AI Post Traning: DiffusionNFT
导言
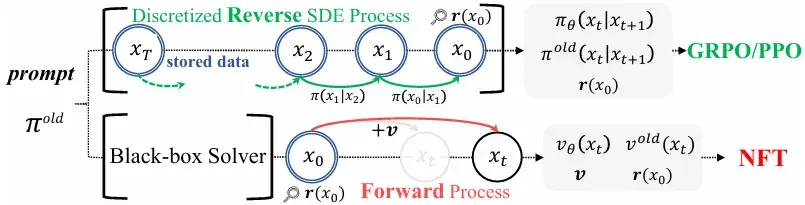
DiffusionNFT 直接在前向加噪过程(forward process)上进行优化,在彻底摆脱似然估计与特定采样器依赖的同时,显著提升了训练效率与生成质量。在GenEval任务上,DiffusionNFT仅用约1.7k步就达到0.94分,而对比方法FlowGRPO需要超过5k步且依赖CFG才达到0.95分。这表明DiffusionNFT的训练效率比FlowGRPO快约25倍。
动机¶
- 似然估计困难:自回归模型的似然可精确计算,而扩散模型的似然只能以高开销近似,导致 RL 优化过程存在系统性偏差。1
- 解释:指扩散模型的打分相对于LLM困难
- 前向–反向不一致:现有方法仅在反向去噪过程中施加优化,没有对扩散模型原生的前向加噪过程的一致性进行约束,模型在训练后可能退化为与前向不一致的级联高斯。
- 采样器受限:需要依赖特定的一阶 SDE 采样器,无法充分发挥 ODE 或高阶求解器在效率与质量上的优势。
- CFG 依赖与复杂性:现有 RL 方案在集成无分类器引导 (CFG) 时需要在训练中对双模型进行优化,效率低下。
思路¶
为什么不直接在“加噪”的前向过程中融入奖励信号呢?与其在去噪的每一步艰难地“纠正”方向,不如从一开始就引导整个扩散过程,使其“避开”通往低奖励样本的路径。DiffusionNFT 将强化学习的目标巧妙地转化为一个对前向过程的微调任务,从而完全绕开了棘手的似然估计问题。
创新点¶
1 负例感知微调 (Negative-aware FineTuning, NFT)¶
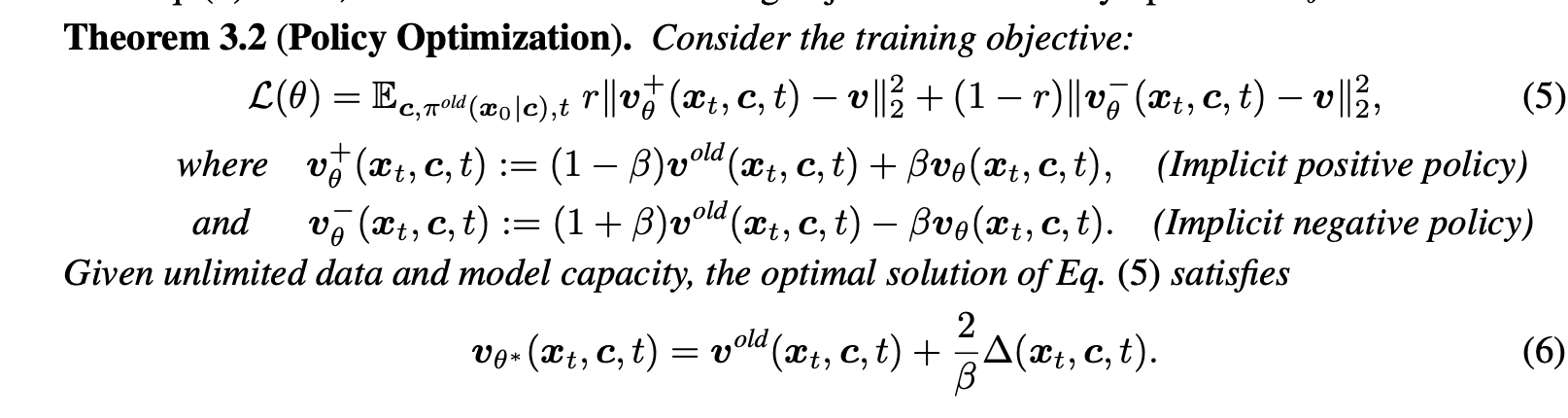
核心公式解释看1,
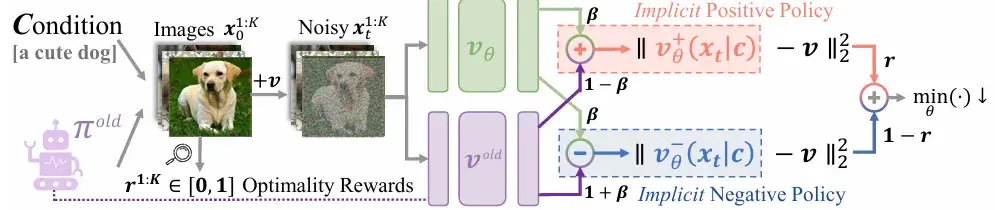
DiffusionNFT 是 DPO变种
代码跳读¶
入口scripts/train_nft_sd3.py
for epoch in range(first_epoch, config.num_epochs):
for i in tqdm(
range(config.sample.num_batches_per_epoch),
desc=f"Epoch {epoch}: sampling",
disable=not is_main_process(rank),
position=0,
):
# eval_fn 函数的主要目的是在训练过程中对模型进行评估。
images, latents, _ = pipeline_with_logprob()
rewards_future = executor.submit(reward_fn, images, prompts, prompt_metadata, only_strict=True)
# advantages 来自 reward 的平均值等计算,对应公式5的 r 项
normalized_advantages_clip = (advantages_clip / config.train.adv_clip_max) / 2.0 + 0.5
r = torch.clamp(normalized_advantages_clip, 0, 1)
# 切换模型到"旧"参数状态以获取参考预测值
transformer_ddp.module.set_adapter("old")
with torch.no_grad():
# prediction v
old_prediction = transformer_ddp(
hidden_states=xt,
timestep=train_sample_batch["timesteps"][:, j_idx],
encoder_hidden_states=embeds,
pooled_projections=pooled_embeds,
return_dict=False,
)[0].detach()
transformer_ddp.module.set_adapter("default")
# prediction v
forward_prediction = transformer_ddp(
hidden_states=xt,
timestep=train_sample_batch["timesteps"][:, j_idx],
encoder_hidden_states=embeds,
