World Model/UFMs/Omni-Modal: AR vs DiT
导言
视觉领域的GPT moment要来了吗?4
- World Model: (e.g., Emu3.5)
- Unified Foundation Models, UFMs,强调视觉能力的闭环。证明模型能像“看懂”图片一样“画出”图片。(e.g.,Bagel, Lumina, Emu3.5)
- Omni 强调交互能力的闭环。证明模型能像真人一样,具备实时、全感官的反应。图片生成暂时不是必须的(e.g.,Qwen-3-Omni、longcat-omni), 但是也能支持(e.g., Ming-Omni)
当前多模态设计中AR和DiT的组合关系,单独学习一下
GPT时刻?¶
视频模型将会成为CV 领域统一、通用的基础模型,正如 LLMs 已经成为 NLP 的基础模型。4
在过去几年,NLP 经历了一场彻底的变革:
- 从任务定制化的模型(例如,一个模型用于翻译,另一个用于问答,还有一个用于摘要)转变为 LLMs 作为统一的基础模型,
- 如今的 LLMs 具备通用语言理解能力,使得单一模型能够应对多种任务。
- 通过 prompt engineering,只需要 zero-shot 或 few-shot 即可处理下游任务。
而如今的 Machine vision 与几年前 NLP 领域的状态相似:
- 存在一些针对特定任务的优秀模型,如用于分割的“Segment Anything” ,用于检测的 YOLO 系列等。
- 尽管已有尝试统一某些视觉任务的工作,但是目前尚无模型仅通过精调 prompt 就能解决任何问题。
- 在 NLP 中已经验证的能在 zero-shot的基本要素,同样适用于今天的生成式视频模型——在大规模数据上训练以生成(文本/视频延续)的生成式大模型。
在本文中,作者提出疑问:视频模型是否发展出了通用视觉理解能力,类似于大模型(LLMs)发展出通用语言理解能力?作者认为答案是肯定的:
- 通过对 62 项定性任务和 7 项定量任务下的 18,384 个生成视频进行分析, Veo 3 能够解决未训练或微调过的广泛 Range 任务。
