NPU Training Operators - MC2
导言
MC2 的核心不是异步通信,而是 fused operator 内部的计算/通信切分与流水。MindSpeed-LLM 文档里的典型场景是 TP/SP 下的 matmul + all_reduce/all_gather/reduce_scatter;MindSpeed-MM PR #2480 接入的是 MoE expert parallel 下的 AllToAllv + GroupedMatmul 和 GroupedMatmul + AllToAllv。
本文只记录可迁移信息:PR 改了哪些文件、ep_mc2_forward 怎么跑、迁移前检查什么、怎么验证、哪些结论不能从公开资料直接外推。
结论¶
- PR 状态:MindSpeed-MM PR #2480
feat: support ep mc2已于 2026-05-18 合入。2 - 接入对象:Qwen3.5 MoE / FSDP expert parallel 路径,dispatcher 增加
mc2分支。 - 算子形态:新增
npu_alltoallv_gmm与npu_gmm_alltoallv包装,不是直接使用 TP 场景的npu_mm_all_reduce_base。 - 默认回退:
EPPlanConfig.dispatcher默认仍是alltoall,MC2 是可选分支。 - 硬条件:
ep_mc2_forward要求fused=True,且依赖 NPU backend 的 HCCL comm name。 - 验证基线:必须和普通
alltoall路径双跑,比较前向、反向、loss、step time 和 HCCL/GMM profiler 事件。
背景约束¶
MindSpeed-LLM 对 Ascend MC2 的描述是:在开启 TP/SP 的训练场景中,matmul 与集合通信存在相邻依赖,串行执行会让计算流和通信流互相等待;MC2 通过融合算子把大计算和大通信拆成子任务并流水执行。文档还注明:MC2 默认关闭,使能后部分模型可能有精度问题。3
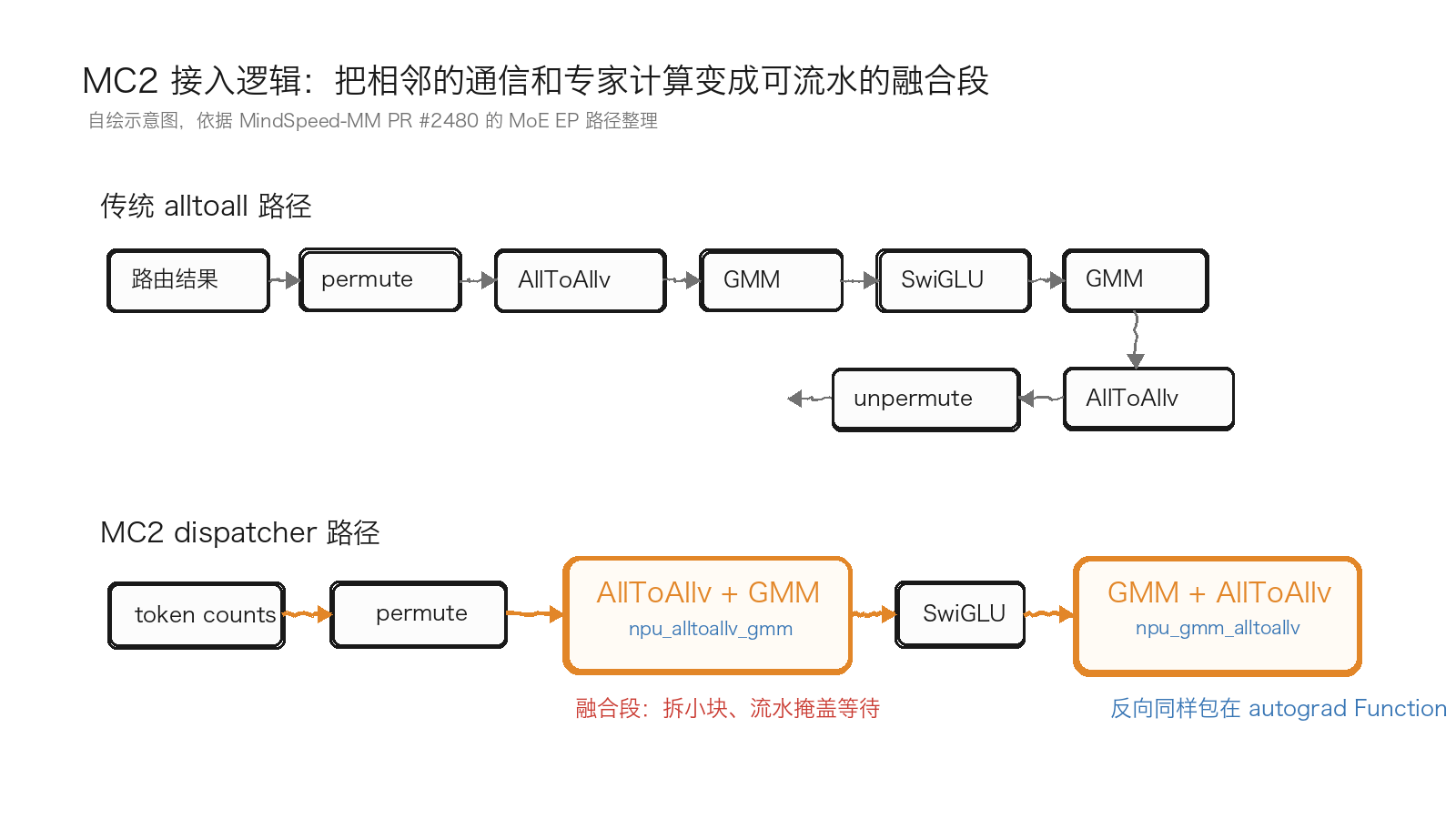
MindSpeed-MM PR #2480 不是 TP linear 的 mm + all_reduce 场景,而是 MoE EP 的 token dispatch/combine 场景。对应算子组合如下:
- Dispatch 段:
AllToAllv -> GroupedMatmul,PR 包装为all2all_grouped_matmul。 - Combine 段:
GroupedMatmul -> AllToAllv,PR 包装为grouped_matmul_all2all。
PR 改动¶
| 文件 | 关键改动 | 迁移含义 |
|---|---|---|
mindspeed_mm/fsdp/params/parallel_args.py |
EPPlanConfig 增加 use_npu_fused_ops,dispatcher 改为 Literal["alltoall", "allgather", "mc2"],默认 alltoall。 |
MC2 通过配置选择,不替换默认路径。 |
mindspeed_mm/fsdp/distributed/expert_parallel/expert_parallel.py |
