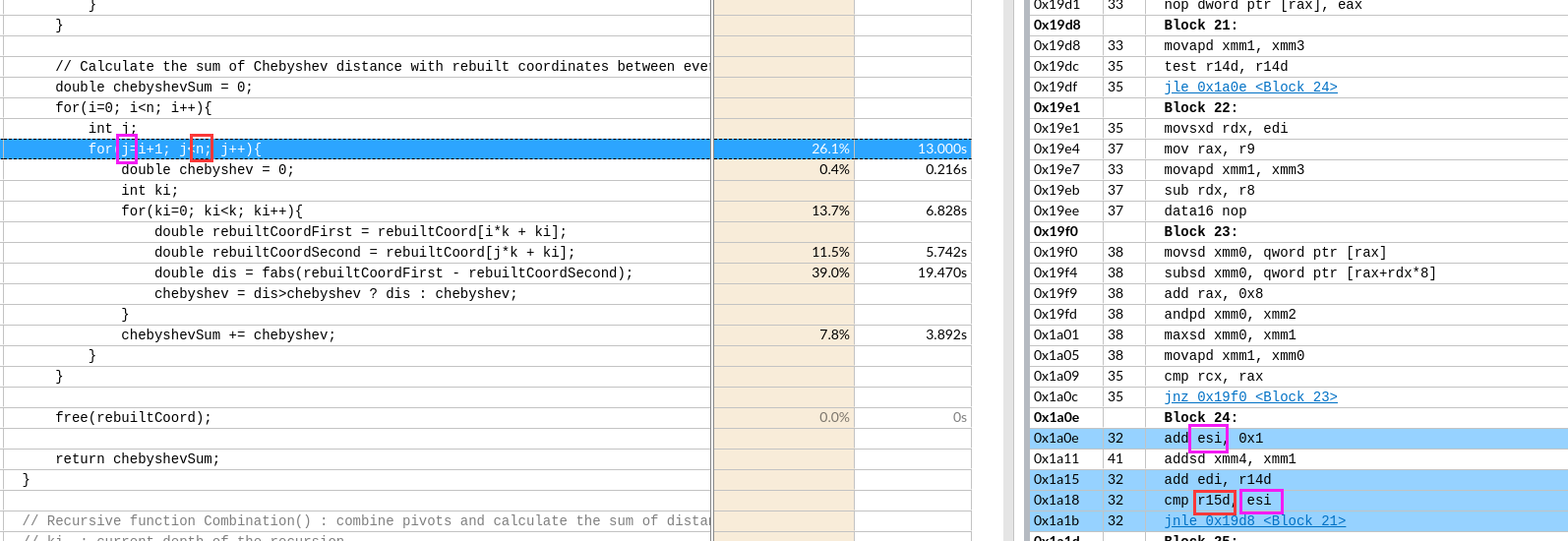
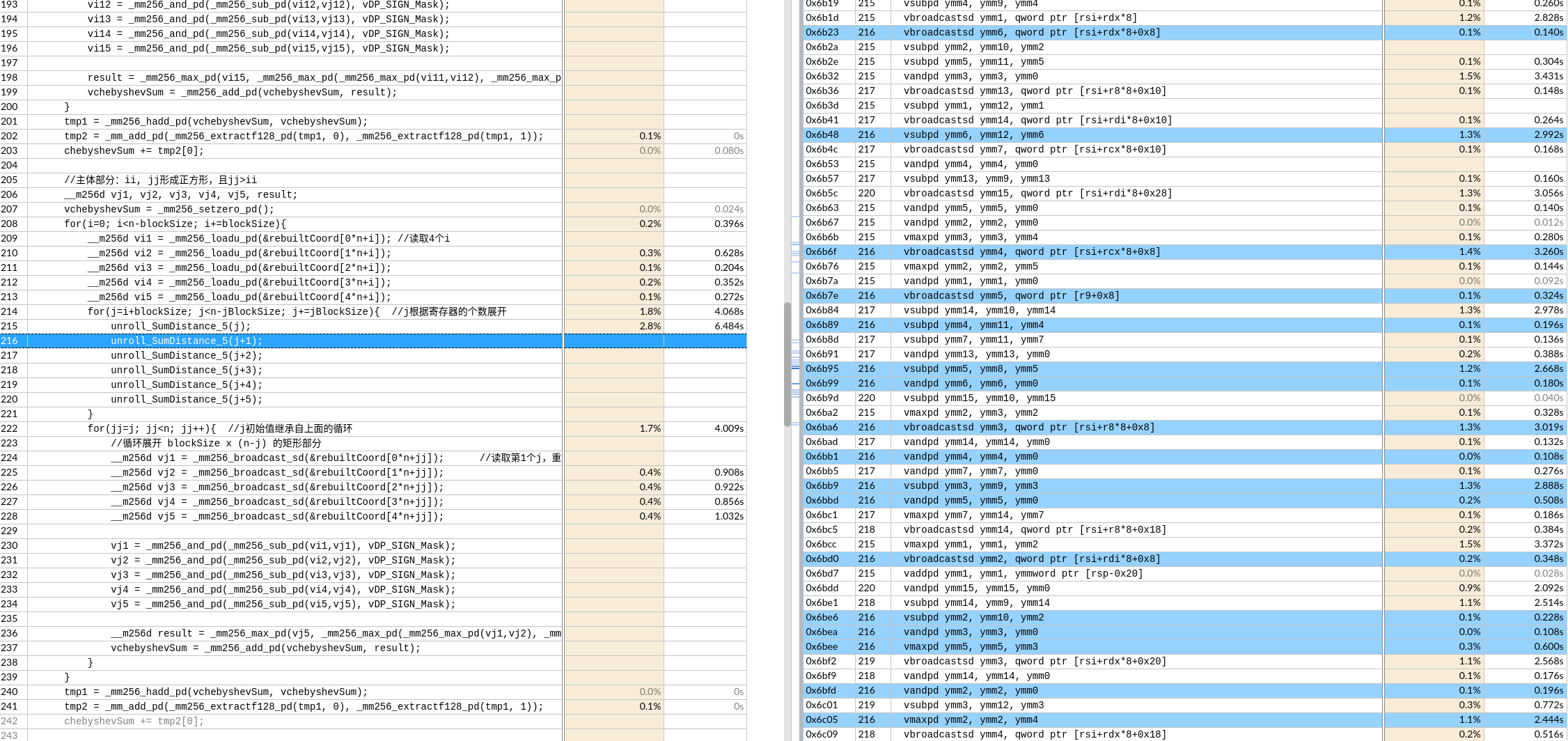
 默认是展开了8层,这应该和xmm寄存器总数有关
默认是展开了8层,这应该和xmm寄存器总数有关
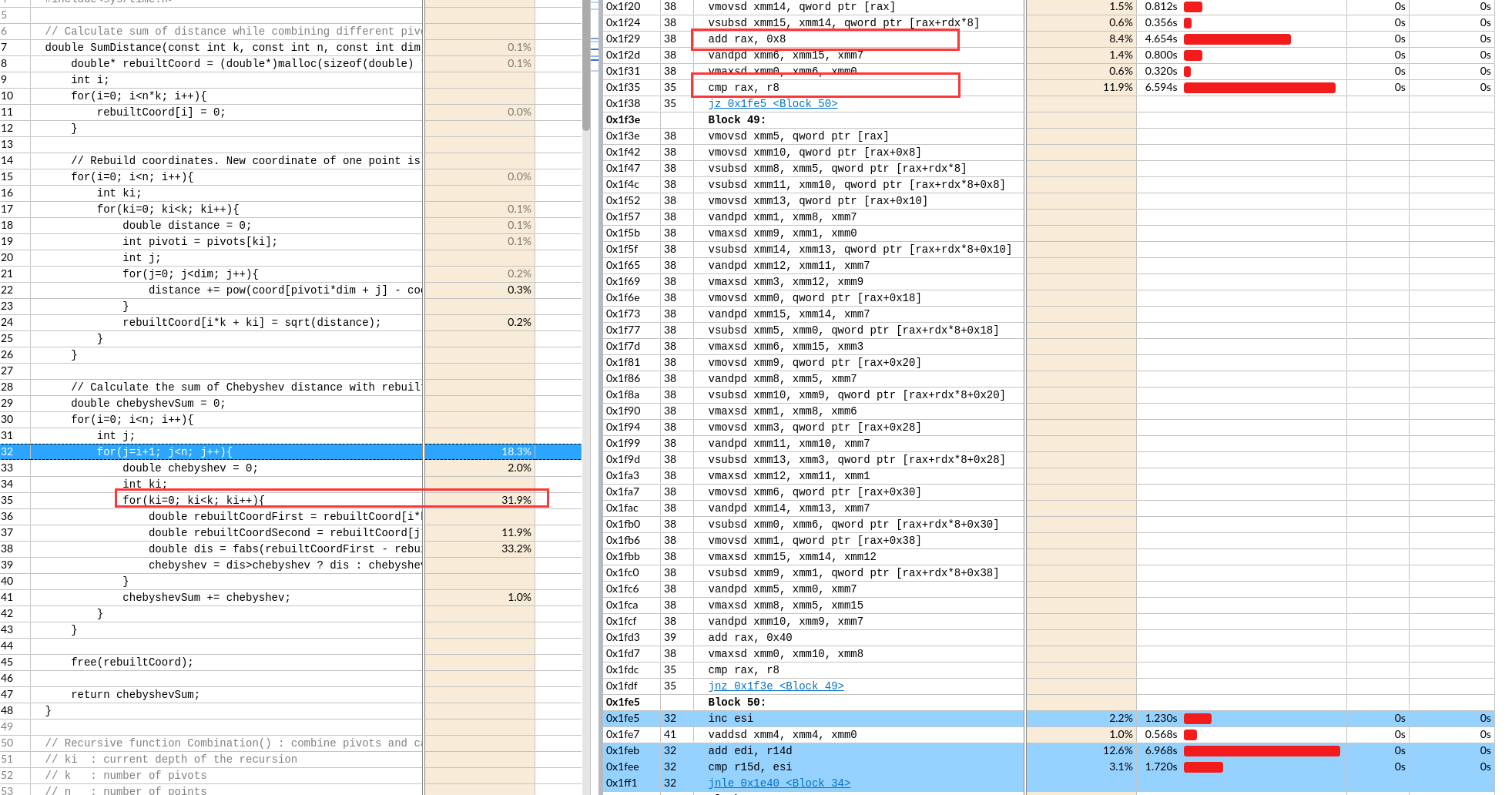
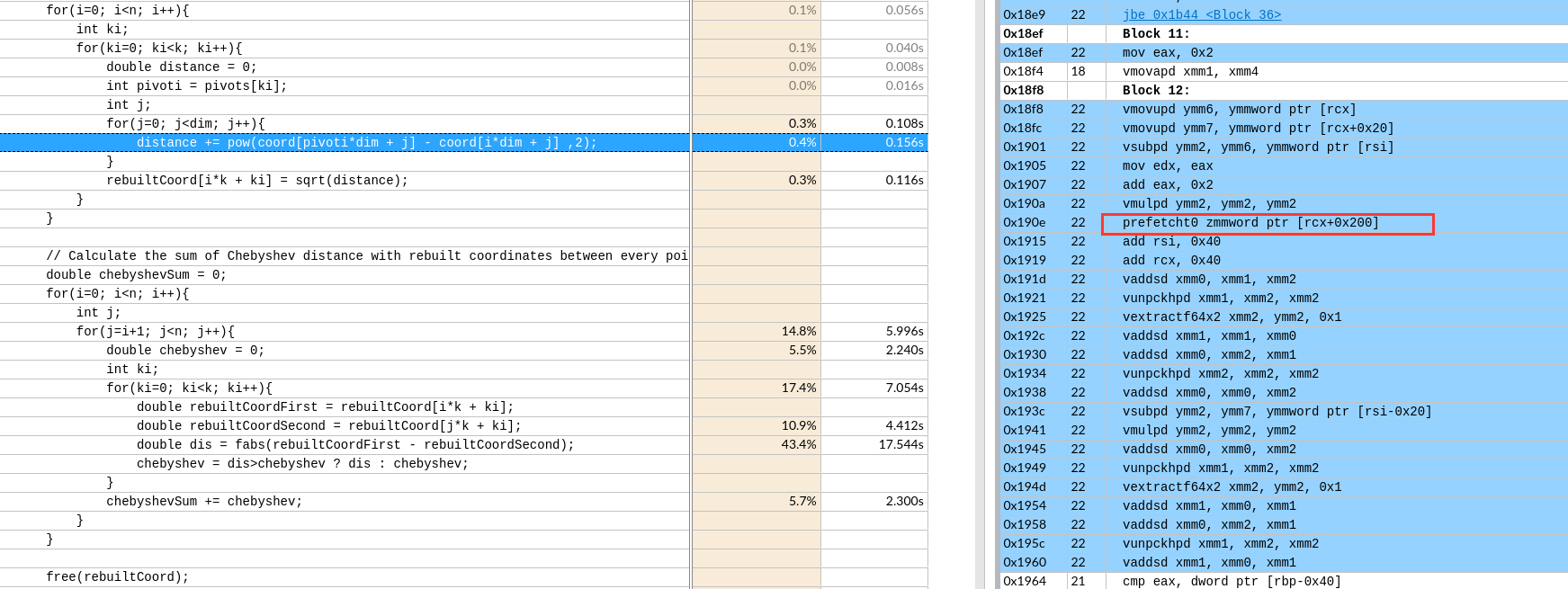
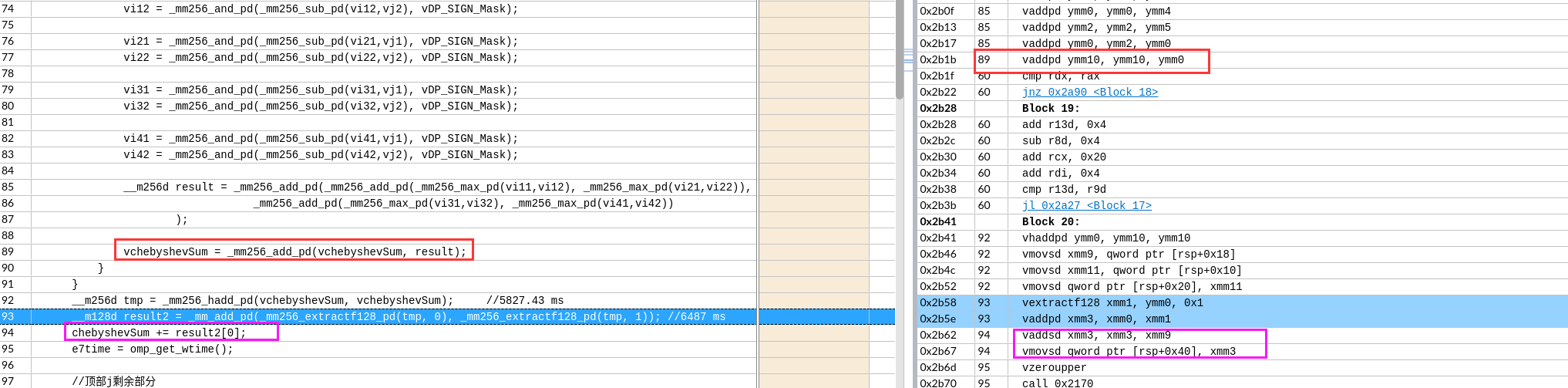
