Memory Consistency and Cache Coherence
导言
许多现代计算机系统,包括同构和异构体系结构,都支持硬件中的共享内存。在共享内存系统中,每个处理器内核可以对单个共享地址空间进行读写。
要拓展Victima模拟器的cache部分,首先要明白一些缓存一致性的基础知识。
导言
许多现代计算机系统,包括同构和异构体系结构,都支持硬件中的共享内存。在共享内存系统中,每个处理器内核可以对单个共享地址空间进行读写。
要拓展Victima模拟器的cache部分,首先要明白一些缓存一致性的基础知识。
导言
在与袁福焱交流他的GPU Design Space Exploration的工作内容时,发现和我PIM模拟器Zsim, Sniper的原理是异曲同工,师出本源的方法。
导言
more clear about the connection and 3D-stacked Mem.
导言
之前ipcc比赛认为很神奇的CPU侧的double2int8的转换,其实思想就是AI推理的常见低比特量化思路。
Disassembly of section .plt:
0000000000402020 <.plt>:
402020: ff 35 e2 bf 02 00 pushq 0x2bfe2(%rip) # 42e008 <_GLOBAL_OFFSET_TABLE_+0x8>
402026: ff 25 e4 bf 02 00 jmpq *0x2bfe4(%rip) # 42e010 <_GLOBAL_OFFSET_TABLE_+0x10>
40202c: 0f 1f 40 00 nopl 0x0(%rax)
0000000000402030 <_Znam@plt>:
402030: ff 25 e2 bf 02 00 jmpq *0x2bfe2(%rip) # 42e018 <_Znam@GLIBCXX_3.4>
402036: 68 00 00 00 00 pushq $0x0
40203b: e9 e0 ff ff ff jmpq 402020 <.plt>
0000000000402040 <_ZNSo3putEc@plt>:
402040: ff 25 da bf 02 00 jmpq *0x2bfda(%rip) # 42e020 <_ZNSo3putEc@GLIBCXX_3.4>
402046: 68 01 00 00 00 pushq $0x1
40204b: e9 d0 ff ff ff jmpq 402020 <.plt>
.plt节主要实现了使用过程链接表(Procedure Linkage Table)实现延迟绑定的功能。
问题:objdump 程序 有许多 类似 <.omp_outlined..16>: 的函数,但是main函数里并没有调用。实际openmp是怎么执行这些代码的呢?
在使用了OpenMP指令的C/C++程序编译后,编译器会自动生成一些名为.omp_outlined.的函数。这些函数是OpenMP所需要的运行时支持函数,不是直接在main函数中调用的,其执行方式主要有以下几种:
.omp_outlined.函数创建线程并发布工作。.omp_outlined.函数,在循环分配工作时调用。所以.omp_outlined.函数的执行是隐式通过运行时库触发和调度的,不需要用户代码直接调用。它们是OpenMP实现所必须的,由编译器和运行时库协调完成。用户只需要编写OpenMP指令,不必关心具体的调用细节。
总体来说,这是一种让并行执行透明化的实现机制,减少了用户的工作量。
不同平台不同,有GOMP_parallel_start开头的。也有如下x86平台的
405854: 48 c7 84 24 a0 00 00 movq $0x4293b9,0xa0(%rsp)
40585b: 00 b9 93 42 00
405860: 48 8d bc 24 90 00 00 lea 0x90(%rsp),%rdi
405867: 00
405868: ba 10 5f 40 00 mov $0x405f10,%edx
40586d: be 02 00 00 00 mov $0x2,%esi
405872: 4c 89 f9 mov %r15,%rcx
405875: 4c 8b 44 24 20 mov 0x20(%rsp),%r8
40587a: 31 c0 xor %eax,%eax
40587c: e8 ff cb ff ff callq 402480 <__kmpc_fork_call@plt>
405881: 48 8b 7c 24 60 mov 0x60(%rsp),%rdi
这段汇编代码实现了OpenMP中的并行构造,主要执行了以下几个步骤:
__kmpc_fork_call函数,这是OpenMP的runtime库函数,用来并行执行一个函数kmpc fork multiple parallel call?所以这段代码实现了调用OpenMP runtime并行执行一个函数的操作,准备参数,调用runtime API,获取返回值的一个流程。
利用runtime库的支持函数可以实现汇编级别的OpenMP并行性。
各section位置以及含义,参考文档
$ readelf -S bfs.inj
There are 37 section headers, starting at offset 0xbe8e8:
在文件内 0xbe8e8字节开始
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
序号 节名称 节类型 节的虚拟地址偏移量 节在文件中的偏移量