- 基于其感知、建模和操控视觉世界的能力,Veo 3 展现了初步的“帧链(Chain-of-Frames, CoF)”视觉推理,如迷宫和对称性求解。
- 尽管task-specific 模型仍优于 zero-shot 视频模型,但从 Veo 2 到Veo 3 性能有了显著且一致的提升,即着视频模型能力正迅速进步。
2512 Kling-Omni¶
RL 使用 DPO,嫌弃GRPO慢
2511 LongCat-flash-omni (TIA2TA)¶
- 基于2509的LongCat-flash开发的
- 特点:
- Shortcut-connected MoE (ScMoE): 零计算专家机制(Zero-computation Experts):模型引入一类特殊的“零计算专家”,当处理常见词汇、标点符号等低复杂度输入时,该专家直接返回原始输入,跳过复杂的矩阵运算,从而节省算力。简单任务(如文本补全)激活少量专家,复杂任务(如数学推理)则调动更多专家资源。
- 模态分离(Modality-Decoupled Parallelism, MDP)是LongCat-Flash-Omni为解决多模态训练异构性问题提出的核心分布式训练策略。其核心思想是使用(ModalityBridge)将模态编码器(视觉/音频编码器)与LLM主干在分布式层面完全解耦,实现独立优化。


2511 ERNIE-5.0-Preview-1120¶
文心 5.0 采用原生全模态统一建模技术,具备全模态理解与生成能力,支持文本、图像、音频、视频等多种信息的输入与输出,在多模态理解、指令遵循、创意写作、事实性、智能体规划与工具应用等方面表现突出,拥有强大的理解、逻辑、记忆和说服力。LLMarena
2510 Lumina-DiMOO 上海AILab (TIV2TIV)¶
DiMOO “Discrete Multi-modal Omni-mOdel”
- 背景: 一类是基于自回归(AR)的模型,比如 GPT 系列,它们通过一步步预测下一个 token 来生成内容,但在生成高分辨率图像时,这个过程会非常漫长,效率不高。另一类是混合了 AR 和扩散(Diffusion)的模型,虽然有所改进,但两种范式的“混搭”也带来了额外的复杂性。
