VeRL Rollout Inference
导言
RL 中的 rollout 不是普通离线推理。它不仅要生成 response,还要和训练阶段共享策略版本、返回 token 级信息,并参与后续 logprob、reward 和 advantage 计算。
因此 vLLM 图模式也不能只写成“开不开 CUDA Graph”。在 verl rollout 里,enforce_eager、compilation_config.cudagraph_mode 和 cudagraph_capture_sizes 共同决定性能、显存、capture 成本和兼容性。
Rollout 特性¶
普通推理关注 latency / throughput;RL rollout 还要关注:
- policy version:response 来自哪个 actor checkpoint。
- sample id / group id:同一 prompt 的多条采样必须可追踪。
- response mask:哪些 token 属于有效 response。
- logprob 口径:old logprob、rollout logprob、actor recompute logprob 是否一致。
- metadata 回流:finish reason、abort status、routing metadata、accepted token mask 是否完整。
这些信息决定了 rollout 输出能否无损进入 reward、old logprob、ref logprob、advantage 和 actor update。
vLLM 执行路径¶
典型 vLLM rollout 包含:
- prefill:处理 prompt,建立 KV cache。
- decode:逐步生成 response token。
- sampling:按温度、top-p、stop 条件采样。
- postprocess:生成 response mask、metadata、logprob 或 routed experts。
- DataProto 回填:把输出写回训练数据结构或 TransferQueue。
RL rollout 通常 decode-heavy,因此图重放对减少 host launch overhead 很有价值。但图本身会占显存,capture size 过大也会放大 warmup 和常驻资源压力。
eager 与图模式¶
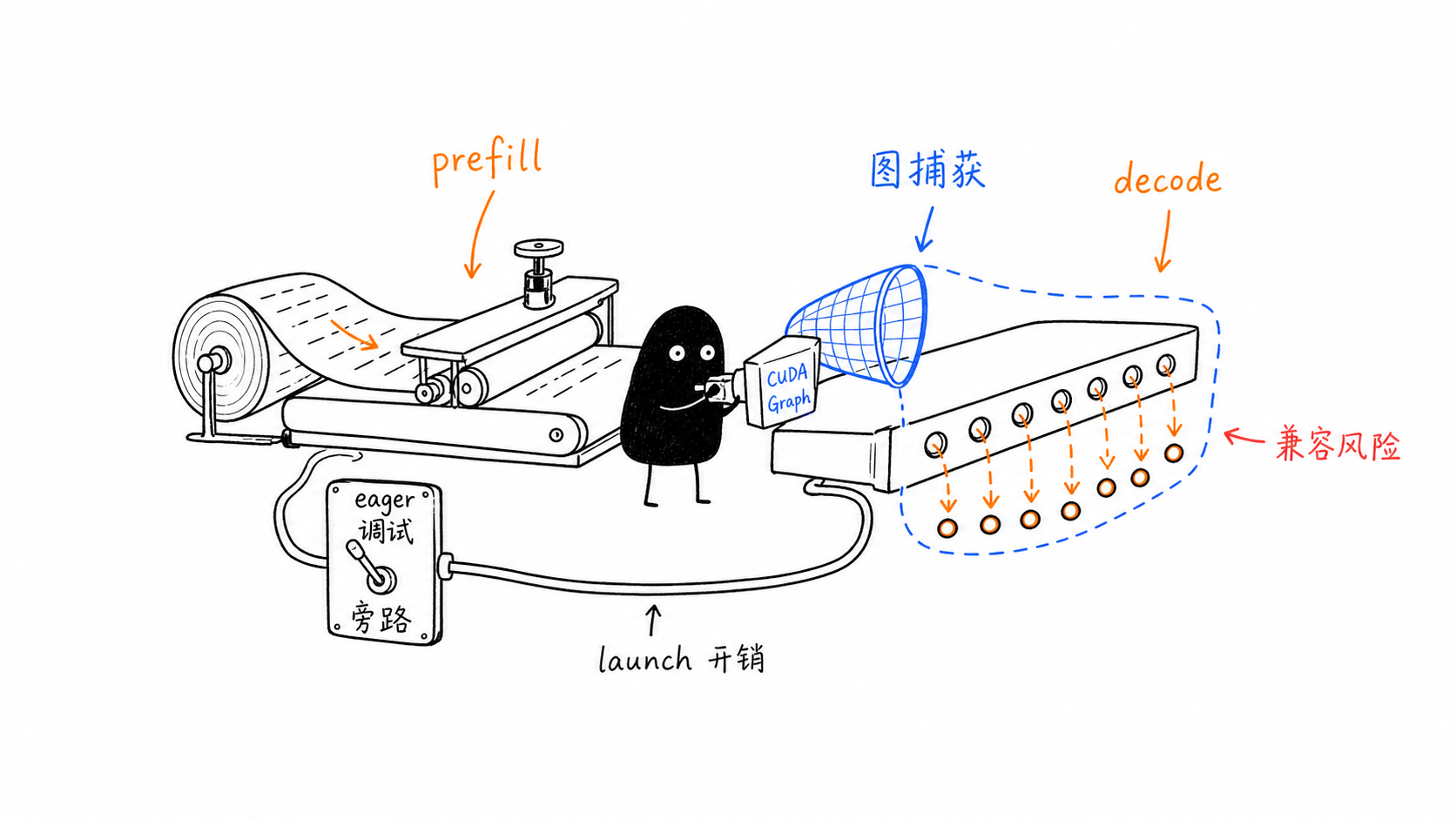
enforce_eager=True 是最强的调试开关:它让 vLLM 禁用 torch.compile 和 CUDA Graph,牺牲性能换取更直接的执行路径。当前 vLLM 默认 enforce_eager=False;verl rollout 配置也倾向默认关闭 eager,让 vLLM 使用图模式。1
enforce_eager=False 后,vLLM 通过 compilation_config.cudagraph_mode 控制图捕获策略。常见模式如下:
| 模式 | 语义 | 适合场景 | 风险 |
|---|---|---|---|
NONE |
不做 cudagraph capture | debug、平台不支持图 | 性能通常较弱 |
PIECEWISE |
捕获 cudagraph-compatible 片段 | attention backend 对 full graph 支持不足 | 图外边界仍有开销 |
FULL |
尝试 full graph | backend 支持好、shape 稳定 | 兼容性和显存压力 |
FULL_DECODE_ONLY |
decode batch full graph,prefill/mixed 不用图 | P/D 分离、decode-heavy rollout | prefill/mixed batch 收益小 |
FULL_AND_PIECEWISE |
decode full graph,prefill/mixed piecewise | vLLM V1 默认推荐路径 | capture 多、图显存更高 |
双模式不是新 runtime
FULL_DECODE_ONLY 和 FULL_AND_PIECEWISE 容易被误解成新底层运行时。更准确地说,它们是 dual-mode 策略:根据 batch descriptor 在 FULL、PIECEWISE 和 NONE 之间调度。
capture sizes¶
cudagraph_capture_sizes 决定 vLLM 为哪些 batch / token 尺寸提前 capture 图。尺寸覆盖越多,图命中率越高;但 warmup 时间、常驻显存和 graph cache 也会增加。
在 RL rollout 中,KV cache 可以随 sleep / wakeup 或权重同步释放,但图本身不能像 KV cache 一样随意 offload。因此显存紧张时,应该优先尝试较小的 capture size 列表,而不是盲目保留默认大范围 capture。