节大小 每个条目的大小(如果大小固定) 节的标志 节的链接信息 节的额外信息 节的信息对齐方式
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .interp PROGBITS 00000000004002a8 000002a8
000000000000001c 0000000000000000 A 0 0 1
[ 2] .note.gnu.build-i NOTE 00000000004002c4 000002c4
0000000000000024 0000000000000000 A 0 0 4
[ 3] .note.ABI-tag NOTE 00000000004002e8 000002e8
0000000000000020 0000000000000000 A 0 0 4
[ 4] .gnu.hash GNU_HASH 0000000000400308 00000308
000000000000005c 0000000000000000 A 5 0 8
[ 5] .dynsym DYNSYM 0000000000400368 00000368
00000000000007e0 0000000000000018 A 6 1 8
[ 6] .dynstr STRTAB 0000000000400b48 00000b48
0000000000000b1d 0000000000000000 A 0 0 1
[ 7] .gnu.version VERSYM 0000000000401666 00001666
00000000000000a8 0000000000000002 A 5 0 2
[ 8] .gnu.version_r VERNEED 0000000000401710 00001710
0000000000000110 0000000000000000 A 6 5 8
[ 9] .rela.dyn RELA 0000000000401820 00001820
00000000000000f0 0000000000000018 A 5 0 8
[10] .rela.plt RELA 0000000000401910 00001910
00000000000006c0 0000000000000018 AI 5 24 8
[11] .init PROGBITS 0000000000402000 00002000
000000000000001b 0000000000000000 AX 0 0 4
[12] .plt PROGBITS 0000000000402020 00002020
0000000000000490 0000000000000010 AX 0 0 16
[13] .text PROGBITS 00000000004024b0 000024b0
0000000000026475 0000000000000000 AX 0 0 16
[14] .fini PROGBITS 0000000000428928 00028928
000000000000000d 0000000000000000 AX 0 0 4
[15] .rodata PROGBITS 0000000000429000 00029000
0000000000001180 0000000000000000 A 0 0 16
[16] .eh_frame_hdr PROGBITS 000000000042a180 0002a180
00000000000002ac 0000000000000000 A 0 0 4
[17] .eh_frame PROGBITS 000000000042a430 0002a430
0000000000001780 0000000000000000 A 0 0 8
[18] .gcc_except_table PROGBITS 000000000042bbb0 0002bbb0
00000000000005d0 0000000000000000 A 0 0 4
[19] .init_array INIT_ARRAY 000000000042dbc8 0002cbc8
0000000000000010 0000000000000008 WA 0 0 8
[20] .fini_array FINI_ARRAY 000000000042dbd8 0002cbd8
0000000000000008 0000000000000008 WA 0 0 8
[21] .data.rel.ro PROGBITS 000000000042dbe0 0002cbe0
00000000000001f0 0000000000000000 WA 0 0 8
[22] .dynamic DYNAMIC 000000000042ddd0 0002cdd0
0000000000000220 0000000000000010 WA 6 0 8
[23] .got PROGBITS 000000000042dff0 0002cff0
0000000000000010 0000000000000008 WA 0 0 8
[24] .got.plt PROGBITS 000000000042e000 0002d000
0000000000000258 0000000000000008 WA 0 0 8
[25] .data PROGBITS 000000000042e258 0002d258
0000000000000010 0000000000000000 WA 0 0 8