 每次预取一个Cache Line,后面两条指令预取的数据还有重复部分(导致时间增加 39s->61s)
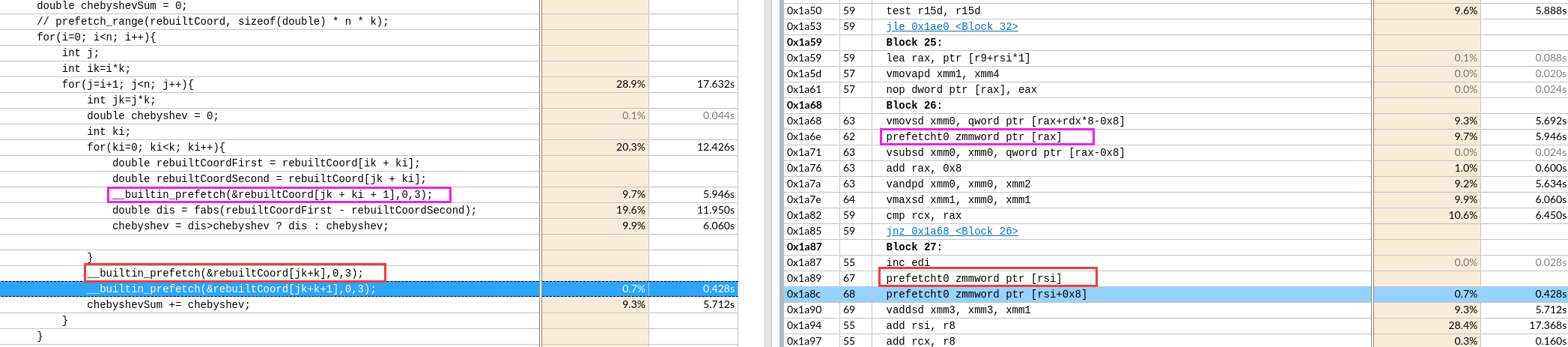
每次预取一个Cache Line,后面两条指令预取的数据还有重复部分(导致时间增加 39s->61s)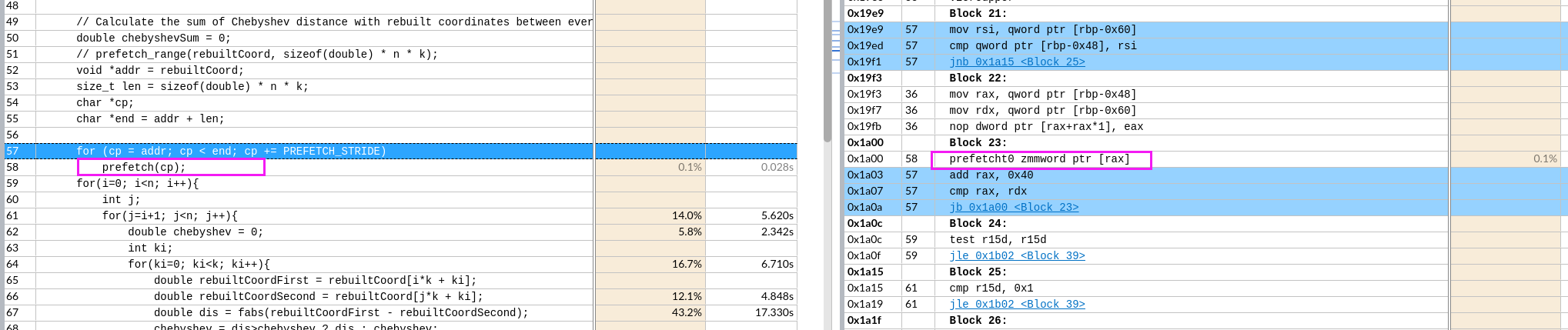 想预取全部,循环每次预取了512位=64字节