示例配置:
actor_rollout_ref.rollout.enforce_eager=False
+actor_rollout_ref.rollout.engine_kwargs.vllm.compilation_config.cudagraph_mode=FULL_AND_PIECEWISE
+actor_rollout_ref.rollout.engine_kwargs.vllm.compilation_config.cudagraph_capture_sizes=[8,16,32,64,128]
如果是 decode-heavy 的 P/D 分离或希望降低 piecewise graph 显存,可以尝试:
版本边界
verl v0.8.0 中,rollout.cudagraph_capture_sizes 仍可能通过旧参数名 cuda_graph_sizes 传给 vLLM;当前 verl main 已按 vLLM 版本做兼容分支:<=0.11.0 继续使用 cuda_graph_sizes,>0.11.0 写入 compilation_config.cudagraph_capture_sizes。写实验记录时要同时保存 verl 与 vLLM 版本。
配置路径¶
可以把配置传递链理解为:
rollout.yaml
-> RolloutConfig
-> vllm_async_server
-> vLLM EngineArgs
-> CompilationConfig
-> CUDAGraphDispatcher
verl 的 vLLM rollout server 会从 engine_kwargs.vllm.compilation_config 读取图模式配置,并在缺省时补 FULL_AND_PIECEWISE;当 decode_context_parallel_size > 1 且 full graph 不支持时,会降级为 PIECEWISE。2
服务化 rollout¶
内嵌式 rollout¶
- 优点:路径短,调试直接,生命周期简单。
- 缺点:训练和推理强耦合,资源隔离与弹性较差。
服务化 rollout¶
- 优点:隔离推理资源,便于弹性扩缩,便于多训练任务复用。
- 风险:网络延迟、故障恢复、权重同步、policy version 一致性。
FullAsync、AgentLoop server、vLLM server mode 和 TransferQueue 都会把 rollout 服务化需求推得更明显。
与其它文章的边界¶
TransferQueue 不是 rollout backend 小特性,而是 RL 数据系统。它的机制、v1 trainer 集成和 controller 数据瓶颈讨论见 VeRL TransferQueue。
Speculative decoding 的 MTP / DFlash 讨论见 VeRL Speculative Decoding。
MoE 路由结果回传与复放见 VeRL Router Replay。
推理侧 DFX¶
| 指标 | 目的 |
|---|---|
| TTFT / TPOT | 区分 prefill 和 decode 瓶颈 |
| request latency p50 / p99 | 观察长尾 rollout |
| prefill / decode throughput | 判断图模式是否覆盖主路径 |
| graph capture time | 判断 warmup 成本 |
| graph hit ratio | 判断 capture sizes 是否合适 |
| peak memory / graph memory | 判断图缓存显存压力 |
| KV cache utilization | 判断 batch 与长度分布 |
| abort / timeout ratio | 判断 rollout 服务稳定性 |
| response clip ratio | 判断 max response length 设置 |
实践建议¶
- 先 eager baseline:小 batch、短 response、日志完整,确认语义正确。
- 默认图模式:
enforce_eager=False,优先FULL_AND_PIECEWISE。 - 调 capture sizes:按真实 decode batch 分布选择尺寸。
- 尝试 FULL_DECODE_ONLY:在 decode-heavy 或显存紧张时验证。
- 记录版本边界:verl、vLLM、vLLM-Ascend、attention backend 都要记录。
参考文献¶
-
vLLM CUDA Graphs documentation and vLLM
CompilationConfig. ↩ -
verl
vllm_async_server.pyhandlescudagraph_mode,cudagraph_capture_sizes, and DCP downgrade. ↩