VeRL
导言
VeRL 作为RL领域趋势最火的开源仓,值得学习。
核心设计¶
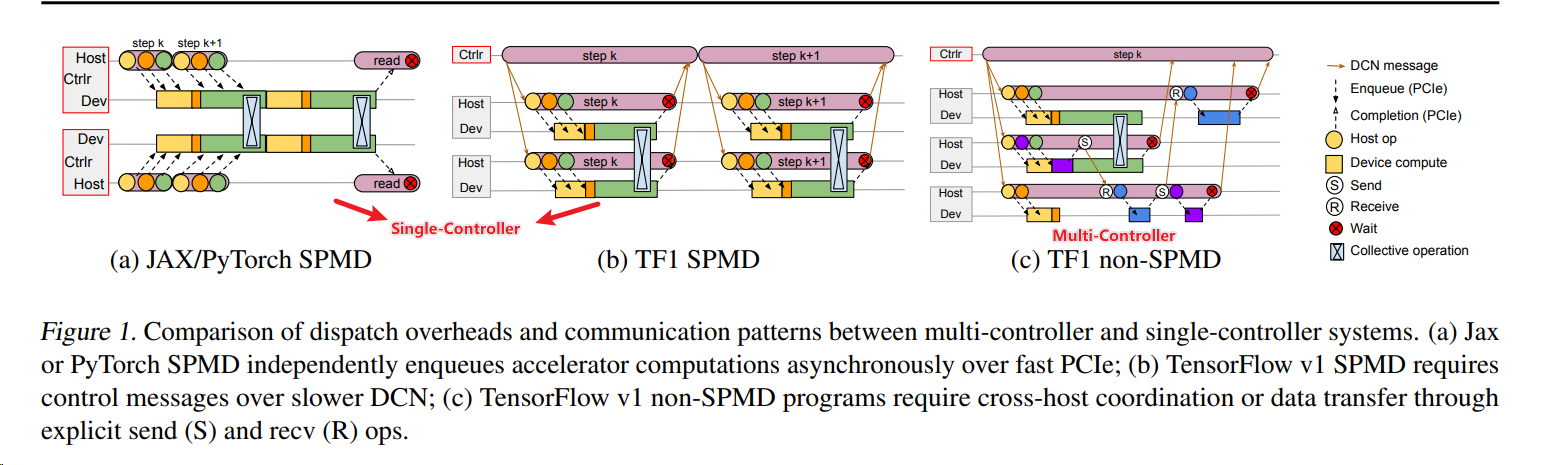
Single/Multi-Controller¶
Google Pathways2 在论文中对这两点做了非常详细的阐述。
- Single-Controller 由一个中心控制器驱动所有 worker 工作,这个中心控制器向所有 worker 发送数据和计算指令,worker 可以运行不同的程序(MPMD)。
- 优点是灵活、异构,即每个 worker 可以执行不同的算法;
- 缺点是因为是单点控制,所以会引入额外的通信开销。
- 典型的 Single-Controller,比如 Spark、TensorFlow1.0 的 non-SPMD 的模式。
- Multi-Controller 无中心控制器,各个 worker 自驱,各自计算,通过一些通信原语进行同步,worker 运行相同的程序(SPMD)。
- 优点是高效;
- 缺点是因为同构所以不够灵活。
- Multi-Controller 则更普遍,基本上主流的开源 RLHF 分布式训练框架,比如 Megatron-LM、Deepspeed、FSDP,以及 vLLM 都是 Multi-Controller 模式的。这是因为主流 RLHF 框架基本上是从预训练框架演进而来,而预训练基本上都是 Multi-Controller 模式。
HybridFlow¶
核心思想1:
- 通过Single-Controller来实现RL算法控制的数据流,并易修改拓展,支持简单单进程调用;
- 通过Multi-Controller来实现各个推理/训练组件:
- 基于已有框架
- 训练:megatron/FSDP1/FSDP2
- 推理:vllm/SGlang
参数说明¶
三个batch_size的解释
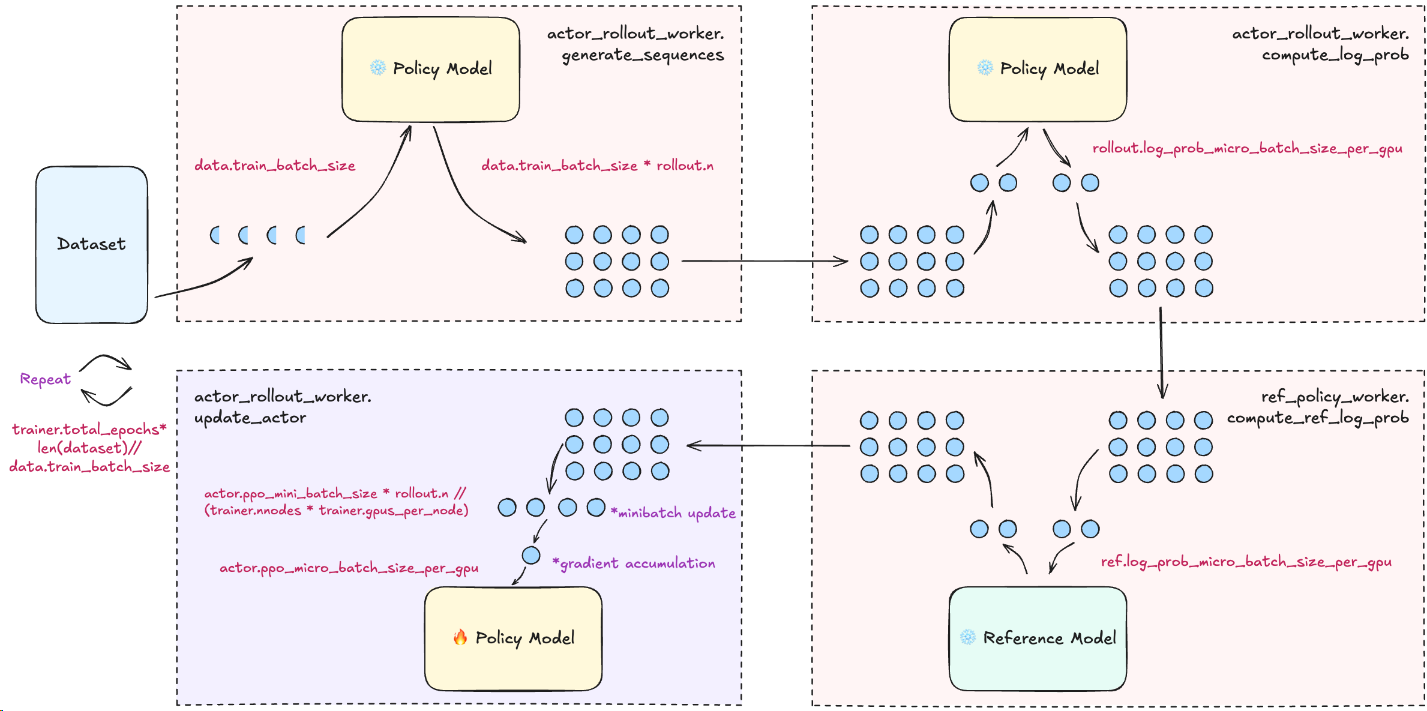
其余参数参考,link
GRPO 日志输出指标¶
[
"actor/entropy",
"actor/kl_loss",
"actor/kl_coef",
"actor/pg_clipfrac",
"actor/ppo_kl",
"actor/pg_clipfrac_lower",
"actor/pg_loss",
"actor/grad_norm",
"perf/mfu/actor",
"perf/max_memory_allocated_gb",
"perf/max_memory_reserved_gb",
"perf/cpu_memory_used_gb",
"actor/lr",
"val-core/hiyouga/geometry3k/reward/mean@1",
"training/global_step",