替换 forward 时传入 ep_plan;get_experts_forward_fn_for_qwen 根据 dispatcher 选择 ep_forward 或 ep_mc2_forward。 |
dispatcher 下沉到模型 forward。 |
mindspeed_mm/fsdp/models/qwen3_5_moe/modeling_qwen3_5_moe.py |
Qwen3_5MoeExperts.ep_forward 增加 ep_plan 参数,并使用同样的 dispatcher map。 |
具名模型也走统一分发逻辑。 |
mindspeed_mm/fsdp/distributed/expert_parallel/ep_dispatcher.py |
新增 ep_mc2_forward;token 计数处从 bincount 改为 histc。 |
MC2 前向准备 send_counts / recv_counts。 |
mindspeed_mm/fsdp/ops/moe_ops/gemm_mc2.py |
新增两个 autograd Function:AllToAllGroupedMatmul、GroupedMatmulAllToAll。 |
前向和反向都封装 NPU fused operator。 |
注意:虽然配置类型里出现了 allgather,当前 PR 的分发表只实现了 alltoall 和 mc2。迁移时不要把 allgather 当作已可用路径。
执行路径¶
ep_mc2_forward 的数据流:
hidden_states = hidden_states.view(-1, hidden_size)。num_local_tokens_per_expert = torch.histc(selected_experts.view(-1), bins=num_experts, min=0, max=num_experts)。dist.all_gather_into_tensor(num_global_tokens_per_expert, num_local_tokens_per_expert, group=ep_group)。send_counts = num_local_tokens_per_expert。recv_counts = num_global_tokens_per_expert[:, start_idx:end_idx].reshape(-1)。permute(hidden_states, selected_experts.to(torch.int32), fused=True)。all2all_grouped_matmul(inputs, fc1_weight, ep_group, send_counts, recv_counts)。swiglu(intermediate_hidden_states, fused=True)。grouped_matmul_all2all(inputs, fc2_weight, ep_group, recv_counts, send_counts)。unpermute(hidden_states, unpermute_indices, probs=routing_weights, fused=True)。
gemm_mc2.py 中取通信 handle 的方式:
rank = torch.distributed.get_rank(group)
global_rank = torch.distributed.get_global_rank(group, rank)
hcomm = group._get_backend(torch.device("npu")).get_hccl_comm_name(global_rank)
这说明 MC2 接入点同时依赖 EP group、NPU backend、HCCL comm name、token counts、expert weight shard。只改 Python dispatcher 不足以验证成功。
底层 API 对照¶
昇腾文档中的 torch_npu.npu_mm_all_reduce_base 用于 TP 切分场景,功能是融合 mm 与 all_reduce,并在融合算子内部做计算/通信流水。接口需要 hcom,示例中通过 default process group 的 NPU backend 获取 HCCL comm name。5
PR #2480 的 EP MC2 使用:
torch_npu.npu_alltoallv_gmmtorch_npu.npu_gmm_alltoallvtorch_npu.npu_grouped_matmul
因此迁移时要先确认目标版本的 torch_npu 是否包含这几个接口,以及接口对 dtype、shape、count list、shared expert 输入的约束。
迁移检查¶
迁移前检查:
- 模型是否是 MoE,且 EP forward 中存在
AllToAllv与GroupedMatmul相邻段。 ep_group是否是 NPU/HCCL backend,且能取到get_hccl_comm_name(global_rank)。num_experts % ep_size == 0,本 rank 的 expert 范围可由ep_rank * num_local_experts推出。selected_experts的取值范围是否在[0, num_experts)。send_counts/recv_counts是否和 fused op 要求一致。use_npu_fused_ops=True,否则ep_mc2_forward直接报错。- 普通
alltoall路径保留,作为功能和性能 baseline。
建议配置形态:
ep_dispatcher = {
"alltoall": ep_forward,
"mc2": ep_mc2_forward,
}
hidden_states = ep_dispatcher[ep_plan.dispatcher](
num_experts,
routing_weights,
selected_experts,
hidden_states,
fc1_weight=gate_up_proj,
fc2_weight=down_proj,
ep_group=ep_group,
fused=ep_plan.use_npu_fused_ops,
)
验证项¶
| 类型 | 检查项 | 失败信号 |
|---|---|---|
| Shape | send_counts.sum()、recv_counts.sum()、permute 后 token 数、两层 GMM 输出 shape。 |
rank 间 shape 不一致,或 unpermute 后无法还原 batch。 |