pooled_projections=pooled_embeds,
return_dict=False,
)[0]
# 对应公式5的 正负 v 项
positive_prediction = config.beta * forward_prediction + (1 - config.beta) * old_prediction.detach()
implicit_negative_prediction = (
1.0 + config.beta
) * old_prediction.detach() - config.beta * forward_prediction
timestep对效果影响很大,原仓没实现
Adaptive Weighting. We find stability improves when the flow-matching loss is given higher weight at larger t, whereas inverse strategies (e.g., w(t) = 1 − t) lead t
生成sampling¶
def run_sampling(
v_pred_fn,
z,
sigma_schedule,
solver="flow",
determistic=False,
eta=0.7,
):
assert solver in ["flow", "dance", "ddim", "dpm1", "dpm2"]
dtype = z.dtype
all_latents = [z]
all_log_probs = []
if "dpm" in solver:
order = int(solver[-1])
dpm_state = DPMState(order=order)
for i in tqdm(
range(len(sigma_schedule) - 1),
desc="Sampling Progress",
disable=not dist.is_initialized() or dist.get_rank() != 0,
):
sigma = sigma_schedule[i]
pred = v_pred_fn(z.to(dtype), sigma)
if solver == "flow":
z, pred_original, log_prob = flow_grpo_step(
)
elif solver == "dance":
z, pred_original, log_prob = dance_grpo_step(
pred.float(), z.float(), eta if not determistic else 0, sigmas=sigma_schedule, index=i, prev_sample=None
)
elif solver == "ddim":
z, pred_original, log_prob = ddim_step(
pred.float(), z.float(), eta if not determistic else 0, sigmas=sigma_schedule, index=i, prev_sample=None
)
elif "dpm" in solver:
assert determistic
z, pred_original, log_prob = dpm_step(
)
else:
assert False
z = z.to(dtype)
all_latents.append(z)
all_log_probs.append(log_prob)
latents = z.to(dtype)
return latents, all_latents, all_log_probs
这部分逻辑和danceGRPO是类似的,但是训练没有对应逻辑,并且all_latents只用于计算x0
x0 = train_sample_batch["latents_clean"]
t = train_sample_batch["timesteps"][:, j_idx] / 1000.0
t_expanded = t.view(-1, *([1] * (len(x0.shape) - 1)))
noise = torch.randn_like(x0.float())
xt = (1 - t_expanded) * x0 + t_expanded * noise