想预取全部,循环每次预取了512位=64字节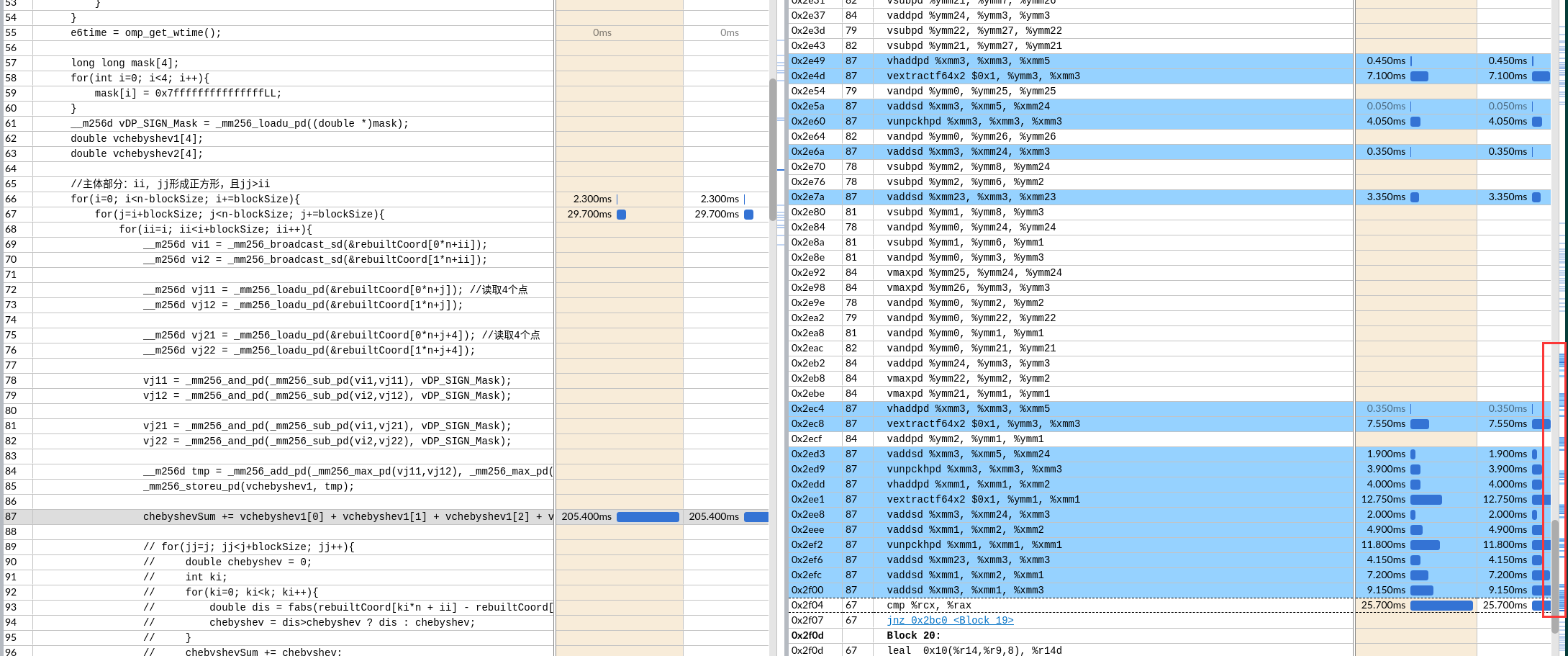
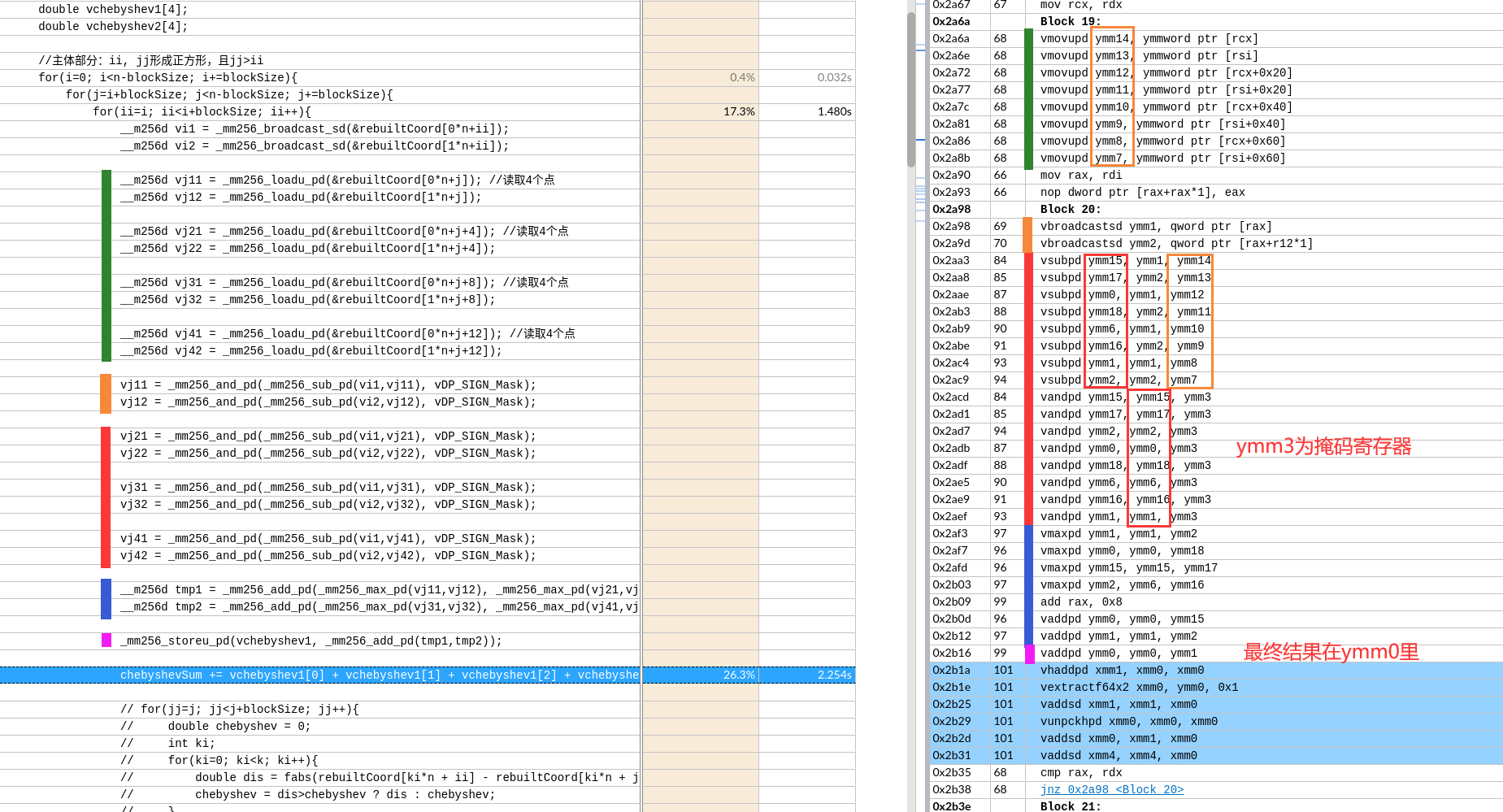
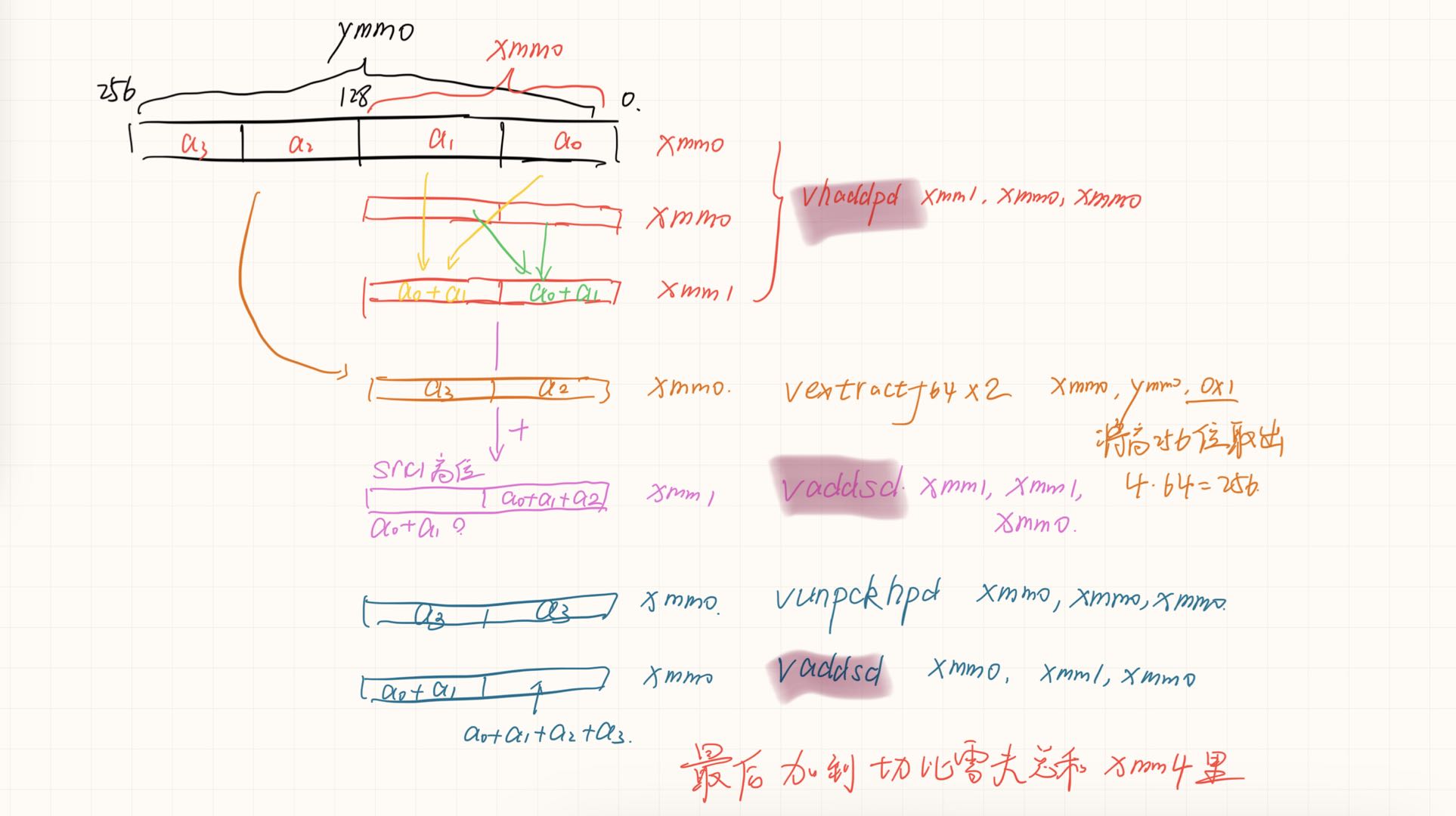
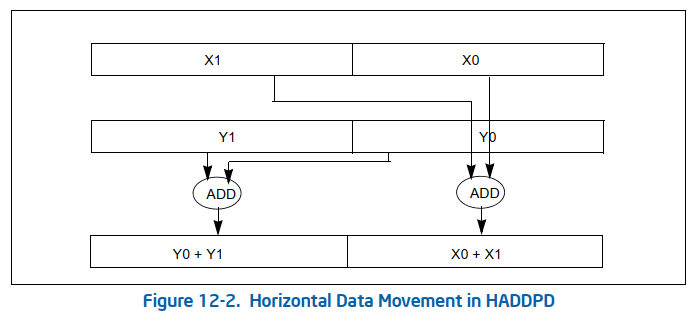
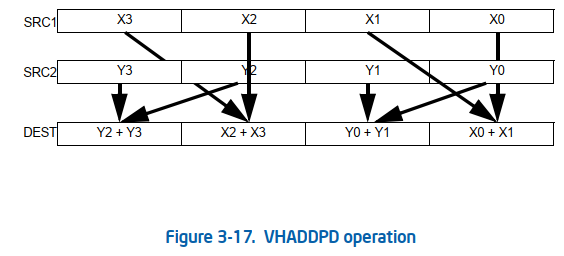
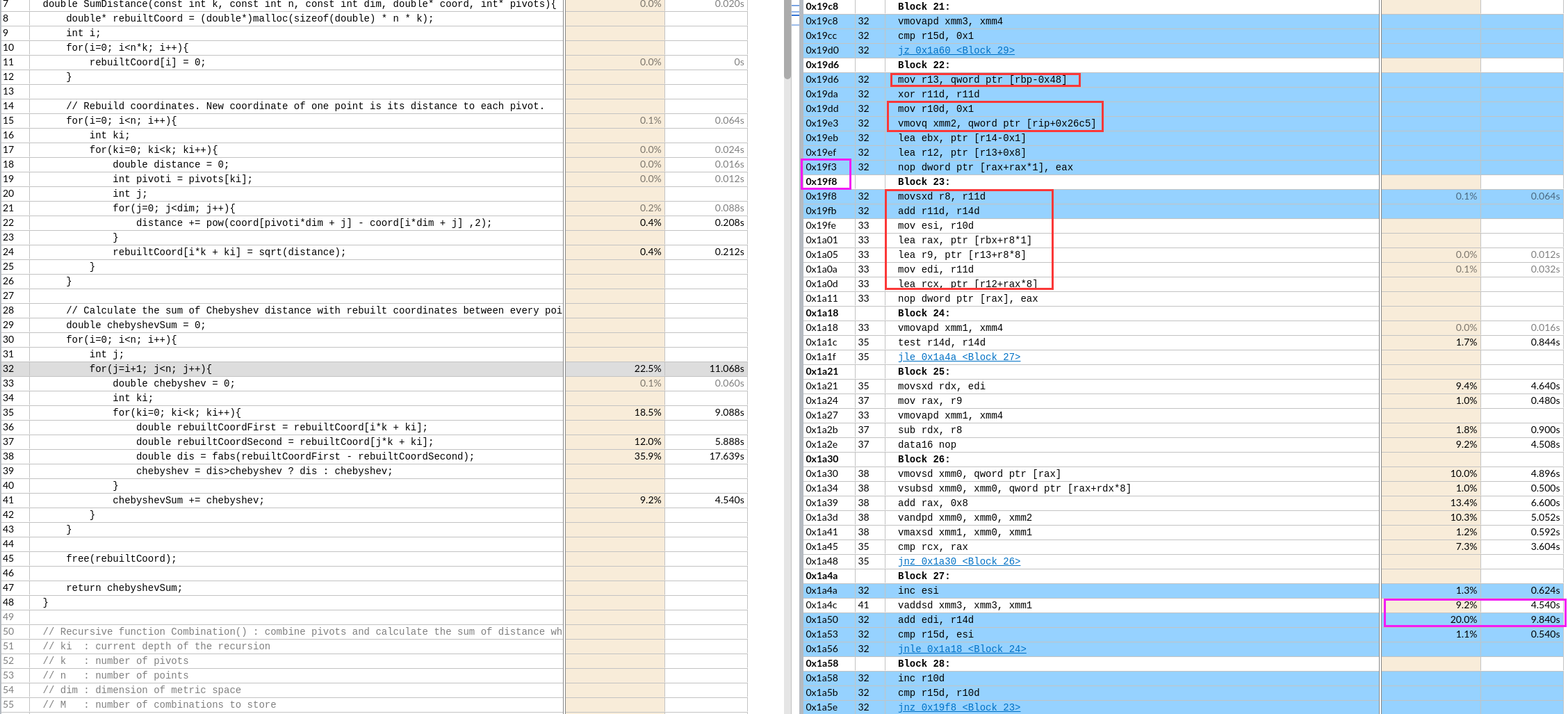