- 架构:不同于大家熟悉的自回归(AR)模型或是混合AR-扩散模型,Lumina-DiMOO另辟蹊径,采用了一种完全离散的扩散(fully discrete diffusion)方法,巧妙地实现了对图像、文本等多种模态的统一处理。
- 核心思想:
- 不再区分文本、图像或其他模态,而是将它们统统“打碎”成离散的 token 序列。无论是文字、图片,还是控制信号,在这个模型眼里都是一视同仁的 token。
- 巧妙利用token mask, 来实现推理。
2510 Emu3.5 智源 (TIV2TIV)¶
悟界·Emu3.5
- 特点:
- 实现了从“下一Token 预测”(Next-Token Prediction)到“下一状态预测”(Next-State Prediction)的能力跃迁:从预测词元,到预测视频下一帧?实现方式:数据不再是图像文本对,而是连续视频输入。
- “多模态 Scaling”规律(从数据年限、质量、模态交错密度到模型参数/目标的协同扩展):预训练采用 >10 万亿多模态 tokens,主力来自互联网视频及转录文本,累计视频时长约 790 年;这是从此前级别(~15 年)的大跨越。
- 离散扩散适配 (DiDA):复制一份图像噪声来加速推理(感觉类似token的投机推理MTP)
- 强化学习:GRPO + 复合奖励系统: 通用奖励(美学、图文一致性)+任务奖励(OCR 准确率、人脸 ID 保持、布局对齐等)

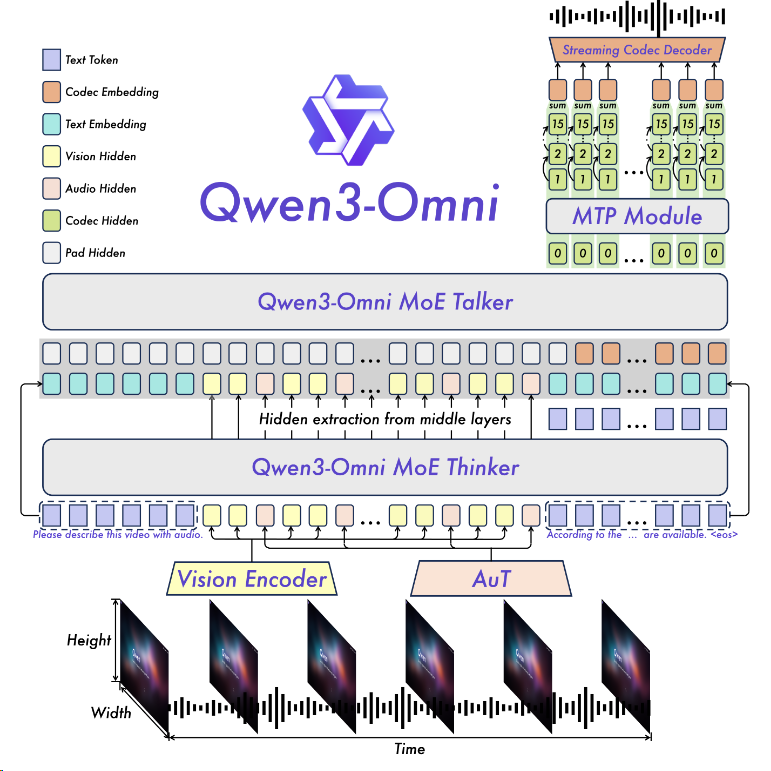
2509 Qwen3-Omni (TIVA2TA)¶
特点:
- 理解音频:大部分Vision模型只能理解语言、图片和视频,但是Omini能理解音频;
- 生成音频:不仅能生成文字,还能生成音频
- 架构特点: Thinker-Talker结构(简单理解: LLM 30B常规理解+音频生成 3B小模块)
- 应用场景: 能直接理解和生成输出多种语言,这在人机交互时是非常重要的体验提升,不用再繁琐的打字和阅读,可以和人交互样使用。