[26] .bss NOBITS 000000000042e280 0002d268
0000000000000180 0000000000000000 WA 0 0 64
[27] .comment PROGBITS 0000000000000000 0002d268
000000000000004a 0000000000000001 MS 0 0 1
[28] .debug_info PROGBITS 0000000000000000 0002d2b2
000000000002a06e 0000000000000000 0 0 1
[29] .debug_abbrev PROGBITS 0000000000000000 00057320
0000000000000a57 0000000000000000 0 0 1
[30] .debug_line PROGBITS 0000000000000000 00057d77
000000000000af9a 0000000000000000 0 0 1
[31] .debug_str PROGBITS 0000000000000000 00062d11
0000000000010328 0000000000000001 MS 0 0 1
[32] .debug_loc PROGBITS 0000000000000000 00073039
0000000000042846 0000000000000000 0 0 1
[33] .debug_ranges PROGBITS 0000000000000000 000b587f
00000000000054c0 0000000000000000 0 0 1
[34] .symtab SYMTAB 0000000000000000 000bad40
00000000000018c0 0000000000000018 35 106 8
[35] .strtab STRTAB 0000000000000000 000bc600
0000000000002177 0000000000000000 0 0 1
[36] .shstrtab STRTAB 0000000000000000 000be777
000000000000016c 0000000000000000 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings), I (info),
L (link order), O (extra OS processing required), G (group), T (TLS),
C (compressed), x (unknown), o (OS specific), E (exclude),
l (large), p (processor specific)
[ 5] .dynsym 有关One section type, SHT_NOBITS described below, occupies no
space in the file, and its sh_offset member locates the conceptual placement in the
file.
so the number "2d258" remains unchanged.
[25] .data PROGBITS 000000000042e258 0002d258
0000000000000010 0000000000000000 WA 0 0 8
[26] .bss NOBITS 000000000042e280 0002d268
0000000000000180 0000000000000000 WA 0 0 64
global offset table
This section holds the procedure linkage table. See ‘‘Special Sections’’ in Part 1 and ‘‘Procedure Linkage Table’’ in Part 2 for more information.
Function symbols (those with type STT_FUNC) in shared object files have special significance. When another object file references a function from a shared object, the link editor automatically creates a procedure linkage table entry for the referenced symbol.
暂无
暂无
上面回答部分来自ChatGPT-3.5,没有进行正确性的交叉校验。
无
导言
Cache is to reduce latency
LLVM项目开始于一种比Java字节码更低层级的IR,因此,初始的首字母缩略词是Low Level Virtual Machine。它的想法是发掘低层优化的机会,采用链接时优化。
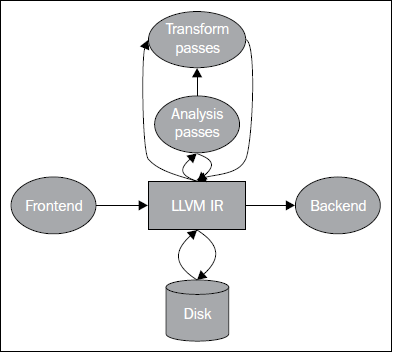
学过编译原理的人都知道,编译过程主要可以划分为前端与后端:
经典的编译器如gcc:在设计上前端到后端编写是强耦合的,你不需要知道,无法知道,也没有API来操作它的IR。
如果有M种语言、N种目标平台,那么最坏情况下要实现 M*N 个前后端。这是很低效的。