"training/epoch",
"critic/score/mean",
"critic/score/max",
"critic/score/min",
"critic/rewards/mean",
"critic/rewards/max",
"critic/rewards/min",
"critic/advantages/mean",
"critic/advantages/max",
"critic/advantages/min",
"critic/returns/mean",
"critic/returns/max",
"critic/returns/min",
"response_length/mean",
"response_length/max",
"response_length/min",
"response_length/clip_ratio",
"response_length_non_aborted/mean",
"response_length_non_aborted/max",
"response_length_non_aborted/min",
"response_length_non_aborted/clip_ratio",
"response/aborted_ratio",
"prompt_length/mean",
"prompt_length/max",
"prompt_length/min",
"prompt_length/clip_ratio",
"timing_s/start_profile",
"timing_s/generate_sequences",
"timing_s/generation_timing/max",
"timing_s/generation_timing/min",
"timing_s/generation_timing/topk_ratio",
"timing_s/gen",
"timing_s/reward",
"timing_s/old_log_prob",
"timing_s/ref",
"timing_s/adv",
"timing_s/update_actor",
"timing_s/step",
"timing_s/testing",
"timing_s/stop_profile",
"timing_per_token_ms/update_actor",
"timing_per_token_ms/ref",
"timing_per_token_ms/gen",
"timing_per_token_ms/adv",
"perf/total_num_tokens",
"perf/time_per_step",
"perf/throughput"
]
以下是您提供的 Actor 相关指标的详细解释:
1. 策略多样性与分布指标¶
actor/entropy(策略熵)- 含义:描述模型输出预测的不确定性(随机性)。
-
解读:熵值越高,表示模型输出越多样,还在积极探索;熵值下降过快,可能意味着模型陷入了局部最优(Mode Collapse),输出变得非常单一。
-
actor/ppo_kl(实际 KL 散度) - 含义:在当前训练步中,新策略与旧策略(采样时的策略)之间的平均 KL 散度。
- 解读:它反映了策略更新的步长。如果这个值突然飙升,说明模型训练不稳定,更新幅度过大。
2. KL 惩罚相关 (用于约束模型不偏离基准太远)¶
actor/kl_loss(KL 损失)- 含义:这是作为 Loss 函数一部分的 KL 惩罚项。
- 公式参考:通常为 \text{kl_coef} \times \text{KL}(\pi_{\theta} | \pi_{ref})。
-
解读:模型在优化奖励(Reward)的同时,必须支付这个“KL 成本”,以防止模型为了刷分而彻底变成无法沟通的乱码(即防止对 Reward Model 的过拟合)。
-
actor/kl_coef(KL 系数) - 含义:KL 惩罚项的权重系数。
- 解读:在 verl 中,这通常是动态调整的(Adaptive KL)。如果
ppo_kl太高,系统会自动调大这个系数来增强约束;反之则调小以鼓励更多更新。
3. 策略梯度与截断指标 (PPO 核心机制)¶
actor/pg_loss(策略梯度损失)- 含义:Actor 网络的核心损失函数。
-
解读:这是结合了优势函数(Advantage)和概率比率(Ratio)后的损失。GRPO 的目标就是最小化这个值(通常表现为负值,因为是最大化奖励)。
-
actor/pg_clipfrac(策略截断比例) - 含义:在当前 Batch 中,概率变化超过 PPO 允许范围(通常是 0.8 到 1.2 之间)而被强制截断(Clip)的 Token 比例。
- 解读:
- 如果该值在 0.1~0.3 左右,说明训练比较健康。
-
如果该值过高(如 >0.5),说明学习率太大,模型试图一步跨得太远。
-
actor/pg_clipfrac_lower(下限截断比例) - 含义:专门指代那些概率变动比例低于下限(例如 1 - \epsilon)而被截断的比例。这通常发生在模型想要大幅降低某个动作概率时。
4. 训练稳定性指标¶
actor/grad_norm(梯度范数)- 含义:所有参数梯度的 L2 范数(模长)。
- 解读:这是监控梯度爆炸的关键指标。
- 如果值突然变得非常大,可能会导致训练崩溃。
- verl 通常会设置
max_grad_norm(如 1.0)进行梯度裁剪。如果该值长期维持在裁剪阈值附近,可能需要检查学习率是否过高。
基础响应长度¶
(response_length/...)