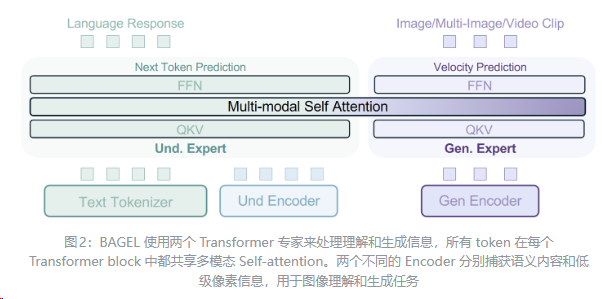
2507 BAGEL 字节¶
- 采用 MoT(Mixture-of-Transformers-Experts) 架构,包含两个独立专家:
- 理解专家:处理文本和ViT视觉特征(用于图像理解)。
- 生成专家:处理VAE视觉特征(用于图像生成)。
- 共享自注意力机制实现跨模态上下文交互,避免传统模型的信息瓶颈。
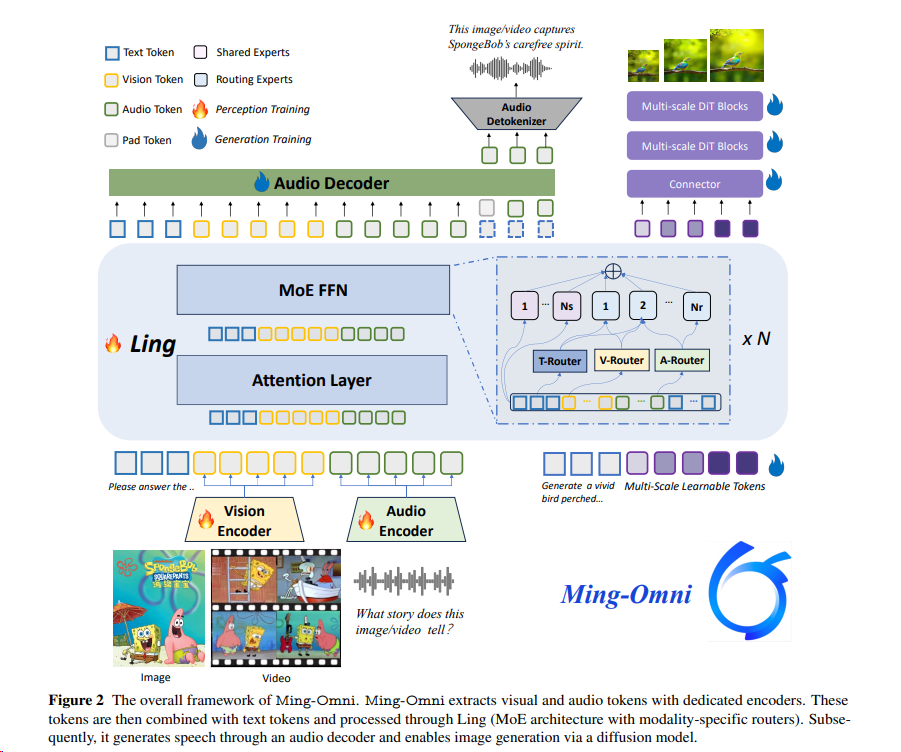
2506 Ming-Omni (TIV2TI)¶
综述¶
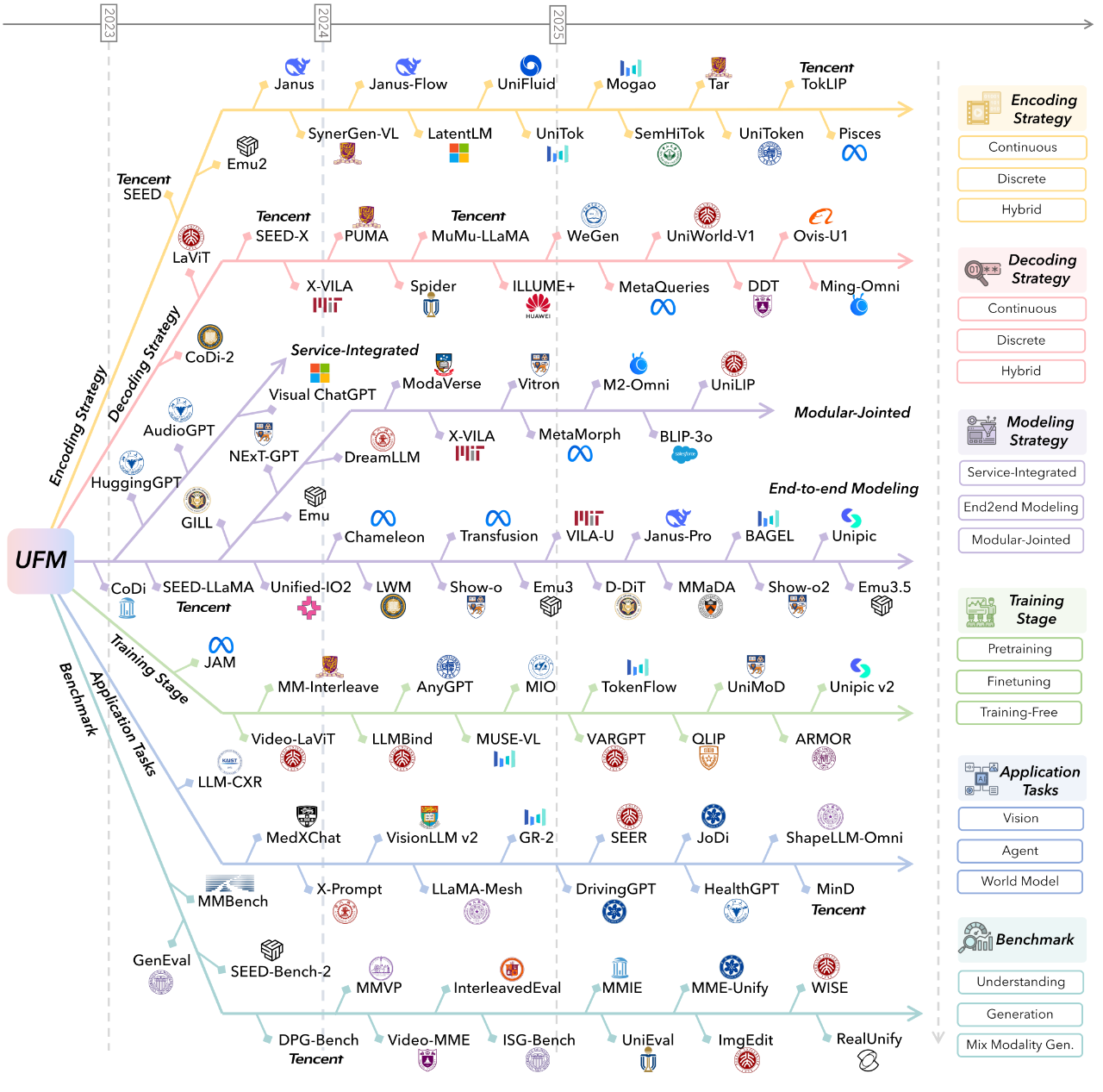
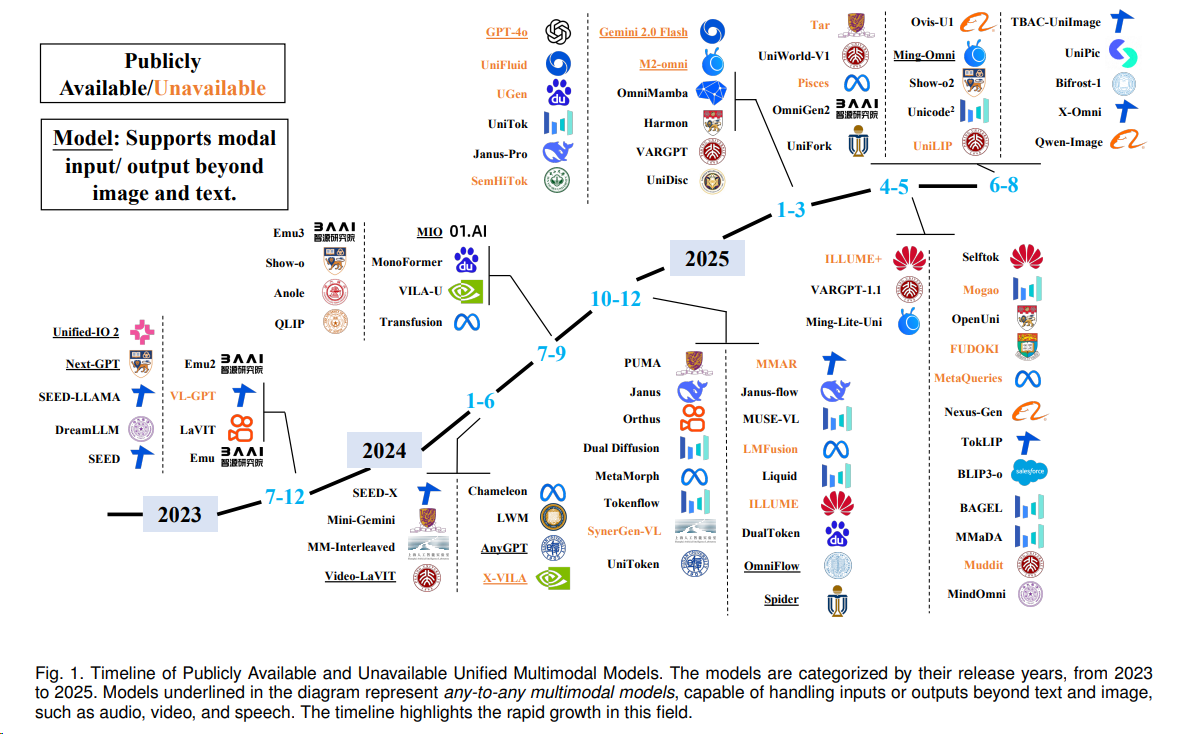
UFMs的设计¶
早期¶
外部服务集成建模将大语言模型作为功能核心,通过调用外部 API(如文生图模型)来完成生成任务。2
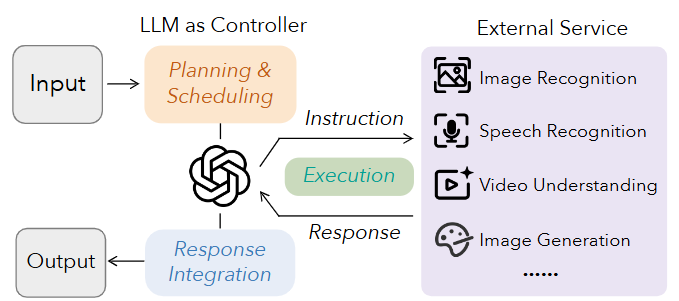
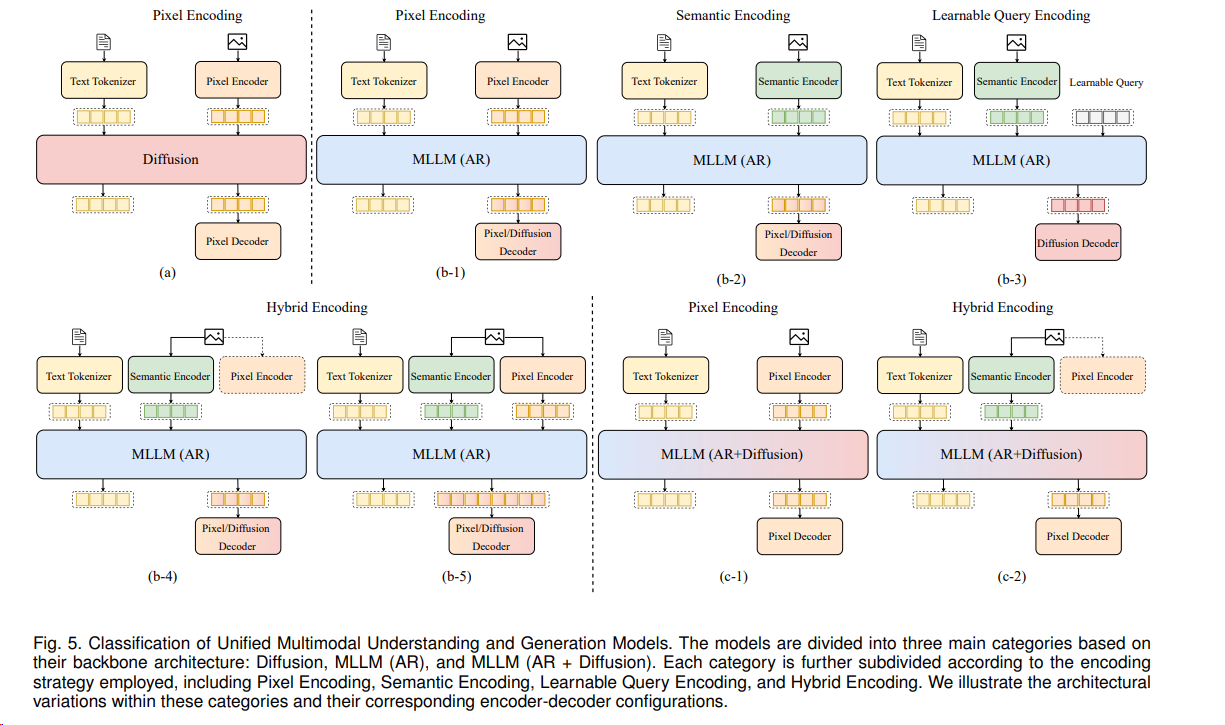
当前主流分类¶

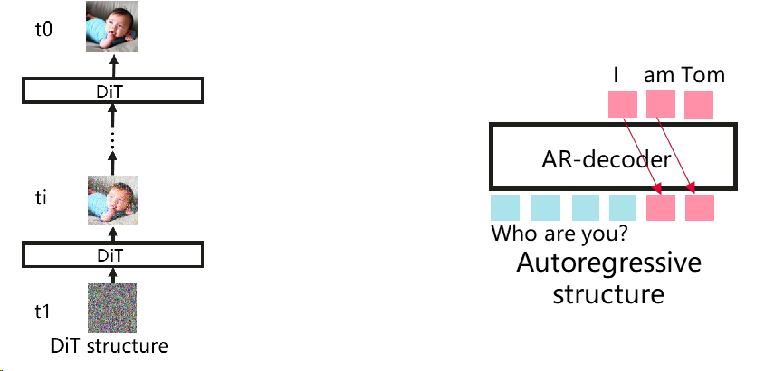
AR 和 DiT 的区别¶
- Diffusion Transformer(DiT):在采样时间戳的控制下,利用随机潜在噪声初始化,变换器模型迭代地预测多个步骤的潜在输出。最后,由变分自动编码器 (VAE) 的解码器对其进行解码。vLLM不支持。1
- 自回归(Autoregressive):文本的主导生成范式,vLLM支持。它生成令牌的条件在以前的令牌一个接一个。vLLM提供的高效KV缓存管理可以有效地加速推理。
| 特性 | 自回归(AR) | DiT(Diffusion-based Iterative Transformer) |
|---|---|---|
| 场景 | 文本生成 | 多模态生成 |
| 生成方式 | Token-by-token,从左到右 | 连续向量,迭代细化 |
| 主要优势 | 局部一致性好 | 全局一致性、多样性和可控制性强 |