LLVM的核心设计了一个叫 LLVM IR 的通用中间表示, 并以库(Library) 的方式提供一系列接口, 为你提供诸如操作IR、生成目标平台代码等等后端的功能。
LVM IR实际上有三种表示:
各种格式是如何生成并相互转换:
| 格式 | 转换命令 |
|---|---|
| .c -> .ll | clang -emit-llvm -S a.c -o a.ll |
| .c -> .bc | clang -emit-llvm -c a.c -o a.bc |
| .ll -> .bc | llvm-as a.ll -o a.bc |
| .bc -> .ll | llvm-dis a.bc -o a.ll |
| .bc -> .s | llc a.bc -o a.s |
对于LLVM IR来说,.ll文件就相当于汇编,.bc文件就相当于机器码。 这也是llvm-as和llvm-dis指令为什么叫as和dis的缘故。

clang实现的前端包括
见 llvm Backend 一文
Clang 是 LLVM 项目中的一个 C/C++/Objective-C 编译器,它使用 LLVM 的前端和后端进行代码生成和优化。它可以将 C/C++/Objective-C 代码编译为 LLVM 的中间表示(LLVM IR),然后进一步将其转换为目标平台的机器码。Clang 拥有很好的错误信息展示和提示,支持多平台使用,是许多开发者的首选编译器之一。同时,Clang 也作为 LLVM 项目的一个前端,为 LLVM 的生态系统提供了广泛的支持和应用。
Clang 的开发起源于苹果公司的一个项目,即 LLVM/Clang 项目。在 2005 年,苹果公司希望能够使用一种更加灵活、可扩展、优化的编译器来替代 GCC 作为其操作系统 macOS (Mac OS X) 开发环境的默认编译器。由于当时的 GCC 开发被其维护者们认为变得缓慢和难以维护,苹果公司决定开发一款新的编译器,这就是 Clang 诞生的原因。Clang 的开发团队由该项目的创立者 Chris Lattner 领导,他带领团队将 Clang 发展为一款可扩展、模块化、高效的编译器,并成功地将其嵌入到苹果公司的开发工具链 Xcode 中,成为了 macOS 开发环境中默认的编译器之一。
Clang 是一个开源项目,在苹果公司的支持下,Clang 的开发得到了全球各地的开发者们的广泛参与和贡献。现在,Clang 成为了 LLVM 生态中的一个重要组成部分,被广泛地应用于多平台的编译器开发中。
Clang and Clang++ "borrow" the header files from GCC & G++. It looks for the directories these usually live in and picks the latest one. If you've installed a later GCC without the corresponding G++, Clang++ gets confused and can't find header files. In your instance, for example, if you've installed gcc 11 or 12.
You can use clang-10 -v -E or clang++-10 -v -E to get details on what versions of header files it's trying to use.
安装g++-12解决
github/tools目录下有许多实用工具
llvm-as:把LLVM IR从人类能看懂的文本格式汇编成二进制格式。注意:此处得到的不是目标平台的机器码。llvm-dis:llvm-as的逆过程,即反汇编。 不过这里的反汇编的对象是LLVM IR的二进制格式,而不是机器码。opt:优化LLVM IR。输出新的LLVM IR。llc:把LLVM IR编译成汇编码。需要用as进一步得到机器码。lli:解释执行LLVM IR。暂无
暂无
文章部分内容来自ChatGPT-3.5,暂时没有校验其可靠性(看上去貌似说得通)。
关于X86 与 arm的寄存器的区别写在了arm那篇下
In x86 terminology/documentation, a "word" is 16 bits
x86 word = 2 bytes
x86 dword = 4 bytes (double word)
x86 qword = 8 bytes (quad word)
x86 double-quad or xmmword = 16 bytes, e.g. movdqa xmm0, [rdi].
https://en.wikipedia.org/wiki/X86_instruction_listings
https://www.felixcloutier.com/x86/
https://officedaytime.com/simd512e/
SHR # Shift right (unsigned shift right)
SAL # Shift Arithmetically left (signed shift left)
lea # Load Effective Address, like mov but not change Flags, can store in any register, three opts
imul # Signed multiply
movslq # Move doubleword to quadword with sign-extension.