| 数值 | 固定 seed,比对 alltoall 与 mc2 前向输出、fc1/fc2 梯度。 |
diff 超过 dtype 预期,或某些 expert 梯度为 0。 |
| 精度 | 短训 loss、grad norm、overflow、router top-k 分布。 | loss 曲线漂移,router 分布异常集中。 |
| 性能 | step time、HCCL 时间、GMM 时间、NPU util、host bound。 | HCCL 时间下降但 GMM/host 开销上升,端到端无收益。 |
| 回退 | 同一配置切回 dispatcher=alltoall。 |
回退路径不可用,无法定位 MC2 问题。 |
PR 描述中也说明 UT 暂时无法 mock 通信组,因此本地单卡测试不能替代多 rank 验证。2
公开证据¶
PR #2480 没有公开 benchmark,只写了“某些场景下可以取得性能收益”。不要把非官方博客中的推理加速数字当成 NPU 训练结论。6
可引用的系统证据来自 MoE 论文:
- GShard:MoE 层包含 gating、dispatch、expert compute、combine;跨设备 dispatch/combine 依赖 AllToAll。7
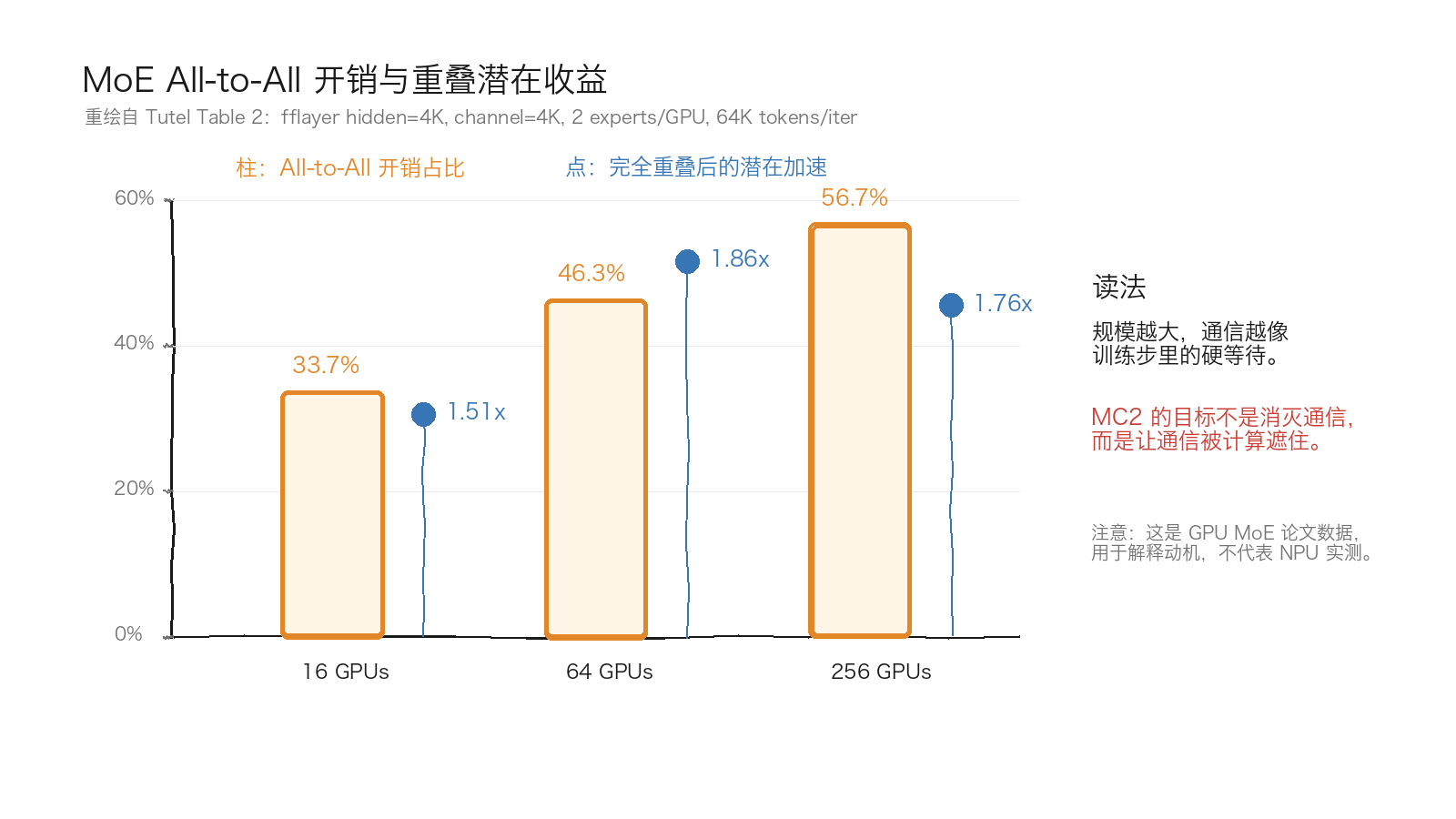
- Tutel:MoE 中 All-to-All 开销随规模增大。Table 2 给出在典型设置下完全重叠 All-to-All 与 fflayer 的潜在加速为 1.51x、1.86x、1.76x。该数据来自 GPU 集群,只能解释动机,不能代表 NPU 实测。8
- MegaBlocks:MoE 专家计算需要高效处理动态 token 分布,Grouped / block sparse 计算是专家层性能核心。9
风险¶
- 精度风险:MindSpeed-LLM 文档明确提示 MC2 可能在部分模型带来精度问题。3
- 接口风险:
npu_alltoallv_gmm/npu_gmm_alltoallv不是 PyTorch 通用 API,版本约束需要单独确认。 - 计数风险:MoE EP 的
send_counts/recv_counts是数据交换控制面,计数错误会造成跨 rank token 错位。 - 收益风险:如果专家计算太短、通信量太小、host bound 明显,融合后可能没有端到端收益。
- 兼容风险:CoC 也做通信计算并行,但 MindSpeed-LLM 文档注明暂不兼容
--use-ascend-mc2,不要同时开启。4
实测表模板¶
| Case | alltoall | mc2 | 备注 |
|---|---|---|---|
| step time | 待测 | 待测 | 固定模型、EP size、batch、seq len。 |
| HCCL time | 待测 | 待测 | profiler 按 rank 汇总。 |
| GMM time | 待测 | 待测 | 查看融合后计算是否变长。 |
| host time | 待测 | 待测 | 排除 count/permute 引入 host bound。 |
| max abs diff | 待测 | 待测 | 对齐 dtype 容差。 |
| loss slope | 待测 | 待测 | 短训对比。 |