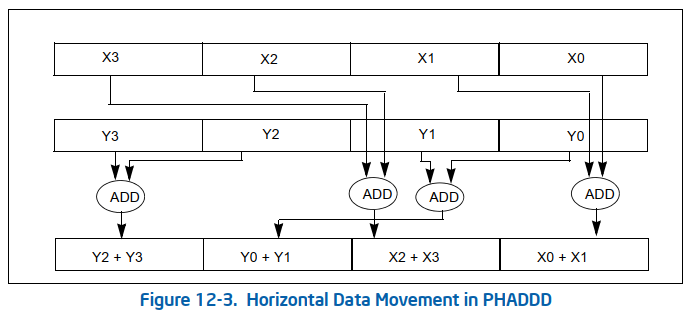
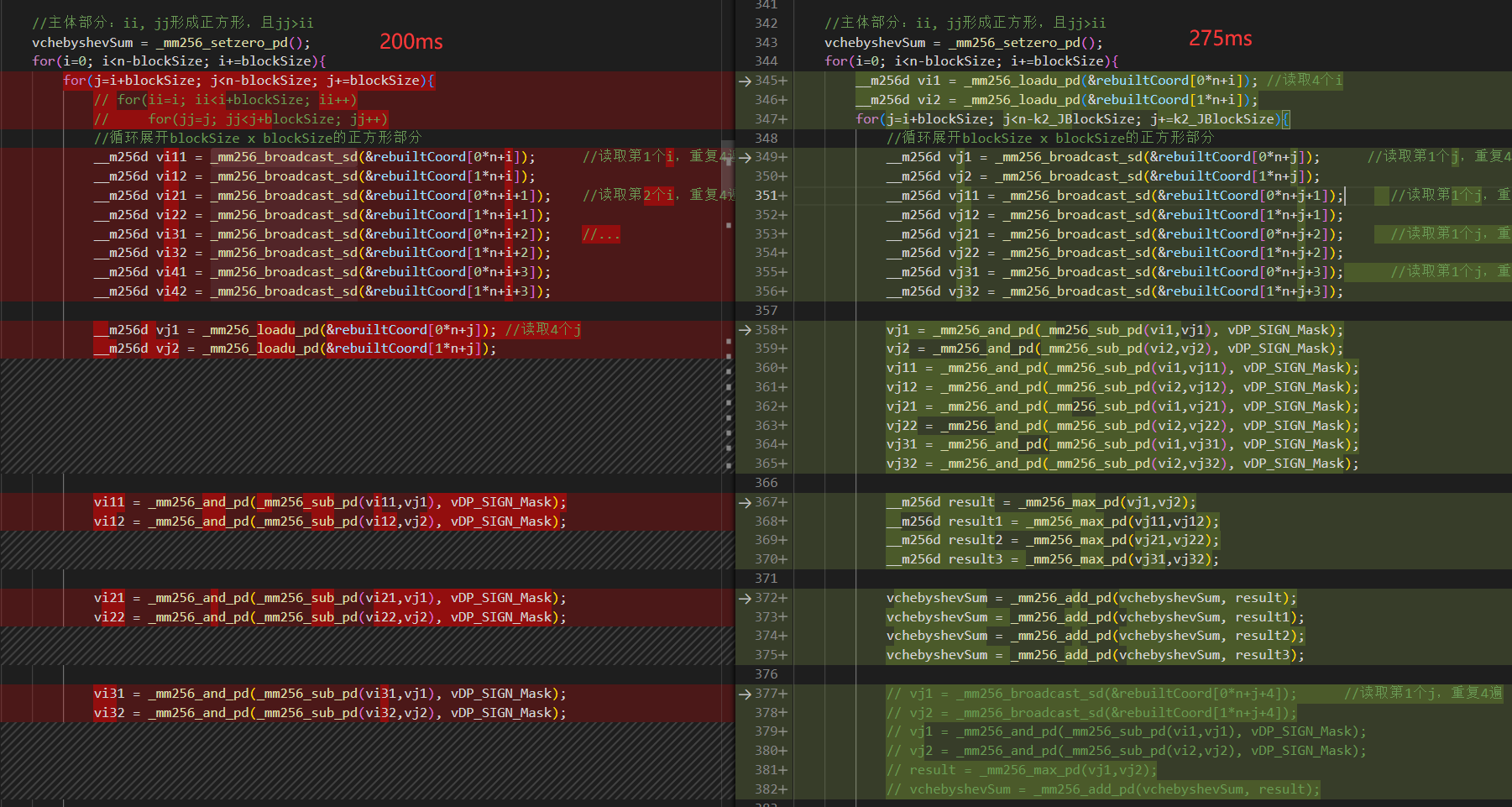
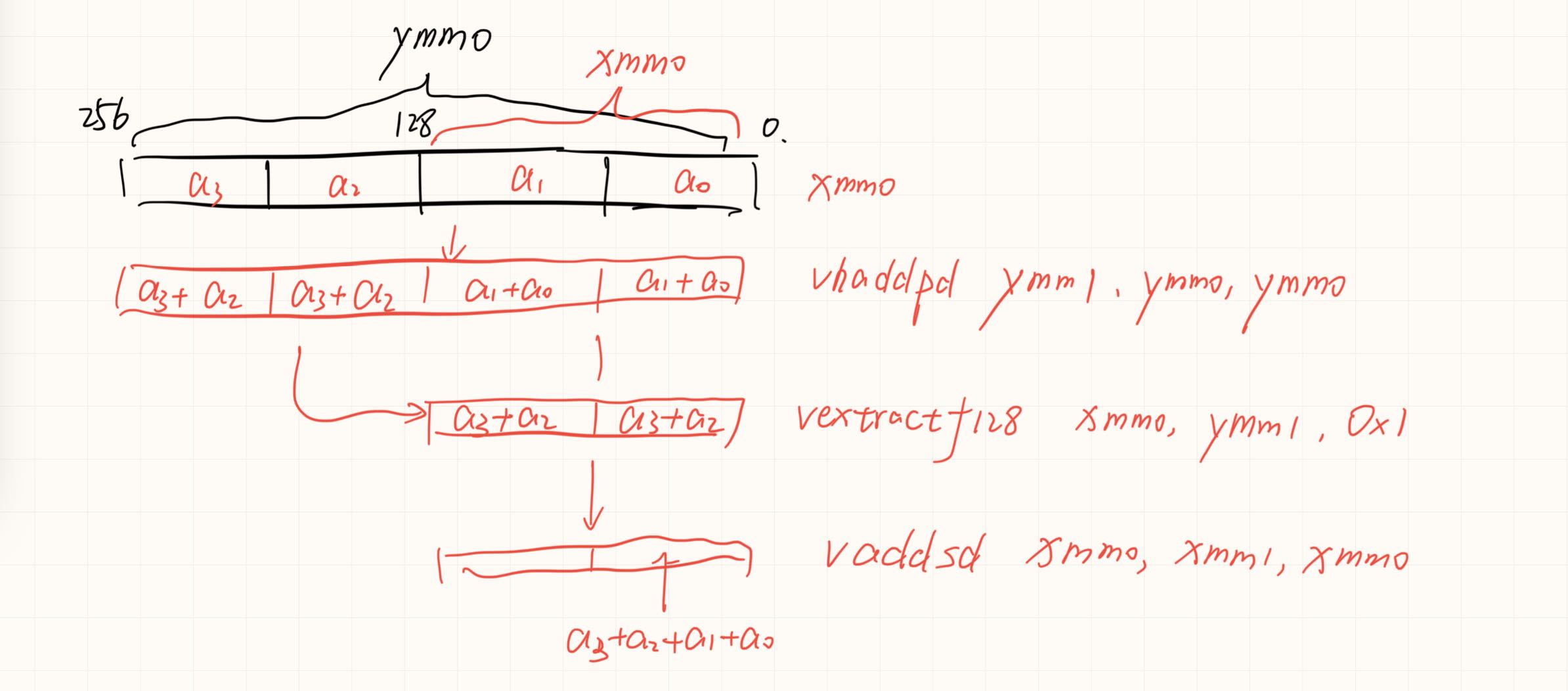 如果可以实现会节约一次数据移动和一次数据add。没有分析两种情况的寄存器依赖。可能依赖长度是一样的,导致优化后时间反而增加一点。
如果可以实现会节约一次数据移动和一次数据add。没有分析两种情况的寄存器依赖。可能依赖长度是一样的,导致优化后时间反而增加一点。