movl $0x46dd0bfe, 0x804a1dc #将数值0x46dd0bfe放入0x804a1dc的地址中
movl 0x46dd0bfe, 0x804a1dc #将0x46dd0bfe地址里的内容放入0x804a1dc地址中
// x is %rdi, result is %rax 就是计算地址,没有寻址操作
lea 0x0(,%rdi,8),%rax //result = x * 8;
lea 0x4b(,%rdi),%rax //result = x + 0x4b;

Call 地址:返回地址入栈(等价于“Push %eip,mov 地址,%eip”;注意eip指向下一条尚未执行的指令)ret:从栈中弹出地址,并跳到那个地址(pop %eip)leave:使栈做好返回准备,等价于
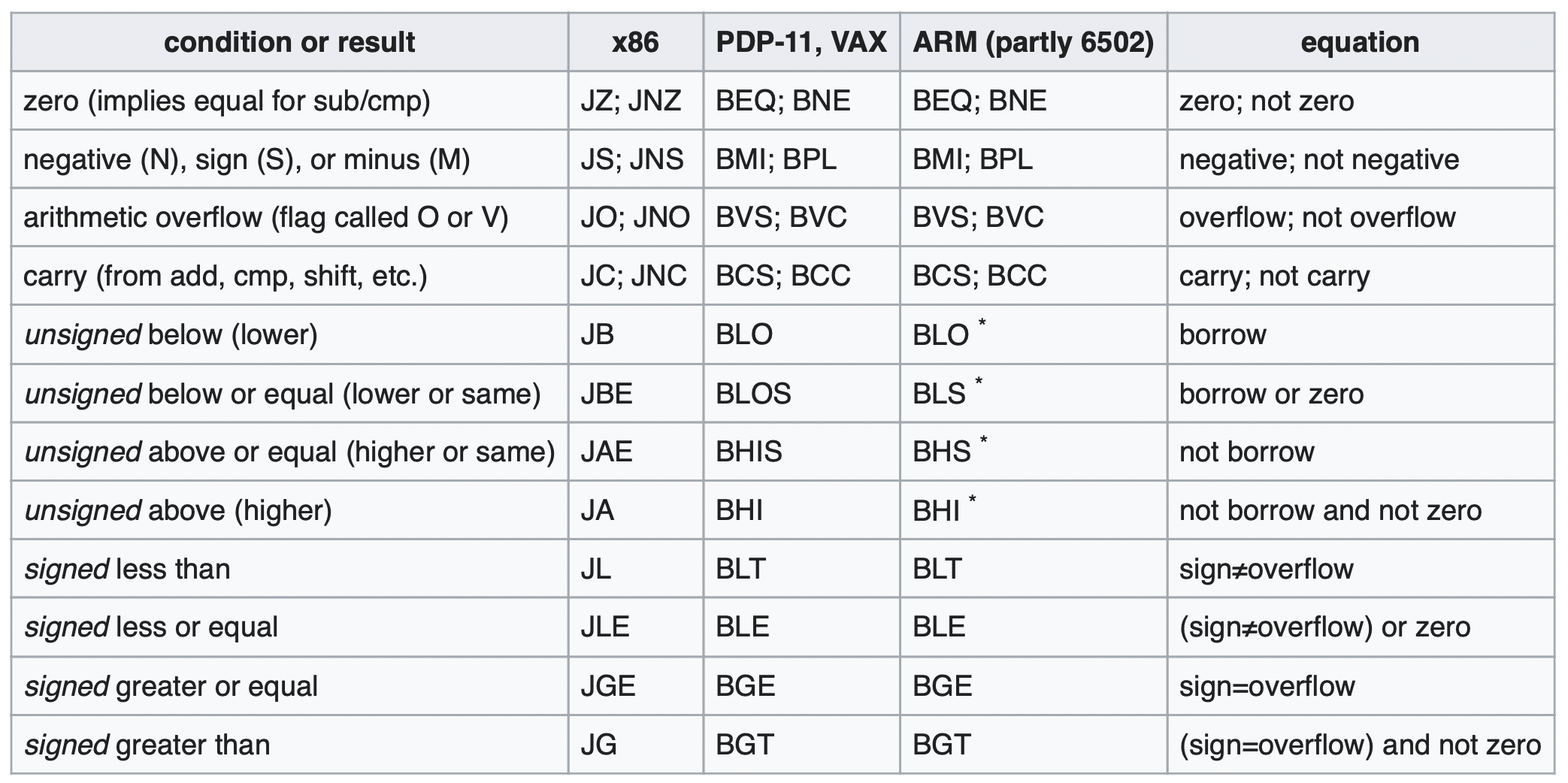
X86 不像 ARM有专门的ldr, str指令。是通过mov实现的
movswl (%rdi), %eax sign-extending load from word (w) to dword (l). Intel movsx eax, word [rdi]
https://docs.oracle.com/cd/E36784_01/html/E36859/gntbd.html
vxorpd XORPD
Bitwise Logical XOR for Double-Precision Floating-Point Values
vxorps XORPS
Bitwise Logical XOR for Single-Precision Floating-Point Values
vmovaps MOVAPS
Move Aligned Packed Single-Precision Floating-Point Values
The test instruction performs a logical and of the two operands and sets the CPU flags register according to the result (which is not stored anywhere). If al is zero, the anded result is zero and that sets the Z flag. If al is nonzero, it clears the Z flag. (Other flags, such as Carry, oVerflow, Sign, Parity, etc. are affected too, but this code has no instruction testing them.)