| 效率 | 更高效的 KV 缓存 | 需要反复生成,速度较慢 |
| 误差累积 | 容易累积 | 可在后续迭代中修复 |
| 主要挑战 | 全局规划能力有限,长上下文生成困难 | 全局计算成本巨大 |
| 序列长度 | 可变长度 | 固定长度 |
| 注意力掩码 | 下三角形(因果掩码) | 全双向矩阵 |
| 并行策略 | TP, DP, PP 等 | DP, CP 等 |
| vLLM 支持 | 支持 | 不支持 |
全模态模型的AR和DiT构成¶
广义的理解:AR可以给模型引入理解能力,DiT能给模型带来生成能力。所以两者不同的占比,带来了不同的模型设计:1
DiT作为主要结构,AR作为文本编码器¶
用于图像生成和编辑的流行模型。主要的视觉生成模型与结构相似,如Flux。(例如: qwen-image)
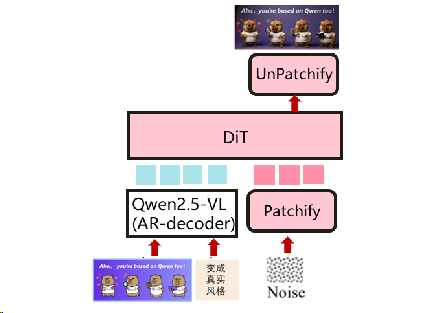
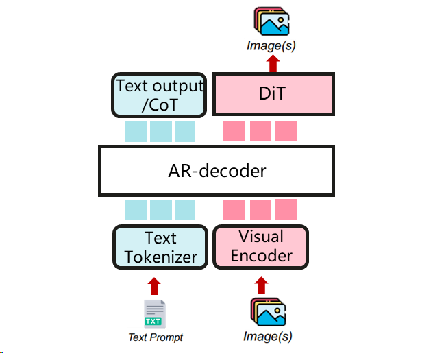
AR作为主要结构,DiT作为多模式生成器¶
一个统一的多模态理解和生成模型。视觉生成可以利用CoT文本生成输出。主要的统一多模态模型与结构相似。 (例如BAGEL)
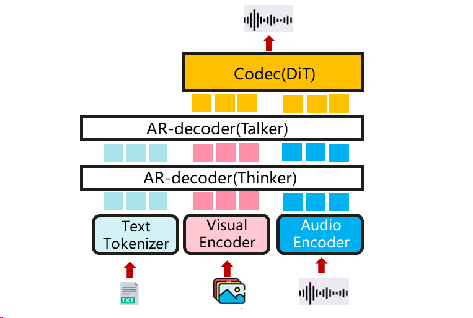
扩展,multi-AR + DiT¶
多模态输入输出的新模型。它设计了thinker-talker-codec结构,该结构是双AR+DiT格式。(例如qwen-omni)
UFMs vs Omni¶
在多模态(Multimodal)AI 领域,这三个概念其实反映了从“拼凑组合”到“深度融合”再到“全能集成”的技术演进过程。你可以把它们理解为三个不同层级的定义:
1. 多模态模型 (Multimodal Model) —— “基础广义概念”¶
这是最宽泛的概念。只要一个模型能够处理(输入或输出)超过一种类型的数据(如文本+图片、文本+音频),就可以被称为多模态模型。
- 核心特征: 跨模态交互。
- 实现方式: 早期多采用“搭积木”的方式。比如,用一个视觉编码器(如 CLIP)提取图片特征,再喂给一个语言模型(LLM)来理解。
