Multimodal Generation Evaluation
导言
多模态生成 RL 的评测不能沿用 VLM 问答评测的一套逻辑。理解任务可以用正确答案、选项或短文本验证;生成任务还要评价 视觉质量、语义一致、运动时序、编辑边界、音频质量、音画同步和人类偏好。
因此,评测方案要先回答一个问题:训练时 reward 优化的是哪一种生成能力,最终 benchmark 是否真的测了同一种能力。本文把 AISBench、VBench、VEFX-Bench、Flow-Factory 和 VeRL-Omni 放在一起,整理一个后续实验可执行的评测地图。
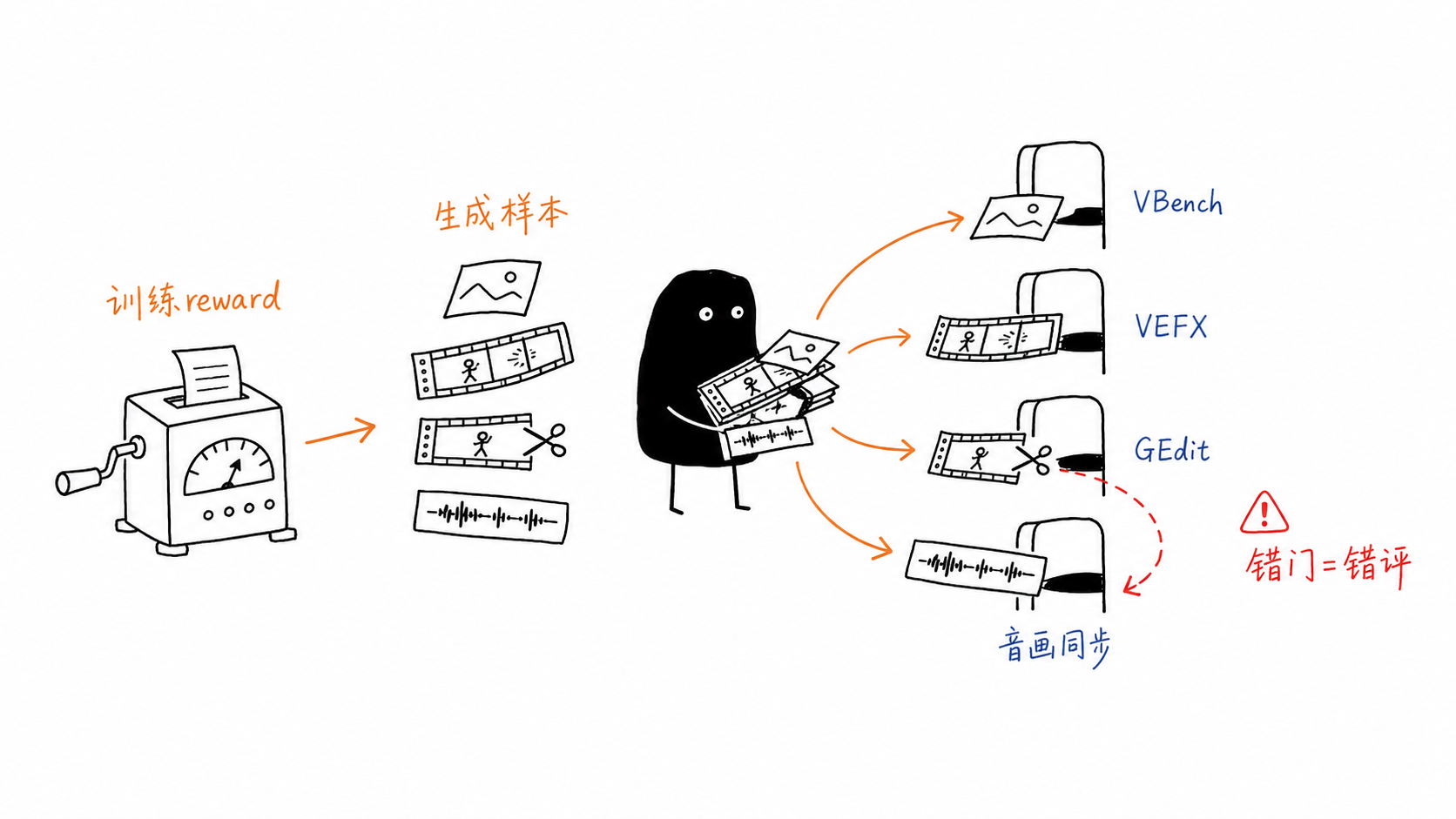
核心判断¶
结论先说:
- 理解型评测和生成型评测要分开。Geo3K、VideoBench、Video-MME 这类问答评测主要验证模型是否理解输入;VBench、GEdit-Bench、VEFX-Bench 则验证模型生成出来的图像或视频是否好。
- AISBench 已经有多模态生成评测入口。截至 2026-06-26,AISBench README 和文档已经接入 GEdit-Bench 与 VBench 1.0;但 VBench 页面明确说明,AISBench 当前不负责生成视频,需要先完成视频生成,再把生成结果交给 AISBench 评测。123
- VEFX-Bench 更适合视频编辑和视觉特效,不是通用 T2V 榜单。它评估的是原视频、编辑指令、编辑后视频之间的匹配,核心维度是 Instruction Following、Render Quality 和 Edit Exclusivity。6
- Flow-Factory 与 VeRL-Omni 更像训练框架,不是最终评测基准。它们提供 reward 接入、生成模型 rollout 和 RL 算法;最终论文或客户报告仍要接 VBench、GEdit-Bench、VEFX-Bench、人评或音频类指标。
不要只看 reward 上涨
生成 RL 中的 reward 上涨只能说明训练时的 scorer 被优化了。它不自动等价于 VBench、VEFX-Bench 或人工偏好变好。最终报告应把 training reward 和 external evaluation 分成两张表。
评测地图¶
多模态生成至少要按输出形态拆成四类:图像生成、图像编辑、视频生成、音视频生成。每一类的样本格式、自动指标和人工检查点都不同。
| 方向 | 典型输入输出 | 训练 reward | 最终评测 | 适用结论 |
|---|---|---|---|---|
| T2I 图像生成 | prompt -> image | PickScore、HPSv2/HPSv3、CLIP、OCR、Qwen-Image-Bench、RationalRewards | GenEval、Qwen-Image-Bench、人工偏好 | 证明图像质量、语义对齐、文字渲染或组合泛化。 |
| 图像编辑 | source image + instruction -> edited image | RationalRewards-Edit、Qwen-Image-Bench、VLM-as-Judge | GEdit-Bench、编辑前后人评 | 证明真实编辑请求、保真和指令遵循。 |
| T2V 视频生成 | prompt -> video | HPSv3、ImageBind、VLM-as-Judge、任务定制 reward | VBench Standard / Custom、人工偏好 | 证明视频质量、运动、时序和 prompt 对齐。 |
| 视频编辑 / VFX | source video + instruction -> edited video | VLM video reward、VEFX-Reward、局部一致性 reward | VEFX-Bench | 证明编辑是否只改该改的地方,且画面稳定。 |