The jne instruction alters EIP if the Z flag is not set. There is another mnemonic for the same operation called jnz.
注意 cmp不等于 test
The TEST operation sets the flags CF and OF to zero.
The SF is set to the MSB(most significant bit) of the result of the AND.
If the result of the AND is 0, the ZF is set to 1, otherwise set to 0.
AT&T syntax jmpq *0x402390(,%rax,8) into INTEL-syntax: jmp [RAX*8 + 0x402390].
JUMP IF ABOVE AND JUMP IF GREATER
ja jumps if CF = 0 and ZF = 0 (unsigned Above: no carry and not equal)
jg jumps if SF = OF and ZF = 0 (signed Greater, excluding equal)
cmp performs a sub (but does not keep the result).
cmp eax, ebx
Let's do the same by hand:
reg hex value binary value
eax = 0xdeadc0de 11011110101011011100000011011110
ebx = 0x1337ca5e 00010011001101111100101001011110
- ----------
res 0xCB75F680 11001011011101011111011010000000
The flags are set as follows:
OF (overflow) : did bit 31 change -> no
SF (sign) : is bit 31 set -> yes
CF (carry) : is abs(ebx) < abs(eax) -> no
ZF (zero) : is result zero -> no
PF (parity) : is parity of LSB even -> no (archaic)
AF (Adjust) : overflow in bits 0123 -> archaic, for BCD only.
Carry Flag is a flag set when:
a) two unsigned numbers were added and the result is larger than "capacity" of register where it is saved.
Ex: we wanna add two 8 bit numbers and save result in 8 bit register. In your example: 255 + 9 = 264 which is more that 8 bit register can store. So the value "8" will be saved there (264 & 255 = 8) and CF flag will be set.
b) two unsigned numbers were subtracted and we subtracted the bigger one from the smaller one.
Ex: 1-2 will give you 255 in result and CF flag will be set.
Auxiliary Flag is used as CF but when working with BCD. So AF will be set when we have overflow or underflow on in BCD calculations. For example: considering 8 bit ALU unit, Auxiliary flag is set when there is carry from 3rd bit to 4th bit i.e. carry from lower nibble to higher nibble. (Wiki link)
Overflow Flag is used as CF but when we work on signed numbers.
Ex we wanna add two 8 bit signed numbers: 127 + 2. the result is 129 but it is too much for 8bit signed number, so OF will be set.
Similar when the result is too small like -128 - 1 = -129 which is out of scope for 8 bit signed numbers.
Positive or negative The CPU does not know (or care) whether a number is positive or negative. The only person who knows is you. If you test SF and OF, then you treat the number as signed. If you only test CF then you treat the number as unsigned. In order to help you the processor keeps track of all flags at once. You decide which flags to test and by doing so, you decide how to interpret the numbers.
The computer makes use of binary multiplication(AND), followed by bit shift (in the direction in which the multiplication proceeds), followed by binary addition(OR).
1100100
0110111
=======
0000000
-1100100
--1100100
---0000000
----1100100
-----1100100
------1100100
==============
1010101111100
100 = 1.1001 * 2^6
55 = 1.10111* 2^5
100 * 55 -> 1.1001 * 1.10111 * 2^(6+5)
for more:
How computer multiplies 2 numbers? And: Binary multiplier - Wikipedia
DB, DW, and DD can be used to declare one, two, and four byte data locations,
# 基本例子
.DATA
var DB 64 ; Declare a byte, referred to as location var, containing the value 64.
var2 DB ? ; Declare an uninitialized byte, referred to as location var2.
DB 10 ; Declare a byte with no label, containing the value 10. Its location is var2 + 1.