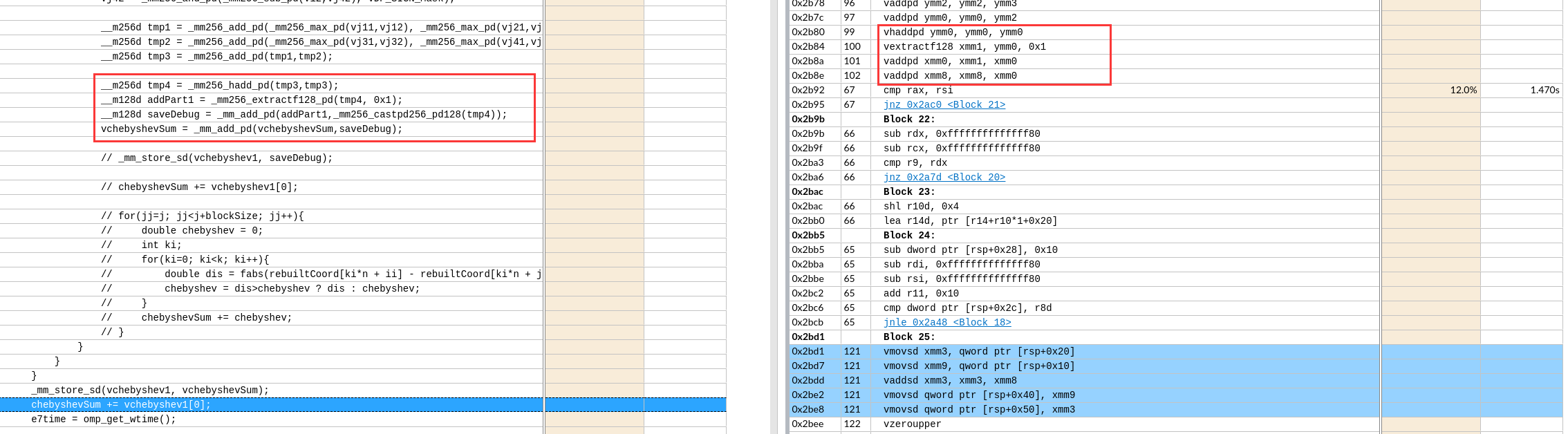
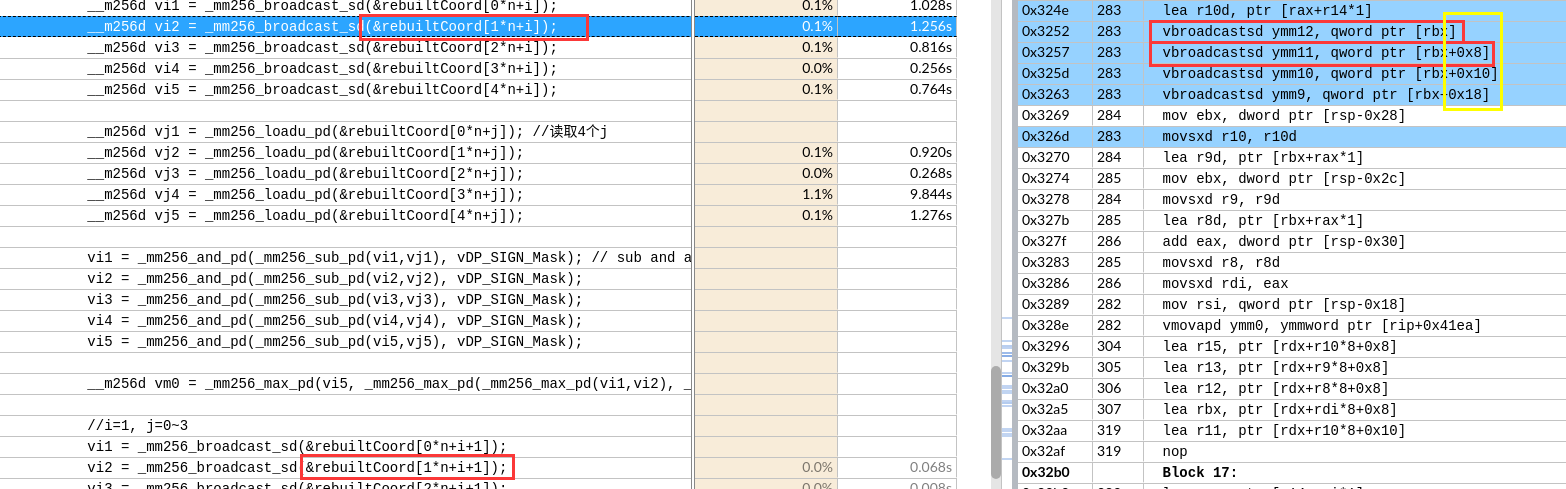



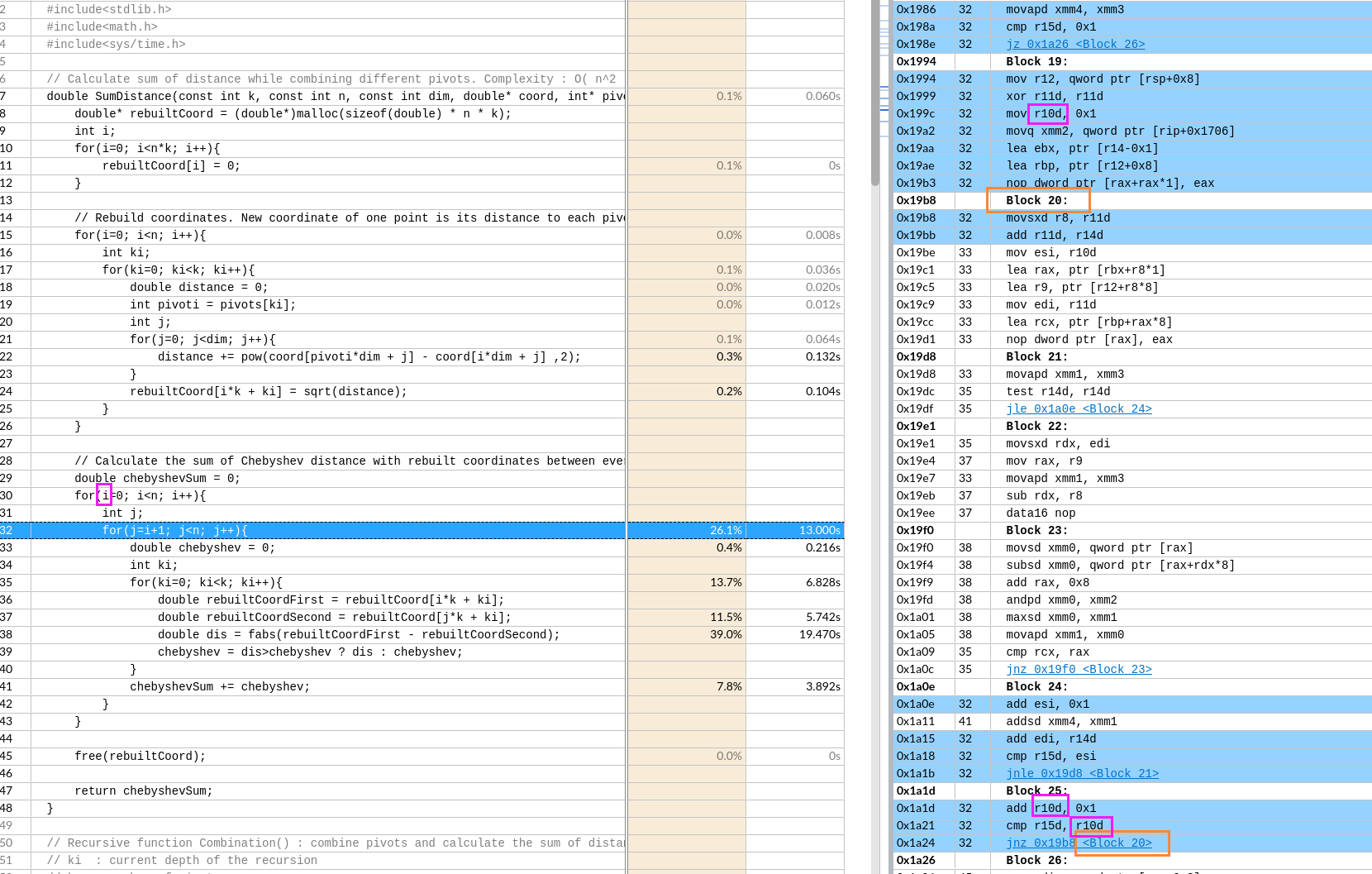
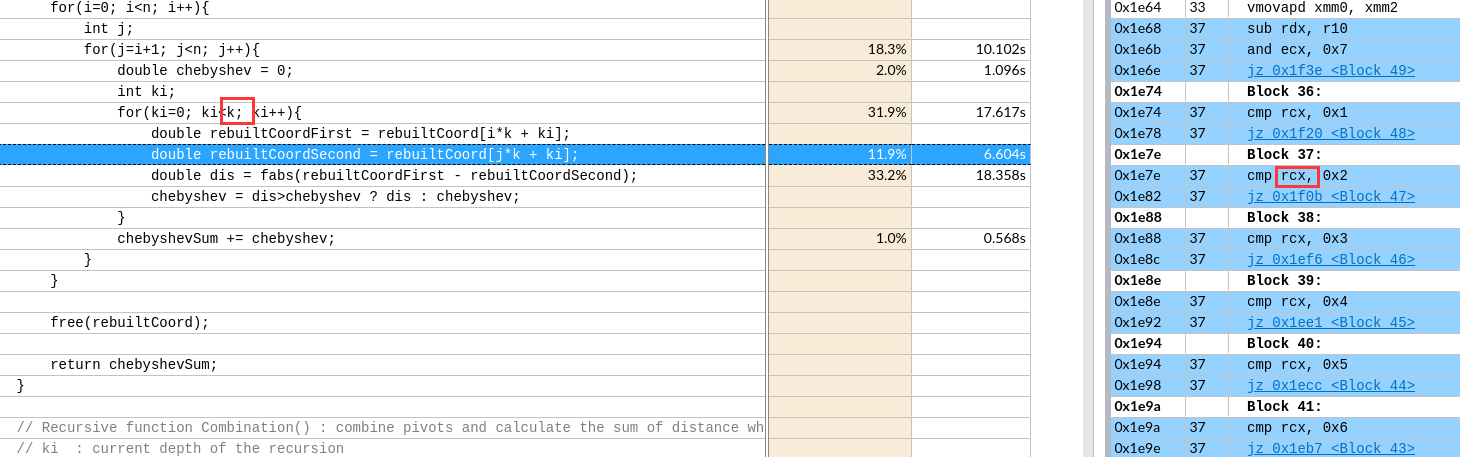
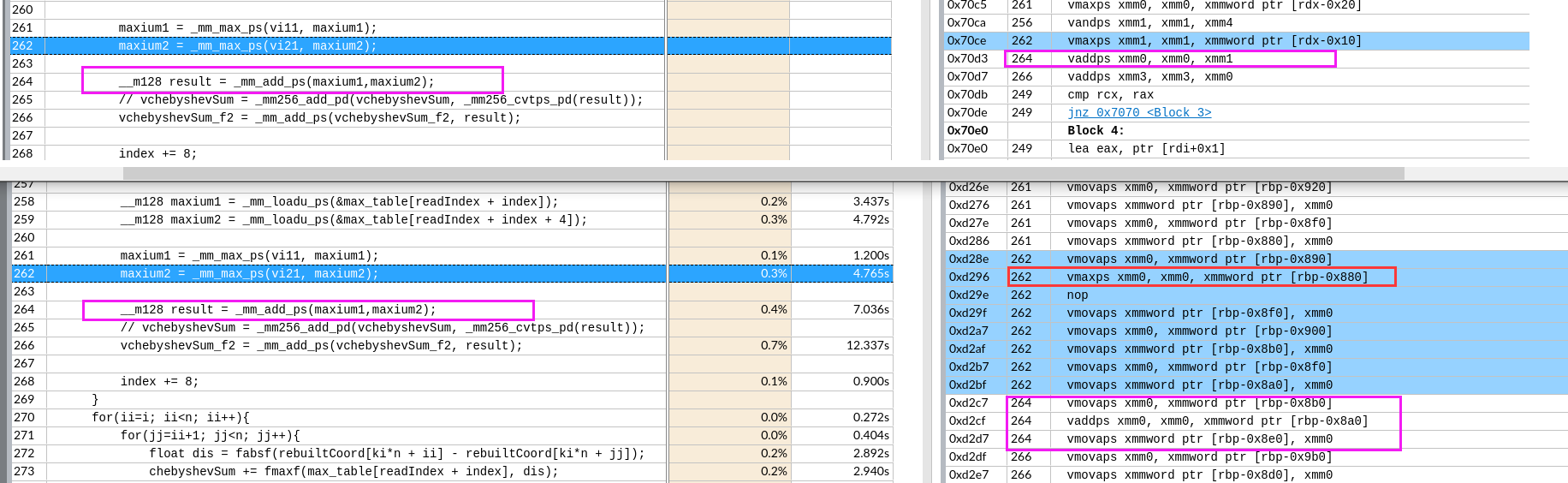
 左图外层load了8个寄存器,但是右边只有2个。