这组指标反映了当前训练批次中,模型生成内容的原始长度统计(通常以 Token 为单位)。
response_length/mean(平均长度)- 含义:当前 Batch 中所有回答的平均长度。
-
监控点:如果这个值在训练过程中持续上升且没有停止迹象,模型可能在通过“多说话”来刷分(Length Bias)。
-
response_length/max&min(最大/最小长度) - 含义:当前 Batch 中最长和最短的回答。
-
监控点:
max经常触及你的max_response_length设定值,说明你的长度限制可能设小了,模型的话还没说完就被切断了。 -
response_length/clip_ratio(截断比例) - 含义:回答长度达到预设最大限制而被强制截断(Truncated)的样本比例。
- 解读:如果这个值很高(例如 > 0.1),说明大量回答被强制掐断了,这会严重影响模型学习逻辑的完整性。
非异常终止响应长度¶
(response_length_non_aborted/...)
在分布式训练或大规模采样中,部分样本可能会因为超时、显存溢出(OOM)或其他系统错误而“终止(Aborted)”。这组指标排除了这些无效样本,只统计成功完成推理的回答。
non_aborted/mean(有效平均长度)-
含义:仅针对那些正常生成结束符(EOS)或在正常流程内结束的回答计算平均长度。
-
non_aborted/clip_ratio(有效截断比例) - 含义:在所有成功生成的样本中,有多少比例是因为触及长度限制而被截断的。
- 关键点:如果
response_length/clip_ratio很高,但non_aborted/clip_ratio很低,说明大部分截断是由于系统异常导致的,而不是因为模型真的写了那么多。
1. perf/mfu/actor (模型算力利用率)¶
- 全称:Model FLOPs Utilization (MFU)。
- 含义:这是衡量训练效率的黄金标准。它表示 Actor 网络在训练过程中实际执行的浮点运算(FLOPS)占硬件(如 H100/A100)理论峰值算力的比例。
- 解读:
- 理想值:在大型配置下,通常在 30%~50% 之间。
- 异常值 0.0:在你提供的日志中该值为
0.0。这通常意味着当前步骤尚未完成正式的 Backward 权重更新,或者verl的 MFU 计算器尚未初始化/未捕捉到统计周期。 - 作用:如果你发现这个值很低(比如 < 10%),说明你的通信开销太大或 Pipeline 并行配置不合理,硬件大部分时间在等待数据,而不是在计算。
2. perf/max_memory_allocated_gb (峰值分配显存)¶
- 含义:指 PyTorch 的显存管理器在 GPU 上实际存放张量(Tensors)所占用的最大空间。
- 解读:
- 这反映了模型参数、梯度、优化器状态以及激活值(Activations)实际占用的空间。
- 数据参考:你的日志显示为 57.43 GB。这说明你的 Actor 网络(加之中间状态)已经吃掉了 80GB 显卡的大部分。
3. perf/max_memory_reserved_gb (峰值预留显存)¶
- 含义:指 PyTorch 从操作系统申请并锁定(Cache)的总显存。
- 与 Allocated 的区别:PyTorch 为了提高效率,不会在释放张量后立即把显存还给系统,而是留在池子里备用(即显存池)。
- 解读:
- 数据参考:你的日志显示为 88.44 GB。
- 风险预警:这是最接近 OOM(显存溢出)的指标。如果这个值接近你显卡的物理上限(比如 80GB 或 141GB),系统就会报错。
- 碎片率:如果
Reserved比Allocated大得多(如差距超过 30%),说明显存碎化严重,可能需要调整内存管理策略。
4. perf/cpu_memory_used_gb (系统内存占用)¶
- 含义:当前训练节点或集群所消耗的 CPU 内存(RAM)。
- 解读:
- 数据参考:你的日志显示为 1845.19 GB。这是一个非常大的数值,通常出现在超大规模集群或使用了 ZeRO-Offload(将优化器状态/权重卸载到 CPU)的情况下。