X DW ? ; Declare a 2-byte uninitialized value, referred to as location X.
Y DD 30000 ; Declare a 4-byte value, referred to as location Y, initialized to 30000.
数组的声明,The DUP directive tells the assembler to duplicate an expression a given number of times. For example, 4 DUP(2) is equivalent to 2, 2, 2, 2.
Z DD 1, 2, 3 ; Declare three 4-byte values, initialized to 1, 2, and 3. The value of location Z + 8 will be 3.
bytes DB 10 DUP(?) ; Declare 10 uninitialized bytes starting at location bytes.
arr DD 100 DUP(0) ; Declare 100 4-byte words starting at location arr, all initialized to 0
str DB 'hello',0 ; Declare 6 bytes starting at the address str, initialized to the ASCII character values for hello and the null (0) byte.
32位X86机器寻址支持
# right
mov eax, [ebx] ; Move the 4 bytes in memory at the address contained in EBX into EAX
mov [var], ebx ; Move the contents of EBX into the 4 bytes at memory address var. (Note, var is a 32-bit constant).
mov eax, [esi-4] ; Move 4 bytes at memory address ESI + (-4) into EAX
mov [esi+eax], cl ; Move the contents of CL into the byte at address ESI+EAX
mov edx, [esi+4*ebx] ; Move the 4 bytes of data at address ESI+4*EBX into EDX
# wrong and reason
mov eax, [ebx-ecx] ; Can only add register values
mov [eax+esi+edi], ebx ; At most 2 registers in address computation
mov BYTE PTR [ebx], 2 ; Move 2 into the single byte at the address stored in EBX.
mov WORD PTR [ebx], 2 ; Move the 16-bit integer representation of 2 into the 2 bytes starting at the address in EBX.
mov DWORD PTR [ebx], 2 ; Move the 32-bit integer representation of 2 into the 4 bytes starting at the address in EBX.
这和汇编器语法有关:
For instructions with two operands, the first (lefthand) operand is the source operand, and the second (righthand) operand is the destination operand (that is, source->destination).
AT&T Syntax is an assembly syntax used in UNIX environments, that originates from AT&T Bell Labs. It is descended from the MIPS assembly syntax. (AT&T, American Telephone & Telegraph)
AT&T Syntax is an assembly syntax used mostly in UNIX environments or by tools like gcc that originated in that environment.
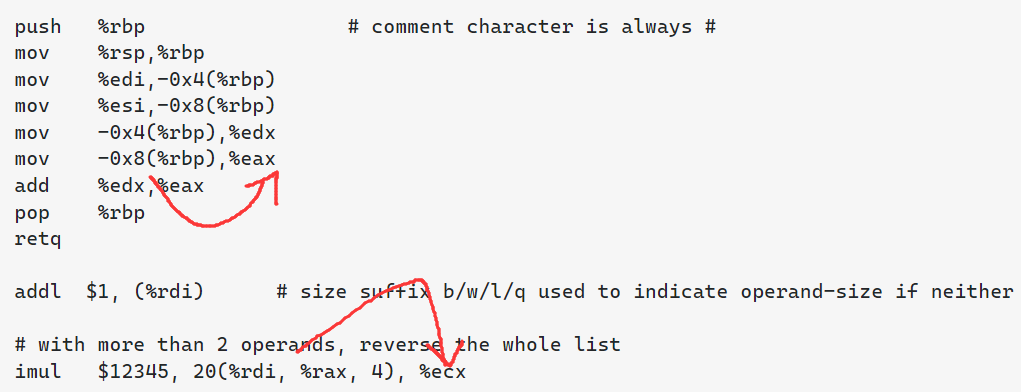
语法特点:https://stackoverflow.com/tags/att/info
需要注意的:
%, and immediates are prefixed with $sub $24, %rsp reserves 24 bytes on the stack.b/w/l/q suffix on the mnemonicaddb $1, byte_table(%rdi) increment a byte in a static table.
imul $13, 16(%rdi, %rcx, 4), %eax 32-bit load from rdi + rcx<<2 + 16, multiply that by 13, put the result in %eax. Intel imul eax, [16 + rdi + rcx*4], 13.movswl (%rdi), %eax sign-extending load from word (w) to dword (l). Intel movsx eax, word [rdi].The Intel assembler(icc,icpc我猜) uses the opposite order (destination<-source) for operands.