- 局限性: 很多早期的多模态模型是“偏科生”。例如 LLaVA 擅长理解图片并回答问题,但它自己不能生成图片;Stable Diffusion 擅长生成图片,但它不具备复杂的对话逻辑。
2. 生成理解统一模型 (Unified Understanding and Generation) —— “技术架构目标”¶
这是研究界针对“偏科”问题提出的技术方案。在 2024-2025 年的研究中,核心在于打破自回归 (AR)(擅长理解和文本生成)与 扩散模型 (Diffusion)(擅长视觉生成)之间的壁垒。
- 核心特征: “同构化”。同一个模型,既能像人类一样“读懂”图片,又能像画家一样“画出”图片。
- 实现方式:
- 离散化 (Tokenization): 将图片、音频也像文字一样切成一个个“Token”。模型像预测下一个字一样预测下一个像素块(例如 Chameleon, Llama 3.2 视觉版的部分思路)。
-
架构融合: 在同一个 Transformer 架构中,交替进行理解任务和生成任务。
-
意义: 实现了双向流通。理解能力可以辅助生成更符合逻辑的内容,生成任务也能增强模型对细节的感知。
3. Omni 模型 —— “全能、原生、实时”¶
“Omni” 源自拉丁语 omnis(意为“全、总”),由 OpenAI 的 GPT-4o 带火。它不仅是技术上的统一,更强调交互体验的无缝化。
- 核心特征:
- 原生 (Native): 并非先转写文字再理解。模型从头开始就在文本、音频、图像的混合数据上训练,具有“原生感官”。
- 全输入全输出 (Any-to-Any): 任意模态进,任意模态出。你可以对着它说话,它直接用带情感的语音回你,中间不经过文字转写。
-
实时低延迟: 响应速度极快,模拟人类的感官反应(如 300ms 左右的语音反馈)。
-
代表作: GPT-4o, Mini-Omni, Moshi。
核心区别对比表¶
| 概念 | 关注点 | 典型能力 | 举例 |
|---|---|---|---|