- 作用:监控此项是为了防止由于内存泄漏或数据预处理进程(DataLoader)过多导致整个系统被挂起或 OOM-Killer 杀掉进程。
精度问题
裸机跑得好好的,但是在docker里长跑,到200步的时候,两者表现不一样了:
- docker里的 显存指标突然拉满, entropy升高一段后迅速下降,kl loss 也突然暴涨,后续评测分数直线往下掉,推理也变成乱码
代码走读¶
以 GRPO + megatron后端为例,大致逻辑如下:
ray+GRPO算法¶
class RayPPOTrainer:
def fit(self):
for epoch in range(current_epoch, self.config.trainer.total_epochs):
for batch_dict in self.train_dataloader:
# 推理
gen_batch_output = self.actor_rollout_wg.generate_sequences(gen_batch_output)
# 可选:old_log_prob
old_log_prob = self.actor_rollout_wg.compute_log_prob(batch)
# 可选:ref_log_prob
ref_log_prob = self.actor_rollout_wg.compute_ref_log_prob(batch)
# update actor
actor_output = self.actor_rollout_wg.update_actor(batch)
推理训练后端¶
而self.actor_rollout_wg的四个子操作,根据后端不同,使用不同worker,megatorn后端使用megatron_worker.py
class AsyncActorRolloutRefWorker(ActorRolloutRefWorker):
class ActorRolloutRefWorker(MegatronWorker, DistProfilerExtension):
def init_model(self):
self.actor = MegatronPPOActor(
config=actor_cfg,
model_config=self.actor_model_config,
hf_config=self.hf_config,
tf_config=self.tf_config,
actor_module=self.actor_module,
actor_optimizer=self.actor_optimizer,
)
self._build_rollout(trust_remote_code=self.config.model.get("trust_remote_code", False))
self.ref_policy = MegatronPPOActor(
config=self.config.ref,
model_config=self.ref_model_config,
hf_config=self.hf_config,
tf_config=self.tf_config,
actor_module=self.ref_module,
actor_optimizer=None,
)
def _build_rollout(self, trust_remote_code=False):
self.rollout = get_rollout_class(rollout_config.name, rollout_config.mode)(
config=rollout_config, model_config=model_config, device_mesh=rollout_device_mesh
)
def generate_sequences(self, prompts: DataProto):
output = self.rollout.generate_sequences(prompts=prompts)
def compute_log_prob(self, data: DataProto):
output, entropys, layers_topk_idx = self.actor.compute_log_prob(data=data, calculate_entropy=True)