| T2AV 音视频生成 | prompt -> video + audio | CLAP、ImageBind、音画同步 reward、VLM/AVLM judge | VBench 视觉维度 + 音频质量指标 + 音画同步人评 | 证明声音内容、视觉内容和同步关系一起成立。 |
这里有一个容易混淆的点:VBench 和 VEFX-Bench 都是视频相关,但不是同一个问题。
- VBench 主要面向视频生成模型,对生成视频做 16 个维度的质量和语义评测,包括主体一致、背景一致、时序闪烁、运动平滑、动态程度、美学质量、图像质量、物体类别、空间关系、动作、场景、整体一致等。5
- VEFX-Bench 主要面向文本驱动视频编辑和视觉特效,数据有 5,049 个标注样例、1,419 个源视频、9 个类别和 32 个子类,并用 VEFX-Reward 在 1-4 分上评分。6
现场选择规则
如果客户现场说的是 vefx bench,需要先确认任务是不是 video editing / VFX。如果任务是纯文本到视频生成,用 VBench 更自然;如果任务是给定原视频再做局部编辑、替换、移除、风格或镜头变化,用 VEFX-Bench 才对。
AISBench 入口¶
AISBench 现在可以覆盖两类生成评测:
- GEdit-Bench:面向真实世界图像编辑请求。AISBench 文档说明该数据集来自真实用户编辑请求,最终有英文和中文两套,单语言 606 个测试样本,总计 1,212 个样本,覆盖 11 类高频编辑场景。3
- VBench 1.0:面向视频生成质量评测。AISBench 提供 Standard 和 Custom 两种配置,Standard 模式按官方 prompt suite 组织 16 个维度,最终聚合 Quality、Semantic 和 Total。2
这两类和 AISBench 数据集准备页里的 textvqa、videobench、Video-MME、MathVision 等理解型评测不同。后者通常评估模型回答是否正确,前者评估模型生成结果是否符合质量和语义要求。4
AISBench VBench 页面对使用方式有一个关键约束:它评的是 已经生成好的视频目录。这意味着实验流程不能写成“AISBench 直接评模型”,而应拆成:
- 生成阶段:用待评模型按 VBench prompt suite 或自定义 prompt 生成视频。
- 落盘阶段:按维度或文件名规则保存视频,尤其注意
temporal_flickering需要更多采样。 - 评测阶段:用 AISBench 的 VBench 配置读取视频目录,输出各维度结果。
- 汇总阶段:Standard 模式聚合 Quality、Semantic 和 Total,Custom 模式按维度输出。
生成类任务打破原有接口
VLM 问答评测通常是 dataset 给 prompt,model 返回 answer,metric 直接算分。生成类评测多了一步“先生成样本并落盘”,因此数据目录、prompt 名称、采样数、随机种子和视频编码都会影响可复现性。
Flow-Factory 位置¶
Flow-Factory 的定位是 面向 diffusion 和 flow-matching 模型的 RL 训练框架,不是一个固定的视频生成 benchmark。它支持的任务已经覆盖 T2I、I2I、T2V、I2V、T2AV、I2AV 等模型族,并支持 Wan2.1/Wan2.2、Qwen-Image、FLUX、BAGEL、LTX-2/LTX-2.3 等模型入口。7
数据格式¶
Flow-Factory 的数据格式很轻:
- T2I / T2V:
train.txt或train.jsonl,核心字段是prompt。 - I2I / I2V:
train.jsonl里带prompt和image或images。 - V2V:
train.jsonl里带prompt和video或videos。 - T2AV / I2AV:仍然围绕 prompt 和条件图像组织,但 reward 需要同时处理 audio、video 和文本对齐。
这说明 Flow-Factory 的“数据集”更像训练 prompt 池,而不是评测闭环本身。它可以把 Open-Sora-Plan、PickScore、T2IS、自定义 prompt 或客户 prompt 接进来,但最终要证明模型变好,还需要外部评测。
奖励模型¶
Flow-Factory 内置 reward 大致分三类:8
- 图像质量和偏好:PickScore、HPSv2、CLIP、Qwen-Image-Bench。
- 组合与文字能力:GenEval、OCR、GenEval2 Soft-TIFA。
- 音视频对齐:CLAP、ImageBind,以及可通过 VLM-as-Judge 接入的远程裁判。
这对后续方案的启发是:训练 reward 可以多样化,但最终评测要按能力域切开。例如 T2AV 训练中可以用 CLAP 和 ImageBind,但最终报告仍要分别看视频质量、音频质量和音画同步。
VeRL-Omni 方案¶
VeRL-Omni 是从 verl 多模态生成 RL 需求中拆出来的专门仓库,目标是服务 diffusion generator、统一理解生成模型和 omni-modality 模型。README 中列出的范围包括 Qwen-Image、Wan2.2、BAGEL、Qwen3-Omni 等。9
当前做法¶
从公开示例看,VeRL-Omni 当前的“评测”更偏训练闭环和验证信号:
- Wan2.2 T2V / DanceGRPO:示例使用来自 Open-Sora-Plan 的 1,233 条预切分 prompt,训练 reward 是 HPSv3。该示例验证的是 T2V RL 流程和 reward 上涨,不等同于完整 VBench 结论。10
- Qwen-Image / FlowGRPO 系列:支持 HPSv3、GenRM-OCR、UnifiedReward、HTTP scorer、JPEG compressibility 等 scorer,适合验证图像生成 reward 链路。11
- Qwen3-Omni Thinker / GSPO:公开示例使用 MATH-lighteval 这类数学推理数据,reward 来自
dapo数学答案解析,验证指标是val-core/.../acc/mean@1。这更像 omni 模型的理解/推理训练,不是生成质量评测。12
因此,如果目标是证明“生成模型 RL 后变好”,只汇报 VeRL-Omni 内部 reward 不够。需要补上外部评测矩阵。
推荐闭环¶
建议把 VeRL-Omni 的后续评测拆成三层:
- 训练层:记录 reward mean、reward std、clip ratio、prompt length、response length、rollout time、reward latency、OOM / timeout 等,证明训练稳定。
- 任务层:按模型类型选择 benchmark。
- Qwen-Image / SD3.5:GEdit-Bench、Qwen-Image-Bench、GenEval。
- Wan2.2 T2V:AISBench VBench Standard + Custom。
- Wan2.2 / VACE 类视频编辑:VEFX-Bench。
- LTX-2 / LTX-2.3 音视频:VBench 视觉维度 + CLAP/ImageBind + 人工音画同步打分。
- 报告层:训练 reward、外部 benchmark、人评三张表分开展示,避免把 reward 当成最终效果。
Geo3K 不是生成评测
如果讨论的是 verl 多模态理解 RL,Geo3K、NextQA 和 multimodal-open-r1-8k-verified 的匹配关系可以参考已有笔记《VLM RL Evaluation Datasets》。如果讨论的是 VeRL-Omni 的生成 RL,Geo3K 只能作为理解能力的旁路检查,不能替代 VBench、GEdit-Bench 或 VEFX-Bench。