| 多模态 (Multimodal) | 数据类型 | 能看图说话,或能根据文字画图。 | CLIP, LLaVA, DALL-E |
| 生成理解统一 (Unified) | 架构融合 | 同一个模型既能 VQA(问答)也能文生图。 | Chameleon, Show-o, SEED-X |
| Omni 模型 | 原生交互 | 毫秒级响应,语音/视觉/文本原生流式处理。 | GPT-4o, Mini-Omni |
总结¶
- 多模态是你的“研究领域”;
- 生成理解统一是你要攻克的“技术难点”(如何让一个模型学会所有技能);
- Omni 是你最终想要达成的“产品形态”(像真人一样对世界进行全方位、实时的感知和表达)。
Omni不支持图片输出?¶
Omni 模型不支持图片输出,是因为目前市面上最火的几个标杆(如早期的 GPT-4o 演示或开源的 Mini-Omni)在输出端的表现各有侧重。
实际上,“Omni” 的终极目标是 Any-to-Any(任意到任意),但在现实落地的过程中,不同模型由于其侧重领域不同,表现出了差异:
1. 为什么你会有“不支持图片输出”的印象?¶
- 初期阶段的割裂: 2024 年 GPT-4o 发布初期,虽然号称是原生多模态,但它生成图片依然通过“调用 DALL-E 3”这个外部工具实现,而不是模型直接吐出像素或图片 Token。
- Omni 模型的“音频优先”倾向: 很多冠以 “Omni” 之名的开源模型(如 Mini-Omni, Moshi)核心突破点在于实时语音交互(Speech-to-Speech)。对这些模型来说,音频流的实时性比图片生成更具“Omni(全感官)”的代表性,因此它们往往放弃了图片输出。
- 计算开销: 在同一个模型里既要处理高频音频流,又要处理复杂的视觉像素生成,对架构设计和显存的要求极高。
2. “Omni” 与 “生成理解统一” 在图片输出上的核心区别¶
虽然两者都在往“全能”发展,但它们的出发点不同:
| 维度 | 生成理解统一模型 (Unified) | Omni 模型 (Omni) |
|---|---|---|
| 首要任务 | 视觉能力的闭环。证明模型能像“看懂”图片一样“画出”图片。 | 交互能力的闭环。证明模型能像真人一样,具备实时、全感官的反应。 |