左图外层load了8个寄存器,但是右边只有2个。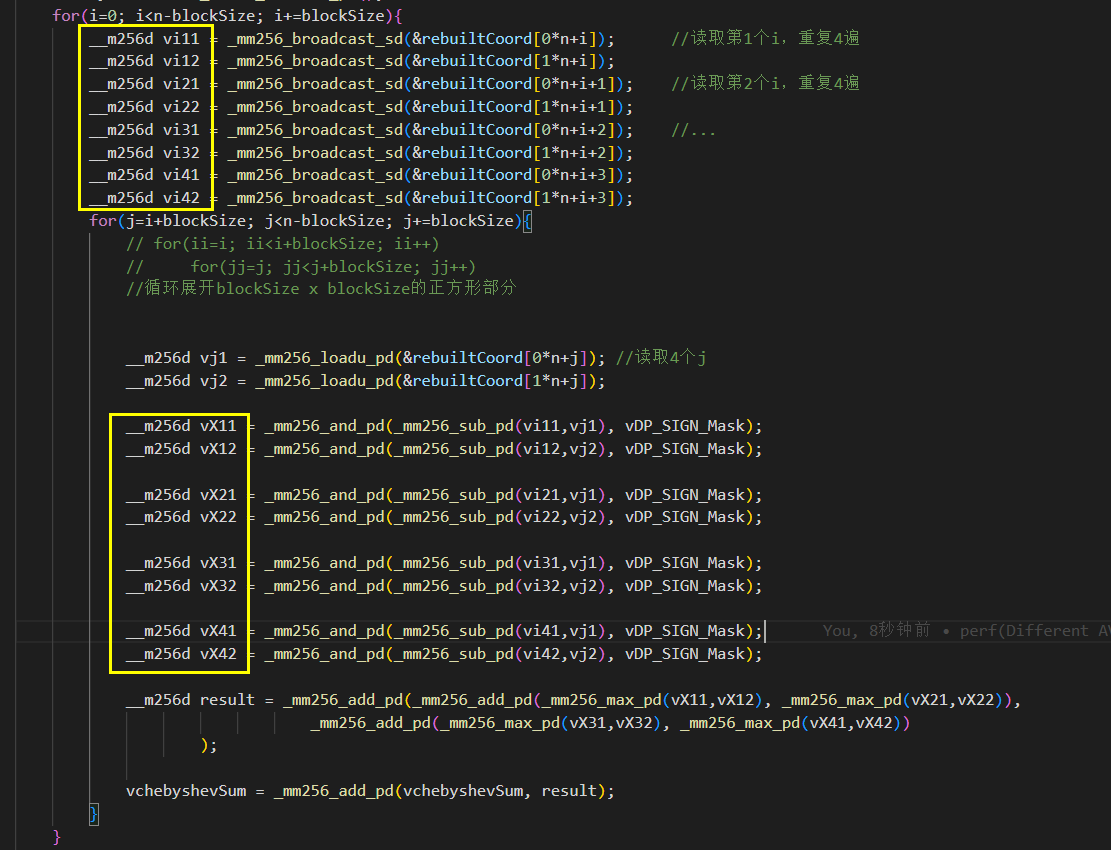 如图,黄框就有16个了。
如图,黄框就有16个了。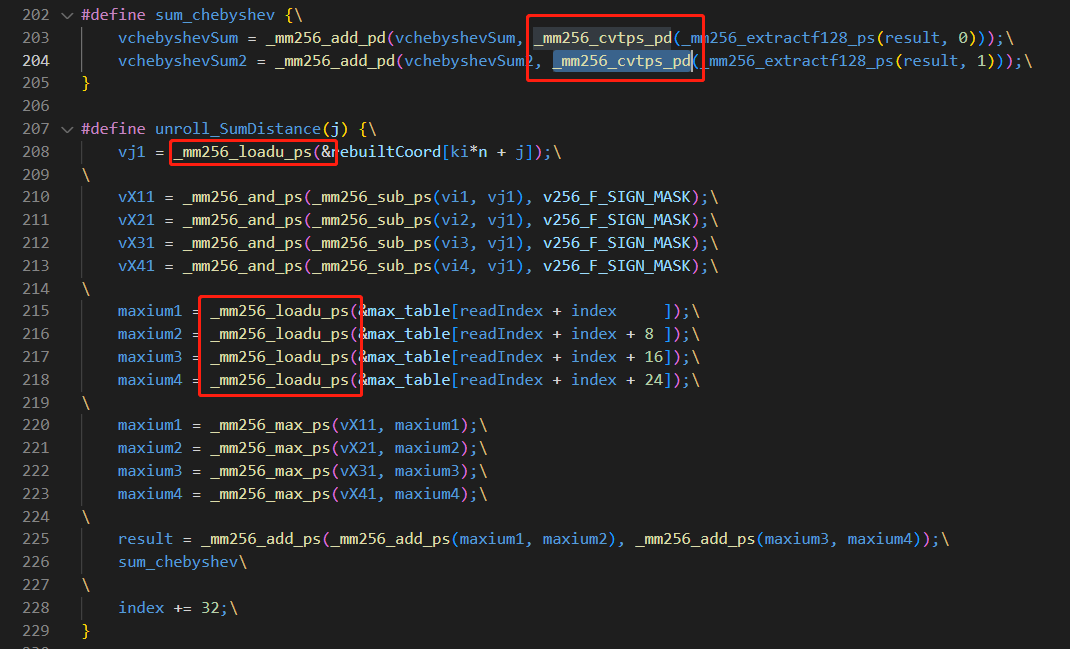
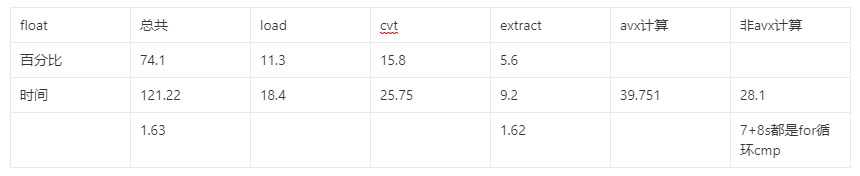

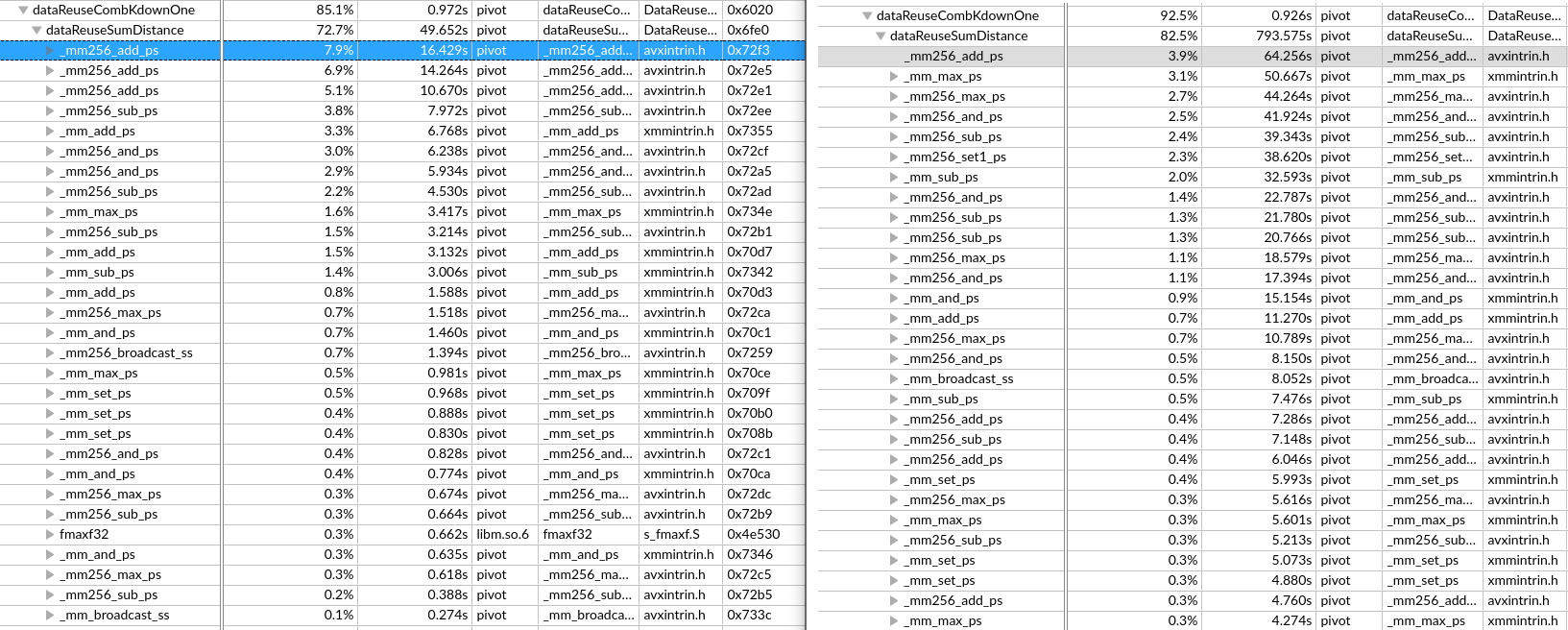


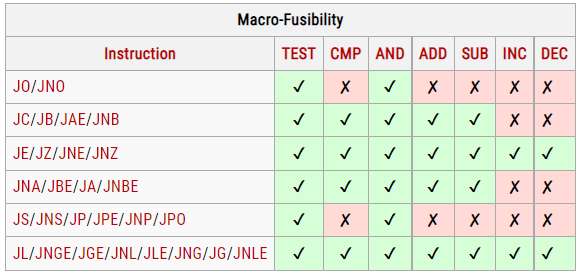