后续问题¶
把这些 benchmark 真正接进实验,还需要逐项确认:
- 客户任务是不是编辑:如果现场任务输入包含原视频和编辑指令,就按 VEFX-Bench 设计;如果只有 prompt 生成视频,就按 VBench 设计。
- 视频样本如何生成:VBench Standard 要按官方 prompt 和目录结构生成,不能随意混用客户 prompt 后再和榜单分数比较。
- 采样预算是否一致:每个 prompt 的视频数、seed、分辨率、帧率、时长和编码参数要固定,否则指标会混入采样差异。
- 音视频指标是否缺口:AISBench 当前已有图像编辑和视频生成评测,但没有形成 T2AV 的完整官方套件。音频质量、音画同步和音频语义仍需自定义指标或人评补足。
- reward 是否会被过拟合:如果训练 reward 和最终评测使用同一个裁判模型,报告里最好加入不同裁判或人评,观察泛化。
- NPU 环境是否缓存齐全:AISBench VBench 依赖多种小模型和第三方包,最好提前缓存权重并固定
VBENCH_CACHE_DIR。
实验建议¶
最小可行方案可以按下面走:
| 实验线 | 训练框架 | 训练 reward | 外部评测 | 主要回答 |
|---|---|---|---|---|
| T2V baseline | VeRL-Omni / Flow-Factory | 无 RL | AISBench VBench Standard | 原模型在视频质量和语义维度的起点。 |
| T2V RL | VeRL-Omni DanceGRPO | HPSv3 或自定义 VLM reward | AISBench VBench Standard + Custom | reward 上涨是否转化为 VBench 维度提升。 |
| Video edit RL | Flow-Factory 或自研链路 | VEFX-Reward / VLM judge | VEFX-Bench | 编辑指令遵循、画质和编辑排他性是否提升。 |
| T2AV RL | Flow-Factory LTX-2 / LTX-2.3 | CLAP + ImageBind + 人工抽检 | VBench 视觉维度 + 音频/同步人评 | 音频、视觉和同步是否同时改善。 |
| 负向迁移 | 任意 RL checkpoint | 同训练 | 跨域 benchmark | 检查只优化 reward 是否伤害其他能力。 |
最终对外结论建议写成能力域,而不是笼统写“多模态生成变强”:
- 视频生成质量提升:用 VBench Quality / Semantic / Total 说明。
- 视频编辑能力提升:用 VEFX-Bench IF / RQ / EE 说明。
- 图像编辑能力提升:用 GEdit-Bench SC / PQ / O 说明。
- 音视频生成能力提升:需要同时报告视觉、音频语义、音画同步和人工偏好。
总结¶
多模态生成 RL 的评测主线可以压缩成一句话:训练 reward 负责优化,外部 benchmark 负责证明,人评负责兜底。
对当前工作来说:
- AISBench 已有 GEdit-Bench 和 VBench 入口,可以作为图像编辑和视频生成的标准化评测框架。
- 客户现场的
vefx bench应按 VEFX-Bench 理解,适合视频编辑 / VFX,而不是纯 T2V。 - Flow-Factory 和 VeRL-Omni 提供训练链路,但最终效果要接 VBench、VEFX-Bench、GEdit-Bench 或 T2AV 自定义评测。
- 对 T2AV,行业还没有像 VBench 一样统一的单一入口,短期要用 CLAP、ImageBind、视频质量评测和人工同步偏好组合起来。