| 图片输出方式 | 原生 Token 生成。把图片切成 Token,像写作文一样“写”出一张图(如 Chameleon, Show-o)。 | 端到端流式输出。目标是无需切换模型,直接流式吐出语音、文字甚至视频/图片流(如最新的 GPT-4o 2025 版)。 |
| 典型案例 | Show-o, OmniGen。这类模型能根据指令精准改图、扩图,视觉逻辑极强。 | GPT-4o, Ming-Omni。这类模型更强在“边听、边看、边说”,图片输出是其全能属性的一环。 |
3. 最新的进展:Omni 正在补齐图片输出¶
到 2025 年,这个界限正在模糊,“Omni” 正在收割“生成理解统一”的技术成果:
- GPT-4o (2025版): 已逐步实现在模型内部原生生成图片(Native Image Generation),不再依赖 DALL-E。这让它在生成文字排版、逻辑连贯的连环画上有了质的飞跃。
- OmniGen 2: 这是一个典型的“生成理解统一”模型,它不仅支持图片输出,甚至能把所有的视觉任务(如边缘检测、物体识别)都统一成“图片生成”任务。
- Ming-Omni: 这是一个开源的尝试,它真正做到了在一个模型里同时支持语音、文本和图片的原生输出。
总结¶
- 如果你看到一个模型强调“画图”和“改图”的逻辑统一,它更倾向于被归类为 Unified(统一模型)。
- 如果你看到一个模型强调“实时对话”和“感官共情”,它就是典型的 Omni(全能模型)。
当前的趋势是: Omni 模型正在通过吸纳“生成理解统一”的技术架构(如离散化 Token 方案),从而获得真正的原生图片输出能力。
参考文献¶
-
https://docs.vllm.ai/projects/vllm-omni/en/latest/design/architecture_overview/ ↩↩
-
Unified Multimodal Understanding and Generation Models: Advances, Challenges, and Opportunities ↩↩