语法特点: https://stackoverflow.com/tags/intel-syntax/info
beq rs1, rs2, Label #RISC-V
SW rs2, imm(rs1) # Mem[rs1+imm]=rs2 ,汇编将访存放在最后
add rd, rs1, rs2 # rd = rs1 + rs2
但是这个语法不是很重要,因为decompiler有选项控制语法
objdump has -Mintel flag, gdb has set disassembly-flavor intel option.
gcc -masm=intel -S or objdump -drwC -Mintel.
暂无
暂无
https://www.cs.virginia.edu/~evans/cs216/guides/x86.html
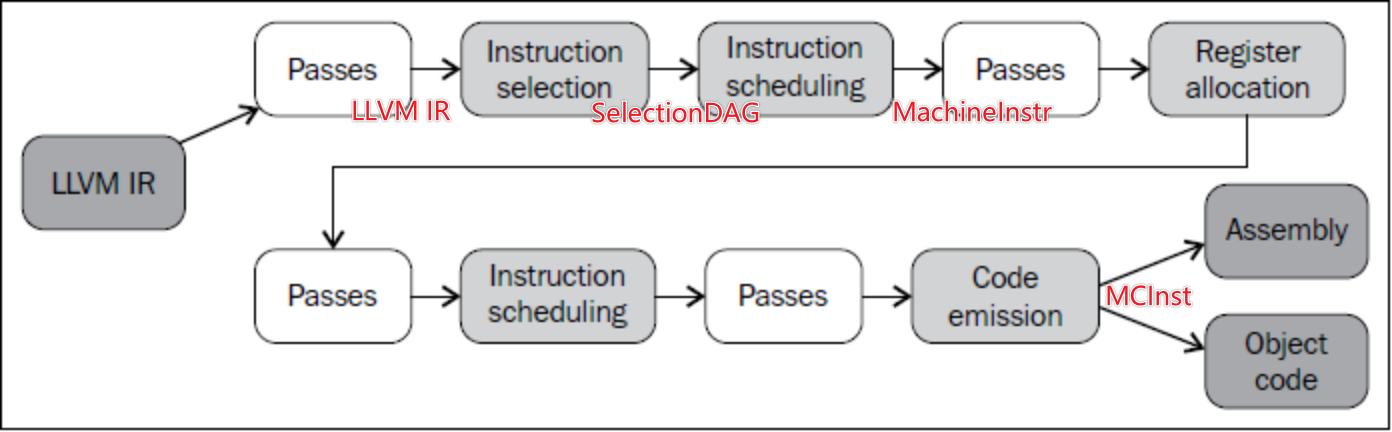
-O3的优化,而且其顺序对结果也有影响。详细解释各阶段:
后端的实现分散在LLVM源代码树的不同目录中。代码生成背后的主要程序库位于lib目录和它的子文件夹CodeGen、MC、TableGen、和Target中, 具体参考文档
Tablegen位置在类似 llvm/lib/Target/X86/X86.td的地方
程序优化选项 -O3 是通过启用 LLVM Pass Manager 并按照顺序执行包含多个具体优化 Pass 的过程实现的。包括:
这些 Pass 的执行范围涵盖 LLVM IR 与 LLVM 后端。
TableGen的输入文件使用扩展名“.td”(TableGen的缩写),它们可以描述如下内容:
Instruction Scheduling - 描述调度器行为、指令之间的时间关系,以及如何将指令插入到调度图中的规则等。
TableGen自动化了目标机指令集的大部分工作,同时也使得自定义目标机变得相对容易。
实现一个简单的LLVM IR后端,将LLVM IR转换为x86汇编代码,能line by line的输出。
参考LLVM官方文档中的“Writing an LLVM Backend”以及“TableGen Backends”
暂无
暂无
https://getting-started-with-llvm-core-libraries-zh-cn.readthedocs.io/zh_CN/latest/ch06.html#id2