# save 2 old_log_probs
def compute_ref_log_prob(self, data: DataProto):
output, _, _ = self.ref_policy.compute_log_prob(data=data, calculate_entropy=False)
# save 2 ref_log_prob
def update_actor(self, data: DataProto):
metrics = self.actor.update_policy(dataloader=dataloader)
推理后端¶
vllm
训练后端¶
megatron
待验证选项:
- use_dynamic_bsz
- self.use_fused_kernels
最终走 from megatron.core.pipeline_parallel import get_forward_backward_func
loss 计算¶
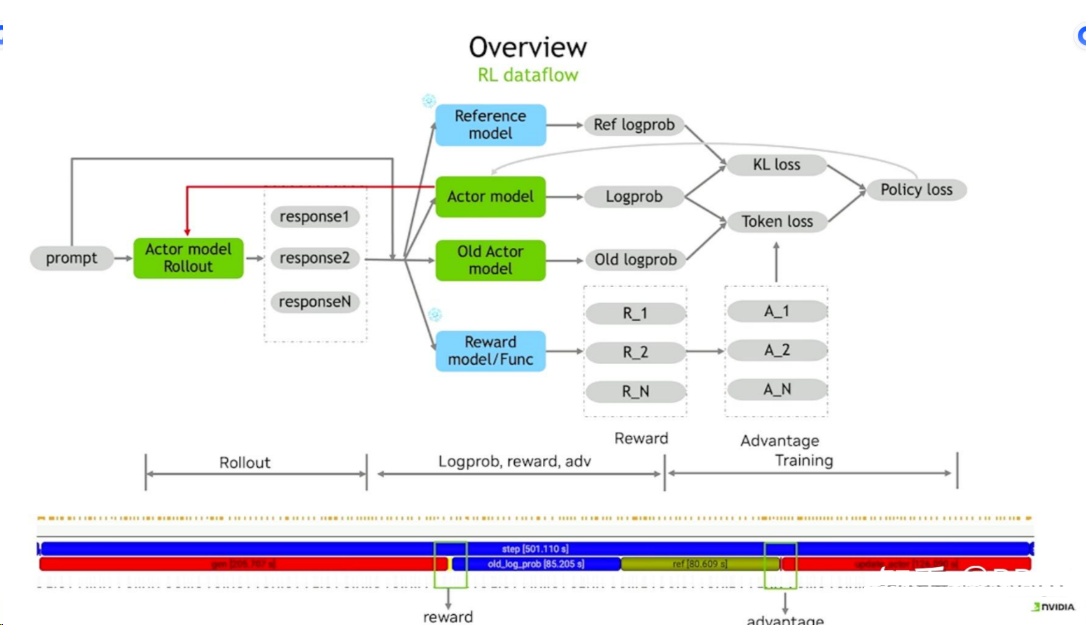
这里loss计算的代码又重构了
def loss_func
# pg_loss 看上去和上图 Token loss 是一个含义
pg_loss, pg_metrics = policy_loss_fn(
old_log_prob=old_log_prob,
log_prob=log_prob,
)
policy_loss = pg_loss
# policy_loss = pg_loss - entropy_coeff * entropy_loss
# kl loss计算如上图
kld = kl_penalty(logprob=log_prob, ref_logprob=ref_log_prob, kl_penalty=self.config.kl_loss_type)
kl_loss = agg_loss(loss_mat=kld, loss_mask=response_mask, loss_agg_mode=self.config.loss_agg_mode)
policy_loss = policy_loss + kl_loss * self.config.kl_loss_coef
old log p
用于重要性采样

vllm优化¶
FSDP训练优化¶
特性:multi-turn¶
swift现已支持multi-turn
VeRL 对 multi-turn的支持
- 基于SGlang的multi-turn
- 推荐使用
- 基于agent_loop设计,参考zhihu,官方wiki
- 但是没有商发, 评论区和issue都有相当多的bug
精度问题¶
KL Loss 和 Grad Norm¶
这是一个在深度强化学习(Deep Reinforcement Learning, DRL),特别是基于策略梯度(Policy Gradient)的方法,如VeRL(可能指的是某种基于[V]ariational或[V]olcano Engine的RL框架,结合RLHF/PPO)中常见的训练不稳定(Training Instability)现象,尤其是涉及到大规模模型(如LLM)的训练。
-
KL Loss 陡增 (\(D_{KL}\) Spike)
-
含义: 在 VeRL/PPO 这类算法中,KL 散度(Kullback-Leibler Divergence)通常用于衡量新策略 (\(\pi_{\text{new}}\)) 与旧策略 (\(\pi_{\text{old}}\)) 之间的差异。它确保策略更新不会偏离太远。
- 陡增的意义:
- 策略剧烈变化: 意味着在某一步更新中,新策略相对于旧策略发生了极大的变化。
- PPO/KL 约束失效: 这表明用于限制策略更新幅度(如 PPO 中的 Clipping 或 KL 惩罚项)的机制可能失效或不足以应对当前数据批次。
- 探索过度/错误更新: 模型可能在一个或少数几个批次数据上进行了过度激进的更新,导致策略分布远离了之前收集数据时的策略分布。
-
合理表现:
- 在稳定训练中,KL Loss 应该保持在一个较小的、受控的范围内,通常围绕设定的 KL 目标值(\(D_{KL}^{\text{target}}\))波动。