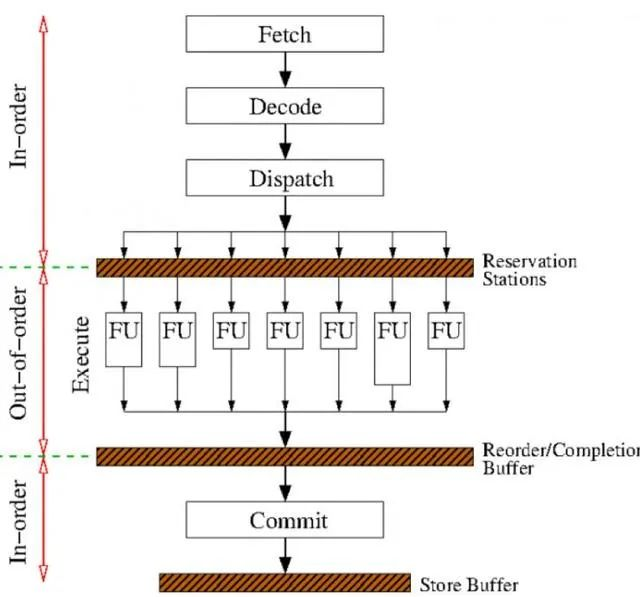
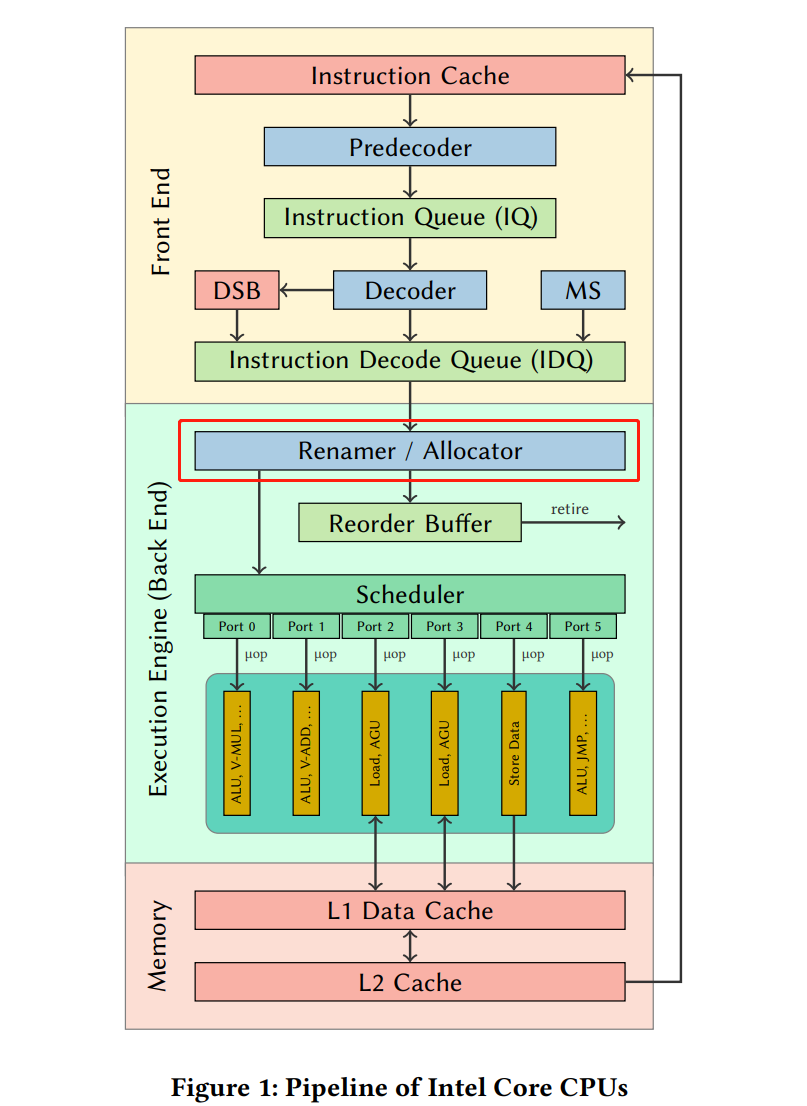
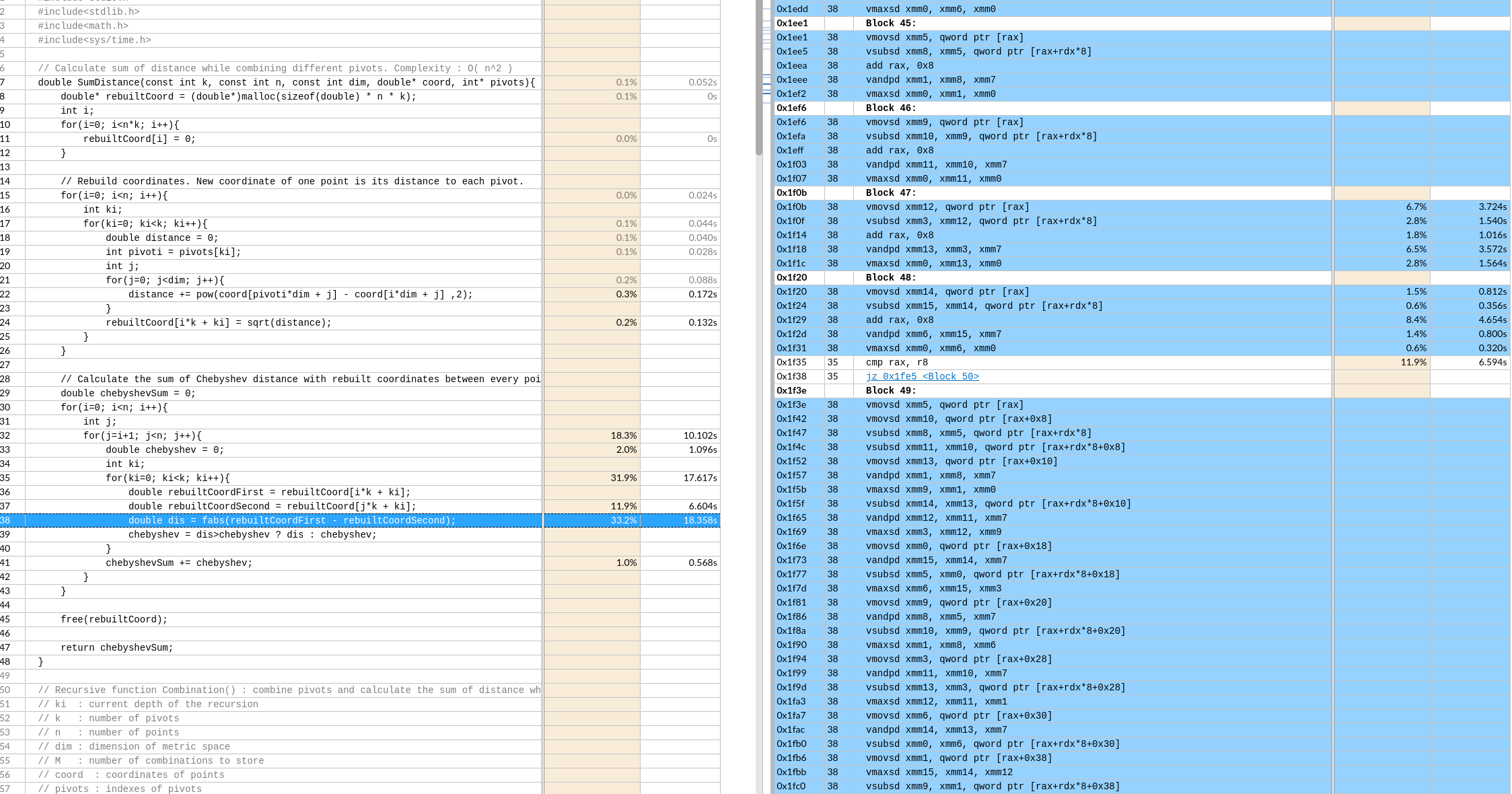
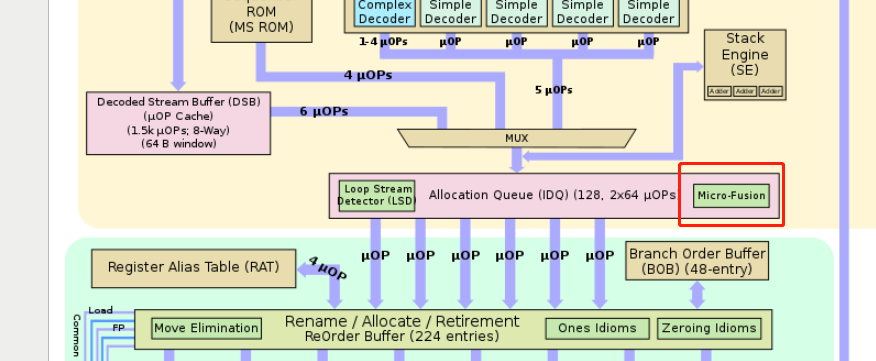 在RAT以及RRF阶段,把同一条指令的几个μops混合成一个复杂的μop,使得其只占用一项(比如在ROB里,但是Unlaminated μops会占用2 slots);
在RAT以及RRF阶段,把同一条指令的几个μops混合成一个复杂的μop,使得其只占用一项(比如在ROB里,但是Unlaminated μops会占用2 slots);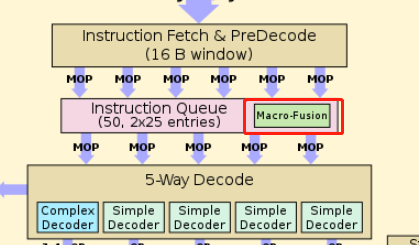 在IQ时读取指令流,把两条指令组合成一个复杂的μop,并且在之后decode等流水线各个阶段都是认为是一项uops。
在IQ时读取指令流,把两条指令组合成一个复杂的μop,并且在之后decode等流水线各个阶段都是认为是一项uops。