- 陡增到非常大的值(如从 0.01 增加到 1.0 甚至更高)是不合理的,通常预示着训练即将或已经进入崩溃(Divergence)状态,尽管 Reward 曲线可能由于延迟反馈或采样方差而暂时保持对齐或看似稳定。
-
Grad Norm 陡增(梯度范数爆炸)
-
含义: 梯度范数(Gradient Norm, \(\|g\|_2\))是模型所有参数梯度向量的 \(L_2\) 范数。它代表了权重更新的总体“力量”或“幅度”。
- 陡增的意义:
- 梯度爆炸(Exploding Gradients): 这是深度学习训练中一个经典的不稳定问题。它意味着当前批次数据产生了非常大的梯度,如果没有处理(如梯度裁剪),将会导致权重被过度更新。
- 模型参数发散: 极大的梯度更新可能导致模型参数(权重)跳到损失函数的病态(pathological)区域,从而产生更大的梯度,形成恶性循环,最终可能导致参数变为
NaN或Inf,训练崩溃。 - 罕见样本或数据问题: 可能是遇到了数据集中极端的、难以处理的或损坏的样本批次,导致了巨大的梯度。
- 合理表现:
- 在稳定训练中,Grad Norm 应该保持在一定范围的波动。如果使用了梯度裁剪(Gradient Clipping),则 Grad Norm 不应超过裁剪阈值。
- 陡增到远超平时波动范围的值(尤其是在没有梯度裁剪或裁剪阈值太高的情况下)是不合理的,是训练不稳定的明确信号。
为什么 Reward 曲线能对齐?
Reward 曲线对齐但 KL/Grad Norm 陡增,可能意味着:
- 策略网络和价值网络的独立性: 即使策略更新过度,如果价值函数网络(Value Function)的更新相对稳定,或者早期的 Reward 结果是在策略崩溃前就已经计算并记录下来,Reward 曲线可能短期内不受影响。
- 采样方差: 在强化学习中,Reward 曲线本身就具有很高的方差。一两个批次的剧烈更新可能不会立即体现在平滑后的 Reward 曲线中,尤其是在采样间隔较大的情况下。
- 延迟效应: 策略的剧烈变化导致模型输出“胡言乱语”或“无效动作”的负面影响,需要一段时间(更多步数、更多环境交互)才会反映在 Reward 的平均表现上。
诊断与解决建议
既然你是在 NPU 上复现 GPU 流程,请重点关注以下可能导致不稳定的因素:
| 潜在原因 | 解决建议 |
|---|---|
| 梯度爆炸(最常见) | 应用或调整梯度裁剪(Gradient Clipping)。 确保 Grad Norm 限制在一个合理的阈值(例如 0.5 或 1.0)。如果已应用,请尝试降低阈值。 |
| KL 惩罚系数/学习率 | 降低策略网络的学习率(Learning Rate)。 策略更新太快是 KL Loss 陡增的常见原因。尝试使用更小的 \(\alpha\)。 |
| PPO Clipping 阈值 \(\epsilon\) | 检查 PPO 的 \(\epsilon\) 参数。 尝试降低 clip_range(如从 0.2 降到 0.1),以更严格地限制策略比率 \(r_t(\theta)\)。 |
| 数据精度 | 检查 NPU 上的数据类型。 如果 NPU 使用 FP16 或其他低精度训练,低精度训练更容易引起梯度和损失的尖峰。尝试使用更高的精度(如 FP32 或 BF16),或使用精度敏感的优化器/归一化。 |
| Warmup 阶段 | 确保在训练初期有适当的 Learning Rate Warmup 阶段,以避免初始阶段就产生巨大的梯度。 |
| 批量大小/经验重放 | 检查批次大小(Batch Size)。 批次太小会增加梯度的方差,可能导致尖峰。 |
| NaN/Inf 问题 | 检查是否有任何 NaN 或 Inf 出现在 Loss 或参数中。KL Loss 的计算(如 \(\log(\pi)\))在 \(\pi \to 0\) 时可能产生极值,考虑添加 \(\epsilon\) 或进行数值稳定处理。 |
总结: KL Loss 和 Grad Norm 突然陡增是不合理且危险的,是训练不稳定的强烈信号。你需要尽快采取措施(主要是梯度裁剪和调整学习率/KL惩罚)来控制更新幅度,否则训练可能会在未来的步骤中崩溃。